










الكاتب: ماكس، الذي لا يزال في الطريق، 01Founder
إذا كان على المرء أن يكتب ملخصًا مرحلًا لعام 2025 لشركة OpenAI، فسيستخدم الكثيرون وصفًا مملًا أو حتى متواضعًا بعض الشيء.
على مدار أكثر من عام مضى، نفذوا بالفعل مسار الاستدلال المنطقي خطوة بخطوة، وأصدروا بكثافة نماذج الاستدلال من o3pro إلى o4mini، كما أطلقوا نماذج أساسية جديدة مثل GPT-4.5 وGPT-5.
لكن في مجال التوليد البصري الذي يشعر به المستخدمون العاديون بسهولة ويُسهل عليهم نشره تلقائيًا، فإن وجودهم يتناقص تدريجيًا.
بعد الصدمة الأولى من ظهور Sora، يبدو أن OpenAI دخلت فترة صمت طويل في هذا المجال.
في الوقت نفسه، لم يكُن اللاعبون الآخرون على الطاولة ينتظرون دون فعل شيء.
في البيئة المفتوحة المصدر، قام نموذج مثل Flux بتفكيك عتبة إنشاء صور محلية عالية الجودة تمامًا؛
في الجانب التجاري، لا يقتصر الأمر على المنافسين القدامى الذين يسيطرون على حواجز جمالية مطلقة، بل ظهر أيضًا منافسون جدد مثل Nano-banana الذين يتمتعون بوظيفة بحث متصلة بالإنترنت.
على العكس، فإن نموذج OpenAI السابق لإنشاء الصور GPT-Image-1.5 أصبح الآن يبدو عتيقًا:
الجودة البصرية سيئة، والتنسيق رتيب، وغالبًا ما يتعطل عند التعامل مع نصوص معقدة.
بمرور الوقت، تشكل إجماع في الصناعة:
واجهت OpenAI عقبة تقنية في مجال التوليد البصري، وأصبحت غير قادرة على مجاراة المنافسين في جميع الاتجاهات.
حتى الأسابيع القليلة الماضية، ظهرت نقطة التحول بطريقة سرية جدًا.
على منصة الاختبار العمياء الشهيرة للنماذج الكبيرة LM Arena، تم إدخال نموذج صور غامض برمز Duct Tape.
اكتشف المستخدمون المشاركون في الاختبار المغلق أن الأمور ليست على ما يرام:
لا يقتصر هذا النموذج على التحكم الدقيق جدًا في الإطارات المتطرفة، بل يُنتج أيضًا ملصقات تنسيقية تحتوي على كميات كبيرة من النصوص متعددة اللغات دون عيوب، بل ويبدو وكأنه هناك عملية تخطيط منطقية خفية تحدث قبل إنشاء الصورة.
لوقتٍ طويل، كانت المجتمعات التقنية تُخمن أي شركة أطلقت هذه الميزة سرًا، لكن OpenAI ظلت صامتة.
في الساعات المبكرة من اليوم، سقطت الحذاء أخيرًا.
بدون مؤتمرات صحفية مطولة أو حملات تسويقية مكثفة، أطلقت OpenAI رسميًا النموذج ذو الرمز "شريط لاصق" باسم ChatGPT GPT-Image-2 وطرحته بشكل شامل في السوق.
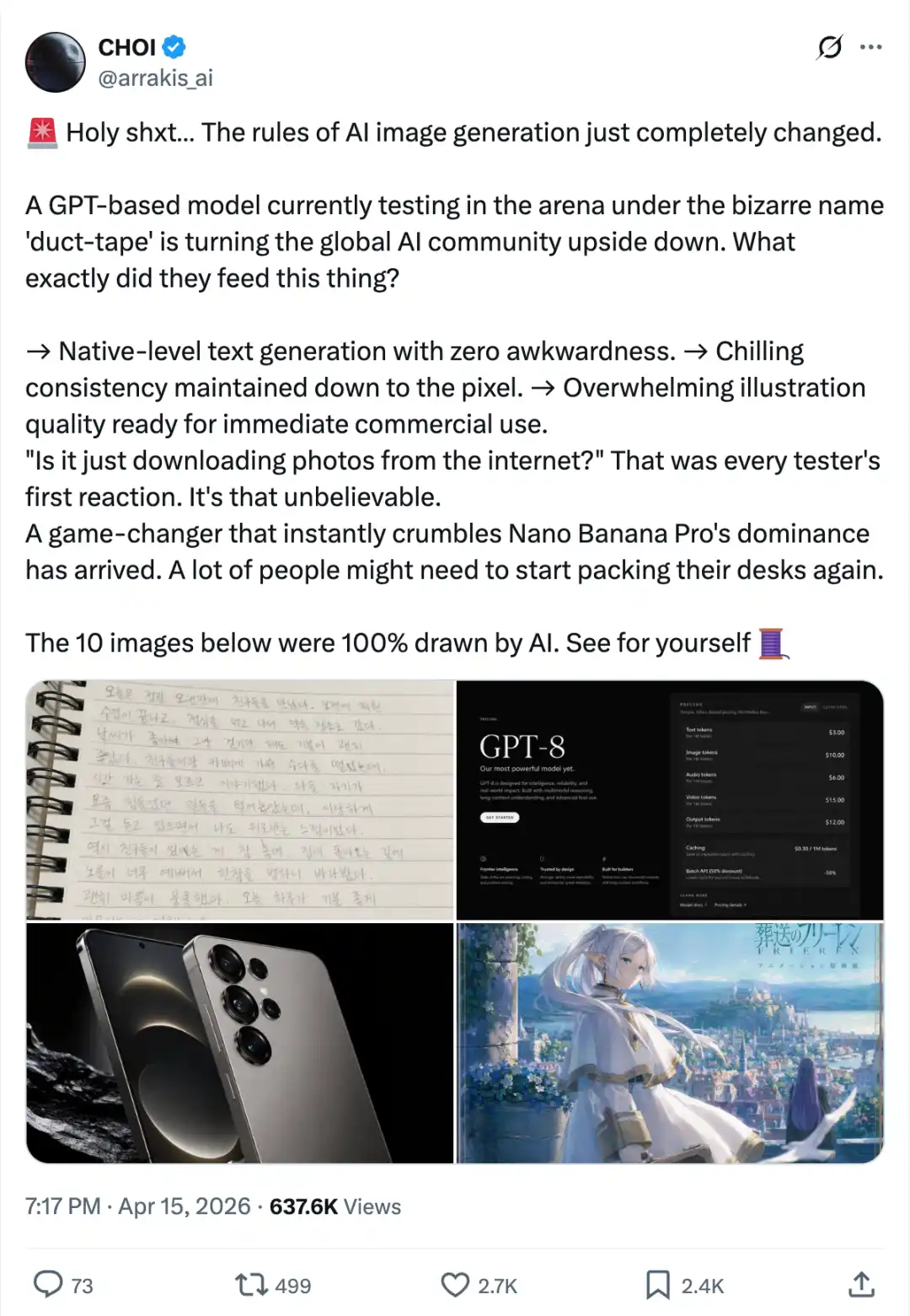
كما تم نشر قائمة تصنيفات Text-to-Image التي تسبب شعورًا بالاختناق.
حقق GPT-Image-2 درجة عالية جدًا قدرها 1512، وصعد مباشرة إلى المركز الأول، متقدماً على المركز الثاني (وهو Nano-banana-2 المزود بخاصية البحث عبر الإنترنت) بفارق 242 نقطة.
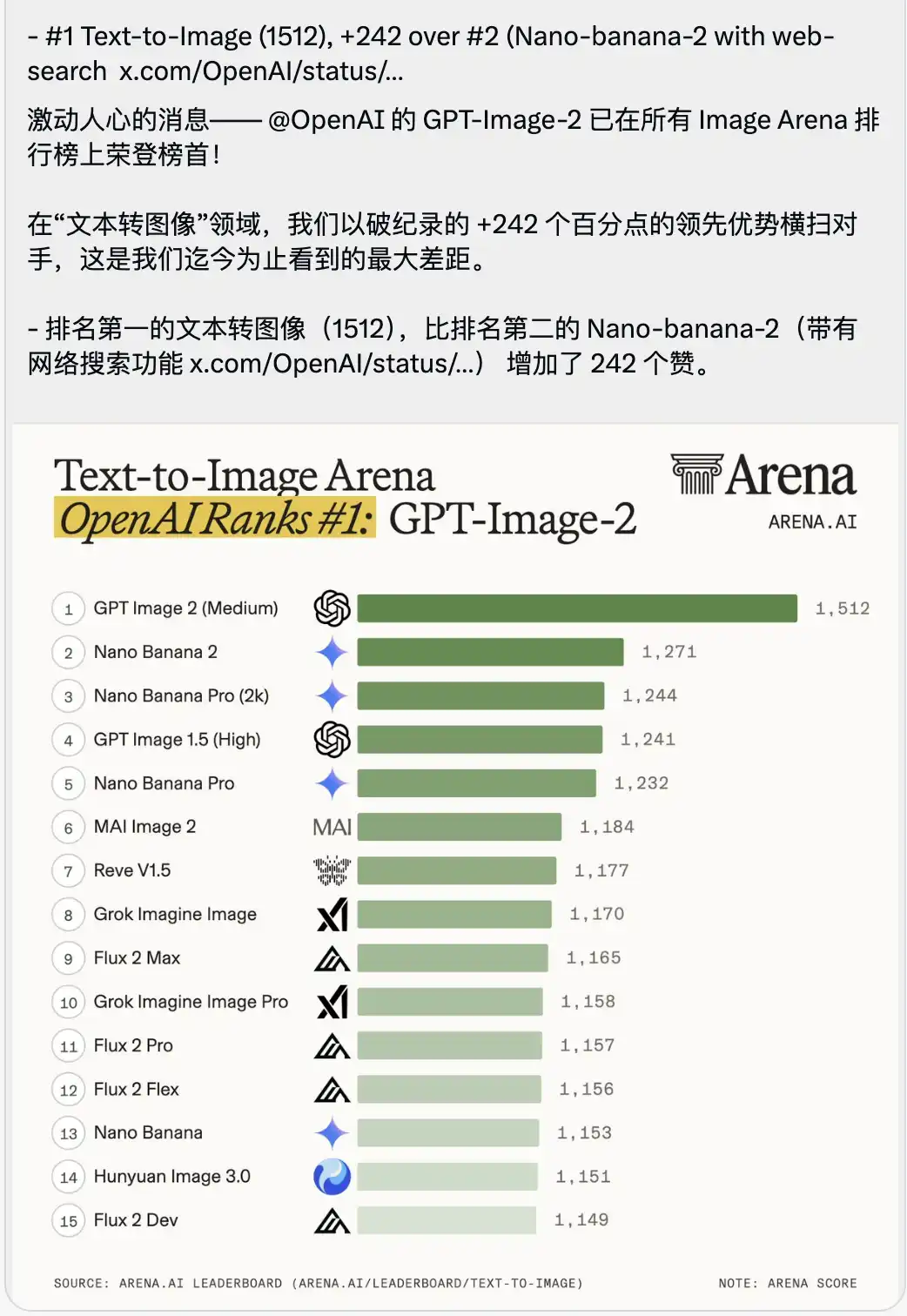
في سياق اختبارات النماذج الكبيرة، يُبالغ عادةً في الترويج لأي تفوق بقيمة جزئية من واحد أو رقم واحد، حيث تكون النقاط بين النماذج الرائدة متشابكة بشدة.
فارق قيادة بقيمة 242 نقطة هو أمر غير مسبوق في تاريخ الأرينا.
هذا ليس مجرد تحديث طفيف، بل هو تفوق ساحق من جيل إلى جيل.
قضيت نصف يوم أستعرض بدقة جميع قدراته القصوى ووثائق واجهة برمجة التطبيقات الأحدث.
الشعور الأكبر هو واحد فقط:
OpenAI هي نفس OpenAI.
عندما قررت استعادة أراضيها، استخدمت طريقة قلب الطاولة القديمة مباشرة.
أمام هذا النموذج، يمكن القول إن أعمال التصميم البصري التي كنا نعتقد أنها ستستغرق عامين أو ثلاثة أعوام أخرى حتى يتم استبدالها بالكامل من قبل الذكاء الاصطناعي، قد انتهت تقريبًا اليوم.
الجزء 01: توليد الصور من النموذج إلى الوكيل البصري
لفهم سبب قدرة GPT-Image-2 على تحقيق فرق كبير جدًا في النقاط، يجب التخلي عن المفاهيم السابقة لنماذج توليد الصور من النص.
في الماضي، كنا نستخدم الذكاء الاصطناعي لرسم الصور، وكان ذلك في جوهره كأننا نفتح صناديق مفاجآت، ندخل بضع كلمات مفتاحية وننتظر حتى يرتب البكسلات بالطريقة التي نريدها.
لكن GPT-Image-2 يشبه أكثر وكيلًا مزودًا بمحرك بصري مدمج.
أوضح تغيير هو أنه قسم بشكل مباشر في آلية العمل نمطين مختلفين تمامًا.
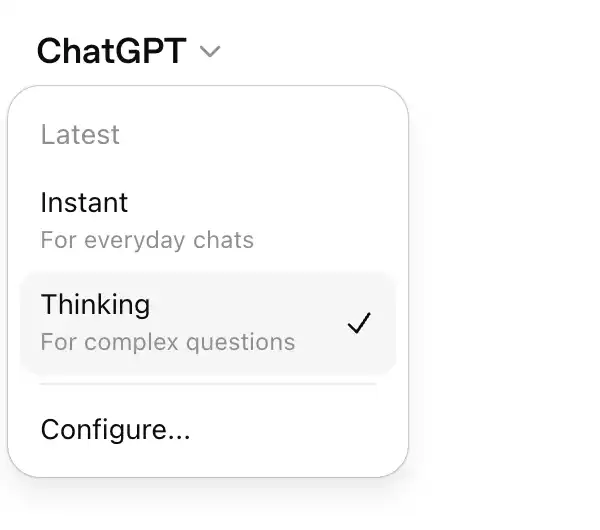
واحد هو الوضع الفوري (Instant Mode) المفتوح لجميع المستخدمين.
هذا النموذج يركز على الاستجابة الفائقة السرعة والتكامل السلس مع سير العمل اليومي.
على سبيل المثال، إذا أرسلت له أمرًا من هاتفك، فسيمكنه إعطاؤك صورة ذات هيكل كامل في غضون ثوانٍ.
إن قدرتها الأساسية على فهم الصور قوية جدًا، لكنها تحل في المقام الأول احتياجات التحويل البصري المتكررة والفردية.
ووضع التفكير (Thinking Mode) المفتوح للمستخدمين المدفوعين.
قبل أن تبدأ في عرض أي بكسل على الإطلاق، فإنها تدخل في فترة من المنطق الاستنتاجي والبحث عبر الإنترنت تستمر لعدة عشرات الثواني.
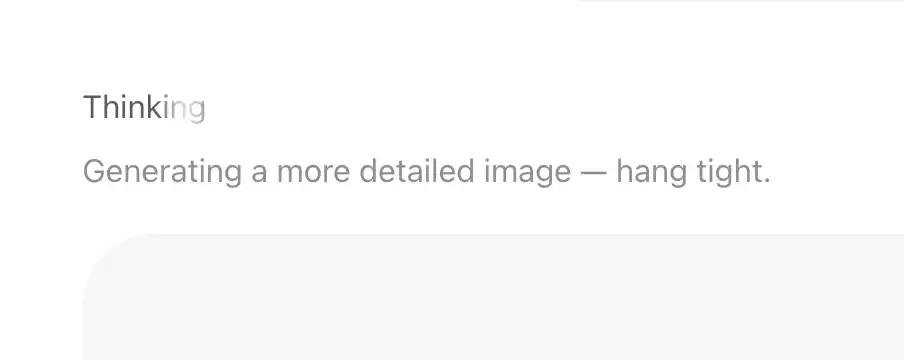
هذا正是 النموذج الذي حلّ مسألة جوهرية للغاية ولكنها صعبة للغاية:
النموذج عرف لأول مرة ما يجب عليه رسمه.
مثالًا مباشرًا.
اكتب في مربع الحوار:
ساعدني في إنشاء ملصق، ابحث عبر الإنترنت عن تقييمات الناس للنموذج الغامض Duct Tape، وقم بإضافة رمز الاستجابة السريعة لـ ChatGPT.

إذا استخدمت النموذج السابق، فلن يفهم ما قاله المستخدمون على الإنترنت، بل سيقدم لك ملصقًا به أحرف عشوائية، والرمز المربع أيضًا سيكون صورة مزيفة لا يمكن مسحها.
لكن في وضع التفكير، فإن سير العمل الخاص به هو كالتالي:
سيقوم أولاً بوقف الرسم، وتشغيل أداة البحث عبر الإنترنت لاستخراج تقييمات المستخدمين الحقيقية من Reddit أو Threads أو LinkedIn؛
ثم بدأت في تخطيط تصميم الملصق، والمساحات الفارغة، وهرمية الخطوط؛
أخيرًا، يُنشئ رمزًا QR حقيقيًا وقابلًا للاستخدام يمكن مسحه ضوئيًا للانتقال مباشرة، ثم يُعرض الصورة بأكملها.

هذا لم يعد مجرد رسم، بل هو إنجاز ذاتي لعملية متكاملة تشمل إجراء البحوث، التخطيط، استخلاص النصوص، وتصميم التخطيط.
هنا يحتاج الأمر إلى مقارنة موازية.
يعرف الجميع في دائرة النماذج الكبيرة أن نماذج توليد الصور ذات القدرة على الاتصال بالإنترنت والبحث ليست ابتكارًا من OpenAI.
النسخة الثانية في الترتيب، Nano-banana، كانت تمتلك هذا الآلية منذ وقت طويل.
لكن عند استخدام Nano-banana في الواقع، ستجد أنه يبدو أحيانًا غير فعّال في العديد من الأماكن.
غالبًا ما تكون تفكيرات Nano-banana نوعًا من المنطق الميكانيكي المدمج.
على سبيل المثال، إذا طلبت منه البحث عن اتجاهات الصناعة لإنشاء ملصق، فسيقوم بالبحث بالفعل، لكنه عادةً ما ينقل جملًا حرفيًا من ويكيبيديا ويُلصقها بشكل قسري على الصورة.
عند مواجهة تعليمات تتطلب تفسير متطلبات تجارية مجردة، فإنها تصبح عرضة للارتباك بسهولة.

الشعور كأنه متدرب يفهم ما يُقال له لكنه لا يمتلك أي خبرة عملية، يفهم التنفيذ لكنه لا يفهم الاستراتيجية على الإطلاق.
لكن أداء GPT-Image-2 في هذا المجال لا يمكن وصفه إلا بالمبالغة.
تفكيره ليس شكليًا، بل فهم حقيقي للسياق الثقافي والنية التجارية وراءه.
أدخلت أمرًا صينيًا موجزًا جدًا أثناء الاختبار: ساعدني في رسم لقطة شاشة لمسك وهو يبيع豆包 في بث مباشر على دويني.
إذا استخدمت نموذج رسم قديم، فسيكون من المحتمل جدًا أن يرسم لك رجلاً أبيض يشبه ماسك وهو يحمل كعكة بابا، مع خلفية غير واضحة، وحتى لا يعرف كيف يبدو تيك توك.
لكن في وضع التفكير، تُظهر نتائج GPT-Image-2 شيئًا يثير القلق بعض الشيء.
لم تقم ببساطة بتركيب العناصر، بل استدعت بشكل مستقل فهمها للإنترنت الصيني، وأنتجت لقطة شاشة لواجهة بث مباشر على Douyin مطابقة بدقة على مستوى البكسل.
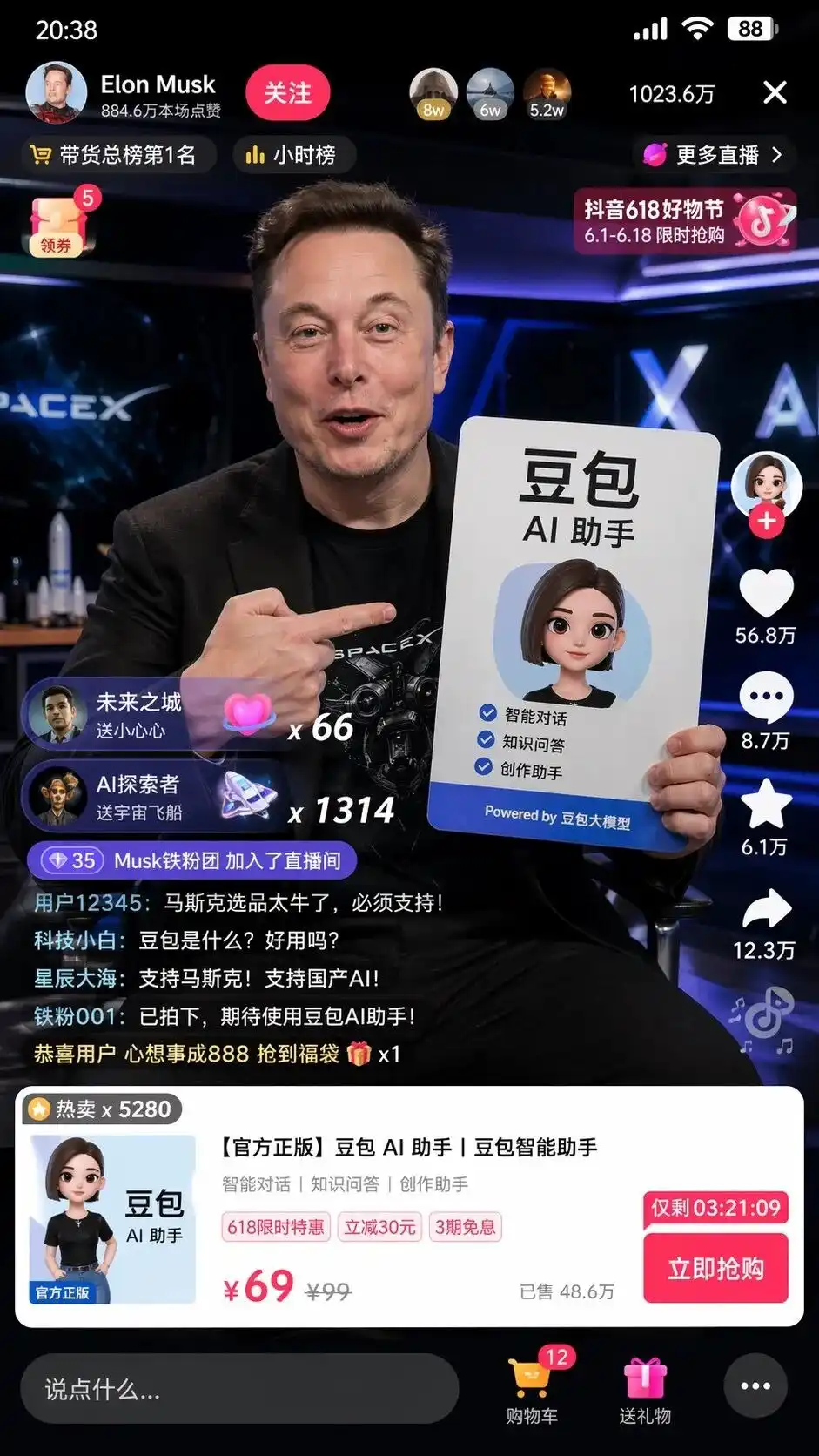
لا يحتوي المشهد فقط على ماسك واقف بلوح إعلاني لمساعد豆包 AI بتنسيق مثالي، بل أيضًا تفاصيل لم تُذكر في التعليمات:
زر المتابعة في الزاوية العلوية اليسرى، وقائمة الساعات، وعدد المستخدمين المتصلين 10.23 مليون في الزاوية العلوية اليمنى، وبطاقة المنتج القياسية المنبثقة في الأسفل، وحتى سعر المُخطّط 99 وسعر العرض 69 وزر الشراء الفوري مع عدّ تنازلي.
الأكثر إثارة للرعب هو شريط الرسائل المتدفق من المستخدمين في الزاوية اليسرى السفلية، والذي يبدو واقعيًا بشكل مذهل:
المبتدئ في التكنولوجيا: ما هو دوباء؟ هل هو سهل الاستخدام؟
النجوم والمحيطات: ندعم ماسك! ندعم الذكاء الاصطناعي المحلي!
لم يقل له أحد ما يجب كتابته في الرسائل المتدفقة، أو كيف يجب أن يبدو واجهة المنتج، أو كيف يجب تحديد السعر.
هذا تصميم واجهة المستخدم التجارية وخطة التشغيل الكاملة التي أكملها النموذج ونفذها بعد تحليل وسوم "التسويق عبر دوين" و"نموذج دو باو الكبير".
في هذه اللحظة، تجاوزت معايير تقييم النماذج الكبيرة في توليد الصور مجرد قدرتها على رسم صور جمالية، لتشمل فهمها للإستراتيجية ومنطق التخطيط.
الجزء 02: اختبار القدرات الأساسية
للاستكشاف الحد الأدنى له، قمت بتجربته وفقًا لمعايير التصميم التجاري باستخدام عدة سيناريوهات متكررة ومعقدة.
اتضح أن دقة حلها للمشكلة وصلت إلى درجة تُثير الرعب.
السيناريو الأول: فهم البصرية وإغلاق الدورة التجارية (وضع الملابس على العارضة)
في التصميم البصري للتجارة الإلكترونية التقليدية أو التخطيط الأزيائي، فإن تكلفة التنفيذ بين الفكرة ورؤية التأثير على الجسم مرتفعة جدًا.
You're looking for a model, borrowing clothes, setting up a studio, and post-production retouching.
بعد ذلك، مع ظهور الذكاء الاصطناعي، بدأ الناس في تدريب نماذج LoRA لثبات ملامح الوجه، لكن هذا ما زال يتطلب عشرات الصور كمواد أولية وتكلفة تعلم كبيرة.
في GPT-Image-2، تم تقليل هذه العملية إلى أقصى حد.
حاولت تحميل صورة Selfie يومية لي، وأخبرته أنني سأذهب في عطلة إلى جزيرة الشهر القادم، وطلبت منه مساعدتي في اختيار عدة ملابس.
أولاً، قدم لي 8 مجموعات من كتالوجات ملابس الصيف بأساليب مختلفة تمامًا، وكان التخطيط يبدو وكأنه كتالوج تسويقي احترافي، مع وجود تسميات نصية صحيحة بجانب كل قطعة.
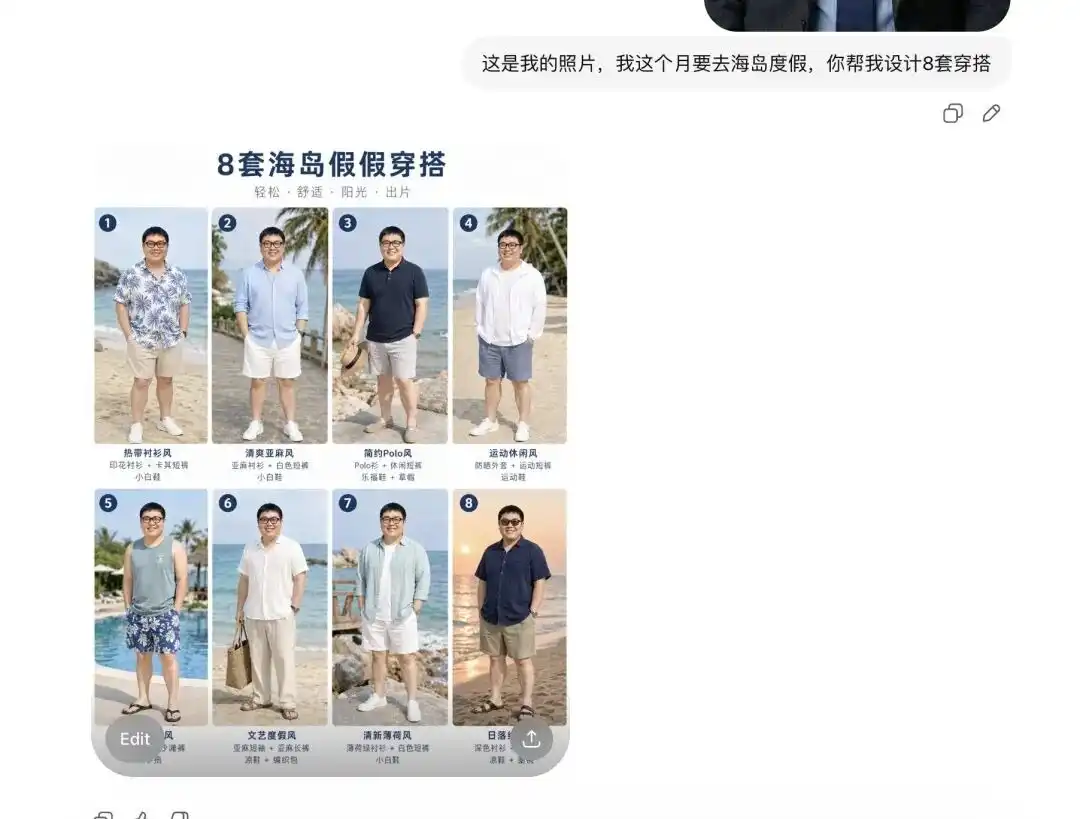
الأهم من ذلك، أنه فكّر بدقة ملامح وجهي ونسب جسدي في هذه اللحظة.
عندما طلبت منه أن يعرض لي مظهر الطقم الأول على جسدي، ويوفر لي عدة صور تفصيلية من زوايا مختلفة، قام مباشرة باستخراج الشخص من صورتي الذاتية واستبداله بالطقم الصيفي، وأنتج صورًا من زوايا مختلفة مثل الجانب والنصف.

هذا التحول سلس جدًا. وهذا يعني أن حواجز الحماية الخاصة بالرسم الأولي للملابس أو أعمال التفويض المتعلقة بتجربة الملابس على النماذج قد تم قطعها بالكامل.
السيناريو الثاني: حل مشكلة الاتساق والسرد المستمر (توليد كوميكس من جملة واحدة)
يعرف الجميع الذين استخدموا الذكاء الاصطناعي لإنشاء الصور أن من السهل جعل الذكاء الاصطناعي يرسم صورة جميلة، لكن الصعوبة تكمن في جعله يرسم عشر صور لنفس الشخص مع الحفاظ على استمرارية الحركة والمنظور.
هذا ما يُعرف بمشكلة التوافق (Consistency).
لكن في هذا الاختبار العملي، شاهدت حالة تتعارض بشدة مع التجارب السابقة.
يمكنك رفع صورة واحدة فقط لك ولصديقك من الأمس، ثم إدخال كلمة إرشادية بسيطة جدًا:
اجعلنا نحن الاثنين البطلين، وارسم ثلاث صفحات من القصص المصورة اليابانية، وحدد القصة أنت
بعد بضع ثوانٍ، أنتجت مباشرة ثلاث صفحات من القصة المصورة بالأبيض والأسود مع لوحات معيارية.
أكبر ما يخيف هو أن هذين الشخصين الكرتونيّين المُنشأين من أشخاص حقيقيين، موجودان في لقطات مختلفة على ثلاث صفحات.

سواء كان لقطة قريبة، أو مشهد بعيد يركض، أو ظهر، وحتى ملامح وجوههم وتفاصيل تسريحة شعرهم وتجاعيد ملابسهم، فقد حافظت جميعها على اتساق تام.
الأكثر إثارة للدهشة أن سرد القصة في القصة المصورة متماسك تمامًا، بل وحتى النصوص داخل مربعات الحوار تشكل منطقًا قصصيًا كاملًا.

القدرة على تحقيق الاتساق في الزمن والمكان تشير إلى أنها تجاوزت نطاق إنشاء صورة واحدة، وتمتلك قدرة المخرج على السرد المتسلسل.
السيناريو الثالث: عبور العتبة الأخيرة في عرض النصوص (التنسيق متعدد اللغات)
إذا كان التوافق يحل مشكلة السرد، فإن العرض الدقيق للنصوص متعددة اللغات هو ما يدفع مصممي الجرافيك إلى الحائط.
في السابق، عندما تحتوي الصورة على أي نص، كانت النماذج الكبيرة تبدأ في رسم فوضى.
لأن النموذج يفهم النص كـ Token (كتل دلالية)، بينما تُولَّد الصور كنقاط بكسل، وكان هذان الأمران منفصلين في الماضي.
GPT-Image-2 حلّت هذه المسألة تمامًا.
قمت بإنشاء غلاف مجلة أزياء باللغة الفرنسية، وقائمة مطعم يابانية مزودة بحروف هيراغانا وكنجي، وحاولت أيضًا تخطيط ملاحظات روسية بكثافة عالية جدًا.

The result is one-time成型, zero spelling errors.
الأكثر إحباطًا هو أنه لم يكتب الكلمات بشكل صحيح فحسب، بل أيضًا يفهم كيفية مواءمة التصميم الجرافيكي والجماليات الثقافية المحلية حسب اللغة.
على سبيل المثال، الأحرف الصينية في النشرة اليابانية، والتي تستخدم خطًا فنيًا يابانيًا أصيلًا وتقليديًا، كما أن ترتيب الحروف الهيراغانا يتوافق مع عادة القراءة الرأسية باللغة اليابانية.
كان تصميم التخطيط أرضًا مخصصة لمصممي الجرافيك.
ضبط مسافات الحروف، وتحديد الأولويات، وتحقيق التوازن البصري بين النص والخلفية يتطلب ممارسة كبيرة.
لكن عندما يكون لدى الذكاء الاصطناعي القدرة على معالجة هذا العدد الكبير من اللغات بدون أخطاء، مع تضمين جمالية تخطيط متقدمة، فلن تحتاج المزيد من الأشخاص إلى ضبط خطوط المرجع يدويًا للحصول على محاذاة في الملصقات اليومية، الكتيبات، والإعلانات في تدفق المعلومات.
السيناريو الرابع: نسب غير طبيعية والتحكم الدقيق للغاية (نقش على حبة أرز)
أخيرًا، لرؤية مدى طاعته الحقيقي، أعطيته عدة تعليمات صعبة جدًا.
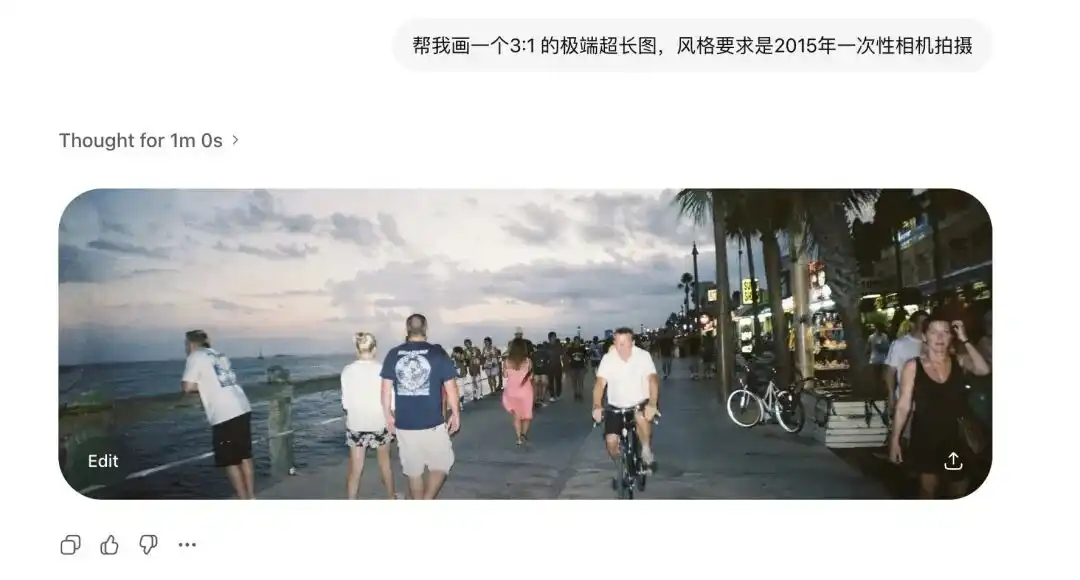
First, I tested its extreme aspect ratio.
نماذج الانتشار التقليدية تخشى بشدة النسب غير القياسية.
في السابق، عندما تُطيل الصورة قليلاً، كانت تظهر رأسان داخل المشهد.
لكنني طلبت من Images 2.0 توليد صور فائقة العرض بنسبة 3:1 وصور رأسية طويلة بنسبة 1:3، ولم تتعطل فقط، بل أنتجت صورة بانورامية 360 درجة متصلة من البداية إلى النهاية وذات حلقة منطقية مغلقة.
بعد إضافة مصطلحات التصوير بكاميرا لمرة واحدة من عام 2015، تم إعادة إنتاج تشوه العدسات القديمة والانعكاس الرديء للوميض على الجدار بوضوح تام.
أما الآخر الذي يُظهر قدرتها على التحكم الدقيق، فهو اختبار الحبة الصغيرة الذي عرضته الشركة الرسمية أثناء المؤتمر الصحفي.
قام الباحثون باستدعاء واجهة برمجة التطبيقات التجريبية 4K التي لا تزال قيد الاختبار الداخلي، ولم يستخدموا أي صفات مثل التصوير المقرب أو فائق الوضوح 8K، بل أصدروا أمرًا واحدًا جدًا مجردًا وبسيطًا:
كمية من الأرز. على حبة أرز واحدة من هذه الكمية مكتوب GPT Image 2.
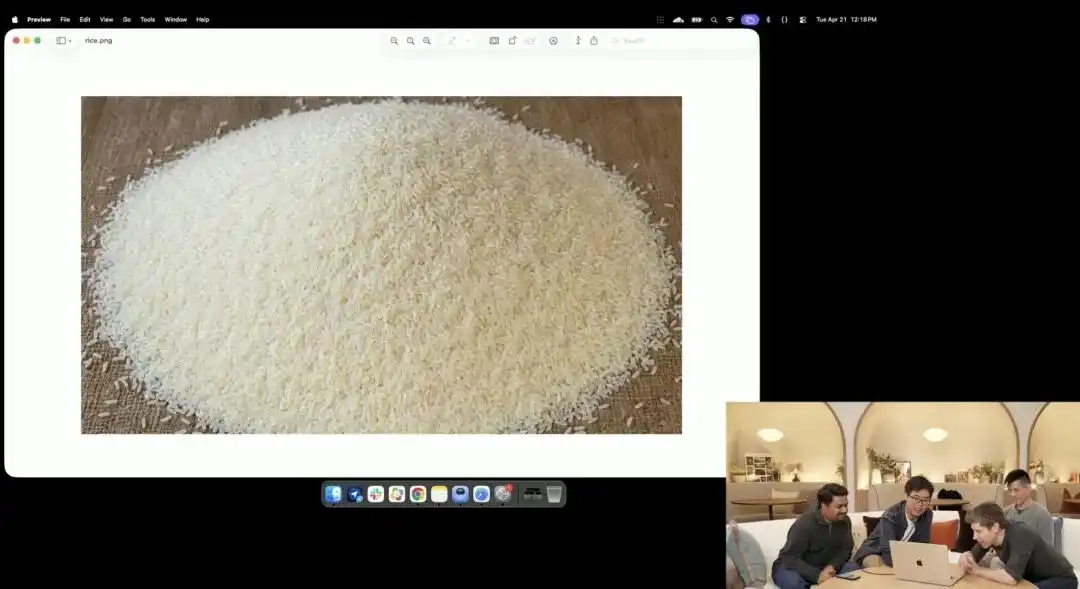
عندما يتم تكبير الشاشة على الشاشة بمقدار عشرات المرات، وحتى ظهور حبيبات البكسل، هل يمكنك حقًا العثور على حبة دقيقة محفورة بحرف ضمن كمية من الأرز؟
Still adheres to the laws of physics, with text precisely embedded along the subtle curves of the grain.
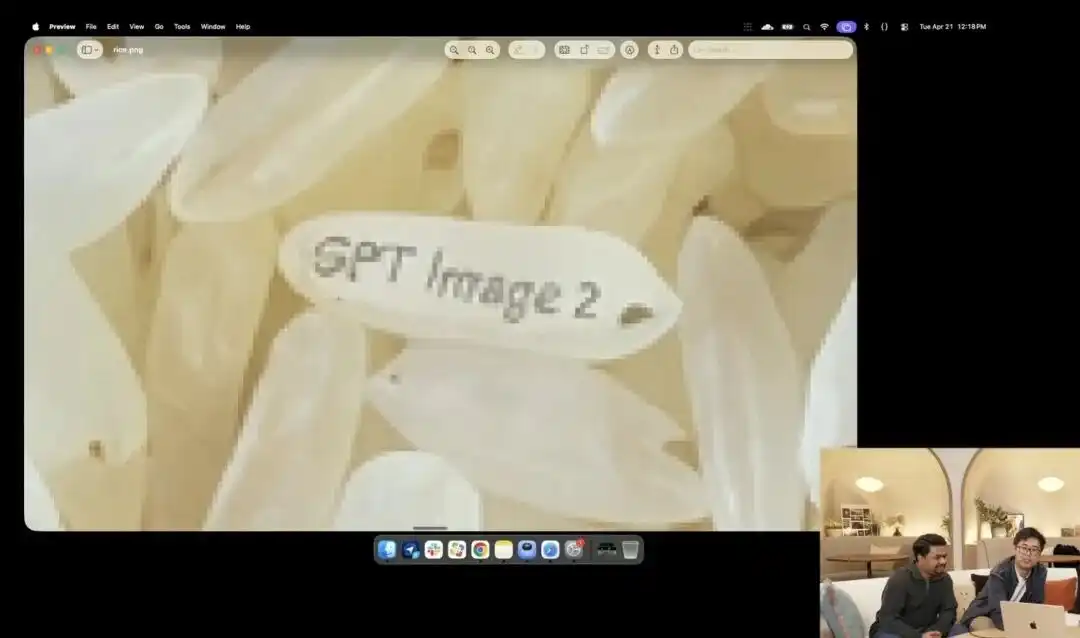
جميع المهام المتبقية — تفعيل منظور الماكرو، حساب عمق المجال، البحث عن الإحداثيات الفيزيائية للحبة الأرز في الفضاء الكامن، وطباعة الحروف عليها — تم توليدها وإكمالها تلقائيًا من قبل النموذج الكبير أثناء وضع التفكير.
يُظهر هذا المثال بشكل بصري أن النموذج وصل إلى دقة جراحية على مستوى البكسل في فهم المواقع المكانية.
هذا يعني أنه في المستقبل، يمكنك تعديل أي جزء صغير في تصميم العمل بدقة، حيث تشير إلى المكان وتُجري التعديل، بدلاً من أن تتغير الصورة بأكملها عند محاولة تعديل عنصر واحد مثل الياقة، كما كان يحدث من قبل.
الجزء 03 بعض التفاصيل التقنية
هذا النوع من السيطرة المتطرفة والذكاء الاستراتيجي لا يمكن تحقيقه فقط من خلال تجميع قوة الحوسبة بشكل عشوائي.
لتحديد ما هي أوراقه الرابحة بالضبط، أجريت بعض اختبارات الاستكشاف على GPT-Image-2.
تم اكتشاف نقطة مثيرة جدًا.
على الرغم من أن الوثائق الرسمية تدّعي أن تاريخ انتهاء معرفة GPT-Image-2 تم تحديثه إلى ديسمبر 2025، إلا أنني في اختباراتي العملية.
تاريخ انتهاء بيانات التدريب للوضع الفوري (Instant Mode) لا يزال حتى نهاية مايو 2024؛

ووضع التفكير (Thinking Mode) الذي يتطلب تفكيرًا طويلًا، فإن قاعدة معرفته الأصلية تبقى تقريبًا حتى يونيو 2024 (لكن يمكنه الحصول على التاريخ الحالي عبر الاتصال المباشر بالإنترنت).

بناءً على هذين النقطتين الزمنيتين، يبدو أن هناك أدلة تشير إلى الأساس الكامن وراء GPT-Image-2.
أولاً، نتحدث عن الوضع الفوري المتميز بالإخراج عالي التردد.
تاريخ الانتهاء في مايو 2024 يعني أنه من المرجح أنه استخدم مباشرة o4-mini، أو إصدار خفيف من عائلة GPT-5 (مثل GPT-5 mini أو حتى إصدار GPT-5 nano بمعاملات صغيرة جدًا).
لأن هذه القاعدة الخفيفة قد اكتسبت بالفعل قدرات قوية في التخطيط المكاني وفهم التعليمات المعقدة، تمكّن توليد الصور من الطبقات العليا من الحفاظ على استقراره وعدم الفوضى.
وأن نمط التفكير الذكي للغاية والذي يفهم استراتيجيات الأعمال لا يمكن أن يكون قائمًا على النموذج الأساسي GPT-5.
بسبب انتهاء تاريخ قاعدة المعرفة الأساسية لـ GPT-5 في سبتمبر 2024.
يُرجح بشدة أن وضع التفكير يتصل بنموذج استنتاج سلسلة O الذي يتم تطويره باستمرار في الخلفية (مثل o4 أو o3 المحدث).
يستخدم النموذج الكبير أولاً آلية التفكير الطويلة الخاصة بسلسلة O، حيث يحسب بدقة المنطق التجاري ونفسية الجمهور وتنسيق الإحداثيات في الفضاء الكامن، ثم يُسلّمها إلى وحدة التصور للرسم النهائية على مستوى البكسل.
بالطبع، هناك مسار محتمل آخر:
تحت آلية توزيع قوة الحوسبة الدقيقة جدًا داخل OpenAI، قد يستخدم الوضع السريع GPT-5 nano كحد أدنى، بينما يستخدم الوضع التفكيري GPT-5 mini الأكبر قليلاً مع أدوات خارجية.
لكن بغض النظر عن أي تركيبة قاعدة تستخدم، إذا كنت تتابع بانتظام نظام OpenAI البيئي للواجهة البرمجية، فستلاحظ أن منطق التوليد الأساسي له لم يعد في نفس المستوى تمامًا مثل Midjourney.
الجزء 04 التسعير الذي يهتم به الجميع أكثر
لكن أكثر من التخمين حول القاعدة، ما يهم حقًا للمطورين والشركات التي تخطط لدمجه في سير عملهم هو جدول تسعير API الواقعي للغاية والمُضاد للحدس.
كان DALL-E 3 سابقًا يُفرض عليه رسوم لكل صورة (مثل 0.04 دولار لكل صورة).
لكن منذ الجيل الأول GPT-Image-1، قامت OpenAI بتحويله بالكامل إلى إطار يُحسب بناءً على الـ Token.
يستمر GPT-Image-2 في هذه المرة في الالتزام بهذا المعيار، بل ويضيف ميزات إضافية بسعر أقل.
وفقًا لجدول التسعير الذي أُعلن عنه حديثًا من قبل الشركة الرسمية، فإن سعر كل مليون رمز هو كالتالي.
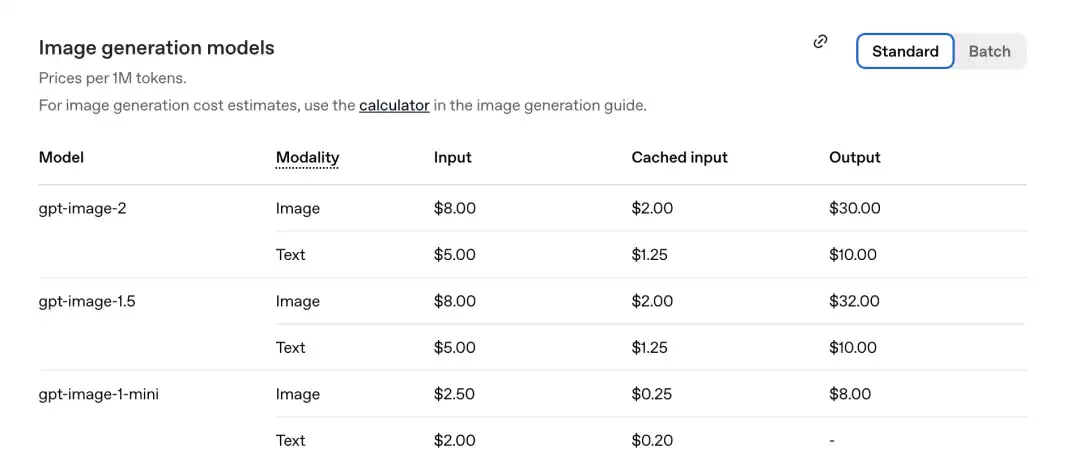
الجزء الصوري لـ GPT-Image-2: الإدخال 8.00، المدخلات المخزنة مؤقتًا (Cachedinputs) 2.00، الإخراج $30.00.
مقارنةً بإصدار GPT-Image-1.5 السابق: التكلفة هي $32.00.
النموذج الجديد أصبح أرخص.
دعونا نحسب التكلفة.
في النماذج السابقة، كان توليد صورة عالية الجودة يتطلب حوالي 1000 إلى 1500 رمز إخراج.
بافتراض سعر 30 دولارًا لكل مليون مُخرَج توكين، فإن التكلفة الفعلية لإنشاء صورة تتراوح بين 0.03 و0.045 دولارًا أمريكيًا (ما يعادل حوالي 2 إلى 3 قروش صينية).
إذا لم تكن بحاجة إلى رد فوري، بل تستخدم نمط واجهة برمجة التطبيقات (API) للدُفعات (Batch) المقدمة من الشركة الرسمية، فسيتم خفض هذا السعر مباشرة إلى النصف (ينخفض السعر مباشرة إلى 15.00 دولارًا).
بحساب ذلك، فإن توليد صورة واحدة يكلف أقل من 1.1 قرش.
هذا السعر للورقة الواحدة كافٍ بالفعل من حيث القيمة، لكن قوته الحقيقية تكمن في مدخلات التخزين المؤقت (Cached inputs) في جدول التسعير.
في الماضي، عندما كنت ترسم قصصًا مصورة أو تصمّم ملصقات ضمن سلسلة موحدة، كان عليك إعادة رفع مجموعة كبيرة من صور المرجع للشخصيات، وموجزات سابقة، وتعليمات طويلة في كل مرة تُعيد فيها التوليد، مما يُعدّ تكلفة إدخال عالية جدًا.
لكن في نموذج التسعير القائم على الرموز الحالي، عندما تطلب منه إنشاء 8 كوميكس متصلة دفعة واحدة، تُخزَّن عناصر الصورة الأولى مباشرةً كمحتوى سياقي.
من الصورة الثانية فصاعدًا، انخفضت تكلفة إدخال الصورة مباشرة من 8.00 دولار إلى 2.00 دولار (أي يتم收取 فقط 25% من المبلغ).
هذا يعني أنه عند إجراء طبعات تجارية كبيرة أو إنشاء متسلسل يتطلب اتساقًا عاليًا في الشخصيات، فإن تكلفته الحدية ستتراجع بشكل حاد.
كلما كان النموذج أكثر ذكاءً وأكثر رسمًا، انخفضت التكلفة المتوسطة لكل صورة.
هذا المنطق الفاتورة الصناعي هو ما سيُدفع فنانو الخطوط الإنتاجية حقًا إلى الحائط.
الجزء 05 كشف هوية الفريق الخلفي
أخيرًا، دعونا نعود إلى فريق الرؤية المثالي الداخلي من OpenAI الذي قام بالعرض التوضيحي أثناء البث المباشر، فكل الوظائف التي اعتبرها الكثيرون غير منطقية تصبح مفهومة تمامًا.
على سبيل المثال، كيف تحل هذه المشكلة بالضبط فيما يتعلق بالتنسيق المعقد متعدد اللغات وصعوبات الكتابة الغامضة.
هذا لا يُمكن تحقيقه دون العالم البارز في الفريق، غابرييل جوه.

في هذا المجال الأكاديمي، هو معروف بشكل أساسي كمؤلف أساسي للنموذج متعدد الوسائط الرائد CLIP.
CLIP established the foundation for understanding how modern AI correlates human language with image pixels.
بقيادة هذا الخبير في التعيين الدلالي متعدد الوسائط، لم يعد GPT-Image-2 يخمن أشكال النص عشوائيًا، بل يكتب فعليًا على مستوى البكسل.
على سبيل المثال، كيف يمكنه فهم العلاقات ثلاثية الأبعاد، وحتى إنشاء صور بانورامية 360 درجة بنسب عرض إلى طول متطرفة، بالإضافة إلى فهم الأضواء والظلال الدقيقة على حبة أرز؟
هذا يعود إلى عضو أساسي آخر، أليكس يو.

قبل انضمامه إلى OpenAI، كان مؤسسًا مشتركًا ورئيسًا تقنيًا سابقًا لشركة Luma AI الناشئة الرائدة في مجال توليد الصور ثلاثية الأبعاد، كما كان باحثًا رائدًا متخصصًا في التصوير العصبي ثلاثي الأبعاد (مثل NeRF).
بوجوده، تجاوز GPT-Image-2 فعليًا طلاء البكسل التقليدي ثنائي الأبعاد.
من المحتمل جدًا أنه أنشأ أولًا مشهدًا ثلاثي الأبعاد في الذهن، وضبط الإضاءة، ثم قام بعرض شريحة 2D دقيقة لك.
كيف تم تحقيق اتساق القصة المصورة ذات الصفحات العديدة هذا المخيف للغاية؟
هذا يتوافق مع الزوجين الشابين من فريقنا اللذين تخرجا للتو من معهد ماساتشوستس للتكنولوجيا (MIT CSAIL):
بو يوان تشين (يسار) وكيوهان سونغ (يمين).
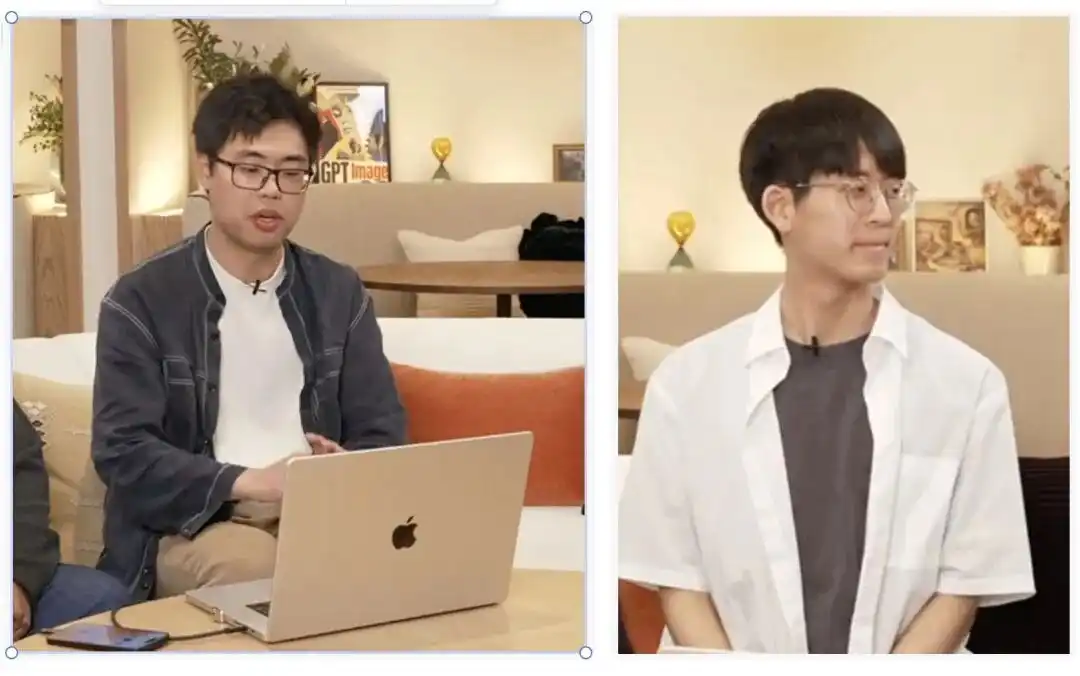
اتجاههم الأساسي في الأوساط الأكاديمية يُسمى النماذج العالمية (World Models) والذكاء المتجسد.
تعليم الآلة لفهم كيفية عمل العالم المادي، وضمان بقاء الشخصيات متماسكة وثابتة دون تشوه عبر مشاهد مختلفة في أوقات وفضاءات متنوعة، هو بالضبط المهمة التي حاول هذان العالمان حلها.
أخيرًا، أضف نيثانت كوديج (اليسار، مؤلف رئيسي لنموذج الاستدلال من سلسلة O) وكينجي هاتا (اليمين، باحث سابق في جوجل وخريج مختبر الرؤية في ستانفورد) اللذين لا يزالان ملتزمين بربط نماذج الاستدلال الكبيرة بالمنطق الأساسي للرؤية.

عندما يجتمع هذا الفريق معًا، يتم دمج المنطق الأساسي للاستدلال، وتصور الفضاء ثلاثي الأبعاد، والمحاذاة المثلى للنص والصور، وقوانين العالم المادي، في نموذج واحد بشكل طبيعي.
القسم 06 حدود GPT-Image-2
كل نموذج له حدود.
The official also acknowledges that it still struggles in the face of certain extreme situations.
مثل أدوات إرشادية للأوراق المطوية التي تتطلب عكسًا فيزيائيًا دقيقًا، أو حل مكعبات الروبيك، أو تفاصيل متكررة جدًا مثل حبيبات الرمل الكثيفة، لا تزال تصل إلى حدود قدراتها.
لكن في سياق التطبيقات التجارية، هذه عيب ضئيل جدًا.
لصناعة التصميم بأكملها، لا داعي للإثارة بالقلق، فهذا لا يعني على الإطلاق موتها الجمالي.
الأشخاص ذوو الذوق، والبصيرة التجارية، وفهم الاستراتيجية، لا يزال بإمكانهم إنشاء أشياء ممتازة باستخدامه.
لكن الحقيقة الموضوعية هي أن حواجز الدخول للمهنة كمصمم قد تم تفكيكها بشكل جوهري.
في الماضي، كان الناس يعتمدون على حفظ مفاتيح الاختصار لبرامج التصميم، ومعرفة كيفية محاذاة الخطوط بشكل مستوٍ وعمودي، ومعرفة كيفية تخطيط النصوص حسب اللغة، ومعرفة كيفية تعديل الصور بدقة وقص الخلفيات.
لكن سيكون الأمر أصعب في المستقبل، لأن المهارات التي كان يمكن تسعيرها وتجريدها للتداول في الماضي أصبحت الآن أوامر أساسية يمكن لأي شخص استدعاؤها مجانًا بجملة واحدة.
بعد فترة من الصمت، أثبتت OpenAI بطريقة هادئة للغاية ولكنها فعالة بشكل كبير أن من يملك الأوراق السرية على هذه الطاولة هو هو.
تتعرض سلسلة أدوات التنفيذ القديمة للانهيار، والسؤال الذي لم يعد يُطرح على الصناعة هو ما إذا كان الذكاء الاصطناعي سيستبدلنا، بل كيف لنا أن نتكيف مع خط الإنتاج الجديد تمامًا.