










المصدر: معهد CoinW
ملخص
Gradients هي شبكة فرعية لتدريب الذكاء الاصطناعي لامركزية مبنية على Bittensor (SN56)، وجوهرها يكمن في تحويل عملية تدريب النماذج من إجراءات تقنية معقدة إلى عملية تعاون شبكي مدفوعة بالسوق من خلال آليات مثل "نشر المهام، المنافسة بين عمال المناجم، والتحقق والتصفية". من حيث البنية، تجمع Gradients بين AutoML وقوة الحوسبة الموزعة لتشكيل سوق تدريب مدعوم بآلية تحفيز، مما لا يقلل فقط من عتبة استخدام الذكاء الاصطناعي، بل يزيد أيضًا من كفاءة استخدام قوة الحوسبة. من حيث الأداء البيئي والبيانات، أكملت Gradients بناء الشبكة الأساسية، لكن وزن التحفيز وتدفق الأموال لا يزالان محدودين حاليًا. تملأ Gradients فجوة البنية التحتية للتدريب في نظام TAO البيئي، وتستكشف نموذجًا جديدًا يعتمد على "تحسين الذكاء الاصطناعي المدفوع بالسوق"، ولها إمكانات طويلة الأجل للتطور كبوابة رئيسية لتدريب الذكاء الاصطناعي اللامركزي.
1. البدء من Web2 AutoML: حالة وحدود تدريب الذكاء الاصطناعي
1.1 ما هو AutoML
في الفهم التقليدي، كان تدريب نموذج ذكاء اصطناعي أمرًا يتطلب عتبة عالية، حيث كان على المهندسين معالجة البيانات، واختيار النموذج، وضبط المعلمات مرارًا وتكرارًا، بالإضافة إلى تقييم الأداء، وكانت العملية بأكملها معقدة ومستهلكة للوقت. لكن ظهور AutoML (التعلم الآلي التلقائي) يُعد في جوهره "تجميعًا تلقائيًا" لهذه الخطوات المتعبة. يمكن فهمه كأداة "تُنشئ النموذج تلقائيًا": حيث يكفي للمستخدم تقديم البيانات وإخبار النظام بالهدف المطلوب، مثل التصنيف أو التنبؤ أو التعرف، بينما يقوم النظام تلقائيًا بجميع الخطوات المتبقية، بما في ذلك اختيار النموذج، وضبط المعلمات، والتدريب والتحسين. وهذا يحول الذكاء الاصطناعي من أداة مخصصة لعدد قليل من المهندسين المتخصصين إلى قدرة يمكن للمطورين العاديين وحتى الشركات استخدامها، وهو خطوة مهمة نحو تعميم الذكاء الاصطناعي.
1.2 الحدود الأساسية لـ AutoML التقليدي
تتركز التحقيقات الحالية لـ AutoML بشكل رئيسي على منصات مزودي السحابة، مثل Google Vertex AI و AWS SageMaker، التي توفر "تدريب الذكاء الاصطناعي كخدمة". على الرغم من أن AutoML في Web2 قد خفّض بشكل كبير من عتبة استخدام الذكاء الاصطناعي، إلا أن نماذجه الأساسية لا تزال تواجه قيودًا واضحة. أولاً، تكمن المشكلة في المركزية، حيث تتحكم المنصات في قوة الحوسبة والأسعار والقواعد، مما يجعل المستخدمين معتمدين بشدة على مزود واحد ويفتقرون إلى القدرة على التفاوض. ثانيًا، التكلفة مرتفعة وغير شفافة، حيث تتركز موارد GPU اللازمة لتدريب الذكاء الاصطناعي في أيدي مزودي السحابة فقط، وتغيب آليات التسعير التنافسية السوقية. والأهم من ذلك، أن كفاءة التحسين لها حدود. فـ AutoML التقليدي ما زال في جوهره "نظامًا واحدًا يساعدك على إيجاد الحل الأمثل"، بغض النظر عن مدى تعقيد هذا النظام، فهو ينتمي في جوهره إلى تحسين مسار تقني واحد فقط. إن مساحة استكشافه محدودة، ويصعب عليه تجربة أفكار مختلفة تمامًا في نفس الوقت. وبالتالي، فإن تدريب الذكاء الاصطناعي في Web2 الحالي هو "نظام مغلق"، حيث تحدث عملية تدريب النموذج وتحسينه وجدولة الموارد جميعها في بيئة يسيطر عليها مزود واحد. على الرغم من كفاءة هذا النموذج، إلا أنه مع نمو الطلب، بدأت حدوده تظهر تدريجيًا.
2. التدرجات: إعادة بناء تدريب الذكاء الاصطناعي باستخدام "الشبكة"
2.1 Gradients ما هو: منصة AutoML لامركزية
في الفصل السابق، أشرنا إلى أن المشكلة الأساسية في AutoML التقليدي القائم على Web2 هي "النظام المغلق"، حيث يعتمد تدريب النماذج على المنصة، وتحدد مسارات التحسين، وتقيد تدفق الموارد. إن Gradients هو إعادة هيكلة لهذا النموذج. نشأت Gradients من مجتمع المهندسين اللامركزي الذي أطلقه WanderingWeights، وتُبنى على شبكة Bittensor، وهي شبكة فرعية لتدريب الذكاء الاصطناعي تعمل على Subnet 56. على عكس المنصات التقليدية، لا تقدم خدمات مركزية، بل تفكك عملية التدريب وتُسند تنفيذها إلى شبكة مفتوحة. يكفي للمستخدمين تحديد أهداف المهمة، مثل نوع النموذج والبيانات، بينما تقوم الشبكة تلقائيًا بتنفيذ التدريب، وتحسين المعلمات، وفرز النتائج. في هذا النموذج، يتحول تدريب الذكاء الاصطناعي من عملية هندسية معقدة إلى عملية بسيطة تتمثل في "تقديم الطلب والحصول على النتيجة"، ليصبح أكثر قربًا من قدرة عامة بدلاً من كونه عملًا تقنيًا يتطلب حدًا عالٍ من التخصص.
2.2 من النظام المغلق إلى التعاون المفتوح: ما المشكلات التي يحلها Gradients
التغيير الأساسي في Gradients يكمن في تحويل عملية التدريب التي كانت مغلقة داخل منصة واحدة إلى عملية شبكة مفتوحة وتعاونية. لم تعد مهام التدريب تُنفَّذ من قبل نظام واحد، بل تُوزَّع على عدة مشاركين لمحاولة تنفيذها بالتوازي، ثم يتم اختيار أفضل النتائج من خلال آلية تقييم موحدة. هذا الهيكل يقلل أولاً من الاعتماد على مزودي الخدمة المركزيين، ويبني التدريب على قوة حوسبة موزعة؛ في الوقت نفسه، يتم دمج موارد GPU الموزعة داخل شبكة واحدة، مما يخلق طريقة توزيع موارد أقرب إلى السوق من خلال المنافسة. والأهم من ذلك، لم تعد تحسينات النموذج مقيدة بمسار واحد، بل تقترب باستمرار من حلول أفضل من خلال الاستكشاف المتوازي لطرق متعددة، مما يرفع الحد الأقصى العام للتحسين.
2.3 التغيير الجوهري: من أداة إلى "سوق تدريب"
في AutoML التقليدي، تشبه المنصة أداة تساعد المستخدمين على إيجاد الحل الأمثل من خلال خوارزميات داخلية. أما في Gradients، فإن هذه العملية تشبه أكثر "سوقًا" يعمل باستمرار: يُنشر المستخدمون طلباتهم، وتنافس مشاركون مختلفون على نفس المهمة، ويتم تصفية النتائج من خلال آلية تقييم. وهكذا، لم تعد أداء النماذج تعتمد على قدرة نظام واحد، بل على المنافسة والتحديث المستمر الناتج عن مشاركة متعددة الأطراف. وقد تحول AutoML من مشكلة تقنية تحسينية مغلقة نسبيًا إلى عملية ديناميكية مدفوعة بالحوافز، مما يسمح بتوسيع قدرات التحسين مع زيادة عدد المشاركين. هذا التحول جعل تدريب الذكاء الاصطناعي يبدأ في امتلاك خصائص تطور ذاتي مشابهة للأسواق.
2.4 الدور في نظام TAO البيئي: طبقة البنية التحتية لتدريب الذكاء الاصطناعي
في نظام الشبكات الفرعية لـ Bittensor، تؤدي الشبكات الفرعية المختلفة وظائف متنوعة مثل الاستدلال ومعالجة البيانات والتدريب، وتقع Gradients في طبقة التدريب. فهي مسؤولة عن تحويل قوة الحوسبة الموزعة إلى إنتاج نماذج فعلية، ومن خلال آليات توزيع المهام والتقييم، تمكن هذه الموارد من التوزيع المستمر والتحسين. كما أنها تربط بين عرض قوة الحوسبة وطلب النماذج، مما يحول التدريب من عملية استهلاك موارد بسيطة إلى عملية تعاون شبكي يمكن تنظيمها وتحسينها. في هذا النظام، تشبه Gradients عنصرًا محوريًا يحول الموارد الموزعة إلى قدرات ذكاء اصطناعي قابلة للاستخدام، وتدعم تطور التطبيقات العليا.
3. الهيكل الأساسي: كيف تتم تدريب الذكاء الاصطناعي على الشبكة
في الفصل السابق، ذكرنا أن Gradients حوّلت تدريب الذكاء الاصطناعي من "الإكمال داخل المنصة" إلى "الإكمال عبر التعاون الشبكي". فكيف تعمل هذه الشبكة بالضبط؟ جوهر هذا الفصل هو تفكيك هذه العملية بطريقة أكثر وضوحًا وسهولة.
3.1 التدريب الموزع: كيف تُنجز مهمة واحدة من قبل عدة أشخاص
يمكنك تصور Gradients كشبكة تعاونية تعمل باستمرار للتدريب. عندما يُقدّم المستخدم مهمة تدريب، لا تُسنَد هذه المهمة إلى نظام واحد فقط، بل تُوزَّع في نفس الوقت على عدة مشاركين في الشبكة. يحاول هؤلاء المشاركون، بناءً على نفس البيانات والهدف، استخدام أساليب تدريب مختلفة، ثم يقدّمون نتائجهم ضمن الوقت المحدد. بعد ذلك، تقوم النظام بتقييم هذه النتائج بشكل موحد، ويختار أفضل الحلول منها. في النهاية، تُمنح المكافآت للنتائج الأفضل أداءً، بينما تُستبعد الحلول الأخرى. من منظور المستخدم، يتطلب هذا العملية مجرد إطلاق مهمة واحدة، كأنه يُنشّط في نفس الوقت عدة أساليب تحسين مختلفة، ويختار تلقائيًا الحل الأمثل. المفتاح في هذه الطريقة ليس قوة العقدة الفردية، بل في محاولة متوازية من قبل العديد من الأشخاص + التصفية التلقائية، مما يدفع النتائج نحو التقارب المستمر مع الحل الأمثل.
في هذا الشبكة، هناك ثلاث فئات رئيسية من المشاركين: المستخدمون، والمنقبون، والمتحققون. يتحمل المستخدمون مسؤولية طلب التدريب؛ ويقدم المنقبون قوة الحوسبة ويجربون أساليب تدريب مختلفة؛ بينما يتحمل المتحققون مسؤولية تقييم النتائج وانتقاء النموذج الأمثل. هذا التقسيم للعمل يسمح بتشغيل عملية التدريب باستمرار، مع استمرار筛选 الحلول الأفضل. بشكل عام، فهو يشكل شبكة تعاونية مدفوعة بـ "الطلب، العرض، التقييم".
3.2 AutoML المُحفَّز بالسوق
في تحليل الآلية المذكورة سابقًا، يمكن ملاحظة أن Gradients لا تنقل AutoML ببساطة إلى السلسلة، بل تغيّر المنطق الأساسي لتحسين النموذج من خلال إدخال مشاركة متعددة الأطراف وآليات تحفيز. في AutoML التقليدي، يعتمد الأمر على نظام واحد يبحث عن الحل الأمثل ضمن مسارات محدودة، بينما في Gradients، تم توسيع هذه العملية لتشمل الشبكة بأكملها: حيث يحاول المشاركون المختلفون باستمرار أساليب مختلفة لنفس المهمة، ويقومون بفرزها وتحسينها بشكل مستمر عبر تقييم موحد. هذا يجعل تحسين النموذج ليس عملية حسابية لمرة واحدة، بل عملية ديناميكية يمكن تطويرها مرارًا وتكرارًا. في هذه الآلية، تحصل النتائج الأفضل أداءً على عوائد أعلى، مما يجذب باستمرار المشاركين لتحسين استراتيجياتهم ودفع تحسينات مستمرة في الأداء العام.
4. آليات التحفيز والمنافسة: كيف تشكل تدريبات الذكاء الاصطناعي "دورة إيجابية"
4.1 آلية التحفيز (مدعومة بـ TAO): من السلوك التدريبي إلى العوائد
إن مفتاح تشغيل Gradients على المدى الطويل هو آلية الحوافز وراءه، والتي تعتمد على نظام الحوافز الأصلي الذي يقدمه Bittensor. حيث يُعد TAO العملة الأصلية لشبكة Bittensor، ويعمل كـ"ناقل للقيمة" في جميع أنحاء الشبكة: فهو يُستخدم من ناحية لتعويض المشاركين الذين يقدمون قوة حوسبة ومساهمات نموذجية، ومن ناحية أخرى يشارك في توزيع أوزان الشبكات الفرعية من خلال طرق مثل الرهن، مما يؤثر على كيفية تدفق الموارد بين الشبكات الفرعية المختلفة.
يُنتج الشبكة الرئيسية لـ Bittensor باستمرار مكافآت جديدة (Emission) على شكل TAO (الكمية المناسبة حاليًا حوالي 3600 TAO يوميًا)، وتُوزع وفقًا لقواعد محددة على الشبكات الفرعية المختلفة. يعتمد مقدار التوزيع الذي تحصل عليه كل شبكة فرعية على "أدائها" داخل الشبكة بأكملها، مثل مستوى النشاط وجودة المساهمات وحالة الدعم المالي، إلخ. بالنسبة للشبكة الفرعية التي ينتمي إليها Gradients، يتم توزيع جزء TAO المخصص لها مرة أخرى داخليًا بين المشاركين. يعتمد التوزيع الأساسي على من قدم نموذجًا أفضل، حيث يحصل على عائدات أكبر.
على المستوى التفصيلي، يقدم العمال نتائج التدريب، ويقوم المحققون باختبار هذه النتائج وتصنيفها. يحسب النظام "وزن المساهمة" لكل مشارك بناءً على التصنيفات، ثم يوزع المكافآت وفقًا لهذا الوزن. ستتلقى النماذج الأفضل أداءً (مثل تلك التي تتمتع بقدرة تعميم أقوى ونتائج أكثر استقرارًا) عوائد أعلى، بينما سيحصل المحققون الذين يقدمون تقييمات أكثر دقة ويعكسون الجودة الحقيقية بشكل أفضل على حوافز إضافية. هذا التصميم يجعل "الأداء الأفضل" يرتبط مباشرة بـ"الربح الأكبر"، مما يحفز المشاركين على تحسين النماذج باستمرار.
4.2 المنافسة بين الشبكات الفرعية: ليست فقط منافسة داخلية، بل أيضًا تصنيف خارجي
بخلاف المنافسة داخل الشبكة الفرعية، يواجه Gradients أيضًا "منافسة أفقية" عبر شبكة Bittensor بأكملها. نظرًا لأن توزيع TAO ديناميكي، فإن الشبكات الفرعية المختلفة تتنافس على الحصول على أوزان أعلى. فقط تلك الشبكات الفرعية التي تنتج باستمرار نتائج عالية الجودة وتجذب مشاركين أكثر، يمكنها الحصول على حصة أكبر من المكافآت. وبالتالي، فإن حوافز Gradients لا تعتمد فقط على أداء النماذج الداخلية، بل أيضًا على قدرتها التنافسية النسبية داخل النظام البيئي بأكمله. يشكل النظام بأكمله حلقة متعددة المستويات: هناك منافسة بين النماذج داخل الشبكة الفرعية؛ وهناك منافسة على الأداء العام بين الشبكات الفرعية. في النهاية، يتم ربط استثمار القوة الحسابية وفعالية النموذج والعائد الاقتصادي معًا، مما يشكل آلية تغذية راجعة إيجابية تعمل باستمرار.
4.3 التدرجات 5.0: من المنافسة إلى "آلية البطولة"
على أساس المنافسة المستمرة في المراحل المبكرة، تطورت Gradients إلى آلية أكثر تنظيماً تُعرف بـ"التدريب على شكل بطولة". يمكن فهمها كمنافسة دورية: حيث يتم تحديد نافذة زمنية لكل جولة تدريب، وتنافس عدة مشاركين على نفس المهمة، ويتم التخلص التدريجي من المشاركين عبر جولات متعددة حتى يتم اختيار أفضل حل. يركز هذا النموذج على المقارنة التدريجية والتقييم المركّز. أحد التغييرات المهمة هو أن عمال المناجم لم يعودوا يرسلون نتائج التدريب مباشرة، بل يرسلون "طريقة التدريب" (الكود)، ثم يتم تنفيذها بشكل موحد من قبل عقد التحقق. هذا يعزز العدالة من خلال تجنب التداخل الناتج عن بيئات الحوسبة المختلفة، كما يحمي بشكل أفضل خصوصية البيانات وعملية التدريب. بالإضافة إلى ذلك، غالباً ما يتم تثبيت الحلول الفائزة كأساليب قابلة لإعادة الاستخدام، مشابهة لـ"أفضل الممارسات" التي تتراكم باستمرار. على المدى الطويل، لا تهدف هذه الآلية فقط إلى اختيار النموذج الأمثل، بل أيضاً إلى بناء مكتبة متقدمة باستمرار من أساليب التدريب.
5. الحالة البيئية الحالية
5.1 هيكل المشاركين: شبكة تعاونية مكونة من الطلب والعرض والتقييم
يتكون نظام Gradients من ثلاث فئات رئيسية من الأدوار: المستخدمون (الجانب الطلب)، والمنقبون (الجانب العرض)، والمدققون (الجانب التقييمي). ويشمل المستخدمون بشكل رئيسي مطوري الذكاء الاصطناعي، والشركات الصغيرة والمتوسطة، ومبنيي Web3، وهؤلاء الأفراد عادةً ما يمتلكون أساسًا تقنيًا، لكنهم يفتقرون إلى قوة الحوسبة أو القدرة الكاملة على تدريب النماذج، وبالتالي يفضلون استخدام Gradients لإكمال بناء النماذج بتكلفة أقل. أما المنقبون فيقدمون قوة معالجة GPU ويشتركون في منافسة مهام التدريب، ودافعهم الأساسي هو الحصول على عوائد TAO؛ بينما يتحمل المدققون مسؤولية تقييم وترتيب نتائج التدريب، وهي خطوة حاسمة لضمان جودة النموذج وفعالية عمل الآلية.
من منظور أكثر تفصيلاً للجمهور المستهدف، يظهر أن مجموعة المستخدمين الفعلية لـ Gradients تتميز بسمة "شبه المطورين": فهي لا تشبه مختبرات الذكاء الاصطناعي الرائدة، ولا تشمل المستخدمين العاديين غير التقنيين بالكامل، بل تتركز أساساً على المطورين ذوي القدرات الهندسية ومستخدمي تقنيات Web3. ويعكس هذا الأمر أيضاً بنية المجتمع، حيث يهيمن اللغة الإنجليزية على البيئة الحالية، مع تواجد المستخدمين الأساسيين في أوساط المطورين في أمريكا الشمالية وأوروبا، بالإضافة إلى تغطية جزء من عمال المناجم في جنوب شرق آسيا وموفرَي موارد GPU على مستوى العالم. بشكل عام، يشبه هذا مجتمعاً تقنياً يقوده المطورون.
5.2 الحالة الحالية لتشغيل النظام البيئي
حتى 12 مايو، كان سعر رمز Gradients alpha حوالي 0.0255 TAO، مع حوالي 4,890 عنوانًا يحمل الرمز، و243 عامل منجم، و12 محققًا، ونسبة الإصدار 1.61%. في الوقت نفسه، كانت نسبة TAO في حاوية السيولة 2.19%، ونسبة Alpha 97.81%. من حيث السعر وعدد العناوين الحاملة، يمتلك Gradients قاعدة مستخدمين واهتمامًا معينين، لكنه لا يزال في مرحلة مبكرة من الانتشار. مقارنةً بمشروع Chutes الرائد في نظام TAO، كان سعر رمز alpha في ذلك اليوم 0.0877 TAO، مع 13,409 عناوين حاملة.
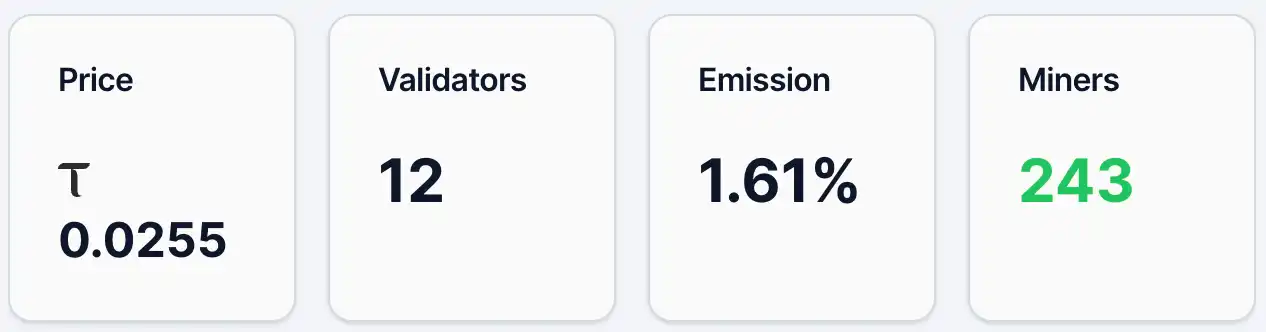
الشكل 1. بيانات التدرجات.
المصدر:https://bittensormarketcap.com/subnets/56
ثانيًا، آلية التحفيز Emission. في نظام Bittensor، تشير Emission إلى الوزن الزمني للحصول على المكافآت الجديدة في الشبكة بالكامل لكل شبكة فرعية. تقوم شبكة Bittensor باستمرار بإنشاء TAO جديدة وتوزيعها وفقًا للأوزان على الشبكات الفرعية المختلفة، وتمثل نسبة 1.61% الحالية لـ Gradients حصة صغيرة فقط من المكافآت الجديدة في الشبكة بأكملها. يعكس هذا المؤشر جوهرًا "نتيجة التصويت" من قبل السوق عبر تدفقات الأموال (مثل التزكية) على الشبكات الفرعية المختلفة. وبالتالي، فإن مستوى 1.61% عادةً يعني أن القبول السوقي الحالي وتدفق الأموال محدودان نسبيًا، وفي الوقت نفسه، يعني أيضًا وجود إمكانية للارتفاع في الوزن مستقبلًا. من حيث هيكل التمويل (خزانات السيولة)، فإن نسبة TAO تبلغ فقط 2.19%، بينما تصل نسبة Alpha إلى 97.81%، مما يشير إلى أن تدفق الأموال الخارجية لا يزال محدودًا، وأن العرض الحالي يهيمن عليه بشكل أساسي داخل الشبكة الفرعية. السعر حساس جدًا للأموال الجديدة، وعندما يتدفق المزيد من TAO، قد يؤدي ذلك إلى تأثير مضاعف أكثر وضوحًا.
6. مشهد المنافسة والنقاط القوية والضعيفة
6.1 التحديد الصناعي: البنية التحتية للتدريب الخاصة بالـ AutoML اللامركزية
تُشغل Gradients فئة فرعية متمثلة في "بنية تحتية لتدريب الذكاء الاصطناعي + AutoML لامركزية". فهي تسعى لإطلاق تدريب النماذج من المنصات المركزية، وتحقيق استخدام أكثر كفاءة للموارد وتحسين النماذج من خلال آليات شبكة. في نظام Web2، أصبحت هذه الفئة الفرعية ناضجة نسبيًا، مع أمثلة نموذجية مثل Google Vertex AI وAWS SageMaker. توفر هذه المنصات للمطورين خدمات متكاملة لتدريب النماذج ونشرها عبر الحوسبة السحابية، لكن جوهرها يظل بنية مركزية. على العكس، لا يكمن اختلاف Gradients في "المزيد من الوظائف"، بل في المنطق الأساسي المختلف: فهي تحول التدريب من "خدمة منصة" إلى "تعاون شبكي"، وتستخدم آلية تنافسية لاختيار أفضل النتائج، مما يجعلها أقرب إلى نظام تدريب يعمل وفق آليات السوق.
6.2 مقارنة أفقية: الفروق بين Web2 و Web3 AutoML
من منظور أوسع، يمثل الفرق بين Web2 و Web3 في مجال AutoML مقارنة بين نموذجين مختلفين. يركز نموذج Web2 على الكفاءة والاستقرار، من خلال تجميع الموارد وتحسين الهندسة لتقديم تجربة خدمة قابلة للتحكم وناضجة؛ بينما يركز نموذج Web3 على الانفتاح وآليات الحوافز، من خلال إشراك أطراف متعددة لدفع تحسين النماذج عبر المنافسة. من حيث التفاصيل، يشبه AutoML في Web2 "أداة قوية"، حيث يُسند المستخدمون المهام إلى المنصة لتنفيذ البحث عن الحل الأمثل داخليًا؛ بينما يشبه AutoML في Web3، كما في Gradients، "سوقًا مفتوحًا"، حيث يُنشر المستخدمون احتياجاتهم، ويقدم المشاركون المختلفون حلولًا، ثم تُختَرَق النتائج عبر آلية تقييم. هذا الفرق يؤدي مباشرة إلى أن النموذج الأول أكثر استقرارًا وقابلية للتحكم، لكنه يمتلك مسارات تحسين محدودة؛ بينما الثاني يوفر مساحة استكشافية أوسع وحدودًا إمكانية أعلى، لكنه لا يزال بحاجة إلى تحسين في الاستقرار والنضج.
6.3 التميّز في Gradients ضمن Web3
في سباق Web3 AI الحالي، لا تزال معظم المشاريع تركز على طبقة الاستنتاج أو اتجاه AI Agent، بينما المشاريع المركزة على "بنية التدريب الأساسية" نادرة نسبيًا. تحاول بعض المشاريع دمج شبكات الحوسبة أو شبكات البيانات لتوفير قدرات التدريب، لكن بشكل عام، لا تزال معظمها في مرحلة جدولة الموارد أو سوق الحوسبة. يكمن تميز Gradients في أنه لا يوفر فقط تطابق الحوسبة، بل يمتد أعلى إلى "آلية تحسين النموذج" نفسها، من خلال إدخال نظام تقييم وتنافس، مما يمنح عملية التدريب قدرة على التطور المستمر. هذا يعني أنه لا يحل فقط مشكلة "من أين تأتي الحوسبة"، بل يحل أيضًا "كيفية استخدام هذه الحوسبة بكفاءة أكبر". من حيث التحديد، فإن Gradients أقرب إلى شبكة "موجهة بنتائج التدريب" بدلاً من مجرد سوق حوسبة أو منصة أدوات، وهو ما يمثل الفرق الأساسي بينه وبين معظم مشاريع Web3 AI.
6.4 الميزة الأساسية: تحسين الكفاءة المُحَفَّز بالآلية
بشكل عام، تكمن مزايا Gradients بشكل رئيسي في تصميم آلية عملها. أولاً، إنها تقلل من عتبة الاستخدام من خلال تجريد المهام، مما يسمح للمستخدمين بتحقيق نتائج النموذج دون الحاجة إلى المشاركة العميقة في عمليات التدريب المعقدة، وبالتالي توسيع قاعدة المستخدمين المحتملين. ثانيًا، من حيث الموارد، فإن إدخال قوة الحوسبة الموزعة يجعل التدريب لا يعتمد على مزود سحابي واحد، ويمكن نظريًا تحقيق هيكل تكلفة أكثر مرونة من خلال المنافسة. والأهم من ذلك، تغيير طريقة التحسين. من خلال الاستكشاف المتوازي من قبل متعددين للمشاركين مع دمج آلية الترشيح، توفر Gradients حلاً يختلف عن التحسين التقليدي ذو المسار الواحد، مما يمنح النموذج فرصة للوصول إلى أداء أفضل في وقت أقصر. إن نموذج "التحسين المُحَرَّك بالمنافسة" هذا هو أبرز ميزة له.
6.5 التحديات المحتملة
قد تواجه جودة النموذج مشاكل في الاستقرار. يعتمد التدريب اللامركزي على مشاركة أطراف متعددة، مما يمكن أن يرفع الحد الأقصى للقدرة، لكنه قد يؤدي أيضًا إلى تقلبات في النتائج، مقارنةً بالنظم المركزية، حيث توجد درجة من عدم اليقين في التحكم. ثانيًا، تكمن مشكلة الثقة من حيث الأعمال. بالنسبة للعملاء المؤسسيين، فإن أمان البيانات وقابلية التحقق من عملية التدريب أمران بالغان الأهمية، وما زال التحدي الرئيسي هو كيفية ضمان عدم إساءة استخدام البيانات وقابلية مراجعة النتائج في بيئة لامركزية. وأخيرًا، يعتمد تشغيل Gradients بشكل كبير على آلية الحوافز؛ فإذا انخفض جاذبية عائدات TAO، فقد يؤثر ذلك على مستوى مشاركة عمال المناجم ونشاط الشبكة العام. وبالتالي، فإن استدامتها على المدى الطويل تعتمد إلى حد ما على قدرة النموذج الاقتصادي على تشكيل دورة إيجابية مستقرة.
7. التطلعات المستقبلية: هل يمكن أن ينجح AutoML اللامركزي؟
من منظور المرحلة الحالية، لا يزال Gradients في مراحله المبكرة، ويعتمد نجاحه المستقبلي على عدة نقاط رئيسية. الأكثر جوهرية هو القدرة على جذب احتياجات تدريب حقيقية بشكل مستمر، وليس فقط المشاركة المستحثة بالحوافز؛ ثانياً، جودة النموذج، وهل يمكن للنهج اللامركزي أن ينتج نتائج قابلة للاستخدام، أو حتى أفضل، بشكل مستقر؛ بالإضافة إلى ما إذا كانت الآلية الاقتصادية قادرة على تشكيل دورة إيجابية تضمن التوازن طويل الأمد بين عرض قوة الحوسبة والعوائد.
في السياق الصناعي الأوسع، ينقسم تدريب الذكاء الاصطناعي إلى مسارين. الأول هو نموذج Web2، الذي تقوده شركات التكنولوجيا الرائدة، وتُعزز من خلال الموارد والقدرات الهندسية المركزية أداء النماذج باستمرار، وميزته تكمن في الاستقرار والنضج؛ والآخر هو مسار Web3 الذي يمثله Gradients، والذي يتيح لمزيد من المشاركين الانخراط في تحسين النماذج من خلال الشبكة المفتوحة وآليات الحوافز، ويرفع باستمرار الحد الأقصى في سياق المنافسة. الأول يهدف إلى "بناء نظام أقوى"، بينما الثاني يشبه أكثر "بناء شبكة تتطور ذاتيًا".
من هذا المنظور، يمثل استكشاف Gradients إمكانية جديدة: لم يعد تدريب الذكاء الاصطناعي مجرد مشكلة تقنية، بل هو دمج بين "القوة الحسابية + البيانات + آليات السوق". إذا نجح هذا النموذج، فقد يصبح مدخلًا لتدريب الذكاء الاصطناعي اللامركزي، ويلعب دورًا أساسيًا كبنية تحتية في نظام Bittensor. بالطبع، لا يزال هذا الاتجاه بحاجة إلى وقت للتحقق منه، لكنه قدّم بالفعل فكرة تطور مختلفة عن المسار التقليدي لـ AutoML.
مرجع
1. وثائق Bittensor:https://docs.learnbittensor.org
2. موقع Gradients:https://www.gradients.io/
3. التدرجات:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart