









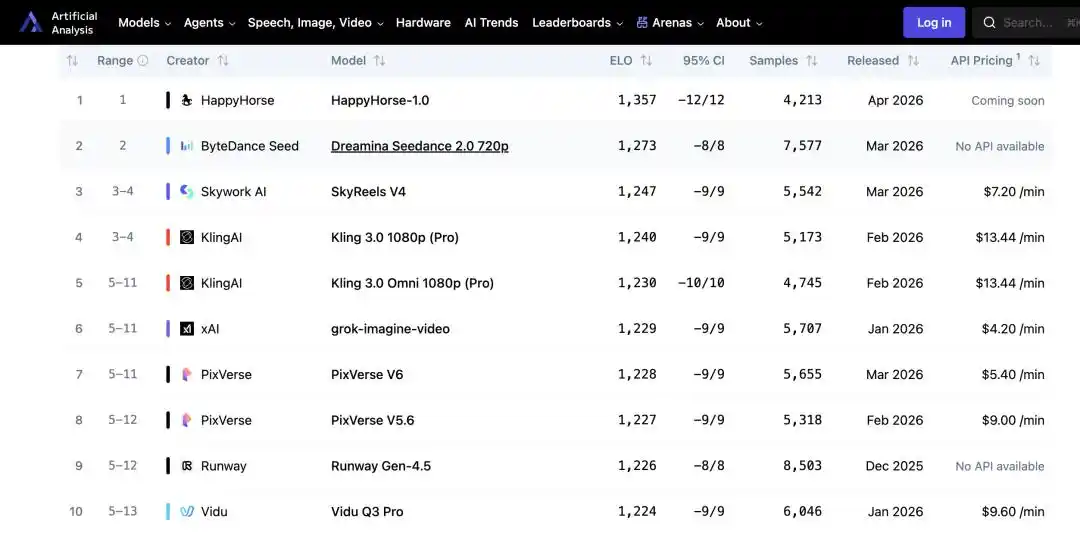
بدون مؤتمر صحفي، دون مدونة تقنية، دون أي دعم من شركة—نموذج تحويل النص إلى فيديو بعنوان HappyHorse-1.0، صعد صامتًا إلى صدارة قائمة AI Video Arena على منصة التقييم المرموقة Artificial Analysis، متفوقًا على Seedance 2.0 بدرجة Elo أعلى، ومتخطيًا جميع اللاعبين الرئيسيين مثل Ke Ling وTiangong، مما أثار مسابقة "فك الشفرة" في الدوائر التقنية.
لا يُعد ترتيب Artificial Analysis ناتجًا عن تقييمات تقنية، بل هو مجموع نقاط Elo المستخلصة من اختبارات عمياء من قبل مستخدمين حقيقيين، ويعكس الإدراك الحقيقي الذي يشعر به العاديون بعد مشاهدته. وهذا يجعل هذا الترتيب أصعب في التشكيك به مقارنة بقوائم الأداء المعتادة، ويجعل السؤال "من قام بصنع هذا الشيء؟" يصبح سؤالًا لا يمكن تجاهله.
"Happy Horse" صعدت سرًا إلى القمة، مُحدثة مسابقة تشفير في عالم التكنولوجيا
التكهنات على X جاءت بسرعة. أول ما لاحظه الناس هو ترتيب اللغات في الموقع الرسمي: الصينية المعيارية والكانتونية تأتيان قبل الإنجليزية. هذا الترتيب غير معتاد لمنتج موجه للجمهور العالمي — إذا كان الفريق الأمريكي هو المُهيمن، فمن المستحيل تقريبًا أن لا تكون الإنجليزية في المرتبة الأولى. يمكن التأكيد بشكل أساسي أن الفريق الخلفي قادم من الصين.
الاسم نفسه هو أيضًا دليل. عام 2026 هو عام الفرس في التقويم القمري، واسم "HappyHorse" يحتوي على إشارة غير خفية إلى عام الفرس، حيث استخدم نفس النهج سابقًا في وقت مبكر من هذا العام مع "Pony Alpha". وهكذا توسعت قائمة المشتبه بهم بسرعة: مؤسسو تينسنت وعلي بابا كلاهما يحملان لقب "ما"، مما يجعلهما طبيعيين في القائمة؛ هناك من راهن على شاومي، معتقدًا أن لي جون يميل دائمًا إلى التواضع ويحب الكشف المفاجئ؛ كما يرى آخرون أن الطابع يشبه أكثر DeepSeek، فمنذ فترة قام DS بإطلاق نموذج بصري بصمت، ثم أزاله بصمت أيضًا. تتصاعد التكهنات من كل الاتجاهات، لكن لا يوجد أي دليل قاطع حتى الآن.
الشيء الذي يحدد الهدف بدقة هو المقارنة التفصيلية على المستوى التقني. قام مستخدم X، فيغو زهاو، بمقارنة بيانات المرجع العامة لـ HappyHorse-1.0 مع النماذج المعروفة واحدًا تلو الآخر، ووجد نموذجًا متطابقًا بشكل عالٍ: daVinci-MagiHuman، وهو النموذج المفتوح المصدر "دافنشي ماجي هومان" الذي تم إطلاقه على GitHub في مارس.
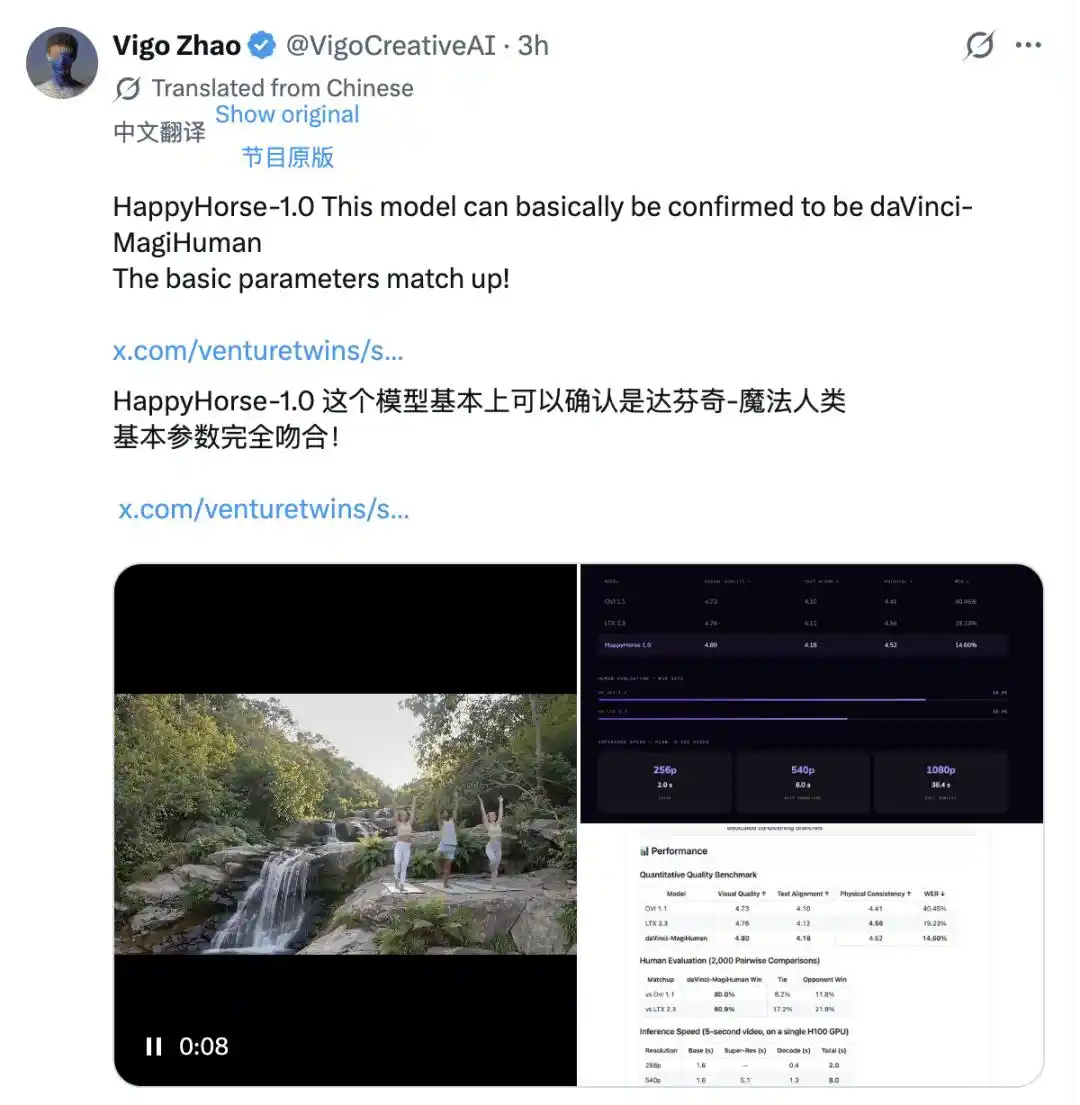
جودة البصرية 4.80، محاذاة النص 4.18، الاتساق الفيزيائي 4.52، معدل أخطاء التحدث 14.60٪ — تطابقت البياناتان تمامًا في كل بند. كما أن هيكل الموقع الرسمي متشابه إلى حد كبير: أسلوب عرض وصف البنية، جدول الأداء، ومقاطع الفيديو التوضيحية يبدو أنه مستمد من نفس القالب. كلاهما يستخدمان بنية Transformer أحادية التدفق، ويولدان الصوت والفيديو معًا، ويدعمان قائمة اللغات نفسها تمامًا. هذا المستوى من التشابه يصعب تفسيره كصدفة.
الاستنتاج الأكثر قبولًا في الدوائر التقنية حاليًا هو أن HappyHorse هو إصدار مُحسّن تم تطويره من قبل Sand.ai، إحدى الجهات المُطورة المشتركة لـ daVinci-MagiHuman، وهدفه الأساسي هو اختبار الحد الأقصى لأداء النموذج تحت تفضيلات المستخدمين الحقيقية، كخطوة استعدادية للتطبيق التجاري اللاحق.
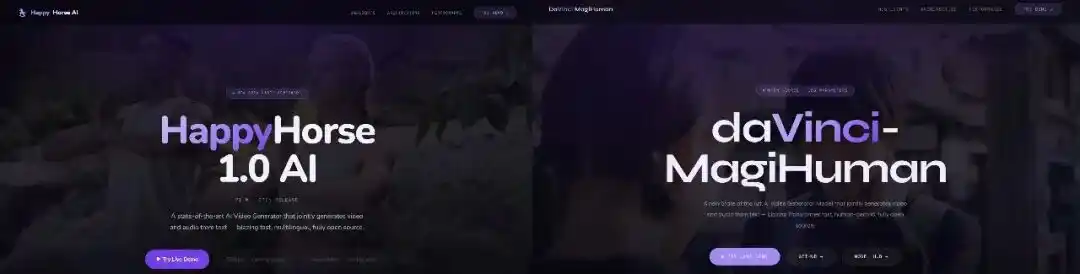
تم إطلاق daVinci-MagiHuman كمصدر مفتوح رسميًا في 23 مارس 2026، وهو نتاج تعاون بين فريقين شابين. أحد الفريقين من مختبر البحث في الذكاء الاصطناعي التوليدي (GAIR) التابع لكلية شنغهاي للابتكار (SII)، ويقوده الباحث ليو بينغفي؛ والفريق الآخر هو Sand.ai (San Dai Technology) في بكين، والذي أسسه تشاو يويه، وهو أيضًا لديه خلفية أكاديمية، وتتركز شركة الشركة على نماذج العالم التكرارية.
يستخدم النموذج Transformer أحادي التدفق بالكامل يعتمد على الانتباه الذاتي بـ 15 مليار معلمة، ويُدمج جميع رموز النص والفيديو والصوت في تسلسل واحد واحد لنموذج مشترك — لم يقم أي شخص في المجتمع المفتوح من قبل بتدريب مسبق مشترك حقيقي للصوت والفيديو من الصفر، فمعظم المحاولات كانت تدمج النماذج أحادية المودالية.
كيف حقق نموذج فيديو مفتوح المصدر انقلابًا خلال أسبوعين؟
بعد تحديد الهوية، أصبح السؤال الآخر أكثر صعوبة في الإجابة: كيف استطاع HappyHorse-1.0 تحقيق درجة Elo أعلى من Seedance 2.0 في غضون أسبوعين فقط، بينما تم فتح مصدر daVinci-MagiHuman في نهاية مارس؟
وفقًا للمعلومات المنشورة على الموقع الرسمي، لم تُجرِّ HappyHorse أي تعديلات على البنية الأساسية، والافتراض الأكثر معقولية هو أنها أجرت تعديلات مخصصة على استراتيجية الإنشاء الافتراضية لتناسب سيناريوهات التقييم.
يُعد نظام Elo في جوهره تراكمًا لتفضيلات المستخدمين؛ فتحسينات طفيفة في نقاط الحساسية الإدراكية مثل استقرار تعبيرات الشخصيات، وتوافق الصوت مع الصورة، وجمال المشهد، تجعله أكثر عرضة لل اختيار في الاختبارات العمياء. إن حدود قدرة النموذج لم تتغير، لكن "الأداء في التقييم" يمكن تحسينه وصقله.
في الواقع، تمثل صور البشر والمواد المُقدمة شفهيًا أكثر من 60% من عينات الاختبار العشوائي لـ Artificial Analysis، ونظرًا لأن daVinci-MagiHuman ركز منذ مرحلة التدريب على أداء صور البشر، فهو يتمتع بميزة طبيعية في هذه السيناريوهات، وهي السبب الأساسي لتفوقه في معدلات الفوز في الاختبارات العشوائية؛ فإذا كانت عينات الاختبار العشوائي تعتمد بشكل رئيسي على لقطات مقربة للبشر، فستكون النماذج المتميزة في التعامل مع صور البشر متفوقة بشكل منهجي، وهذا لا يرتبط مباشرة بأدائها الفعلي في السيناريوهات المعقدة مثل المشاهد متعددة الشخصيات أو الحركات الكاميرا المعقدة أو السرد الطويل الزمني.
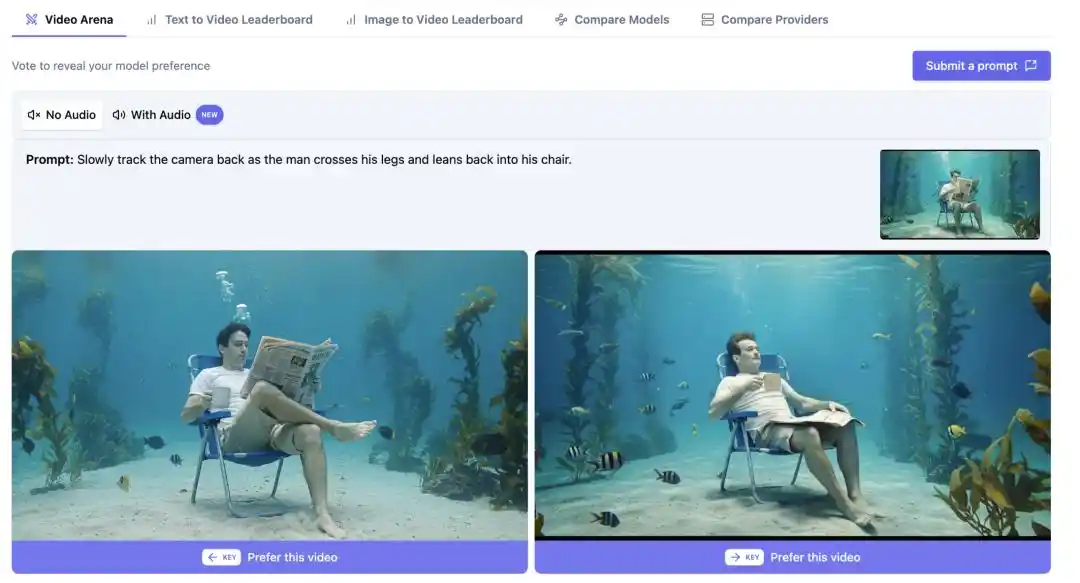
نتيجةً لذلك، ظهر فرق واضح بين الأرقام على الترتيب والتجربة العملية، وانقسم المُناقشون على X إلى فريقين. رأى الفريق المشكك، بعد الاختبار، أن HappyHorse-1.0 وSeedance 2.0 لا يزالان يظهران فروقًا مرئية في تفاصيل الشخصيات وانسيابية الحركة، وبالتالي شككا في تمثيلية تقييم Elo.
بينما يضع المؤيدون آمالًا كبيرة على إمكانات HappyHorse في حل مشكلة "الاتساق البصري في التسلسلات متعددة الكاميرات"، وهي مشكلة لم تُحل جيدًا بعد من قبل النماذج الفيديو السائدة، فإذا حقق daVinci-MagiHuman حقًا تقدمًا في هذا المجال، فقد يكون ذلك أكثر أهمية من مجرد ترتيب في قائمة.
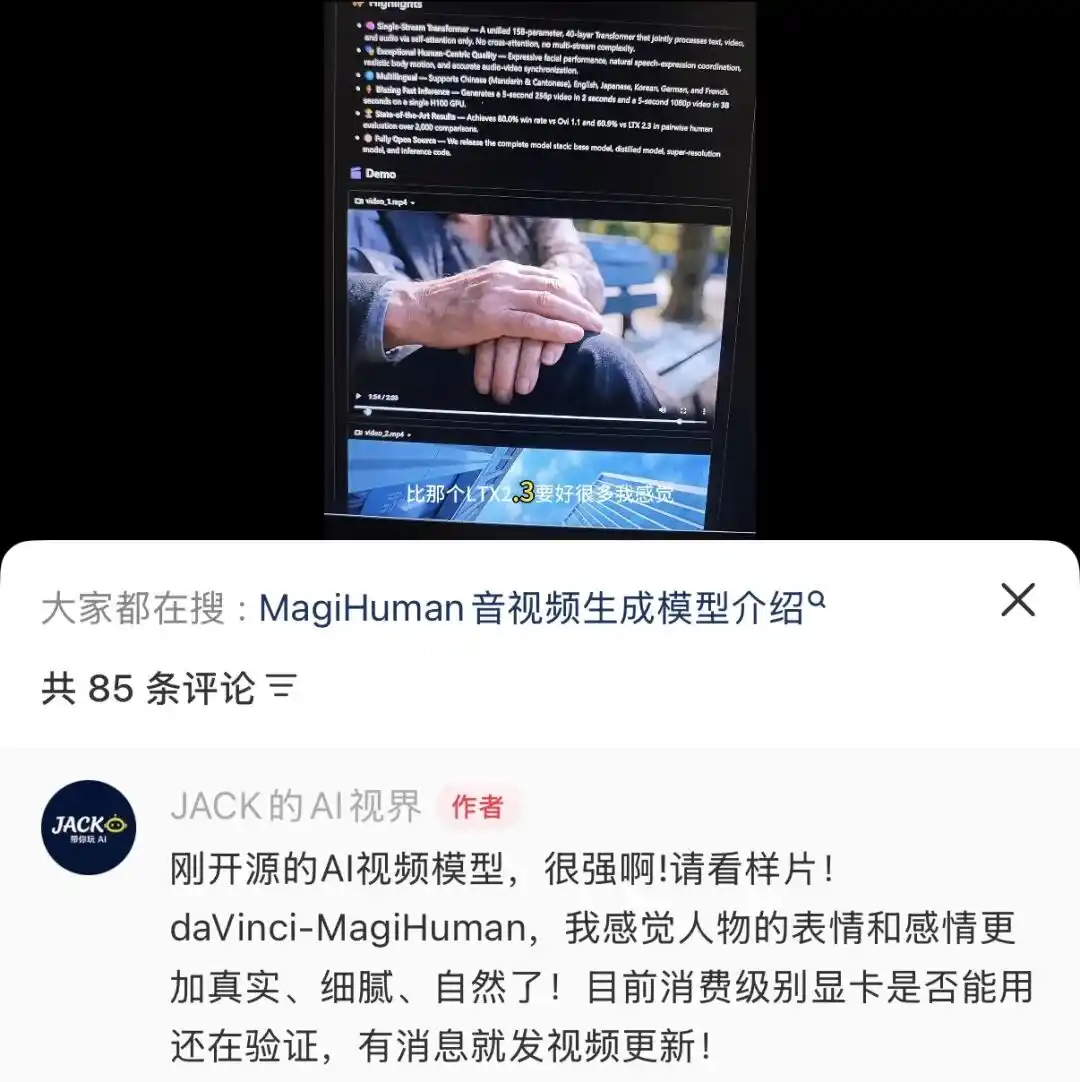
لا ينبغي تغطية قيود النموذج نفسه بالأرقام. قام مدوّن على Xiaohongshu @JACK's AI Vision بنشر واختبار daVinci-MagiHuman في أسرع وقت ممكن، ووجد أن تشغيله يتطلب H100، بينما من الصعب جدًا تشغيله على بطاقات رسومية استهلاكية عادية، وعلى الرغم من أن المجتمع يدرس حلول التكميم، إلا أن المستخدمين العاديين لا يزالون يواجهون صعوبة في نشره محليًا في المدى القصير.
من الناحية العملية، فهو يتقن حاليًا الشخص الواحد فقط، وعندما يظهر أكثر من شخص أو تصبح المشهد معقدًا، ينخفض الأداء — هذه ليست مشكلة يمكن حلها بضبط المعلمات، بل لها علاقة مباشرة بتصميمه المركّز على الصور الشخصية. عادةً ما يكون طول التوليد حوالي 10 ثوانٍ، وأي مدة أطول تؤدي إلى فوضى، ويجب الاعتماد على ملحقات التحسين العالي الدقة لتحسين جودة الإخراج عالي الدقة.
استنتجت منظور الذكاء الاصطناعي لـ @JACK أن daVinci-MagiHuman أقل سهولة في الاستخدام مقارنةً بـ LTX 2.3، ويجب الانتظار حتى تقوم المجتمع بتحسين التحليل الكمي قبل أن تكون مناسبة للاستخدام اليومي.
مجال توليد الفيديو، هل جاءت "السمكة المُحفزة" الحقيقية؟
بالطبع، التصدر في قائمة واحدة لا يعني الكثير. بعد ذلك، يجب على HappyHorse الخضوع لاختبارات أكثر شمولاً في الاستقرار، وسرعة الوصول تحت الحمل العالي، والاتساق عبر السيناريوهات المختلفة، ودقة التحكم في الأدوار، وقدرة التعميم خارج مجموعات التقييم. هذه هي المؤشرات الأساسية التي تحدد ما إذا كان النموذج قادرًا على الدخول فعليًا إلى سير عمل المُنشئين.
لكن إذا نظرنا إلى الصورة الأكبر للصناعة، فإن الإشارة التي تنقلها هذه القضية واضحة بالفعل.
ليس نموذج الفيديو مفتوح المصدر بحد ذاته شيئًا جديدًا. لكن ما يظل يفصل بين النماذج المفتوحة والمغلقة هو فجوة مرئية من حيث الأداء — حيث لم يتمكن نموذج مفتوح المصدر من تجاوز عتبة "قابل للاستخدام" إلى "قابل للتسليم" في السيناريوهات التي تتطلب تسليم النتائج للعملاء. إن قدرة منتجات مغلقة المصدر مثل كي لينغ وسيدانس على تحديد الأسعار تستند إلى حد كبير إلى هذه الفجوة.
إن أهمية هذا الحدث تكمن في أن منتجًا مبنيًا على نموذج مفتوح المصدر قد تمكن لأول مرة من المنافسة مباشرة مع المنافسين المغلقين الرائدين في قائمة التقييمات العمياء التي تعتمد على إدراك المستخدمين الحقيقيين. بغض النظر عن مدى وجود تحسينات موجهة لسيناريوهات التقييم، فإن هذا يُعد على الأقل إشارة تستحق الاهتمام الجاد من قبل الشركات المغلقة التي بنت سلطتها التسعيرية على هذا الفرق.
بالنسبة للمطورين، فإن معنى هذه النقطة التحولية أكثر تحديدًا. في السيناريوهات المتخصصة مثل الصور البشرية، والشخصيات الرقمية، والبث المباشر الافتراضي، بمجرد أن تصل جودة الإنتاج للنواة المفتوحة المصدر إلى عتبة "قابلة للتسليم"، فإن هيكل تكلفة النشر الذاتي سيتغير جوهريًا — ليس فقط من خلال تقليل تكاليف استدعاء واجهات برمجة التطبيقات، بل والأهم من ذلك، من خلال إدراج البيانات والنماذج وسلسلة الاستنتاج بالكامل تحت سيطرتك الخاصة، مما يوفر مرونة لا يمكن للحلول المغلقة تقديمها في مجالات التخصيص العميق والامتثال للخصوصية.
لن تُزعزع HappyHorse-1.0 مركزية Seedance 2.0 أو Ke Ling على المدى القصير، ولكن بمجرد ترسيخ إدراك أن نماذج مفتوحة المصدر يمكنها المنافسة مع النماذج المغلقة، ستستمر المجتمعات في تطوير تحسينات كمية، وضبط متخصص، وتسريع الاستنتاج بسرعة تفوق بكثير معدلات تطوير المنتجات المغلقة.
في عام الخيل هذا، ربما ما يستحق الاهتمام حقًا ليس أي حصان يركض أسرع، بل أن المسار نفسه يتوسع.
هذا المقال من حساب وينشين الرسمي "AI Value Officer"، المؤلف: شين ييه، المحرر: مي تشى