










লেখক: কারেনজে, ফোরসাইট নিউজ
২০২৬ সালের ২০ মার্চ, অল-ইন ভেঞ্চার পডকাস্টে একটি অসাধারণ কথোপকথন ঘটেছিল।
ভিসি লিডার চামাথ পালিহাপিটিয়া নভিডিয়ার সিইও হুয়াং রেনক্সনকে বলেন যে, বিটটেনসরে একটি প্রকল্প একটি বেশ পাগলামির মতো প্রযুক্তিগত সাফল্য অর্জন করেছে—এটি ইন্টারনেটে ডিস্ট্রিবিউটেড কম্পিউটিং ব্যবহার করে একটি বড় ভাষা মডেল প্রশিক্ষণ দিয়েছে, যা সম্পূর্ণভাবে ডিসেন্ট্রালাইজড, কোনো কেন্দ্রীয় ডেটা সেন্টারের অংশগ্রহণ ছাড়াই।
হুয়াং রেনক্সান এটিকে এড়াননি। তিনি এটিকে 'Folding@home'-এর আধুনিক সংস্করণের সাথে তুলনা করেছেন, যা ২০০০-এর দশকে সাধারণ ব্যবহারকারীদের অব্যবহৃত কম্পিউটিং ক্ষমতা অবদান রাখার মাধ্যমে প্রোটিন ভাঁজের সমস্যার বিরুদ্ধে একসাথে লড়াইয়ের জন্য একটি বিতরিত প্রকল্প ছিল।
4 দিন আগে, 16 মার্চ, এনথ্রোপিকের সহ-প্রতিষ্ঠাতা জ্যাক ক্লার্ক একটি এআই গবেষণা প্রগতি রিপোর্টে এই বিপ্লবটিকে বিস্তারিতভাবে উল্লেখ ও উদ্ধৃত করেছিলেন: বিটটেনসর ইকোসিস্টেমের সাবনেট টেম্পলার (SN3) 720 বিলিয়ন প্যারামিটারের বড় মডেল (কভেন্যান্ট 72B) এর বিতরিত প্রশিক্ষণ সম্পন্ন করেছে, যার পারফরম্যান্স Meta-এর 2023 সালে প্রকাশিত LLaMA-2-এর সমতুল্য।
জ্যাক ক্লার্ক এই অধ্যায়টির নাম দিয়েছেন «ডিস্ট্রিবিউটেড ট্রেনিং দিয়ে এআই রাজনৈতিক অর্থনীতির চ্যালেঞ্জ», এবং তার বিশ্লেষণে জোর দিয়েছেন যে এটি একটি অবিরাম পর্যবেক্ষণযোগ্য প্রযুক্তি—তিনি একটি ভবিষ্যতের কল্পনা করতে পারেন: ডিভাইস-লেভেল এআই ব্যাপকভাবে ডিসেন্ট্রালাইজড ট্রেনিং দ্বারা উৎপাদিত মডেল ব্যবহার করবে, যখন ক্লাউড-ভিত্তিক এআই প্রোপ্রাইটারি বড় মডেলগুলি চালিয়ে যাবে।
বাজারের প্রতিক্রিয়া কিছুটা বিলম্বিত কিন্তু অত্যন্ত তীব্র: SN3 গত মাসে 440% এর বেশি বেড়েছে, গত দুই সপ্তাহে 340% এর বেশি বেড়েছে, এবং এর বাজার মূল্য 130 মিলিয়ন ডলারে পৌঁছেছে। সাবনেটের গল্পের বিস্ফোরণ সরাসরি TAO-এর জন্য ক্রয়ের চাপ হিসাবে প্রতিফলিত হবে। ফলস্বরূপ, TAO দ্রুত বেড়ে 377 ডলার পর্যন্ত পৌঁছেছিল, গত মাসে এটি দ্বিগুণ হয়েছে, এবং FDV প্রায় 75 বিলিয়ন ডলারে পৌঁছেছে।
প্রশ্ন হলো: SN3 ঠিক কী করেছে? এটি কেন আলোকসজ্জার কেন্দ্রে চলে এসেছে? ডিস্ট্রিবিউটেড ট্রেনিং এবং ডিসেন্ট্রালাইজড এআই-এর মূল্য বর্ণনা কীভাবে বিকশিত হবে?
সেই 72B মডেলটি
এই প্রশ্নের উত্তর দিতে হলে প্রথমে SN3-এর পারফরম্যান্স দেখতে হবে।
২০২৬ সালের ১০ মার্চ, কভেন্যান্ট এআই দল arXiv-এ একটি প্রযুক্তিগত রিপোর্ট প্রকাশ করে ঘোষণা করে যে Covenant-72B-এর প্রশিক্ষণ সম্পন্ন হয়েছে। এটি একটি 720 বিলিয়ন প্যারামিটারের বড় ভাষা মডেল, যা প্রায় 1.1 ট্রিলিয়ন টোকেনের কর্পাসে 70টি স্বতন্ত্র নোড পিয়ার (প্রতিটি রাউন্ডে প্রায় 20টি নোড সিঙ্ক্রোনাইজড, প্রতিটি নোডে 8টি B200 গ্রাফিক্স কার্ড সহ) ব্যবহার করে প্রশিক্ষণ লাভ করেছে।
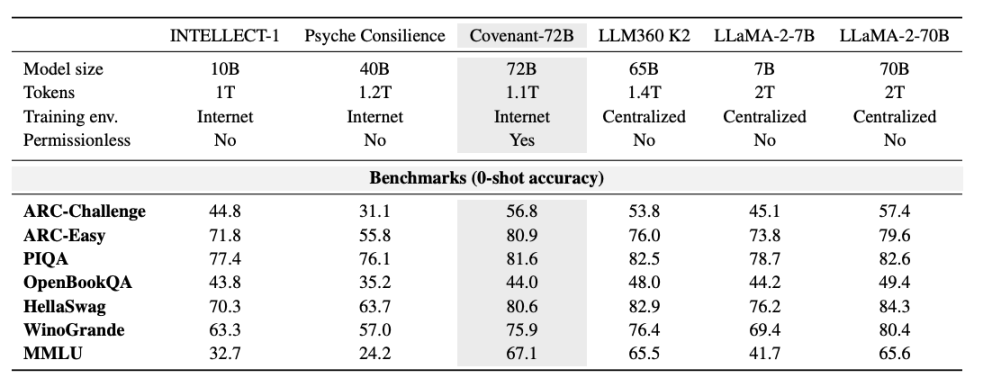
টেম্পলার বেঞ্চমার্ক সম্পর্কে কিছু ডেটা প্রদান করেছেন, যেখানে তুলনা করা হয়েছে Meta-এর 2023 সালে প্রকাশিত LLaMA-2-70B মডেলের সাথে। যেমনটি Anthropic-এর সহ-প্রতিষ্ঠাতা জ্যাক ক্লার্ক বলেছেন, 2026 সালে Covenant-72B একটু পুরনো মনে হতে পারে। MMLU-তে Covenant-72B-এর 67.1 স্কোর প্রায় মিলে যায় Meta-এর 2023 সালে প্রকাশিত LLaMA-2-70B (65.6 স্কোর)-এর সাথে।
আর 2026 সালের অগ্রগামী মডেলগুলি—GPT সিরিজ, Claude বা Gemini যাই হোক না কেন—এখনই লক্ষ লক্ষ GPU-এর উপর এমন প্যারামিটার সংখ্যা নিয়ে প্রশিক্ষণ সম্পন্ন করেছে যা 100 বিলিয়নেরও বেশি, এবং ইনফারেন্স, কোডিং, গণিতের দক্ষতার পার্থক্য শতাংশের নয়, বরং ক্রমের প্রশ্ন। এই বাস্তবিক পার্থক্যটি মার্কেটের মনোভাবের দ্বারা মুছে ফেলা উচিত নয়।
কিন্তু যদি এটিকে "ওপেন ইন্টারনেটের ডিস্ট্রিবিউটেড কম্পিউটিং পাওয়ার দিয়ে ট্রেন করা" এই প্রসঙ্গে বিবেচনা করা হয়, তাহলে এর অর্থ সম্পূর্ণ ভিন্ন হয়ে যায়।
একটি তুলনা করুন: একই ডিসেন্ট্রালাইজড ট্রেনিংয়ের অধীনে INTELLECT-1 (Prime Intellect টিম দ্বারা তৈরি, 10 বিলিয়ন প্যারামিটার) MMLU স্কোর 32.7; অন্যটি হল ওয়াইটলিস্টেড অংশগ্রহণকারীদের মধ্যে ডিস্ট্রিবিউটেড ট্রেনিংয়ের মাধ্যমে Psyche Consilience (40 বিলিয়ন প্যারামিটার), যার স্কোর 24.2। Covenant-72B 72B স্কেল এবং 67.1 MMLU স্কোরের সাথে ডিসেন্ট্রালাইজড ট্রেনিং পথে একটি উল্লেখযোগ্য সংখ্যা।
আরও গুরুত্বপূর্ণ বিষয় হলো, এই প্রশিক্ষণটি অনুমতি-হীন। যেকোনো ব্যক্তি প্রশিক্ষণে অংশগ্রহণকারী নোড হিসেবে যোগাযোগ করতে পারেন, পূর্বানুমতি বা সাদা তালিকার প্রয়োজন হয় না। ৭০টিরও বেশি স্বাধীন নোড বিশ্বজুড়ে যোগাযোগ করে কম্পিউটেশনাল পাওয়ার অবদান রেখেছে।
হুয়াং রেনক্সন কী বলেছেন, কী বলেননি
এই «সমর্থন»-এর বাইরের ব্যাখ্যাগুলি সংশোধন করতে পডকাস্ট আলাপচারিতার বিস্তারিতগুলি পুনর্স্থাপন করা উপকারী।
চামাথ পালিহাপিতিয়া কথোপকথনে বিটাটেন্সরের প্রযুক্তিগত সাফল্য হাওয়েন জেনের কাছে উপস্থাপন করেন এবং এটিকে একটি ল্লামা মডেলকে বিতরিত কম্পিউটিং শক্তি দিয়ে প্রশিক্ষণ দেওয়ার প্রক্রিয়া হিসাবে বর্ণনা করেন, যা "সম্পূর্ণভাবে বিতরিত, একসাথে অবস্থা বজায় রেখে"। হাওয়েন জেনের প্রতিক্রিয়া ছিল এটিকে "আধুনিক Folding@home"-এর সমতুল্য বলে তুলনা করা এবং ওপেন-সোর্স এবং প্রপ্রাইটারি মডেলগুলির সমান্তরালে সহাবস্থানের প্রয়োজনীয়তা নিয়ে আলোচনা করা।
লক্ষণীয় যে, হুয়াং রেনশুন বিটাটেন্সরের টোকেন বা কোনো বিনিয়োগ সংক্রান্ত প্রভাবের কথা সরাসরি উল্লেখ করেননি এবং ডিসেন্ট্রালাইজড এআই প্রশিক্ষণের বিষয়টিও আরও আলোচনা করেননি।
বিট্যানসর সাবনেট এবং SN3 বুঝুন
SN3-এর ব্রেকআউট বুঝতে, প্রথমে বিটটেনসর এবং তার সাবনেটগুলির কার্যপ্রণালী বুঝতে হবে। সহজ কথায়, বিটটেনসর হল একটি AI-ভিত্তিক পাবলিক চেইন এবং প্ল্যাটফর্ম, আর প্রতিটি সাবনেট হল একটি স্বতন্ত্র "AI উৎপাদন লাইন", যা প্রতিটির নিজস্ব মূল কাজ, ইনসেন্টিভ মেকানিজম এবং ডিসেন্ট্রালাইজড AI ইকোসিস্টেম গঠনের জন্য সহযোগিতা করে।
এর কার্যপ্রণালী স্পষ্ট এবং ডিসেন্ট্রালাইজড: সাবনেট মালিকরা সাবনেটের লক্ষ্য নির্ধারণ করেন এবং প্রেরণা মডেল তৈরি করেন; মাইনাররা সাবনেটে কম্পিউটেশনাল পাওয়ার প্রদান করে, AI-সংক্রান্ত কাজ (যেমন ইনফারেন্স, ট্রেনিং, স্টোরেজ ইত্যাদি) সম্পন্ন করে; ভেরিফায়াররা মাইনারদের অবদানের জন্য স্কোর দেয় এবং সেই স্কোরগুলি Bittensor কনসেনসাস লেয়ারে আপলোড করে; শেষ পর্যন্ত, Bittensor-এর Yuma কনসেনসাস অ্যালগরিদম প্রতিটি সাবনেটের সঞ্চিত পুরস্কারের ভিত্তিতে সাবনেটের অংশগ্রহণকারীদের প্রতিটির জন্য উপযুক্ত আয় বণ্টন করে।
বর্তমানে বিটটেনসরে ১২৮টি সাবনেট রয়েছে, যা ইনফারেন্স, সার্ভারলেস এআই ক্লাউড সার্ভিস, ইমেজ, ডেটা লেবেলিং, রিইনফোর্সমেন্ট লার্নিং, স্টোরেজ, কম্পিউটেশন ইত্যাদি বিভিন্ন এআই টাস্ককে কভার করে।
এবং SN3 হল এই সাবনেটগুলির মধ্যে একটি। এটি অ্যাপ্লিকেশন লেয়ার শেলিং করে না, বরং বিদ্যমান বড় মডেল API ভাড়া করে না, বরং সরাসরি AI শিল্প শৃঙ্খলের সবচেয়ে দামি এবং সবচেয়ে বন্ধ কেন্দ্রীয় অংশগুলির মধ্যে একটি—বড় মডেল প্রি-ট্রেনিং-এর দিকে নিয়ে যায়।
SN3 বিটটেনসর নেটওয়ার্কের মাধ্যমে বিভিন্ন ধরনের কম্পিউটিং সম্পদকে সমন্বিত করে বিতরণকৃত ট্রেনিংয়ের জন্য প্রচেষ্টা চালাচ্ছে। এই পদ্ধতিতে প্রোত্সাহন-ভিত্তিক বিতরণকৃত বড় মডেল ট্রেনিংয়ের মাধ্যমে প্রমাণিত হচ্ছে যে, মহাকায় কেন্দ্রীয় সুপারকম্পিউটার ক্লাস্টারের প্রয়োজন ছাড়াইও শক্তিশালী বেসিক মডেল ট্রেন করা সম্ভব। এর মূল আকর্ষণ হলো 'সমতা'—কেন্দ্রীয় ট্রেনিংয়ের সম্পদের একচেটিয়াত্বকে ভাঙতে, যাতে সাধারণ ব্যক্তি বা ছোট-মাঝারি প্রতিষ্ঠানগুলিও বড় মডেল ট্রেনিংয়ে অংশগ্রহণ করতে পারে, এবং বিতরণকৃত কম্পিউটিং ক্ষমতার মাধ্যমে ট্রেনিংয়ের খরচও কমানো যায়।
SN3-এর উন্নয়নের মূল শক্তি হলো Templar, যার পেছনে গবেষণা দল হলো Covenant Labs। এই দল আরও দুটি সাবনেট চালায়: Basilica (SN39, কম্পিউটিং সার্ভিসের জন্য) এবং Grail (SN81, RL-এর পরের ট্রেনিং এবং মডেল মূল্যায়নের জন্য)। তিনটি সাবনেট একটি উল্লম্বভাবে একীভূত ব্যবস্থা গঠন করে, যা বড় মডেলের প্রি-ট্রেনিং থেকে অ্যালাইনমেন্ট অপ্টিমাইজেশন পর্যন্ত সম্পূর্ণ প্রক্রিয়াকে কভার করে, এবং ডিসেন্ট্রালাইজড বড় মডেল ট্রেনিং-এর একটি সম্পূর্ণ ইকোসিস্টেম তৈরি করে।
বিশেষভাবে, মাইনাররা গণনার সম্পদ অবদান রাখে এবং গ্রেডিয়েন্ট আপডেট (মডেল প্যারামিটারের সমন্বয়ের দিক এবং পরিমাণ) নেটওয়ার্কে আপলোড করে; ভেরিফায়াররা প্রতিটি মাইনারের অবদানের গুণগত মান মূল্যায়ন করে এবং ত্রুটির উন্নতির মাত্রা অনুযায়ী চেইন-অন স্কোর প্রদান করে। ফলাফলগুলি পুরস্কারের ওজন নির্ধারণ করে, যা স্বয়ংক্রিয়ভাবে বণ্টন করা হয়, কোনও তৃতীয় পক্ষের উপর বিশ্বাসের প্রয়োজন হয় না।
প্রেরণার ডিজাইনের মূল বিষয় হলো, পুরস্কার সরাসরি আপনার অবদানের সাথে সংযুক্ত হবে যে আপনি মডেলটিকে কতটা ভালো করেছেন, শুধুমাত্র ক্যালকুলেশন ক্ষমতা উপস্থিতির উপর নয়। এটি মৌলিকভাবে ডিসেন্ট্রালাইজড পরিস্থিতিতে সবচেয়ে কঠিন সমস্যাটি সমাধান করে: মাইনারদের কাজ এড়ানোর প্রতিরোধ করা।
Covenant-72B কিভাবে যোগাযোগের দক্ষতা এবং উদ্দীপনার সামঞ্জস্যতা সমস্যা সমাধান করে?
একই মডেল ট্রেন করার জন্য কয়েক দশক অবিশ্বাস্য, হার্ডওয়্যারভিত্তিকভাবে বিভিন্ন এবং নেটওয়ার্ক কোয়ালিটি অসম নোডগুলিকে সমন্বিতভাবে কাজ করানোর দুটি চ্যালেঞ্জ রয়েছে: প্রথমত, যোগাযোগের দক্ষতা, যা স্ট্যান্ডার্ড ডিস্ট্রিবিউটেড ট্রেনিং সলিউশনগুলি নোডগুলির মধ্যে উচ্চ ব্যান্ডউইথ এবং কম ল্যাটেন্সির সংযোগের প্রয়োজনীয়তা রাখে; দ্বিতীয়ত, উদ্দীপনা-সঙ্গতি, কীভাবে ক্ষতিকর নোডগুলিকে ভুল গ্রেডিয়েন্ট জমা দিতে থামানো যায়? কীভাবে প্রতিটি অংশগ্রহণকারীকে আসলেই ট্রেনিং করতে বাধ্য করা যায়, অন্যদের ফলাফলের নকল করার পরিবর্তে?
SN3 এই দুটি সমস্যা সমাধান করে দুটি কেন্দ্রীয় উপাদান দিয়ে: SparseLoCo এবং Gauntlet।
SparseLoCo যোগাযোগ দক্ষতার সমস্যা সমাধান করে। প্রচলিত বিতরিত প্রশিক্ষণে প্রতিটি পদক্ষেপে সম্পূর্ণ গ্রেডিয়েন্ট সিঙ্ক্রোনাইজ করা হয়, যার ডেটা পরিমাণ অত্যন্ত বড়। SparseLoCo-এর পদ্ধতি হল: প্রতিটি নোড স্থানীয়ভাবে 30 পদক্ষেপের অভ্যন্তরীণ অপ্টিমাইজেশন (AdamW) চালায়, এরপর উৎপন্ন “প্রতিকৃতি গ্রেডিয়েন্ট”গুলিকে সংকুচিত করে অন্যান্য নোডগুলিতে আপলোড করে। সংকুচনের পদ্ধতিগুলির মধ্যে রয়েছে Top-k স্পারসিটি (শুধুমাত্র সবচেয়ে গুরুত্বপূর্ণ গ্রেডিয়েন্ট উপাদানগুলি রাখা), ত্রুটি ফিডব্যাক (বাদ দেওয়া অংশগুলি সংরক্ষণ করে পরবর্তী পর্যায়ে সঞ্চয় করা), এবং 2-বিট কোয়ান্টাইজেশন। চূড়ান্ত সংকুচন অনুপাত 146x-এরও বেশি।
অর্থাৎ, যা আগে 100MB ট্রান্সমিট করার প্রয়োজন হত, এখন তার চেয়ে কম, মাত্র 1MB এর বেশি লাগছে না।
এটি সিস্টেমকে সাধারণ ইন্টারনেট (আপলোড 110 মেগাবিট/সেকেন্ড, ডাউনলোড 500 মেগাবিট/সেকেন্ড) এর ব্যান্ডউইথ সীমার মধ্যে গণনা ব্যবহারকে প্রায় 94.5% তে রাখে—20টি নোড, প্রতিটি নোডে 8টি B200, প্রতিটি কমিউনিকেশন রাউন্ড শুধুমাত্র 70 সেকেন্ড সময় নেয়।
গ্যান্টলেট প্রেরণামূলক সামঞ্জস্যতা সমস্যা সমাধান করে। এটি বিটটেনসর ব্লকচেইন (সাবনেট ৩) এ চলে এবং প্রতিটি নোড দ্বারা জমা দেওয়া প্রতিকৃতি গ্রেডিয়েন্টের মান যাচাইয়ের দায়িত্ব বহন করে। এটি করে: একটি ছোট ডেটা ব্যাচ ব্যবহার করে "এই নোডের গ্রেডিয়েন্টটি ব্যবহার করার পরে মডেলের ক্ষতি কতটা কমেছে" তা পরীক্ষা করা, ফলাফলকে LossScore বলা হয়। একইসাথে, সিস্টেমটি পরীক্ষা করে যে নোডটি কি তার বরাদ্দকৃত ডেটা দিয়েই প্রশিক্ষণ দিচ্ছে—যদি একটি নোড র্যান্ডম ডেটাতে ক্ষতির উন্নতি তার বরাদ্দকৃত ডেটার চেয়েও ভালো হয়, তবে এটির নেতিবাচক স্কোর দেওয়া হবে।
প্রতিটি ট্রেনিং রাউন্ডে শুধুমাত্র সর্বোচ্চ স্কোর পাওয়া নোডের গ্রেডিয়েন্ট অ্যাগ্রিগেশনে অংশগ্রহণ করে, বাকি সব নোড এই রাউন্ড থেকে বাদ পড়ে। অতিরিক্ত প্রতিযোগীদের সময়সাপেক্ষে প্রতিস্থাপন করা হয়, যাতে সিস্টেমটি স্থিতিশীল থাকে। সমগ্র ট্রেনিং প্রক্রিয়ায়, গড়ে প্রতিটি রাউন্ডে 16.9টি নোডের গ্রেডিয়েন্ট অ্যাগ্রিগেশনে অন্তর্ভুক্ত হয়, এবং মোট 70টিরও বেশি অনন্য নোড ID একবার বা তারও বেশি সময় অংশগ্রহণ করেছে।
ডিসেন্ট্রালাইজড এআইয়ের মূল্য বর্ণনা মৌলিকভাবে পরিবর্তন হচ্ছে
প্রযুক্তিগত এবং শিল্পের দৃষ্টিকোণ থেকে দেখলে, কভেন্যান্ট-72B এর দিকটি কয়েকটি বাস্তব অর্থ বহন করে।
প্রথমত, "বিতরিত প্রশিক্ষণ শুধুমাত্র ছোট মডেলের জন্য উপযুক্ত" এই ধারণাকে ভাঙ্গা হয়েছে। যদিও এখনও সর্বশেষ মডেলের সাথে দূরত্ব রয়েছে, কিন্তু এই দিকটির স্কেলযোগ্যতা প্রমাণিত হয়েছে।
দ্বিতীয়ত, অনুমতি ছাড়াই অংশগ্রহণ বাস্তবসম্মত। এটি অবহেলিত হয়েছে। আগের বিতরিত প্রশিক্ষণ প্রকল্পগুলি সাদা তালিকা নির্ভর করত—শুধুমাত্র অনুমোদিত অংশগ্রহণকারীরাই কম্পিউটেশনাল পাওয়ার অবদান রাখতে পারত। SN3-এর এই প্রশিক্ষণে, যে কেউ যথেষ্ট কম্পিউটেশনাল পাওয়ার রাখেন, তিনি যোগাযোগ করতে পারেন, এবং যাচাইকরণ ব্যবস্থা দুষ্টু অবদানকারীদের ফিল্টার করে। এটি “প্রকৃত ডিসেন্ট্রালাইজেশন”-এর দিকে একটি বাস্তব পদক্ষেপ।
তৃতীয়ত, বিটটেনসরের dTAO মেকানিজম সাবনেটের মূল্য নির্ধারণকে সম্ভব করে তোলে। dTAO প্রতিটি সাবনেটকে তাদের নিজস্ব অ্যালফা টোকেন জারি করতে দেয়, যার মাধ্যমে AMM মেকানিজমের মাধ্যমে বাজার সিদ্ধান্ত নেয় যে কোন সাবনেটগুলি বেশি TAO প্রদান পাবে। এটি SN3-এর মতো সুনির্দিষ্ট ফলাফল উৎপাদনকারী সাবনেটগুলির জন্য একটি কাঁচা কিন্তু কার্যকরী মূল্য ধরে রাখার মেকানিজম প্রদান করে। অবশ্যই, এই মেকানিজমটিও গল্প এবং আবেগের দ্বারা প্রভাবিত হতে পারে, কারণ LLM প্রশিক্ষণের ফলাফলের গুণগতমান সাধারণ বাজার অংশগ্রহণকারীদের জন্য স্বতন্ত্রভাবে মূল্যায়ন করা কঠিন।
চতুর্থ, ডিসেন্ট্রালাইজড এআই প্রশিক্ষণের রাজনৈতিক-অর্থনৈতিক প্রভাব। জ্যাক ক্লার্ক Import AI-এ এই প্রশ্নটিকে “কে এআইয়ের ভবিষ্যৎ নিয়ন্ত্রণ করবে” এই পর্যায়ে উত্থাপন করেছেন। বর্তমানে অগ্রণী মডেল প্রশিক্ষণ কয়েকটি বড় ডেটা সেন্টার সম্পদ রাখা প্রতিষ্ঠানগুলির দ্বারা একচেটিয়াভাবে নিয়ন্ত্রিত, যা শুধুমাত্র ব্যবসায়িক সমস্যা নয়, বরং ক্ষমতার গঠনেরও সমস্যা। বিতরণীকৃত প্রশিক্ষণ যদি প্রযুক্তিগত অগ্রগতি অব্যাহত রাখে, তবে কিছু মডেলের ধরন (যেমন: নির্দিষ্ট ক্ষেত্রের ছোট আকারের অগ্রণী মডেল)এর জন্য সত্যিকারের ডিসেন্ট্রালাইজড উন্নয়ন পরিবেশ গড়ে তোলা সম্ভব। তবে, এই দৃশ্যটি এখনও দূরে।
সারাংশ: একটি বাস্তব মাইলফলক, এবং অসংখ্য বাস্তব সমস্যা
হুয়াং রেনক্সন বলেছেন, এটি একটি "আধুনিক Folding@home"-এর মতো। Folding@home অণু সিমুলেশন ক্ষেত্রে বাস্তব অবদান রেখেছে, কিন্তু এটি বড় ফার্মাসিউটিক্যাল কোম্পানিগুলির মূল গবেষণা ও উন্নয়নের অবস্থানকে হুমকির মুখে ফেলেনি। এই তুলনা খুবই সঠিক।
SN3 প্রোটোকলটি চালু করেছে এবং ডিস্ট্রিবিউটেড ট্রেনিংয়ের সম্ভাব্য দিকগুলি যাচাই করেছে। তবে প্রযুক্তিগত এবং শিল্পের দৃষ্টিকোণ থেকে দেখলে, এই পারফরম্যান্সের পিছনে এখনও অনেকগুলি সমস্যা রয়েছে যেগুলির বিষয়ে খুব কম মানুষ গুরুত্বপূর্ণভাবে আলোচনা করতে চায়:
MMLU নিজেই একটি বিতর্কিত মেট্রিক, যার প্রকাশ্য বেঞ্চমার্কের প্রশ্ন ও উত্তরগুলি ট্রেনিং সেটে প্রবেশের ঝুঁকি বহন করে। আরও গুরুত্বপূর্ণ বিষয় হলো তুলনামূলক বেসলাইনের পছন্দ: পেপারটি LLaMA-2-70B এবং LLM360 K2-এর সাথে তুলনা করেছে, যা 2023 থেকে 2024 এর পুরনো মডেল; একই সময়কালে 65 থেকে 70 পয়েন্ট, Grok এবং DouBao-এর ক্ষেত্রে মধ্যম-নিচু এবং শুরুর স্তরের হিসাবে বিবেচিত হয়, Claude-এর ক্ষেত্রে এটি গুরুতরভাবে পিছিয়ে যাওয়ার মতো। যদি এটিকে ডাইনামিকভাবে আপডেটযুক্ত লিস্ট বা পOLLUTIOn-প্রতিরোধী ডিজাইনযুক্ত নতুন প্রজন্মের বেঞ্চমার্কের উপর রাখা হয়, তবে উপসংহারটি আরও সৎহীন হত।
আরও গুরুত্বপূর্ণ বিষয় হলো, মডেলের ক্ষমতার সীমানা নির্ধারণ করে এমন উচ্চ মানের ডেটা—কথোপকথনের ডেটা, কোড, গণিতের প্রমাণ, বৈজ্ঞানিক গবেষণা—এগুলি বড় কোম্পানি, প্রকাশনা প্রতিষ্ঠান এবং শিক্ষাগত ডেটাবেসগুলিতে থাকবে। ক্যালকুলেশনের ক্ষমতা ডেমোক্রেটাইজড হয়েছে, কিন্তু ডেটা প্রান্তে এখনও অলিগার্কিক কাঠামো বিদ্যমান, এই বিরোধটি কখনও আলোচিত হয়নি।
নিরাপত্তার বিষয়ে, অনুমতি ছাড়া অংশগ্রহণ মানে আপনি জানেন না যে ৭০টিরও বেশি নোডের পিছনে কে আছে এবং তারা কোন ডেটা দিয়ে প্রশিক্ষণ দিচ্ছে। গ্যানটেল স্পষ্টভাবে অস্বাভাবিক গ্রেডিয়েন্টগুলি ফিল্টার করতে পারে, কিন্তু সূক্ষ্ম ডেটা পয়জনিংয়ের বিরুদ্ধে প্রতিরোধ করতে পারে না—যদি একটি নোড কোনো ক্ষতিকর কনটেন্টের দিকে সিস্টেম্যাটিকভাবে কয়েকটি অতিরিক্ত প্রশিক্ষণ চক্র দেয়, তবে উৎপন্ন গ্রেডিয়েন্টের পরিবর্তনগুলি এতটাই সূক্ষ্ম হয়ে যায় যে লস স্কোরিংয়ের মাধ্যমে এটি পারিতোষিকভাবে পাস করে, কিন্তু মডেলের আচরণের উপর সঞ্চয়ীভাবে বিস্থাপনা ঘটায়। চূড়ান্ত প্রশ্নটি হল: ফাইন্যান্স, মেডিকেল, লিগ্যাল—এইসব উচ্চ-কমপ্লায়েন্স, নিরাপত্তা-কঠোর পরিস্থিতিতে, কয়েকটি anonimous node-এর দ্বারা প্রশিক্ষিত, ডেটা-সোর্সিংয়ের ট্রেসবিলিটি-অসম্পূর্ণ মডেলকে ব্যবহার করা কীভাবে ঝুঁকির সৃষ্টি করবে?
একটি গঠনগত সমস্যা সম্পর্কে সোজাসুজি বলা উচিত: Covenant-72B নিজেই Apache 2.0 লাইসেন্সে ওপেন সোর্স করা হয়েছে এবং SN3 টোকেন ব্যবহার করে না। SN3 টোকেন ধারণকারীরা মডেলটির ব্যবহারের যেকোনো প্রত্যক্ষ আয় নয়, বরং এই সাবনেটের ভবিষ্যতে নতুন মডেলের নিরন্তর উৎপাদনের ফলে উৎপাদিত এমিশন লাভের সাথে ভাগাভাগি করে। এই মূল্য শৃঙ্খলটি নিরন্তর প্রশিক্ষণ উৎপাদন এবং Bittensor-এর সমগ্র নেটওয়ার্কের এমিশন মেকানিজমের স্বাস্থ্যকর কার্যকারিতার উপর নির্ভরশীল। যদি ভবিষ্যতে প্রশিক্ষণ বন্ধ হয়ে যায়, অথবা নতুন প্রশিক্ষণের ফলাফলের মান প্রত্যাশিতের মতো না হয়, তবে টোকেনের মূল্যায়নের 논গুলি দুর্বল হয়ে পড়বে।
এই প্রশ্নগুলি তালিকাভুক্ত করা হয়েছে ক্যাভেন্ট-72B-এর গুরুত্বকে নাকচ করার জন্য নয়। এটি প্রমাণ করেছে যে যা আগে অসম্ভব বলে মনে করা হত, তা সম্ভব—এই তথ্যটি অদৃশ্য হবে না। কিন্তু করা এবং এর অর্থ কী, এটি দুটি ভিন্ন বিষয়।
SN3 টোকেন গত মাসে 440% বৃদ্ধি পেয়েছে। এই ব্যবধানটি শুধুমাত্র স্পেকুলেশন নাও হতে পারে, বরং কাহিনীর গতি সবসময় বাস্তবতার গতির চেয়ে দ্রুত। এই ব্যবধানটি চূড়ান্তভাবে বাস্তবতা দ্বারা পূরণ হবে নাকি বাজার দ্বারা সংশোধিত হবে, তা নির্ভর করছে Covenant AI দলের পরবর্তী কী প্রদান করা।
গুরুত্বপূর্ণ বিষয় হলো, গ্রিসকেল জানুয়ারি 2026-এ TAO ETF-এর আবেদন জমা দিয়েছে, যা প্রতিষ্ঠিত মূলধনের জন্য এই ক্ষেত্রে প্রবেশের সংকেত দেয়। এছাড়াও, 2025 সালের ডিসেম্বরে বিটটেনসর TAO-এর দৈনিক সরবরাহ অর্ধেক করেছে, যা সরবরাহের গঠনগত কঠোরতাকে আরও বাড়িয়ে তুলছে।
রেফারেন্স লিঙ্ক:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95