
من يرغب في معرفة أي نموذج كبير هو الأقوى في مهام الوكيل الواقعي لـ OpenClaw؟
قامت MyToken بتطوير معيار شفاف مخصص لتقييم القدرات العملية لوكالات البرمجة بالذكاء الاصطناعي، استنادًا إلى تقييمات مواقع التقييم، مع التركيز فقط على بعد واحد أساسي: معدل النجاح (السرعة والتكلفة هما بعدان مستقلان سيتم تحليلهما لاحقًا بشكل منفصل). المعيار مفتوح بالكامل وقابل للتكرار، ويعرض فقط معايير التقييم الدقيقة + قائمة أفضل 10 تطبيقات حسب معدل النجاح الأحدث.
أولاً: معيار التقييم: معدل النجاح
المعيار المحدد: النسبة المئوية للمهام التي أكملها الوكيل الذكي بشكل كامل ودقيق. كل مهمة تتبع عملية موحدة للغاية:
تعليمات المستخدم الدقيقة
إرسال إلى الوكيل بالكامل لمحاكاة سيناريو طلب المستخدم الحقيقي
السلوك المتوقع
تشمل جميع التفاصيل الطرق المقبولة للتنفيذ ونقاط القرار الرئيسية
معايير التقييم (قائمة المراجعة)
قم بإدراج قائمة مُحدَّدة بعناصر فردية يمكن التحقق منها لتحديد النجاح
ثانيًا: ثلاث طرق تقييم
يتم اعتماد ثلاث طرق تقييم رئيسية في هذه المراجعة
التحقق التلقائي: يقوم سكريبت Python بالتحقق المباشر من محتوى الملفات، وسجلات التنفيذ، واستدعاءات الأدوات، وغيرها من النتائج الموضوعية
محكم نموذج LLM الكبير: Claude Opus يُعطي درجات وفق مقياس تفصيلي (جودة المحتوى، المناسبة، الشمولية، إلخ)
الوضع المختلط: دمج الفحص الذاتي الآلي وتقييم الجودة من قبل نموذج LLM
جميع تعريفات المهام والـ Prompt ومنطق التقييم مفتوحة للتحقق والاختبار مرة أخرى.
ثالثًا: المهام المستخدمة للتقييم
يغطي هذا الاختبار المرجعي 23 فئة مختلفة من المهام. يشمل التفاعل الأساسي، وعمليات الملفات/الكود، وإنشاء المحتوى، والتحليل البحثي، واستدعاء أدوات النظام، وتخزين الذاكرة على المدى الطويل، وغيرها من الجوانب، مع محاكاة وثيقة لسيناريوهات الاستخدام اليومية للمطورين لـ OpenClaw:
فحص الصواب (أتمتة) — معالجة الأوامر البسيطة والرد بشكل صحيح على التحية
إنشاء حدث في التقويم (أتمتة) — توليد نصي طبيعي لملف تقويم ICS
بحث أسعار الأسهم (أتمتة) — استعلام فوري عن أسعار الأسهم وإصدار تقرير مُنسق
كتابة مقال مدونة (حاكم LLM) — اكتب مقالًا مُنسقًا بتنسيق Markdown بطول حوالي 500 كلمة
إنشاء نص الطقس (أتمتة) — كتابة نص Python لواجهة برمجة تطبيقات الطقس مع معالجة الأخطاء
تلخيص المستندات (محكم LLM) — ملخص مكثف على ثلاثة أجزاء للموضوع الأساسي
بحث مؤتمر التكنولوجيا (حاكم LLM) — جمع وتنظيم معلومات 5 مؤتمرات تكنولوجية حقيقية (الاسم، التاريخ، المكان، الرابط)
صياغة بريد إلكتروني احترافي (حاكم LLM) — رفض لطيف للاجتماع واقتراح بديل
استرجاع الذاكرة من السياق (تلقائي) — استخراج دقيق للتاريخ، والأعضاء، وتقنيات المشروع من ملاحظات المشروع
إنشاء هيكل الملفات (تلقائي) — إنشاء تلقائي لدليل المشروع القياسي وملف README و.gitignore
سلسلة عمل واجهة برمجة التطبيقات متعددة الخطوات (مختلطة) — قراءة التكوين → كتابة نص المكالمة → توثيق كامل
تثبيت مهارة ClawdHub (الأتمتة) — تثبيت من مستودع المهارات والتحقق من الجاهزية
البحث وتثبيت المهارة (الأتمتة) — ابحث عن مهارات الطقس وثبّتها بشكل صحيح
إنشاء صور بالذكاء الاصطناعي (مختلط) — أنشئ واحفظ الصور وفقًا للوصف
إنسانية المحتوى المُنشأ بواسطة الذكاء الاصطناعي (حكم LLM) — حوّل المحتوى ذو الطابع الآلي إلى لغة طبيعية ومحادثة
ملخص البحث اليومي (محكم LLM) – دمج عدة مستندات في ملخص يومي متماسك
فرز صندوق البريد الإلكتروني (مختلط) — تحليل عدة رسائل وتنظيم تقرير حسب مستوى الطوارئ
بحث وتلخيص البريد الإلكتروني (مختلط) — ابحث عن رسائل البريد الإلكتروني المخزنة واستخلص المعلومات الأساسية
بحث تنافسي في السوق (مختلط) — تحليل المنافسين في مجال APM للشركات
تلخيص CSV وExcel (مختلط) — تحليل ملفات الجداول وإخراج الرؤى
تلخيص PDF بأسلوب ELI5 (اشرحه لي كأنني طفل في الخامسة) — باستخدام LLM كحكم
فهم تقرير OpenClaw (أتمتة) — الإجابة بدقة على أسئلة محددة من تقارير بحثية بصيغة PDF
استمرارية معرفة Second Brain (مختلطة) — تخزين واسترجاع دقيق للمعلومات عبر الجلسات
رابعًا: الاستنتاجات الأساسية: ترتيب أكبر 10 نماذج من حيث أعلى نسبة نجاح (أفضل % / متوسط %)
تم تحديث البيانات حتى 7 أبريل 2026
أفضل % هي أعلى نسبة نجاح في مرة واحدة، ومتوسط % هو متوسط نسبة النجاح على مدى عدة مرات، وهو ما يعكس الاستقرار بشكل أفضل
هذه هي أفضل عشر نماذج من حيث نسبة النجاح
anthropic/claude-opus-4.6 (Anthropic) —— 93.3% / 82.0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91.9% / 91.9%
openai/gpt-5.4 (OpenAI) —— 90.5% / 81.7%
qwen/qwen3.5-27b (Qwen) —— 90.0% / 78.5%
minimax/minimax-m2.7 (MiniMax) — 89.8% / 83.2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89.5% / 78.1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89.1% / 80.4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88.8% / 70.2%
qwen/qwen3.6-plus-preview (Qwen) — 88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88.6% / 75.5%
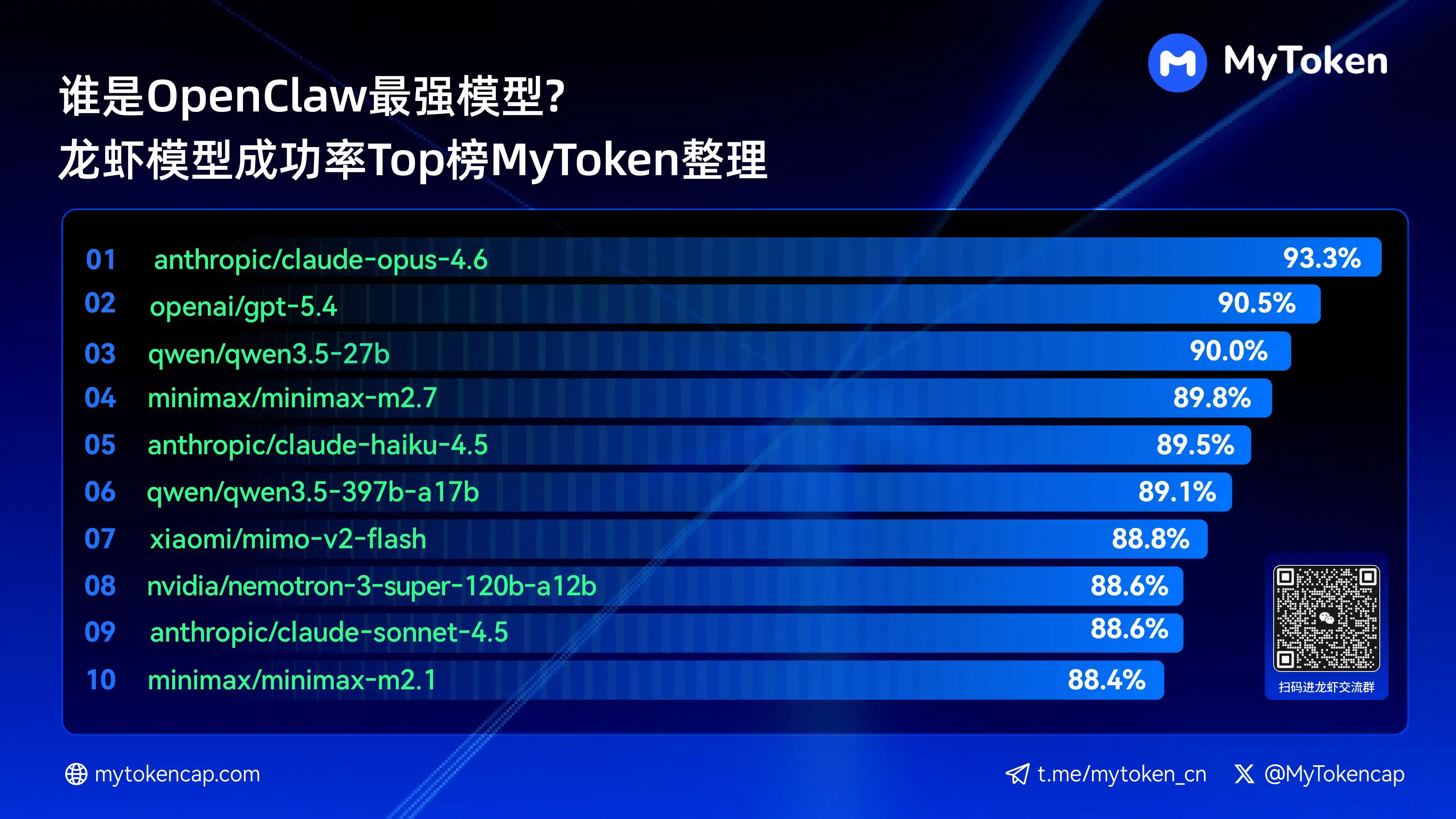
يتصدر Claude Opus 4.6 بمستوى نجاح أعلى بلغ 93.3٪، لكن Trinity من Arcee أظهرت أداءً ملحوظًا في الاستقرار المتوسط، كما دخلت عدة نماذج من سلسلة Qwen قائمة العشرة الأوائل، مما يُظهر إمكانات كبيرة من حيث القيمة مقابل التكلفة. إن نسبة النجاح هي الحد الأدنى الأساسي، وستؤثر بعد ذلك عوامل السرعة والتكلفة على التجربة العملية بشكل أكبر.
هذه المهمات الـ23 معيارًا شفافًا تمامًا، ونوصي بشدة الجميع باختباره وفقًا لسياقاتهم الفعلية. لمزيد من ترتيبات النماذج الأخرى، يرجى الانتظار لميزة ترتيب الوكلاء التي ستطلقها MyToken قريبًا.
(البيانات مأخوذة من اختبارات وكيل OpenClaw التي نشرتها PinchBench، وتحديث مستمر.)