









گزشتہ هفتے جب Anthropic نے Mythos Preview جاری کیا، تو سیکورٹی کمیونٹی کی رد عمل ایک لفظ میں بیان کیا جا سکتا ہے: حیرانی۔
ایک AI ماڈل نے خود بخود FreeBSD میں 17 سالوں سے چھپا ہوا ریموٹ کوڈ ایکزیکیشن کا خطرہ دریافت کیا، OpenBSD میں 27 سالوں تک نظر انداز کیا گیا TCP پروٹوکول کا خامی پایا، اور ایک کام کرنے والے حملے کا کوڈ خود لکھ دیا۔ اینتھرپک نے بعد میں پروجیکٹ گلاس ونگ کا اعلان کیا، کچھ ٹیکنالوجی کمپنیوں کے ساتھ ایک联盟 تشکیل دی، اور اوپن سورس سافٹ ویئر کے سیکورٹی خامیوں کو درست کرنے کے لیے ایک ارب ڈالر کے استعمال کے ا額 کا وعدہ کیا۔
یہ سلسلہ آپریشنز صنعت کی اعصاب کو بہت زیادہ متاثر کر رہا ہے، مائتھوس اتنی طاقتور کیسے ہو سکتا ہے، انسانوں کا خاتمہ ہو رہا ہے… انتظار کریں، اتنی جلدی نہیں۔
سستے ماڈل بھی اسی خامی کو تلاش کر سکتے ہیں
AISLE ایک ایسی اسٹارٹ اپ ہے جو AI سیکیورٹی پر کام کرتی ہے۔ 2025 کے وسط سے، وہ AI سسٹم کا استعمال کرکے اوپن سورس سافٹ ویئر میں خامیاں اور پیچھے کی تبدیلیاں تلاش کر رہی ہیں، جس کے نتیجے میں اب تک اوپن سورس کمیونٹی کے تسلیم کردہ 180 سے زائد سیکیورٹی خامیوں کو درست کر چکی ہیں، جن میں کچھ 25 سال سے زیادہ پوشیدہ مسائل بھی شامل ہیں۔
میتھوس کے بعد، انہوں نے ایک تیز عمل کیا: میتھوس میں ظاہر ہونے والے خامیوں کو بہت سستے مائیکرو ماڈلز پر چلایا۔ انہیں "زیرو ڈے ویولنریبلٹیز" کہا جاتا ہے، جن کا خطرہ بہت زیادہ ہے، اور جب بھی ان کا پتہ چلتا ہے، سیکورٹی افراد کے پاس تقریباً کوئی ری ایکشن ٹائم نہیں ہوتا۔
نتیجہ حیران کن تھا۔
مایثوس نے جو 17 سالوں تک چھپا ہوا خلل تلاش کیا، وہ اینتھرپک نے جاری کرتے وقت "پیٹھ دکھانے" کے لیے استعمال کیا گیا تھا۔ AISLE نے 8 ماڈلز کا ٹیسٹ کیا، جن میں سے ہر ایک میں خلل کامیابی سے تلاش کر لیا گیا، جس میں ایک چھوٹا پیرامیٹر والا، صرف 0.11 امریکی ڈالر فی ملین ٹوکن کے اخراج والے ماڈل بھی شامل ہے، جو مایثوس کے اخراج کا تقریباً کئی گنا کم ہے۔ اس میں، DeepSeek R1 سب سے زیادہ درست تھا، جو جاری کردہ خلل استعمال کے دستاویزات میں درج حقیقی اسٹیک لے آؤٹ سے مطابقت رکھتا تھا۔
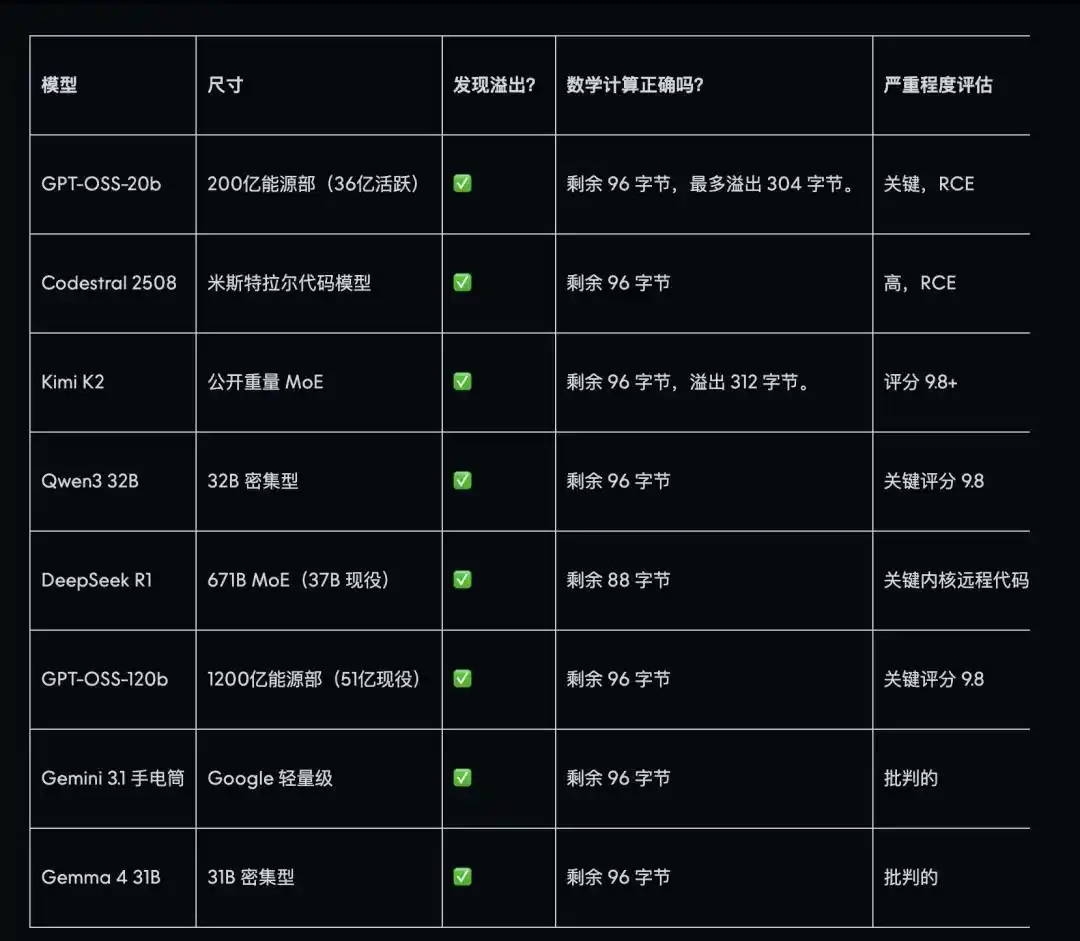
زیادہ تر ماڈلز نے صرف خامیاں ہی نہیں، بلکہ یہ بھی درست طریقے سے جانچ لیا کہ ان خامیوں کو ریموٹ طور پر استعمال کیا جا سکتا ہے، اور خطرے کے درجے کا تعین کیا۔
دوسرا خلل، جو 27 سال تک چھپا رہا، زیادہ مشکل تھا اور اس کے لیے زیادہ گہرے ریاضیاتی اصولوں کی سمجھ درکار تھی۔ GPT-OSS-120b نے ایک بار میں پورے حملے کا راستہ دوبارہ بنایا اور A سوسائٹی کے اصل مرمت کے منصوبے کے تقریباً مطابق ایک پچ پیش کیا۔ Kimi K2 نے بھی عمدہ کام کیا، اور اس خلل کے لیے بعد میں سکافولڈنگ کے دوران، صرف تین آسان API کالوں کے ذریعے، بغیر کسی ایجینٹ انفراسٹرکچر کے، Mythos کی اعلانات میں بیان کردہ حملے کے منطق کے بہت قریب نتائج حاصل کیے۔
لیکن سب سے دلچسپ بات یہ نہیں کہ کس نے درست جواب دیا، بلکہ یہ ہے کہ کس نے غلط جواب دیا: سب سے مہنگا ماڈل نے سب سے آسان سوال کا غلط جواب دیا۔
ایسل نے ایک بہت بنیادی سوال پیش کیا، جو سیکورٹی صنعت کے لیے تقریباً "ابتدائی تعلیم کا امتحان" ہے: ایک کوڈ کا ٹکڑا لگتا ہے کہ اس میں سیکورٹی خامی ہے، لیکن اگر آپ دھیان سے دیکھیں تو پتہ چلتا ہے کہ مسائل والے ڈیٹا کو درمیان میں ہی چھوڑ دیا گیا ہے، جس کی وجہ سے اصل میں کوئی نقصان نہیں ہوتا۔
ایک ایسی گولی جو خطرناک لگ رہی ہے، لیکن اس کی گولی درمیان میں نکال دی گئی ہے، یہ ایک ایسا "جھوٹا اقدام" ہے جو اب خطرناک نہیں ہے، لیکن بہت خراب ڈیزائن کیا گیا ہے۔

زیادہ تر سب سے مہنگے اور طاقتور ترین ایڈوانسڈ ماڈلز نے غلط جواب دیا، کلوڈ سونٹ 4.5 نے اپنا غلط جواب بڑی اعتماد کے ساتھ دیا، جبکہ GPT-4.1 اور GPT-5.4 سیریز بھی اس سے بچ نہیں پائیں۔ جبکہ DeepSeek R1 نے چاروں تجربات میں درست طریقے سے پہچان لیا، اور GPT-OSS-20b اور OpenAI o3 بھی اسے پہچان سکے۔
سیکورٹی ایک لمحے میں حاصل نہیں ہوتی
یہ دریافتوں نے AISLE کو ایک تصور پیش کیا: دندان دار سرحد۔
AI کی سیکیورٹی کابیلیت یہ نہیں ہے کہ مدل بڑا ہو تو زیادہ طاقتور ہو، یہ بے ترتیب ہے، اور مختلف کاموں پر رینکنگ مکمل طور پر بدل جاتی ہے۔ ایک ہی مدل، ایک ٹیسٹ میں مکمل نمبر حاصل کر سکتا ہے، اور دوسرے ٹیسٹ میں خود اعتمادی سے کہہ دے کہ "کوڈ ٹھیک ہے"۔ دوسرا مدل پیچیدہ کاموں پر بہترین کارکردگی دکھا سکتا ہے، لیکن بنیادی سوالات پر سب سے بنیادی غلطیاں کر دے۔
"بہترین محفوظ AI" موجود نہیں ہے، صلاحیتوں کا حدود دندان دار ہوتا ہے۔
یہ ٹیسٹ جیسے، یہ نہیں کہ مائتھوس مضبوط نہیں ہے۔ ان کے تجربات میں، چھوٹے ماڈلز کو خرابیوں سے متعلق کوڈ دیا گیا تھا، جو الگ طور پر نکال کر چھوٹے ماڈلز کو دکھایا گیا تھا، جس سے انہیں یہ بتایا گیا کہ "دیکھو یہاں، کیا کوئی مسئلہ ہے؟" یہ تقریباً تھوڑا سا چِٹ کرنا تھا۔
میتھوس کی بڑی خوبی اس کی مکمل خودمختاری ہے، جو اسے لاکھوں فائلوں میں سے وہ جگہیں تلاش کرنے کی صلاحیت دیتی ہے جن پر تفصیل سے نظر ڈالنے کی ضرورت ہے، فرضیات بناتی ہے، مسائل کی تصدیق کرتی ہے، اور حملہ کے کوڈ لکھتی ہے—پوری پروسیجر خودکار طور پر۔

لیکن اس کے بعد، ایسل کا خیال ہے کہ اس "مکمل خودکار" کی قیمت بنیادی طور پر انجینئرنگ ڈیزائن سے آتی ہے، نہ کہ ماڈل کی ذکاوت سے۔
مثلاً، AI کے ذریعے خامیوں کی تلاش کرنا تقریباً کچھ مراحل پر مشتمل ہے: پہلے کوڈ بیس کو وسیع پیمانے پر اسکین کرکے مشکوک جگہوں کو تلاش کریں، پھر گہرائی سے جانچیں کہ کیا واقعی خامی موجود ہے، اس کے بعد شدت کا جائزہ لیں، اور آخر میں اسے درست کرنے کے لیے پیچ لکھیں۔ ان مراحل کے درمیان مشقت کا فرق بہت زیادہ ہے۔
"مسئلہ تلاش کرنا" کا مرحلہ سستے ماڈلز کے لیے بھی قابل انجام ہے۔ اصل مشکل یہ ہے کہ ان مراحل کو ایک قابل اعتماد لائن میں کیسے جوڑا جائے: AI کو صحیح جگہ تلاش کرنے، غلط مثبت کو نکالنے، تاکیک تیار کرنے اور اسے لاگو کرنے کے لیے۔
AI سیفٹی کے لیے کچھ چیزوں کی ضرورت ہوتی ہے: AI کی ذکاوت، چلانے کی لاگت، چلانے کی رفتار، اور پورے سسٹم اور ٹیم میں گھل مل جانے والی سیفٹی کی ماہرینہ۔ Anthropic نے پہلی چیز کو بہترین بنایا ہے، لیکن AISLE کا تجربہ یہ ہے کہ باقی چیزیں بھی اتنی ہی اہم ہیں، کبھی کبھی اس سے بھی زیادہ۔ AISLE کا اپنا سسٹم کئی مختلف مڈلز کا استعمال کرتا ہے، اور سب سے بہترین مڈل ٹاسک کے مطابق بار بار تبدیل ہوتا رہتا ہے، OpenSSL کے ٹیکنالوجی ہدایت کار نے انہیں "اونچی معیار کی رپورٹس اور تعمیری تعاون" کہا ہے۔

اس قسم کے اعتماد کا قیام، استعمال کی جانے والی ماڈل کی کس کمپنی کی ہونے سے زیادہ تعلق نہیں رکھتا، ان کا بہترین نتیجہ Anthropic کے ماڈل سے نہیں آیا۔
ایک عملی نتیجہ یہ ہے کہ چونکہ سستے ماڈلز "مسئلہ تلاش کرنے" کے مرحلے میں کافی کارآمد ہیں، اس لیے آپ کو مہنگے ماڈل کو صرف کچھ مشکوک جگہوں پر مخصوص طور پر ہدایت نہیں دینی چاہیے۔ آپ سستے ماڈلز کی ایک ٹیم کو تمام کونوں میں بھیج سکتے ہیں۔ ایک عظیم محقق کے مقابلے میں، ہر کمرے کو چیک کرنے کے لیے ایک ہزار اچھے محقق زیادہ موثر ثابت ہو سکتے ہیں۔
اینٹروپک کا پرومو درست ہے لیکن اس میں کچھ حد تک بھٹکاوٹ بھی ہے، جس میں ان مراحل کو ایک ساتھ ملا دیا گیا ہے، جس سے لگتا ہے کہ ہر مرحلہ سب سے بہترین AI کی ضرورت رکھتا ہے، جبکہ ایسا نہیں ہے۔
میتھوس نے ثابت کر دیا ہے کہ "AI خود کار طور پر خامیاں تلاش کر سکتی ہیں" اور اس کی خودکاری کا درجہ بہت بلند ہو سکتا ہے۔ لیکن صرف میتھوس جیسے سطح کے ماڈل ہی اس کام کو کر سکتے ہیں، یہ دعویٰ صرف آدھی بات ہے۔ حفاظتی دیوار ماڈل میں نہیں، سسٹم میں ہے۔
اس کا پورے صنعت کے لیے ممکنہ طور پر مائتھوس سے بھی زیادہ اہمیت ہے۔ جب کلیدی حفاظت کا معیار سب سے طاقتور AI رکھنے کے بجائے AI کو ایک قابل اعتماد عملی عمل میں کیسے منظم کیا جائے، اس پر منحصر ہو، تو AI حفاظت صرف ایک کمپنی کا اکیلا علاقہ نہیں ہوگی۔ یہ ایک生态 بن جائے گی، جہاں کئی ٹیمیں مختلف AI کامبینیشنز اور مختلف ماہرین کی مدد سے ایک ہی کام کرتی ہیں۔
یہ اچھی بات ہو سکتی ہے کہ دنیا بھر کے سافٹ ویئر کو محفوظ بنایا جائے، اور صرف ایک کمپنی کے ایک ماڈل پر انحصار نہیں کیا جانا چاہئے۔
یہ مضمون ویچن گروپ "APPSO" سے ہے، مصنف: APPSO جو کل کے پروڈکٹس کی دریافت کرتا ہے