










Уявіть цю сцену:
Ви попросили AI-агент допомогти вам виправити баг у коді. Він відкрив проект, прочитав 20 файлів, щось змінив, запустив тести — не пройшли, знову змінив, знову запустив — все ще не пройшли… Після десятків спроб — все ще не виправлено.
Ти вимкнув комп’ютер і полегше подихнув. Потім отримав рахунок за API.
Наведені цифри можуть здатися вражаючими — автономні AI-агенти, що виправляють баги через офіційні API за кордоном, часто витрачають мільйони токенів за одну невиправлену задачу, що призводить до витрат у діапазоні від десятків до сотень доларів США.
У квітні 2026 року дослідницька стаття, опублікована спільно Стенфордом, MIT, Університетом Мічигану та іншими, вперше систематично розкрила «чорний ящик» витрат AI Agent у завданнях, пов’язаних із кодом: де саме витрачаються гроші, чи варто це робити та чи можна передбачити це заздалегідь — відповіді викликали подив.
Відкриття 1: Швидкість витрат на написання коду агентом в 1000 разів вища, ніж у звичайного діалогового ІІ
Можливо, ви думаєте, що витрати на те, щоб AI писав код для вас, і на те, щоб AI розмовляв з вами про код, майже однакові.
Порівняння, наведене в статті:
Споживання токенів для агентних завдань кодування становить приблизно 1000 разів більше, ніж для звичайних завдань кодування та логічного міркування.
Різниця цілі три порядки величини.
Чому це відбувається? У статті зазначено факт: гроші витрачаються не на «написання коду», а на «читання коду».
Тут «читання» не означає, що людина читає код, а те, що агент у процесі роботи постійно «підкидає» моделі весь контекст проекту, історію операцій, інформацію про помилки та вміст файлів. З кожною додатковою сесією діалогу цей контекст стає довшим; а модель оплачується за кількість токенів — чим більше ви надаєте, тим більше платите.
Наприклад: це як запросити майстра, який перед кожним обертом гайкового ключа вимагає, щоб ви знову і знову читали йому всі креслення будівлі — вартість читання креслень набагато вища, ніж вартість обертання гайки.
Папір суміщує це явище в одному реченні: витрати на агента обумовлені експоненційним зростанням вхідних токенів, а не вихідних.
Друге виявлення: той самий баг, запущений двічі, може вимагати витрат, що відрізняються вдвічі — і чим дорожчий баг, тим менш стабільний він
Ще більш дратівливою є випадковість.
Дослідники запустили один і той самий агент на одній і тій самій задачі чотири рази і виявили:
- Між різними завданнями найдорожче завдання спалює приблизно на 7 мільйонів токенів більше, ніж найдешевше (Рисунок 2a)
- У кількох запусках однієї моделі на одній задачі найдорожча виконання приблизно вдвічі дорожча за найдешевшу (Рисунок 2b)
- А якщо порівнювати одне й те саме завдання між різними моделями, різниця між найвищим і найнижчим споживанням може досягати 30 разів.
Останнє число особливо важливе: це означає, що різниця в витратах між правильним і неправильним моделями — це не просто «трохи дорожче», а «на порядок дорожче».
Ще болісніше — витрачати більше не означає робити краще.
Дослідження виявило «обернену U-подібну» криву:
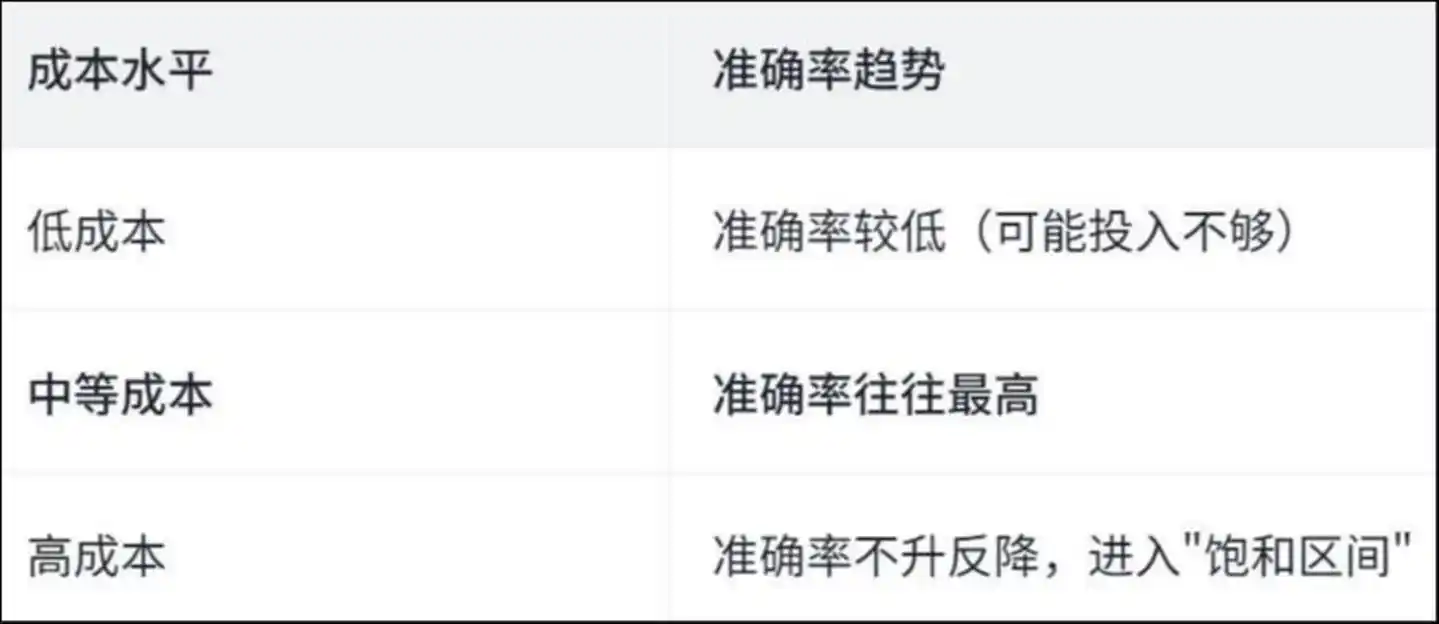
Рівень витрат: точність тенденції — низькі витрати, низька точність (можливо, недостатні інвестиції); середні витрати, найвища точність; високі витрати, точність не зростає, а навпаки знижується, входить у «інтервал насичення»
Чому це відбувається? Стаття дає відповідь, проаналізувавши конкретні дії агента —
У процесі високих витрат Agent значну кількість часу витрачає на «повторювану роботу».
Дослідження показало, що при високих витратах приблизно 50% операцій перегляду та зміни файлів є дублюючими — тобто агент постійно читає один і той самий файл та змінює один і той самий рядок коду, як людина, яка кружляє по кімнаті, все більше заплутуючись і все глибше потрапляючи в цикл.
Гроші не були витрачені на вирішення проблеми, а на «заблукання».
Відкриття 3: Ефективність між моделями дуже відрізняється — GPT-5 найбільш економний, деякі моделі витрачають на 1,5 мільйона токенів більше
У статті було протестовано вісім передових великих моделей щодо їх агентних здібностей на SWE-bench Verified — стандарті галузі, що містить 500 реальних проблем GitHub. У перерахунку на долари, моделі з високою ефективністю токенів можуть дозволити собі витрачати на кілька десятків доларів більше на завдання. У контексті корпоративного застосування — коли щодня виконується кілька сотень завдань — ця різниця стає реальними грошима.
Цікавішим виявленням є те, що ефективність токенів — це «вбудована риса» моделі, а не результат завдання.
Дослідники вибрали завдання, які всі моделі успішно вирішили (230), і завдання, які всі моделі не змогли вирішити (100), і порівняли їх, виявивши, що відносний рейтинг моделей майже не змінився.
Це означає: деякі моделі за природою «дуже розмовні» і це мало пов’язано зі складністю завдання.
Ще одне глибоке відкриття: модель не має «свідомості про стоп-втрати».
У випадку складних завдань, яких не можуть вирішити жодні моделі, ідеальний агент повинен якомога раніше зупинитися, а не продовжувати витрачати кошти. Але на практиці моделі зазвичай витрачають більше токенів на невдалих завданнях — вони не «здаються», а продовжують досліджувати, повторювати спроби та перечитувати контекст, наче автомобіль без індикатора рівня палива, що їде до моменту злому.
Висновок 4: Те, що людям здається складним, агенту не обов’язково здається дорогим — сприйняття складності повністю не збігається
Ви можете подумати: а хоча б чи можу я оцінити вартість залежно від складності завдання?
Для оцінки складності 500 завдань були залучені людські експерти, а потім отримані результати порівняно з фактичним споживанням токенів агентом—
Результат: між ними існує лише слабка кореляція.
Простими словами: завдання, які людям здаються надзвичайно складними, агент може виконати легко й недорого; а завдання, які людям здаються простими, агент може зробити так, що він почне сумніватися у своєму існуванні.
Це тому, що складність, яку бачать люди та ШІ, зовсім не однакова:
- Люди бачать: логічну складність, складність алгоритмів, бар’єри розуміння бізнес-процесів
- Агент дивиться: наскільки великий проект, скільки файлів потрібно прочитати, наскільки довгий шлях дослідження та чи будуть повторно змінюватися ті самі файли
Те, що людина-експерт вважає «досить змінити один рядок», агент може спочатку зрозуміти всю структуру кодової бази, щоб знайти цей рядок — саме «читання» вимагає великої кількості токенів. А те, що людина вважає «дуже складною логікою», агент може мати на увазі стандартний розв’язок і швидко вирішити його.
Це призводить до незручної реальності: розробники майже неможливо передбачити вартість виконання агента інтуїтивно.
Відкриття п’яте: навіть модель не може точно розрахувати, скільки вона витратить
Якщо люди не можуть точно передбачити, чому б не дати AI самому зробити прогноз?
Дослідники розробили витончений експеримент: дали агенту спочатку «перевірити» репозиторій коду, а потім оцінити, скільки токенів йому знадобиться для виправлення — але не виконувати саме виправлення.
Які результати?
Всі моделі, повний провал.
Найкращий результат — це кореляція передбачень Claude Sonnet-4.5 щодо виведених токенів — 0,39 (за шкалою від 0 до 1). Більшість моделей мають кореляцію в діапазоні від 0,05 до 0,34, а Gemini-3-Pro показав найнижчий результат — лише 0,04 — майже що випадкове вгадування.
Ще більш дивно: усі моделі систематично недооцінювали своє споживання токенів. На діаграмі розсіювання на рисунку 11 майже всі точки лежать нижче «лінії ідеального прогнозу» — моделі вважали, що «не витратять стільки», а насправді витрачали більше. Крім того, ця помилка недооцінки ще більше збільшується, коли приклади не надаються.
Ще більш іронічно — самі прогнози також коштують грошей.
Вартість прогнозування Claude Sonnet-3.7 та Sonnet-4 може перевищувати вдвічі вартість самої задачі. Тобто, попросити їх спочатку «оцінити вартість» коштує дорожче, ніж виконати роботу безпосередньо.
Висновок статті прямий:
На даний момент сучасні моделі не можуть точно передбачити використання власних токенів. Натиснення «Запустити агента» схоже на відкриття «сліпого боксу» — ви дізнаєтесь, скільки витратили, тільки коли отримаєте рахунок.
За цим «путанням» схований більш серйозний проблема галузі
Прочитавши це, ви можете запитати: що ці висновки означають для бізнесу?
Модель ціноутворення «підписка на місяць» розколюється під тиском агентів
Дослідження вказує, що підпискові моделі, такі як ChatGPT Plus, є виправданими, оскільки споживання токенів у звичайних діалогах відносно контролюване й передбачуване. Однак завдання агентів повністю порушують це припущення — одне завдання може спожити величезну кількість токенів через зациклення агента.
Це означає, що чисто підпискова цінова модель може бути непостійною для сценаріїв Agent, і платіж за використанням (Pay-as-you-go) протягом довгого часу залишатиметься найбільш реалістичним варіантом. Але проблема з платою за використанням полягає в тому, що обсяг використання сам по собі непередбачуваний.
2. Ефективність токену повинна стати «третім показником» при виборі моделі
Традиційно компанії оцінюють моделі за двома вимірами: здатність (чи може зробити) і швидкість (чи робить швидко). Ця стаття запропонувала третій рівноцінно важливий вимір: енергоефективність (скільки потрібно витратити, щоб досягти результату).
Модель, трохи слабша за потужність, але в 3 рази ефективніша, може мати більшу економічну цінність у масштабних сценаріях, ніж «найпотужніша, але найвартісніша» модель.
3. Агенту потрібні «показник палива» і «гальмо»
У статті згадується варто уваги майбутній напрямок — політики використання інструментів з урахуванням бюджету. Простими словами, це означає надати агенту «показник рівня палива»: коли споживання токенів наближається до бюджету, вимушено зупиняти його неефективні пошуки, а не витрачати всі ресурси до кінця.
Наразі майже всі основні фреймворки Agent не мають такого механізму.
Проблема «згорання грошей» агента — це не баг, а необхідний болісний етап індустрії
Ця стаття розкриває не недолік певної моделі, а структурний виклик усього парадигму агентів — коли ШІ еволюціонує від «один запит — одна відповідь» до «автономного планування, багатокрокового виконання та повторних налагоджень», непередбачуваність споживання токенів майже неминуча.
Доброю новиною є те, що це перший раз, коли хтось систематично вивів цю плутанину на чисту воду. З цими даними розробники можуть більш обґрунтовано вибирати моделі, встановлювати бюджети та проектувати механізми стоп-лосу; виробники моделей отримують новий напрямок оптимізації — не лише робити їх сильнішими, а й робити їх більш економними.
В кінці кінців, доки AI Agent справді не увійде у виробничі процеси всіх галузей, розумне витрачання кожної гривні важливіше, ніж красиво написаний код. (Ця стаття вперше опублікована в додатку Titanium Media, автор | Silicon Valley Tech news, редактор | Чжао Хуньюй)
Примітка: Ця стаття написана на основі пре-принту наукової роботи, опублікованого 24 квітня 2026 року на arXiv: *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Автори походять з університету Вірджинії, Стенфордського університету, MIT, Університету Мічигану та інших установ. Дослідження ще не пройшло рецензування.