










الكاتب الأصلي: KarenZ، Foresight News
في 20 مارس 2026، كانت هناك محادثة غير عادية في بودكاست All-In Ventures.
قام المستثمر المغامر تشاماث باليهابيتيا بتسليم الكلمة إلى الرئيس التنفيذي لشركة نيفيديا، هوانغ رينشون، قائلاً إن هناك مشروعًا على Bittensor "أنجز إنجازًا تقنيًا مجنونًا تمامًا"، حيث تم تدريب نموذج لغوي كبير على الإنترنت باستخدام قوة حوسبة موزعة، وبطريقة تمامًا لامركزية، دون أي مراكز بيانات مركزية.
لم يتجنّب هواينغ رينشون. فقد قارن هذا الأمر بإصدار حديث من "Folding@home"، وهو مشروع توزيعي في عقد 2000 سمح للمستخدمين العاديين بالتبرع بقوة الحوسبة غير المستخدمة للتعاون في مواجهة تحدي طي البروتينات.
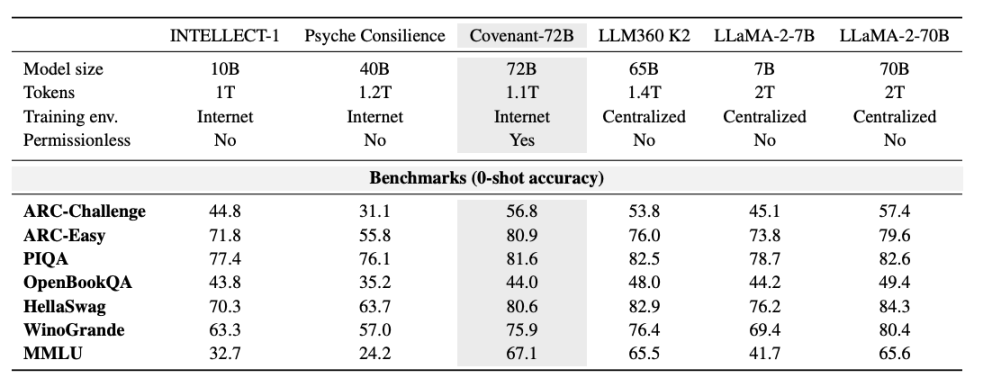
قبل أربعة أيام، في 16 مارس، استخدم جاك كلارك، المؤسس المشارك في Anthropic، قسمًا كبيرًا من تقريره عن تقدم أبحاث الذكاء الاصطناعي لتسليط الضوء على هذا الإنجاز واستشهادات به: اكتمل التدريب الموزع للنموذج الكبير ذو 72 مليار معلمة (Covenant 72B) في شبكة فرعية لبيتنتانسور Templar (SN3)، وأداء النموذج يعادل أداء LLaMA-2 الذي أصدرته Meta في عام 2023.
سمى جاك كلارك هذا الفصل "تحدي السياسة الاقتصادية للذكاء الاصطناعي من خلال التدريب الموزع"، وشدد في تحليله على أن هذه تقنية تستحق المتابعة المستمرة—فهو يستطيع تصور مستقبل حيث يتم اعتماد نماذج تدريب موزعة على نطاق واسع على الأجهزة، بينما تستمر نماذج الذكاء الاصطناعي السحابية في تشغيل النماذج الكبيرة الحصرية.
رد السوق كان متأخرًا قليلاً لكنه شديد للغاية: ارتفع SN3 بنسبة تزيد عن 440% خلال الشهر الماضي، وبنسبة تزيد عن 340% خلال الأسبوعين الماضيين، ليصل إلى رأس مال سوقي قدره 130 مليون دولار. انفجار سردية الشبكة الفرعية سيُنقل مباشرةً إلى ضغط شراء على TAO. وبالتالي، ارتفع TAO بسرعة، ووصل إلى 377 دولارًا في ذروته، ومضى في الارتفاع مرتين خلال الشهر الماضي، ليصل FDV إلى حوالي 7.5 مليار دولار.
السؤال الآن: ماذا فعلت SN3؟ ولماذا تم إبرازها في مركز الأضواء؟ وكيف ستتطور سردية القيمة للتدريب الموزع والذكاء الاصطناعي اللامركزي؟
ذلك النموذج بحجم 72B
للإجابة على هذا السؤال، يجب أولاً مراجعة النتائج التي قدمها SN3.
في 10 مارس 2026، نشر فريق Covenant AI تقريرًا تقنيًا على arXiv، وأعلن رسميًا اكتمال تدريب Covenant-72B. هذا نموذج لغوي ضخم يحتوي على 72 مليار معلمة، تم تدريبه على حوالي 1.1 تريليون رمز على أكثر من 70 عقدًا مستقلة (حوالي 20 عقدة مزامنة في كل دورة، وكل عقدة مجهزة بـ 8 وحدات B200).
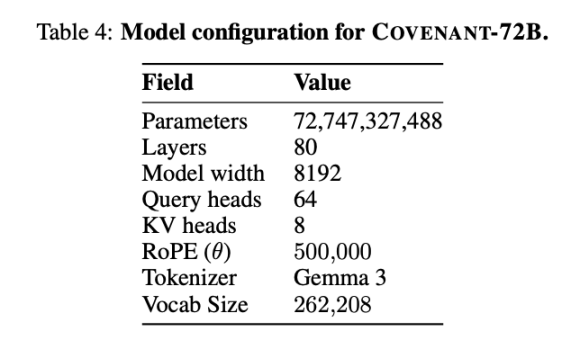
قدم Templar بعض البيانات المتعلقة بالاختبارات المرجعية، مع مقارنة نموذج LLaMA-2-70B الذي أصدرته Meta في عام 2023. كما قال جاك كلارك، المؤسس المشارك لشركة Anthropic، فقد يكون Covenant-72B قديمًا بعض الشيء بحلول عام 2026. درجة Covenant-72B البالغة 67.1 في MMLU تقابل تقريبًا درجة نموذج LLaMA-2-70B الذي أصدرته Meta في عام 2023 (65.6).
بينما تم تدريب النماذج المتقدمة لعام 2026 — سواءً من سلسلة GPT أو Claude أو Gemini — بالفعل على مئات الآلاف من وحدات GPU، بكمية معلمات تتجاوز بكثير 100 مليار، فإن الفجوة في القدرة على الاستدلال والبرمجة والرياضيات هي فجوة من رتبة مختلفة، وليست فجوة نسبية. لا ينبغي أن تُطمس هذه الفجوة الواقعية بسبب مشاعر السوق.
لكن عند تحويله إلى الافتراض المتمثل في "التدريب باستخدام قوة الحوسبة الموزعة على الإنترنت المفتوح"، فإن المعنى يختلف تمامًا.
قارن: INTELLECT-1 (من فريق Prime Intellect، 10 مليارات معلمة) حصل على درجة MMLU قدرها 32.7، بينما حقق مشروع التدريب الموزع الآخر Psyche Consilience (40 مليار معلمة) الذي تم تدريبه بين المشاركين المدرجين في القائمة البيضاء درجة MMLU قدرها 24.2. يُعد Covenant-72B بحجم 72 مليار ومعدل MMLU قدره 67.1 رقمًا بارزًا في مسار التدريب اللامركزي.
الأهم من ذلك، أن هذه التدريبات هي "بدون إذن". يمكن لأي شخص الاتصال كعقدة مشاركة دون مراجعة مسبقة أو قائمة بيضاء. شارك أكثر من 70 عقدة مستقلة في تحديث النموذج، حيث قدمت قوة حوسبة من جميع أنحاء العالم.
ماذا قال هوانغ رينشون، وماذا لم يقل
استعادة تفاصيل حوار البودكاست ستساعد في تصحيح التفسيرات الخارجية لهذه "التأييد".
عرض تشاماث باليهابيتيا إنجازات Bittensor التقنية على هوانغ رينشون ووصفها بأنها تدريب نموذج Llama باستخدام قوة حوسبة موزعة، مع الحفاظ على الحالة "بشكل موزع بالكامل وفي نفس الوقت". وكان رد هوانغ رينشون مقارنة ذلك بـ"نسخة حديثة من Folding@home"، وتوسع في مناقشة ضرورة التوازي بين النماذج المفتوحة المصدر والنماذج الحصرية.
تجدر الإشارة إلى أن هوانغ رينشون لم يذكر صراحةً رمز Bittensor أو أي تأثير استثماري، ولم يتناول بشكل إضافي تدريب الذكاء الاصطناعي اللامركزي.
فهم شبكات Bittensor و SN3
لفهم اختراق SN3، يجب أولاً فهم منطق عمل Bittensor وشبكاته الفرعية. باختصار، يمكن اعتبار Bittensor سلسلة عامة ومنصة للذكاء الاصطناعي، وكل شبكة فرعية تمثل "خط إنتاج ذكاء اصطناعي" مستقلًا، لكل منها مهمة مركزية محددة وآلية تحفيز مصممة خصيصًا، وتعمل معًا لتشكيل نظام بيئي للذكاء الاصطناعي لامركزي.
عملية تشغيلها واضحة ولامركزية: يحدد مالكو الشبكات الفرعية أهداف الشبكات الفرعية وينشئون نماذج الحوافز؛ يقدم العاملون حسابات في الشبكات الفرعية ويؤدون مهام مرتبطة بالذكاء الاصطناعي (مثل الاستنتاج، التدريب، التخزين، إلخ)؛ يقوم المحققون بتقييم مساهمات العاملين ورفع التقييمات إلى طبقة توافق Bittensor؛ في النهاية، يوزع خوارزمية توافق Yuma في Bittensor المكافآت المتراكمة لكل شبكة فرعية على المشاركين في الشبكة الفرعية وفقًا لذلك.
يوجد حاليًا 128 شبكة فرعية على Bittensor، تغطي مهام ذكاء اصطناعي متنوعة مثل الاستدلال، وخدمات سحابية لذكاء اصطناعي بدون خوادم، والصور، ووضع العلامات على البيانات، والتعلم المعزز، والتخزين، والحاسوب.
وSN3 هو أحد الشبكات الفرعية. فهو لا يُطبّق طبقة تطبيقية، ولا يستأجر واجهات برمجة تطبيقات نماذج كبيرة جاهزة، بل يركّز مباشرة على أحد أكثر المراحل تكلفةً وإغلاقًا في سلسلة صناعة الذكاء الاصطناعي: التدريب المسبق للنماذج الكبيرة نفسها.
تسعى SN3 إلى استخدام شبكة Bittensor لتنسيق تدريب موزع على موارد حوسبة متنوعة، من خلال التدريب الموزع المحفز للنماذج الكبيرة، لإثبات أنه يمكن تدريب نماذج أساسية قوية دون الحاجة إلى مجموعات مركزة باهظة الثمن من الحواسيب الفائقة. يكمن جاذبيتها الأساسية في "المساواة" — كسر احتكار الموارد في التدريب المركزي، وتمكين الأفراد العاديين أو المؤسسات الصغيرة والمتوسطة من المشاركة في تدريب النماذج الكبيرة، مع خفض تكلفة التدريب من خلال استخدام قوة حوسبة موزعة.
القوة المحركة لتطوير SN3 هي Templar، وفريق البحث خلفها هو Covenant Labs. يدير الفريق أيضًا شبكتين فرعيتين أخريين: Basilica (SN39)، المتخصصة في خدمات الحوسبة، وGrail (SN81)، المتخصصة في التدريب بعد التدريب وتقديم النماذج بالتعلم المعزز. تشكل الشبكات الثلاثة تكاملًا عموديًا يغطي بالكامل دورة حياة النماذج الكبيرة من التدريب المبدئي إلى تحسين التوافق، مُشكّلةً بذلك نظامًا بيئيًا متكاملًا للتدريب اللامركزي للنماذج الكبيرة.
على وجه التحديد، يساهم عمال المناجم بموارد الحوسبة لرفع تحديثات التدرج (اتجاه وشدة تعديل معلمات النموذج) إلى الشبكة؛ ويقيم المحققون جودة مساهمة كل عامل منجم، ويعطون تقييمًا على السلسلة بناءً على مدى تحسن الخطأ. وتحدد النتائج وزن المكافآت، التي تُوزع تلقائيًا دون الحاجة إلى الثقة بأي طرف ثالث.
المفتاح في تصميم آلية التحفيز هو ربط المكافآت مباشرة بـ "كمية تحسين النموذج التي حققتها"، وليس فقط بوجود قوة الحوسبة. وهذا يحل جذريًا أصعب مشكلة في السيناريوهات اللامركزية: كيفية منع عمال المناجم من التهرب من العمل.
كيف يحل Covenant-72B مشكلتي كفاءة الاتصال والتوافق الحافزي؟
تشجيع عشرات العقد غير الموثوقة، ذات الأجهزة المتنوعة، ونوعية الشبكة المتغيرة على تدريب نموذج واحد مشترك، يواجه تحديين: أولًا، كفاءة الاتصال، حيث تتطلب حلول التدريب الموزع القياسية اتصالًا عالي السعة ومنخفض التأخير بين العقد؛ ثانيًا، التوافق الحافزي، كيف يمكن منع العقد الخبيثة من إرسال تدرجات خاطئة؟ وكيف يمكن ضمان أن كل مشارك يتدرب بصدق، وليس فقط انتحال نتائج الآخرين؟
حلت SN3 هاتين المشكلتين باستخدام مكونين أساسيين: SparseLoCo و Gauntlet.
SparseLoCo يحل مشكلة كفاءة الاتصال. في التدريب الموزع التقليدي، يجب مزامنة جميع التدرجات في كل خطوة، مما ينتج كميات هائلة من البيانات. يعتمد SparseLoCo على نهج يُجري كل عقدة 30 خطوة من التحسين المحلي (AdamW)، ثم يُضغِط "التدرجات الزائفة" الناتجة قبل رفعها إلى العقد الأخرى. تشمل طرق الضغط التخفيف القائم على Top-k (الاحتفاظ فقط بمركّزات التدرج الأكثر أهمية)، تغذية الخطأ (تخزين الأجزاء المُستبعدة وجمعها للدورة التالية)، وكمية بتين. في النهاية، يتجاوز معدل الضغط 146 ضعفًا.
بعبارة أخرى، ما كان يتطلب نقل 100 ميغابايت، يكفي الآن أقل من 1 ميغابايت.
هذا يسمح للنظام بالحفاظ على استخدام الحوسبة عند حوالي 94.5% تحت قيود عرض النطاق الترددي للإنترنت العادي (110 ميجابت/ثانية صعودًا، 500 ميجابت/ثانية هبوطًا) — مع 20 عقدة، وكل عقدة تحتوي على 8 وحدات B200، وتستغرق كل جولة اتصال فقط 70 ثانية.
Gauntlet تحل مشكلة التوافق الحافز. تعمل على سلسلة بيتينتور (Subnet 3) وتُشرف على التحقق من جودة التدرجات الزائفة المقدمة من كل عقدة. يتم ذلك من خلال اختبار مجموعة صغيرة من البيانات لقياس "كمية تقليل خسارة النموذج عند استخدام تدرج هذه العقدة"، وتُسمى النتيجة LossScore. كما يتحقق النظام مما إذا كانت العقدة تتدرب على البيانات المخصصة لها — إذا كانت تحسين الخسارة على بيانات عشوائية أفضل من تحسينها على بياناتها المخصصة، فستحصل على درجة سلبية.
في النهاية، يتم اختيار تدرجات العقد ذات التقييم الأعلى فقط للمشاركة في التجميع في كل دورة تدريبية، بينما يتم استبعاد العقد الأخرى من هذه الدورة. يتم استبدال المشاركين الزائدين في أي وقت لضمان استقرار النظام. خلال عملية التدريب بأكملها، تم تضمين تدرجات ما متوسطه 16.9 عقدة في التجميع في كل دورة، مع تجاوز عدد معرفات العقد الفريدة التي شاركت في التدريب 70 معرفًا.
سرد القيمة الخاص بالذكاء الاصطناعي اللامركزي يمر بتحول جوهري
من منظور تقني وصناعي، فإن الاتجاه الذي يمثله Covenant-72B له عدة معاني حقيقية.
أولاً، كسر الافتراض القائل بأن التدريب الموزع مناسب فقط للنماذج الصغيرة. على الرغم من أن هناك فجوة كبيرة ما زالت موجودة مقارنة بالنماذج الرائدة، إلا أنه أثبت قابلية التوسع في هذا الاتجاه.
ثانيًا، المشاركة بدون إذن هي ممكنة وواقعية. هذه النقطة مُهملة. كانت مشاريع التدريب الموزعة السابقة تعتمد على قائمة بيضاء — فقط المشاركون المعتمدون يمكنهم المساهمة بالقوة الحسابية. في تدريب SN3 هذا، يمكن لأي شخص يمتلك قوة حسابية كافية الاتصال، بينما تتحمل آلية التحقق مسؤولية تصفية المساهمات الضارة. هذه خطوة ملموسة نحو "اللامركزية الحقيقية".
ثالثًا، تتيح آلية dTAO في Bittensor اكتشاف قيمة الشبكات الفرعية في السوق. تسمح dTAO لكل شبكة فرعية بإصدار رمز Alpha الخاص بها، وتمكّن السوق من تحديد أي الشبكات الفرعية تحصل على المزيد من توزيعات TAO من خلال آلية AMM. وهذا يوفر آلية خشنة ولكن فعالة لاكتساب القيمة للشبكات الفرعية التي أنتجت نتائج ملموسة، مثل SN3. بالطبع، هذه الآلية عرضة أيضًا للتلاعب من خلال السرديات والعواطف، حيث يصعب على المشاركين العاديين في السوق تقييم جودة نتائج تدريب نماذج الذكاء الاصطناعي بشكل مستقل.
رابعًا، الدلالات السياسية والاقتصادية للتدريب الموزع للذكاء الاصطناعي. رفع جاك كلارك في Import AI هذه المسألة إلى مستوى "من يملك مستقبل الذكاء الاصطناعي؟". حاليًا، يتم احتكار تدريب النماذج المتقدمة من قبل عدد قليل من المؤسسات التي تمتلك مراكز بيانات ضخمة، وهذا ليس مجرد مشكلة تجارية، بل هو أيضًا مسألة هيكلية للسلطة. إذا استطاع التدريب الموزع تحقيق تقدم تقني مستمر، فقد يُشكّل في بعض أنواع النماذج (مثل النماذج الصغيرة المتقدمة في مجالات محددة) نظامًا تطويريًا موزعًا حقًا. بالطبع، هذا الأفق لا يزال بعيدًا حاليًا.
ملخص: إنجاز حقيقي، بالإضافة إلى مجموعة من المشكلات الحقيقية
قال هواينغ رينشون إن هذا يشبه "نسخة حديثة من Folding@home". لقد قدم Folding@home مساهمات حقيقية في مجال محاكاة الجزيئات، لكنه لم يهدد المراكز الأساسية للبحث والتطوير لدى شركات الأدوية الكبرى. هذا التشبيه دقيق جدًا.
تم تشغيل SN3 وتم التحقق من الاتجاهات الممكنة للتدريب الموزع. لكن من منظور تقني وصناعي، فإن هذه النتائج التي قدمتها خلفها مجموعة من المشكلات التي نادرًا ما يرغب أحد في مناقشتها بجدية:
MMLU هو مؤشر مثير للجدل في الأوساط الأكاديمية، حيث توجد مخاطر تسريب أسئلة وحلول المعايير العامة إلى مجموعات التدريب. والأكثر أهمية هو اختيار خط الأساس المقارن: فالنماذج التي تم مقارنتها بها في الورقة، LLaMA-2-70B وLLM360 K2، هي نماذج قديمة من عامي 2023 إلى 2024، بينما تُصنف الدرجات بين 65 و70 في نفس الفترة على أنها من المستوى المتوسط السفلي والمبتدئ عند مقارنتها مع Grok وBaidu Wenxin، وتُعتبر متخلفة بشدة وفقًا لـ Claude. إذا تم وضعها على قوائم محدثة ديناميكيًا أو على معايير جديدة مصممة لمقاومة التلوث، فقد تكون النتائج أكثر صدقًا.
الأهم من ذلك، البيانات عالية الجودة التي تحدد حدود قدرة النموذج—مثل بيانات المحادثات، والكود، والاستنتاجات الرياضية، والأوراق العلمية—من المرجح أن تكون بيد الشركات الكبرى، ومؤسسات النشر، وقواعد البيانات الأكاديمية. لقد أصبحت قوة الحوسبة ديمقراطية، لكن جانب البيانات لا يزال هيمنة أحادية، وهذه المفارقة لم تُناقش قط.
بالنسبة للأمان، فإن المشاركة بدون ترخيص تعني أنك لا تعرف من وراء تلك الـ70 عقدًا أو ما البيانات التي يستخدمونها للتدريب. يمكن لـ Gauntlet تصفية التدرجات الواضحة غير الطبيعية، لكنه لا يستطيع منع التسميم الدقيق للبيانات — إذا قام عقد ما بتدريب نظامي على أنواع معينة من المحتوى الضار لبضع دورات إضافية، فإن التغيرات في التدرج ستكون دقيقة بما يكفي لتجاوز فحص درجات الخسارة، لكنها تسبب انحرافًا تراكميًا في سلوك النموذج. السؤال النهائي هو: ما المخاطر المرتبطة باستخدام نموذج تم تدريبه بواسطة عدد قليل من العقد المجهولة المصدر، مع مصادر بيانات غير قابلة للتتبع، في سيناريوهات تتطلب امتثالًا وأمانًا عاليين مثل المالية والرعاية الصحية والقانون؟
هناك مشكلة هيكلية أخرى تستحق التصريح بها بصراحة: يُفتح Covenant-72B بموجب ترخيص Apache 2.0 ولا يستخدم رمز SN3. حيازة رمز SN3 تعني مشاركة العوائد الناتجة عن انبعاثات الشبكة الناتجة عن إنتاج نماذج جديدة مستقبلية من هذا الشبكة الفرعية، وليس أي عوائد مباشرة من استخدام النموذج. تعتمد هذه السلسلة القيمية على الإنتاج المستمر للتدريب، وعلى سير آلية انبعاثات شبكة Bittensor بشكل صحي. إذا توقف التدريب في المستقبل، أو لم تحقق نتائج التدريب الجديدة الجودة المتوقعة، فستضعف منطق تقييم الرمز.
Listing these issues is not meant to negate the significance of Covenant-72B. The fact that it proved something previously thought impossible is achievable will not disappear. But achieving it and what it means are two different things.
ارتفع رمز SN3 بنسبة 440% خلال الشهر الماضي. قد لا يكون هذا الفرق مجرد تضخيم، بل نتيجة سرعة السرد الأسرع من سرعة الواقع. ويعتمد ما إذا كان هذا الفرق سيُملأه الواقع في النهاية أو سيُمتصه السوق عبر تصحيحه، على ما يقدمه فريق Covenant AI في الخطوات القادمة.
يُجدر التنبه إلى أن Grayscale قد قدمت طلبًا لصندوق تداول منفصل لـ TAO في يناير 2026، وهو ما يشير إلى إشارة دخول رؤوس الأموال المؤسسية إلى هذا القطاع. بالإضافة إلى ذلك، سيتم تخفيض إصدار TAO اليومي إلى النصف في ديسمبر 2025، مما يُواصل تعميق التقييد الهيكلي على جانب العرض.
رابط المرجع:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95