










Автор: Max, який завжди в дорозі, 01Founder
Якщо підсумовувати 2025 рік для OpenAI, багато хто, ймовірно, охарактеризує його як спокійний, навіть трохи пасивний.
Протягом останнього року вони систематично пройшли шлях логічного міркування, щільно запустивши моделі висновування від o3pro до o4mini, а також представили нові базові моделі, такі як GPT-4.5 і GPT-5.
Але у сфері візуального генерування, яку найлегше сприймають звичайні користувачі і яка найбільше сприяє спонтанному поширенню, їхня присутність поступово зменшується.
Після початкового шоку від появи Sora, OpenAI, здається, ввійшла у довгий період мовчання в цьому сегменті.
Тим часом інші гравці за столом не сиділи без діла.
У відкритій екосистемі такі моделі, як Flux, повністю знищили бар’єри для якісного локального створення зображень;
На бізнес-площадці крім старих суперників, які тримають високі стандарти естетики, з’явилися нові гравці, такі як Nano-banana, які мають вбудовану функцію пошуку в інтернеті.
Навпаки, попередня основна модель генерації зображень OpenAI GPT-Image-1.5 вже виглядає застарілою:
Якість зображення погана, макет жорсткий, і система часто аварійно завершує роботу при роботі зі складними текстами.
Поступово в галузі сформувалася згода:
OpenAI зіткнулася з технічними бар’єрами у сфері візуального генерування і вже не в змозі ефективно конкурувати зі своїми конкурентами.
До кількох тижнів тому точка повороту з’явилася дуже приховано.
На відомій платформі сліпого тестування великих моделей LM Arena таємно з’явилася загадкова зображення-модель під кодовою назвою Duct Tape.
Учасники сліпого тестування швидко зрозуміли, що щось не так:
Ця модель не лише надзвичайно точно керує екстремальними співвідношеннями сторін, але й бездоганно генерує розміщення плакатів з великою кількістю багатомовних текстів, навіть здається, що перед створенням зображення відбувається прихований логічний процес планування.
Протягом деякого часу різні технічні спільноти припускали, що це був прихований хід якоїсь компанії, але OpenAI залишалася мовчазною.
Сьогодні вночі ботинки нарешті впали.
Без довгих презентацій та масштабної маркетингової підготовки OpenAI офіційно назвала модель під кодовою назвою Tape — ChatGPT GPT-Image-2 і повністю запустила її на ринок.
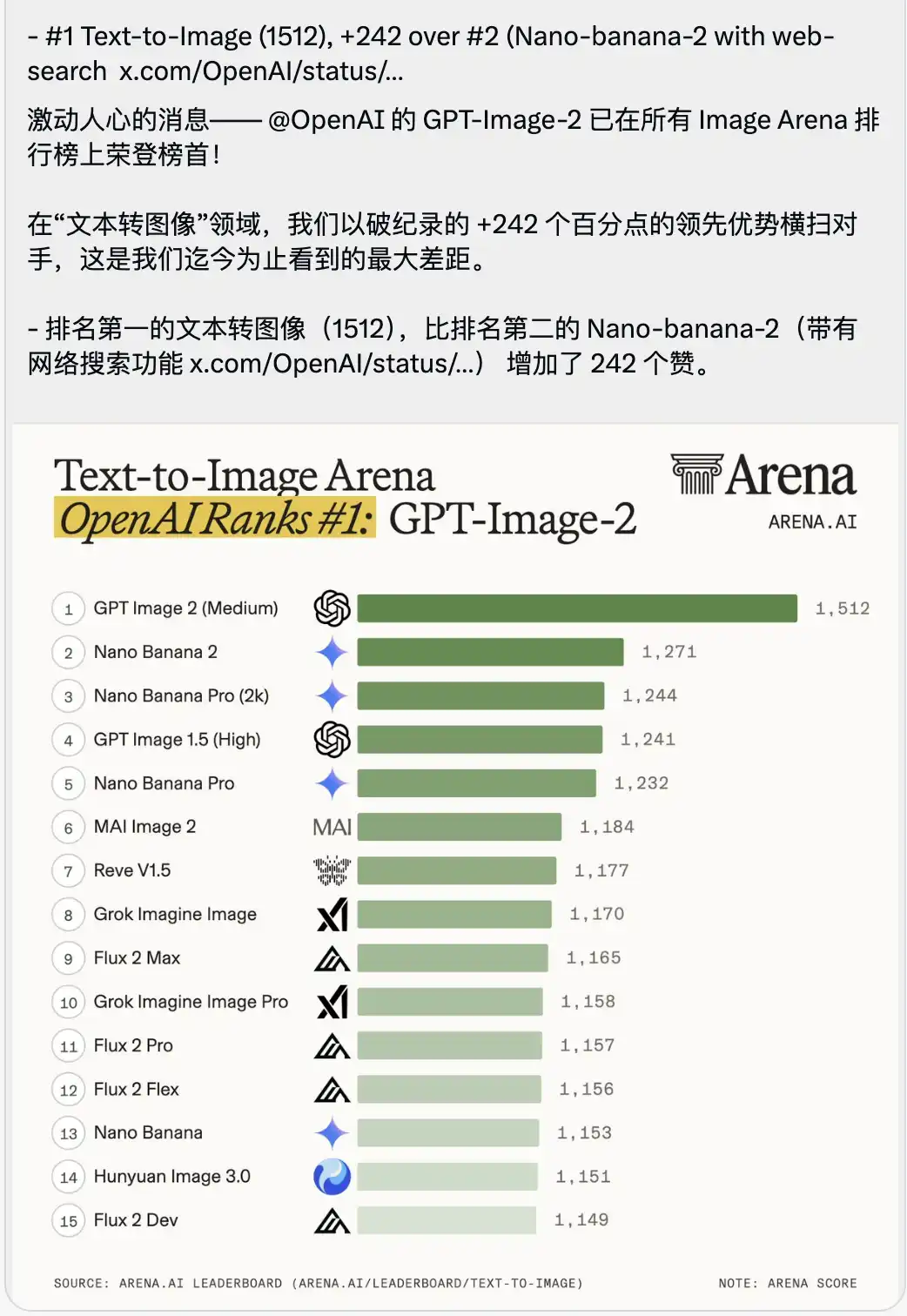
Разом із цим було опубліковано рейтингову таблицю Text-to-Image, яка викликає відчуття певної задухи.
GPT-Image-2 з рекордним результатом 1512 безпосередньо зайняв перше місце, обігнавши друге місце (Nano-banana-2 з функцією пошуку в інтернеті) на цілих 242 бали.
У контексті оцінки великих моделей, люди часто надто підкреслюють переваги на кілька десятих або одиниць, оскільки бали лідерів дуже близькі.
Різниця в 242 бали — безпрецедентна в історії арени.
Це зовсім не невелика версійна оновлення, це грубе перевага покоління.
Я витратив велику частину дня, уважно ознайомившись з усіма його граничними можливостями та останніми документами API.
Єдине найбільше враження:
OpenAI залишається тією самою OpenAI.
Коли він вирішив відновити втрачене, він зробив це, повністю зруйнувавши старий стіл.
Перед цією моделлю роботи з візуального дизайну, які ми вважали, що ще потребуватимуть двох-трьох років, перш ніж їх повністю замінять ШІ, сьогодні практично можна вважати завершеними.
ЧАСТИНА.01 Генерація зображень від моделі до візуального агента
Щоб зрозуміти, чому GPT-Image-2 показує таку велику різницю в оцінках, спочатку потрібно відкинути минулі уявлення про моделі генерації зображень за текстом.
Раніше ми використовували AI для малювання, що було схоже на відкриття сліпих коробок: вводили кілька ключових слів і чекали, поки він впорядкує пікселі у бажану картинку.
Але GPT-Image-2 більше схожий на агента з вбудованим візуальним двигуном.
Найбільш очевидною зміною є те, що в механізмі було прямо розділено два абсолютно різні режими.
Один із режимів — миттєвий режим (Instant Mode), доступний для всіх користувачів.
Цей режим зосереджений на швидкій відповіді та безперервному підключенні до робочих та побутових процесів.
Наприклад, ви надсилаєте йому команду зі свого телефону, і він за кілька секунд надає вам повну структуровану діаграму.
Його базова здатність до візуального розуміння дуже сильна, але він вирішує переважно часті, одноразові візуальні завдання.
А режим мислення (Thinking Mode), доступний для платних користувачів.
Перш ніж він почне відображати навіть один піксель, він проходить через кілька десятків секунд логічних міркувань та пошуку в інтернеті.
Саме ця модель вирішує надзвичайно важливу, але надзвичайно складну проблему:
Модель вперше справді дізналася, що малювати.
Наведемо найбільш наочний приклад.
Введіть у вікні діалогу:
Допоможіть створити плакат, знайдіть в інтернеті відгуки про таємничу модель Duct Tape та додайте QR-код ChatGPT.

Якби використовувався попередній моделі, він взагалі не розумів би, що сказав користувач, і просто намалював би плакат із сміттям і фальшивими символами, а QR-код був би фальшивою зображенням, яку неможливо відсканувати.
Але в режимі міркування його робочий процес виглядає так:
Він спочатку призупинить малювання, запустить інструмент пошуку в інтернеті, щоб зібрати реальні відгуки користувачів з Reddit, Threads або LinkedIn;
Потім він почав планувати макет плаката, відступи та ієрархію шрифтів;
Нарешті, він генерує справжній, працездатний QR-код, який можна відсканувати для переходу, і відображає ціле зображення.

Це вже не малювання, а справді повний цикл роботи: самостійне проведення досліджень, планування, виділення текстів та дизайн макетів.
Тут потрібно зробити паралельне порівняння.
Усі, хто стежить за світом великих моделей, знають, що генеративні моделі з можливістю підключення до інтернету та пошуку — це не винахід OpenAI.
Другий у рейтингу Nano-banana вже мав цей механізм.
Але під час реального використання Nano-banana ви помітите, що він виглядає трохи неспритним у багатьох місцях.
Міркування Nano-banana часто є механічним з’єднанням логіки.
Наприклад, якщо ви попросите його знайти тенденції галузі для плаката, він дійсно шукає, але зазвичай просто механічно вирізає речення з Вікіпедії і насильницьки накладає їх на зображення.
Коли зустрічається команда, що вимагає інтерпретації абстрактних бізнес-вимог, вона легко збивається з панелі.

Це відчувається як інтерн, який розуміє, що йому кажуть, але не має жодного досвіду — він знає, як виконувати завдання, але повністю не розуміє стратегії.
Але GPT-Image-2 у цьому аспекті можна описати лише надмірно.
Його міркування не є формальним актом, а справжнім розумінням культурного контексту та бізнес-намірів.
Під час тестування я ввів надзвичайно коротку китайську команду: допоможи мені зробити скріншот Маска, який проводить прямий ефір на Douyin і продаватиме DouBao.
Якби ви використовували попередні моделі для створення зображень, вони, найімовірніше, намалювали б білого чоловіка, схожого на Маска, який тримає баоцзы, з нечітким фоном і навіть не знаючи, як виглядає TikTok.
Але в режимі міркування результати GPT-Image-2 викликають певний ланцюжок тривоги.
Він не просто склав елементи, а самостійно використав розуміння китайського інтернету, щоб згенерувати знімок екрану інтерфейсу стрім-комнати Douyin, який є точним відтворенням на піксельному рівні.
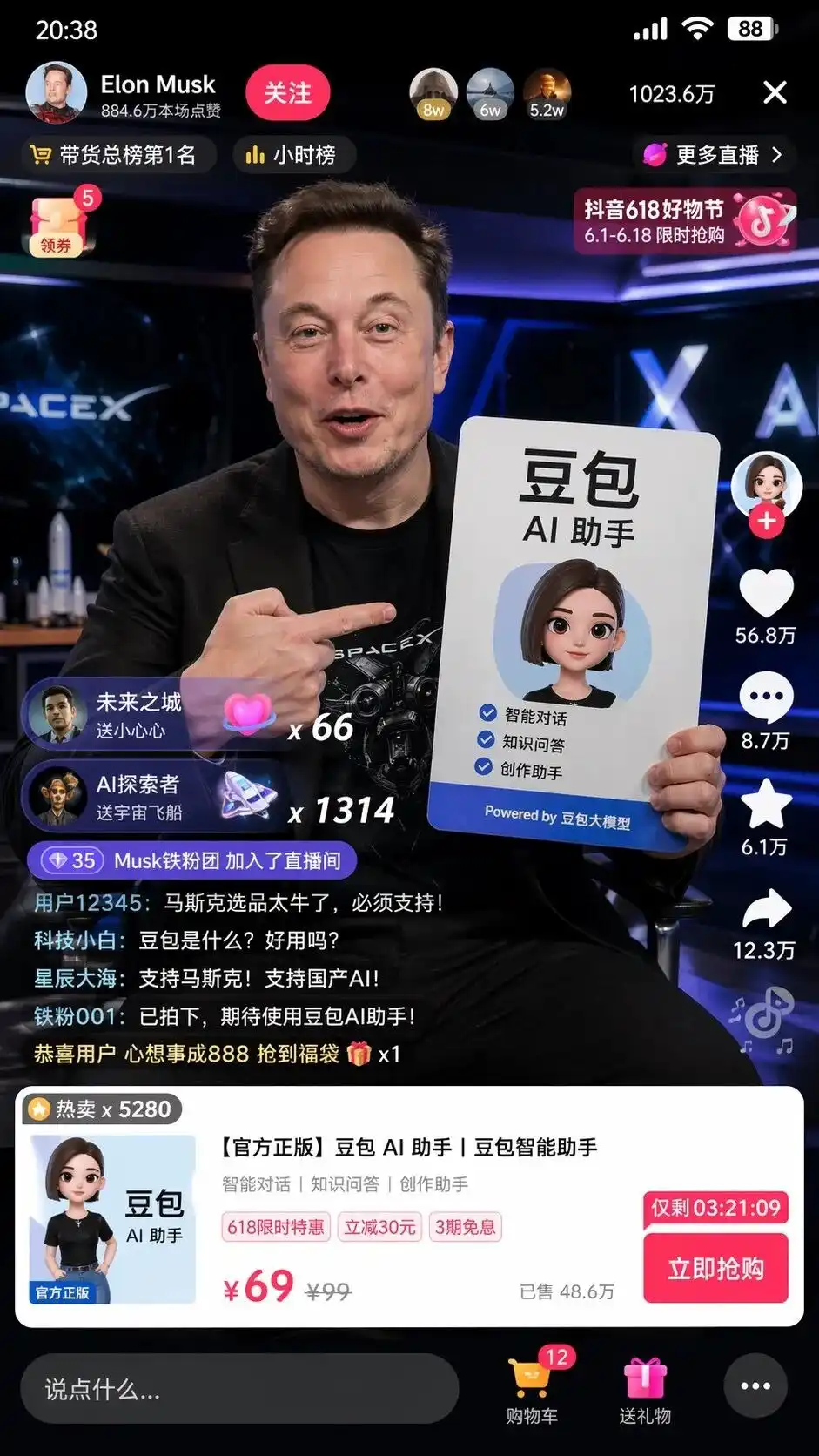
На екрані не лише реалістичний Маск тримає плакат із рекламою допоміжного програмного забезпечення DouBao AI з ідеальним форматуванням, але ще й більш жахливі деталі, яких не було в підказці:
Кнопка підписки у верхньому лівому куті, тайм-лист, 10,23 мільйона онлайн-користувачів у верхньому правому куті, стандартна картка товару у нижній частині, а також вказана перекреслена ціна 99, спеціальна ціна 69 та кнопка «Купити зараз» з таймером зворотного відліку.
Найбільш жахливе — це ролінг-коментарі в лівому нижньому куті, які виглядають надзвичайно реалістично:
Технічний новачок: Що таке Доуба? Чи зручний він у використанні?
Зіркова море: Підтримуємо Маска! Підтримуємо вітчизняний ІІ!
Ніхто не говорив йому, що писати в чаті, як має виглядати інтерфейс товару чи як встановлювати ціни.
Це повний дизайн користувацького інтерфейсу та маркетингова стратегія, які модель сгенерувала та виконала після аналізу тегів «продаж через Douyin» та «велика модель DouBao».
Оцінні критерії великих моделей у генерації зображень зараз офіційно перейшли від простого питання «чи може вони малювати гарно» до розуміння стратегії та логіки композиції.
ЧАСТИНА.02 Практичне тестування ключових здібностей
Щоб перевірити його межі, я застосував кілька частотних та складних сценаріїв у відповідності зі стандартами бізнес-дизайну.
Виявилось, що рівень деталізації, з яким вона вирішує проблеми, досить жахливий.
Перший сценарій: візуальне розуміння та бізнес-цикл (одягнення моделі)
У традиційній електронній комерції чи плануванні моди витрати на реалізацію від ідеї до вигляду на собі дуже високі.
Вам потрібно знайти модель, позичити одяг, організувати студію та провести фінальну обробку.
Пізніше з появою ШІ люди почали навчати моделі LoRA для фіксації обличчя персонажів, але це все ще вимагало десятки зображень і значних витрат на навчання.
У GPT-Image-2 цей процес було максимально стиснуто.
Я спробував завантажити своє звичайне селфі, сказавши йому, що наступного місяця їду на відпустку на острів, і попросив допомогти вибрати кілька комплектів одягу.
Спочатку він надав мені 8 комплектів летніх образів у різних стилях, розміщення яких нагадувало професійний електронний комерційний Lookbook, а біля кожної речі навіть були правильні текстові підписи.
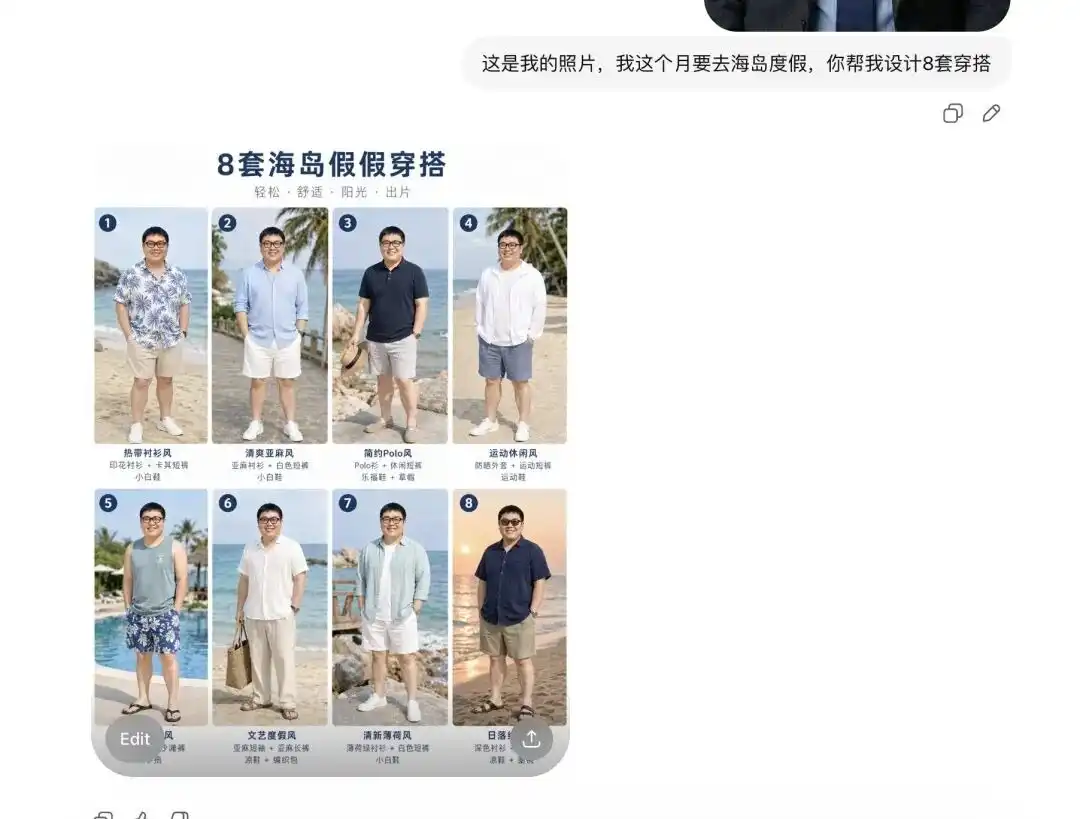
Ще важливіше, в цей самий момент він точно проаналізував мої риси обличчя та пропорції тіла.
Коли я сказав йому, що хочу побачити, як виглядає перший комплект на мені, і надав кілька детальних зображень з різних кутів, він безпосередньо витягнув людину з моєї фотографії, замінив її на літній комплект і вивів зображення з боку, напівфігури та інших кутів.

Цей поворот дуже плавний. Це означає, що бар’єр для початкового візуалізування одягу або зовнішніх робіт зі зняттям моделей у одязі повністю знищено.
Другий сценарій: вирішення консистентності та неперервного оповідання (генерація коміксів одним реченням)
Ті, хто вже використовував AI для генерації зображень, знають, що змусити AI створити одну гарну картинку — не складно, складно — змусити її створити десять зображень однієї й тієї ж особи, причому з послідовними рухами та кутами огляду.
Це й називається проблемою послідовності (Consistency).
Але в цьому практичному тесті я побачив випадок, який суттєво суперечить минулому досвіду.
Можете завантажити лише одну фотографію з другом з вчора, а потім ввести дуже простий ключовий рядок:
Перетворіть нас на головних героїв, намалюйте три тристорінкові японські манґи, сюжет визначте ви
Через кілька секунд він одразу вивів три сторінки чорно-білої комікси зі стандартними сценаріями.
Найбільш жахливим є те, що ці два персонажі, створені на основі реальних людей, з’являються в різних кадрах на трьох сторінках.

Незалежно від плану — крупний план, дальній план з бігом чи силует — навіть риси обличчя, деталі зачіски та складки на одязі зберігали ідеальну відповідність.
Ще більш вражаючим є те, що сюжет комікса повністю логічний, навіть текст у бульбашках діалогів утворює цілісну історію.

Здатність до узгодження часу та простору свідчить про те, що вона вийшла за межі генерації окремих зображень і володіє режисерськими здібностями для створення послідовного розповіді.
Третій сценарій: подолання останнього бар’єру рендерингу тексту (багатомовне верстка)
Якщо послідовність вирішує проблему повідомлення, то точне відтворення багатомовного тексту справді загнало графічних дизайнерів у кут.
Раніше, якщо на зображенні були хоча б трохи тексту, велика модель починала рисувати брехню.
Оскільки модель розуміє текст у вигляді токенів (семантичні блоки), а генерує зображення у вигляді пікселів, ці два елементи раніше були розділені.
GPT-Image-2 повністю вирішив це питання.
Я згенерував обкладинку французького модного журналу, створив меню японського ресторану з повним набором хірагани та ієрогліфів і навіть спробував розмістити надзвичайно щільний російський коментар.

Результат — одноразова форма, без помилок у написанні.
Найбільш розчаровуючим є те, що він не лише правильно написав символи, але й розуміє, як відповідати культурним смакам та дизайну шрифтів для кожної мови.
Наприклад, китайські ієрогліфи в японських листівках використовують дуже аутентичні японські вінтажні шрифти, а розташування хірагани відповідає традиційній вертикальній структурі читання японської мови.
Дизайн макету колись був власністю графічних дизайнерів.
Налаштування інтервалів між символами, визначення пріоритетів та досягнення візуальної рівноваги між текстом і фоном вимагають багато практики.
Але коли ШІ здатен обробляти стільки мов без помилок і має вбудовану високу естетику верстки, тоді щоденні плакати, брошури та рекламні пости в стрічці справді більше не потребують ручного вирівнювання за допомогою допоміжних ліній.
Четвертий сценарій: деформоване співвідношення сторін і екстремальний мікроконтроль (написи на зерні рису)
Нарешті, щоб перевірити, наскільки вона підкорюється, я дав їй кілька дуже складних команд.
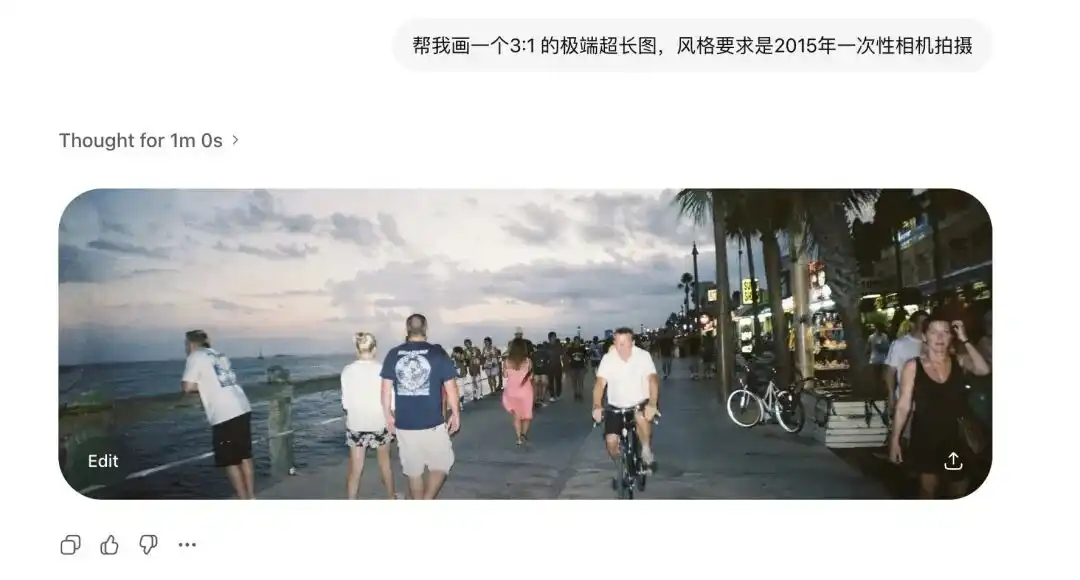
Я спочатку протестував його екстремальні співвідношення сторін.
Традиційні дифузійні моделі дуже бояться нестандартних пропорцій.
Раніше трохи потягнувши зображення, на екрані з’являлися дві голови.
Але я вимагав, щоб Images 2.0 створив надзвичайно широкі зображення зі співвідношенням 3:1 та довгі вертикальні зображення зі співвідношенням 1:3, і вони не тільки не зламалися, а й створили 360-градусну панораму зі з’єднаними кінцями та логічно замкненою структурою.
Після додавання термінів, знятих одноразовою камерою 2015 року, навіть дисторсія старих об’єктивів і погана відбивна здатність відспалаху на стіні відтворюються чітко.
Іншим прикладом, що краще підкреслює його мікроконтроль, є трохи дивний тест з рисинкою, продемонстрований офіційною стороною на презентації.
Дослідники використали експериментальну 4K API, яка ще перебуває на внутрішньому тестуванні; вони не використовували жодних додаткових описів, таких як макрофотографія або 8K надвисока чіткість, а лише дали дуже абстрактну просту інструкцію:
Купа рису. На одній з зернин цієї купи рису написано GPT Image 2.
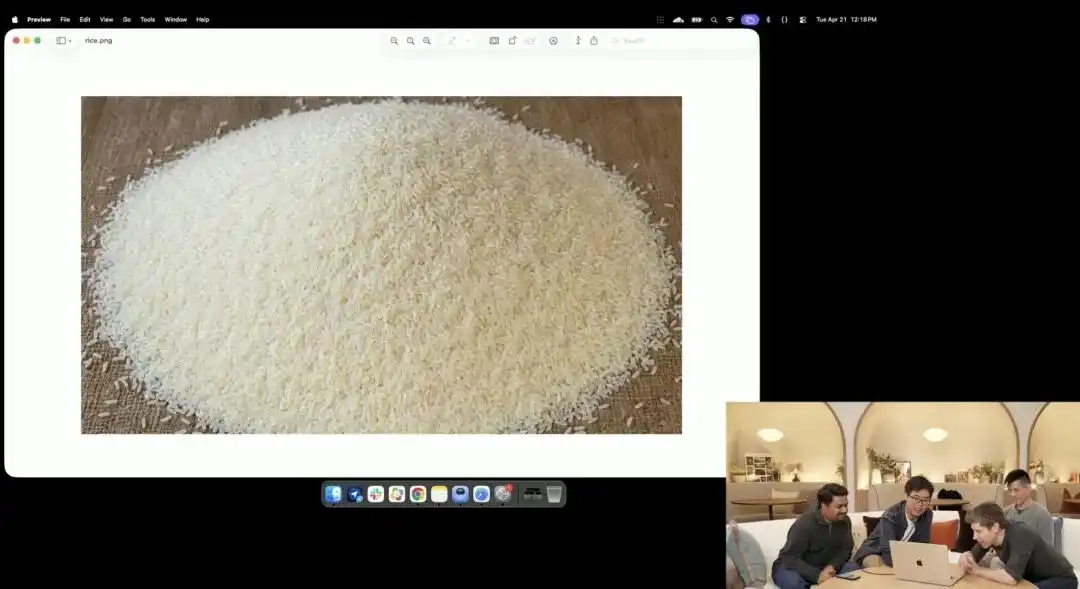
Коли зображення збільшено десятки разів на екрані і навіть з’являються піксельні зерна, чи зможете ви дійсно знайти ту крихітну частинку з написом серед купи рису?
Текстура цього рису все ще відповідає фізичним законам, і текст точно вписався у мікрокривизни поверхні зерна.
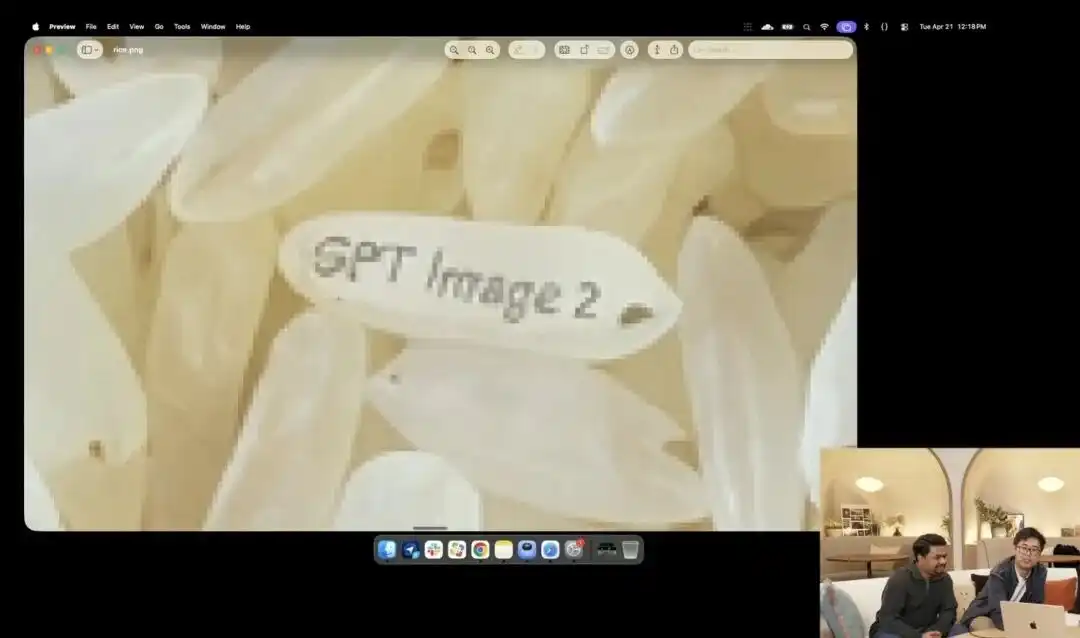
Всі решта роботи — виклик макро-перспективи, розрахунок глибини різкості, пошук фізичних координат зерна в латентному просторі та нанесення тексту — були автоматично вигадані та виконані великою моделлю в режимі міркування.
Цей приклад наочно демонструє, що модель розуміє просторове розташування з точністю до пікселя.
Це означає, що тепер у реальній роботі ви зможете точно змінювати будь-який дрібний фрагмент макету — точно в ціль, а не як раніше, коли, намагаючись змінити комір, ви змінювали всю картинку.
ЧАСТИНА.03 Деякі технічні деталі
Ця екстремальна контрольна здатність та стратегічна інтелігентність абсолютно не можуть бути досягнуті лише шляхом сліпої накачки обчислювальних потужностей.
Щоб зрозуміти, що саме вона має на увазі, я провів кілька тестів-зондів для GPT-Image-2.
Виявилася дуже цікава деталь.
Хоча в офіційній документації зазначено, що дата оновлення загальної бази знань GPT-Image-2 — грудень 2025 року, але в моїх практичних тестах.
Дані для навчання режиму миттєвого режиму (Instant Mode) все ще залишаються на кінець травня 2024 року;

А режим міркування (Thinking Mode), який вимагає довгого обдумування, має власну базу знань, що приблизно відповідає червню 2024 року (але може отримувати актуальну інформацію через реальний доступ до Інтернету).

Виходячи з цих двох моментів часу, здається, можна відстежити основу GPT-Image-2.
Спочатку розглянемо режим у реальному часі, орієнтований на часті виведення зображень.
Дедлайн у травні 2024 року означає, що, ймовірно, він безпосередньо використовує o4-mini або є легковажною версією родини GPT-5 (GPT-5 mini або навіть надмалої GPT-5 nano).
Саме тому, що ця легка базова модель вже має дуже сильні здібності до планування простору та розуміння складних інструкцій, генерація зображень на верхньому рівні зможе залишитися стабільною і не вийде з-під контролю.
А та надзвичайно розумна, зрозуміла стратегію бізнесу, модель мислення не може базуватися на основній моделі GPT-5.
Оскільки база знань GPT-5 має дату завершення версії вересень 2024 року.
Режим міркувань, найімовірніше, підключений до постійно ітерованої в фоновому режимі моделі серії O (наприклад, o4 або оновленої o3).
Велика модель спочатку використовує унікальний механізм довгого міркування серії O, щоб у прихованому просторі чітко розрахувати комерційну логіку, психологію аудиторії та координати верстки, а потім передає це візуальному модулю для фінального піксельного рендерингу.
Звичайно, існує й інший можливий шлях:
Під дуже точним механізмом розподілу обчислювальних ресурсів всередині OpenAI, швидкий режим може безпосередньо використовувати GPT-5 nano для базового виконання, тоді як режим міркування використовує трохи більший GPT-5 mini разом із зовнішніми інструментами.
Але яка б комбінація базових компонентів не була, якщо ви стежите за екосистемою API OpenAI, ви помітите, що її базова логіка генерації давно вже не на тому ж рівні, що й Midjourney.
ЧАСТИНА 04 Найбільш важлива ціноутворення
Але замість вгадування бази, для розробників і підприємств, які справді хочуть інтегрувати його у свій робочий процес, більш важливим є дуже реалістична та протилежна інтуїції таблиця цін на API.
Раніше DALL-E 3 стягувався за зображення (наприклад, 0,04 долара за зображення).
Але з першого покоління GPT-Image-1 OpenAI повністю перетворила його на систему оплати за токени.
GPT-Image-2 знову підтримує цей стандарт, а ще й додає більше функцій за ту саму ціну.
Згідно з офіційно опублікованою ціновою таблицею, ціна за мільйон токенів така:
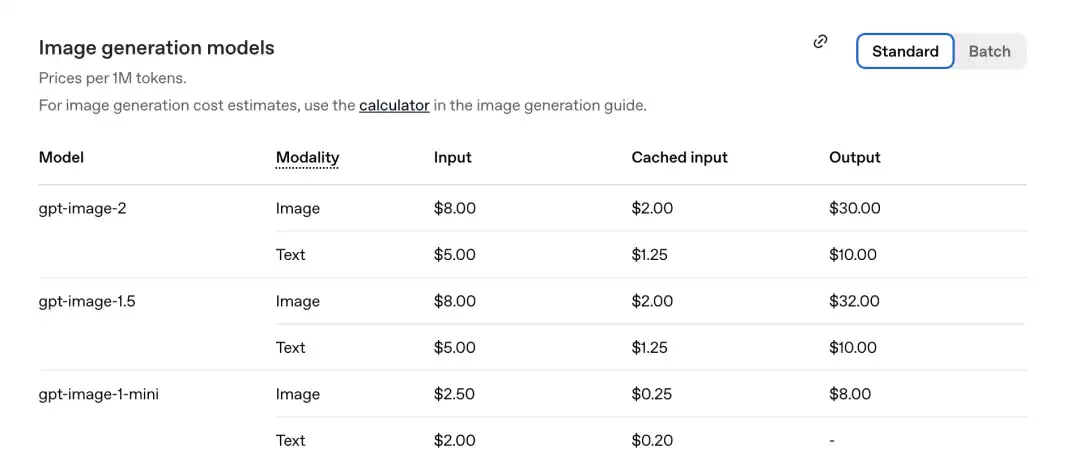
GPT-Image-2: частина зображення — вхід 8,00, кешовані вхідні дані (Cachedinputs) 2,00, вихід $30,00.
Порівняно з попереднім поколінням gpt-image-1.5: вартість становить $32.00.
Нова модель тепер дешевша.
Давайте проведем розрахунок.
У попередніх моделях для генерації якісного зображення зазвичай витрачалося від 1000 до 1500 вихідних токенів.
Розраховуючи за ціною 30 доларів США за мільйон виведених токенів, реальна вартість генерації зображення становить приблизно 0,03–0,045 долара США (близько 2–3 юанів).
Якщо вам не потрібен миттєвий відповідь, а ви використовуєте офіційний режим API Batch (пакетна обробка), ціна знову зменшиться наполовину (вивід знизиться до $15,00).
На виробництво однієї картинки виходить всього більше 10 центів.
Ціна цього одиночного аркуша вже достатньо вигідна, але його справжнім козирем є кешовані вхідні дані (Cached inputs) у таблиці цін.
Раніше, коли ви малювали комікси або робили серії плакатів, кожного разу, коли генерували нове зображення, вам потрібно було знову завантажувати велику кількість референсів персонажів, попередній контекст і довгі промпти — витрати на введення були надто високими.
Але в теперішній моделі оплати за токени, коли ви вимагаєте одночасно згенерувати 8 послідовних коміксів, візуальні елементи першого зображення безпосередньо зберігаються у кеші як контекст.
З другого зображення вартість введення зображення безпосередньо впала з $8,00 до $2,00 (тобто стягується лише 25% від суми).
Це означає, що під час масштабного комерційного виробництва зображень або при вимозі високої послідовності персонажів, його граничні витрати різко знижуються.
Чим розумніший модель і чим більше зображень вона створює, тим нижчою стає вартість на одне зображення.
Ця індустриалізована логіка оплати — справжній вбивця художників на конвеєрі.
ЧАСТИНА.05 Розкриття команди за кулисами
Нарешті, знову звернемо увагу на внутрішню візуальну мрію OpenAI, яка демонструвалася під час прямого ефіру — багато функцій, які раніше здавалися неймовірними, тепер повністю пояснюються.
Наприклад, як саме він вирішує проблеми багатомовного складного форматування та незрозумілих символів.
Це неможливо без досвідченого вченого з команди Габріеля Го.

У цьому академічному середовищі він найбільш відомий як ключовий автор інноваційної багатомодальної моделі CLIP.
CLIP заклав основу для сучасного AI, що розуміє, як людська мова та пікселі зображень пов’язані між собою.
З цим вченим у галузі міжмодального семантичного відображення на чолі, GPT-Image-2 більше не вгадує форму тексту, а справді пише на рівні пікселів.
Наприклад, як він може розуміти тривимірні просторові відношення, навіть створювати 360-градусні панорами з екстремальним співвідношенням сторін і розуміти мікроскопічне світло і тінь на зерні рису.
Це завдяки іншому ключовому члену команди Алексу Ю.

До приєднання до OpenAI він був співзасновником і колишнім CTO зіркового стартапу у сфері 3D-генерації Luma AI, а також провідним дослідником, спеціалізуючись на 3D-нейронній рендерингу (наприклад, NeRF).
З ним GPT-Image-2 фактично вийшов за межі традиційного 2D-малювання пікселями.
Ймовірно, спочатку в голові створюється тривимірна сцена, налаштовується освітлення, а потім генерується точний 2D-переріз.
Як досягнуто такої жахливої послідовності багатосторінкової коміксів.
Це відповідає молодій парі з команди, яка щойно закінчила Массачусетський технологічний інститут (MIT CSAIL):
Боюань Чень (ліворуч) і Кіхан Сонг (праворуч).
Їхні основні напрямки в академічному середовищі — це світові моделі (World Models) та ембодірована інтелігентність.
Навчити машину розуміти, як працює фізичний світ, і забезпечити, щоб персонажі залишалися незмінними та не деформувалися в різних кадрах у часі та просторі — саме це й є проблемою, яку ці два вчені намагалися вирішити.
Нарешті, додайте Нітанта Кудіге (ліворуч, ключовий автор моделей висновку серії O), який завжди працював над зв’язком великих моделей висновку з базовою логікою візуалізації, та Кенджі Хату (праворуч, колишній дослідник Google, випускник лабораторії зору Стенфорду).

Коли ця група зібралася разом, базова логічна міркування, 3D-рендеринг, ідеальне вирівнювання тексту та зображень та закони фізичного світу були природно поєднані в одній моделі.
ЧАСТИНА.06 Межі GPT-Image-2
У будь-якої моделі є межі.
Офіційно також визнано, що він все ще має труднощі при вирішенні деяких екстремальних ситуацій.
Наприклад, інструкції з складання оригамі, які вимагають точного фізичного перевертання, збирання кубика Рубіка або дуже щільні деталі, подібні до надзвичайно густого піску, все ще можуть досягати меж його можливостей.
Але в контексті комерційного застосування це вже надзвичайно мала недолік.
Для всієї індустрії дизайну нам не потрібно розповсюджувати тривогу — це зовсім не означає загибелі смаку.
Люди з смаком, бізнес-інсайтом і розумінням стратегій все ще можуть створювати чудові речі.
Але об’єктивною реальністю є те, що конкурентна перевага професії дизайнера була суттєво зруйнована.
Раніше життя залежало від того, що ти напам’ять знати комбінації клавіш дизайн-програм, вміти правильно вирівнювати шрифти по горизонталі та вертикалі, знати, як робити верстку залежно від мови, а також вміти досконало редагувати та виділяти зображення.
Але тепер це буде набагато складніше, бо ці навички, які раніше можна було відкрито купити й продати, зараз перетворилися на базові команди, які будь-хто може викликати безкоштовно одним рядком.
Після періоду бездіяльності OpenAI використала дуже спокійний, але надзвичайно потужний спосіб знову довести, хто на цій гральній карті справді тримає козирні карти.
Стара виробнича ланцюжка розпадається, і питання, що залишилося для галузі, — не чи замінять нас ШІ, а як нам адаптуватися до цієї абсолютно нової виробничої лінії.