










تخيل هذا المشهد:
طلبت من وكيل الذكاء الاصطناعي مساعدتك في إصلاح عيب في الكود. فتح المشروع، وقرأ 20 ملفًا، وعدل بعض الأشياء، وتشغيل الاختبارات، ففشلت، ثم عدل مرة أخرى وتشغيل الاختبارات، وما زالت فاشلة... تكرر هذا العملية أكثر من عشر مرات، وفي النهاية — لم يتم إصلاحه.
أطفأت الكمبيوتر وشعرت بالراحة. ثم تلقيت فاتورة API.
قد تجعلك الأرقام أعلاه تأخذ نفسًا عميقًا — إن إصلاح الأخطاء بشكل ذاتي من قبل عوامل الذكاء الاصطناعي تحت واجهات برمجة التطبيقات الرسمية في الخارج غالبًا ما يستهلك أكثر من مليون رمز في المهمة الواحدة غير المصلحة، مع تكاليف تتراوح بين عشرات ومئات الدولارات.
في أبريل 2026، نُشرت ورقة بحثية مشتركة من قبل جامعة ستانفورد ومعهد ماساتشوستس للتكنولوجيا وجامعة ميشيغان، وفتحت لأول مرة بشكل منهجي "الصندوق الأسود" لـ AI Agent في مهام البرمجة—أين تنفق الأموال بالضبط، وهل هي تستحق التكلفة، وهل يمكن التنبؤ بها مسبقًا، وكانت الإجابات مذهلة.
الاكتشاف الأول: إن تكلفة كتابة الكود بواسطة العامل تبلغ 1000 ضعف تكلفة المحادثة العادية مع الذكاء الاصطناعي.
قد يظن الناس أن إنفاق المال على جعل الذكاء الاصطناعي يكتب لك الشيفرة يعادل إنفاق المال على جعل الذكاء الاصطناعي يتحدث معك عن الشيفرة.
أظهرت الورقة مقارنة:
استهلاك رموز مهام الترميز Agentic يبلغ حوالي 1000 ضعف استهلاك مهام أسئلة وأجوبة الكود والاستدلال الكودي العادية.
تفاوت بثلاثة مستويات من العشرة.
لماذا يحدث هذا؟ أشار البحث إلى حقيقة أن المال لا يُنفق على "كتابة الكود"، بل يُنفق على "قراءة الكود".
هنا، "القراءة" لا تشير إلى قراءة الإنسان للشفرة، بل إلى أن العميل يحتاج أثناء عمله إلى تزويد النموذج باستمرار بسياق المشروع بأكمله، وسجل العمليات السابقة، ومعلومات الأخطاء، ومحتوى الملفات دفعة واحدة. مع كل جلسة حوار إضافية، يصبح هذا السياق أطول؛ والنماذج تُحسب تكلفتها بناءً على عدد الـTokens — كلما أطعمت النموذج أكثر، دفعت أكثر.
دعنا نضرب مثلاً: إنه مثل استدعاء فني لإصلاح شيء، حيث يجب عليك أن تقرأ له من البداية إلى النهاية مخططات المبنى بأكمله قبل أن يحرك أي مفتاح — تكلفة قراءة المخططات أعلى بكثير من تكلفة شد البراغي.
لخص البحث هذه الظاهرة في جملة واحدة: العامل الذي يدفع تكلفة الوكلاء هو الزيادة الأسية في عدد رموز الإدخال، وليس رموز الإخراج.
الاكتشاف الثاني: نفس الخطأ، تشغيله مرتين، يمكن أن يختلف التكلفة ضعفين — وكلما كان الخطأ أكثر تكلفة، كان أكثر عدم استقرار
الأمر الأكثر إزعاجًا هو العشوائية.
طلب الباحثون من نفس العامل تشغيل نفس المهمة أربع مرات، ووجدوا أن:
- بين المهام المختلفة، فإن المهمة الأغلى تحرق حوالي 7 ملايين توكن أكثر من المهمة الأرخص (الشكل 2a)
- في عمليات التشغيل المتعددة لنفس النموذج ونفس المهمة، فإن أغلق عملية تكلف تقريبًا ضعف أرخص عملية (الشكل 2b)
- أما إذا قورنت نفس المهمة عبر نماذج مختلفة، فقد يختلف الاستهلاك الأعلى عن الأدنى بنسبة تصل إلى 30 ضعفًا.
الرقم الأخير يستحق особое внимание: هذا يعني أن فرق التكلفة بين اختيار النموذج الصحيح والنموذج الخاطئ ليس "أغلى قليلاً"، بل "أغلى بدرجة واحدة".
الأكثر إيلامًا — أن الإنفاق الكثير لا يعني بالضرورة الأداء الجيد.
أظهرت الدراسة وجود منحنى "على شكل حرف U مقلوب":
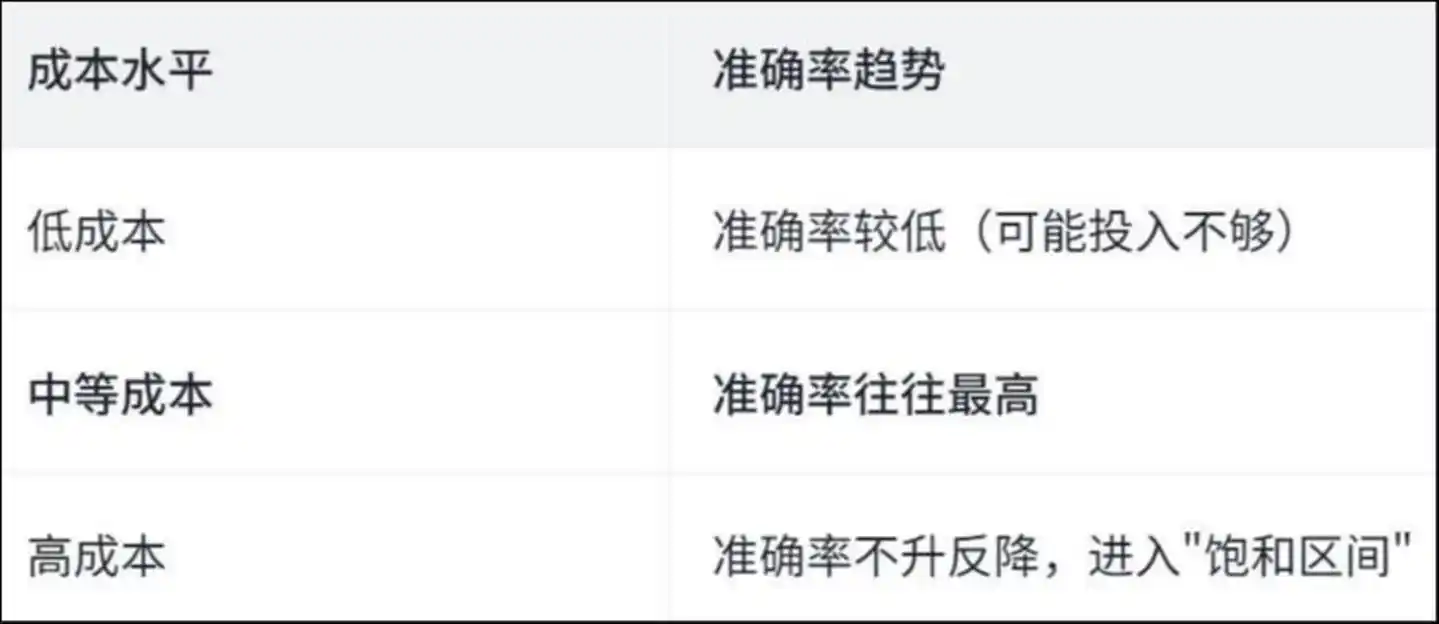
مستوى التكلفة دقة الاتجاه تكلفة منخفضة دقة منخفضة (ربما بسبب استثمار غير كافٍ) تكلفة متوسطة دقة غالبًا الأعلى تكلفة عالية دقة لا تزداد بل تنخفض، وتدخل "منطقة التشبع"
لماذا يحدث هذا؟ توفر الورقة الإجابة من خلال تحليل العمليات المحددة للوكيل—
في ظل التكاليف العالية للتشغيل، يقضي العامل وقتًا كبيرًا في "العمل المتكرر".
أظهرت الدراسات أنه في عمليات التشغيل عالية التكلفة، فإن حوالي 50% من عمليات عرض الملفات وتعديلها هي متكررة — أي أن العامل يقرأ نفس الملف مرارًا وتكرارًا، ويعيد تعديل نفس السطر من الكود، كشخص يدور في غرفة، كلما دار أكثر ازداد دوخة، وكلما ازداد دوخة دار أكثر.
لم يُنفق المال على حل المشكلة، بل على "الضياع".
الاكتشاف الثالث: الفرق الهائل في "كفاءة الطاقة" بين النماذج — GPT-5 هو الأكثر ادخارًا، وبعض النماذج تستهلك 1.5 مليون رمز إضافي
تم اختبار أداء 8 نماذج كبيرة متقدمة على عامل Agent باستخدام معيار صناعي SWE-bench Verified (500 مشكلة حقيقية على GitHub). عند التحويل إلى الدولار، تختلف النماذج ذات كفاءة التوكن العالية بمبالغ تصل إلى عشرات الدولارات لكل مهمة. وفي التطبيقات المؤسسية — حيث يتم تشغيل مئات المهام يوميًا — يصبح هذا الفرق ملموسًا وماديًا.
اكتشاف أكثر إثارةً هو أن كفاءة الرمز المميز هي "طبيعة جوهرية" للنموذج، وليست نتيجة للمهمة.
قارن الباحثون المهام التي نجح فيها جميع النماذج (230 مهمة) مع المهام التي فشل فيها جميع النماذج (100 مهمة)، ووجدوا أن الترتيب النسبي للنماذج تغير بشكل شبه معدوم.
هذا يوضح أن بعض النماذج مُصممة بشكل طبيعي لتكون "مُتحدثة أكثر"، ولا يرتبط ذلك كثيرًا بصعوبة المهمة.
كما كشفت ملاحظة أخرى مثيرة للتأمل: أن النموذج يفتقر إلى "الوعي بوقف الخسارة".
عند مواجهة مهام صعبة لا يمكن لأي نموذج حلها، يجب على العامل المثالي أن يتوقف مبكرًا بدلاً من الاستمرار في إنفاق الأموال. لكن الواقع هو أن النماذج تستهلك عادةً المزيد من الرموز في المهام الفاشلة — فهي لا تُقرّ بالهزيمة، بل تستمر في الاستكشاف والمحاولة مرة أخرى وقراءة السياق من جديد، مثل سيارة لا تمتلك مصباح تحذير لمستوى الوقود، وتستمر في القيادة حتى تتوقف تمامًا.
الاستنتاج الرابع: ما يصعب على البشر لا يعني بالضرورة أنه مكلف للوكيل — إدراك الصعوبة مختل تمامًا
قد تفكر: على الأقل، يمكنني تقدير التكلفة بناءً على صعوبة المهمة؟
تم جمع أوراق بحثية من خبراء بشريين لتقييم صعوبة 500 مهمة، ثم مقارنتها باستهلاك Token الفعلي للوكيل—
النتيجة: هناك ارتباط ضعيف فقط بينهما.
المهام التي يظن البشر أنها صعبة جدًا ومرهقة، قد يُنهيها العامل بسهولة وبتكلفة قليلة؛ بينما المهام التي يظن البشر أنها سهلة جدًا، قد تُكلّف العامل كثيرًا لدرجة يشك فيها في وجوده.
لأن صعوبة ما يراه الإنسان والذكاء الاصطناعي ليست شيئًا واحدًا على الإطلاق:
- ما يراه الإنسان: تعقيد المنطق، صعوبة الخوارزميات، عتبة فهم الأعمال
- يُركز الوكيل على: حجم المشروع، وعدد الملفات التي يجب قراءتها، وطول مسار الاستكشاف، وما إذا كان سيتم تعديل نفس الملف مرارًا وتكرارًا
مشكلة يراها خبير بشري أنها "تحتاج تعديل سطر واحد" قد يتطلب من الوكيل أولاً فهم هيكل كامل قاعدة الكود لتحديد السطر المعني — وفقط "القراءة" قد تستهلك كمية كبيرة من الرموز. بينما قد يكون الوكيل على دراية بالحل القياسي لمشكلة خوارزمية يراها البشر معقدة للغاية، فيحلها بسرعة وسهولة.
وهذا يؤدي إلى واقع محرج: من المستحيل تقريبًا للمطورين تقدير تكلفة تشغيل العامل بشكل حدسي.
الاكتشاف الخامس: حتى النموذج نفسه لا يستطيع حساب تكلفته بدقة
إذا كان البشر لا يستطيعون التنبؤ بدقة، فلماذا لا تدع الذكاء الاصطناعي يتنبأ بنفسه؟
صمم الباحثون تجربة دقيقة: جعلوا الوكيل يُجري "فحصًا" لمستودع الكود قبل البدء الفعلي في إصلاح الأخطاء، ثم يُقدّر عدد الرموز التي سيستهلكها — دون تنفيذ الإصلاح فعليًا.
How did it go?
All models, completely wiped out.
أفضل نتيجة كانت لـ Claude Sonnet-4.5 في ارتباط تنبؤات رموز الإخراج: 0.39 (من أصل 1.0). معظم النماذج كانت ارتباطات تنبؤاتها بين 0.05 و 0.34، بينما كان Gemini-3-Pro الأدنى عند 0.04 — أي تقريبًا مثل التخمين العشوائي.
الأمر أكثر غرابة: جميع النماذج قللت بشكل منهجي من استهلاك رموزها. في مخطط التشتت في الشكل 11، تقع تقريبًا جميع نقاط البيانات أسفل "خط التنبؤ المثالي" — فالنموذج يشعر أنه "لن يستهلك هذا الكم"، لكنه في الواقع استهلك أكثر. كما أن هذا التحيز في التقليل يزداد سوءًا عندما لا يتم تقديم أمثلة.
الأكثر سخرية—أن التنبؤ نفسه يتطلب إنفاقًا.
تكلفة التنبؤ بـ Claude Sonnet-3.7 و Sonnet-4 تصل حتى أكثر من ضعف تكلفة المهمة نفسها. أي أن طلب منهما "تقديم تقدير" أغلب تكلفة من تنفيذ المهمة مباشرة.
استنتاج الورقة مباشر:
في هذه المرحلة، لا تستطيع النماذج المتقدمة التنبؤ بدقة بكمية الرموز التي ستستخدمها. النقر على "تشغيل العميل" يشبه فتح صندوق مفاجأة — فقط عند ظهور الفاتورة ستعرف كم أنفقت.
خلف هذه "الحسابات المربكة" يكمن مشكلة أكبر في الصناعة
عند قراءة هذا، قد تتساءل: ماذا تعني هذه النتائج للشركات؟
نموذج التسعير "الاشتراك الشهري" يُفتح له شقوق من قبل Agent
تشير الورقة البحثية إلى أن نماذج الاشتراك مثل ChatGPT Plus قابلة للتطبيق لأن استهلاك الرموز للدردشات العادية يكون متحكمًا فيه نسبيًا وقابلًا للتنبؤ. لكن مهام الوكلاء تدمر هذا الافتراض تمامًا — فقد تستهلك مهمة واحدة كمية هائلة من الرموز بسبب دخول الوكيل في حلقة مفرغة.
هذا يعني أن التسعير القائم على الاشتراك فقط قد لا يكون مستدامًا لسيناريوهات العامل، وأن التسعير حسب الاستخدام (Pay-as-you-go) سيظل الخيار الأكثر واقعية لفترة طويلة. لكن المشكلة في التسعير حسب الاستخدام هي أن الاستخدام نفسه غير قابل للتنبؤ.
2. يجب أن تصبح كفاءة الرمز المميز "المؤشر الثالث" عند اختيار النموذج
تقليديًا، تختار الشركات النموذج بناءً على بعدَين: القدرة (هل يمكنه القيام بذلك؟) والسرعة (هل ينجزه بسرعة؟). تقدم هذه الورقة بعدًا ثالثًا بنفس الأهمية: الكفاءة الطاقية (كم التكلفة المطلوبة لإتمامه؟)
نموذج أقل قوة بقليل لكنه أكثر كفاءة بثلاث مرات قد يكون له قيمة اقتصادية أكبر في سيناريوهات التوسع.
3. يحتاج الوكيل إلى "مقياس الوقود" و"المكابح"
تشير الورقة إلى اتجاه مستقبلي يستحق الاهتمام: سياسات استخدام الأدوات المدركة للميزانية. ببساطة، هذا يعني تزويد الوكيل بـ"مؤشر وقود": عندما يقترب استهلاك الرموز من الميزانية، يتم إجباره على وقف الاستكشاف غير الفعال بدلاً من الاستمرار في استهلاك الموارد حتى النهاية.
حاليًا، تفتقر جميع أطر Agent الرئيسية تقريبًا إلى هذه الآلية.
مشكلة "إنفاق الأموال" الخاصة بالوكيل ليست خطأ، بل هي ألم لا مفر منه في الصناعة
لكن الورقة لا تكشف عن عيب في نموذج معين، بل عن التحدي البنيوي الذي يواجهه نموذج العامل ككل — عندما تنتقل الذكاء الاصطناعي من "سؤال وجواب" إلى "التخطيط الذاتي، والتنفيذ متعدد الخطوات، والتصحيح المتكرر"، فإن استهلاك الرموز يصبح غير قابل للتنبؤ تقريبًا.
الخبر الجيد هو أن هذا هو المرة الأولى التي يُستعرض فيها هذا الحساب المربك بشكل منهجي. وبفضل هذه البيانات، يمكن للمطورين اتخاذ قرارات أكثر حكمة بشأن اختيار النماذج، وتحديد الميزانيات، وتصميم آليات وقف الخسارة؛ كما يحصل مقدمو النماذج على اتجاه تحسين جديد — ليس فقط جعل النماذج أقوى، بل أيضًا جعلها أكثر ادخارًا.
في النهاية، قبل أن تدخل عوامل الذكاء الاصطناعي حقًا إلى بيئات الإنتاج في صناعات متعددة، فإن إنفاق كل دولار بوضوح أهم من كتابة كل سطر كود بشكل جميل. (تم نشر هذا المقال لأول مرة على تايميديا APP، الكاتب | Silicon Valley Tech news، المحرر | Zhao Hongyu)
ملاحظة: تم إعداد هذا المقال بناءً على ورقة مسبقة النشر منشورة في arXiv في 24 أبريل 2026 بعنوان *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (باي، هوانغ، وانغ، سون، ميهالتسا، برينجولفسون، بنتلاند، بي). يأتي المؤلفون من مؤسسات مثل جامعة فرجينيا، وستانفورد، وMIT، وجامعة ميشيغان. لا تزال هذه الدراسة خاضعة لمراجعة الأقران.