










اس منظر کو تصور کریں:
آپ نے AI ایجینٹ کو ایک کوڈ بگ درست کرنے کے لیے کہا۔ اس نے پروجیکٹ کھولا، 20 فائلیں پڑھیں، کچھ تبدیلیاں کیں، ٹیسٹ چلائے، ناکام ہو گئے، پھر دوبارہ تبدیلیاں کیں، دوبارہ چلائے، اب بھی ناکام ہو گئے… کئی دہرائیں کے بعد، آخرکار—ابھی بھی درست نہیں ہوا۔
آپ نے کمپیوٹر بند کر دیا اور آرام کی سانس لی۔ پھر API بل موصول ہوا۔
اوپر کے اعداد و شمار آپ کو سانس لینے دیں گے — AI Agent کی خودکار بگ فکسی کے دوران، بیرونی سرکاری API پر ایک منفرد غیر فکس شدہ ٹاسک عام طور پر لاکھوں ٹوکن خرچ کرتا ہے، جس کا خرچ دہائیوں سے ایک سو ڈالر تک ہو سکتا ہے۔
اپریل 2026 میں، ایک مطالعہ جس میں اسٹینفورڈ، ایم آئی ٹی، اور میشیگن یونیورسٹی سمیت دیگر اداروں نے حصہ لیا، نے AI ایجینٹس کے کوڈ ٹاسکس میں "کنسم کا بلوک" کو پہلی بار نظام مند انداز میں کھولا — پیسہ کہاں خرچ ہوا، کیا اس کی قیمت مناسب تھی، اور کیا اسے پہلے سے تخمینہ لگایا جا سکتا ہے، جواب حیرت انگیز تھا۔
ایک دریافت: ایجینٹ کوڈ لکھنے کی لاگت عام AI بات چیت کی 1000 گنا ہے
لوگوں کو لگ سکتا ہے کہ AI کو اپنے لیے کوڈ لکھوانا اور AI کے ساتھ کوڈ پر بات چیت کرنا، دونوں میں خرچ تقریباً ایک جیسا ہونا چاہیے۔
مطالعہ میں تقابلی نتائج دیے گئے ہیں:
ایجینٹک کوڈنگ ٹاسک کے لیے ٹوکن کا استعمال، عام کوڈ سوالات اور کوڈ ریزننگ ٹاسکس کے مقابلے میں تقریباً 1000 گنا زیادہ ہے۔
پورے تین درجے کا فرق۔
یہ کیوں ہو رہا ہے؟ تحقیقی مقالہ ایک حقیقت پر روشنی ڈالتا ہے کہ پیسہ "کوڈ لکھنے" پر نہیں، بلکہ "کوڈ پڑھنے" پر خرچ ہوتا ہے۔
یہاں "پڑھنا" کا مطلب انسان کے کوڈ پڑھنا نہیں، بلکہ ایجینٹ کے کام کے دوران پورے پروجیکٹ کے کنٹیکسٹ، تاریخی آپریشنز کے ریکارڈ، ایرر میسجز، اور فائلز کے مواد کو ایک ساتھ مدل کو "فیڈ" کرنا ہے۔ ہر اضافی ڈائیلاگ کے ساتھ، یہ کنٹیکسٹ ایک اور چکر تک لمبا ہو جاتا ہے؛ اور مدل کی فیس ٹوکن کی تعداد کے حساب سے لگائی جاتی ہے — جتنا زیادہ فیڈ کریں گے، اتنی ہی زیادہ رقم ادا کرنا پڑے گی۔
ایک مثال کے طور پر: یہ ایسے ہے جیسے آپ نے ایک مکینیک کو بلایا ہے جو ہر گھنٹی لگانے سے پہلے آپ کو پوری عمارت کا ڈرائنگ پورا پڑھنا پڑتا ہے — ڈرائنگ پڑھنے کا خرچہ، گھنٹی لگانے کے خرچے سے بہت زیادہ ہوتا ہے۔
اس ظاہر کو مقالہ ایک جملے میں خلاصہ کرتا ہے: ایجنٹ کی لاگت کو ڈرائیو کرنے والا، آؤٹ پٹ ٹوکن نہیں بلکہ ان پٹ ٹوکن کا اسی طرح بڑھتا ہوا اضافہ ہے۔
دوسرا دریافت: ایک ہی بگ کو دو بار چلانے سے لاگت دگنا ہو سکتی ہے — اور جتنا مہنگا بگ، اتنا ہی بے ثبات
مزید پریشانی کا سبب تصادفیت ہے۔
محققین نے ایک ہی ایجینٹ کو ایک ہی کام پر چار بار چلایا، اور پایا کہ:
- مختلف کاموں کے درمیان، سب سے مہنگا کام سب سے سستے کام سے تقریباً 7 ملین ٹوکن زیادہ جلاتا ہے (شکل 2a)
- ایک ہی ماڈل اور ایک ہی کام کے متعدد عملوں میں، سب سے مہنگا عمل تقریباً سب سے سستے عمل کا دو گنا ہے (شکل 2b)
- اور اگر ایک ہی کام کے لیے مختلف ماڈلز کا موازنہ کیا جائے، تو سب سے زیادہ اور سب سے کم استعمال کے درمیان 30 گنا کا فرق ہو سکتا ہے
آخری عدد خاص طور پر قابل توجہ ہے: اس کا مطلب ہے کہ درست ماڈل اور غلط ماڈل کے درمیان لاگت کا فرق صرف "थोڑا مہنگا" نہیں، بلکہ "ایک درجہ بڑھ جاتا ہے"۔
زیادہ خرچ کرنا، بہتر کام کرنے کا مطلب نہیں۔
مطالعہ نے ایک "الٹا U شکل" منحنی دریافت کیا:
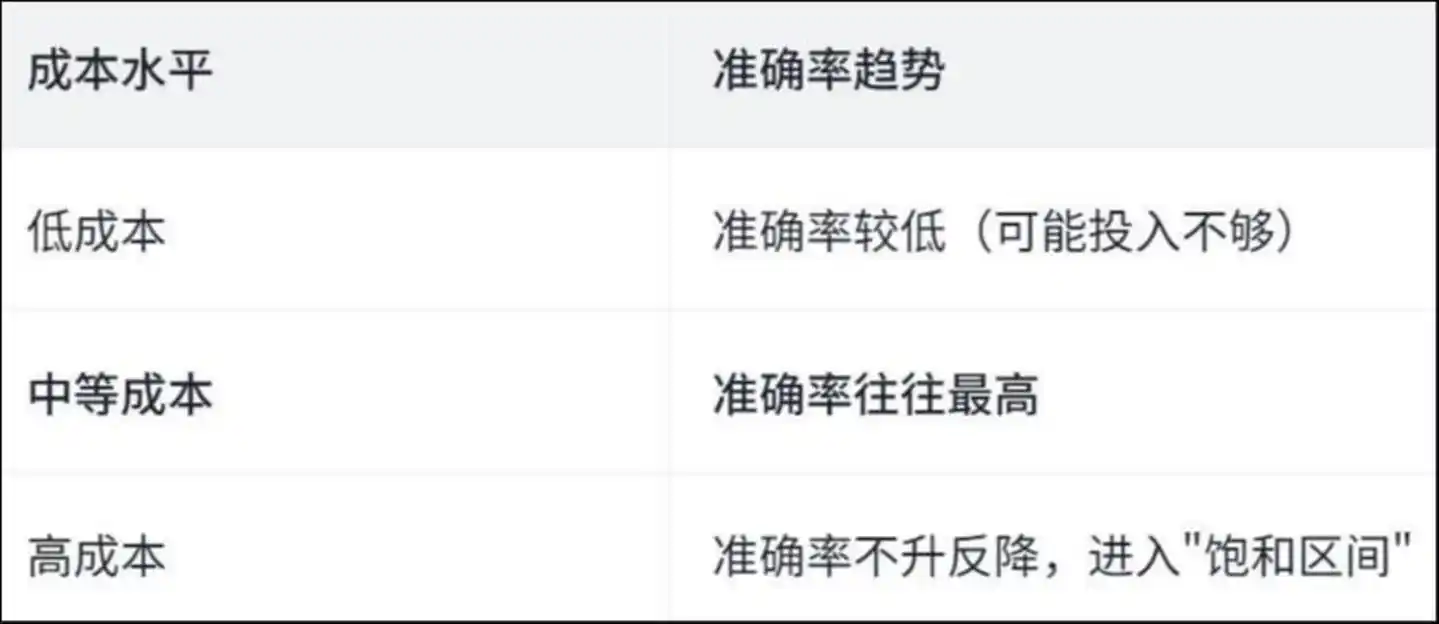
لاگت کے سطح کی درستگی کا رجحان: کم لاگت پر درستگی کم ہوتی ہے (ممکنہ طور پر سرمایہ کاری کم ہے)۔ درمیانی لاگت پر درستگی عام طور پر سب سے زیادہ ہوتی ہے۔ زیادہ لاگت پر درستگی نہیں بڑھتی بلکہ گھٹتی ہے، اور "شبھ سطح" میں داخل ہو جاتی ہے۔
یہ کیوں ہوا؟ مقالہ Agent کے مخصوص عمل کے تجزیے کے ذریعے جواب دیتا ہے—
اعلیٰ لاگت کے تحت، ایجنٹ کا زیادہ تر وقت "دوہرائی جانے والی مزدوری" پر خرچ ہوتا ہے۔
مطالعہ سے پتہ چلتا ہے کہ اعلی لاگت والے عمل میں، فائلیں دیکھنے اور فائلیں تبدیل کرنے کے تقریباً 50 فیصد کام دہرائے جاتے ہیں — یعنی، ایجنٹ ایک ہی فائل کو بار بار پڑھ رہا ہے اور ایک ہی لائن کوڈ کو بار بار تبدیل کر رہا ہے، جیسے کوئی شخص کمرے میں گھوم رہا ہو، جتنا گھومے، اتنا ہی گھومتا جائے۔
پیسہ مسئلہ حل کرنے پر نہیں، بلکہ "بھٹک جانے" پر خرچ ہوا۔
دریافت 3: ماڈلز کے درمیان "انرجی کارکردگی" میں بہت بڑا فرق ہے — GPT-5 سب سے کم استعمال کرتا ہے، کچھ ماڈلز 1.5 ملین ٹوکن زیادہ استعمال کرتے ہیں
اس پیپر نے صنعتی معیار کے SWE-bench Verified (500 حقیقی GitHub Issues) پر 8 جدید بڑے ماڈلز کے ایجینٹ کی کارکردگی کا جائزہ لیا۔ ٹوکن کی کارکردگی والے ماڈلز ہر ٹاسک کے لیے کئی دہائیوں کے فرق کا فائدہ اٹھا سکتے ہیں۔ جب اسے کاروباری سطح پر لاگو کیا جائے — جہاں روزانہ سینکڑوں ٹاسک چلائے جاتے ہیں — تو یہ فرق حقیقی رقم بن جاتا ہے۔
ایک اور دلچسپ دریافت یہ ہے کہ ٹوکن کی کارکردگی ماڈل کا "بنیادی خاصہ" ہے، نہ کہ کام کی وجہ سے۔
محققین نے تمام ماڈلز کے کامیاب ہونے والے کام (230) اور تمام ماڈلز کے ناکام ہونے والے کام (100) کو الگ الگ ترتیب دے کر موازنہ کیا، جس سے پتہ چلا کہ ماڈلز کی نسبی درجہ بندی میں تقریباً کوئی تبدیلی نہیں آئی۔
یہ بتاتا ہے کہ کچھ ماڈلز خود بخود "زیادہ باتیں" کرتے ہیں، جو کام کی مشکل سے زیادہ متعلق نہیں ہوتے۔
ایک اور گہرا خیال کرنے والی بات یہ ہے کہ ماڈل میں "اسٹاپ لاس ایونس" کی کمی ہے۔
جب تمام ماڈلز کے لیے حل نہ ہونے والی مشکل کاموں کا سامنا ہو، تو مثالی ایجنٹ کو پیسہ برباد کرنے کے بجائے جلد ہی چھوڑ دینا چاہیے۔ لیکن حقیقت یہ ہے کہ ماڈلز عام طور پر ناکام کاموں پر زیادہ ٹوکنز کھاتے ہیں — وہ "ہار نہیں مانتے"، بلکہ جاری رکھتے ہیں، دوبارہ کوشش کرتے ہیں، اور ماحول کو دوبارہ پڑھتے ہیں، جیسے ایک کار جس میں فیول کا ایلارم نہ ہو اور وہ خراب ہو جانے تک چلتی رہے۔
پائے گیا چوتھا نتیجہ: جو چیز انسان کے لیے مشکل ہے، اس کا مطلب یہ نہیں کہ ایجنٹ کے لیے مہنگی ہے — مشکل کا احساس بالکل غلط ہے
آپ سوچ سکتے ہیں: کم از کم کیا میں کام کی مشکل کے لحاظ سے لاگت کا اندازہ لگا سکتا ہوں؟
ایک مصنف نے انسانی ماہرین کو بلایا تاکہ 500 ٹاسکس کی مشکل کی درجہ بندی کریں، اور پھر ایجنٹ کے حقیقی ٹوکن استعمال کے ساتھ تقابل کیا —
نتیجہ: دونوں کے درمیان صرف کمزور تعلق ہے۔
انسان کے لیے بہت مشکل کام، ایجنٹ آسانی سے اور کم خرچ میں کر سکتا ہے؛ جبکہ انسان کے لیے آسان کام، ایجنٹ کے لیے ایسا ہو سکتا ہے جیسے وہ اپنی پہچان ہی بھول جائے۔
یہ اس لیے ہے کہ انسان اور AI کو “دیکھنا” بالکل مختلف چیز ہے:
- انسان دیکھتے ہیں: منطقی پیچیدگی، الگورتھم کی مشکل، اور کاروباری سمجھ کی رکاوٹ
- ایجینٹ دیکھ رہا ہے: پروجیکٹ کتنا بڑا ہے، کتنے فائلیں پڑھنی ہیں، ایکسپلوریشن کا راستہ کتنا لمبا ہے، اور کیا وہ ایک ہی فائل کو دوبارہ تبدیل کرے گا
ایک انسانی ماہر جو سمجھتا ہے کہ "صرف ایک لائن تبدیل کریں" کا بگ ہے، ایجنٹ شاید اس لائن کو تلاش کرنے کے لیے پورے کوڈ بیس کی ساخت کو سمجھنا پڑے — صرف "پڑھنا" ہی بہت زیادہ ٹوکنز استعمال کر دے گا۔ اور ایک انسان جو سمجھتا ہے کہ الگورتھم بہت پیچیدہ ہے، ایجنٹ شاید معیاری حل جانتا ہو اور صرف تین چار کوششوں میں اسے حل کر دے۔
اس سے ایک عجیب حقیقت پیدا ہوتی ہے کہ ڈویلپرز کے لیے ایجنٹ کے آپریشن کی لاگت کا اندازہ لگانا تقریباً ناممکن ہے۔
پانچواں دریافت: مدل خود بھی نہیں جانتا کہ اسے کتنی رقم خرچ کرنی ہوگی
اگر انسان درست پیشگوئی نہیں کر سکتا، تو کیا AI خود پیشگوئی کرے؟
محققین نے ایک ہنر مند تجربہ ڈیزائن کیا: ایجینٹ کو اصل میں بگ کو درست کرنے سے پہلے، کوڈ بیس کا "انسپیکٹ" کرنے دیا جائے، اور پھر یہ اندازہ لگائے کہ اسے کتنے ٹوکنز کی ضرورت ہوگی—لیکن درستگی کا عمل نہیں کیا جائے۔
نتیجہ کیا ہوا؟
سبھی ماڈلز، مکمل طور پر ناکام۔
بہترین نتیجہ Claude Sonnet-4.5 کا ہے، جس نے آؤٹ پٹ ٹوکن کی پیش گوئی کی متعلقہ درجہ بندی 0.39 (满分 1.0) حاصل کی۔ زیادہ تر ماڈلز کی پیش گوئی کی متعلقہ درجہ بندی صرف 0.05 سے 0.34 کے درمیان ہے، جبکہ Gemini-3-Pro کا نتیجہ سب سے کم 0.04 ہے—جو تقریباً اندازہ لگانے کے برابر ہے۔
مزید عجیب بات یہ ہے کہ تمام ماڈلز اپنے ٹوکن کے استعمال کو نظام کے طور پر کم اندازہ کرتے ہیں۔ شکل 11 کے اسکیٹر پلٹ میں، تقریباً تمام ڈیٹا پوائنٹس "مکمل پیشگوئی لائن" کے نیچے ہیں—ماڈل سمجھتے ہیں کہ "انہیں اتنے زیادہ نہیں خرچ کرنے پڑیں گے"، جبکہ واقعی میں وہ زیادہ خرچ کرتے ہیں۔ اور یہ کم اندازہ کرنے کا جھکاؤ اس صورت میں مزید شدید ہوتا ہے جب مثالیں فراہم نہ کی جائیں۔
مزید طنز ایک ہے کہ خود پیشگوئی کے لیے بھی پیسے خرچ کرنے پڑتے ہیں۔
کلوڈ سونیٹ-3.7 اور سونیٹ-4 کی پیشگی تخمینہ لاگت کافی زیادہ ہے، جو کام کی اصل لاگت سے دو گناں سے زیادہ ہو سکتی ہے۔ یعنی، انہیں پہلے "قیمت بتانے" کے لیے بھیجنا، براہ راست کام کرنے سے زیادہ مہنگا ہے۔
کاغذ کا نتیجہ سیدھا سادہ ہے:
ابھی، اگری فارم مدلز اپنے ٹوکن استعمال کو درست طریقے سے پیش بینی نہیں کر سکتے۔ "ایجینٹ چلائیں" پر کلک کرنا، ایک اندھا باکس کھولنا جیسا ہے — بِل آنے تک پتہ نہیں چلتا کہ کتنا خرچ ہوا۔
اس "بیکار خاتمے" کے پیچھے ایک بڑا صنعتی مسئلہ چھپا ہوا ہے
اسے پڑھ کر آپ پوچھ سکتے ہیں: ان دریافتوں کا کاروبار پر کیا اثر ہے؟
"ماہانہ سبسکرپشن" کا قیمتی نظام، ایجنٹ کے ذریعے دراڑوں سے بھر گیا ہے
مطالعہ کا کہنا ہے کہ ChatGPT Plus جیسے سبسکرپشن ماڈل کام کرتے ہیں کیونکہ عام مکالموں کے ٹوکن استعمال کو نسبتاً قابل کنٹرول اور پیش گوی کیا جا سکتا ہے۔ لیکن ایجنٹ کے کام اس فرضیہ کو مکمل طور پر توڑ دیتے ہیں — ایک ایجنٹ کا کام اس لیے بہت زیادہ ٹوکن استعمال کر سکتا ہے کیونکہ ایجنٹ حلقوں میں پھنس جاتا ہے۔
اس کا مطلب یہ ہے کہ صرف سبسکرپشن بنیادی قیمت گذاری Agent کے سیناریوز کے لیے قائم نہیں رہ سکتی، اور پے-اس-یو-گو (Pay-as-you-go) طریقہ کار کافی لمبے عرصے تک سب سے عملی اختیار رہے گا۔ لیکن پے-اس-یو-گو کا مسئلہ یہ ہے کہ استعمال کا تقاضا خود بخود غیر قابل پیشگوئی ہے۔
2. ٹوکن کی کارکردگی کو ماڈل کے انتخاب کا "تیسرا معیار" بنایا جانا چاہئے
سنتوں سے، کاروباری ادارے ماڈل کا انتخاب دو ابعاد پر کرتے ہیں: صلاحیت (کیا یہ کر سکتا ہے) اور رفتار (کیا یہ جلدی کرتا ہے)۔ اس تحقیقی مقالے نے تیسرا، برابر اہم پہلو پیش کیا ہے: توانائی کی کارکردگی (کام مکمل کرنے میں کتنا خرچ ہوتا ہے)۔
ایک تھوڑا کم صلاحیت والا مگر تین گنا زیادہ کارآمد ماڈل، سکیل پر منحصر صورتحال میں "سب سے طاقتور مگر سب سے زیادہ مہنگا" ماڈل کے مقابلے میں زیادہ مالی اہمیت رکھ سکتا ہے۔
3. ایجینٹ کو "آئل گیج" اور "بریک" کی ضرورت ہے
کاغذ میں ایک قابل توجہ مستقبل کی سمت کا ذکر ہے — بجٹ ایوار ٹول استعمال کی پالیسیز۔ سادہ الفاظ میں، یہ ایجنٹ کو ایک "آئل گیج" لگانا ہے: جب ٹوکن کا استعمال بجٹ کے قریب پہنچ جائے، تو اسے غیر ضروری تلاش کو روک دیا جائے، نہ کہ مکمل طور پر خرچ کر دیا جائے۔
اب تک، تقریباً تمام ممتاز ایجنٹ فریم ورکس میں یہ مکانیزم نہیں ہے۔
ایجینٹ کا "پیسہ جلانے کا مسئلہ" بگ نہیں، بلکہ صنعت کا ضروری درد ہے
یہ تحقیقی مقالہ کسی مدل کی کمی نہیں بلکہ پورے ایجنٹ پیرادائیم کی ساختی چیلنج کو ظاہر کرتا ہے — جب AI "ایک سوال، ایک جواب" سے آگے بڑھ کر "خودکار منصوبہ بندی، متعدد مراحل کا انجام، اور دوبارہ ٹیسٹنگ" تک پہنچ جائے، تو ٹوکن کے استعمال کی غیر متوقعیت تقریباً ایک ضرورت ہے۔
اچھی خبر یہ ہے کہ یہ پہلی بار ہے جب کسی نے اس بھول بسکی کو منظم طریقے سے نکال کر حساب لگایا ہے۔ اس ڈیٹا کے ساتھ، ڈویلپرز مدلز کا انتخاب، بجٹ طے کرنے اور سٹاپ لاس مکانزم ڈیزائن کرنے میں زیادہ سمجھدار بن سکتے ہیں؛ جبکہ مدل فراہم کنندگان کے لیے ایک نیا بہتر بنانے کا راستہ بھی کھل گیا ہے — صرف زیادہ طاقتور بننے کے بجائے، زیادہ محفوظ بننا بھی۔
آخر کار، AI ایجنٹ کے حقیقی پیداواری ماحول میں ہر صنعت میں داخل ہونے سے پہلے، ہر روپیہ جس طرح خرچ کیا جا رہا ہے، اس سے زیادہ اہم ہے کہ ہر لائن کوڈ خوبصورتی سے لکھی جائے۔ (یہ مضمون پہلی بار ٹائی میڈیا ایپ پر شائع ہوا، مصنف | سلیکون ویلی ٹیک نیوز، ادیٹر | زھاو ہنگیو)
نوٹ: یہ مضمون 24 اپریل 2026 کو arXiv پر شائع ہونے والی پری پرنٹ پیپر *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei) پر مبنی ہے۔ مصنفین ورجینیا یونیورسٹی، اسٹینفورڈ یونیورسٹی، MIT، میشیگن یونیورسٹی وغیرہ سے ہیں۔ یہ تحقیق ابھی تک م同行评审 کے ذریعے جانچ گزاری نہیں گئی ہے۔