









لکھاری:ٹینا، ڈنگ می،InfoQ
1. تقریباً تین سال بعد، مسک کے ایکس تجویز الگورتھم کو دوبارہ سے آزاد کر دیا گیا
تازہ ہی X انجینئرنگ ٹیم نے X پر پوسٹ کر کے اعلان کیا ہے کہ وہ X کے تجویز کن الگورتھم کو آفیشل طور پر آپن سورس کر رہے ہیں۔ معلومات کے مطابق، یہ آپن سورس لائبریری X پر "اُمی" (For You) فیڈ کو سپورٹ کرنے والی کور تجویز کن سسٹم کو شامل کرتی ہے۔ یہ ڈیٹا ورچوئل نیٹ ورک کے اندر کے مواد (صارف کے فالو کردہ اکاؤنٹس سے) اور نیٹ ورک کے باہر کے مواد (ماشین لرننگ کی بنیاد پر ریٹریول کے ذریعے دریافت کیا گیا) کو جوڑتا ہے، اور تمام مواد کو رینکنگ کے لیے گروک کی بنیاد پر ٹرانسفارمر ماڈل کا استعمال کرتا ہے۔ دوسرے الفاظ میں، یہ الگورتھم گروک کے ٹرانسفارمر ڈیزائن کا استعمال کرتا ہے۔
میگھر کوڈ کا ایڈریس: https://x.com/XEng/status/2013471689087086804
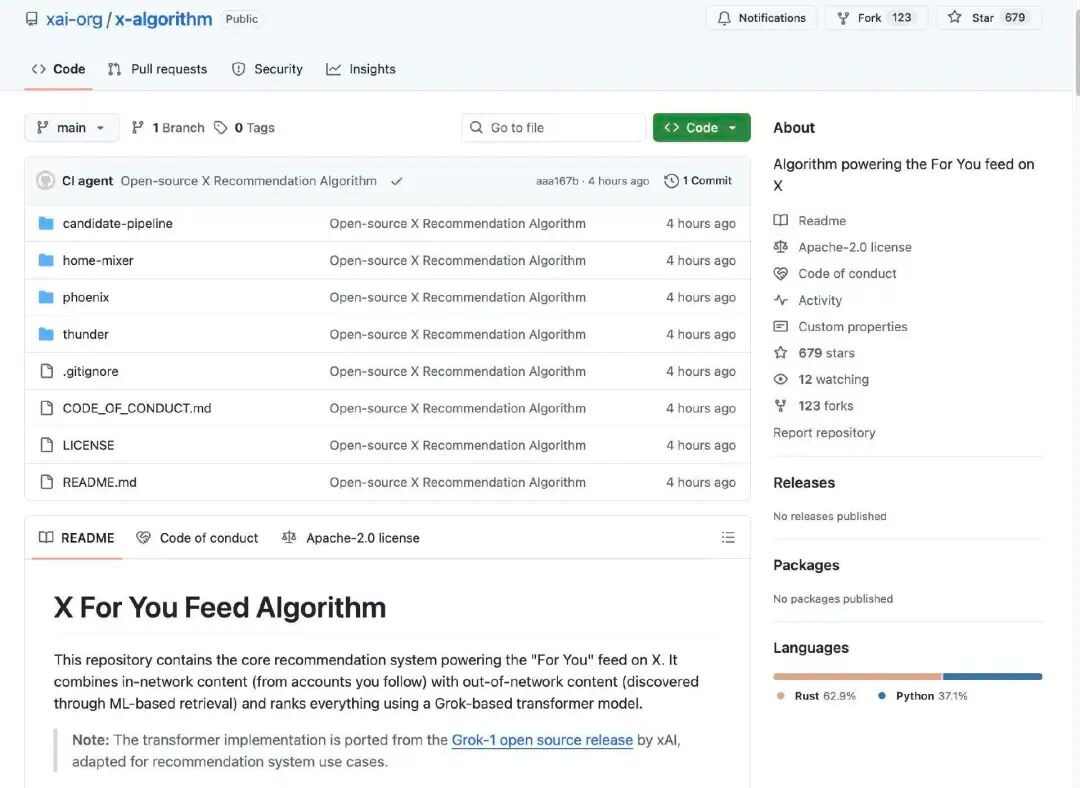
X کے ریکامنڈیشن الگورتھم کا کام یہ ہوتا ہے کہ وہ ایکس کی گھریلو اسکرین پر صارف کو د"آپ کے لیے" (For You Feed) مواد. اس کے دو اصلی ذرائع ہیں جو اسے امیدوار پوسٹس دیتے ہیں:
اکاونٹس جن کا آپ نے خیال رکھا ہے (In-Network / Thunder)
دیگر پوسٹس ملی ہیں جو پلیٹ فارم پر (Out-of-Network / Phoenix)
ان ممکنہ مواد کو بعد میں ایک جیسی طریقے سے پر کیا جاتا ہے، فلٹر کیا جاتا ہے، پھر اہمیت کے حساب سے ترتیب دیا
اچھا، الگورتھم کے اصل ڈھانچہ اور کارکردگی کا منطق کیسا ہے؟
الگورتھم ابتدا دو قسم کے ذرائع سے ممکنہ مواد حاصل کرتا ہے:
دیکھی گئی چیزیں: ایسی پوسٹس جو آپ نے خود اپنی پسند سے فالو کی ہیں۔
غیر متعلقہ مواد: سسٹم کے ذریعہ مجموعی مواد کی فہرست میں سے تلاش کیے گئے امکانی طور پر آپ کے دل چسپی رکھنے والے پوسٹس۔
اس مراحل کا مقصد "متعلقہ پوسٹس کو ڈھونڈنا ہے۔"
سستم خودکار طرز کم معیار، دوہری، غیر قانونی یا ناموزون مواد کو ہٹا دیتا ہے۔ مثلاً:
ممنوعہ اکاؤنٹ کا محتوٰى
وہ موضوع جو صارف کو دلچسپی نہیں دیتے
غیر قانونی، پرانہ یا نااہل پوسٹ
اس طریقہ یقینی بناتا ہے کہ آخری ترتیب میں صرف اہم ممکنہ مواد کا سامنا کیا جائے۔
ایلی چنل اوریئنٹڈ الگورتھم کا مرکزی حصہ سسٹم کا ایک گروک-بیسڈ ٹرانسفارمر ماڈل (بڑے زبان ماڈل / گہری تعلیمی نیٹ ورک کی طرح) ہے جو ہر امیدوار پوسٹ کو اسکور کرتا ہے۔ ٹرانسفارمر ماڈل ہر کارروائی کی احتمال کی پیش گوئی کرتا ہے جو صارف کے تاریخی رویوں (لائک، جواب، شیئر، کلک وغیرہ) کی بنیاد پر ہوتی ہے۔ آخر میں، ان کارروائی کے احتمال کو وزنی طور پر مل کر ایک مجموعی اسکور بنایا جاتا ہے، جو زیادہ اسکور والی پوسٹ کو صارف کو سفارش کرنے کی زیادہ امکان ہوتا ہے۔
اس میں ڈیزائن میں روایتی ہاتھ سے خصوصیات کو نکالنے کے عمل کو تقریباً ختم کر دیا گیا ہے اور صارف کے دلچسپی کی پیشن گوئی کے لیے ابتدائی سے انجام تک تعلیمی عمل کا استعمال کیا جاتا
یہ مسک کی ایکس کے تجویز الگورتھم کو آپن کرنے کی پہلی دفعہ نہیں ہے۔
2023ء کے مارچ 31 کو ٹوئٹر کو خریدنے کے وعدے کے مطابق مسکر نے ٹوئٹر کے کچھ سرچشمہ کوڈ کو رسمی طور پر آزاد کر دیا جس میں صارفین کی ٹائم لائنز میں ٹوئٹس کی سفارش کرنے والے الگورتھم کو شامل کیا گیا۔اُس کھولنے کے دن ہی اس منصوبے کو گٹ ہب پر 10k+ سٹار مل چکے تھے۔
اس ماسک نے اس وقت ٹوئٹر پر کہا کہ اس اشاعت کا مقصد تھا"اکثر تجویز الگورتھم"ان کے علاوہ دیگر الگورتھم بھی آہستہ آہستہ منظر عام پر لائے جائیں گے ۔ اس نے مزید کہا کہ امید ہے کہ "مستقل تیسرے فریق ایسے مضامین کی مناسب تفصیل کے ساتھ تشخیص کر سکیں جو ٹویٹر صارفین کو دکھا سکتا ہے "۔
اسپیس چیٹ میں الگورتھم کے اعلان کے حوالے سے، اس نے کہا کہ اس کا مقصد ٹوئٹر کو "انٹرنیٹ کا سب سے شفاف نظام" بنانا ہے، اور اسے سب سے مشہور اور کامیاب مفت ذریعہ کی طرح مضبوط بنانا ہے، لینکس۔ "اصل مقصد یہ ہے کہ ٹوئٹر کو جاری رکھنے والے صارفین کو یہاں سب سے زیادہ فائدہ حاصل ہو۔"
ابراہیم مسک کے X الگورتھم کو آزاد کر دینے کے تقریبا تین سال گزر چکے ہیں۔ اور ٹیکنالوجی کے میدان میں ایک سپر کیو ایل کے طور پر، مسک نے اس بار آزاد کر دینے کی کافی تیاری کر لی ہے۔
11 جنوری کو مسکز نے ایکس پر پوسٹ کی کہ وہ 7 دن کے اندر نئے ایکس الگورتھم (جس میں صارفین کو کونسی قسم کی قطعی تلاشی معلومات اور تبلیغات کی سفارش کرنے کے لیے استعمال ہونے والے تمام کوڈ کو شامل کیا گیا ہے) کو اوپن سورس کر دیں گے۔
اس روایت 4 ہفتہ بعد دوبارہ شروع ہو گا اور تفصیلی ترقیاتی وضاحتیں شامل ہوں گی تاکہ صارفین کو یہ بتایا جا سکے کہ کیا تبدیلیاں ہو رہی ہیں۔
آج اس کا وعدہ دوبارہ پورا ہو گیا۔
2. مسک کیوں اوپن سورس کر رہے ہیں؟
جب ایلون مسک جب "اُر سورس" کا نام لے تو اس کا پہلا رد عمل ٹیکنالوجی کے مثیلہ سوچ کی بجائے حقیقی دباؤ کی طرف اشارہ کرتا ہے۔
گذشتہ سال X اپنے محتوائی تقسیم کے نظام کی وجہ سے متعدد دفعہ تنازعات میں مبتلا رہا۔ اس پلیٹ فارم کو الگورتھم کی سطح پر دائیں بازو کے موقف کی حمایت اور اس کی ترقی کے لیے ترجیح دینے کی وسیع پیمانے پر مذمت کی گئی۔ اس قسم کی مثالیں نہ تو کمیاب ہیں اور نہ ہی اتفاقیہ ہیں بلکہ اس کو سسٹمی طور پر سمجھا جاتا ہے۔ ایک تحقیقاتی رپورٹ گذشتہ سال جاری کی گئی جس میں X کے سفارشی نظام میں سیاسی محتوا کے پھیلاؤ کے حوالے سے واضح طور پر نئی طرف مائلی کا ذکر کیا گیا۔
اس کے ساتھ ساتھ کچھ انتہائی واقعات نے مزید سوالات کو سامنے لایا۔ ایک سال قبل، ایک غیر تصدیق شدہ ویڈیو جو امریکی دائیں بازو کے سیاست دان چارلی کارک کے قتل سے متعلق تھی، پلیٹ فارم ایکس پر تیزی سے پھیل گئی اور عام آدمی کی توجہ حاصل کی۔ تنقید کاروں کا کہنا ہے کہ یہ نہ صرف پلیٹ فارم کے معیاری جائزہ کے نظام کی ناکامی کو ظاہر کرتا ہے بلکہ الگورتھم کے "کس چیز کو بڑھانے اور کس چیز کو نہیں" کے معاملے میں دوبارہ سے توجہ مرکوز کر دی ہے۔ چھپا ہوا اختیار
ایسے سیاسی اور معاشی ماحول میں مسکو کی طرف سے اچانک الگورتھم شفافیت کی طرف توجہ دلانا کسی سادہ ٹیکنیکی فیصلے کی طرح نہیں دیکھا جا سکتا۔

3. آن لائن صارفین کیا کہتے ہیں؟
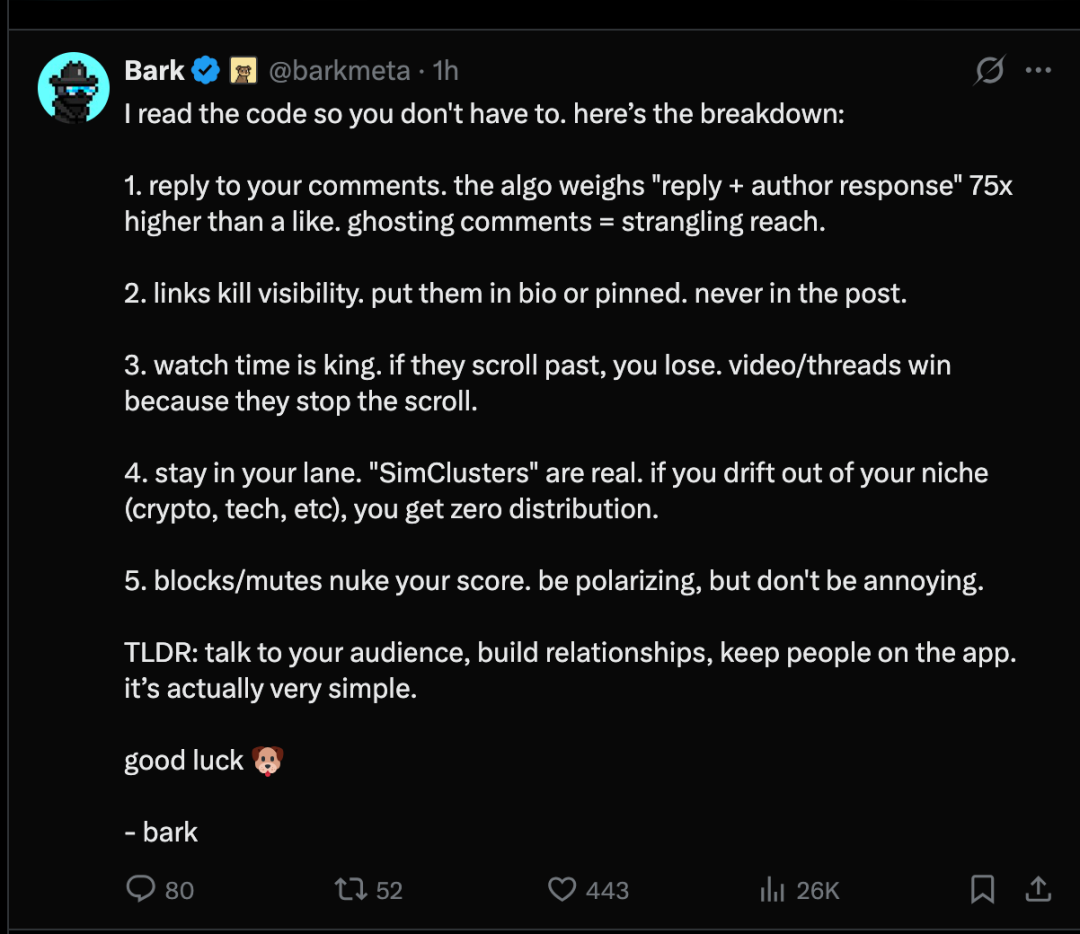
X کے تجویز کن الگورتھم کو آپرنس کرنے کے بعد X پلیٹ فارم پر صارفین نے تجویز کن الگورتھم کے میکانیزم پر 5 نکاتی خلاصہ پیش کیا ہے:
- آپ کے تبصرے کا جواب دیں۔"جواب + مصنف کا جواب" کا وزن الگورتھم میں 75 گنا لائک کے برابر ہے۔ کمنٹس کا جواب نہ دینا اظہار کو بہت متاثر کر سکتا ہے۔
- لینک کی وجہ سے دکھائی دینے کی شرح کم ہلینک کو ذاتی تعارف یا ٹاپ ٹاپک میں رکھنا چاہیے، یقیناً اسے پوسٹ کے متن میں نہیں رکھنا چاہیے۔
- دیکھنے کی مدت بہت اہم ہےاگر وہ اسکرین پر اسکرول کر کے چلے جائیں تو آپ ان کو متوجہ نہیں کر سکیں گے۔ ویڈیوز / پوسٹس کو زیادہ توجہ ملتی ہے کیونکہ وہ صارفین کو رکنے پر مجبور کرتی ہیں۔
- اپنے میدان کو مضبوطی سے"سیم ہیپ" واقعی ہے۔ اگر آپ اپنے نوکری کے شعبے (کرپٹو کرنسی، ٹیکنالوجی وغیرہ) سے ہٹ جاتے ہیں تو آپ کو کوئی بھی ڈسٹری بیوشن کے ذریعے حاصل نہیں ہوں گے۔
- چھپانا / خاموش رہنا آپ کے اسکور کو کافی حد تک کم کر دے گاقابل بحث ہونا چاہیے لیکن نفرت نہ کرے۔
خاصل کریں: اپنی مخاطب کے ساتھ رابطہ کریں، تعلقات قائم کریں، اور صارفین کو ایپ میں رکھیں۔ یہ بہت آسان ہے۔
اُن افراد نے بھی نوٹ کیا ہے کہ ہاں چیمپئن شپ کھلی ہے لیکن کچھ چیزیں اب بھی کھلی نہیں ہیں۔ اس شخص نے کہا کہ اس اشاعت کی بنیادی طور پر ایک فریم ورک ہے، انجن نہیں۔ کون سی چیزیں کم ہیں؟
وزن پارامیٹر درکار ہے - کوڈ نے "مثبت رویوں کو اضافی نمبر دیں" اور "منفی رویوں کو کم کریں" کی تصدیق کی ہے، لیکن 2023 کی نسخہ سے مختلف یہ ہے کہ خاصی اقدار حذف کر دی گئی ہیں۔
چھپائی گئی مالیت کا - ماڈل کے خود کے اندر کے پارامیٹرز اور گणنہ شامل نہیں ہیں۔
غیر منشرون ٹریننگ ڈیٹا - ہمیں تربیتی ماڈل کے لیے ڈیٹا، صارفین کے رویوں کی نمونہ اخذ کی حکمت عملی اور "اچھے" اور "بُرے" نمونوں کی تعمیر کے بارے میں کچھ بھی نہیں معلوم ہے۔
اکثر X کے صارفین کے لیے، الگورتھم کا سرچھپا ہونا کوئی بڑا فرق نہیں پڑے گا۔ لیکن زیادہ شفافیت یہ واضح کر سکتی ہے کہ کیوں کچھ پوسٹس دیکھی جاتی ہیں اور کچھ نہیں، اور اس کے ذریعے ماہرین تحقیق کرسکتے ہیں کہ پلیٹ فارم محتویات کو کس طرح رینک کرتا ہے۔
4. یہ کیوں کہا جاتا ہے کہ سفارشی نظام جیتنے کی چیز ہے؟
زیادہ تر ٹیکنیکل گفتگوؤں میں،racommend systemیہ عام طور پر پس پردہ انجینئرنگ کا حصہ سمجھا جاتا ہے، یہ کم ظاہر ہونے والی، پیچیدہ چیز ہے، لیکن اکثر روشنی کے چراغوں کے سامنے نہیں آتی۔ لیکن اگر واقعی انٹرنیٹ کے بڑے چہرے کی کاروباری چارچی کو تحلیل کیا جائے تو یہ پتہ چلتا ہے کہ تجویز کرنے والی سسٹم کوئی سطحی ماڈل نہیں ہے بلکہ کاروباری ماڈل کے سارے نظام کی حمایت کرنے والی "بنیادی ڈھانچہ سطحی موجودگی" ہے۔ اسی وجہ سے، اسے انٹرنیٹ صنعت کا "سکوت کا عظیم جانور" کہا جا سکتا ہے۔
اُسکی تصدیق عام دستیابی داری معلومات کریز کر چک کی گئی ہے۔ ایمیزون نے ظاہر کیا ہے کہ اُس کے پلیٹ فارم پر تقریباً 35 فیصد خریداری سسٹم کی سفارشات کے نتیجے میں ہوتی ہے؛ نیٹ فلیکس کی سفارشات کے حوالے سے مزید واضح ہے، تقریباً 80 فیصد دیکھنے کا وقت سفارشات کے الگورتھم کے ذریعے ہوتا ہے؛ یو ٹیوب کی حالت بھی اسی طرح ہے، تقریباً 70 فیصد دیکھنے کا وقت سفارشات کے سسٹم، خصوصاً فیڈ کے ذریعے ہوتا ہے۔ میٹا کے بارے میں، چاہے واضح تناسب ظاہر نہ کیا گیا ہو، لیکن اُس کا ٹیکنیکی ٹیم کہہ چکا ہے کہ کمپنی کے اندر کمپیوٹنگ کلب کے تقریباً 80 فیصد کمپیوٹنگ سائیکل سفارشات کے متعلق کام کی خدمت کے لیے استعمال ہوتے ہیں۔
یہ اعداد و شمار کیا ظاہر کر رہے ہیں؟اگر سفارشی کردہ نظام کو ان مصنوعات سے ہٹا دیا جائے تو یہ زمین کے فرش کو اتارنے کے برابر ہےمیٹا کی مثال لیجیے، اشتہارات کی ترسیل، صارفین کی چپقلش، تجارتی تبدیلیاں، تقریبا ہر چیز تجویز کن نظام پر مبنی ہے۔ تجویز کن نظام نہ صرف یہ فیصلہ کرتا ہے کہ صارف کیا دیکھے گا بلکہ یہ بھی فوری طور پر فیصلہ کرتا ہے کہ پلیٹ فارم کیسے کمائی کرے گا۔
تاہم یہ ایک ایسا نظام ہے جو زندگی اور موت کا فیصلہ کرتا ہے، جو درازہوائی میں بہت زیادہ تکنیکی پیچیدگی کا سامنا کر رہا ہے۔
کلاسک ریکامنڈیشن سسٹم ارکیٹیکچر میں، ایک یونیفارم ماڈل کے ذریعے تمام سکینریوز کو ڈھانپنا مشکل ہے۔ واقعیت میں، پروڈکشن سسٹم بہت فریکچر ہوتے ہیں۔ میٹا، لینکڈ ان، نیٹ فلکس جیسی کمپنیوں کے مثال کے طور پر، ایک مکمل ریکامنڈیشن چین کے پیچھے عام طور پر 30 یا اس سے زیادہ خصوصی ماڈلز کام کر رہے ہوتے ہیں: ریکال ماڈل، کوئس فلٹر ماڈل، فائن فلٹر ماڈل، ری رینک ماڈل، ہر ایک مختلف مقاصد کے فنکشنز اور کاروباری اشاریوں کو بہتر بنانے کے لیے۔ ہر ماڈل کے پیچھے عام طور پر ایک یا اس سے زیادہ ٹیمیں ہوتی ہیں جو خصوصیات کی انجینئرنگ، تربیت، پیرامیٹرز کو بدلنا، چلائو اور جاری رکھنے کے لیے ذمہ دار ہوتی ہیں۔
اس کی قیمت واضح ہے: انجینئرنگ کی پیچیدگی، بہت زیادہ مینٹیننس کی لاگت، مختلف کاموں کے درمیان تعاون کی مشکل۔ جب کوئی شخص سوال کرتا ہے کہ "کیا ہم ایک ماڈل کے استعمال سے مختلف سفارشات کے مسائل حل کر سکتے ہیں؟" تو یہ سارے سسٹم کے لیے پیچیدگی کی سطح کو کم کر دیتا ہے۔ یہی صنعت کا ایک اہم اور طویل عرصے سے چاہا ہوا لیکن حاصل نہ ہونے والا مقصد ہے۔
بڑے زبان ماڈلز کی موجودگی نے سفارشی نظام کے لیے ایک نیا ممکنہ راستہ فراہم کیا ہے۔
ایل ایم ال (LLM) کی ایک قدرتی مثال ہے کہ یہ ایک بہت قوی عام مقاصد کا ماڈل کیسے بن سکتا ہے: مختلف کاموں کے درمیان ٹرانسفر کرنے کی صلاحیت ہوتی ہے، اور جب ڈیٹا کے سائز اور کمپیوٹنگ کی طاقت بڑھتی ہے تو اس کی کارکردگی میں مسلسل بہتری آتی ہے۔ دوسری طرف، روایتی سفارشاتی ماڈل عام طور پر "کام کے مطابق" ہوتے ہیں، اور مختلف سیٹنگز کے درمیان صلاحیتوں کی شئیرنگ کرنا مشکل ہوتا ہے۔
اہم بات یہ ہے کہ ایک ہی بڑے ماڈل کے ذریعے نہ صرف انجینئرنگ کو سادہ بنایا جا سکتا ہے بلکہ "چارج کرکے سیکھنے" کی صلاحیت بھی حاصل ہو سکتی ہے۔ جب ایک ہی ماڈل مختلف سفارشات کے کاموں کو ہم ایک ساتھ سنبھال رہا ہو تو مختلف کاموں کے سگنل ایک دوسرے کو مکمل کر سکتے ہیں، اور جیسے ہی ڈیٹا کے حجم میں اضافہ ہوتا ہے، ماڈل کو مجموعی طور پر ترقی کرنے میں آسانی ہوتی ہے۔ یہی وہ خصوصیت ہے جس کی سفارشی نظاموں کو طویل عرصے سے ضرورت تھی لیکن روایتی طریقے سے حاصل کرنا مشکل تھ
اے ایل ایم نے کیا تبدیل کیا؟ اصل میں یہ خصوصیات کی تعمیر سے سمجھ کی صلاحیت تک تبدیل کر گیا۔
اکثر تبدیلیاں جو LLM نے سفارشی نظام میں میتھڈالوجی کی سطح پر کی ہیں وہ "سمیتی کھوج" کے اہم مرحلے میں ہوئی ہیں۔
کلاسک تجویز کی سسٹم میں، انجینئرز کو پہلے بڑی تعداد میں سگنلز کی مدد سے کام کرنا ہوتا ہے: صارف کی کلک کرنے کی تاریخ، وقت کی مدت، مشابہ صارفین کی ترجیحات، مواد کے ٹیگز وغیرہ، پھر وہ واضح طور پر ماڈل کو بتاتے ہیں کہ "براہ کرم ان خصوصیات کی بنیاد پر فیصلہ کریں"۔ ماڈل خود ان سگنلز کے معنی کو سمجھتا ہے، بلکہ صرف تعداد کے فضا میں نقشہ کی تعلیم حاصل کرتا ہے۔
لینگوئسٹک ماڈل متعارف کرانے کے بعد یہ پورا عمل بہت زیادہ تصوری ہو چکا ہے۔ آپ کو اب یہ واضح کرنے کی ضرورت نہیں ہے کہ "اس سگنل کو دیکھو، اس سگنل کو نظرانداز کرو"۔ بلکہ آپ اب ماڈل کو مسئلہ کی خود بیان کر سکتے ہیں: یہ ایک صارف ہے، یہ محتوا ہے؛ یہ صارف اس طرح کے محتوا کو پہلے سے پسند کر چکا ہے، دوسرے صارفین نے اس محتوا کو مثبت جواب دیا ہے۔ اب براہ کرم فیصلہ کریں کہ کیا اس محتوا کو اس صارف کو سفارش کیا جانا چاہیے؟
زبان ماڈل کے پاس خود کو سمجھنے کی صلاحیت موجود ہے، اور یہ خود ہی فیصلہ کر سکتا ہے کہ کون سی معلومات اہم سگنل ہیں اور ان سگنل کو کس طرح مل کر فیصلہ کرنا ہے۔ کسی معنوں میں، یہ صرف سفارشات کے قواعد کو نہیں چلارہا بلکہ "سفاش کی بات کو سمجھ رہا ہے"۔
اس کی صلاحیت کا سبب یہ ہے کہ ایل ایل ایم کو تربیت کے مرحلے میں وسیع اور مختلف ڈیٹا کا سامنا کرایا گیا ہے، جس سے اہم اور ظاہر نہ ہونے والے پیٹرنز کو پکڑنے میں آسانی ہوتی ہے۔ برعکس، روایتی سفارشی نظام کو انجینئروں کے ذریعہ ان پیٹرنز کو صریحاً ترتیب دینے پر انحصار کرنا پڑتا ہے، اور اگر کوئی چیز چھوٹ جائے تو ماڈل اسے محسوس نہیں کر سکتا۔
پچھلے سروں کی طرح یہ تبدیلی نئی نہیں ہے۔ جیسے کہ آپ GPT سے سوال کرتے ہیں، اس کے جوابات ماحولیاتی معلومات کی بنیاد پر تیار ہوتے ہیں۔ اسی طرح، جب آپ اس سے پوچھتے ہیں کہ "کیا مجھے اس مضمون سے دلچسپی ہو گی" تو اس کے پاس موجود معلومات کی بنیاد پر اس کا جواب تیار ہوتا ہے۔ کسی حد تک، زبانی ماڈل کو خود "سجاوٹ" کی صلاحیت سے متصف کیا جا سکتا ہے۔