










لکھنے والے: ہمیشہ راستے میں ماکس، 01Founder
اگر 2025 کے لیے OpenAI کا ایک مراحل وار جائزہ لینا ہو، تو بہت سے لوگ اسے سادہ یا تھوڑا سا غیر فعال قرار دیں گے۔
گزشتہ ایک سال سے زیادہ کے دوران، انہوں نے منطقی استدلال کے راستے کو بالکل مکمل کیا، o3pro سے لے کر o4mini تک کے استدلال ماڈلز کو تیزی سے جاری کیا، اور GPT-4.5 اور GPT-5 جیسے نئے بنیادی ماڈلز بھی متعارف کرائے۔
لیکن عام صارفین کے لیے جہاں سب سے زیادہ محسوس ہونے والا اور خودبخود پھیلنے والی ویژوئل جنریشن کا شعبہ ہے، ان کی موجودگی آہستہ آہستہ کم ہوتی جا رہی ہے۔
سورا کے شروعاتی اثر کے بعد، اوپن اے آئی لگتا ہے کہ اس راستے پر لمبی خاموشی میں چلا گیا ہے۔
اسی دوران، ٹیبل پر دیگر کھلاڑیوں نے بیٹھے نہیں رہے۔
ا开源生态系统中,像 Flux 这样的模型彻底打破了高质量本地出图的门槛;
کاروباری طور پر، صرف قدیمی مقابلہ کنندگان ہی نہیں بلکہ نینو-بینانا جیسے خودکار ویب سرچ فنکشن کے ساتھ نئے مقابلہ کنندگان بھی ظاہر ہوئے ہیں۔
اس کے مقابلے میں، OpenAI کا پرانا ممتاز تصویر تخلیقی ماڈل GPT-Image-1.5 پہلے ہی پرانا پڑ چکا ہے:
گھٹیا کوالٹی، سخت لے آؤٹ، اور پیچیدہ متن کے سامنے اکثر کریش ہوتا ہے۔
آہستہ آہستہ، صنعت میں ایک اتفاق رائے قائم ہوا:
اوپن اے آئی کو ویژول جنریشن کے شعبے میں ٹیکنیکل بند راستہ کا سامنا ہے اور مختلف مقابلہ کرنے والوں کے دباؤ میں وہ تھک چکی ہے۔
پچھلے کچھ ہفتہ تک، موڑ بہت ہی پوشیدہ طریقے سے ظاہر ہوا۔
مشہور بڑے ماڈل اندھا ٹیسٹنگ پلیٹ فارم LM Arena پر، ایک رازدار تصویری ماڈل جس کا کوڈ نام Duct Tape ہے، چپکے سے شامل ہو گیا۔
بلائنڈ ٹیسٹ میں شرکت کرنے والے صارفین نے جلد ہی محسوس کیا کہ کچھ غلط ہے:
یہ ماڈل نہ صرف انتہائی دقیق طریقے سے انتہائی عجیب اسپیکٹ ریشیو کو کنٹرول کرتا ہے، بلکہ بہت سارے متعدد زبانوں کے متن کے ساتھ بے عیب ٹائپوگرافک پوسٹرز بھی پیدا کرتا ہے، اور شاید تصویر بنانے سے پہلے ایک ناپید منطقی منصوبہ بندی کا عمل ہوتا ہے۔
ایک وقت کے لیے، تمام ٹیکنیکل کمیونٹیز یہ اندازہ لگا رہی تھیں کہ یہ کون سی کمپنی کا چھپا ہوا بڑا ایڈوانس ہے، لیکن OpenAI کی طرف سے کوئی جواب نہیں دیا گیا۔
آج رات، بالٹیاں نے زمین پر گرنا شروع کر دیں۔
کوئی لمبی پریس کانفرنس نہیں، کوئی بھرپور مارکیٹنگ پرچھاڑ نہیں، اوپنای آئی نے اس کوڈ نام ٹیپ کے ماڈل کا رسمی نام ChatGPT GPT-Image-2 رکھا اور اسے مکمل طور پر مارکیٹ میں لانچ کر دیا۔
اس کے ساتھ ایک ایسا ٹیکسٹ-ٹو-ایمیج چیلنج لیڈر بورڈ بھی جاری کیا گیا جو کچھ زیادہ ہی دباؤ دیتا ہے۔
GPT-Image-2 نے 1512 کے انتہائی اعلی اسکور کے ساتھ فوراً ٹاپ پر قبضہ کر لیا، جو دوسرے نمبر پر (جس میں انٹرنیٹ سرچ فنکشن شامل ہے) Nano-banana-2 سے 242 اسکور زیادہ ہے۔
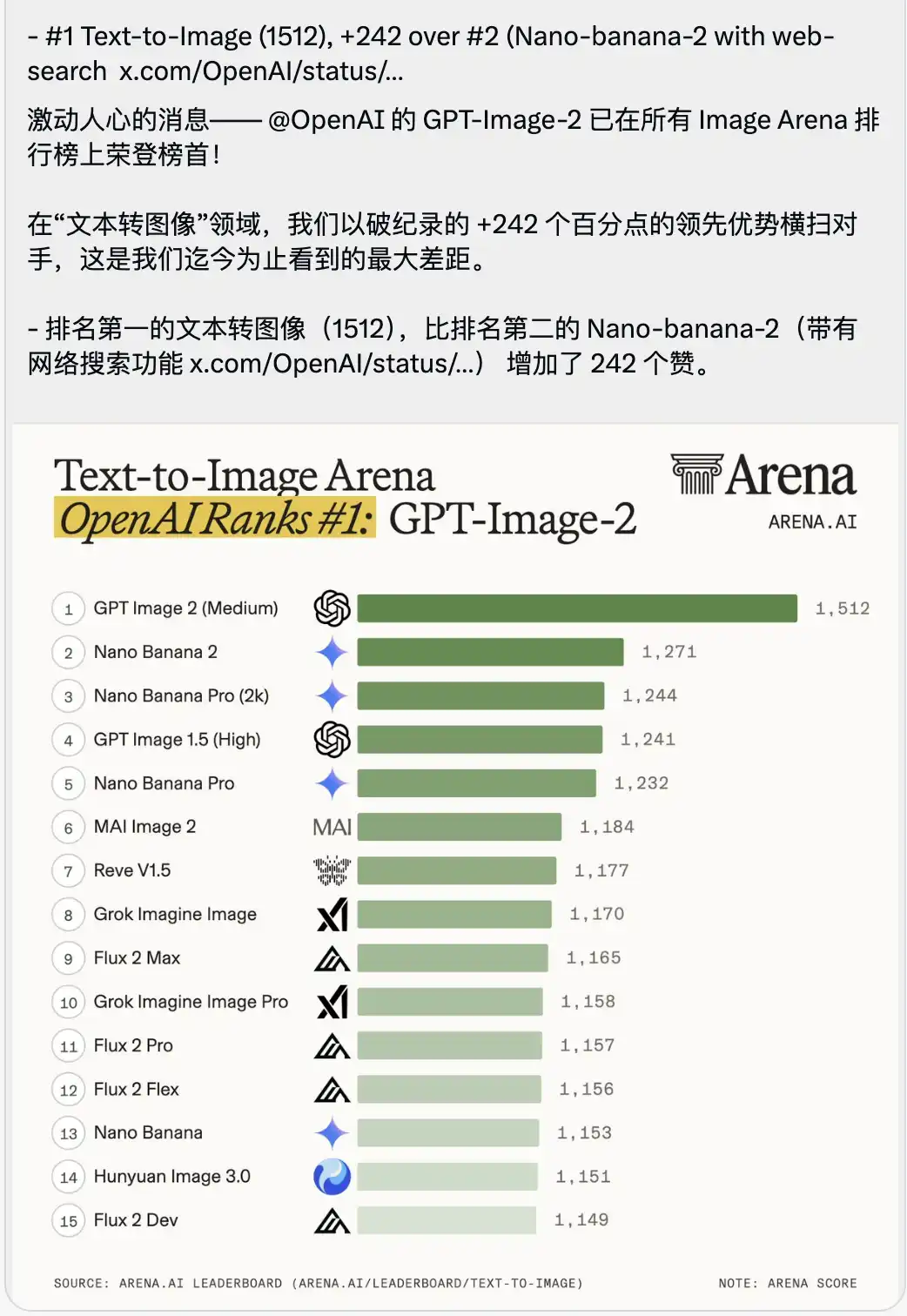
بڑے ماڈلز کے اسکورنگ کے حوالے سے، لوگ عام طور پر صفر کے بعد ایک یا دو اعشاریہ یا ایک ہندسے کے فرق کو بڑے پیمانے پر اہمیت دیتے ہیں، جبکہ ٹاپ ماڈلز کے اسکورز بہت کم فرق سے گھل مل جاتے ہیں۔
ایک 242 کا لیڈ فرق، اس اسٹیڈیم کی تاریخ میں کبھی نہیں دیکھا گیا۔
یہ صرف ایک چھوٹا اپڈیٹ نہیں ہے، یہ ایک جبری نسلی دباؤ ہے۔
میں نے اس کی تمام حدی امکانات اور تازہ ترین API دستاویزات کو دوپہر تک تفصیل سے دیکھا۔
سب سے بڑا احساس صرف ایک ہے:
اوپن اے آئی وہی اوپن اے آئی ہے۔
جب اس نے اپنی زمین دوبارہ حاصل کرنے کا فیصلہ کیا، تو اس نے پرانا کھیل کا میدان ہی الٹ دیا۔
اس ماڈل کے سامنے، جن ویژول ڈیزائن کے کاموں کو ہم سمجھتے تھے کہ ان کی جگہ AI کو دو تین سال لگیں گے، آج تقریباً ختم ہو چکا ہے۔
پارٹ.01 تصویر تخلیق ماڈل سے ویژول ایجینٹ تک
GPT-Image-2 کیوں اتنی بڑی اسکور کی فرق پیدا کرتا ہے، اسے سمجھنے کے لیے آپ کو متن سے تصویر بنانے والے ماڈلز کے بارے میں پرانی سوچ کو چھوڑنا ہوگا۔
ہم پہلے AI کا استعمال کرکے تصویر بناتے تھے، جو بنیادی طور پر ایک اندھا باکس کھولنا تھا، کچھ پرامپٹس ڈال کر انتظار کرتے تھے کہ یہ پکسلز کو آپ کی مرضی کے مطابق ترتیب دے دے۔
لیکن GPT-Image-2 زیادہ تر ایک ویژل انجن کے ساتھ یکجا ایجنٹ کی طرح ہے۔
سب سے واضح تبدیلی یہ ہے کہ اس نے مکمل طور پر دو مختلف موڈز کو مکینزم میں الگ کر دیا ہے۔
ایک فوری موڈ (Instant Mode) ہے جو تمام صارفین کے لیے کھلا ہے۔
یہ موڈ تیز رفتار ریسپانس اور زندگی اور کام کے عمل کے بے دردی اندراج پر مرکوز ہے۔
جیسے کہ آپ اپنے فون پر اسے ایک حکم بھیجیں، تو وہ کچھ سیکنڈوں میں ایک مکمل ساخت کی گراف دے دے گا۔
اس کی بنیادی ویژول سمجھ کی صلاحیت بہت زیادہ ہے، لیکن یہ زیادہ تر اعلیٰ ترین، ایک بار کی ویژول تبدیلی کی ضروریات کو پورا کرتا ہے۔
اور اداہ کرنے والے صارفین کے لیے دستیاب سوچنے کا موڈ (Thinking Mode)۔
اس کے ایک بھی پکسل کو رینڈر کرنے سے پہلے، یہ کئی دہائیوں تک منطقی استدلال اور آن لائن تلاش میں مصروف ہو جائے گا۔
یہی ماڈل ہے جو ایک بہت ہی بنیادی لیکن بہت ہی مشکل مسئلہ کو حل کرتا ہے:
ماڈل نے پہلی بار اصل میں جان لیا کہ وہ کیا بنانا چاہتا ہے۔
سب سے زیادہ واضح مثال دیں۔
آپ چیٹ باکس میں درج کریں:
براہ کرم ایک پوسٹر تیار کریں، آن لائن جا کر لوگوں کی رائے Duct Tape اس پراسیس مدل کے بارے میں جانیں اور ChatGPT کا کوڈ قریب لگائیں۔

اگر پرانے ماڈل کا استعمال کیا جائے، تو یہ نہیں جانتا کہ صارفین نے کیا کہا، بلکہ صرف ایک پوسٹر بنائے گا جس میں بے ترتیب حروف ہوں گے، اور کوڈ بھی ایک جعلی تصویر ہوگی جسے اسکین نہیں کیا جا سکتا۔
لیکن سوچنے کے موڈ میں، اس کا عملی عمل ایسا ہے:
یہ پہلے ڈرائنگ کو روک دے گا، انٹرنیٹ سرچ ٹول شروع کرے گا، اور ریڈیٹ، تھریڈز یا لینکڈ ان پر صارفین کے اصل جائزے حاصل کرے گا؛
پھر، اس نے پوسٹر کی ڈیزائن، خالی جگہ اور فونٹ ہائرارکی کی منصوبہ بندی شروع کر دی؛
آخر میں، یہ ایک اصلی، قابل استعمال، براہ راست اسکین کرکے ہدف تک جانے والا کوڈ تیار کرتا ہے اور پوری تصویر کو رینڈر کرتا ہے۔

یہ صرف ڈرائنگ نہیں ہے، یہ دراصل تحقیق، منصوبہ بندی، متن کا استخراج اور ڈیزائن کے ساتھ ایک جامع عمل ہے۔
یہاں ایک موازنہ کرنا ہوگا۔
بڑے ماڈلز کے گروپ میں لوگ جانتے ہیں کہ انٹرنیٹ اور تلاش کی صلاحیت والے تصویر تخلیق کرنے والے ماڈلز کو OpenAI نے نہیں بنایا۔
دوسرا نمبر پر رہنے والے نینو-بینانا میں یہ مکینزم پہلے ہی موجود تھا۔
لیکن جب آپ نینو-بینانا کا استعمال کرتے ہیں، تو آپ پائیں گے کہ یہ کئی جگہوں پر تھوڑا بے وقوف لگتا ہے۔
نانو-بینانا کا خیال اکثر ایک مکینیکل جوڑ کا منطق ہوتا ہے۔
مثلاً آپ اسے ایک صنعتی رجحان کی تلاش کرنے کے لیے کہیں تو وہ واقعی تلاش کر لیتا ہے، لیکن عام طور پر صرف ویکیپیڈیا کے جملوں کو بے رحمی سے نکال کر تصویر پر زبردستی لگا دیتا ہے۔
جب کوئی انتہائی تصوری تجارتی درخواست کی تشریح کرنے کا حکم ملتا ہے، تو یہ آسانی سے پریشان ہو جاتا ہے۔

اس کا احساس یہ ہے جیسے کوئی ایسا انٹرن شپ کر رہا ہو جو بات سمجھتا ہے لیکن جس کے پاس کوئی تجربہ نہیں، وہ کام کرنے کا طریقہ جانتا ہے لیکن حکمت عملی پوری طرح سے نہیں سمجھتا۔
لیکن GPT-Image-2 کا اس حوالے سے کام صرف تجاوز کے ساتھ بیان کیا جا سکتا ہے۔
اس کا خیال صرف ایک فارمیلیٹی نہیں ہے، بلکہ اس نے پیچھے کے ثقافتی سیاق و سباق اور تجارتی مقاصد کو حقیقی طور پر سمجھا ہے۔
میں نے ٹیسٹ کے دوران ایک بہت ہی مختصر چینی ہدایت درج کی: میرے لیے ایک اسکرین شاٹ بنائیں جس میں ماسک ڈانشی میں دوباؤ کی فروخت کر رہا ہو۔
اگر پرانے ڈرائنگ ماڈل کا استعمال کیا جائے، تو اس نے ایک سفید فام شخص کو جس کا چہرہ ماسک جیسا ہو، ایک باؤ کے ساتھ، اور پیچھے ادھیرا پس منظر بنایا ہوگا، جبکہ ڈیویو کی شکل بھی نہیں جانتا ہوگا۔
لیکن سوچنے کے موڈ میں، GPT-Image-2 کا نتیجہ کچھ ڈراؤنا لگتا ہے۔
اس نے صرف عناصر کو جوڑنے کی بجائے چینی انٹرنیٹ کی سمجھ کو خودکار طور پر استعمال کیا اور ڈیو ٹیو ڈیو لائیو اسٹریمنگ UI کا ایک پکسل لیول کا مکمل نقل بنایا۔
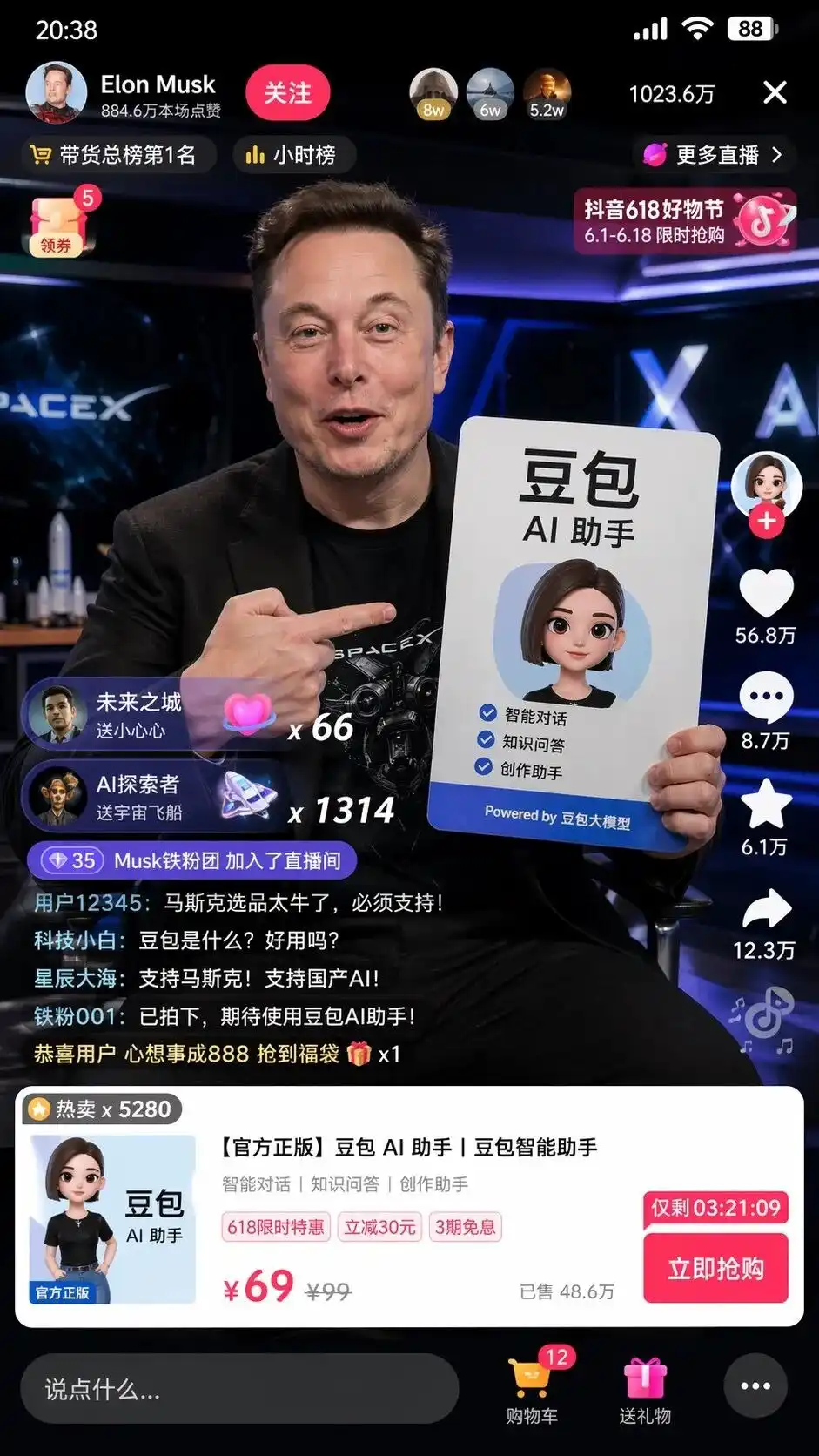
اسکرین پر صرف ایک واقعی ماسک نہیں ہے جو مثالی ٹائپوگرافی والے ڈوباؤ AI اسسٹنٹ کے اشتہار کا بورڈ اٹھا رہا ہے، بلکہ وہ تفصیلات بھی ہیں جو پرامپٹ میں شامل نہیں تھیں:
بائیں اوپر کا فولو بٹن، گھنٹے کی فہرست، دائیں اوپر کے 1023.6 ملین آن لائن صارفین، نیچے کا مانک مصنوعات کارڈ، اور 99 کی ریٹیل قیمت، 69 کی خصوصی قیمت اور گنتی کے ساتھ فوری خریدنے کا بٹن۔
بائیں نیچے سے بہت حقیقی طریقے سے لُٹتی ہوئی صارفین کی چیٹ بار سب سے زیادہ ڈراؤنی ہے:
ٹیک نویس: دوباؤ کیا ہے؟ کیا یہ استعمال کرنے میں اچھا ہے؟
سٹار سی اور سمندر: مسک کی حمایت کریں! ڈومیسٹک AI کی حمایت کریں!
کسی نے اسے نہیں بتایا کہ چیٹ بار کیا لکھنا ہے، پروڈکٹ UI کیسی ہونی چاہیے، اور قیمت کیسے طے کرنی چاہیے۔
یہ ماڈل نے ڈویان ٹوک اور دوباؤ بڑے ماڈل کے دونوں ٹیگز کا تجزیہ کرنے کے بعد انسان کے لیے مکمل بزنس UI ڈیزائن اور آپریشنل منصوبہ بندی کی ہے۔
اب، بڑے ماڈلز کی تصویر تخلیق پر جائزہ لینے کے معیار، صرف اس بات تک محدود نہیں رہے کہ کیا وہ خوبصورت تصویر بناسکتے ہیں، بلکہ اب یہ بھی دیکھا جا رہا ہے کہ وہ حکمت عملی اور ترتیب کے منطق کو سمجھتے ہیں۔
پارٹ.02 مرکزی صلاحیتوں کا عملی جائزہ
اس کی حد تک جانچنے کے لیے، میں نے تجارتی ڈیزائن کے معیارات کے مطابق کچھ اعلیٰ اور پیچیدہ سیناریوز کا امتحان لیا۔
پتہ چلا کہ اس کا مسئلہ حل کرنے کا سطح بہت گہرا ہو گیا ہے، جس سے ڈر لگتا ہے۔
پہلا منظر: بصری سمجھ اور کاروباری بند حلقة (ماڈل کو کپڑے پہنانا)
روایتی الیکٹرانک کمرشل ویژول یا فیشن پلاننگ میں، ایک خیال سے لے کر اس کے جسم پر اثر دیکھنے تک، انجام دینے کی لاگت بہت زیادہ ہوتی ہے۔
آپ کو ماڈل چاہیے، کپڑے ادھار لینے ہیں، سٹوڈیو ترتیب دینا ہے، اور پوسٹ پروڈکشن کی تفصیلی ترمیم کرنی ہے۔
بعد میں AI آیا، اور لوگوں نے شخصیت کے چہرے کو مستحکم کرنے کے لیے LoRA ماڈلز کو ٹرین کرنا شروع کر دیا، لیکن اب بھی اس کے لیے دہائیوں کی تصاویر اور کافی سیکھنے کی لاگت درکار ہوتی ہے۔
GPT-Image-2 میں، یہ عمل بہت زیادہ کم ہو گیا ہے۔
میںنے اپنا ایک روزمرہ کا سیلفی اپ لوڈ کیا اور اسے بتایا کہ میں اگلے ماہ جزیرے پر چھٹیاں گزارنے جا رہا ہوں، اور میرے لیے کچھ کپڑے سجھائیں۔
اس نے پہلے میرے لیے 8 مختلف انداز کے گرمی کے کپڑوں کا گائیڈ دیا، جس کی ترتیب پیشہ ورانہ الیکٹرانک کمرشل لوک بک جیسی لگ رہی تھی، اور ہر ایک چیز کے ساتھ درست متن کا لیبل بھی دیا گیا تھا۔
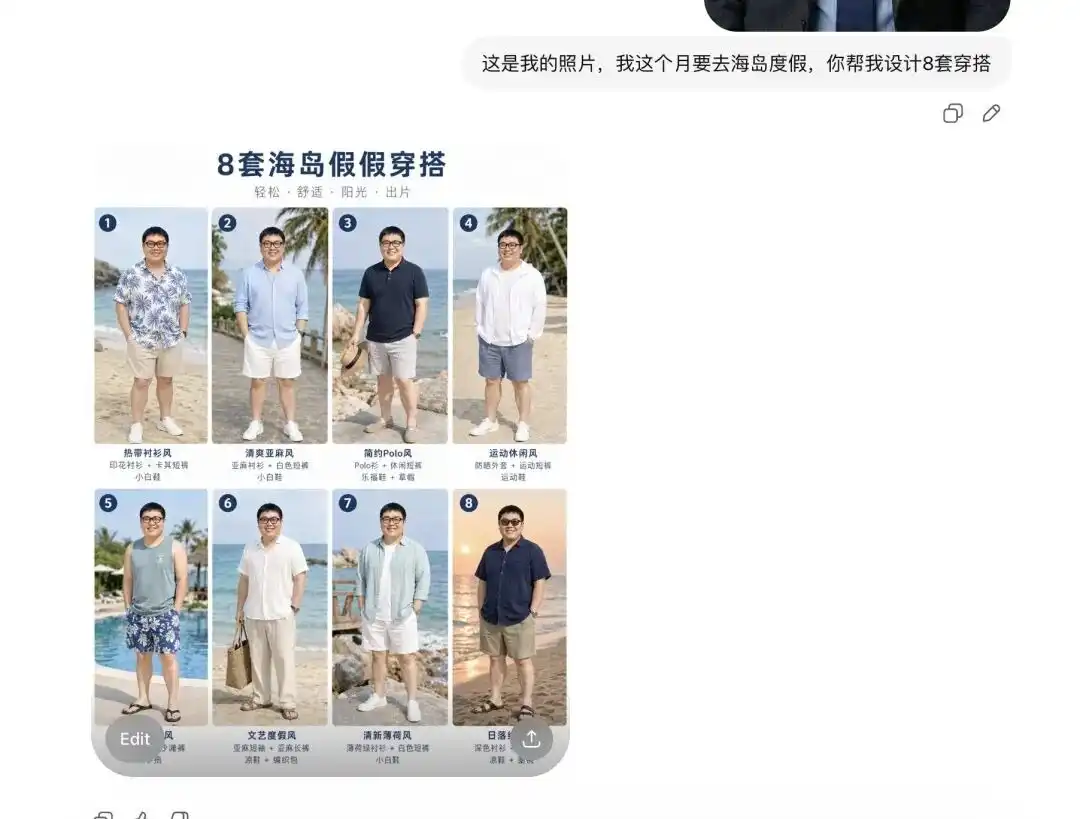
زیادہ اہم بات یہ ہے کہ اس لمحے میں ہی اس نے میرے چہرے کے خصوصیات اور جسم کے تناسب کو درست طریقے سے تحلیل کر لیا۔
جب میں نے اسے بتایا کہ میں پہلے سیٹ کو پہنے ہوئے دیکھنا چاہتا ہوں اور کچھ مختلف زاویوں سے تفصیلی تصاویر چاہتا ہوں، تو اس نے براہ راست میری اپنی تصویر سے شخص کو نکال کر اس کی جگہ گرمی کے لیے کپڑے پہنا دیے اور مختلف نظاروں جیسے سائیڈ اور ہاف بڈی کی تصاویر پیدا کر دیں۔

یہ موڑ بہت نرم تھا۔ اس کا مطلب یہ ہے کہ بنیادی کپڑوں کی ڈیزائننگ یا باہر کی گئی مدلز کے لیے فٹنگ کا کام، اس کا محفوظ راستہ مکمل طور پر ختم ہو گیا ہے۔
دوسرا منظر: ایک جملے کے ساتھ کامکس بنانا — ایکنیسٹی اور مسلسل کہانی کو حل کرنا
ای آئی تصویر بنانے والے سب جانتے ہیں کہ ایک خوبصورت تصویر بنانا آسان ہے، لیکن ایک ہی شخص کی دس تصاویر بنانا جن میں حرکت اور نظر کا زاویہ مسلسل ہو، مشکل ہے۔
یہی تو مسلسل (Consistency) کا مسئلہ کہلاتا ہے۔
لیکن اس عملی جائزے میں، میں نے ایک ایسا معاملہ دیکھا جو ماضی کے تجربے کے خلاف تھا۔
آپ صرف کل اپنے دوست کے ساتھ ایک فوٹو اپ لوڈ کر سکتے ہیں، اور ایک بہت سادہ ہدایت درج کر سکتے ہیں:
ہم دونوں کو مرکزی کردار بنائیں، تین ایپیسود والی جاپانی مانگا کا تین صفحات پر نقشہ بنائیں، کہانی آپ طے کریں
کچھ سیکنڈ کے بعد، اس نے معیاری اسکیٹچ کے ساتھ تین صفحات کا سیاہ و سفید کامکس فوراً نکال دیا۔
سب سے خوفناک بات یہ ہے کہ ان دوں نے ایک حقیقی شخص سے بنائے گئے کارٹون کرداروں کو تین صفحات پر مختلف فریم میں دکھایا ہے۔

قریبی شاٹ، دور کا دوڑنا، یا پیچھے کا منظر، یہاں تک کہ ان کے چہروں کی خصوصیات، بالوں کی تفصیلات اور کپڑوں کے جھریاں، سب میں مکمل ایک جیسے ہونے کا خیال رکھا گیا ہے۔
مزید تفصیل کے ساتھ، کارٹون کا کہانی کا رخ مکمل طور پر منسجم ہے، اور یہاں تک کہ مکالمے کے باکس میں لکھا گیا متن بھی مکمل کہانی کے منطق کو تشکیل دیتا ہے۔

وقت اور جگہ کی ایک جیسی مطابقت کو حاصل کرنا، اس بات کی نشاندہی کرتا ہے کہ یہ صرف ایک منفرد تصویر بنانے کے دائرے سے باہر نکل گیا ہے اور مسلسل کہانی سنانے کی ہدایت کرنے کی صلاحیت رکھتا ہے۔
تیسرا منظر: آخری رکاوٹ پر قدم رکھنا (بہت زبانوں کا ٹائپوگرافی)
اگر ایک جانچ کے ساتھ کہانی کا مسئلہ حل ہو جاتا ہے، تو بہت سی زبانوں کے متن کی درست رینڈرنگ حقیقت میں پلین ڈیزائنرز کو دیوار پر لے جاتی ہے۔
پہلے جب بھی تصویر میں کچھ متن ہوتا، تو بڑے ماڈل گھنٹے کی طرح کچھ بھی لکھنے لگ جاتے۔
کیونکہ ماڈل کی سمجھی جانے والی متن ٹوکن (معنیاتی ٹکڑے) ہیں، جبکہ تخلیق کی جانے والی تصاویر پکسلز ہیں، جو پہلے الگ تھلگ تھے۔
GPT-Image-2 نے اس مسئلے کو بالکل حل کر دیا۔
میں نے اسے ایک فرانسیسی فیشن میگزین کا کور بنانے دیا، ایک جاپانی ریستوران کا مینو جس پر مانہارا اور کینجی کے ساتھ بھرپور تھا، اور اس کے علاوہ روسی تبصرے کی بہت زیادہ ڈینسٹی والی ٹائپ سیٹنگ بھی کی۔

نتیجہ ایک ہی مرحلے میں تیار ہو گیا، کوئی املائی غلطی نہیں۔
سب سے زیادہ ناامید کرنے والی بات یہ ہے کہ وہ صرف الفاظ درست لکھتی ہے، بلکہ زبان کے مطابق مقامی ثقافتی ذائقہ اور فونٹ ڈیزائن کو بھی موزوں بناتی ہے۔
مثلاً، جاپانی فلیر میں استعمال کیے جانے والے ہانزی، بہت معمولی جاپانی ریٹرو آرٹ فونٹس کا استعمال کرتے ہیں، اور ہیراگانا کا لکھا ہوا انداز جاپانی کے عمودی پڑھنے کے رسم و رواج کے مطابق ہے۔
لے آؤ ڈیزائن پہلے گرافک ڈیزائنرز کا اپنا شعبہ تھا۔
فیسٹنگ، وزن کا تعین، اور متن اور پس منظر کے درمیان بصری توازن کے لیے بہت ساری مشق کی ضرورت ہوتی ہے۔
لیکن جب AI اتنی زبانوں کو صفر غلطیوں کے ساتھ ہینڈل کر سکے اور اس کے پاس اعلیٰ ٹائپوگرافی کا جذبہ ہو، تو روزمرہ کے پوسٹرز، پروموشنل بروشرز اور انفو اسٹریم اشتہارات کے لیے انسانوں کو مینوئل لائنز کے لیے ہاتھ لگانے کی ضرورت نہیں رہ جاتی۔
چوتھا منظر: خراب نسبت اور انتہائی مائیکرو کنٹرول (چاول کے دانے پر نقش)
آخر میں، اس کی اطاعت کی حد کو جاننے کے لیے، میں نے اسے کچھ بہت مشکل ہدایات دیں۔
میں نے اس کے انتہائی پہلو کا امتحان کیا۔
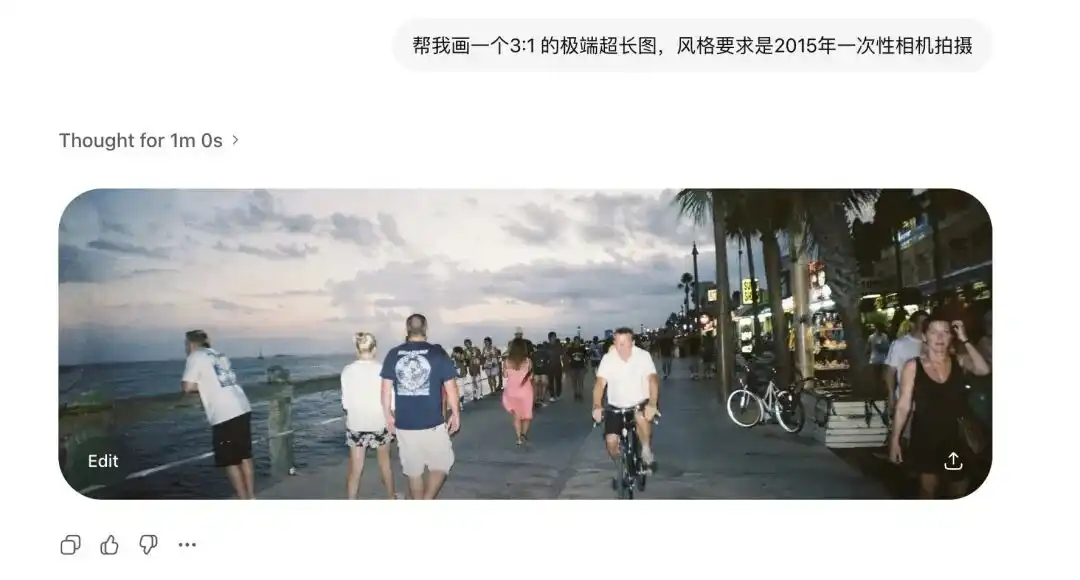
سنتی دھندلے ماڈلز غیر معیاری تناسب سے بہت خوف کھاتے ہیں۔
پہلے تصویر کو تھوڑا کشیدہ کرنے پر اس میں دو سر ہو جاتے تھے۔
لیکن میں نے Images 2.0 سے 3:1 کی انتہائی وسیع اور 1:3 کی عمودی لمبی تصاویر بنانے کا مطالبہ کیا، جس نے نہ صرف خرابی نہیں کی بلکہ شروع اور اختتام کو جوڑ کر 360 ڈگری پینورامک تصویر بھی تخلیق کی۔
2015 کے ایک بار استعمال کی جانے والی کیمرہ کی تصویروں کو شامل کرنے کے بعد، پرانے لینس کی ڈیسٹورشن اور دیوار پر فلیش کی کم معیاری ریفلاکشن تک واضح طور پر درست طریقے سے دکھائی دیتی ہیں۔
اور اس کی مائیکرو کنٹرول کی طاقت کو اور بہتر طریقے سے ظاہر کرنے والا، اس کے لانچ ایونٹ پر دکھائے گئے ایک تھوڑے سے پاگل پن والے چاول کے ٹیسٹ تھے۔
ریسرچر نے ابھی تک ٹیسٹ کے مراحل میں موجود تجرباتی 4K API کو بلایا، انہوں نے مائیکرو فوٹوگرافی، 8K اولٹرا ہائی دیفینشن جیسے کوئی بھی تفصیلات نہیں استعمال کیں، صرف ایک بہت عام اور سادہ ہدایت دی:
ایک ڈھیر چاول۔ اس ڈھیر کے ایک اکیلے دانے پر GPT Image 2 لکھا ہوا ہے۔
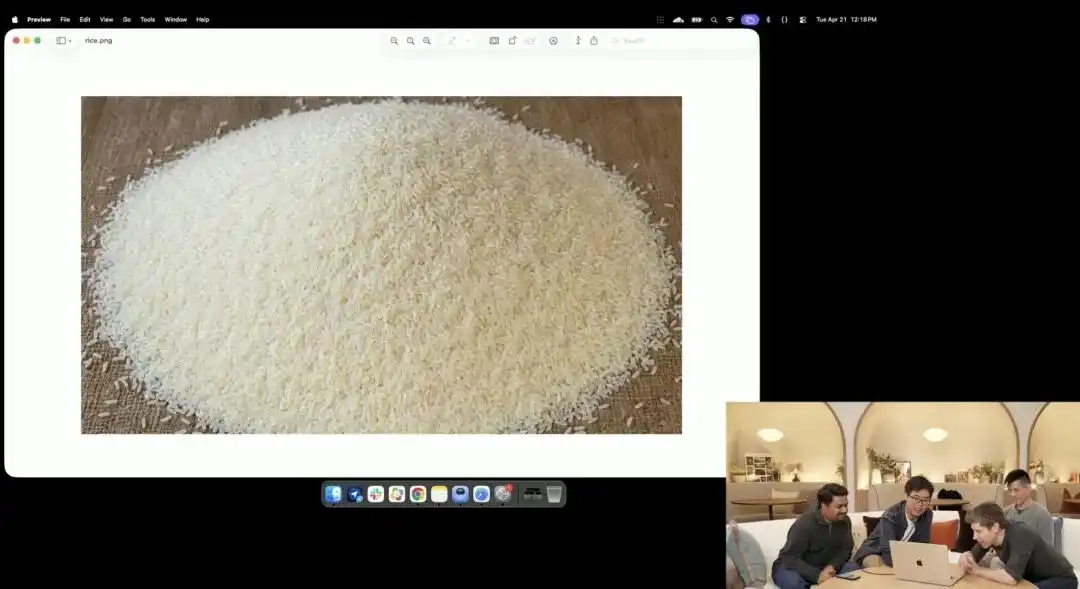
جب اسکرین پر تصویر دہ گنا یا اس سے زیادہ بڑھ جائے اور پکسلز کے دانے ظاہر ہو جائیں، تو کیا آپ ایک ڈھیر چاول میں سے ایک لکھے ہوئے میکرو ڈین کو تلاش کر سکتے ہیں؟
اس چاول کی بناوٹ اب بھی فزیکل قوانین کے مطابق ہے، اور حروف درستگی سے چاول کی چھوٹی چھوٹی منحنی سطح پر گھل گئے ہیں۔
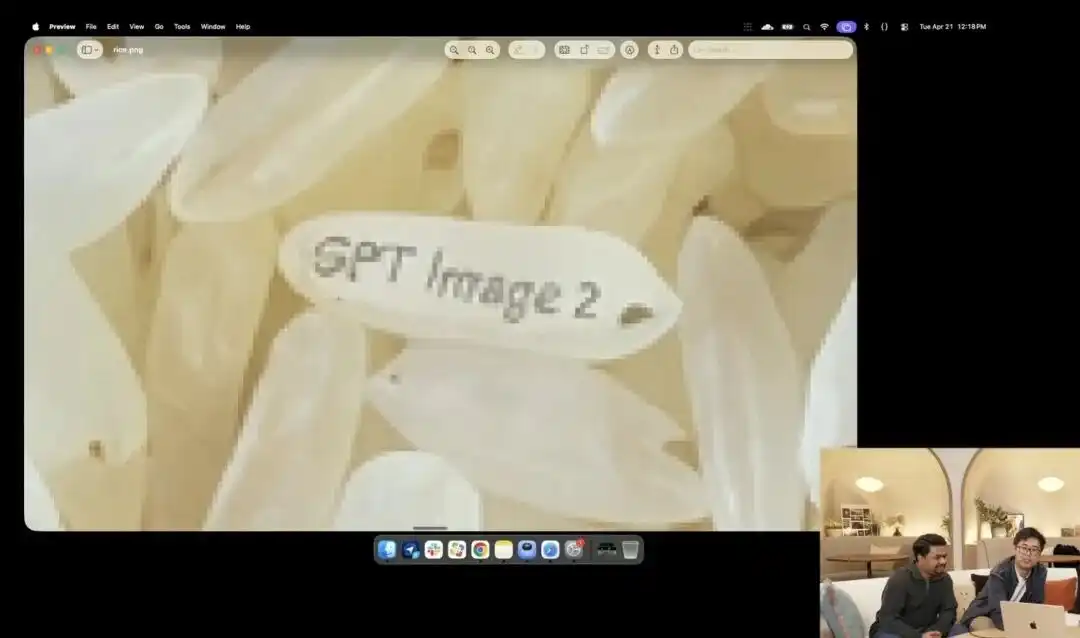
باقی تمام کام — مائیکرو ویو کو کال کرنا، ڈیپتھ آف فیلڈ کو کیلکولیٹ کرنا، لیٹنٹ اسپیس میں اس دانے کے فزیکل کوآرڈینیٹس تلاش کرنا، اور اس پر حروف چھاپنا — تمام یہ باتیں بڑے ماڈل نے سوچنے کے موڈ میں خود بخود سوچ کر انجام دے دیں۔
یہ معاملہ واضح طور پر ظاہر کرتا ہے کہ ماڈل کی فضائی مقام کی سمجھ پیکسل سطح کی جراحی کی درستگی تک پہنچ گئی ہے۔
اس کا مطلب یہ ہے کہ اب آپ اپنے عملی کام میں ڈیزائن کے کسی بھی چھوٹے حصے کو درست کر سکتے ہیں، جہاں چاہیں وہی تبدیل کر سکتے ہیں، جبکہ پہلے اگر آپ کو collar تبدیل کرنا تھا تو پوری تصویر تبدیل ہو جاتی تھی۔
پارٹ.03 کچھ ٹیکنیکل تفصیلات
یہ انتہائی کنٹرول اور اسٹریٹجک ذہانت بالکل بے وقوف طور پر کمپیوٹیشنل پاور کے اضافے سے حاصل نہیں ہوتی۔
اس کے اصل ہتھیار کیا ہیں، یہ جاننے کے لیے میں نے GPT-Image-2 کے لیے کچھ جانچ کی ہے۔
ایک بہت دلچسپ بات سامنے آئی۔
ہاں، حالانکہ افسرانی دستاویزات میں GPT-Image-2 کے کل جنرل کنولج بیس کی تاریخ دسمبر 2025 تک اپڈیٹ کرنے کا دعویٰ کیا گیا ہے، لیکن میرے عملی ٹیسٹ میں۔
انسٹنٹ موڈ کے ٹریننگ ڈیٹا کی حد تاریخ اب بھی مئی 2024 کے آخر تک ہے؛

اور وہ لمبی سوچ کی حالت (Thinking Mode)، جس کا اصلی جانکاری کا ذخیرہ تقریباً جون 2024 تک کا ہے (لیکن اسے حقیقی وقت میں انٹرنیٹ سے جوڑ کر موجودہ تاریخ حاصل کی جا سکتی ہے)۔

ان دو اوقات کے بنیاد پر، پورے GPT-Image-2 کی بنیاد میں کچھ نشانات دکھائی دیتے ہیں۔
سب سے پہلے ایک جلدی تصویر فراہم کرنے والے فوری موڈ کی بات کرتے ہیں۔
مئی 2024 کی میعاد کا مطلب ہے کہ یہ اکثر o4-mini کا براہ راست استعمال ہے، یا GPT-5 خاندان کا ہلکا ورژن (GPT-5 mini یا انتہائی کم پیرامیٹر والی GPT-5 nano)۔
کیونکہ یہ ہلکے بنیادی ماڈل پہلے ہی فضائی منصوبہ بندی اور پیچیدہ حکمات کو سمجھنے کی انتہائی طاقت رکھتے ہیں، اس لیے اوپری تصویر تخلیق کا نظام مستحکم رہتا ہے۔
اور وہ بہت ذکی، بازاری حکمت عملی کو سمجھنے والا سوچنے کا انداز، GPT-5 بنیادی ماڈل پر مبنی نہیں ہو سکتا۔
کیونکہ GPT-5 کی بنیادی معلومات کی تاریخ ستمبر 2024 تک ہے۔
سوچنے کا موڈ بہت زیادہ احتمال کے ساتھ پیچھے سے لگاتار اپڈیٹ ہونے والے O سیریز انفرینس ماڈلز (جیسے o4 یا اپڈیٹڈ o3) سے جڑا ہوا ہے۔
بڑے ماڈل پہلے O سیریز کے خاص طویل سوچنے کے مکینزم کا استعمال کرتے ہوئے، پوشیدہ جگہ میں تجارتی منطق، مخاطب کے نفسیات، اور ڈیزائن کے کوآرڈینیٹس کو مکمل طور پر حساب کرتا ہے، اور پھر آخری پکسل رینڈرنگ کے لیے ویژول ماڈیول کو منتقل کرتا ہے۔
بے شک، ایک اور ممکنہ راستہ بھی ہے:
اوپن اے آئی کے اندر بہت دقیق کمپیوٹنگ ریسورسز کے انتظام کے تحت، فاسٹ موڈ ممکنہ طور پر گٹی-5 نینو کو بیس لائن کے طور پر استعمال کرتا ہے، جبکہ تھنکنگ موڈ تھوڑا بڑا جی پی ٹی-5 مائیکرو اور باہری ٹولز کو استعمال کرتا ہے۔
لیکن چاہے آپ کسی بھی بنیادی کمبو کا استعمال کر رہے ہوں، اگر آپ OpenAI کے API ایکوسسٹم پر مستقل نظر رکھتے ہیں تو آپ دیکھیں گے کہ اس کی بنیادی پیداواری منطق پہلے ہی Midjourney سے بالکل الگ سطح پر ہے۔
حصہ 04: لوگوں کی سب سے زیادہ فکر کیا ہے، قیمت گذاری
لیکن اصل میں اپنے ورک فلو میں اسے شامل کرنے والے ڈیولپرز اور کمپنیوں کے لیے، زیادہ اہم بات وہ بہت عملی اور غیر منطقی API قیمت گاہ ہے۔
پہلے DALL-E 3 کو فی تصویر کے حساب سے چارج کیا جاتا تھا (مثلاً 0.04 امریکی ڈالر فی تصویر)۔
لیکن پہلی نسل GPT-Image-1 سے، OpenAI نے اسے مکمل طور پر ٹوکن کے لحاظ سے بلنگ کے فریم ورک میں تبدیل کر دیا ہے۔
GPT-Image-2 اس معیار کو برقرار رکھتا ہے، اور اس کے علاوہ، اس نے مزید فائدے کے ساتھ قیمت کم کر دی ہے۔
آفیشل طور پر جاری کردہ قیمت کی فہرست کے مطابق، ہر ملین ٹوکن کی قیمت درج ذیل ہے۔
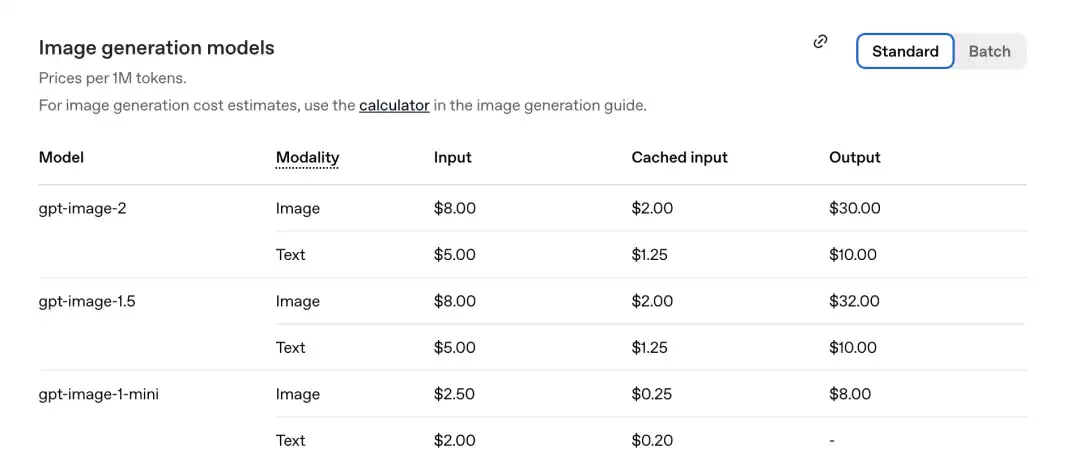
GPT-Image-2 تصویری حصہ: درج کریں 8.00، کیشڈ انپٹس (Cachedinputs) 2.00، آؤٹ پٹ $30.00۔
پچھلی نسل gpt-image-1.5 کے مقابلے میں: خروجی $32.00 ہے۔
نیا ماڈل اب زیادہ سستا ہے۔
آئیے ایک حساب لگاتے ہیں۔
پچھلے ماڈلز میں، ایک اعلیٰ معیار کی تصویر بنانے کے لیے تقریباً 1000 سے 1500 آؤٹ پٹ ٹوکنز کا استعمال ہوتا تھا۔
ہر ملین ٹوکن کے لیے 30 امریکی ڈالر کی قیمت کے مطابق، ایک تصویر بنانے کی اصل لاگت تقریباً 0.03 سے 0.045 امریکی ڈالر کے درمیان ہوتی ہے (تقریباً 2 سے 3 چنے کے برابر)۔
اگر آپ کو فوری جواب کی ضرورت نہیں ہے اور آپ آفیشل طور پر فراہم کردہ Batch (بیچ) API موڈ استعمال کرتے ہیں، تو یہ قیمت مزید آدھی ہو جائے گی (آؤٹ پٹ فوراً $15.00 پر گر جائے گا)۔
محاسبہ کے مطابق، ایک تصویر بنانے کی کم سے کم لاگت صرف ایک دہائی سے زائد ہے۔
یہ قیمت پہلے سے ہی بہت معقول ہے، لیکن اس کا اصل طوفان، قیمت کی جدول میں موجود کیشڈ ان پٹس (Cached inputs) ہے۔
پہلے کامکس یا ایک ہی سیریز کے پوسٹر ڈیزائن بناتے وقت، ہر بار نئی تخلیق کے لیے آپ کو بہت ساری کردار ریفرنس تصاویر، پچھلی کہانی اور لمبے پرامپٹس دوبارہ اپ لوڈ کرنے پڑتے تھے، جس کا ان پٹ اخراج بہت زیادہ تھا۔
لیکن موجودہ ٹوکن بیلینس کے تحت، جب آپ اسے ایک ساتھ 8 مسلسل کامکس بنانے کے لیے کہتے ہیں، تو پہلی تصویر کے ویژول عناصر کو براہ راست کنٹیکس کی کیش میں محفوظ کر لیا جاتا ہے۔
دوسری تصویر سے شروع کرتے ہوئے، تصویر کی درج کرنے کی لاگت فوراً 8.00 ڈالر سے گھٹ کر 2.00 ڈالر ہو گئی (یعنی صرف 25% کا تحصیل کیا جا رہا ہے)۔
اس کا مطلب یہ ہے کہ بڑے پیمانے پر تجارتی بیچ میں تصویریں بنانے، یا بالکل ایک جیسے کرداروں کی مسلسل تخلیق کے لیے، اس کا حاشیہ لاگت براہ راست کم ہو جائے گی۔
جتنا زیادہ ماڈل ذکی اور زیادہ تصویریں بنائے، اتنا ہی کم ہو جائے گا ہر تصویر کا اوسط اخراج۔
یہ صنعتی بلنگ منطق وہ چیز ہے جو لائن پر کام کرنے والے مصور کو حتمی طور پر پریشان کر دے گی۔
پارٹ.05 پیچھے کی ٹیم کا انکشاف
آخر میں، ہم اس لائیو ایونٹ میں پیش کیے گئے OpenAI کے اندر کے ویژول ٹیم کو دوبارہ دیکھتے ہیں، جس کی بدولت کئی ایسے فنکشن جو پہلے بے حد لگتے تھے، اب مکمل طور پر سمجھ میں آ جاتے ہیں۔
مثلاً، یہ کیسے متعدد زبانوں کی پیچیدہ ٹائپوگرافی اور بے معنی نشانات کے مسائل کو حل کرتا ہے۔
اس کے لیے ٹیم کے سینئر سائنسدان گابریل گو کی ضرورت ہے۔

اس اکیڈمک دنیا میں، وہ کلپ نامی انقلابی بہ متاثر مدل کے مرکزی مصنف کے طور پر سب سے زیادہ مشہور ہیں۔
CLIP نے جدید AI کو انسانی زبان اور تصویری پکسلز کے درمیان تعلق کو سمجھنے کی بنیاد رکھی۔
اس بین الائیکی مفہومی نقشہ سازی کے ماہر کی قیادت میں، GPT-Image-2 صرف متن کے شکلوں کا اندازہ نہیں لگا رہا، بلکہ اصل میں پکسل لیول پر لکھ رہا ہے۔
دوسری طرف، یہ تین بعدی فضا کے تعلقات کو کیسے سمجھتا ہے، انتہائی لمبے اور تنگ نسبت کے 360 ڈگری پینورامک تصاویر بناتا ہے، اور چاول کے دانے پر مائیکرو کی شکل میں روشنی اور سایہ کو سمجھتا ہے۔
یہ دوسرے اہم رکن ایلیکس یو کی وجہ سے ہے۔

اس سے پہلے کہ وہ OpenAI میں شامل ہوئے، وہ 3D جنریشن کے شعبے کی مشہور اسٹارٹ اپ Luma AI کے ملکیت دار اور سابق CTO تھے، اور 3D نیورل رینڈرنگ (NeRF وغیرہ) پر توجہ مرکوز کرنے والے عالمی سطح کے ماہرین میں سے ایک تھے۔
اس کی موجودگی میں، GPT-Image-2 اصل میں روایتی 2D پکسل کی ترمیم سے باہر نکل چکا ہے۔
یہ احتمالاً دماغ میں پہلے ایک تین بعدی منظر بناتا ہے، روشنی کو ترتیب دیتا ہے، اور پھر آپ کو ایک درست 2D کٹنگ کا رینڈر دیتا ہے۔
وہ بہت خوفناک متعدد صفحات والی کامک کی ایک جانی کیسے حاصل کی گئی۔
یہ مسچوسٹس انسٹیٹیوٹ آف ٹیکنالوجی (MIT CSAIL) سے تازہ گریجویٹ نوجوان جوڑے کے لیے ہے:
بویوان چین (بائیں) اور کیوان سانگ ( دائیں)۔
ان کا اکادمیک مرکزی شعبہ عالمی ماڈلز اور جسمانی ذہانت کہلاتا ہے۔
مشین کو فزیکل دنیا کے کام کرنے کے طریقے کو سمجھنے کی تعلیم دینا، اور کرداروں کو مختلف وقت اور جگہ کے سین میں اپنی خصوصیات مکمل طور پر برقرار رکھنا، جس میں کوئی تبدیلی نہ ہو، بالکل وہی مسئلہ ہے جس پر یہ دونوں ماہرین لگاتار کام کر رہے ہیں۔
آخر میں، استدلال بڑے ماڈلز اور ویژول بنیادی منطق کو جوڑنے پر لگاتار کام کر رہے Nithanth Kudige (بائیں، O سیریز استدلال ماڈل کے اہم مصنف) اور Kenji Hata ( دائیں، سابق گوگل ریسرچر، اسٹینفورڈ ویژول لیب سے فارغ التحصیل) کو شامل کریں۔

جب یہ لوگ اکٹھے ہو جاتے ہیں، تو بنیادی منطقی استدلال، 3D فضا رینڈرنگ، گرافکس اور متن کی بہترین ترتیب، اور فزیکل دنیا کے قوانین ایک ہی ماڈل میں آسانی سے جُڑ جاتے ہیں۔
پارٹ.06 GPT-Image-2 کا حد
کسی بھی ماڈل کے حدود ہوتے ہیں۔
سیکورٹی کی طرف سے بھی تسلیم کیا گیا ہے کہ وہ کچھ انتہائی صورتحالوں کا مقابلہ کرتے وقت پریشان رہتی ہے۔
جیسے کہ کاغذ کے طریقہ کار، کیوب کو حل کرنا، یا بہت زیادہ مکمل ریت کے دانوں جیسی بہت زیادہ تکرار والی تفصیلات، جو اس کی صلاحیتوں کی حد تک پہنچ جاتی ہیں۔
لیکن تجارتی застосування کے سندھ میں، یہ بہت چھوٹی خامی ہے۔
پورے ڈیزائن صنعت کے لیے، ہمیں خوف پھیلانے کی ضرورت نہیں، یہ خوبصورتی کے خاتمے کا نہیں ہے۔
ذوق، تجارتی بصیرت اور حکمت والے لوگ اس سے اب بھی بہترین چیزیں بناسکتے ہیں۔
لیکن ایک واقعی حقیقت یہ ہے کہ ڈیزائنر کے پیشے کی دفاعی دیوار کو عملی طور پر تباہ کر دیا گیا ہے۔
پہلے، ڈیزائن سافٹ ویئر کے شارٹ کٹس کو یاد رکھنا، فونٹس کو سیدھا اور مستوی لائن میں الائن کرنا، زبان کے مطابق ٹیکسٹ کا لے آؤٹ کرنا، اور تفصیلی تصویری ترمیم اور پس منظر ہٹانے کا علم رکھنا اپنا روزی روٹی کا ذریعہ تھا۔
لیکن اب مشکل ہو جائے گا، کیونکہ جو مہارتیں پہلے صاف طور پر قیمت لگا کر ٹریڈ کی جاتی تھیں، وہ اب کسی بھی شخص کے لیے ایک جملہ کے ذریعے مفت استعمال کی جانے والی بنیادی ہدایات بن گئی ہیں۔
کچھ عرصہ خاموشی کے بعد، OpenAI نے ایک بہت ہی خاموش، لیکن بہت طاقتور انداز میں ثابت کر دیا کہ اس ٹیبل پر کس کے ہاتھ میں حقیقی کارڈ ہیں۔
پرانا ایگزیکیشن ٹول چین ٹوٹ رہا ہے، اور صنعت کے لیے سوال یہ نہیں رہ گیا کہ AI کیا ہم کو بدل دے گا، بلکہ یہ ہے کہ ہم اس مکمل نئی پروڈکشن لائن کے ساتھ کیسے مطابقت رکھیں۔