









بڑے ماڈلز لگاتار بڑھ رہے ہیں، اور عام رائے یہ ہے کہ جتنا زیادہ ماڈل کے پیرامیٹرز ہوں، اتنا ہی وہ انسانی سوچ کے قریب پہنچ جائے گا۔ تاہم، زج یونیورسٹی کی ٹیم نے 1 اپریل کو Nature Communications پر ایک تحقیقی مقالہ جاری کیا جس میں الگ خیال پیش کیا گیا (اصل لنک:https://www.nature.com/articles/s41467-026-71267-5)۔ انہوں نے پایا کہ جب ماڈلز (بنیادی طور پر SimCLR، CLIP، DINOv2) کا سائز بڑھتا ہے، تو مخصوص چیزوں کو پہچاننے کی صلاحیت لگاتار بہتر ہوتی رہتی ہے، لیکن تصوراتی تصورات کو سمجھنے کی صلاحیت نہ تو بڑھتی ہے اور نہ ہی مستقل رہتی ہے، بلکہ کم ہوتی جاتی ہے۔ جب پیرامیٹرز 22.06 ملین سے بڑھ کر 304.37 ملین ہو گئے، تو مخصوص تصورات کے امتحان میں درجات 74.94% سے بڑھ کر 85.87% ہو گئے، جبکہ تصوراتی تصورات کے امتحان میں درجات 54.37% سے گھٹ کر 52.82% ہو گئے۔
انسان اور ماڈل کے سوچنے کے طریقے میں فرق
انسانی دماغ جب تصورات کو سمجھتا ہے، تو پہلے ایک طبقہ بندی کا نظام تشکیل دیتا ہے۔ ہنس اور چھیڑچھاڑ کا شکل میں فرق ہوتا ہے، لیکن انسان ان دونوں کو پرندوں کی قسم میں شامل کر دیتا ہے۔ اس سے اوپر، پرندے اور گھوڑے دونوں جانوروں کی زمرہ میں آ جاتے ہیں۔ جب انسان کو کوئی نیا چیز دکھائی دیتی ہے، تو وہ عام طور پر سوچتا ہے کہ یہ اس کے پہلے دیکھے گئے کسی چیز کے相似 ہے اور یہ کس زمرے میں آتی ہے۔ انسان نئے تصورات سیکھتا رہتا ہے اور اپنے تجربات کو منظم کرتا رہتا ہے تاکہ اس طبقہ بندی کے ذریعے نئی چیزوں کی شناخت کر سکے اور نئی صورتحال کے مطابق اپنے آپ کو ڈھال سکے۔
ماڈلز بھی درجہ بندی کرتے ہیں، لیکن ان کا تشکیل پانے کا طریقہ مختلف ہے۔ یہ بنیادی طور پر بڑے پیمانے پر ڈیٹا میں دہرائے جانے والے فارم کے ذریعے کام کرتے ہیں۔ جتنا زیادہ کوئی خاص شے ظاہر ہوتی ہے، ماڈل اسے اتنا ہی آسانی سے پہچانتا ہے۔ جب بڑے درجات تک پہنچتے ہیں، تو ماڈل کو مشکل ہوتی ہے۔ اسے متعدد شیوں کے درمیان مشترکہ خصوصیات کو پکڑنا ہوتا ہے، اور پھر ان مشترکہ خصوصیات کو ایک ہی فہرست میں شامل کرنا ہوتا ہے۔ موجودہ ماڈلز کو یہاں واضح کمیاں ہیں۔ جب پیرامیٹرز مزید بڑھائے جاتے ہیں، تو خاص تصورات کے کام بہتر ہوتے ہیں، جبکہ تصوراتی تصورات کے کام کبھی کبھار کم ہوتے ہیں۔

انسانی دماغ اور ماڈل کے درمیان مشترکہ بات یہ ہے کہ دونوں کے اندر ایک طرح کی درجہ بندی کا نظام تشکیل پاتا ہے۔ لیکن دونوں کا زور مختلف ہے: انسانی دماغ کے اعلیٰ بصری علاقوں میں خودبخود جاندار اور غیر جاندار جیسے بڑے زمرے بن جاتے ہیں۔ جبکہ ماڈل مخصوص اشیاء کو الگ کر سکتا ہے، لیکن اس قسم کے بڑے زمرے بنانے میں مستقل طور پر کامیاب نہیں ہوتا۔ یہ فرق کی وجہ سے انسانی دماغ پرانے تجربات کو نئی اشیاء پر آسانی سے لاگو کر سکتا ہے، اس لیے جب ہم کسی نئی چیز کا سامنا کرتے ہیں تو ہم تیزی سے درجہ بندی کر لیتے ہیں۔ جبکہ ماڈل زیادہ تر موجودہ علم پر انحصار کرتا ہے، اس لیے نئی اشیاء کے سامنے وہ صرف سطحی خصوصیات پر ہی رک جاتا ہے۔ تحقیقی مقالے میں پیش کی گئی یہ طریقہ اس خصوصیت پر مبنی ہے جس میں دماغ کے سگنلز کو استعمال کرکے ماڈل کے اندر کے ساخت کو محدود کیا جاتا ہے تاکہ وہ انسانی دماغ کی درجہ بندی کے طریقے کے قریب آ جائے۔
زجیان ٹیم کا حل
ٹیم کی طرف سے پیش کیا گیا حل بھی منفرد ہے، جس میں صرف پیرامیٹرز کا اضافہ نہیں کیا گیا، بلکہ تھوڑے سے مغز کے سگنلز کو سپروائزڈ کیا گیا۔ یہاں مغز کے سگنلز، انسانوں کی تصاویر دیکھتے وقت کے مغز کی سرگرمیوں کے ریکارڈز سے حاصل کیے گئے ہیں۔ پیپر میں لکھا گیا ہے کہ human conceptual structures کو DNNs میں transfer کیا جائے۔ اس کا مطلب ہے کہ انسانی مغز کس طرح طبقہ بندی کرتا ہے، کس طرح خلاصہ کرتا ہے، اور کس طرح قریبی تصورات کو اکٹھا کرتا ہے، اسے ماڈل کو جتنا ممکن ہو اس قدر سکھایا جائے۔
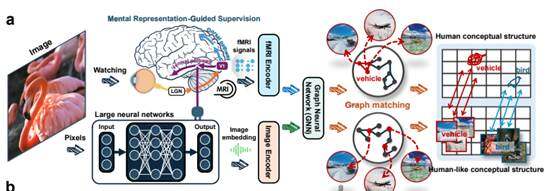
ٹیم نے 150 معلوم تربیتی اقسام اور 50 نئی ٹیسٹ اقسام کے ساتھ تجربہ کیا۔ نتائج نے ظاہر کیا کہ تربیت کے ساتھ ساتھ ماڈل اور مغز کے نمائندگی کے درمیان فاصلہ مستقل طور پر کم ہوتا رہا۔ یہ تبدیلی دونوں اقسام میں ظاہر ہوئی، جس سے ثابت ہوتا ہے کہ ماڈل صرف اکیلے نمونوں کو نہیں سیکھ رہا، بلکہ اب وہ انسانی مغز کے قریب تر مفہومی تنظیم کو سیکھ رہا ہے۔
اس تربیت کے بعد، ماڈل کم نمونوں کے ساتھ زیادہ بہتر سیکھنے کی صلاحیت رکھتا ہے اور نئی صورتحال کے لیے بہتر پرفارم کرتا ہے۔ ایک ایسے کام میں جہاں صرف بہت کم مثالیں دی گئیں تھیں اور ماڈل کو زندہ اور غیر زندہ اشیاء جیسے انتزاعی تصورات کو الگ کرنے کا مطالبہ کیا گیا، ماڈل نے اوسطاً 20.5% کا بہتری دکھائی اور اس سے کہیں زیادہ پیرامیٹرز والے مقابلہ کرنے والے ماڈلز کو پیچھے چھوڑ دیا۔ ٹیم نے مزید 31 الگ ٹیسٹ بھی کیے، جن میں تمام قسم کے ماڈلز نے تقریباً 10 فیصد کی بہتری دکھائی۔
گزشتہ کچھ سالوں میں ماڈل صنعت کے لیے متعارف راستہ بڑے ماڈل سائز تھا۔ زجیانگ یونیورسٹی کی ٹیم نے ایک دوسری راہ اختیار کی، جس میں "بڑا بہتر ہے" کی جگہ "منظم بہتر ہے" کا خیال آیا۔ سائز میں اضافہ بالکل مفید ہے، لیکن یہ بنیادی طور پر پہلے سے جانے گئے کاموں میں کارکردگی میں اضافہ کرتا ہے۔ انسانوں جیسی تصوراتی سمجھ اور منتقلی کی صلاحیت AI کے لیے بھی انتہائی اہم ہے، جس کے لیے مستقبل میں AI کی سوچنے کی ساخت کو انسانی دماغ کے قریب لانا ہوگا۔ اس راہ کا اہمیت یہ ہے کہ یہ صنعت کا توجہ صرف سائز میں اضافے سے دوبارہ认知 ساخت کی طرف موڑ دیتا ہے۔
نیوسول اور مستقبل
یہ ایک بڑی امکان کی طرف لے جاتا ہے کہ AI کی ترقی صرف ماڈل ٹریننگ کے مراحل تک محدود نہیں ہے۔ ماڈل ٹریننگ AI کو اپنے تصورات کو کیسے منظم کرنے اور زیادہ معیاری ججمنٹ کی ساخت بنانے کا طریقہ سکھا سکتی ہے۔ جب یہ حقیقی دنیا میں داخل ہوتا ہے، تو AI کی دوسری سطح کی ترقی صرف شروع ہوتی ہے: AI ایجنٹ کے ججمنٹس کو کیسے ریکارڈ کیا جائے، کیسے چیک کیا جائے، اور حقیقی مقابلے میں مستقل طور پر کیسے بڑھے اور خود کو ترقی دے، جیسے انسان خود سیکھتا اور خود کو ترقی دेतا ہے۔ اسی کو Neosoul ابھی انجام دے رہا ہے۔ Neosoul صرف AI ایجنٹ کو جواب دینے کے لیے نہیں چھوڑتا، بلکہ اسے ایک مستقل پیشگوئی، مستقل تصدیق، مستقل سیٹلمنٹ، اور مستقل فلٹرنگ کے نظام میں ڈالتا ہے تاکہ وہ پیشگوئی اور نتائج کے درمیان اپنے آپ کو بہتر بناتا رہے، بہتر ساختوں کو برقرار رکھا جائے اور بدتر ساختوں کو ختم کر دیا جائے۔ زجداں ٹیم اور Neosoul دونوں اصل میں ایک ہی مقصد کی طرف اشارہ کر رہے ہیں: AI صرف سوالات حل کرنے والا نہ ہو، بلکہ مکمل سوچنے کی صلاحیت رکھے اور مستقل طور پر ترقی کرتا رہے۔