









بينما لا يزال الأشخاص العاديون يدرسون "أقوى عبارات التوجيه السحرية"، حولت المختبرات الرائدة في سيليكون فالي بنية الذكاء الاصطناعي الأساسية إلى خط إنتاج.
مؤلف المقال، المصدر: جديد الذكاء
هل ما زلت تعيد تعديل الـ prompt في مربع دردشة ChatGPT؟
في الآونة الأخيرة، نشر مستخدم على X تغريدة بدأت بصرخة: تسريب قالب مشروع Claude Code الذي تستخدمه الشركات الكبرى سراً!
هذا لم يعد مجرد كتابة تعليمات برمجية. هذا بنية تحتية للهندسة الخاصة بالذكاء الاصطناعي.

يدور أسلوب اللعب الكامل حول ملف واحد "CLAUDE.md"، ومبادئه الأساسية فقط ثلاثة:
كلما ارتكب كلاود خطأً → تضيف قاعدة جديدة؛ كلما كررت نفسك → تضيف سير عمل؛ كلما ظهر خطأ → تضيف حماية.

هذا يهدف إلى ترسيخ تجربة المشروع كسياق طويل الأمد وقيود تلقائية يتم قراءتها عند كل تشغيل.
الهيكل الكامل، كأنه هيكل وظيفي لشركة ذكاء اصطناعي: CLAUDE.md هو دليل التوظيف، وskills/ هي إجراءات العمل القياسية، وhooks/ هي قسم الامتثال، وdocs/ هي النظام الأساسي للشركة، وtools/ هي فريق الدعم اللوجستي، وsrc/ هي قسم الأعمال الحقيقي الذي يُنفّذ العمل.

أنت لست تتحدث مع ذكاء اصطناعي، بل تبني ذكاءً اصطناعيًا يفهم مستودع كودك.
أغرب جزء هو أنك تحتاج فقط إلى التهيئة مرة واحدة، وسيقوم Claude تلقائيًا بمراجعة الكود، وإعادة هيكلته وفقًا للتعليمات، وفرض قواعد البنية، وكتابة ملاحظات الإصدار، وتشغيل سير العمل من المهارات، وتذكر الأخطاء السابقة، إلخ.
وسيصبح أكثر ذكاءً مع الاستخدام.
معظم الناس يفتحون ChatGPT، ويكتبون تعليمات، ثم ينسخون ولصقونها مرارًا وتكرارًا؛ لكن في هذا الأسلوب، ما عليك سوى فتح الطرفية وتشغيل كود مهارة تم تسليمه.
هذا يعادل توظيف فريق من الزملاء الذكاء الاصطناعي في مكتبة الكود الخاصة بك.
خلف هذا التغريدة، هناك إشارة صغيرة تشير إلى أن عصرًا ما يتحول بهدوء، وربما لم يدرك معظم الناس ذلك بعد.
لقطة شاشة "مُسربة" لا تُعد تسريبًا تكشف حقيقة
اللقطة التي نشرها @ai_rohitt هي النموذج القياسي الموصى به علنًا من قبل الوثائق الرسمية لـ Anthropic لـ Claude Code.
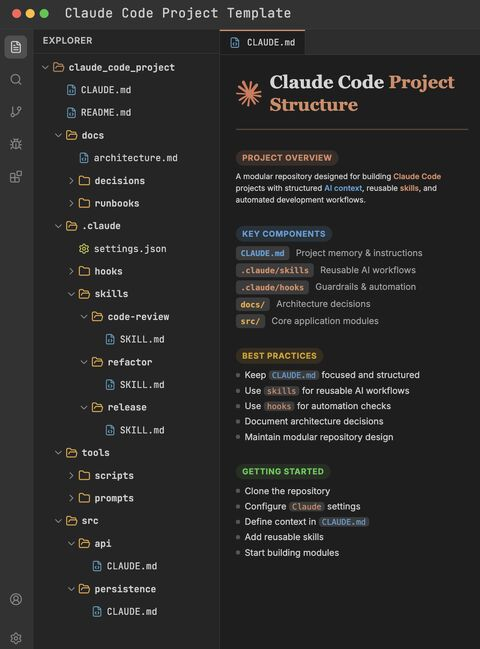
CLAUDE.md هو ملف ذاكرة المشروع الذي يقرأه Claude Code تلقائيًا عند بدء كل جلسة.
.claude/skills/ و .claude/hooks/ هما آليات توسيع مدعومة رسمياً.
هذه ممارسات عامة تم مناقشتها من قبل المجتمع لعدة أشهر، وليست أي "قالب داخلي" تم سرقته من أحد.
لكن كونه أثار مشاركة نشطة من بعض المطورين المتمرسين، فهذا يدل على تأييدهم من قبل مطورين يستخدمون Claude يوميًا.
جزء كبير من الناس ربما أدركوا للتو خلال هذين اليومين أنه يمكن استخدامه بهذه الطريقة.
أما فريق السيليكون فالي، فقد حوّل هذا الأمر إلى خط إنتاج.
المثال الأول هو فريق OpenAI Frontier.
في تجارب فريق Frontier المُعلنة رسمياً من قبل OpenAI، قام Codex بإنشاء حوالي مليون سطر من الشيفرة وحوالي 1500 طلب سحب من مستودع فارغ خلال حوالي 5 أشهر؛ وتم توسيع الفريق من 3 أشخاص إلى 7 أشخاص، دون كتابة الشيفرة يدوياً.
أشار ريان لوبوبولو، القائد، في مقابلة لاحقة إلى أن هذه السيرورة وصلت تقريبًا إلى شكلها النهائي المتمثل في "0 أكواد بشرية، 0 مراجعة بشرية".
他认为,与其节省 التوكن، فمن الأفضل الاستفادة من قدرة النموذج العالية على المعالجة المتزامنة وتكلفته المنخفضة جدًا لاستبدال الانتباه المتزامن المحدود والمرتفع التكلفة للإنسان.
المثال الثاني هو نظام الوكيل الآلي الداخلي لـ Stripe المسمى Minions.
يقوم Minions داخل Stripe بإنشاء ودفع أكثر من 1300 PR للدمج أسبوعيًا، حيث يتم توليد هذا الكود بالكامل بواسطة الذكاء الاصطناعي، لكنه لا يزال يخضع لمراجعة بشرية.
هنا زوج بيانات آخر: 1.6% مقابل 98.4%، وهو مأخوذ من ورقة بحثية نُشرت من قبل مختبر VILA في جامعة محمد بن زايد للذكاء الاصطناعي.

https://arxiv.org/pdf/2604.14228
قام باحث بتحليل منهجي لـ 512,000 سطر من شفرة TypeScript لإصدار Claude Code v2.1.88، وخلص إلى أن 1.6% فقط هي منطق قرار الذكاء الاصطناعي، بينما يمثل البنية التحتية الهندسية الحتمية الـ 98.4% المتبقية.
أي بوابة الصلاحيات، وإدارة السياق، وتوجيه الأدوات، واستعادة الأخطاء.
هذه الأرقام لا تعني أن النموذج يساهم فقط بنسبة 1.6٪ من القدرة، بل توضح أن Claude Code كمنتج، فإن معظم التعقيدات لا تكمن في النموذج نفسه، بل في البنية التحتية الهندسية الحتمية مثل الصلاحيات والسياق وتوجيه الأدوات وآليات الاستعادة.
الهيكل CLAUDE.md/skills/hooks في تلك الصورة هو "بنية تحتية مبسطة" يمكن لأي مطور عادي بناؤه، وهو نفس النموذج المستخدم في البنية التحتية الإنتاجية من OpenAI وStripe، لكن بحجم أصغر بكثير.
الأسرار المكشوفة لـ CLAUDE.md
على مدار السنوات الثلاث الماضية، كان الجميع يسأل: "متى سيصبح GPT أكثر ذكاءً؟" و"متى سيصدر إصدار جديد من Claude؟"
لكن الفرق التي تُطبّق فعلاً البرمجة بالذكاء الاصطناعي في بيئة الإنتاج، قد لا تهتم بهذا الأمر أصلاً، بل تهتم بكيفية جعل الذكاء الاصطناعي يتذكر الأخطاء التي وقع فيها سابقاً، وكيفية جعله يلقي نظرة على قيود بنية المشروع قبل أن يبدأ العمل، وكيفية جعل الأدوات تمنعه من ارتكاب الأخطاء.
CLAUDE.md هو بالضبط الحامل لكل هذا.
التعريف الرسمي من Anthropic هو جملة واحدة فقط:
ملف markdown يوضع في الدليل الجذري للمشروع، ويقرأه Claude Code تلقائيًا في بداية كل جلسة.

https://code.claude.com/docs/en/memory
It sounds simple, but it's the several layers built around it that make it truly impressive.
CLAUDE.md هو دماغ المشروع.
تُجمع هنا قرارات التصميم، واتفاقيات التسمية، ومتطلبات الاختبار، وكل الأخطاء المتكررة التي تم المرور بها. إنها "دليل الموظف" الذي يراه الذكاء الاصطناعي أول شيء عند كل تشغيل.
.claude/skills/ هي سير عمل قابل لإعادة الاستخدام.
أكّد بوريس تشيرني، مؤسس Claude Code، مرارًا وتكرارًا في المجتمع قائلاً: "إذا قمت بفعل شيء ما أكثر من مرة يوميًا، فحوّله إلى مهارة أو أمر."
المهارة هي مجموعة منهجية قابلة للتنفيذ. لا ينبغي أن تكون مراجعة الكود، وتوليد رسائل الالتزام، وكتابة ملاحظات الإصدار، مهامًا تُنفذ يدويًا كل يوم عن طريق إدخال أوامر، بل يجب أن تكون مهامٍ تُنفَّذ ببساطة عبر تشغيل مهارة.
.claude/hooks/ هي حواجز تلقائية.
هذا هو الجزء الأكثر أهمية. فهو لا يعتمد على تقييم الذكاء الاصطناعي نفسه، بل يتم منعه بواسطة كود محدد مسبقًا قبل أن يرتكب الذكاء الاصطناعي أي خطأ. هذا هو السبب في أنه يمكننا السماح للذكاء الاصطناعي بالعمل "بدون رقابة"، لأن الحدود التي تمنع الأخطاء مُحصورة بواسطة hooks.
docs/decisions/ هي سجل قرارات الهيكلية.
اجعل الذكاء الاصطناعي لا يفهم فقط ما هو الكود، بل أيضًا لماذا هو بهذه الطريقة.
هذا العنصر الأكثر تجاهلاً، لكنه أيضًا أكبر نقطة رافعة للتعاون مع الذكاء الاصطناعي.
tools/ و src/ هما طبقة التنفيذ.
الشيء الحقيقي الذي يستحق الملاحظة في هذا الهيكل ليس أن مطورًا واحدًا أنشأ دليلاً أنيقًا، بل أن فرقًا مستقلة متزايدة تتجه نحو نفس الاتجاه: وضع النموذج داخل إطار يتكون من السياق والأدوات والصلاحيات والتقييم ودورات التغذية الراجعة.
يمكن بالفعل رؤية العديد من المشاريع المماثلة على GitHub:
روهيت جي00 وديت103 وأفان مي يبنون بيئة عمل مهندسة لـ Claude Code حول مكونات مثل الوكلاء والمهارات والربطات والقواعد وتكوينات MCP.
هذا يوضح أن تدفق عمل برمجي بالذكاء الاصطناعي ناضج حقًا لا يعتمد فقط على نموذج أقوى، ولا فقط على مطالبة أطول، بل على دمج النموذج داخل نظام هندسي قابل لإعادة الاستخدام، وقابل للتحديد، وقابل للاستعادة، وقابل للمراجعة.
أما بالنسبة لهيكل الدليل المحدد، فتختلف الت implementations من شركة إلى أخرى.
تجربة حدودية من مختبر OpenAI
في 11 فبراير 2026، نشر مدونة OpenAI الرسمية مقالًا بعنوان: «Harness engineering: leveraging Codex in an agent-first world».

https://openai.com/index/harness-engineering/
أعادت Anthropic تشكيل فكرة بنية Claude Code حول هذا المفهوم؛ وخلص موقع مارتن فاولر إلى صيغة واحدة: "الوكيل = النموذج + الإطار".
كلمة "Harness" تأتي من ركوب الخيل. وهي تشير إلى مجموعة كاملة من تجهيزات الجر للحصان، مثل السلاسل، وقائم الفم، والسرج، والقِناع.
يمكن للحصان أن يركض بسرعة وقوة كبيرة، لكنه لا يعرف أين يذهب: إن مجموعة الأدوات المستخدمة تحدد اتجاهه.
مقارنةً ببرمجة الذكاء الاصطناعي: النموذج نفسه قوي جدًا، لكنه لا يعرف أين يذهب داخل مكتبة كودك. هارنيس هو عجلة القيادة والفرامل والملاحة التي صنعتها له.
تجربة فريق OpenAI Frontier "مليون سطر بدون تدخل بشري" هي في جوهرها إنجاز مثالي لـ Harness.
تشمل ممارساتهم الهندسية الأساسية البنود التالية.
قيود قوية على الهيكل الهرمي.
من Types إلى Config إلى Repo إلى Service إلى Runtime إلى UI، تتدفق التبعيات في اتجاه واحد، ويُفرض ذلك بواسطة linter على مستوى CI. إذا كتب العميل كودًا يخرق العلاقة الطبقية؟ يفشل البناء مباشرة.
معلومات خطأ linter هي نفسها تعليمات الإصلاح، وهذا هو أدق تفصيل غير بديهي.
أخطاء التحقق في المشاريع العادية هي «تم اكتشاف مخالفة»، موجهة للبشر؛ بينما أخطاء التحقق في OpenAI Frontier هي «استخدم logger.info({event: 'name', …data}) بدلاً من console.log»، وهي تعليمات موجهة للوكلاء ويمكنهم قراءتها وإصلاحها مباشرة.
الوثيقة كمصدر وحيد للحقيقة. جميع مخططات البنية، خطط التنفيذ، ومواصفات التصميم موجودة في دليل docs/ داخل المستودع. لا يحتاج العامل إلى أي قاعدة معرفية خارجية، فكل شيء موجود داخل المستودع.
How effective is this set?
لم يتغير النموذج، لكن LangChain عدّلت harness، بما في ذلك التلميحات النظامية والأدوات والبرمجيات الوسيطة ونمط الاستدلال، مما رفع درجة Terminal Bench 2.0 من 52.8 إلى 66.5.
ما يمكنك فعله اليوم
إنشاء عقل مشروع للذكاء الاصطناعي
السؤال يعود إلى المطور العادي: إذا كان النموذج قد تغير بالفعل، ماذا يمكن للمهندس العادي فعله اليوم؟
أول شيء، أنشئ ملفًا باسم CLAUDE.md في الدليل الجذرى لأهم مشروع لك.
لا تحتاج إلى الكمال ولا إلى الطول. اكتب قواعد هيكل فريقك، واتفاقات التسمية، ومتطلبات الاختبار، والأخطاء المتكررة التي وقعت فيها — يمكنك إكمال نسخة قابلة للاستخدام خلال 10 دقائق.
عندما يرتكب الذكاء الاصطناعي خطأً المرة القادمة، لا تصلحه يدويًا أولاً، بل اسأل نفسك: ما الذي ينقصه في CLAUDE.md؟
الشيء الثاني، حوّل المهام اليومية المتكررة إلى مهارة.
يجب الانتباه إلى مقولة بوريس تشيرني: "إذا كنت تفعل شيئًا أكثر من مرة يوميًا، فحوّله إلى مهارة أو أمر."
مراجعة الكود، توليد رسالة commit، كتابة ملاحظات الإصدار، إصلاح نوع واحد من الأخطاء المتكررة، هذه كلها مهارات، ولا ينبغي أن تكون مدخلات يدوية تُكتب يوميًا.
الشيء الثالث، أضف مُحفزًا في الأماكن التي من السهل الوقوع فيها في فخ.
الـ Hook هو الجزء الأكثر رافعة من الـ 98.4%. إنه لا يعتمد على الذكاء الاصطناعي ليصبح ذكيًا، بل يعتمد على كود محدد لتنفيذ فحوصات إجبارية. إنه عملية ترجمة حكم المهندسين البشريين إلى قيود قابلة للقراءة من قبل الآلة.
جوهر هذا الأمر ليس في كتابة الكود، بل في كتابة القواعد.
العبارة التي نُشرت على تويتر من قبل كارباتي في يناير من هذا العام والتي تم إعادة تغريدها على نطاق واسع: "لقد انتقلت من كتابة 80% من الكود يدويًا إلى تكليف 80% منه للوكيل."
على مدار الخمس سنوات القادمة، يتحول منحنى كفاءة المهندسين من "كم عدد أسطر الكود التي يمكنني كتابتها" إلى "ما مدى صرامة بيئة العمل التي يمكنني تصميمها للذكاء الاصطناعي".
المهام المتعلقة بكتابة الكود يتم استلامها من قبل الوكلاء.
لكن تصميم العالم الذي يمكن للوكيل فيه كتابة كود جيد لا يزال مسؤولية الإنسان. وأصعب وأهم وأكثر إثارة من ذي قبل.