
کون سا بڑا ماڈل OpenClaw کے حقیقی دنیا کے ایجینٹ ٹاسکس میں سب سے زیادہ طاقتور ہے؟
میٹوکن نے ایک شفاف بنچ مارک تیار کیا ہے جو AI کوڈنگ ایجینٹس کی عملی صلاحیتوں کا جائزہ لینے پر مرکوز ہے، صرف کامیابی کے فیصد کو ایک مرکزی پہلو کے طور پر دیکھتے ہوئے (رفتار اور لاگت دوسرے الگ الگ پہلو ہیں جن کا بعد میں الگ سے جائزہ لیا جائے گا)۔ یہ مکمل طور پر شفاف اور دوبارہ قابل حاصل ہے، صرف سخت بنچ مارک معیارات اور تازہ ترین کامیابی کے ٹاپ 10 لسٹ کو ظاہر کرتا ہے۔
ایک، جائزہ کے پہلو: کامیابی کی شرح
معیار: دی گئی کام کو AI ایجینٹ کی مکمل اور درست طور پر مکمل کرنے کا تناسب۔ ہر کام ایک انتہائی معیاری عمل کے ذریعے کیا جاتا ہے:
درست صارف کے حکم (Prompt)
ایجنٹ کو مکمل پیغام بھیجیں تاکہ حقیقی صارف کی درخواست کا خاکہ تیار کیا جا سکے
متوقع رویہ
قبول کردہ عمل کے طریقے اور اہم فیصلہ سازی کے نکات کی وضاحت
评分标准 (چیک لسٹ)
ایٹمک کامیابی کے معیارات کی فہرست بنائیں
دو، تین قسم کے اسکورنگ طریقے
اس جائزے کے لیے بنیادی طور پر تین قسم کے اسکورنگ طریقے استعمال کیے گئے۔
آٹومیٹڈ چیک: پائیتھن اسکرپٹ فائل کے مواد، ایکزیکیشن ریکارڈ، ٹول کالز اور دیگر عینی نتائج کو ب без تصدیق کرتا ہے
LLM بڑا ماڈل جج: کلاڈ اوپس تفصیلی سکیل پر اسکور دیتا ہے ( مواد کی معیار، مناسب ہونا، مکمل ہونا وغیرہ)
مکسڈ موڈ: آٹومیٹڈ آبجیکٹو چیک + LLM ایڈیٹر کوالیٹی ایویلیویشن کا امتزاج
تمام مہمات کی تعریفیں، پرومپٹس اور اسکورنگ کے منطق سب کو شفاف کر دیا گیا ہے تاکہ دوبارہ جانچ کی جا سکے۔
تین: جائزہ کے لیے استعمال ہونے والے کام
اس بنچ مارک میں 23 مختلف زمرے کے کام شامل ہیں۔ بنیادی تفاعل، فائل/کوڈ آپریشنز، مواد تخلیق، تحقیق اور تجزیہ، سسٹم ٹولز کا استعمال، اور یادداشت کو مستقل بنانا جیسے متعدد پہلوؤں کو کور کرتا ہے، جو ڈویلپرز کے روزمرہ OpenClaw کے استعمال کے مناظر کے بہت قریب ہے:
سینٹی چیک (آٹومیٹڈ) — آسان ہدایات کو سمجھ کر سلام کا درست جواب دیں
کیلنڈر واقعہ تخلیق (آٹومیٹیڈ) — قدرتی زبان سے معیاری ICS کیلنڈر فائل بنائیں
اسٹاک قیمت تحقیق (آٹومیٹڈ) — فوری اسٹاک قیمت کی جانچ کریں اور فارمیٹ شدہ رپورٹ جاری کریں
Blog Post Writing (LLM Judge) — ایک تقریباً 500 الفاظ کی ساخت شدہ مارک ڈاؤن بلاگ لکھیں
موسمیات کا اسکرپٹ تخلیق (آٹومیٹیشن) — غلطیوں کے لیے ہینڈلنگ کے ساتھ پائیتھن موسمیات API اسکرپٹ لکھیں
دستاویز کا خلاصہ (LLM ایڈیٹر) — تین حصوں پر مشتمل مرکزی موضوع کا مختصر خلاصہ
ٹیک کانفرنس تحقیق (LLM جج) — 5 حقیقی ٹیک کانفرنسوں کی معلومات (نام، تاریخ، مقام، لنک) کا جمع کرنا اور ترتیب دینا
پیشہ ورانہ ای میل تیار کرنا (LLM جج) — ملاقات کو منع کرنا اور متبادل پیش کرنا
کنٹیکس سے میموری ریٹریول (آٹومیٹڈ) — پراجیکٹ نوٹس سے تاریخوں، افراد، ٹیکنالوجی اسٹیک وغیرہ کو درست طریقے سے نکالنا
فائل سٹرکچر کا ایجاد (آٹومیٹیڈ) — معیاری پروجیکٹ ڈائرکٹری، README، .gitignore کو خودکار طور پر تخلیق کریں
متعدد مراحل کی API ورک فلو (مکس) — کنفیگریشن پڑھیں → کال اسکرپٹ لکھیں → مکمل دستاویزیت
ClawdHub سکل (آٹومیشن) انسٹال کریں — سکل ریپوزٹری سے انسٹال کریں اور دستیابی کی تصدیق کریں
تلاش کریں اور مہارت نصب کریں (آٹومیٹیشن) — موسم کی قسم کی مہارت تلاش کریں اور درست طریقے سے نصب کریں
AI تصویر تخلیق (مخلوط) — تفصیل کے مطابق تصویر تخلیق کریں اور محفوظ کریں
AI سے تخلیق کردہ بلاگ کو انسانی انداز میں تبدیل کریں (LLM جج) — مشین کے انداز کو قدرتی بول چال میں بدلیں
روزانہ تحقیق کا خلاصہ (LLM جج) — متعدد دستاویزات کو ملا کر ایک مسلسل روزانہ خلاصہ تیار کرنا
ای میل انباک ٹریج (مکس) — متعدد ای میلز کا تجزیہ کریں اور فوریت کے لحاظ سے رپورٹ تیار کریں
ای میل تلاش اور خلاصہ کرنا (مکس) — آرکائیو کی گئی ای میلز کو تلاش کریں اور اہم معلومات نکالیں
مقابلہ کار مارکیٹ ریسرچ (مکس) — کاروباری APM شعبے میں مقابلہ کار تجزیہ
CSV اور Excel کا خلاصہ (مخلوط) — جدول فائلز کا تجزیہ کریں اور اہم باتیں نکالیں
ELI5 PDF خلاصہ کریں (LLM جج) — ٹیکنیکل PDF کو 5 سال کے بچے کے لیے سمجھائیں
اوپنکل�و رپورٹ کمپریہینژن (آٹومیٹڈ) — رپورٹس کے PDF سے خاص سوالات کا درست جواب دینا
دومین مغز کی معلومات کی مستقلیت (مکس) — سیشن کے درمیان معلومات کو محفوظ کرنا اور درست طریقے سے یاد رکھنا
چوتھا: مرکزی نتیجہ: کامیابی کی شرح کے ٹاپ 10 بڑے ماڈلز کی فہرست (بہترین %/اوسط %)
ڈیٹا 7 اپریل، 2026 تک اپ ڈیٹ کیا گیا ہے
بہترین % ایک منفرد سب سے زیادہ کامیابی کی شرح ہے، اوسط % کئی بار کی اوسط کامیابی کی شرح ہے، جو استحکام کو بہتر طور پر ظاہر کرتا ہے
سب سے زیادہ کامیابی والے دس ماڈلز یہ ہیں
anthropic/claude-opus-4.6 (Anthropic) —— 93.3% / 82.0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91.9% / 91.9%
openai/gpt-5.4 (OpenAI) —— 90.5% / 81.7%
qwen/qwen3.5-27b (Qwen) —— 90.0% / 78.5%
minimax/minimax-m2.7 (MiniMax) —— 89.8% / 83.2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89.5% / 78.1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89.1% / 80.4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88.8% / 70.2%
qwen/qwen3.6-plus-preview (Qwen) —— 88.6% / 84.0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88.6% / 75.5%
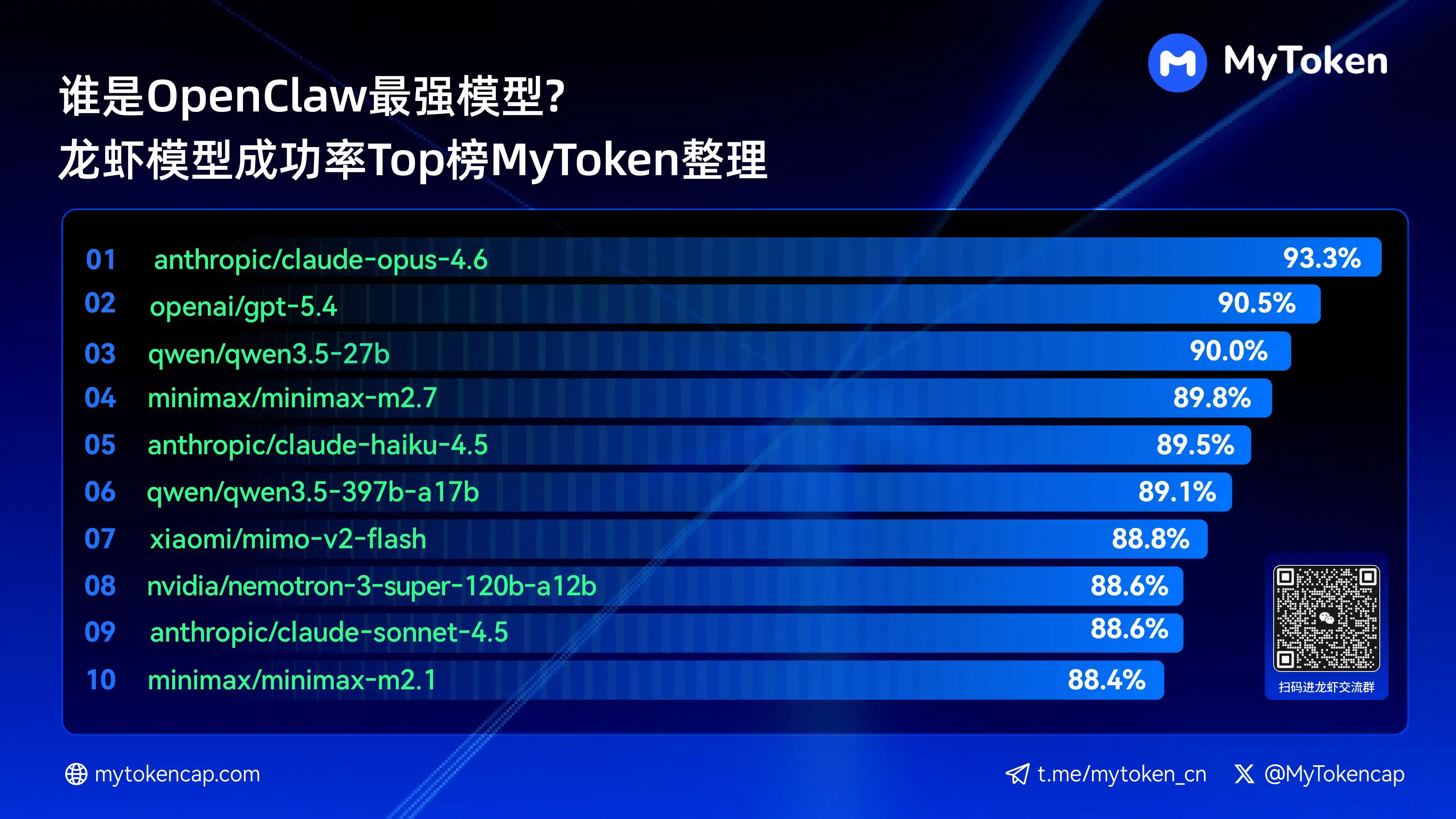
کلود آپس 4.6 اب 93.3% کی سب سے زیادہ کامیابی کے ساتھ لیڈ کر رہا ہے، لیکن آرسری کا ٹرینیٹی اوسط استحکام کے لحاظ سے نمایاں طور پر اچھا پرفارم کر رہا ہے، اور کوون سیریز کے کئی مدلز بھی دس کی فہرست میں شامل ہیں، جو اعلیٰ قیمت اور عملی صلاحیت کی صلاحیت کو ظاہر کرتے ہیں۔ کامیابی کا تناسب بنیادی حد ہے، اس کے بعد رفتار اور لاگت کے پہلوؤں سے عملی تجربہ مزید متاثر ہوگا۔
یہ 23 کارروائیوں کا بینچ مارک مکمل طور پر شفاف ہے، اور ہم سب کو اپنے مخصوص سیاق و سباق کے مطابق ٹیسٹ کرنے کی شدید تجویز کرتے ہیں۔ مزید دیگر ماڈل رینکنگز کے لیے MyToken کے قریب ہی شروع ہونے والے ایجنٹ رینکنگ فیچر کا انتظار کریں۔
(ڈیٹا PinchBench کے علیحدہ OpenClaw ایجینٹ بینچ مارک سے ماخوذ ہے، جو مستقل اپڈیٹ ہوتا رہتا ہے۔)