










اصل مصنف: کارن زی، فورسائٹ نیوز
20 مارچ 2026 کو، آل-این وینچر کاسٹ پر ایک غیر معمولی بات چیت ہوئی۔
وینچر کیپٹلسٹ چماث پالیہاپٹیا نے نووید کے سی ای او ہوانگ رینکون کو بات کا تھا دیا، کہ بٹ ٹینسر پر ایک پروجیکٹ نے ایک کافی پاگل پن والا ٹیکنالوجی کا کام مکمل کر لیا ہے — انٹرنیٹ پر ڈسٹریبیوٹڈ کمپوٹنگ کا استعمال کرتے ہوئے ایک بڑا زبانی ماڈل تربیت دیا گیا، جس کا عمل مکمل طور پر ڈی سینٹرلائزڈ تھا اور کسی بھی مرکزی ڈیٹا سینٹر کا کوئی حصہ نہیں تھا۔
ہو رنیون نے اس بات سے گریز نہیں کیا۔ اس نے اسے "Folding@home" کے جدید ورژن کے طور پر بیان کیا، جو 2000 کی دہائی میں عام صارفین کو اپنی بے استعمال کی گئی کمپیوٹنگ طاقت فراہم کرنے اور پروٹین فولڈنگ کے مسائل کا مقابلہ کرنے کے لیے ایک ڈسٹریبیوٹڈ پراجیکٹ تھا۔
4 دن پہلے، 16 مارچ کو، اینتھرپک کے سہقائم کنندہ جیک کلارک نے AI تحقیق کی ترقیات کی ایک رپورٹ میں اس کامیابی کو زیادہ توجہ دی اور اس کا حوالہ دیا: بٹ ٹینسر ایکوسسٹم کا سب نیٹ Templar (SN3) نے 72 ارب پیرامیٹرز کے بڑے ماڈل (Covenant 72B) کی تقسیم شدہ تربیت مکمل کر لی ہے، جس کی مصنوعی ذہانت کی صلاحیت میٹا کے 2023 میں جاری کردہ LLaMA-2 کے برابر ہے۔
جیک کلارک نے اس سیکشن کا نام "ڈسٹریبیوٹڈ ٹریننگ کے ذریعے AI پالیٹیکل ایکونومی کو چیلنج کرنا" رکھا اور اپنے تجزیہ میں زور دیا کہ یہ ایک ایسی ٹیکنالوجی ہے جس کا مستقل طور پر نگرانی کی جانی چاہیے — وہ ایک مستقبل کا تخیل کر سکتے ہیں جہاں ڈیوائس پر AI، ڈسٹریبیوٹڈ ٹریننگ سے تیار کردہ ماڈلز کو بڑے پیمانے پر استعمال کرے گا، جبکہ کلاؤڈ AI مخصوص بڑے ماڈلز کو چلاتا رہے گا۔
بازار کی 반응 تھوڑی دیر سے ہوئی لیکن بہت شدید تھی: SN3 پچھلے ایک ماہ میں 440% سے زیادہ بڑھ چکا ہے، پچھلے دو ہفتے میں 340% سے زیادہ، اور اس کی کل قیمت 130 ملین امریکی ڈالر تک پہنچ گئی ہے۔ سب نیٹ کے نریٹیو کا افراط، TAO پر خریداری کا دباؤ بن کر براہ راست اثر انداز ہوگا۔ اس لیے، TAO تیزی سے بڑھا، ایک وقت پر 377 امریکی ڈالر تک پہنچا، پچھلے ایک ماہ میں دوگنا ہوا، اور FDV تقریباً 75 ارب امریکی ڈالر تک پہنچ گیا۔
سوال یہ ہے:SN3 نے بالآخر کیا کیا؟ اسے اتنی توجہ کیوں ملی؟ ڈسٹریبیوٹڈ ٹریننگ اور ڈیسینٹرلائزڈ AI کی قیمت کی کہانی کیسے ترقی کرے گی؟
وہ 72B ماڈل
اس سوال کا جواب دینے کے لیے، SN3 کی کارکردگی کو واضح طور پر دیکھنا ہوگا۔
10 مارچ 2026 کو، Covenant AI ٹیم نے arXiv پر ایک ٹیکنیکل رپورٹ جاری کر کے Covenant-72B کی تربیت مکمل ہونے کا اعلان کیا۔ یہ ایک 720 ارب پیرامیٹرز والا بڑا زبانی ماڈل ہے، جسے تقریباً 1.1 تریلین ٹوکنز کے کارپس پر 70 سے زائد الگ نوڈس پیرز (ہر راؤنڈ میں تقریباً 20 نوڈس سینکرونائز ہوتے ہیں، جن میں سے ہر نوڈ پر 8 B200 گرافکس کارڈ لگے ہوئے ہیں) پر پری-ٹرین کیا گیا۔
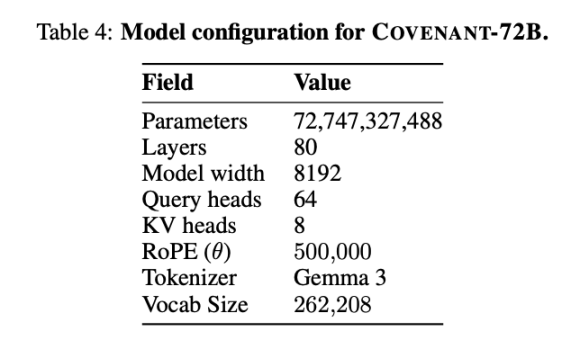
ٹیمپلر نے بنچ مارک کے حوالے سے کچھ ڈیٹا فراہم کیا، جس میں مقابلہ LLaMA-2-70B سے کیا گیا جو میٹا نے 2023 میں جاری کیا تھا۔ جیسے اینتھرپک کے ملکہ متحدہ جیک کلارک نے کہا، Covenant-72B 2026 میں کچھ زمانہ سے گزر چکا ہو سکتا ہے۔ Covenant-72B کا MMLU پر 67.1 اسکور، میٹا کے 2023 میں جاری کردہ LLaMA-2-70B (65.6 اسکور) کے تقریباً برابر ہے۔
جبکہ 2026 کے سب سے آگے کے ماڈلز — چاہے GPT سیریز، Claude یا Gemini ہوں — پہلے ہی لاکھوں GPU پر 100 ارب سے زیادہ پیرامیٹرز کے ساتھ تربیت پا چکے ہیں، اور ان کی استدلال، کوڈنگ اور ریاضی کی صلاحیتوں میں فرق صدفی نہیں بلکہ ایک درجہ کا فرق ہے۔ اس حقیقی فرق کو مارکیٹ کے جذبات نہیں دھو سکتے۔
لیکن "کھلے انٹرنیٹ پر ڈسٹریبیوٹڈ کمپیوٹنگ پاور کے ذریعے تربیت دی گئی" کے پیش نظر، اس کا مطلب بالکل مختلف ہو جاتا ہے۔
ایک تقابلی جائزہ: ڈی سینٹرلائزڈ ٹریننگ کے تحت تیار کیا گیا INTELLECT-1 (Prime Intellect ٹیم، 10 ارب پیرامیٹرز) کا MMLU اسکور 32.7 ہے، جبکہ دوسرے ڈسٹریبیوٹڈ ٹریننگ پروجیکٹ Psyche Consilience (40 ارب پیرامیٹرز)، جس میں صرف وائٹ لسٹ شدہ شرکاء شامل تھے، کا اسکور 24.2 ہے۔ Covenant-72B، جو 72B پیرامیٹرز کے ساتھ 67.1 کا MMLU اسکور رکھتا ہے، ڈی سینٹرلائزڈ ٹریننگ کے شعبے میں ایک نمایاں کارکردگی ہے۔
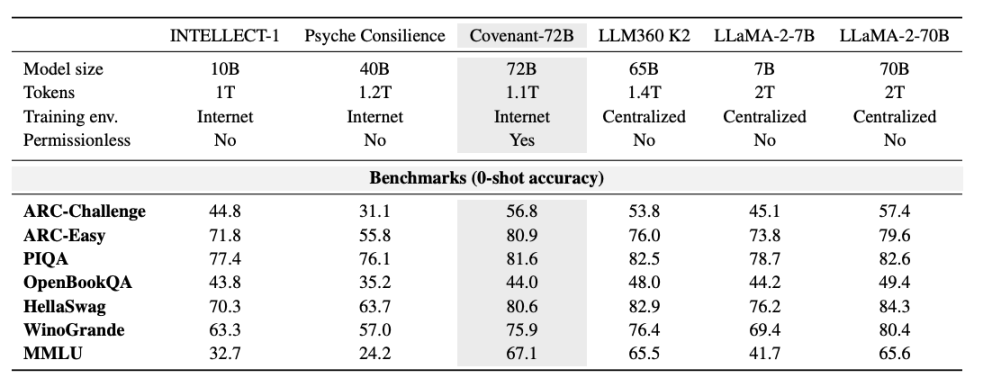
زیادہ اہم بات یہ ہے کہ یہ تربیت "اجازت کے بغیر" ہے۔ کوئی بھی بغیر پہلے سے جانچ کے، بغیر سفید فہرست کے، شرکت کرنے والے نوڈ میں شامل ہو سکتا ہے۔ ماڈل اپڈیٹ میں 70 سے زائد الگ الگ نوڈز شامل ہوئے، جو دنیا بھر سے کنکشن کر کے کمپوٹیشنل طاقت فراہم کر رہے ہیں۔
ہو رینکسن نے کیا کہا، کیا نہیں کہا
اس "تفہیم" کی تشریح کو درست کرنے کے لیے پॉडکاسٹ کے مکالمے کے تفصیلات کو دوبارہ ترتیب دیں۔
چماث پالیہاپٹیا نے بات چیت میں بٹٹنسور کی ٹیکنیکل کامیابی کو ہوئنگ نیون کو پیش کیا اور اسے ڈسٹریبیوٹڈ کمپوٹنگ پر لاما ماڈل کو ٹرین کرنے کے طور پر بیان کیا، جس کا عمل "مکمل طور پر ڈسٹریبیوٹڈ، جبکہ حالت برقرار رکھی جاتی ہے"۔ ہوئنگ نیون کے جواب میں اسے "جدید Folding@home" کے طور پر تشبیہ دی گئی اور اوپن سورس اور پراپرائٹری ماڈلز کے ساتھ ساتھ وجود کی ضرورت پر بحث ہوئی۔
یہ قابل ذکر ہے کہ ہوئنگ یین کھون نے بٹ ٹینسر کے ٹوکن یا کسی بھی سرمایہ کاری کے معنی کا ذکر نہیں کیا، اور مرکزیت سے آزاد AI ٹریننگ پر مزید بحث نہیں کی۔
بٹٹنسور سب نیٹ اور SN3 کو سمجھیں
SN3 کے برجستہ ہونے کو سمجھنے کے لیے، سب سے پہلے بٹ ٹینسر اور اس کے سب نیٹ کے کام کرنے کے منطق کو سمجھنا ضروری ہے۔ آسان الفاظ میں، بٹ ٹینسر کو ایک AI پبلک چین اور پلیٹ فارم کے طور پر دیکھا جا سکتا ہے، جبکہ ہر سب نیٹ ایک الگ "AI پروڈکشن لائن" کے برابر ہوتا ہے، جس کا اپنا واضح مرکزی کام، اپنا انعامی نظام ہوتا ہے، اور جو مل کر ایک ڈی سینٹرلائزڈ AI ایکوسسٹم بناتا ہے۔
اس کا عمل واضح اور مرکزیت سے آزاد ہے: ذیلی نیٹ ورک مالکین ذیلی نیٹ ورک کے مقاصد کو تعریف کرتے ہیں اور انعامی ماڈل ترتیب دیتے ہیں؛ مائنوں ذیلی نیٹ ورک میں کمپوٹنگ طاقت فراہم کرتے ہیں اور AI سے متعلق کام جیسے استدلال، تربیت، اور ذخیرہ سازی وغیرہ پورے کرتے ہیں؛ ویریفائرز مائنوں کے اہداف کو اسکور دیتے ہیں اور ان اسکورز کو Bittensor کانسنسس لیئر پر اپ لوڈ کرتے ہیں؛ آخرکار، Bittensor کا Yuma کانسنسس الگورتھم مختلف ذیلی نیٹ ورکس میں جمع ہونے والے انعامات کے بنیاد پر ذیلی نیٹ ورک شرکاء کو متعلقہ منافع تقسیم کرتا ہے۔
بٹیٹنسور پر اب تک 128 سب نیٹس موجود ہیں جو استدلال، سرور کے بغیر AI کلاؤڈ سروسز، تصاویر، ڈیٹا اینوٹیشن، ری انفورسمنٹ لرننگ، اسٹوریج، کمپوٹیشن سمیت مختلف AI کاموں کو کور کرتے ہیں۔
اور SN3 ان میں سے ایک سب نیٹ ہے۔ یہ ایپلیکیشن لیور کا کوئی لیئر نہیں بناتا، نہ ہی کوئی موجودہ بڑے ماڈل API کرایہ پر لیتا ہے، بلکہ یہ AI صنعت کے سب سے مہنگے اور سب سے بند ترین مرکزی حصوں میں سے ایک، یعنی بڑے ماڈل کی پری ٹریننگ کو ب без توجہ دیتا ہے۔
SN3 بٹیٹنسور نیٹ ورک کا استعمال کرکے غیر متجانس کمپیوٹنگ وسائل کی توزیع شدہ تربیت کو ہدایت کرنا چاہتا ہے، جس سے انعامی توزیع شدہ بڑے ماڈل تربیت کے ذریعے ثابت ہوتا ہے کہ مہنگے مرکزی سوپر کمپیوٹر کلبس کے بغیر بھی طاقتور بنیادی ماڈلز تربیت دیے جا سکتے ہیں۔ مرکزی خصوصیت "مساوات" ہے — مرکزی تربیت کے وسائل کے اکتساب کو توڑنا، جس سے عام افراد یا چھوٹے اور درمیانے ادارے بھی بڑے ماڈل تربیت میں شامل ہو سکیں، اور توزیع شدہ کمپیوٹنگ طاقت کے ذریعے تربیت کے اخراجات میں کمی آئے۔
SN3 کی ترقی کا مرکزی طاقت Templar ہے، جس کے پیچھے تحقیقی ٹیم Covenant Labs ہے۔ یہ ٹیم دو اور سب نیٹس بھی چلاتی ہے: Basilica (SN39، کمپوٹنگ سروسز پر مبنی) اور Grail (SN81، RL کے بعد کی ٹریننگ اور ماڈل ایوالویشن پر مبنی)۔ تینوں سب نیٹس ایک عمودی اینٹیگریشن تشکیل دیتے ہیں جو بڑے ماڈلز کی پری ٹریننگ سے لے کر ایلائنمنٹ اور بہتر بنانے تک کے مکمل پروسیس کو کور کرتا ہے، اور ڈی سینٹرلائزڈ بڑے ماڈل ٹریننگ کا مکمل ایکوسسٹم تشکیل دیتا ہے۔
خاص طور پر، مائنز کمپیوٹنگ وسائل فراہم کرتے ہیں اور گریڈینٹ اپڈیٹس (ماڈل پیرامیٹرز کی تبدیلی کی سمت اور شدت) نیٹ ورک پر اپ لوڈ کرتے ہیں؛ ویریفائرز ہر مائنر کے اہمیت کے معیار کا جائزہ لیتے ہیں اور خطاء میں بہتری کے لحاظ سے چین پر اسکور دیتے ہیں۔ نتائج انعام کے وزن کا تعین کرتے ہیں، جو خودکار طور پر تقسیم ہوتے ہیں اور کسی تیسرے طرف پر اعتماد کی ضرورت نہیں ہوتی۔
انسپائریشن ڈیزائن کا کلیدی پہلو یہ ہے کہ انعامات کو ب без صرف کمپیوٹیشنل ایویلیبلٹی بلکہ "آپ کے اشتراک نے ماڈل کو کتنا بہتر بنایا" سے جوڑا جائے۔ اس سے ڈی سینٹرلائزڈ منظر میں سب سے بڑی چیلنج — یعنی مائنرز کو آرام دینے سے کیسے روکا جائے — کا بنیادی طور پر حل نکال لیا جاتا ہے۔
تو Covenant-72B مواصلاتی کارکردگی اور انگیجمنٹ کے مطابقت کے مسائل کو کیسے حل کرتا ہے؟
اکھٹے کئی نوڈس جو ایک دوسرے پر بھروسہ نہیں کرتے، مختلف ہارڈویئر کے ساتھ، اور نیٹ ورک کوالٹی میں فرق ہے، ایک ہی ماڈل کو تربیت دینے کے لیے دو چیلنجز ہیں: ایک تو مواصلات کی کارکردگی، جس میں معیاری تقسیم شدہ تربیت کے منصوبوں کو نوڈس کے درمیان اعلیٰ بینڈ ویتھ اور کم لیٹنسی کی ضرورت ہوتی ہے؛ دوسرا، انگیجمنٹ کا مطابقت، برائے نام نوڈس کو غلط گریڈینٹس جمع کرنے سے کیسے روکا جائے؟ ہر شرکاء کو یقینی بنایا جائے کہ وہ اپنا کام سچائی سے کر رہے ہیں، نہ کہ دوسروں کے نتائج کا نقل کر رہے ہیں؟
SN3 اس دو مسائل کو دو مرکزی کمپوننٹس، SparseLoCo اور Gauntlet کے ذریعے حل کرتا ہے۔
SparseLoCo مواصلات کی کارکردگی کے مسائل کو حل کرتا ہے۔ روایتی تقسیم شدہ تربیت میں ہر مرحلے پر مکمل گریڈینٹس کو سینکرنائز کیا جاتا ہے، جس سے ڈیٹا کی مقدار بہت زیادہ ہوتی ہے۔ SparseLoCo کا طریقہ یہ ہے کہ ہر نوڈ اپنے مقامی طور پر 30 قدم (AdamW) کی داخلی بہتری کے بعد، "جھوٹے گریڈینٹس" کو دوسرے نوڈس کو اپ لوڈ کرنے سے پہلے دبایا جاتا ہے۔ دباؤ کے طریقے میں Top-k اسپارسیفکیشن (صرف سب سے اہم گریڈینٹ کمپوننٹس کو برقرار رکھنا)، ایرر فیڈ بیک (ڈال دیے گئے حصوں کو ذخیرہ کرنا اور اگلے دور میں جمع کرنا)، اور 2 بٹ کوانتائزیشن شامل ہیں۔ آخری دباؤ نسبت 146 گنا سے زیادہ ہے۔
دوسرا الفاظ میں، جس چیز کو اب تک 100 میگا بائٹس کی ضرورت تھی، اب اس کے لیے صرف 1 میگا بائٹ سے کم کافی ہے۔
یہ نظام کو عام انٹرنیٹ (اپ لینک 110 میگا بٹ فی سیکنڈ، ڈاؤن لینک 500 میگا بٹ فی سیکنڈ) کے بینڈ ویتھ پر محدود ہونے کے باوجود، کمپوٹیشن استعمال کو تقریباً 94.5% پر برقرار رکھتا ہے — 20 نوڈس، ہر نوڈ پر 8 B200 گرافکس کارڈز، اور ہر کمیونیکیشن راؤنڈ صرف 70 سیکنڈ کی مدت۔
گینٹل انشورنس کے مطابق مسائل کو حل کرتا ہے۔ یہ بٹٹینٹور بلاکچین (سبرنیٹ 3) پر چلتا ہے اور ہر نوڈ کے ذریعے جمع کرائے گئے جھوٹے گریڈینٹس کی معیار کی تصدیق کرتا ہے۔ اس کا طریقہ یہ ہے کہ ایک چھوٹی سی ڈیٹا بیچ کا استعمال کرتے ہوئے "اس نوڈ کے گریڈینٹس کو استعمال کرنے سے ماڈل کا نقصان کتنا کم ہوا" اس کا جائزہ لیا جاتا ہے، جس کا نتیجہ LossScore کہلاتا ہے۔ اسی طرح، سسٹم یہ بھی جانچتا ہے کہ کیا نوڈ اپنے مختص ڈیٹا پر تربیت دے رہا ہے — اگر کوئی نوڈ اپنے مختص ڈیٹا پر نقصان میں بہتری کے بجائے تصادفی ڈیٹا پر بہتری دکھائے تو اسے منفی نمبر دیا جائے گا۔
آخر کار، ہر تربیتی دور میں صرف سب سے زیادہ اسکور والے نوڈس کے گریڈیئنٹس کو ایکٹھا کرنے کے لیے استعمال کیا جاتا ہے، باقی نوڈس اس دور سے خارج ہو جاتے ہیں۔ زائد شرکاء کو وقتاً فوقتاً جگہ دی جاتی رہتی ہے تاکہ نظام مستحکم رہے۔ پورے تربیتی عمل کے دوران، اوسطاً ہر دور میں 16.9 نوڈس کے گریڈیئنٹس ایکٹھے کیے گئے، اور شامل ہونے والے منفرد نوڈس کی کل تعداد 70 سے زائد ہے۔
ڈیسینٹرلائزڈ AI کی قیمت کی کہانی میں بنیادی تبدیلی ہو رہی ہے
اس بات کو ٹیکنالوجی اور صنعت کے نقطہ نظر سے دیکھیں تو، کونونینٹ-72 بی کی طرف جانے والا راستہ کچھ حقیقی اہمیت رکھتا ہے۔
سب سے پہلا، "توزیع شدہ تربیت صرف چھوٹے ماڈلز کے لیے مناسب ہے" کا افتراض توڑ دیا گیا۔ حالانکہ ابھی بھی اگلی نسل کے ماڈلز سے کافی دور ہیں، لیکن اس راستے کی قابلیتِ توسیع کا ثبوت دیا گیا۔
دوم، بے اجازت شرکت ممکن اور عملی ہے۔ اس بات کو کم سمجھا جاتا ہے۔ پہلے کے تقسیم شدہ تربیتی منصوبوں میں وائٹ لسٹ کا استعمال ہوتا تھا — صرف تصدیق شدہ شرکاء ہی کمپیوٹنگ طاقت فراہم کر سکتے تھے۔ SN3 کی اس تربیت میں، کوئی بھی جس کے پاس کافی کمپیوٹنگ طاقت ہو، وہ جڑ سکتا ہے، اور تصدیق کا نظام برائے نام نہاد شرکاء کو فلٹر کرتا ہے۔ یہ “حقیقی غیر مرکزیت” کی طرف ایک عملی قدم ہے۔
تیسری بات، بٹٹنسور کا dTAO مکانزم ذیلی نیٹ ورکس کی قیمت کی مارکیٹ کی دریافت کو ممکن بناتا ہے۔ dTAO ہر ذیلی نیٹ ورک کو اپنا اپنا Alpha ٹوکن جاری کرنے کی اجازت دیتا ہے، جس سے AMM مکانزم کے ذریعے مارکیٹ فیصلہ کرتی ہے کہ کون سے ذیلی نیٹ ورکس کو زیادہ TAO اخراجات ملیں۔ اس سے SN3 جیسے ذیلی نیٹ ورکس کو جو واضح نتائج پیدا کرتے ہیں، ایک خشن لیکن موثر قیمت حاصل کرنے کا طریقہ فراہم ہوتا ہے۔ بالکل، یہ مکانزم نرخوں اور جذبات سے بھی آسانی سے متاثر ہوتا ہے، کیونکہ عام مارکیٹ شرکاء LLM ٹریننگ کے نتائج کی معیار کو الگ طور پر جانچ نہیں سکتے۔
چوتھا، ڈیسینٹرلائزڈ AI ٹریننگ کے سیاسی معاشی مفہوم۔ جیک کلارک نے Import AI میں اس مسئلے کو "AI کے مستقبل کا مالک کون ہے؟" کے سطح تک بلند کر دیا ہے۔ موجودہ ایلیٹ ماڈلز کی ٹریننگ صرف کچھ بڑے ڈیٹا سینٹر رکھنے والے اداروں کے ہاتھوں میں ہے، جو صرف ایک تجارتی مسئلہ نہیں بلکہ طاقت کی ساخت کا مسئلہ بھی ہے۔ اگر ڈسٹریبیوٹڈ ٹریننگ مسلسل ٹیکنالوجی کی ترقی حاصل کرتی رہی تو، کچھ ماڈلز کی قسم (جیسے خاص شعبوں کے لیے چھوٹے ایلیٹ ماڈلز) پر اصلی ڈیسینٹرلائزڈ ترقیاتی ایکوسسٹم تشکیل پا سکتا ہے۔ البته، یہ خوبصورت تصویر ابھی بہت دور ہے۔
خلاصہ: ایک حقیقی ایٹم، اور کئی حقیقی مسائل
ہو رینکون نے کہا کہ یہ "مڈرن ورژن آف فولڈنگ@ہوم" کی طرح ہے۔ فولڈنگ@ہوم نے مولیکیولر سیمولیشن کے شعبے میں اصلی کامیابی حاصل کی ہے، لیکن اس نے بڑی فارماسیوٹیکل کمپنیوں کے مرکزی ریسرچ اور ڈویلپمنٹ کے عہدے کو خطرے میں نہیں ڈالا۔ یہ تشبیہ بہت درست ہے۔
SN3 نے پروٹوکول کو کامیابی سے مکمل کر لیا اور تقسیم شدہ تربیت کے ممکنہ راستے کی تصدیق کر لی۔ لیکن ٹیکنالوجی اور صنعت کے نقطہ نظر سے، اس کی یہ کارکردگی کے پیچھے کئی ایسے مسائل ہیں جن کے بارے میں کم لوگ سنجیدہ طور پر بات کرنا چاہتے ہیں:
MMLU خود اکیڈیمک دنیا میں ایک تنازعاتی اشاریہ ہے، جس کے عوامی بنچ مارک کے سوالات اور جوابات ٹریننگ سیٹ میں لیک ہونے کا خطرہ ہے۔ زیادہ اہم بات یہ ہے کہ تقابلی بنیاد کا انتخاب: مقالہ جس LLaMA-2-70B اور LLM360 K2 کے ساتھ موازنہ کرتا ہے، وہ 2023 سے 2024 کے پرانے ماڈلز ہیں، جبکہ اسی دوران 65 سے 70 کے اسکور، جب Grok اور DouBao کے بارے میں پوچھا جاتا ہے، تو انہیں درمیانی سے نیچے اور شروعاتی سطح کے طور پر درج کیا جاتا ہے، جبکہ Claude کے لحاظ سے یہ شدید پیچھے رہنا ہے۔ اگر اسے مسلسل اپڈیٹ ہونے والی لسٹ یا نئی نسل کے آلودگی سے محفوظ ڈیزائن والے بنچ مارکس پر رکھا جائے، تو نتائج زیادہ ایماندار ہو سکتے ہیں۔
زیادہ اہم بات یہ ہے کہ ماڈل کی صلاحیتوں کی حد کا تعین کرنے والی معیاری ڈیٹا—مکالمے، کوڈ، ریاضی کی استدلال، اور سائنسی تحریریں—بڑی کمپنیوں، شائع کرنے والے اداروں اور اکیڈمک ڈیٹا بیسز کے پاس ہونے کا احتمال ہے۔ کمپوٹیشنل طاقت ڈیموکریٹائز ہو چکی ہے، لیکن ڈیٹا کا شعبہ اب بھی اولیگارک ہے، اور اس تضاد پر کبھی بحث نہیں ہوئی۔
سیکورٹی کے حوالے سے، اجازت کے بغیر شرکت کا مطلب ہے کہ آپ نہیں جانتے کہ وہ 70 سے زیادہ نوڈس کس کے پیچھے ہیں اور وہ کس ڈیٹا کے ساتھ تربیت دے رہے ہیں۔ گونٹل نمایاں طور پر غیر معمولی گریڈینٹس کو فلٹر کر سکتا ہے، لیکن نرم ڈیٹا پوئسنگ سے نہیں بچا سکتا—اگر کوئی نوڈ کسی خاص قسم کے نقصان دہ مواد کی طرف متعدد دفعات زیادہ تربیت دے رہا ہو، تو اس سے پیدا ہونے والے گریڈینٹس میں تبدیلیاں اتنی ظریف ہوتی ہیں کہ وہ نقصان اسکور کی جانچ سے گزر جاتی ہیں، لیکن ماڈل کے رویے پر جمعی تبدیلیاں پیدا کرتی ہیں۔ آخری سوال یہ ہے کہ فنانشل، میڈیکل، لیگل جیسے اعلیٰ کمپلائنس اور سیکورٹی کی ضرورت والے مناظر میں، ایک ایسا ماڈل استعمال کرنا جس کی تربیت کچھ نامعلوم نوڈس نے کی ہو اور اس کا ڈیٹا سورس مکمل طور پر ٹریس نہ ہو، کس قسم کے خطرات کا باعث بنتا ہے؟
ایک اور ساختی مسئلہ جس کا صاف طور پر ذکر کیا جانا چاہیے: Covenant-72B خود Apache 2.0 لائسنس کے تحت اوپن سورس ہے اور SN3 ٹوکن کا استعمال نہیں کرتا۔ SN3 ٹوکن رکھنا، ماڈل کے استعمال سے کوئی ب без دیکھنے والا فائدہ نہیں، بلکہ اس سب نیٹ ورک کے مستقبل میں نئے ماڈلز کے مستقل پیداوار سے حاصل ہونے والی امیشن آمدنی کا شیرہ ہے۔ یہ قیمتی سلسلہ، مستقل تربیت کے پیداوار اور Bittensor کے مجموعی نیٹ ورک امیشن مکینزم کے صحت مند عمل پر منحصر ہے۔ اگر مستقبل میں تربیت روک دی جائے، یا نئے تربیتی نتائج کی معیاری درجہ بندی متوقع سطح تک نہ پہنچے، تو ٹوکن کی قیمت کا منطق کمزور ہو جائے گا۔
ان سوالات کو درج کیا جا رہا ہے تاکہ Covenant-72B کی اہمیت کو انکار نہ کیا جائے۔ اس نے ایک ایسا حقیقت ثابت کی ہے جسے پہلے ناممکن سمجھا جاتا تھا، اور یہ حقیقت کبھی نہیں گھل سکتی۔ لیکن کچھ کرنا اور اس کا کیا مطلب ہے، دو الگ باتیں ہیں۔
SN3 ٹوکن نے پچھلے ایک ماہ میں 440% کا اضافہ کیا ہے۔ اس کے درمیان کا فرق شاید صرف ایک ہائپ نہیں، بلکہ کہانی کی رفتار ہمیشہ حقیقت سے زیادہ تیز ہوتی ہے۔ اس فرق کے آخر میں حقیقت کے ذریعے بھر دیا جائے گا یا مارکیٹ کے ذریعے درست کر دیا جائے گا، یہ Covenant AI ٹیم کے اگلے اقدامات پر منحصر ہے۔
یہ قابل توجہ ہے کہ گرے اسکیل نے جنوری 2026 میں TAO ETF کا درخواست جمع کرایا ہے، جو ادارتی سرمایہ کاروں کے اس شعبے میں داخلے کا اشارہ ہے۔ علاوہ ازیں، دسمبر 2025 میں بٹنٹینر نے روزانہ TAO کی پیداوار کو آدھا کر دیا ہے، جس سے فراہمی کی جانب سے ساختی تنگی مزید بڑھ رہی ہے۔
حوالہ لنک:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95