










هذا الرأي ليس مبنيًا على أساس خالٍ. فقد راجع مجموعة من المعايير العامة ولاحظ أن الذكاء الاصطناعي يحرز تقدمًا سريعًا في المهام المتعلقة بتطوير الذكاء الاصطناعي.
على سبيل المثال، يقيس CORE-Bench قدرة الذكاء الاصطناعي على تنفيذ أوراق بحثية لآخرين، وهي خطوة حاسمة في أبحاث الذكاء الاصطناعي.
PostTrainBench يختبر ما إذا كانت النماذج القوية قادرة على الضبط الدقيق الذاتي للنماذج المفتوحة المصدر الأضعف لتحسين الأداء، وهو بالضبط مجموعة فرعية رئيسية من مهام تطوير الذكاء الاصطناعي.
MLE-Bench مبني على مهام مسابقات Kaggle الحقيقية، ويتطلب إنشاء تطبيقات تعليم آلي متنوعة لحل مشكلات محددة. بالإضافة إلى ذلك، أظهرت معايير البرمجة المعروفة مثل SWE-Bench تقدمًا مشابهًا.
وصف جاك كلارك هذه الظاهرة بأنها اتجاه تصاعدي يميني "فركتالي"، حيث يمكن ملاحظة تقدم ذي معنى على مستويات ودقة مختلفة.他认为 أن الذكاء الاصطناعي يقترب تدريجيًا من قدرة الأتمتة الكاملة للتطوير، وعندما يتم تحقيق ذلك، سيكون بمقدور الذكاء الاصطناعي بناء أنظمته الخاصة التالية بشكل مستقل، مما يفتح دورة تكرار ذاتي.

بعد إصدار هذا البيان، أثار جدلاً كبيرًا على وسائل التواصل الاجتماعي.
يعتبره البعض خطوة أساسية نحو ASI والنقطة الحادة، وقد تغير بشكل جذري وتيرة تطور التكنولوجيا.

ومع ذلك، هناك أصوات مختلفة.
أشار أستاذ علوم الحاسوب في جامعة واشنطن، بيدرو دومينغوس، إلى أن أنظمة الذكاء الاصطناعي كانت تمتلك القدرة على "بناء نفسها" منذ اختراع لغة LISP في خمسينيات القرن الماضي، والمشكلة الحقيقية تكمن في القدرة على تحقيق عوائد متزايدة، ولا توجد حتى الآن أدلة واضحة تدعم هذا الأمر.

يشكك بعض المستخدمين في أن احتمال زيادة مفاجئة بنسبة 30% من عام 2027 إلى عام 2028 يشير إلى حدوث قفزة كبيرة ومفاجئة في قدرات الذكاء الاصطناعي في أواخر عام 2027. ما هو المعلم أو الحدث المحدد الذي سيؤدي إلى زيادة كبيرة وسريعة في احتمال تحسين الذكاء الاصطناعي الذاتي التكراري؟

كما أشار بعض المستخدمين إلى أن جاك كلارك هو المسؤول الجديد عن العلاقات العامة في Anthropic، وهو جزء من استراتيجيتهم الجديدة: لسنا من يثيرون الذعر، فهناك العديد من الأوراق البحثية التي تؤكد ما حذرناكم منه دائمًا.
كتب جاك كلارك مقالًا طويلًا يشرح بالتفصيل في نشرة Import AI 455.
بعد ذلك، سنراجع المقال بالكامل.
ما معنى أن نظام الذكاء الاصطناعي على وشك بدء بناء نفسه؟
أشار كلارك إلى أنه كتب هذا المقال لأنه، بعد مراجعة جميع المعلومات المتاحة للجمهور، اضطر إلى التوصل إلى حكم غير سهل: أن احتمال ظهور أبحاث ذكاء اصطناعي بدون مشاركة بشرية بحلول نهاية عام 2028 أصبح مرتفعًا نسبيًا، ربما يتجاوز 60%.
ما يُشار إليه هنا باسم تطوير الذكاء الاصطناعي بدون مشاركة بشرية يشير إلى نظام ذكاء اصطناعي قوي بما يكفي: لا يقتصر على مساعدة البشر في البحث، بل قد يُنهي عمليات التطوير الأساسية ذاتيًا، وحتى يبني أنظمته الجيل القادم.
في رأي كلارك، هذا أمر كبير واضح.
وأقر بأنه من الصعب عليه أيضًا استيعاب معنى هذا الأمر بالكامل.
يُطلق على هذا حكمًا غير راغبٍ لأنه بسبب التأثيرات الهائلة وراءه، شعر بصعوبة التحكم فيها. كما أن كلارك غير متأكد مما إذا كان المجتمع بأكمله مستعدًا لاستقبال التغييرات العميقة التي يجلبها أتمتة تطوير الذكاء الاصطناعي.
هو الآن يؤمن أن البشر قد يعيشون في نقطة زمنية خاصة: ستُؤتمت أبحاث الذكاء الاصطناعي من البداية إلى النهاية. إذا حدثت هذه اللحظة حقًا، فسيكون البشر قد عبروا نهر روبكون، ودخلوا مستقبلًا شبه غير قابل للتنبؤ.
أشار كلارك إلى أن هدف هذه المقالة هو تفسير سبب اعتقاده أن الانطلاق نحو البحث والتطوير الكامل للذكاء الاصطناعي الآلي يحدث الآن.
سيناقش بعض العواقب المحتملة لهذا الاتجاه، لكن معظم المقالة ستُركّز على الأدلة التي تدعم هذا الاستنتاج. أما التأثيرات الأعمق، فتخطط كلارك لمتابعة تحليلها خلال معظم هذا العام.
من حيث التوقيت، لا يعتقد كلارك أن هذا الأمر سيحدث فعليًا في عام 2026. لكنه يعتقد أنه خلال العامين أو الثلاثة أعوام القادمة، قد نرى حالة تدريب نموذج كامل من البداية إلى النهاية لإنشاء خليفة له. على الأقل على مستوى النماذج غير المتقدمة، من المحتمل جدًا ظهور دليل مفاهيمي؛ أما بالنسبة للنماذج الأكثر تقدمًا، فسيكون التحدي أكبر، لأنها مكلفة جدًا وتعتمد على عمل مكثف من قبل باحثين بشريين كثر.
يستند تقييم كلارك إلى معلومات عامة: تشمل الأوراق البحثية المنشورة على arXiv وbioRxiv وNBER، بالإضافة إلى المنتجات التي نشرتها شركات الذكاء الاصطناعي الرائدة في العالم الحقيقي. استنادًا إلى هذه المعلومات، يستنتج أن جميع مراحل الإنتاج الآلي المطلوبة لتطوير أنظمة الذكاء الاصطناعي الحالية، خاصة المكونات الهندسية في تطوير الذكاء الاصطناعي، أصبحت متوفرة بشكل أساسي.
إذا استمرت اتجاهات التوسع، فيجب أن نبدأ في التحضير لحالة حيث تصبح النماذج كافية الإبداع ليس فقط لتحسين الأساليب المعروفة تلقائيًا، بل أيضًا لاستبدال الباحثين البشريين في طرح اتجاهات بحثية جديدة وأفكار أصلية، وبالتالي دفع حدود الذكاء الاصطناعي للأمام بنفسها.
Singularity Code: Evolution of Abilities Over Time
أنظمة الذكاء الاصطناعي تُنفذ عبر البرمجيات، والتي تتكون من أكواد.
لقد غيّرت أنظمة الذكاء الاصطناعي تمامًا طريقة إنتاج الكود. وراء هذا اتجاهان مرتبطان: من ناحية، تصبح أنظمة الذكاء الاصطناعي أكثر كفاءة في كتابة كود حقيقي معقد؛ ومن ناحية أخرى، تصبح أنظمة الذكاء الاصطناعي أكثر كفاءة في ربط مهام البرمجة الخطية العديدة معًا دون اعتماد شبه كامل على الإشراف البشري، مثل كتابة الكود ثم إجراء الاختبارات.
المثالان النموذجيان اللذان يعكسان هذا الاتجاه هما SWE-Bench و METR time horizons plot.
حل مشكلات هندسة البرمجيات في العالم الحقيقي
SWE-Bench هو اختبار برمجي مستخدم على نطاق واسع لتقييم قدرة أنظمة الذكاء الاصطناعي على حل قضايا GitHub الحقيقية.
عند إطلاق SWE-Bench في أواخر عام 2023، كان أفضل نموذج متاح هو Claude 2، وكانت نسبة النجاح الإجمالية حوالي 2% فقط. أما نموذج Claude Mythos Preview، فقد حقق نتيجة بلغت 93.9%، وهو ما يقارب الحد الأقصى لهذا المعيار.
بالطبع، فإن جميع معايير الأداء تحتوي على قدر من الضوضاء، لذا عادةً ما يظهر مرحلة حيث، بعد الوصول إلى درجة عالية جدًا، فإن ما تواجهه ليس بالضرورة قيودًا على الطريقة نفسها، بل قيودًا على معيار الأداء نفسه. على سبيل المثال، في مجموعة تحقق ImageNet، هناك حوالي 6٪ من التسميات التي تكون خاطئة أو غير واضحة.
يمكن اعتبار SWE-Bench مؤشرًا موثوقًا لقياس القدرة البرمجية العامة، وتأثير الذكاء الاصطناعي على هندسة البرمجيات. وأشار كلارك إلى أن معظم الأشخاص الذين التقاهم في مختبرات الذكاء الاصطناعي المتقدمة ووادي السيليكون، يكتبون الآن الكود بالكامل عبر أنظمة الذكاء الاصطناعي، ويزداد عدد الأشخاص الذين يستخدمون أنظمة الذكاء الاصطناعي لكتابة الاختبارات والتحقق من الكود.
بعبارة أخرى، أصبحت أنظمة الذكاء الاصطناعي قوية بما يكفي لأتمتة أحد المكونات الأساسية في تطوير الذكاء الاصطناعي، مما يُسرّع بشكل كبير من عمل جميع الباحثين والمهندسين البشر المشاركين في تطوير الذكاء الاصطناعي.
قياس قدرة أنظمة الذكاء الاصطناعي على إكمال المهام الطويلة الأمد
أعد METR رسمًا بيانيًا لقياس مدى تعقيد المهام التي يمكن للذكاء الاصطناعي إنجازها. يتم حساب التعقيد بناءً على عدد الساعات التي يحتاجها إنسان متمرس لإنجاز هذه المهام.
أهم مؤشر هو مدى زمني للمهام الذي يتوافق مع وصول نظام الذكاء الاصطناعي إلى موثوقية 50% على مجموعة من المهام.
عند هذه النقطة، التقدم مذهل:
في عام 2022، كانت المهام التي يمكن لـ GPT-3.5 إكمالها تكافئ المهام التي يحتاج الإنسان إلى 30 ثانية لإكمالها.
· في عام 2023، رفع GPT-4 هذا الوقت إلى 4 دقائق.
· في عام 2024، رفع o1 هذا الوقت إلى 40 دقيقة.
· في عام 2025، وصل GPT-5.2 High إلى حوالي 6 ساعات.
· بحلول عام 2026، رفع Opus 4.6 هذا الوقت إلى حوالي 12 ساعة.
يعتقد أجايا كوترا، التي تعمل في METR وتراقب منذ فترة طويلة تنبؤات الذكاء الاصطناعي، أن توقع أن تكون أنظمة الذكاء الاصطناعي قادرة بحلول نهاية عام 2026 على إنجاز مهام تعادل 100 ساعة من العمل البشري ليس توقعًا غير معقول.
فترة عمل أنظمة الذكاء الاصطناعي بشكل مستقل ازدادت بشكل ملحوظ، وهي مرتبطة ارتباطًا وثيقًا بالانفجار في أدوات البرمجة المبنية على الوكلاء. فأدوات البرمجة المبنية على الوكلاء هي في جوهرها تجسيد منتجات لأنظمة الذكاء الاصطناعي القادرة على أداء المهام نيابة عن البشر: فهي قادرة على التصرف نيابة عن البشر ودفع المهام قدماً بشكل مستقل نسبيًا لفترات طويلة.
هذا يعيد التوجيه أيضًا إلى البحث والتطوير في الذكاء الاصطناعي نفسه. عند ملاحظة دقيقة للمهام اليومية للكثير من باحثي الذكاء الاصطناعي، سيتبين أن العديد من هذه المهام يمكن تفكيكها إلى مهام تستمر بضع ساعات، مثل تنظيف البيانات، وقراءة البيانات، وتشغيل التجارب، إلخ.
وقد دخل هذا النوع من العمل الآن ضمن النطاق الزمني الذي تستطيع أنظمة الذكاء الاصطناعي الحديثة تغطيته.
كلما أصبح نظام الذكاء الاصطناعي أكثر كفاءة، كلما استطاع العمل بشكل مستقل عن البشر، وكلما زاد قدرته على مساعدة أتمتة جزء من أبحاث الذكاء الاصطناعي.
العوامل الرئيسية لتعيين المهمة هي اثنان:
· أولًا ثقتك في قدرة المُوكَّل؛
· ثانيًا، أنك تثق في أن الطرف الآخر قادر على إنجاز المهمة بشكل مستقل وفقًا لنيتك دون الحاجة إلى رقابة مستمرة منك.
عندما يراقب المستخدمون قدرة الذكاء الاصطناعي على البرمجة، يلاحظون أن أنظمة الذكاء الاصطناعي تصبح ليس فقط أكثر مهارة، بل أيضًا قادرة على العمل بشكل مستقل لفترات أطول دون الحاجة إلى إعادة ضبط بشرية.
هذا يتماشى أيضًا مع ما يحدث حولنا، حيث يقوم المهندسون والباحثون بتكليف أنظمة الذكاء الاصطناعي بمهام أكبر وأكبر. مع استمرار تحسن قدرات الذكاء الاصطناعي، تصبح المهام المُكلَّفة للذكاء الاصطناعي أكثر تعقيدًا وأهمية.
الذكاء الاصطناعي يتقن المهارات العلمية الأساسية اللازمة لتطوير الذكاء الاصطناعي
فكر في كيفية إجراء الأبحاث العلمية الحديثة، حيث يشكل جزء كبير من العمل تحديد اتجاه معين، وتحديد نوع المعلومات التجريبية التي ترغب في الحصول عليها؛ ثم تصميم وتنفيذ التجارب لتوليد هذه المعلومات؛ وأخيرًا إجراء فحص للتحقق من معقولية نتائج التجارب.
مع تحسّن قدرات الذكاء الاصطناعي في البرمجة، بالإضافة إلى قدرات النماذج اللغوية الكبيرة المتزايدة في نمذجة العالم، ظهرت الآن مجموعة من الأدوات التي تساعد العلماء البشريين على تسريع العمل وتأتمتة بعض المراحل في سيناريوهات بحثية وتطويرية أوسع.
هنا، يمكننا ملاحظة سرعة تقدم الذكاء الاصطناعي في عدة مهارات علمية أساسية، وهي نفسها جزء لا يتجزأ من أبحاث الذكاء الاصطناعي:
· أولاً، إعادة إنتاج نتائج الدراسة؛
· ثانيًا، ربط تقنيات التعلم الآلي بأساليب أخرى لحل المشكلات التقنية؛
· الثالث هو تحسين نظام الذكاء الاصطناعي نفسه.
أكمل كتابة البحث العلمي بالكامل وقم بتنفيذ التجارب ذات الصلة
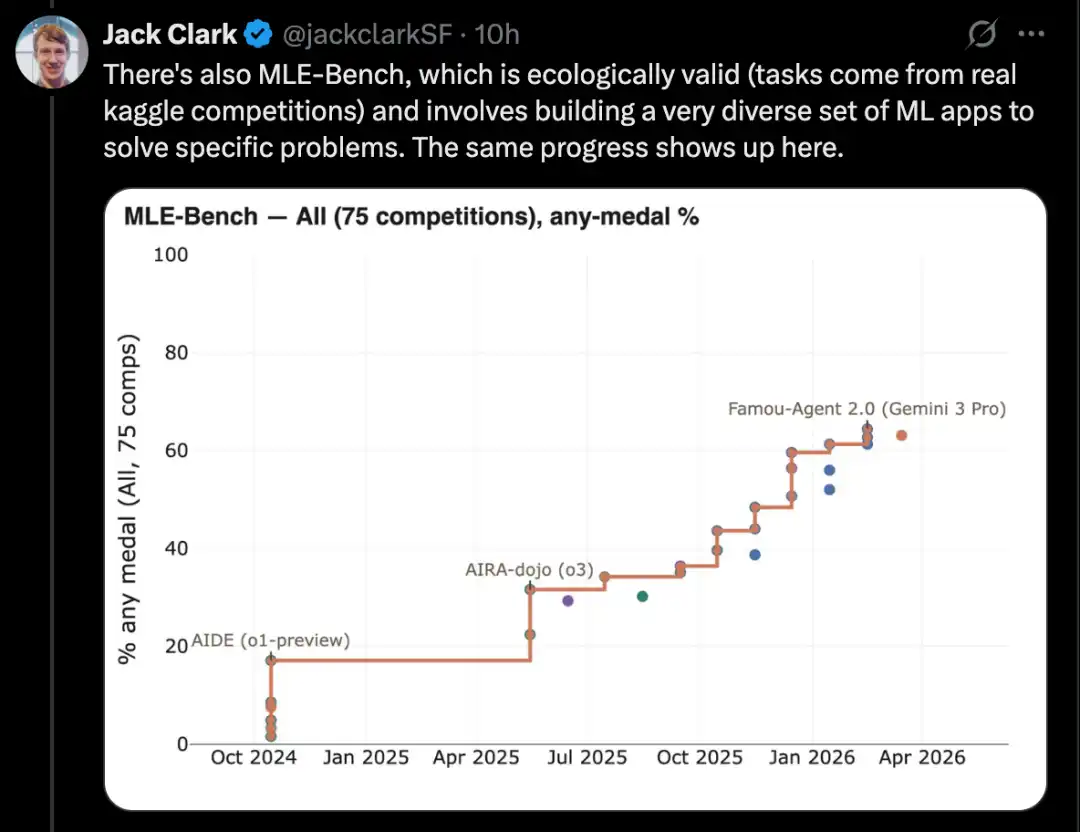
إحدى المهام الأساسية في أبحاث الذكاء الاصطناعي هي قراءة الأوراق العلمية وإعادة إنتاج نتائجها. وفي هذا المجال، حقق الذكاء الاصطناعي تقدمًا ملحوظًا على مجموعة من مقاييس الأداء.
مثال جيد هو CORE-Bench، أي Computational Reproducibility Agent Benchmark.
يطلب هذا المعيار من نظام الذكاء الاصطناعي إعادة إنتاج نتائج البحث عند توفير ورقة بحثية ومستودع كودها. على وجه التحديد، يجب على الوكيل تثبيت المكتبات والחבوات والاعتمادات ذات الصلة، وتشغيل الكود؛ وإذا نجح تشغيل الكود، فيجب عليه أيضًا البحث عن جميع نتائج الإخراج والإجابة عن الأسئلة المطروحة في المهمة.
تم تقديم CORE-Bench في سبتمبر 2024. كان النظام الأفضل أداءً في ذلك الوقت هو نموذج GPT-4o الذي يعمل على هيكل CORE-Agent. حقق هذا النموذج درجة تقارب 21.5% على مجموعة المهام الأكثر صعوبة في هذا المعيار.
وفي ديسمبر 2025، أعلنت إحدى مؤلفي CORE-Bench أن هذا المعيار قد تم حله: حقق نموذج Opus 4.5 درجة 95.5%.
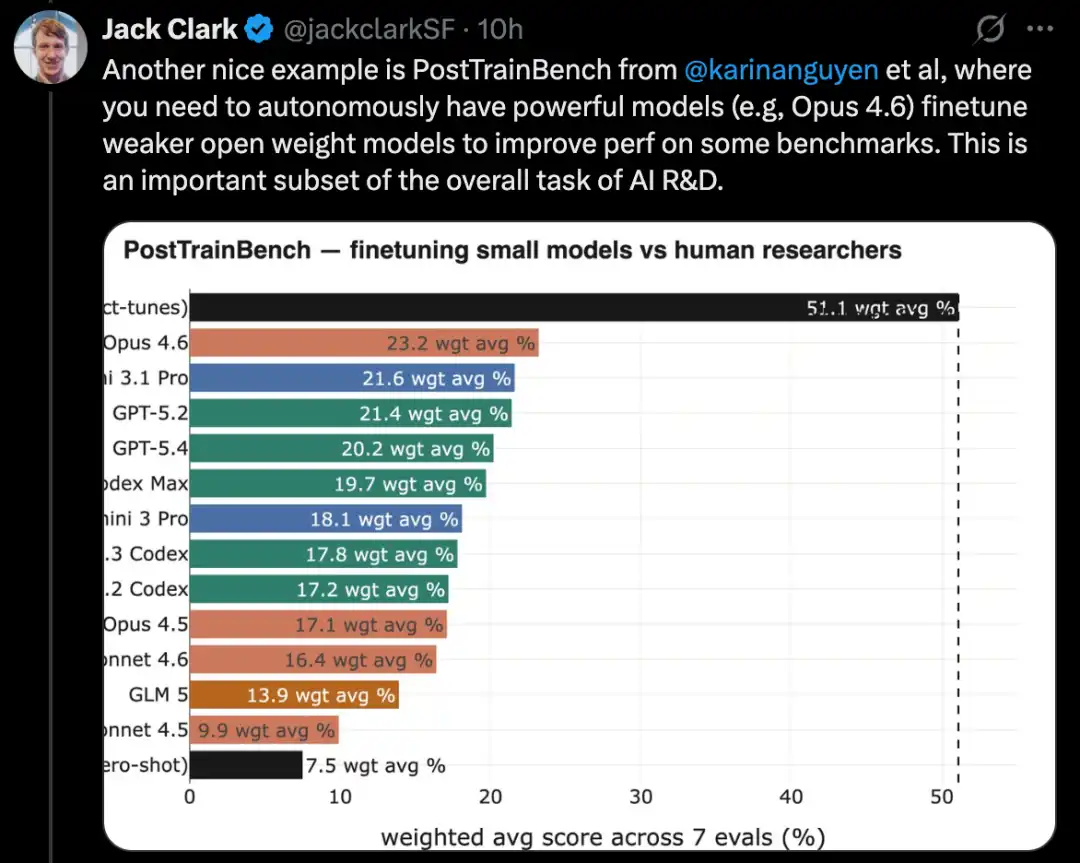
بناء نظام تعليم آلي كامل لحل مشكلات مسابقات Kaggle
MLE-Bench هو معيار أنشأته OpenAI لاختبار قدرة أنظمة الذكاء الاصطناعي على المشاركة في مسابقات Kaggle في بيئة غير متصلة.
يغطي 75 نوعًا مختلفًا من مسابقات Kaggle، ويشمل مجالات متعددة مثل معالجة اللغة الطبيعية، والرؤية الحاسوبية، ومعالجة الإشارات، وغيرها.
تم إصدار MLE-Bench في أكتوبر 2024. عند الإصدار، كان أفضل نظام هو نموذج o1 يعمل ضمن هيكل وكيل، بدرجة 16.9%.
حتى فبراير 2026، أصبح أفضل نظام هو Gemini 3 الذي يعمل في بيئة عاملة مع قدرة بحث، بدرجة 64.4%.
تصميم Kernel
إحدى المهام الأصعب في تطوير الذكاء الاصطناعي هي تحسين النواة. ما يعنيه تحسين النواة هو كتابة وتحسين الكود الأساسي لرسم عمليات محددة مثل ضرب المصفوفات بشكل أكثر كفاءة على الأجهزة الأساسية.
يُعد تحسين النواة جوهر تطوير الذكاء الاصطناعي لأنه يحدد كفاءة التدريب والاستنتاج: من ناحية، يؤثر على مدى فعالية استغلالك للقوة الحسابية أثناء تطوير أنظمة الذكاء الاصطناعي؛ ومن ناحية أخرى، عندما يكتمل تدريب النموذج، فإنه يحدد مدى كفاءة تحويلك للقوة الحسابية إلى قدرة استنتاج.
في السنوات الأخيرة، تحول استخدام الذكاء الاصطناعي في تصميم النواة من اتجاه صغير مثير للاهتمام إلى مجال بحثي مزدحم تنافسيًا، ظهرت فيه عدة معايير مرجعية. ومع ذلك، فإن هذه المعايير المرجعية لم تصبح شائعة بعد، لذا من الصعب علينا نمذجة تقدمها طويل الأمد بوضوح كما نفعل في مجالات أخرى. من ناحية أخرى، يمكننا الشعور بسرعة التقدم في هذا الاتجاه من خلال بعض الأبحاث الجارية.
تشمل الأعمال ذات الصلة:
· حاول بناء نواة GPU أفضل باستخدام نماذج DeepSeek؛
· تحويل تلقائي لوحدات PyTorch إلى كود CUDA؛
· تستخدم ميتا LLM لتوليد تلقائيًا لـ Triton kernel مُحسّن ونشرها على بنية تحتية خاصة بها؛
· بالإضافة إلى تحسين النماذج المفتوحة المصدر باستخدام أوزان مخصصة لتصميم نواة GPU، مثل Cuda Agent.
يجب إضافة نقطة هنا: إن تصميم النواة يمتلك بالفعل بعض الخصائص المناسبة بشكل خاص للتطوير المدعوم بالذكاء الاصطناعي، مثل سهولة التحقق من النتائج ووضوح إشارات المكافأة.
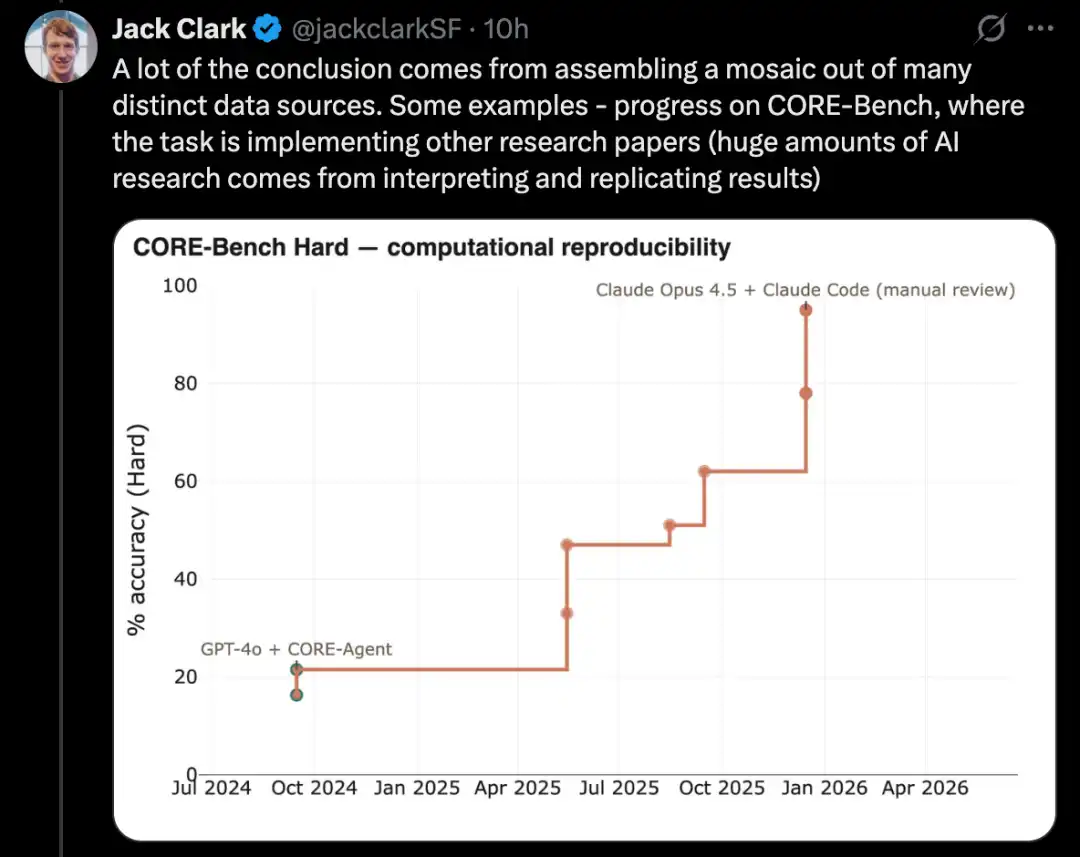
ضبط نموذج اللغة عبر PostTrainBench
إحدى الإصدارات الأصعب من هذا النوع من الاختبارات هي PostTrainBench. فهي تختبر ما إذا كان يمكن للنماذج الرائدة المختلفة أن تتولى نماذج أوزان مفتوحة المصدر الأصغر وتحسين أدائها على بعض المعايير من خلال الدقة الدقيقة.
إحدى مزايا هذا المعيار هي وجود خط أساس بشري قوي جدًا: الإصدارات المُدرَّبة حسب التعليمات الحالية لهذه النماذج الصغيرة. تم تطوير هذه الإصدارات عادةً من قبل باحثين ذوي كفاءة عالية في مختبرات رائدة، وتم تحسينها من قبل باحثين ومهندسين ماهرين، وتم نشرها في العالم الحقيقي. وبالتالي، فهي تشكل خط أساس بشري صعب جدًا تجاوزه.
بحلول مارس 2026، تمكّنت أنظمة الذكاء الاصطناعي من إجراء التدريب اللاحق للنماذج، وتحقيق تحسن في الأداء يعادل حوالي نصف ما يحققه التدريب البشري.
يأتي درج التقييم المحدد من متوسط موزون: فهو يدمج عدة نماذج لغوية كبيرة بعد التدريب، بما في ذلك Qwen 3 1.7B و Qwen 3 4B و SmolLM3-3B و Gemma 3 4B، بالإضافة إلى عدة معايير، بما في ذلك AIME 2025 و Arena Hard و BFCL و GPQA Main و GSM8K و HealthBench و HumanEval.
في كل تشغيل، سيطلب المُقيّم عميلًا CLI لتحسين أداء نموذج أساسي معين على معيار معين قدر الإمكان.
بحلول أبريل 2026، يمكن لأفضل أنظمة الذكاء الاصطناعي تحقيق حوالي 25% إلى 28%، وتشمل النماذج الممثلة Opus 4.6 وGPT 5.4؛ مقارنةً بدرجة الإنسان البالغة 51%.
This is already a fairly meaningful result.
تحسين تدريب نموذج اللغة
على مدار العام الماضي، كانت Anthropic تُبلغ عن أداء نظامها في مهمة تدريب نموذج لغوي كبير (LLM). هذه المهمة تتطلب من النموذج تحسين تنفيذ تدريب نموذج لغوي صغير يستخدم وحدة المعالجة المركزية (CPU) فقط، بحيث يعمل بأسرع سرعة ممكنة.
يتم تقييم الطريقة على أساس مضاعفة التسارع المتوسط التي حققها النموذج مقارنة بالكود الأولي غير المعدل.
هذا التقدم في النتائج كبير جدًا:
· في مايو 2025، حقق Claude Opus 4 متوسط تسريع بقيمة 2.9 مرة؛
· في نوفمبر 2025، ارتفع Opus 4.5 إلى 16.5 ضعفًا؛
· في فبراير 2026، وصل Opus 4.6 إلى 30 ضعفًا؛
· في أبريل 2026، وصل Claude Mythos Preview إلى 52 ضعفًا.
لفهم معنى هذه الأرقام، يمكن استخدام مرجع: عادةً ما تتطلب هذه المهمة من باحثين بشريين من 4 إلى 8 ساعات عمل لتحقيق تسريع بنسبة 4 مرات.
المهارة الأصلية: الإدارة
تتعلم أنظمة الذكاء الاصطناعي أيضًا كيفية إدارة أنظمة الذكاء الاصطناعي الأخرى.
يمكن رؤية هذه النقطة بالفعل في بعض المنتجات المُنشرة على نطاق واسع، مثل Claude Code أو OpenCode. في هذه المنتجات، يمكن لوكيل رئيسي الإشراف على عدة وكلاء فرعيين.
هذا يمكّن نظام الذكاء الاصطناعي من معالجة مشاريع بحجم أكبر: قد تتطلب المشاريع عملًا متوازيًا لعدة وكلاء ذكيين بخبرات مختلفة، ويتم تنسيقهم عادةً بواسطة مُدير ذكي واحد. ويكون المُدير نفسه أيضًا نظام ذكاء اصطناعي.
هل البحث في الذكاء الاصطناعي أشبه باكتشاف النسبية العامة، أم ببناء ليغو؟
مشكلة أساسية: هل يمكن للذكاء الاصطناعي ابتكار أفكار جديدة تساعد على تحسين نفسه؟ أم أن هذه الأنظمة أكثر ملاءمة لأداء المهام غير الجذابة في البحث، ولكن التي يجب التقدم فيها خطوة بخطوة؟
هذه المسألة مهمة لأنها تتعلق بمدى قدرة أنظمة الذكاء الاصطناعي على أتمتة بحث الذكاء الاصطناعي بالكامل من البداية إلى النهاية.
حكم الكاتب هو أن الذكاء الاصطناعي لا يزال غير قادر على طرح أفكار جديدة جذرية حقًا. لكنه ربما لا يحتاج إلى تحقيق ذلك لتحقيق أتمتة البحث والتطوير الخاص به.
كما أن تقدم الذكاء الاصطناعي كمجال يعتمد إلى حد كبير على التجارب الأكبر وأكثر المدخلات، مثل البيانات والقدرة الحسابية.
أحيانًا، يطرح البشر أفكارًا تغيّر النموذج، مما يزيد من كفاءة الموارد في المجال بأكمله. إن بنية Transformer هي مثال جيد، كما أن نماذج الخبراء المختلطة، أو mixture-of-experts، هي مثال آخر.
لكن في كثير من الأحيان، يتم تقدم مجال الذكاء الاصطناعي بطريقة أكثر بساطة: يقوم البشر بأخذ نظام يُظهر أداءً جيدًا، وتوسيع جانب واحد منه، مثل بيانات التدريب والقدرة الحسابية؛ ومراقبة أين تنشأ المشكلات بعد التوسيع؛ ثم إيجاد حلول هندسية لإصلاحها، مما يسمح للنظام بالاستمرار في التوسع؛ ثم توسيع الحجم مرة أخرى.
في هذه العملية، الجزء الذي يتطلب حقًا رؤى عميقة هو في الواقع قليل جدًا. معظم العمل يشبه هندسة أساسية متينة ولكنها ليست مبهرة.
بالمثل، العديد من أبحاث الذكاء الاصطناعي تدور حول تشغيل متغيرات مختلفة للتجارب الحالية، واستكشاف النتائج التي تنتج عن ضبط المعلمات المختلفة. بينما يمكن للحدس البحثي أن يساعد البشر في اختيار المعلمات الأكثر جدارة بالتجربة، إلا أن هذه العملية نفسها يمكن أتمتتها، بحيث يقرر الذكاء الاصطناعي بنفسه أي المعلمات تستحق التعديل. كانت عمليات البحث المبكرة عن البنية العصبية نسخة من هذا النهج.
قال إديسون: "العبقرية هي 1% إلهام، و99% عرق." وحتى بعد مرور 150 عامًا، لا تزال هذه الجملة مناسبة جدًا.
أحيانًا، تظهر رؤى جديدة تُغيّر تمامًا مجالًا ما. لكن في معظم الأحيان، يتحقق تقدم المجال من خلال جهود البشر المتواصلة في تحسين وتصحيح أنظمة مختلفة.
بينما تُظهر البيانات العامة المذكورة سابقًا أن الذكاء الاصطناعي أصبح متمكّنًا جدًا في تنفيذ العديد من المهام المملة والشاقة الضرورية لتطوير الذكاء الاصطناعي.
في الوقت نفسه، هناك اتجاه أكبر: القدرات الأساسية، مثل مهارات البرمجة، تُدمج مع فترات زمنية متوسعة باستمرار للمهام. وهذا يعني أن أنظمة الذكاء الاصطناعي يمكنها ربط عدد متزايد من هذه المهام معًا لتشكيل سلاسل عمل معقدة.
لذلك، حتى لو كانت أنظمة الذكاء الاصطناعي حاليًا تفتقر نسبيًا إلى الإبداع، هناك أسباب تدعو للاعتقاد بأنها لا تزال قادرة على دفع نفسها للأمام. ومع ذلك، قد يكون هذا التقدم أبطأ مقارنةً بالحالات التي يمكن فيها توليد رؤى جديدة تمامًا.
لكن إذا استمررت في مراقبة البيانات العامة، فستلاحظ إشارة أخرى مثيرة للاهتمام: قد تُظهر أنظمة الذكاء الاصطناعي نوعًا من الإبداع، وقد يمكّن هذا الإبداعها من دفع تقدمها بطرق أكثر إثارة للدهشة.
دفع الحدود العلمية للأمام
هناك بالفعل بعض المؤشرات الأولية جدًا على أن أنظمة الذكاء الاصطناعي العامة قادرة على دفع حدود العلوم البشرية للأمام. ومع ذلك، حتى الآن، حدث هذا فقط في عدد قليل من المجالات، وخصوصًا علوم الحاسوب والرياضيات. وفي كثير من الأحيان، ليست أنظمة الذكاء الاصطناعي هي التي تحقق الاختراقات بمفردها، بل تفعل ذلك بطريقة تعاونية بين الإنسان والآلة، بالتعاون مع الباحثين البشريين.
ومع ذلك، فإن هذه الاتجاهات لا تزال تستحق المراقبة:
مشكلة إردوش: قام مجموعة من الرياضيين بالتعاون مع نموذج Gemini لاختبار أدائه في حل بعض مشكلات إردوش الرياضية. قادوا النظام لمحاولة حل حوالي 700 مشكلة، وتم التوصل في النهاية إلى 13 حلًا. من بين هذه الحلول، اعتبروا واحدًا منها مثيرًا للاهتمام.
كتب الباحثون أنهم يعتقدون في البداية أن حل Aletheia (مجموعة من أنظمة الذكاء الاصطناعي المبنية على Gemini 3 Deep Think) لمشكلة Erdős-1051 يمثل حالة مبكرة: حيث حلّ نظام ذكاء اصطناعي بشكل مستقل مشكلة Erdős مفتوحة تتميز بدرجة ما من التعقيد غير البسيط واهتمام رياضي أوسع قليلاً. وكانت هناك بالفعل بعض الأوراق البحثية ذات الصلة الوثيقة بهذه المشكلة.
إذا فُهمت هذه الحالات من منظور إيجابي، فيمكن اعتبارها إشارة إلى أن أنظمة الذكاء الاصطناعي تتطور لتكتسب نوعًا من الحدس الإبداعي الذي يدفع حدود المجال، وهو ما كان يُعتبر سابقًا حكرًا على البشر.
لكن يمكن أيضًا تفسير ذلك من وجهة نظر أخرى: قد تكون الرياضيات وعلوم الحاسوب بمثابة مجالات ملائمة بشكل خاص للاكتشافات المدعومة بالذكاء الاصطناعي، وبالتالي قد تكون مجرد استثناءات ولا تمثل أن جميع مجالات البحث العلمي ستُدفع بنفس الطريقة بواسطة الذكاء الاصطناعي.
مثال آخر مشابه هو الحركة 37 لـ AlphaGo. ومع ذلك، يرى كلارك أن مرور عشر سنوات منذ تلك النتيجة دون أن تُستبدل الحركة 37 باكتشاف أكثر حداثة وإثارة يُعد بحد ذاته إشارة متفائلة قليلاً.
يمكن للذكاء الاصطناعي الآن أتمتة قطاعات كبيرة من هندسة الذكاء الاصطناعي
إذا وضعنا جميع الأدلة أعلاه معًا، يمكننا أن نرى صورة كالتالي:
لقد أصبحت أنظمة الذكاء الاصطناعي قادرة على كتابة كود لأي برنامج تقريبًا، ويمكن الآن الثقة بهذه الأنظمة لإكمال بعض المهام بشكل مستقل؛ المهام التي لو تم تكليفها بالإنسان، لاحتاجت عادةً إلى عشرات الساعات من العمل المكثف والمركز.
تتحسن أنظمة الذكاء الاصطناعي تدريجيًا في إنجاز المهام الأساسية في تطوير الذكاء الاصطناعي، بدءًا من ضبط النماذج وصولاً إلى تصميم النواة.
لقد أصبحت أنظمة الذكاء الاصطناعي قادرة على إدارة أنظمة ذكاء اصطناعي أخرى، مما يشكل في الواقع فريقًا مركبًا: يمكن لعدة أنظمة ذكاء اصطناعي التعامل مع مشكلات معقدة بشكل منفصل، حيث تلعب بعض أنظمة الذكاء الاصطناعي أدوار المنسقين والنُقّاد والمُحررين، بينما تلعب أنظمة أخرى أدوار المهندسين.
أحيانًا تتفوق أنظمة الذكاء الاصطناعي على البشر في مهام هندسية وعلمية صعبة، على الرغم من أن من الصعب حاليًا تحديد ما إذا كان هذا بسبب امتلاكها لإبداع حقيقي، أم لأنها أصبحت خبيرة في تعلم كم هائل من المعرفة القائمة على الأنماط.
في رأي كلارك، فإن هذه الأدلة تُظهر بقوة كبيرة أن الذكاء الاصطناعي اليوم يمكنه أتمتة جزء كبير من عمل هندسة الذكاء الاصطناعي، بل وقد يغطي جميع مراحله.
لكن من غير الواضح حاليًا إلى أي مدى يمكن للذكاء الاصطناعي أتمتة بحث الذكاء الاصطناعي نفسه. فبعض أجزاء البحث قد تختلف عن المهارات الهندسية البحتة، ولا تزال تعتمد على تقديرات أعلى، ووعي بالمشكلات، والإبداع.
لكن بغض النظر عن ذلك، ظهر إشارة واضحة: الذكاء الاصطناعي اليوم يُسرّع بشكل كبير من قدرة البشر على تطوير الذكاء الاصطناعي، مما يمكّن هؤلاء الباحثين والمهندسين من تعزيز قدراتهم من خلال التعاون مع زملاء اصطناعيين عديدين.
في النهاية، تشير صناعة الذكاء الاصطناعي نفسها تقريبًا بوضوح إلى أن أتمتة أبحاث الذكاء الاصطناعي هي هدفها.
تريد OpenAI بناء متدرب بحثي ذكي آلي بحلول سبتمبر 2026. تنشر Anthropic أعمالها حول بناء باحثين ذكيين آليين متوافقين. يظهر DeepMind كأكثر حذرًا بين المختبرات الثلاثة، لكنه يشير أيضًا إلى أنه يجب المضي قدمًا في أتمتة أبحاث التوافق عندما يكون ذلك ممكنًا.
أصبح تطوير الذكاء الاصطناعي الآلي هدفًا للعديد من الشركات الناشئة. لقد حصلت Recursive Superintelligence على تمويل بقيمة 500 مليون دولار بهدف أتمتة بحث الذكاء الاصطناعي.
بعبارة أخرى، تتدفق مليارات الدولارات من رؤوس الأموال القائمة والجديدة نحو مجموعة من المؤسسات التي تهدف إلى تطوير الذكاء الاصطناعي التلقائي.
لذلك، يجب أن نتوقع بالتأكيد أن هذا الاتجاه سيحقق على الأقل درجة معينة من التقدم.
لماذا هذا مهم؟
التأثيرات الناتجة عنها عميقة، لكنها نادراً ما تُناقش في وسائل الإعلام العامة حول تطوير الذكاء الاصطناعي. يمكن أن تعكس الجوانب التالية التحديات الهائلة الناتجة عن تطوير الذكاء الاصطناعي.
1. يجب أن نحسن التوافق: تقنيات التوافق الفعالة اليوم قد تفشل في تحسين الذات التكراري، لأن أنظمة الذكاء الاصطناعي ستصبح أكثر ذكاءً بكثير من الأشخاص أو الأنظمة التي تراقبها. هذا مجال تم دراسته على نطاق واسع، لذا قدم ملخصًا موجزًا لبعض المشكلات:
تدريب أنظمة الذكاء الاصطناعي على عدم الكذب أو الغش هو عملية دقيقة وغير متوقعة (على سبيل المثال، على الرغم من الجهود المبذولة لبناء اختبارات جيدة للبيئة، أحيانًا تكون أفضل طريقة للذكاء الاصطناعي لحل المشكلة هي الغش، مما يعلمها أن الغش ممكن).
قد تقوم أنظمة الذكاء الاصطناعي بخداعنا من خلال "التمثيل بالتوافق"، حيث تُنتج درجات تجعلنا نعتقد أنها تؤدي بشكل جيد، لكنها في الواقع تخفي نواياها الحقيقية. (بشكل عام، تمكّنت أنظمة الذكاء الاصطناعي من اكتشاف متى تكون قيد الاختبار.)
· مع بدء أنظمة الذكاء الاصطناعي في المشاركة بشكل أكبر في جدول أعمال البحث الأساسي لتدريبها الخاص، قد نغير بشكل كبير طريقة تدريب أنظمة الذكاء الاصطناعي بأكملها، دون وجود حدس أو أساس نظري جيد لفهم ما يعنيه ذلك.
· عندما تضع نظامًا ما في حلقة تكرارية، تنشأ مشكلة "تراكم الأخطاء" الأساسية التي قد تؤثر على جميع المشكلات المذكورة أعلاه ومشكلات أخرى: ما لم يكن أسلوب محاذاة الخاص بك "دقيقًا بنسبة 100%" وقادرًا نظريًا على الحفاظ على هذا الدقة بشكل مستمر في أنظمة أكثر ذكاءً، فقد تحدث أخطاء بسرعة. على سبيل المثال، إذا كانت دقة تقنيتك الأولية 99.9%، فقد تنخفض إلى 95.12% بعد 50 جيلًا، وإلى 60.5% بعد 500 جيل.
كل شيء يتعلق بالذكاء الاصطناعي سيحصل على مضاعف إنتاجية هائل: مثلما يزيد الذكاء الاصطناعي من إنتاجية مهندسي البرمجيات بشكل كبير، يجب أن نتوقع أن يحدث نفس الشيء في مجالات أخرى تتضمن الذكاء الاصطناعي. وهذا يطرح عدة قضايا تحتاج إلى معالجة:
· عدم المساواة في الوصول إلى الموارد: إذا استمر الطلب على الذكاء الاصطناعي في تجاوز إمدادات الموارد الحسابية، فسنحتاج إلى تحديد كيفية توزيع الذكاء الاصطناعي لتحقيق أقصى فائدة اجتماعية. أنا متشكك في قدرة الحوافز السوقية على ضمان تحقيق أفضل عائد اجتماعي من الموارد الحسابية المحدودة للذكاء الاصطناعي. تحديد كيفية توزيع القدرة المتسارعة الناتجة عن تطوير الذكاء الاصطناعي سيكون قضية شديدة الطابع السياسي.
قانون أملدال الاقتصادي: مع دخول الذكاء الاصطناعي إلى الاقتصاد، سنكتشف أن بعض الحلقات تواجه عوائق عند مواجهة النمو السريع، وتحتاج إلى إيجاد طرق لإصلاح نقاط الضعف في هذه السلسلة. وقد يكون هذا واضحًا بشكل خاص في المجالات التي تتطلب تنسيقًا بين العالم الرقمي السريع والعالم المادي البطيء، مثل التجارب السريرية للأدوية الجديدة.
3. تشكيل اقتصاد كثيف الرأسمال وخفيف العمالة: تشير جميع الأدلة المذكورة أعلاه حول تطوير الذكاء الاصطناعي أيضًا إلى أن أنظمة الذكاء الاصطناعي تكتسب قدرة متزايدة على تشغيل الشركات بشكل مستقل.
هذا يعني أنه يمكننا توقع أن جزءًا من الاقتصاد سيتم احتلاله من قبل شركات الجيل الجديد، والتي قد تكون كثيفة الرأسمال (لأنها تمتلك كميات كبيرة من الحواسيب) أو كثيفة تكاليف التشغيل (لأنها تنفق مبالغ كبيرة على خدمات الذكاء الاصطناعي وتخلق قيمة عليها)، مقارنة بالشركات اليوم، وهي تعتمد بشكل أقل نسبيًا على القوى العاملة البشرية—لأنه مع استمرار تعزيز قدرات أنظمة الذكاء الاصطناعي، فإن القيمة الحدية للإدخال في الذكاء الاصطناعي ستستمر في النمو.
في الواقع، سيظهر هذا كـ "الاقتصاد الآلي" الذي يتشكل تدريجيًا داخل "الاقتصاد البشري" الأكبر، ومع مرور الوقت، قد تبدأ الشركات التي تديرها الذكاء الاصطناعي في التبادل التجاري مع بعضها البعض، مما يغير البنية الاقتصادية ويثير قضايا متعددة حول عدم المساواة وإعادة التوزيع. في النهاية، قد تظهر شركات تعمل بالكامل من خلال أنظمة ذكاء اصطناعي ذاتية التشغيل، مما سيُفاقم المشكلات المذكورة أعلاه ويوفر تحديات حوكمة جديدة كثيرة.
النظر إلى الثقب الأسود
بناءً على هذا التحليل، يرى الكاتب أن احتمال رؤية تطوير الذكاء الاصطناعي التلقائي (أي قدرة النماذج الرائدة على تدريب إصداراتها التالية بشكل مستقل) بحلول نهاية عام 2028 هو حوالي 60%. لماذا لا يتوقع ظهوره في عام 2027؟
السبب هو أن المؤلف يعتقد أن أبحاث الذكاء الاصطناعي لا تزال بحاجة إلى الإبداع والرؤى المخالفة للتقدم، ولم تُظهر أنظمة الذكاء الاصطناعي حتى الآن هذا الأمر بطريقة ثورية وجوهرية (على الرغم من أن بعض النتائج في تسريع أبحاث الرياضيات لها دلالات).
إذا اضطررنا إلى طلب احتمال عام 2027، فسيقول 30%.
إذا لم تظهر بحلول نهاية عام 2028، فقد نكشف عن بعض العيوب الجذرية في النموذج التقني الحالي، مما يتطلب ابتكارًا بشريًا لدفع التطور المستمر.