









إن تعديل أسعار DeepSeek هذا، من خلال انخفاض حاد غير خطي، أجبر الصناعة على الدخول في عصر تكلفة جديد.
مؤلف المقال والمصدر: 0x9999in1، ME News
ملخص
- السعر يخترق الحد الأدنى: في نهاية أبريل 2026، خفض DeepSeek سعر إخراج نموذج V4-Pro إلى 0.878 دولار لكل مليون رمز، باستخدام خصم زمني مدمج مع تخفيضات التخزين المؤقت، وانخفض سعر الإدخال عند تطابق التخزين المؤقت إلى 0.0037 دولار (ما يعادل حوالي 0.025 يوان صيني)، مُحطمًا تمامًا نقطة المرجع في تسعير نماذج الذكاء الاصطناعي الكبيرة.
- يوجد فجوة في التسعير بين الصين والولايات المتحدة: مقارنةً بشركات الرائدة عالميًا، فإن التكلفة الإجمالية لاستدعاء واجهة برمجة تطبيقات DeepSeek-V4-Pro لا تزيد عن ثلثي واحد من تكلفة OpenAI GPT-5.5 وAnthropic Claude Opus 4.7، مما يخلق فرقًا تكلفة واضحًا جدًا.
- الضغط على هيكل المنافسة المحلي: تحت ضغط التسعير العدائي من DeepSeek، تواجه النماذج الرئيسية المحلية مثل Zhipu GLM 5.1 وMoonshot Kimi K2.6 ضغوطًا تجارية هائلة، وقد تضطر إلى متابعة تخفيض الأسعار، مما سيُسرع بشكل كبير من عملية تصفية الصناعة.
- "التوافق مع ذاكرة التخزين المؤقت" يصبح جوهر الاقتصاد: خفض DeepSeek لسعر التوافق مع ذاكرة التخزين المؤقت إلى واحد من عشرة من السعر الأصلي، هذه الاستراتيجية تُفيد بشكل كبير منطقيًا سيناريوهات المعالجة الطويلة للنصوص، وRAG (الاسترجاع المعزز بالتكوين)، والتفاعلات المتعددة الجلسات المستمرة للوكلاء.
- استنتاجات مركز الأبحاث: إن النماذج الأساسية الكبيرة تتسارع في التحول إلى "بنية تحتية مثل الكهرباء والماء"، وسيتحول محور المنافسة المستقبلي من التنافس على حجم معلمات النموذج الفردي إلى التنافس على قدرة تحسين تكلفة الاستنتاج وحصة نظام المطورين.
مقدمة: لحظة نقطة التحول في تكلفة قوة الحوسبة للنماذج الكبيرة
غالبًا ما يرافق تطور التكنولوجيا انخفاضٌ أسّي في التكاليف، وهو طريق لا مفر منه لأي تقنية ثورية تسعى لتحقيق انتشارٍ شامل. في 25-26 أبريل 2026، شهد قطاع الذكاء الاصطناعي لحظةً بارزة للغاية: أطلقت الشركات الرائدة في نماذج الذكاء الاصطناعي الكبرى، DeepSeek، قنبلتين "عميقتين" متتاليتين. أولاً، أعلنت عن خصمٍ سريع ومحدود الوقت بنسبة 25% على واجهة برمجة تطبيقات نموذج DeepSeek-V4-Pro؛ ثم أعلنت فورًا أن سعر التخزين المؤقت للإدخال في جميع خدمات واجهة برمجة التطبيقات قد انخفض مباشرةً إلى واحد من عشرة من السعر الأصلي.
بعد هاتين الدورتين من استراتيجية التسعير المتراكمة، انخفض سعر إدخال التخزين المؤقت للـ DeepSeek-V4-Flash إلى 0.0029 دولار أمريكي (ما يعادل حوالي 0.02 يوان صيني) لكل مليون توكين قبل 5 مايو 2026، بينما بلغ سعر إدخال التخزين المؤقت للـ DeepSeek-V4-Pro، الذي يُقاس بمستوى عالمي رائد، فقط 0.0037 دولار أمريكي (ما يعادل حوالي 0.025 يوان صيني).
قبل هذا، كان التوقع السائد في الصناعة أن تكلفة استنتاج النماذج الكبيرة ستتراجع بمعدل حوالي 50% سنويًا، لكن هذا التخفيض من DeepSeek أدى إلى انخفاض حاد غير خطي، وأجبر الصناعة بأكملها على الدخول في عصر تكلفة جديد تمامًا. نحن نرى أن هذا ليس نشاطًا تسويقيًا بسيطًا أو "حرب أسعار" قصيرة الأجل، بل هو نتيجة حتمية ناتجة عن تحسينات في البنية الأساسية للخوارزميات (مثل آلية الانتباه النادرة، وتطور هندسة MoE القصوى) بالإضافة إلى تحسين قدرات هندسة مجموعات الحوسبة. ستوفر هذه التقرير تحليلًا عميقًا للاضطرابات التي أحدثها تخفيض أسعار DeepSeek، استنادًا إلى أحدث بيانات الأسعار في جميع أنحاء الصناعة، ومقارنة أفقية للقدرة التنافسية التجارية للنماذج الكبيرة الرئيسية عالميًا، ومحاولة تقديم خريطة طريق واضحة للتطور الصناعي لصناع القرار.
الظاهرة الأساسية: اختراق حدود نظام الأسعار لسلسلة DeepSeek-V4
للفهم العميق لدرجة التخفيض، يجب علينا تحليل الأبعاد الثلاثة الأساسية لحساب تكلفة واجهات برمجة التطبيقات للنماذج الكبيرة: سعر الإدخال (غير مُخزَّن مؤقتًا)، سعر الإدخال (مُخزَّن مؤقتًا)، وسعر الإخراج. غالبًا ما كانت نماذج التسعير السابقة تفرق فقط بين الإدخال والإخراج، لكن مع نضج تقنية السياق الطويل (Long-Context)، فإن "معدل التخزين المؤقت الناجح (Cache Hit)" يصبح متغيرًا محوريًا يعيد تشكيل اقتصاديات واجهات برمجة التطبيقات.
تحليل استراتيجية التسعير: تراكب الخصومات ورفع التأثير المخزن
وفقًا لأحدث البيانات المنشورة، اتخذ DeepSeek استراتيجية ثلاثية تشمل "تخفيض الأسعار الأساسي + خصم لفترة محدودة + رافعة مالية مخزنة".
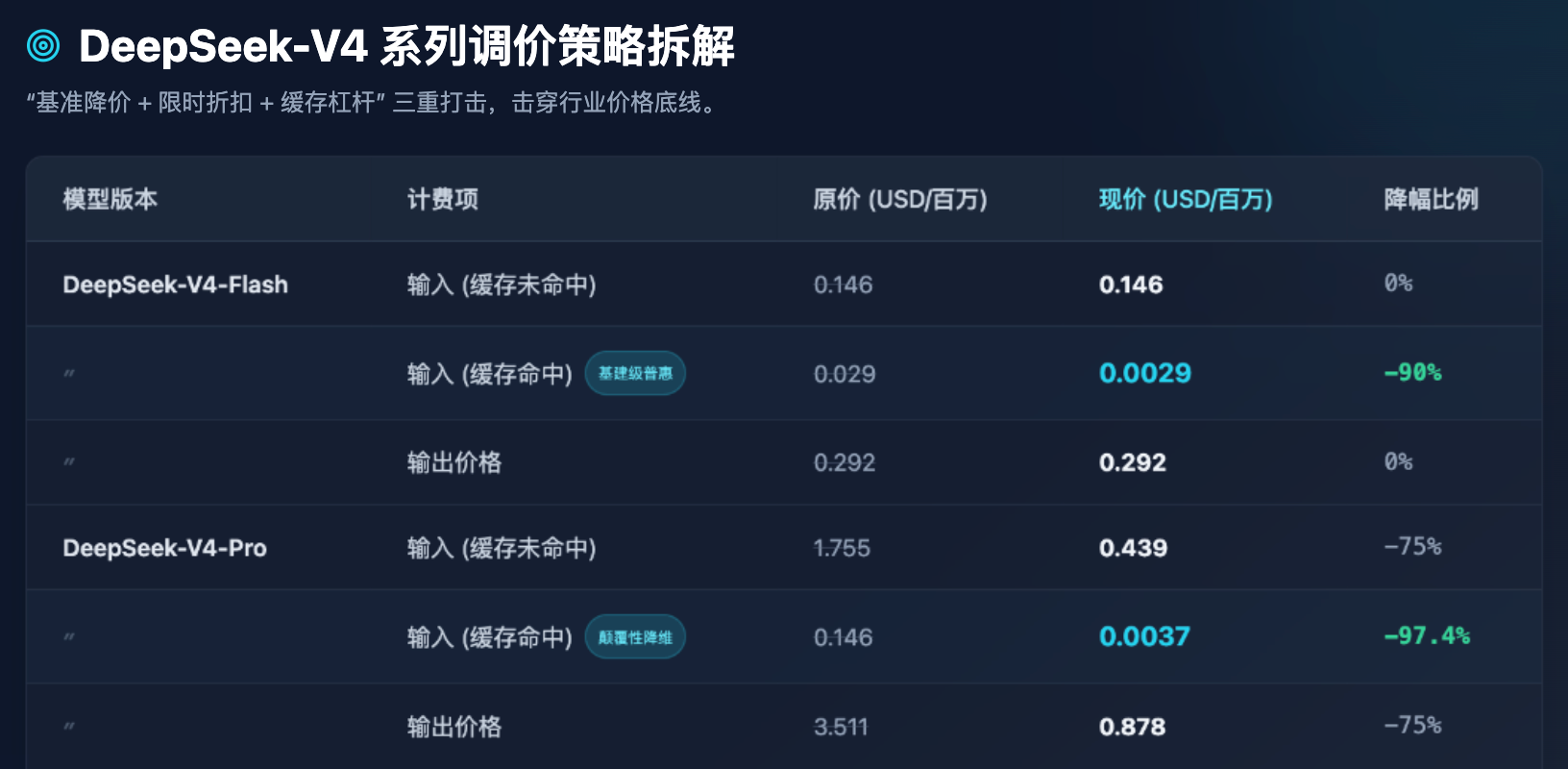
الجدول 1: مقارنة أسعار API الجديدة لسلسلة DeepSeek-V4 قبل وبعد التعديل (بالدولار الأمريكي لكل مليون رمز)
من الجدول 1، يمكننا استخلاص عدة ملاحظات صناعية واضحة جدًا:
أولاً، تمت تغطية تعميم نموذج Flash. بالنسبة للنماذج التي تركز على معالجة عالية التزامن وتأخير منخفض، يظل سعر الإخراج عند 0.292 دولار لكل مليون رمز، وهو ما يقترب بشدة من الحد الأدنى للتكلفة الصلبة لقوة الحوسبة الخادمة. لم يُجرِ DeepSeek أي تعديل على السعر الأساسي لنموذج Flash، بل قام بخفض سعر "الإيجابية في التخزين المؤقت" بنسبة 90%. هذا يعني أنه عند معالجة كميات كبيرة من تعليمات النظام المتكررة أو أسئلة وأجوبة المستندات الثابتة، يمكن تجاهل تكلفة نموذج Flash تقريبًا.
ثانيًا، التخفيض الهائل لنموذج Pro. كنموذج رائد يُقارن بأفضل الفئات العالمية (مثل مستوى GPT-5)، انخفض سعر إخراج V4-Pro من 3.511 دولار إلى 0.878 دولار. وأكثر من ذلك، فقد انخفض سعر الإدخال للذاكرة المؤقتة المُصابة من 0.146 دولار إلى 0.0037 دولار بعد تطبيق خصم زمني قدره 25% بالإضافة إلى تخفيض قدره 1/10. هذا رقم مخيف جدًا — مما يعني أن تكلفة استدعاء أذكى الذكاءات العالمية قد تم تقليلها إلى درجة يمكن للشركات الصغيرة والمتوسطة وحتى المطورين الأفراد استخدامها بحرية وبدون قيود على أساس متكرر.
ثالثًا، يُجبر هذا المطورين على تحسين هندسة الأوامر. بتحديد سعر الطلب المُخزّن مسبقًا كجزء صغير جدًا من سعر الطلب غير المُخزّن (على سبيل المثال، في نموذج Pro: 0.0037 دولار مقابل 0.439 دولار، أي فرق يقارب 118 مرة)، فهذا ليس مجرد استراتيجية تسعير، بل هو وسيلة تجارية لدفع النظام البيئي التقني للأمام. إن DeepSeek تُبلغ المطورين بوضوح: إذا قمتم بتصميم بنيتكم بشكل مناسب (على سبيل المثال، وضع السياق الطويل الثابت في المقدمة والأسئلة القصيرة المتغيرة في الخلف)، فستتمكنون من الاستفادة من قوة حوسبة الإدخال شبه المجانية.
مقارنة أفقية: الفجوة في التسعير بين النماذج الكبيرة العالمية والمحلية
لا يكفي مقارنة تخفيضات DeepSeek نفسها فقط من منظور رأسي لفهم الصورة الكاملة؛ عندما نضع هذه الاستراتيجية التسعيرية في سياق سوق النماذج الكبيرة العالمي لعام 2026، فإن الفجوة المطلقة التي تخلقها تصبح حقًا مخيفة.
بناءً على OpenRouter ومعلومات عامة من مختلف الجهات، قمنا بجمع أحدث أسعار واجهات برمجة التطبيقات (API) للتسعير لتسعة نماذج كبيرة محلية وعالمية تمثل السوق الحالي.

الجدول 2: مقارنة أسعار واجهات برمجة التطبيقات للنماذج الكبيرة الرائدة عالميًا في عام 2026 (بالدولار الأمريكي لكل مليون رمز)
المواجهة مع العمالقة العالميين: تفكيك أسطورة "الذكاء العالي والعلاوة العالية"
على مدار العامين الماضيين في سرد الذكاء الاصطناعي، حافظت OpenAI وAnthropic على تفاهم ضمني: أن أكثر النماذج ذكاءً يجب أن تستفيد من أعلى هوامش ربح إجمالية. حاليًا، تصل أسعار الإخراج لـ GPT-5.5 وClaude Opus 4.7 إلى 30 دولارًا و25 دولارًا لكل مليون رمز على التوالي. تحاول هاتان المجموعتان الرائدتان في سيليكون فالي الحفاظ على ضريبة حوسبة مرتفعة من خلال احتكار أقوى قدرات الاستدلال.
ومع ذلك، فإن ظهور DeepSeek-V4-Pro وسعر إخراجه البالغ 0.878 دولارًا قد كشف مباشرةً هذا الغطاء. افترض أن V4-Pro يمكنه تحقيق مستوى GPT-5.5 أو الاقتراب منه في جميع اختبارات الأداء الأساسية (Benchmarks) والتجارب العملية، فإن فرق السعر البالغ 34 ضعفًا بين المنتجين سيدمر تمامًا منطق التسعير العالي للشركات الكبرى في الأسواق التجارية.
حسب تقديرات "ME News智库"، بالنسبة لشركة ناشئة تعتمد بشدة على المحتوى المُنشأ بالذكاء الاصطناعي للتصدير، إذا استهلكت 1 مليار رمز في الشهر، فإن التكلفة الثابتة باستخدام GPT-5.5 تبلغ 30 ألف دولار أمريكي؛ بينما ستتراجع هذه التكلفة إلى 878 دولارًا أمريكيًا فقط عند التحول إلى DeepSeek-V4-Pro. هذا الفرق الهائل في التكلفة يمكنه أن يؤثر على بقاء شركة ناشئة أو إفلاسها. وهذا يدل على أن شركات الذكاء الاصطناعي الصينية قد سلكت مسارًا مختلفًا تمامًا عن سيليكون فالي، يجمع بين "الجمالية العنيفة" و"الهندسة القصوى" في كفاءة تدريب النماذج الأساسية وتحسين مجموعات الاستنتاج.
محاربة الزملاء المحليين: تسريع إعادة تشكيل الصناعة
إذا كان DeepSeek يُعد ضربة مُحَوِّلة للشركات الكبرى في الخارج، فإنه يُعد معركة صفرية قاسية للمنافسين المحليين.
من الجدول 2، يمكن ملاحظة أن الشركات الرائدة المحلية مثل Zhipu (GLM 5.1، الإخراج 4.4 دولارًا) وMoonshot (Kimi K2.6، الإخراج 4 دولارات) تواجه موقفًا محرجًا من حيث التسعير. كانت هذه الأسعار تُعتبر قبل بضعة أشهر "معقولة وذات قيمة جيدة"، لكنها فقدت فجأة جميع خطوط دفاعها السعرية أمام DeepSeek-V4-Pro (الإخراج 0.878 دولارًا). حتى Alibaba Cloud، التي كانت دائمًا معروفة بالانفتاح والأسعار المنخفضة (Qwen3.6 Plus، الإخراج 1.96 دولارًا)، باتت لا تبدو "رخيصة" بعد الآن.
وفي ساحة نماذج Flash الخفيفة، تتصاعد المعركة أيضًا بشراسة. فنموذج Step 3.5 Flash من Step Infinity يبلغ سعر الإدخال 0.028 دولارًا فقط وسعر الإخراج 0.299 دولارًا، وهو ما يتنافس بشكل شديد مع DeepSeek-V4-Flash (0.292 دولارًا للإخراج). وهذا يوضح أن ضغط تكاليف الحوسبة في مجال النماذج الخفيفة قد وصل إلى مستوى النانومتر، حيث تطير جميع الشركات على طول خط التكلفة.
بشكل عام، يستخدم DeepSeek قدرات من مستوى Pro لمنافسة أسعار المنافسين المحليين من مستوى Plus أو الإصدار القياسي، ويعتمد أسعارًا من مستوى Flash لاستيعاب جميع تدفقات الطيف الطويل ذات الكثافة المنخفضة للقيمة. إن هذه الاستراتيجية "القابضة من الطرفين" تضغط بشدة على مساحة بقاء شركات النماذج الكبيرة الأخرى، وسيتم تسريع سباق التصفية في مجال النماذج الكبيرة للذكاء الاصطناعي المحلي بعد هذه الخصومات.
نظرية عميقة: المنطق التقني والتجاري وراء الأسعار المنخفضة للغاية
الأسعار المنخفضة التي لا تستند إلى الأساسيات لا يمكن أن تستمر. إن سبب تمكّن DeepSeek من تطبيق استراتيجية تخفيض أسعار جذرية如此 في عام 2026 يكمن في دعم تقني عميق وخطة تجارية طموحة للغاية.
المنطق التقني: من "القوة تُطير الطوب" إلى "الهندسة تحقق النصر"
الانخفاض الحاد في السعر هو في جوهره إطلاق مكاسب التطور المعماري التقني.
- الربح العميق لهيكل MoE (المختلط من الخبراء): على عكس النماذج الكثيفة الضخمة المبكرة من OpenAI، فإن النماذج المتقدمة الحالية تستخدم على نطاق واسع هيكل MoE عالي التحسين. من المرجح جدًا أن DeepSeek قلّل من نسبة المعلمات المُفعّلة في هيكل V4. هذا يعني أنه حتى مع كون إجمالي عدد المعلمات كبيرًا، إلا أنه في كل استدلال، يتم تفعيل عدد قليل جدًا من "الخبراء" فقط، مما يقلل بشكل كبير من كمية الحسابات (FLOPs) وضغط عرض النطاق الترددي للذاكرة العشوائية في كل استدعاء.
- ثورة في إدارة KV Cache: أبرز ميزة في هذا التعديل هي "انخفاض معدلات إصابة ذاكرة الإدخال إلى 1/10". في بنية Transformer، أكبر عقبة في الاستدلال على النصوص الطويلة ليست الحساب، بل استهلاك ذاكرة GPU من قبل KV Cache المخزنة لمعلومات السياق. من الواضح أن DeepSeek حققت على مستوى النظام تقنية تجميع KV Cache مشتركة عالميًا عبر الطلبات (مثل إصدار مُحسّن من تقنية RadixAttention). عندما تحتوي طلبات المستخدمين المتزامنة على إعدادات نظام أو قاعدة معرفة خلفية متطابقة، لا يحتاج النموذج إلى إعادة حساب هذه الرموز، بل يقرأها مباشرة من الذاكرة أو من حوض ذاكرة GPU موزع. وهذا يجعل التكلفة الحدية لإدخال النصوص الطويلة تقترب من الصفر.
المنطق التجاري: تبادل الربح مقابل المساحة، وإعادة تشكيل خندق الحماية البيئي
يعتقد "ME News智库" أن خطة DeepSeek للتخفيضات الزمنية وسعرها الأدنى تهدف إلى غرض تجاري واضح وحازم:
أولاً، دمر تمامًا نظام "الضبط الدقيق المُغلف"، مما يُجبر تطبيقات الذكاء الاصطناعي الأصلية على الازدهار. عندما تقترب تكلفة استدعاء نماذج أساسية قوية بشكل لا نهائي من الصفر، سيصبح من غير المنطقي اقتصاديًا للمبتكرين إنفاق مبالغ ضخمة على تدريب أو ضبط نماذج صغيرة خاصة بهم في قطاعاتهم. من خلال الأسعار المنخفضة، تحاول DeepSeek جذب جميع مطوري الذكاء الاصطناعي في المجتمع كله إلى نظامها البيئي للواجهات البرمجية، لتصبح مثل أمازون AWS ومايكروسوفت Azure: "الكهرباء والماء والغاز الأساسيين في عصر الذكاء الاصطناعي".
ثانيًا، شروق عصر انفجار وكيل المواقع. تتطلب التطبيقات الحقيقية القائمة على الوكلاء من النموذج إجراء عدد كبير من التفكير الذاتي، والتأمل، والتخطيط، واستدعاء دورات متعددة (Loop). خلال هذه العملية، يتم استهلاك كمية هائلة من الرموز الضمنية. إن تكلفة واجهات برمجة التطبيقات المرتفعة هي أكبر عقبة أمام انتشار الوكلاء. من خلال خفض سعر الوصول إلى المخزن المؤقت إلى 0.0037 دولار، فإن DeepSeek تقدم قابلية اقتصادية لـ "جعل الذكاء الاصطناعي يجري عشرة آلاف دورة". من يقدم أقل تكلفة تجريبية، سيُنبت أروع التطبيقات الفائقة الأصلية القائمة على الذكاء الاصطناعي.
التأثير الصناعي وتقييم الاتجاهات: من "حرب النماذج" إلى "حرب النظام البيئي"
لعرض تأثير هذا التغير في السعر على قرارات الأعمال بشكل أكثر وضوحًا، أجرينا محاكاة تكلفة تطبيق مؤسسي.
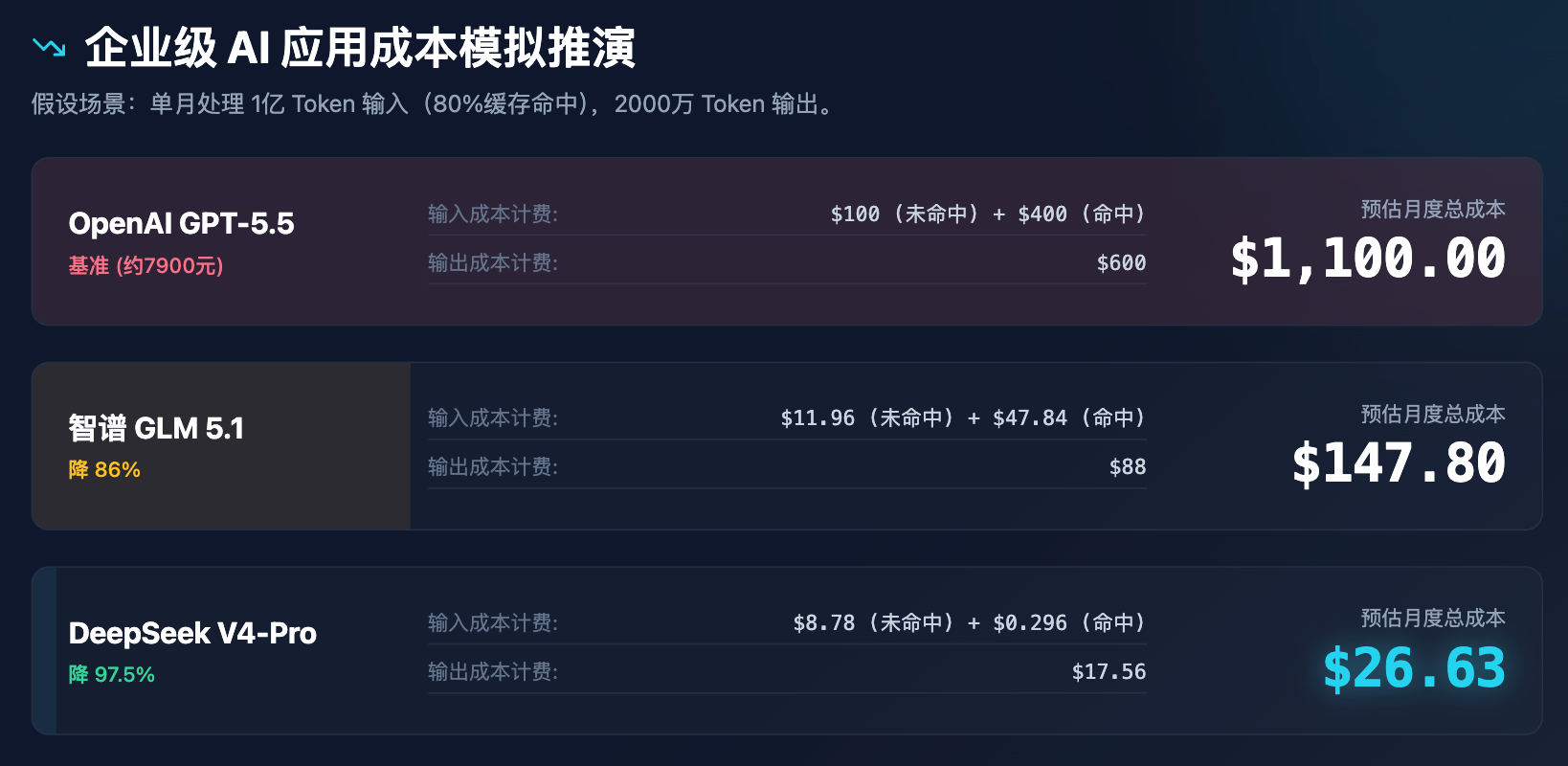
الجدول 3: تحليل محاكاة تكلفة تطبيقات الذكاء الاصطناعي المؤسسية (بافتراض معالجة 100 مليون رمز إدخال و20 مليون رمز إخراج شهريًا)
من خلال المحاكاة المذكورة أعلاه، من الواضح أن تسعير DeepSeek ليس مجرد خصم، بل هو إعادة هيكلة لنموذج التكلفة. فبتكلفة أقل من 30 دولارًا شهريًا، يمكن تلبية جميع احتياجات دعم الخدمة، وتحليل المستندات، وفحص التعليمات البرمجية لشركة متوسطة الحجم، مما سيُحدث سلسلة من التفاعلات المتسلسلة:
- التحول الجوهري في منطق الاستثمار في الذكاء الاصطناعي: سيفقد رأس المال اهتمامه تمامًا بـ"إعادة إنشاء نموذج كبير عام". تم إغلاق الباب أمام النماذج الأساسية العامة، باستثناء عدد قليل جدًا من فرق الدولة أو شركات الإنترنت الكبرى. سيتدفق الاستثمار مستقبلًا بشكل شامل نحو طبقة التطبيقات (Application Layer) والبرمجيات الوسيطة للبنية التحتية (أجهزة توجيه البنية التحتية، بوابات الذكاء الاصطناعي، إلخ).
- أصبحت استراتيجية توجيه النماذج المتعددة (LLM Routing) معيارًا: لم تعد الشركات تركز على نموذج واحد فقط. سيقوم النظام تلقائيًا بتوزيع المهام وفقًا لتعقيدها. على سبيل المثال، يتم تفويض 90٪ من تنظيف البيانات اليومي والتصنيف البسيط إلى DeepSeek-V4-Flash أو Step 3.5 Flash لإنجازها بتكلفة منخفضة جدًا؛ بينما يتم استدعاء DeepSeek-V4-Pro أو GPT-5.5 حسب الحاجة لمعالجة 10٪ من الاستدلالات المنطقية المعقدة وإنشاء تقارير الإدارة العليا.
- تطبيقات النصوص الطويلة تصل إلى نقطة تحول تجارية حقيقية: قبل هذا، كان "رفع تقارير مالية بملايين الكلمات للاستخلاص بواسطة الذكاء الاصطناعي" يبدو رائعًا، لكن تكلفة واجهة برمجة التطبيقات التي تصل عادةً إلى بضعة دولارات كل مرة كانت تثني الشركات عن استخدامها. مع انخفاض سعر إصابة ذاكرة التخزين المؤقت للإدخال إلى مستوى 0.02 يوان صيني لكل مليون رمز، سيصبح "قراءة مستندات المكتبة الكاملة والتفاعل في الوقت الفعلي" ميزة قياسية في جميع برامج OA وERP الخاصة بالشركات.
الاستنتاج والتوصيات الاستراتيجية
تشكل عاصفة التخفيضات في أبريل 2026 علامة فارقة على انتهاء الفترة الكلاسيكية الرومانسية في صناعة النماذج الكبيرة، التي كانت تتمحور حول "التنافس على المعلمات وعرض الأداء"، ودخولها عصرًا صناعيًا قاسيًا يركز على "التنافس على التكاليف، والاستحواذ على قوة الحوسبة، واحتلال النظام البيئي". من خلال استراتيجية التسعير التي تمارس ضغطًا شديدًا، أظهر DeepSeek ليس فقط براعة الشركات الصينية في الذكاء الاصطناعي في هندسة النماذج على المستوى العالمي، بل قام أيضًا بخرق متعمد لفقاعة التسعير المبالغ فيها لقوة الحوسبة في الذكاء الاصطناعي.
لهذا، لدى "ME News智库" ثلاث توصيات:
- لمطوري الطبقة التطبيقية: تخلَّ عن خوفك من تكلفة استدعاء النماذج الكبيرة. أوقف فورًا بناء النماذج الأساسية ذات أقل من مئة مليار معلمة وضبطها، وحوِّل جميع موارد البحث والتطوير نحو تحسين تجربة المنتج، وتوافق الطرف النهائي، وبناء حواجز بيانات خاصة، وصقل سير عمل الوكلاء. استغل هذه الموجة من "الحوسبة الذكية الرخيصة" للاستيلاء السريع على السيناريوهات.
- لـ CIO/CTO في الشركات التقليدية: أعد تقييم استراتيجية تحول شركتك إلى الذكاء الاصطناعي. لقد أصبحت مشاريع مثل أسئلة وأجوبة قاعدة المعرفة، والدعم الآلي، ومساعد الكود Copilot، التي تم تأجيلها سابقًا بسبب الاعتبارات التكلفة، الآن تتمتع بعائد استثماري عالٍ جدًا بأسعار واجهات برمجة التطبيقات الحالية. يُوصى بتبني منصات LLMOps ناضجة وإنشاء بوابة ذكاء اصطناعي على مستوى المؤسسة للسماح بالوصول المرن إلى النماذج الأكثر فعالية من حيث التكلفة حاليًا.
- للمنافسين في النماذج الأساسية: يجب التخلي عن استراتيجية المتابعة. أمام حرب الأسعار، إما أن تخفض التكلفة بشكل أكبر من خلال تحسين متكامل متطرف بين الرقائق والإطار، أو أن تبني حواجز تقنية لا يمكن الاستعاضة عنها في مجالات متميزة مثل الذكاء المتجسد، والنمذجة متعددة الوسائط الأصلية (إنشاء الفيديو/3D)، والاستدلال العميق في الصناعات الرأسية. لقد أصبح النموذج اللغوي الكبير البحت متوسطًا ولا يوجد مستقبل له.
لم تعد النماذج الكبيرة آلهة مُعَبَّدة في المختبرات، بل إنها تنحدر من عرشها بسرعة غير مسبوقة، لتصبح تيارًا هائلاً يدفع الذكاء في كل شيء. وكل هذا، لم يبدأ بعد.
المصدر:
- OpenRouter. (2026). قاعدة بيانات مقارنة أسعار واجهة برمجة التطبيقات.
- الإعلان الرسمي من DeepSeek. (2026، أبريل 25). خطة العرض المحدودة لـ DeepSeek-V4-Pro API.
- الإعلان الرسمي من DeepSeek. (2026، أبريل 26). الحوسبة الشاملة في عصر النماذج الكبيرة: خطة تعديل أسعار تحقق ذاكرة التخزين المؤقت للواجهة البرمجية.