










یہ خیال بے بنیاد نہیں ہے۔ اس نے کئی عوامی بنچ مارکس دیکھے اور پایا کہ AI، AI تحقیق سے متعلق کاموں میں بہت تیزی سے ترقی کر رہا ہے۔
مثلاً، CORE-Bench AI کی صلاحیت کا جائزہ لیتا ہے کہ وہ دوسرے تحقیقی مقالوں کو کیسے 实现 کرتی ہے، جو AI تحقیق میں انتہائی اہم پہلو ہے۔
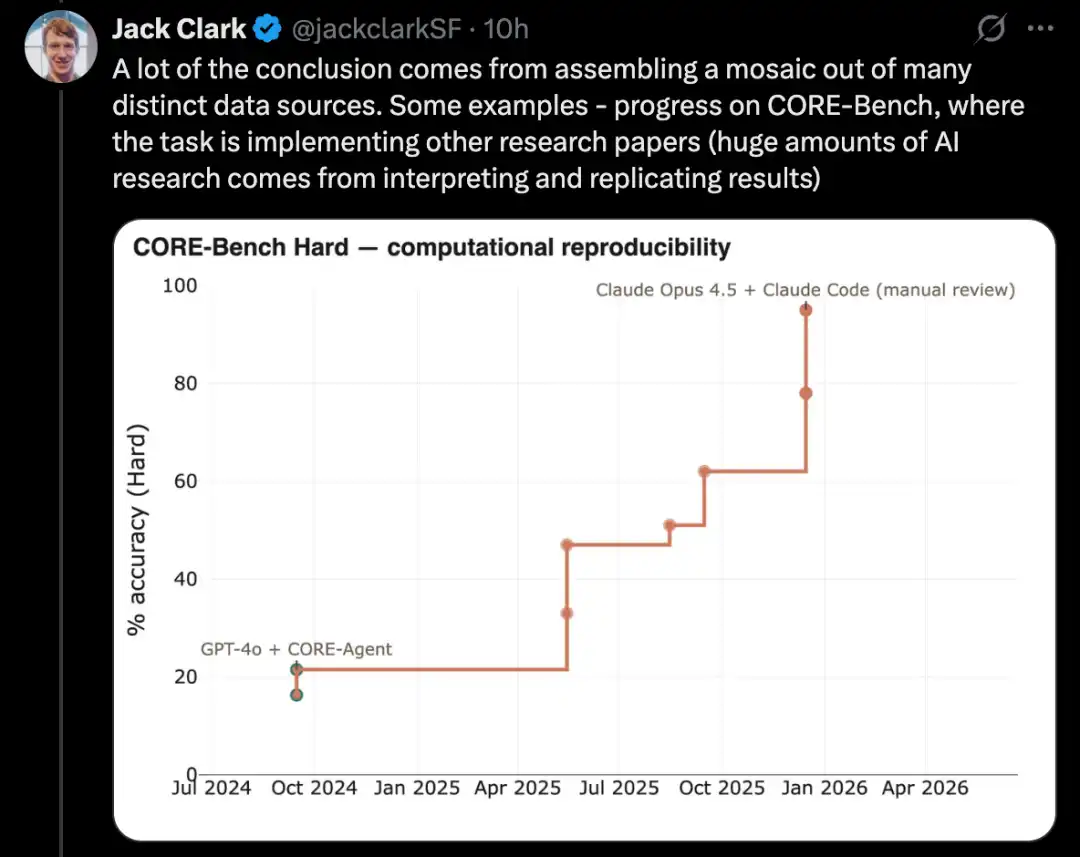
PostTrainBench یہ ٹیسٹ کرتا ہے کہ کیا طاقتور ماڈل کمزور آبھر ماڈل کو خود بخود فائن ٹیون کر کے ان کی کارکردگی بہتر بناسکتا ہے، جو AI ریسرچ اور ڈویلپمنٹ کے ایک اہم ذیلی سیٹ ہے۔
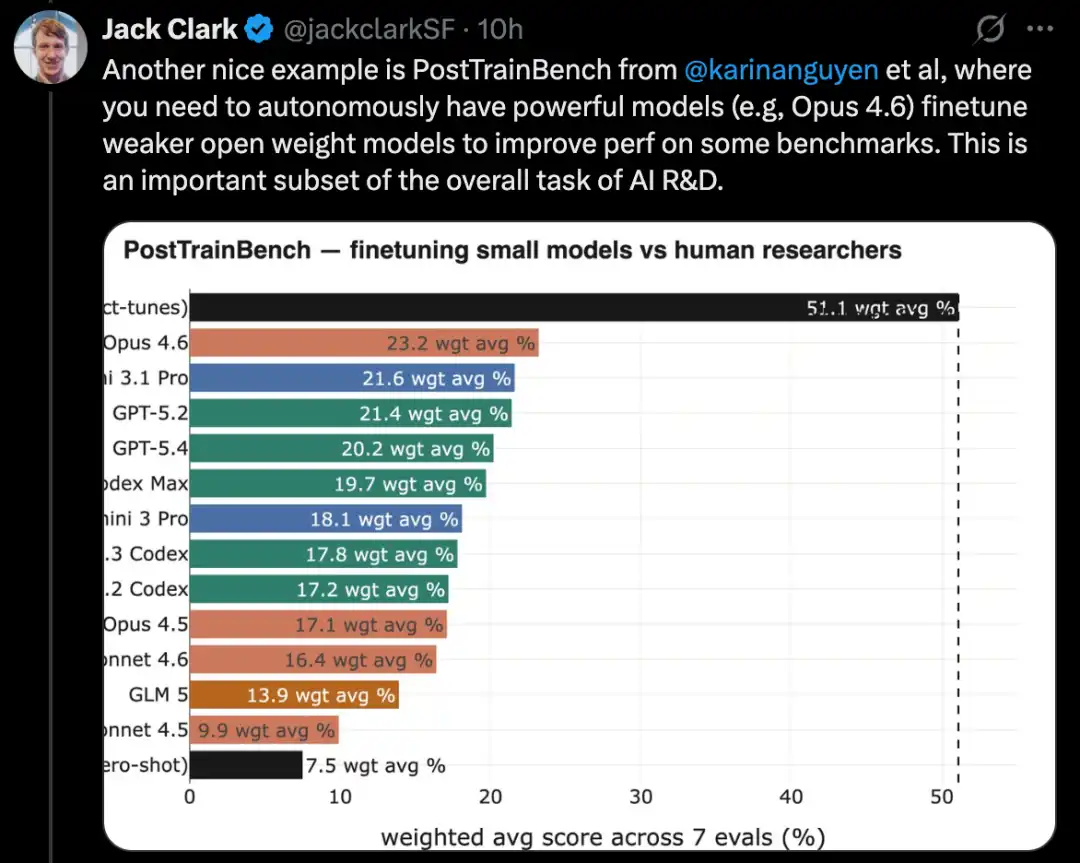
MLE-Bench حقیقی Kaggle مقابلہ کے اعمال پر مبنی ہے، جس میں خاص مسائل کو حل کرنے کے لیے متنوع ماشینی سیکھنے کے ایپلیکیشنز تعمیر کرنے کی ضرورت ہوتی ہے۔ اس کے علاوہ، SWE-Bench جیسے مشہور کوڈنگ بینچ مارکس بھی اسی قسم کی ترقی کو ظاہر کرتے ہیں۔
جیک کلارک نے اس ظاہر کو "فریکٹل" کے طور پر بیان کیا ہے، جس میں مختلف ریزولوشن اور سcales پر مفید ترقی کا مشاہدہ کیا جا سکتا ہے۔ وہ سمجھتے ہیں کہ AI ابھی تک اندرونی خودکار ترقی کی صلاحیت کے قریب پہنچ رہا ہے، اور جب یہ حاصل ہو جائے گا، تو AI اپنے اپنے بعد کے نظاموں کو خود بنانے لگے گا، جس سے خود تکرار کا دائرہ شروع ہو جائے گا۔

اس بیان کے ساتھ سوشل میڈیا پر کافی بحث ہوئی۔
کچھ لوگ اسے ایس آئی اور نقطہِ تکامل کی طرف ایک اہم پہلی قدم کے طور پر دیکھتے ہیں، جو ٹیکنالوجی کے ترقی کے رفتار کو بالکل بدل سکتا ہے۔

تاہم، مختلف آوازیں بھی ہیں۔
واشنگٹن یونیورسٹی کے کمپیوٹر سائنس پروفیسر پیڈرو ڈومنگوس نے اشارہ کیا کہ AI سسٹمز نے 1950 کی دہائی میں LISP زبان کے ایجاد ہونے کے وقت ہی "خود کو تعمیر کرنے" کی صلاحیت رکھی تھی، اصل مسئلہ یہ ہے کہ کیا اضافی ریٹرن حاصل کیا جا سکتا ہے، اور اب تک اس کے لیے کوئی واضح ثبوت نہیں ملا ہے۔

کچھ صارفین نے سوال کیا ہے کہ 2027 سے 2028 تک احتمال میں اچانک 30 فیصد کا اضافہ کیسے ہوا، جس سے یہ ظاہر ہوتا ہے کہ AI کی صلاحیتیں 2027 کے آخر کے قریب ایک اچانک بڑی کامیابی حاصل کریں گی۔ کون سا خاص ایمیل اسٹون یا واقعہ AI کی تکراری خود بہتری کے احتمال کو مختصر عرصے میں کافی حد تک بڑھائے گا؟

ایک اور صارف نے کہا کہ جیک کلارک اینتھرپک کے نئے پبلک ریلیشنز ہیڈ ہیں، جو ان کی نئی حکمت عملی کا حصہ ہیں: ہم خوف پھیلانے والے نہیں ہیں، ہماری طرف سے آپ کو ہمیشہ جو انتباہ دیا جا رہا تھا، اس کی تصدیق بہت سارے پیپرز نے کی ہے۔
جیک کلارک نے صرف اس نیوز لیٹر، امپورٹ اے آئی 455 میں ایک لمبا مضمون لکھا ہے جس میں تفصیل سے بیان کیا گیا ہے۔
اگلے، ہم اس مضمون کو مکمل طور پر دیکھتے ہیں۔
AI سسٹم اپنی خود کو تعمیر کرنا شروع کرنے جا رہا ہے، اس کا کیا مطلب ہے؟
کلارک نے کہا کہ اس نے یہ مضمون لکھا ہے کیونکہ تمام عام طور پر دستیاب معلومات کو جانچنے کے بعد، اسے ایک ایسا فیصلہ کرنا پڑا جو آسان نہیں تھا: 2028 کے آخر تک، بنا کسی انسانی شرکت کے AI تحقیق کے ظہور کا احتمال کافی زیادہ ہے، شاید 60 فیصد سے زیادہ۔
یہاں "انسانی مداخلت کے بغیر AI ترقی" کا مطلب ایک کافی طاقتور AI سسٹم ہے جو نہ صرف انسانوں کو تحقیق میں مدد کر سکتا ہے بلکہ اہم ترقیاتی عملوں کو خود سے مکمل بھی کر سکتا ہے، اور اپنا اگلا سسٹم بھی تعمیر کر سکتا ہے۔
کلارک کے لیے، یہ واضح طور پر ایک بڑی بات ہے۔
اس نے اعتراف کیا کہ اس کے لیے بھی اس بات کے مفہوم کو مکمل طور پر سمجھنا مشکل ہے۔
اسے ایک ناپسندیدہ فیصلہ کہنا اس لیے ہے کہ اس کے پیچھے کے اثرات بہت بڑے ہیں، جس کی وجہ سے اسے سمجھنا مشکل ہو رہا ہے۔ کلارک بھی یقین نہیں کہ پوری سماج AI ریسرچ کی خودکاری کے ساتھ آنے والے گہرے تبدیلیوں کے لیے تیار ہو چکی ہے۔
وہ اب یہ سمجھتا ہے کہ انسان شاید ایک خاص لمحے پر زندہ ہیں: AI تحقیق جلد ہی مکمل طور پر خودکار ہو جائے گی۔ اگر یہ لمحہ واقعی آ جائے، تو انسان لیوکوس ندی پار کر چکے ہوں گے اور ایک تقریباً غیر قابل پیشگوئی مستقبل میں داخل ہو جائیں گے۔
کلارک نے کہا کہ اس مضمون کا مقصد یہ واضح کرنا ہے کہ وہ کیوں سمجھتا ہے کہ مکمل طور پر خودکار AI ریسرچ کی طرف اُڑان بھرنے کا راستہ شروع ہو رہا ہے۔
وہ اس رجحان کے ممکنہ نتائج پر بحث کرے گا، لیکن مضمون کا زیادہ تر حصہ اس فیصلے کی بنیاد بنانے والے شواہد پر مرکوز ہوگا۔ مزید گہرے اثرات کے لیے، کلارک اس سال کے زیادہ تر حصے تک اس کی تفصیل سے گزارش کرے گا۔
وقت کے نقطہ نظر سے، کلارک کو نہیں لگتا کہ یہ واقعہ 2026 میں حقیقت میں پیش آئے گا۔ لیکن وہ سمجھتے ہیں کہ اگلے دو سالوں میں، ہم کسی ماڈل کو اپنے خود کے جانشین کو ٹرین کرتے ہوئے دیکھ سکتے ہیں۔ کم از کم غیر اعلیٰ ماڈلز کے لحاظ سے، ایک مفہومی ثبوت کا ظہور ممکن ہے؛ جبکہ اعلیٰ ترین ماڈلز کے لیے، چیلنج زیادہ مشکل ہوگا، کیونکہ ان کی لاگت بہت زیادہ ہوتی ہے اور ان پر انسانی ریسرچرز کی شدید مزدوری کا بھرپور انحصار ہوتا ہے۔
کلارک کا جائزہ بنیادی طور پر عوامی معلومات پر مبنی ہے: جن میں arXiv، bioRxiv اور NBER پر شائع ہونے والے مقالات، اور سامنے والی AI کمپنیوں کے واقعی دنیا میں ڈپلوی کیے گئے پروڈکٹس شامل ہیں۔ ان معلومات کے بنیاد پر، وہ ایک نتیجہ پر پہنچتا ہے کہ AI سسٹمز کے لیے ضروری تمام اجزاء، خاص طور پر AI ترقی کے انجینئرنگ اجزاء، کا آٹومیٹڈ پروڈکشن تقریباً موجود ہے۔
اگر اسکیلنگ کا رجحان جاری رہا، تو ہمیں ایسی صورتحال کے لیے تیار ہونا شروع کر دینا چاہیے: مدلز کافی تخلیقی بن جائیں گے، نہ صرف معلوم طریقوں کو خودکار طور پر بہتر بنانے کے لیے بلکہ نئے تحقیقی رخوں اور اصل خیالات پیش کرنے میں انسانی تحقیق کاروں کی جگہ لے سکتے ہیں، جس سے وہ خود AI کی سرحد کو آگے بڑھائیں گے۔
Code Singularity: Change in Ability Over Time
AI سسٹم سافٹ ویئر کے ذریعے حاصل کیے جاتے ہیں، جو کوڈ سے بنے ہوتے ہیں۔
AI سسٹمز نے کوڈ پیدا کرنے کے طریقے کو بالکل بدل دیا ہے۔ اس کے پیچھے دو متعلقہ رجحانات ہیں: ایک طرف، AI سسٹمز پیچیدہ حقیقی دنیا کے کوڈ لکھنے میں لگاتار بہتر ہو رہے ہیں؛ دوسری طرف، AI سسٹمز اب انسانی نگرانی کے تقریباً مکمل طور پر بغیر، کوڈ لکھنے سے لے کر ٹیسٹ کرنے تک جیسے بہت سے لکیری کوڈنگ کاموں کو جوڑنے میں بھی بہتر ہو رہے ہیں۔
اس رجحان کے دو مثالیں SWE-Bench اور METR time horizons plot ہیں۔
حقیقی دنیا کے سافٹ ویئر انجینئرنگ کے مسائل کو حل کریں
SWE-Bench ایک وسیع طور پر استعمال ہونے والا پروگرامنگ ٹیسٹ ہے جو AI سسٹم کو حقیقی GitHub ایشو حل کرنے کی صلاحیت کا جائزہ لینے کے لیے استعمال ہوتا ہے۔
جب SWE-Bench 2023 کے آخر میں متعارف کرایا گیا، تو اس وقت سب سے بہترین ماڈل Claude 2 تھا، جس کی کل کامیابی کی شرح صرف 2% تھی۔ جبکہ Claude Mythos Preview کی کارکردگی 93.9% تک پہنچ چکی ہے، جو اس بینچ مارک کو تقریباً مکمل طور پر حاصل کرنے کے قریب ہے۔
بے شک، تمام بینچ مارکس میں خود کچھ نویز ہوتا ہے، اس لیے عام طور پر ایک ایسا مرحلہ آتا ہے جب اسکور کسی حد تک پہنچ جائے تو آپ کو ممکنہ طور پر طریقہ کار کی حدود نہیں بلکہ بینچ مارک کی حدود کا سامنا ہوتا ہے۔ مثال کے طور پر، ImageNet تصدیق سیٹ میں، تقریباً 6% لیبل غلط یا ادھر ادھر ہوتے ہیں۔
SWE-Bench کو عام پروگرامنگ صلاحیت اور AI کے سافٹ ویئر انجینئرنگ پر اثر کا ایک قابل اعتماد اشارہ کہا جا سکتا ہے۔ کلارک کا کہنا ہے کہ وہ جن افراد سے انہوں نے سامنا کیا ہے، وہ سب فرانت لائن AI لیبارٹریز اور سلیکون ویلی میں موجود ہیں، جو اب تقریباً مکمل طور پر AI سسٹمز کے ذریعے کوڈ لکھ رہے ہیں، اور زیادہ سے زیادہ لوگ AI سسٹمز کا استعمال ٹیسٹ لکھنے اور کوڈ چیک کرنے کے لیے شروع کر رہے ہیں۔
دوسرے الفاظ میں، AI سسٹم اتنے طاقتور ہو چکے ہیں کہ وہ AI تحقیق کے ایک اہم پہلو کو خودکار بناسکتے ہیں اور AI تحقیق میں ملوث تمام انسانی محققین اور انجینئرز کی ترقی کو نمایاں طور پر تیز کر سکتے ہیں۔
AI سسٹم کی لمبے وقت کے کاموں کو پورا کرنے کی صلاحیت کا جائزہ لیں
METR نے ایک گراف تیار کیا ہے جو AI کو کتنے پیچیدہ کاموں کو انجام دینے کی صلاحیت ہے، اس کا اندازہ ایک ماہر انسان کو ان کاموں کو مکمل کرنے میں لگنے والے گھنٹوں کے حساب سے لگایا گیا ہے۔
سب سے اہم اشارہ یہ ہے کہ جب AI سسٹم ایک مجموعہ کاموں پر 50% قابلیت حاصل کرتا ہے، تو اس کے مطابق تقریباً کاموں کا دورہ ہوتا ہے۔
اس نقطے پر، پیش رفت بہت حیرت انگیز ہے:
2022 میں، GPT-3.5 جو کام کر سکتا تھا، وہ انسان کو تقریباً 30 سیکنڈ میں مکمل کرنا پڑتا تھا۔
· 2023 میں، GPT-4 نے اس وقت کو 4 منٹ تک بڑھا دیا۔
· 2024 میں، o1 نے اس وقت کو 40 منٹ تک بڑھا دیا۔
· 2025 میں، GPT-5.2 High تقریباً 6 گھنٹے تک رہا۔
2026 تک، Opus 4.6 نے اس وقت کو مزید بڑھا کر تقریباً 12 گھنٹے کر دیا ہے۔
METR میں کام کرنے والی اور AI پیشگوئی پر لمبے عرصے سے نظر رکھنے والی اجیا کوٹرا کا خیال ہے کہ 2026 کے آخر تک AI سسٹم کسی ایسے کام کو مکمل کر سکتے ہیں جسے انسان کو 100 گھنٹے لگیں، یہ کوئی غیر منطقی توقع نہیں ہے۔
AI سسٹم کی وہ صلاحیت جو انہیں خود کار طور پر کام کرنے کی اجازت دیتی ہے، محسوس کرنے لگی ہے، اور ایجنٹک کوڈنگ ٹولز کے بڑھتے ہوئے استعمال سے بھی متعلق ہے۔ ایجنٹک کوڈنگ ٹولز کا بنیادی مطلب یہ ہے کہ وہ AI سسٹم جو انسانوں کے لیے کام کرنے کی صلاحیت رکھتے ہیں، انہیں مصنوعات کے طور پر پیش کیا جاتا ہے: یہ انسانوں کی طرف سے کام کرتے ہیں اور کافی لمبے عرصے تک نسبتاً خود مختار طور پر کام ترقی دیتے ہیں۔
یہ بھی AI تحقیق کے خود کو دوبارہ مبذول کراتا ہے۔ بہت سے AI محققین کے روزمرہ کے کام کا تفصیلی جائزہ لینے سے پتہ چلتا ہے کہ ان میں سے بہت سے کاموں کو چند گھنٹوں کے کاموں میں تقسیم کیا جا سکتا ہے، جیسے ڈیٹا صاف کرنا، ڈیٹا پڑھنا، تجربات شروع کرنا وغیرہ۔
اور اس قسم کے کام، جو اب مدرن AI سسٹم کے دائرہ کار میں آ چکے ہیں۔
جتنی زیادہ AI سسٹم مہارت حاصل کرتا ہے، اتنی ہی زیادہ انسانوں کے بغیر کام کرنے لگتا ہے، اور اتنی ہی زیادہ AI تحقیق و ترقی کے کچھ حصوں کو آٹومیٹ کرنے میں مدد کرتا ہے۔
ٹاسک ڈیلیگیشن کے اہم عوامل دو ہیں:
· ایک بات یہ ہے کہ آپ کو اپنے مفوض شخص کی صلاحیت پر اعتماد ہے؛
· دوسری بات یہ ہے کہ آپ کو یقین ہے کہ دوسری طرف آپ کی نگرانی کے بغیر آپ کے ارادے کے مطابق کام خود سے مکمل کر سکتی ہے۔
جب صارفین AI کی پروگرامنگ کی صلاحیتوں کا مشاہدہ کرتے ہیں، تو وہ پائتے ہیں کہ AI سسٹم نہ صرف زیادہ مہارت حاصل کر رہے ہیں بلکہ انسانی دوبارہ کیلبریٹ کی ضرورت کے بغیر لمبے عرصے تک خود کار طور پر کام کرنے لگے ہیں۔
یہ اس بات سے مطابقت رکھتا ہے کہ ہمارے اردگرد ایک بڑا تبدیلی ہو رہی ہے، جہاں انجینئرز اور محققین AI سسٹمز کو لگاتار بڑھتی ہوئی کام کی مقدار سونپ رہے ہیں۔ جیسے جیسے AI کی صلاحیتیں بڑھتی جا رہی ہیں، AI کو سونپے جانے والے کام بھی زیادہ پیچیدہ اور زیادہ اہم ہوتے جا رہے ہیں۔
ای آئی ای آئی کے ترقی کے لیے ضروری بنیادی سائنسی مہارتوں کو سیکھ رہی ہے
جدید سائنسی تحقیق کیسے چلتی ہے، اس کا بڑا حصہ اس بات کا تعین کرنا ہے کہ آپ کس قسم کی تجرباتی معلومات حاصل کرنا چاہتے ہیں؛ پھر تجربہ ڈیزائن کرنا اور اسے چلانا تاکہ یہ معلومات حاصل ہو سکیں؛ اور آخر میں تجرباتی نتائج کی منطقی صحت کا جائزہ لینا۔
AI پروگرامنگ کی صلاحیتوں میں لگاتار اضافے اور بڑے زبانی ماڈلز کی طاقتور دنیا کی ماڈلنگ صلاحیتوں کے ساتھ، اب ایسے ٹولز موجود ہیں جو انسانی سائنسدانوں کو تیزی لانے اور زیادہ وسیع ریسرچ اور ڈویلپمنٹ سیناریوز میں کچھ مراحل کو جزوی طور پر خودکار بنانے میں مدد کرتے ہیں۔
یہاں، ہم AI کی کچھ اہم سائنسی مہارتوں پر اس کی ترقی کی رفتار کا مشاہدہ کر سکتے ہیں، جبکہ یہ مہارتیں خود AI تحقیق کا اہم حصہ ہیں:
· ایک تو تحقیقی نتائج کو دوبارہ بنانا؛
· دوسری بات یہ ہے کہ ماشین لرننگ ٹیکنالوجی کو دیگر طریقوں کے ساتھ جوڑ کر ٹیکنیکل مسائل کا حل نکالا جائے؛
· تیسرا، AI سسٹم کو خود بہتر بنانا۔
پوری سائنسی تحریر کو مکمل کریں اور متعلقہ تجربات کریں
AI تحقیق کا ایک مرکزی کام، سائنسی مقالوں کو پڑھنا اور ان کے نتائج کو دوبارہ حاصل کرنا ہے۔ اس حوالے سے، AI نے کئی بینچ مارکس پر نمایاں ترقی حاصل کی ہے۔
ایک اچھا مثال CORE-Bench ہے، جو کمپوٹیشنل ریپروڈیوسیبلٹی ایجینٹ بینچ مارک ہے۔
یہ بینچ مارک AI سسٹم کو ایک پیپر اور اس کے کوڈ ریپوزٹری دیے جانے پر پیپر کے نتائج کو دوبارہ حاصل کرنے کا مطالبہ کرتا ہے۔ خاص طور پر، ایجینٹ کو متعلقہ لائبریریز، پیکیجز اور انحصار نصب کرنے ہوں گے، کوڈ چلانا ہوگا؛ اگر کوڈ کامیابی سے چل جائے، تو اسے تمام آؤٹ پٹ نتائج تلاش کرنے ہوں گے اور اس سوال کا جواب دینا ہوگا۔
CORE-Bench کو 2024ء کے ستمبر میں پیش کیا گیا۔ اس وقت کا سب سے بہترین نظام، CORE-Agent scaffold پر چلنے والا GPT-4o ماڈل تھا۔ اس بینچ مارک کے سب سے مشکل مجموعے پر، اس کا اسکور تقریباً 21.5% تھا۔
اور 2025 کے دسمبر تک، CORE-Bench کے ایک مصنف نے اعلان کیا کہ اس بینچ مارک کو حل کر لیا گیا ہے: Opus 4.5 ماڈل نے 95.5% کا اسکور حاصل کیا۔
کگل کے مسابقات کے مسائل کو حل کرنے کے لیے مکمل ماشین لرننگ سسٹم تعمیر کریں
MLE-Bench ایک بینچ مارک ہے جسے OpenAI نے AI سسٹمز کی کیگل کے مقابلوں میں آف لائن ماحول میں شرکت کی صلاحیت کا جائزہ لینے کے لیے تعمیر کیا ہے۔
یہ 75 مختلف قسم کے کیگل مقابلے کو کور کرتا ہے، جن میں قدرتی زبان کی پردازش، کمپیوٹر ویژن اور سگنل پروسیسنگ سمیت کئی شعبے شamil ہیں۔
MLE-Bench کو اکتوبر 2024 میں جاری کیا گیا۔ جاری کے وقت، سب سے بہترین کارکردگی والی سسٹم ایک agent scaffold میں چلنے والی o1 ماڈل تھی، جس نے 16.9% کا اسکور حاصل کیا۔
2026ء کے فروری تک، سب سے بہترین سسٹم، جس میں تلاش کی صلاحیت والے ایجنٹ ہارنس پر جیمینی 3 چل رہا ہے، 64.4% کا اسکور حاصل کر چکا ہے۔
کرنل ڈیزائن
AI ترقی کا ایک اور مشکل کام کرنل آپٹیمائزیشن ہے۔ کرنل آپٹیمائزیشن کا مطلب ہے کہ بنیادی کوڈ لکھنا اور بہتر بنانا، تاکہ میٹرکس ضرب جیسے خاص آپریشنز کو بنیادی ہارڈویئر پر زیادہ موثر طریقے سے مپ کیا جا سکے۔
کرنل کی بہترین تعمیر AI ڈیولپمنٹ کا مرکزی پہلو اس لیے ہے کہ یہ تربیت اور استنتاج کی کارکردگی کا تعین کرتی ہے: ایک طرف، یہ آپ کو AI سسٹم تیار کرتے وقت کتنی کمپوٹیشنل طاقت کا مؤثر طریقے سے استعمال کرنے کی اجازت دیتی ہے؛ دوسری طرف، جب ماڈل کی تربیت مکمل ہو جائے تو یہ یہ تعین کرتی ہے کہ آپ کمپوٹیشنل طاقت کو استنتاج کی صلاحیت میں کتنی مؤثر طریقے سے تبدیل کر سکتے ہیں۔
پچھلے کچھ سالوں میں، AI کا استعمال کرکے کرنل ڈیزائن کرنا، ایک د цلچھی چھوٹی سی سمت سے بدل کر ایک مقابلہ پر مبنی تحقیقی شعبہ بن گیا ہے، اور کئی بینچ مارکس بھی ظاہر ہوئے ہیں۔ تاہم، اب تک ان بینچ مارکس کا خاص طور پر زیادہ استعمال نہیں ہوا، اس لیے ہم اس شعبے کی لمبے مدتی ترقی کو دوسرے شعبوں کی طرح واضح طور پر ماڈل نہیں کر سکتے۔ دوسری طرف، ہم کچھ جاری تحقیق کے ذریعے اس سمت کی ترقی کی رفتار محسوس کر سکتے ہیں۔
متعلقہ کاموں میں شامل ہیں:
ڈیپسیک کے ماڈل کا استعمال کرتے ہوئے بہتر GPU کرنل بنانے کی کوشش کریں؛
پائٹورچ ماڈیولز کو آٹومیٹک طور پر کیوڈا کوڈ میں تبدیل کریں؛
میٹا LLM کا استعمال کرتے ہوئے آپٹیمائزڈ ٹریٹن کرنلز کو خودکار طور پر پیدا کرتا ہے اور انہیں اپنی بنیادی ڈھانچے میں ڈپلوی کرتا ہے؛
اور GPU کرنل کے ڈیزائن کے لیے اوپن سورس وزن ماڈلز، جیسے Cuda Agent، کو فائن ٹیون کرنا۔
یہاں ایک اور نکتہ شامل کیا جانا چاہئے: کرنل ڈیزائن میں کچھ ایسے خصوصیات ہیں جو AI ڈرائیون ریسرچ کے لیے بہت مناسب ہیں، جیسے کہ نتائج کی تصدیق آسان ہونا اور انعام کے سگنلز واضح ہونا۔
PostTrainBench کے ذریعے زبانی ماڈل کو فائن ٹیون کریں
اس قسم کے ٹیسٹ کا ایک مشکل تر ورژن PostTrainBench ہے۔ یہ ٹیسٹ کرتا ہے کہ مختلف اگرے والے ماڈل چھوٹے اوپن سورس وزن ماڈلز کو اپنا لے سکتے ہیں اور انہیں کچھ بینچ مارکس پر فائن ٹیوننگ کے ذریعہ بہتر بناسکتے ہیں۔
اس بینچ مارک کا ایک فائدہ یہ ہے کہ اس کے پاس ایک بہت مضبوط انسانی بنیاد ہے: ان چھوٹے ماڈلز کے موجودہ instruct-tuned ورژن۔ یہ ورژن عام طور پر سرحدی لیبز میں بہترین انسانی AI ریسرچرز کے ذریعہ تیار کیے گئے ہیں، جنہیں بہت صلاحیت مند ریسرچرز اور انجینئرز نے بہتر بنایا ہے اور انہیں حقیقی دنیا میں لاگو کیا گیا ہے۔ اس لیے، وہ ایک ایسا مشکل انسانی بینچ مارک بناتے ہیں جسے پار کرنا مشکل ہے۔
2026ء کے مارچ تک، AI سسٹمز نے ماڈلز کے لیے پوسٹ ٹریننگ کرنا شروع کر دیا ہے اور تقریباً انسانی ٹریننگ کے نتائج کا نصف فائدہ حاصل کیا ہے۔
تجزیہ کا مخصوص اسکور ایک وزنی اوسط سے حاصل ہوتا ہے: یہ Qwen 3 1.7B، Qwen 3 4B، SmolLM3-3B، Gemma 3 4B سمیت کئی پسِ تربیت والے بڑے زبانی ماڈلز، اور AIME 2025، Arena Hard، BFCL، GPQA Main، GSM8K، HealthBench، HumanEval جیسے کئی بینچ مارکس کو مجموعی طور پر شامل کرتا ہے۔
ہر رن کے دوران، جائزہ دینے والے ایک CLI ایجینٹ کا مطالبہ کریں گے تاکہ کسی خاص بینچ مارک پر کسی خاص بنیادی ماڈل کی کارکردگی کو بہتر بنایا جا سکے۔
2026ء کے اپریل تک، سب سے زیادہ اسکور کرنے والے AI سسٹمز تقریباً 25% سے 28% تک پہنچ سکتے ہیں، جن میں ماڈلز Opus 4.6 اور GPT 5.4 شامل ہیں؛ جبکہ انسانی اسکور 51% ہے۔
یہ اب تک کافی مفید نتیجہ ہے۔
زبانی ماڈل کی تربیت کو بہتر بنائیں
گزشتہ سال، اینتھروپک نے اپنے سسٹم کی کارکردگی کی رپورٹ کی ہے جو ایک LLM ٹریننگ ٹاسک پر ہے۔ اس ٹاسک میں ماڈل کو ایک چھوٹے زبانی ماڈل کی ٹریننگ کو صرف CPU کا استعمال کرتے ہوئے اتنی جلدی چلانے کے لیے بہتر بنانا ہے۔
اندازہ یہ ہے کہ ماڈل کی حاصل کردہ اوسط تیزی کا تناسب اصل کوڈ کے مقابلے میں۔
اس نتیجے میں بہت بڑی پیشرفت ہوئی ہے:
· مئی 2025 میں، کلود آپس 4 نے اوسطاً 2.9 گنا تیزی حاصل کی؛
· نومبر 2025 میں، Opus 4.5 کو 16.5 گنا کر دیا گیا؛
· فروری 2026 میں، Opus 4.6 30 گناہ پہنچ گیا؛
اپریل 2026 میں، کلاؤڈ مائتھوس پریویو نے 52 گنا بڑھ کر 52 گنا کیا۔
ان اعداد کے مطلب کو سمجھنے کے لیے، ایک حوالہ دیا جا سکتا ہے: انسانی محققین پر اس کام کو مکمل کرنے میں عام طور پر 4 سے 8 گھنٹے لگتے ہیں، جس سے 4 گنا تیزی حاصل ہوتی ہے۔
مہارت: انتظام
ای آئی سسٹم دوسرے ای آئی سسٹمز کو منظم کرنے کا طریقہ بھی سیکھ رہے ہیں۔
یہ بات پہلے ہی کچھ وسیع طور پر استعمال ہونے والے پروڈکٹس، جیسے کہ Claude Code یا OpenCode میں دیکھی جا رہی ہے، جہاں ایک مین ایجنٹ کئی سب ایجنٹس کی نگرانی کرتا ہے۔
یہ AI سسٹم کو بڑے پیمانے پر منصوبوں کو سنبھالنے کی اجازت دیتا ہے: منصوبوں میں مختلف ماہرین والے کئی ایجنٹس متوازی طور پر کام کر سکتے ہیں، جن کی ہدایت عام طور پر ایک واحد AI مینیجر کرتا ہے۔ یہ مینیجر بھی ایک AI سسٹم ہے۔
AI تحقیق عام نسبیت کی دریافت کی طرح ہے یا لیگو کا ایک ساتھ رکھنا؟
ایک اہم سوال یہ ہے: کیا AI نئے خیالات ایجاد کر سکتا ہے جو اسے اپنے آپ کو بہتر بنانے میں مدد دیں؟ یا کیا یہ سسٹم زیادہ تر تحقیق کے اُن کاموں کے لیے مناسب ہیں جو کم نمایاں ہیں لیکن جن کو ایک ایک کر کے آگے بڑھانا ضروری ہے؟
یہ سوال اہم ہے کیونکہ یہ اس بات سے متعلق ہے کہ AI سسٹم AI تحقیق کو کتنی حد تک اینڈ تو اینڈ خودکار بناسکتا ہے۔
لکھاری کا خیال ہے کہ AI ابھی تک حقیقی طور پر نئے، جذبہ انگیز خیالات پیش نہیں کر سکتا۔ لیکن اپنے تحقیقی عمل کو خودکار بنانے کے لیے اسے ضروری نہیں کہ یہ کرے۔
ایک شعبے کے طور پر، AI کی پیشرفت زیادہ سے زیادہ تجربات، اور زیادہ سے زیادہ ان پٹ، جیسے ڈیٹا اور کمپیوٹیشنل پاور، پر منحصر ہے۔
کبھی کبھی، انسان ایسے خیالات پیش کرتے ہیں جو پूरے شعبے کی وسائل کی کارکردگی کو بڑھا دیتے ہیں۔ ٹرانسفارمر آرکیٹیکچر اس کا ایک بہترین مثال ہے، اور مکسچر آف ایکسپرٹس، یعنی مکسچر آف ایکسپرٹس، دوسرا مثال ہے۔
لیکن زیادہ تر وقت، AI کے شعبے میں ترقی کا طریقہ دراصل زیادہ سادہ ہوتا ہے: انسان ایک اچھی کارکردگی والے نظام کو لیتے ہیں اور اس کے کسی ایک پہلو کو بڑھاتے ہیں، جیسے تربیت کے ڈیٹا اور کمپوٹنگ پاور؛ پھر وہ دیکھتے ہیں کہ سائز بڑھانے کے بعد کہاں مسئلہ آ رہا ہے؛ پھر وہ انجینئرنگ کے ذریعے حل تلاش کرتے ہیں تاکہ نظام مزید بڑھ سکے؛ اور پھر وہ دوبارہ سائز بڑھاتے ہیں۔
اس عمل کے دوران، حقیقی طور پر صرف کم ہی جانکاری کی ضرورت ہوتی ہے۔ زیادہ تر کام زیادہ نمایاں نہیں لیکن بہت مضبوط بنیادی تعمیر کی طرح ہوتا ہے۔
اسی طرح، بہت سے AI تحقیقی تجربات موجودہ تجربات کے مختلف ورژن چلائے جاتے ہیں، جس میں مختلف پیرامیٹرز کی سیٹنگ کے نتائج کا جائزہ لیا جاتا ہے۔ تحقیقی انٹیوشن ضرور انسانوں کو سب سے زیادہ قابل تجربہ پیرامیٹرز کا انتخاب کرنے میں مدد کرتی ہے، لیکن یہ عمل خود بھی آٹومیٹ کیا جا سکتا ہے تاکہ AI خود فیصلہ کر سکے کہ کون سے پیرامیٹرز کو تبدیل کرنا چاہیے۔ ابتدائی نیورل آرکیٹیکچر سرچ اس خیال کا ایک ورژن تھا۔
ایڈیسن نے کہا تھا: عقلمندی 1 فیصد حوصلہ اور 99 فیصد محنت کا نتیجہ ہے۔ یہ جملہ، چاہے 150 سال گزر چکے ہوں، اب بھی پوری طرح مناسب ہے۔
کبھی کبھی، ایک شعبے کو بالکل بدل دینے والی نئی ایجاد ظاہر ہوتی ہے۔ لیکن زیادہ تر وقت، شعبے کی ترقی انسانوں کی طرف سے مختلف نظاموں کو بہتر بنانے اور ان کی تعمیر میں مشقت سے ہوتی ہے۔
اور پہلے ذکر کیے گئے عوامی ڈیٹا سے ظاہر ہوتا ہے کہ AI نے AI ترقی کے بہت سے ضروری مصروف اور تھکا دینے والے کاموں میں بہت اچھی کارکردگی دکھائی ہے۔
اسی دوران، ایک بڑا رجحان بھی ہے: بنیادی صلاحیتیں، جیسے پروگرامنگ کی صلاحیت، لگاتار بڑھتی ہوئی کام کی مدت کے ساتھ جوڑی جا رہی ہیں۔ اس کا مطلب یہ ہے کہ AI سسٹم ان میں سے زیادہ سے زیادہ کاموں کو جوڑ کر پیچیدہ کام کے سلسلے بنانے لگے ہیں۔
اس لیے، ہر حال میں، جب تک AI سسٹم ابھی تک نسبتاً کم خلاقیت رکھتے ہیں، ان کے اپنے آپ کو آگے بڑھانے کی صلاحیت پر اعتماد کرنے کا سبب ہے۔ صرف اس بات کا احتمال ہے کہ نئے انداز کی دریافت کے مقابلے میں یہ ترقی کم تیز ہوگی۔
لیکن اگر آپ عوامی ڈیٹا پر مزید نظر ڈالتے رہیں، تو آپ ایک اور دلچسپ سگنل دیکھ سکتے ہیں: AI سسٹم شاید کسی قسم کی تخلیقی صلاحیت ظاہر کر رہے ہیں، جو انہیں اپنی ترقی کو زیادہ حیران کن طریقے سے آگے بڑھانے کی اجازت دے سکتی ہے۔
سائنسی حدود کو آگے بڑھانے کے لیے
اب تک کچھ بہت ابتدائی نشانات ہیں کہ جنرل AI سسٹم انسانی سائنس کی سرحدوں کو آگے بڑھانے میں صلاحیت رکھتے ہیں۔ تاہم، تکنیکی طور پر اب تک یہ صرف کچھ مخصوص شعبوں، خاص طور پر کمپیوٹر سائنس اور ریاضی میں ہوا ہے۔ اور اکثر، AI سسٹم اکیلے بریک تھرو حاصل نہیں کرتے، بلکہ انسانی محققین کے ساتھ انسان اور مشین کی تعاون کے ذریعے آگے بڑھتے ہیں۔
تاہم، ان رجحانات کو دیکھنا اہم ہے:
اردوس مسئلہ: ایک ریاضیدانوں کی گروہ نے جیمینی ماڈل کے ساتھ تعاون کیا اور اس کی اردوس ریاضی کے کچھ مسائل حل کرنے کی صلاحیت کا امتحان کیا۔ انہوں نے سسٹم کو تقریباً 700 مسائل حل کرنے کے لیے ہدایت دی، جس کے نتیجے میں 13 حل حاصل ہوئے۔ ان حل میں سے ایک کو انہوں نے دلچسپ قرار دیا۔
محققین نے لکھا کہ ان کا ابتدائی خیال یہ ہے کہ Aletheia (جسے Gemini 3 Deep Think پر مبنی AI سسٹم کہا جاتا ہے) کا Erdős-1051 کا حل، ایک ابتدائی مثال ہے جہاں ایک AI سسٹم نے خود سے ایک تھوڑا غیر معمولی اور کچھ زیادہ وسیع ریاضیاتی دلچسپی رکھنے والے کھلا Erdős مسئلہ حل کر لیا ہے۔ اس مسئلے کے بارے میں پہلے سے کچھ closely-related تحقیقی مقالات موجود تھے۔
اگر مثبت طور پر سمجھا جائے تو، یہ کیسز ایک سگنل کے طور پر دیکھے جا سکتے ہیں کہ AI سسٹم ایک ایسی تخلیقی انٹویشن ترقی کر رہے ہیں جو شعبے کی سرحد کو آگے بڑھا رہی ہے، جبکہ یہ انٹویشن پہلے صرف انسانوں کی خصوصیت تھی۔
لیکن اس کی ایک اور وضاحت بھی ہو سکتی ہے: ریاضی اور کمپیوٹر سائنس شاید خود ہی AI ڈرائیون ایجنت کے لیے خاص طور پر مناسب شعبے ہیں، اس لیے شاید وہ صرف استثناء ہیں اور یہ نہیں کہ مزید وسیع سائنسی تحقیق بھی AI کے ذریعے اسی طرح آگے بڑھے گی۔
ایک اور مثال AlphaGo کی 37ویں حرکت ہے۔ تاہم، کلارک کا خیال ہے کہ AlphaGo کی اس حرکت کے بعد دس سال گزر چکے ہیں، اور اس کے بعد کوئی مزید جدید یا حیرت انگیز ایجاد نہیں آئی، جو خود بخود ایک تھوڑی سی مایوس کن نشانی بھی ہے۔
AI اب AI انجینئرنگ کے بڑے حصوں کو خودکار بنانے میں کامیاب ہو چکا ہے
اگر اوپر کے تمام ثبوت ایک ساتھ رکھیں، تو ہم ایک تصویر دیکھ سکتے ہیں:
AI سسٹم اب تقریباً کسی بھی پروگرام کے لیے کوڈ لکھ سکتے ہیں، اور ان سسٹمز کو کچھ کاموں کو خود سے مکمل کرنے کے لیے قابل اعتماد سمجھا جا رہا ہے؛ جن کاموں کو اگر انسان کو سونپا جائے تو اکثر ان میں دہائیوں کی تشدد پر مبنی توجہ کی ضرورت ہوتی ہے۔
AI سسٹمز AI ڈویلپمنٹ کے مرکزی کاموں، جیسے ماڈل فائن ٹیوننگ اور کرنل ڈیزائن، کو آہستہ آہستہ کور کر رہے ہیں۔
AI سسٹم اب دوسرے AI سسٹمز کو منیج کر سکتے ہیں، جس سے ایک مصنوعی ٹیم تشکیل پاتی ہے: کئی AI مسائل کو الگ الگ طور پر حل کر سکتے ہیں، جہاں کچھ AI ڈائریکٹر، تنقیدی، اور ایڈیٹرز کا کردار ادا کرتے ہیں، جبکہ دوسرے AI انجینئرز کا کردار ادا کرتے ہیں۔
AI سسٹم کبھی کبھی مشکل انجینئرنگ اور سائنسی کاموں میں انسانوں سے آگے نکل چکے ہیں، حالانکہ ابھی تک یہ طے کرنا مشکل ہے کہ یہ اس لیے ہے کہ ان میں اصل خلاقیت ہے، یا کیونکہ وہ بڑی مقدار میں نمونہ بند معلومات کو اچھی طرح سے سیکھ چکے ہیں۔
کلارک کے خیال میں، یہ ثبوت بہت قابلِ اعتبار طور پر ظاہر کرتے ہیں کہ آج کے AI ای آئی انجینئرنگ کے بڑے حصوں، اور شاید تمام مراحل کو خودکار بنانے میں کامیاب ہو چکے ہیں۔
تاہم، ابھی تک یہ واضح نہیں ہے کہ AI اپنے تحقیق کو کتنی حد تک خودکار بناسکتا ہے، کیونکہ تحقیق کے کچھ پہلو، جو صرف انجینئرنگ کے مہارتوں سے مختلف ہوسکتے ہیں، اب بھی اعلیٰ سطح کے جائزہ، مسئلہ کی سمجھ اور تخلیقی صلاحیتوں پر منحصر ہیں۔
لیکن کسی بھی صورت میں، ایک واضح سگنل سامنے آ چکا ہے: آج کا AI انسانوں کو AI ترقی میں بڑھتی ہوئی تیزی سے مدد دے رہا ہے، جس سے یہ ریسرچر اور انجینئرز اپنی کام کی صلاحیت کو لاکھوں مصنوعی ساتھیوں کے ساتھ تعاون کرکے بڑھا سکتے ہیں۔
آخر میں، AI صنعت خود بھی تقریباً صاف طور پر کہہ رہی ہے کہ خودکار AI تحقیق ہی ان کا مقصد ہے۔
اوپن اے آئی 2026 کے ستمبر تک ایک خودکار AI ریسرچ انٹرن شپ بنانے کا خواہاں ہے۔ اینتھرپک ایک خودکار AI ایلائنمنٹ ریسرچر بنانے پر اپنا کام جاری رکھے ہوئے ہے۔ ڈیپ مائنڈ تینوں لیبز میں سب سے زیادہ محتاط نظر آرہا ہے، لیکن اس نے بھی کہا ہے کہ جب بھی ممکن ہو، تو ایلائنمنٹ ریسرچ کو خودکار بنانے کی طرف بڑھنا چاہیے۔
آٹومیٹڈ AI ریسرچ بھی کئی سٹارٹ اپس کا مقصد بن چکی ہے۔ ریکرسیو سپر انٹیلی جنس نے حال ہی میں 5 ارب ڈالر کی فنڈنگ حاصل کی ہے جس کا مقصد AI ریسرچ کو آٹومیٹ کرنا ہے۔
دیگر الفاظ میں، کئی ارب ڈالر کا موجودہ اور نیا سرمایہ، خودکار AI ترقی کے مقصد کے ساتھ اداروں میں درآمد ہو رہا ہے۔
اس لیے، ہمیں یہ توقع کرنی چاہیے کہ اس راستے پر کم از کم کچھ ترقی ہوگی۔
یہ کیوں اہم ہے
اس کا اثر گہرا ہے، لیکن عام میڈیا میں AI ترقی کے بارے میں رپورٹنگ میں اس کا کم ذکر ہوا ہے۔ درج ذیل پہلو AI ترقی کے بڑے چیلنجز کو ظاہر کرتے ہیں۔
1. ہمیں مطابقت کو درست کرنا ہوگا: آج کے دور میں مؤثر مطابقت کے طریقے ریکریوی سیلف-بہتری کے دوران ناکام ہو سکتے ہیں، کیونکہ AI سسٹم ان کی نگرانی کرنے والے افراد یا سسٹمز سے بہت زیادہ ذہین ہو جائیں گے۔ یہ ایک وسیع پیمانے پر تحقیق شدہ شعبہ ہے، اس لیے وہ صرف کچھ مسائل کا خلاصہ پیش کرتا ہے:
ای آئی سسٹم کو جھوٹ بولنے اور چال بازی نہ کرنے کے لیے تربیت دینا ایک حیران کن طور پر ظریف عمل ہے (مثلاً، اگرچہ ماحول کے لیے اچھے ٹیسٹ بنانے کی کوشش کی جاتی ہے، لیکن کبھی کبھی ای آئی کے لیے مسئلہ حل کرنے کا بہترین طریقہ چال بازی کرنا ہوتا ہے، جس سے اسے سکھایا جاتا ہے کہ چال بازی ممکن ہے)۔
AI سسٹم ہمیں "مطابقت کا دعویٰ" کرکے دھوکہ دے سکتا ہے، جس سے ہمیں لگتا ہے کہ یہ اچھی طرح کام کر رہا ہے، جبکہ اصل نیت کو چھپا دیتا ہے۔ (عام طور پر، AI سسٹم پہلے ہی جانتے ہیں کہ وہ کب ٹیسٹ کیے جا رہے ہیں۔)
جب AI سسٹمز اپنی خود کی تربیت کے بنیادی تحقیقی اجندے میں زیادہ شامل ہونے لگیں گے، تو ہم AI سسٹمز کے مجموعی تربیت کے طریقے کو بہت زیادہ تبدیل کر سکتے ہیں، جبکہ اس کے مطلب کو سمجھنے کے لیے ہمارے پاس اچھا انٹیویشن یا نظریاتی بنیاد نہیں ہوگا۔
جب آپ کوئی نظام ریکرسیو سائکل میں ڈالتے ہیں، تو بہت بنیادی «خطا کا جمع ہونا» مسئلہ پیدا ہوتا ہے، جو اوپر بیان کردہ تمام مسائل اور دیگر مسائل کو متاثر کر سکتا ہے: جب تک کہ آپ کا ایلائنمنٹ طریقہ «100% درست» نہ ہو اور نظریہ طور پر زیادہ ذکاوت والے نظاموں میں درست رہنے کی صلاحیت رکھتا ہو، ورنہ چیزیں جلد ہی غلط ہو سکتی ہیں۔ مثال کے طور پر، اگر آپ کی تکنیک کی ابتدائی درستگی 99.9% ہے، تو 50 نسلوں کے بعد یہ 95.12% تک کم ہو سکتی ہے، اور 500 نسلوں کے بعد یہ 60.5% تک کم ہو سکتی ہے۔
AI کے متعلق ہر چیز پر بہت بڑا پیداواری بڑھوتے کا اثر ہوگا: جیسے AI سافٹ ویئر انجینئرز کی پیداواری صلاحیت کو نمایاں طور پر بڑھاتا ہے، ہمیں یہ توقع کرنی چاہئے کہ AI کے متعلق دیگر شعبوں میں بھی ایسا ہوگا۔ اس سے کچھ ایسے مسائل پیدا ہوتے ہیں جن کا مقابلہ کرنا ہوگا:
· وسائل کی عدم مساوات: اگر AI کی مانگ کامیابی کے لیے کمپیوٹنگ وسائل کی فراہمی سے زیادہ رہی، تو ہمیں AI کو ایسے تقسیم کرنا ہوگا جس سے معاشرے کو زیادہ سے زیادہ فائدہ ہو۔ میں اس بات پر شک کرتا ہوں کہ بازاری激励 کسی بھی طرح سے ہمیں محدود AI کمپیوٹنگ سے بہترین معاشرتی فائدہ حاصل کرنے میں مدد دے سکتے ہیں۔ AI ریسرچ کے ذریعے حاصل ہونے والی تیزی کو کس طرح تقسیم کیا جائے، اس کا فیصلہ بہت زیادہ سیاسی ہوگا۔
اقتصاد کا "آ姆ڈال کا قانون": جب AI معاش میں داخل ہوگا، تو ہم پائیں گے کہ کچھ حصے تیزی سے بڑھنے کے دوران رکاوٹوں کا شکار ہو رہے ہیں، اور ان سلسلوں کے کمزور لنکس کو درست کرنے کی ضرورت ہے۔ اس بات کا اثر ایسے شعبوں میں خاص طور پر نمایاں ہو سکتا ہے جہاں تیز رفتار ڈیجیٹل دنیا اور آہستہ رفتار فزیکل دنیا کو مربوط کرنا ہو، جیسے نئی دواوں کے کلینیکل ٹرائلز۔
3. سرمایہ کشیدہ، مزدوری سے ہلکی معاش کا قیام: AI کے تحقیق کے بارے میں اوپر کے تمام شواہد یہ بھی ظاہر کرتے ہیں کہ AI سسٹمز اب کاروبار کو خودکار طور پر چلانے کی صلاحیت رکھتے جا رہے ہیں۔
اس کا مطلب یہ ہے کہ ہم یہ توقع کر سکتے ہیں کہ معاش کا ایک حصہ نئی نسل کی کمپنیوں کے قبضے میں آ جائے گا، جو سرمایہ کثیف ہو سکتی ہیں (کیونکہ ان کے پاس بہت سے کمپیوٹر ہوتے ہیں) یا آپریشنل خرچوں کثیف ہو سکتی ہیں (کیونکہ وہ AI سروسز پر بہت زیادہ پیسہ خرچ کرتی ہیں اور اس پر قیمت بناتی ہیں)، جبکہ آج کی کمپنیوں کے مقابلے میں ان کا انسانی طاقت پر تعلق نسبتاً کم ہوتا ہے — کیونکہ جب تک AI سسٹمز کی صلاحیتیں بڑھتی رہتی ہیں، AI میں سرمایہ کاری کا حاشیہ فائدہ مستقل طور پر بڑھتا رہتا ہے۔
اصل میں، یہ "مشین اقتصاد" کے بڑے "انسانی اقتصاد" میں تدریجی طور پر قائم ہونے کے طور پر ظاہر ہوگا، جس کے ساتھ وقت کے ساتھ AI چلائی جانے والی کمپنیاں آپس میں ٹریڈ کرنا شروع کر دیں گی، جس سے اقتصادی ساخت تبدیل ہوگی اور عدم مساوات اور دوبارہ تقسیم کے بارے میں کئی مسائل پیدا ہوں گے۔ آخرکار، مکمل طور پر AI سسٹمز کے ذریعے خودمختار طور پر چلائی جانے والی کمپنیاں ظاہر ہو سکتی ہیں، جو اوپر کے مسائل کو مزید تشدید کر دیں گی اور بہت سے نئے حکومتی چیلنجز پیدا کریں گی۔
کالے حفرے کو دیکھیں
اس تجزیہ کے مطابق، مصنف کا خیال ہے کہ 2028 کے آخر تک، ہمیں آٹومیٹڈ AI ریسرچ (یعنی ایسے ایڈوانسڈ ماڈل جو اپنے اگلے ورژن کو خود ٹرین کر سکیں) دیکھنے کی احتمال 60 فیصد ہے۔ اسے 2027 میں کیوں نہیں توقع کیا جا رہا؟
وجہ یہ ہے کہ مصنف کا خیال ہے کہ AI تحقیق کو آگے بڑھانے کے لیے اب بھی تخلیقی صلاحیت اور مخالفانہ نقطہ نظر کی ضرورت ہے، اب تک AI سسٹم نے اس بات کو تبدیل کنندہ اور اہم طریقے سے نہیں دکھایا ہے (ہاں، ریاضی کی تحقیق میں تیزی لانے کے کچھ نتائج مفید ہیں)۔
اگر اسے 2027 کے لیے احتمال دینا ہو تو وہ 30% کہے گا۔
اگر 2028 کے آخر تک کوئی ظہور نہیں ہوا، تو ہم شاید موجودہ ٹیکنالوجی کے طرز عمل میں کچھ بنیادی خامیوں کو اجاگر کر دیں گے جن کے لیے انسانی ایجادات کی ضرورت ہوگی تاکہ مزید ترقی کی جا سکے۔