










Джерело: CoinW Research Institute
Огляд
Gradients — це децентралізована підмережа навчання штучного інтелекту (SN56), побудована на Bittensor, яка заснована на механізмах, таких як «публікація завдань, конкуренція майнерів, перевірка та відбір», що перетворюють навчання моделей із складного технічного процесу на ринково-орієнтований мережевий процес співпраці. У архітектурі вона поєднує AutoML і розподілені обчислювальні ресурси, формуючи ринок навчання, заснований на стимулах, що не лише знижує бар’єри для використання ШІ, але й підвищує ефективність використання обчислювальних потужностей. З точки зору екосистеми та даних, Gradients вже завершила створення базової мережі, але поточні стимули та надходження коштів ще обмежені. Gradients доповнює інфраструктуру навчання в екосистемі TAO та досліджує нову парадигму «оптимізації ШІ за допомогою ринку», маючи потенціал стати важливим входом у децентралізоване навчання ШІ у довгостроковій перспективі.
1. Починаючи з Web2 AutoML: стан та обмеження навчання ШІ
1.1 Що таке AutoML
У традиційному розумінні навчання моделі ШІ — це завдання з високим порогом входу, яке вимагає від інженерів обробки даних, вибору моделі, багаторазового налаштування параметрів та оцінки ефективності — весь процес складний і витратний за часом. З’явлення AutoML (автоматизованого машинного навчання) суттєво полягає у “пакетуванні” цих складних кроків у автоматизований процес. Це можна розуміти як інструмент “автоматичного створення моделей”: користувачу потрібно лише надати дані та вказати системі бажану мету — наприклад, класифікацію, прогнозування чи розпізнавання — а всі наступні етапи, включаючи вибір моделі, налаштування параметрів, навчання та оптимізацію, виконуються системою автоматично. Це перетворило ШІ з інструменту лише для обмеженої групи професіоналів на здатність, доступну звичайним розробникам і навіть бізнесу, ставши важливим кроком на шляху до масового поширення ШІ.
1.2 Основні обмеження традиційного AutoML
Наразі основні реалізації AutoML зосереджені на платформах хмарних провайдерів, таких як Google Vertex AI та AWS SageMaker, які пропонують «AI навчання як сервіс». Хоча Web2 AutoML значно знизив бар’єри для використання AI, його базова модель все ще має очевидні обмеження. По-перше, це централизованість: обчислювальні ресурси, ціни та правила повністю контролюються платформами, що призводить до сильного залежності користувачів від одного постачальника та відсутності здатності до переговорів. По-друге, витрати високі та нечіткі: ресурси GPU, необхідні для навчання AI, зосереджені в руках хмарних провайдерів, а механізм ціноутворення не піддається ринковій конкуренції. Ще важливіше — існує межа ефективності оптимізації. Традиційний AutoML за суттю залишається «однією системою, яка допомагає знайти оптимальний розв’язок»; незалежно від того, наскільки складною є ця система, вона все одно є оптимізацією лише однієї технологічної траєкторії. Її простір для досліджень обмежений, і вона важко може одночасно експериментувати з кількома абсолютно різними підходами. Тому сучасне Web2 AI-навчання є «закритою системою», де навчання, оптимізація та розподіл ресурсів моделей відбуваються в середовищі, повністю контролюваному однією платформою. Хоча такий підхід ефективний, з ростом попиту його межі поступово стають очевидними.
2. Градієнти: відновлення навчання ШІ за допомогою «мережі»
2.1 Gradients — це децентралізована платформа AutoML
У попередньому розділі ми згадували, що основна проблема традиційного Web2 AutoML полягає у «закритій системі»: навчання моделей залежить від платформи, шляхи оптимізації обмежені, а ресурси не можуть вільно рухатися. Gradients є перебудовою цієї моделі. Gradients виникли з децентралізованої спільноти інженерів, започаткованої WanderingWeights, і побудовані на мережі Bittensor як підмережа AI-навчання, що працює на Subnet 56. На відміну від традиційних платформ, вони не надають централізованих послуг, а замість цього розбивають процес навчання і передають його на виконання відкритій мережі. Користувачу достатньо визначити мету завдання — наприклад, тип моделі та дані — а всі інші процеси, включаючи виконання навчання, оптимізацію параметрів та відбір результатів, автоматично виконуються мережею. У такому підході AI-навчання перетворюється з складного інженерного процесу на просту операцію «поставити запит — отримати результат», стаючи більш схожим на універсальну здатність, ніж на технічну роботу з високим порогом входу.
2.2 Від закритої системи до відкритої співпраці: Що розв’язує Gradients
Суть змін у Gradients полягає у перетворенні раніше замкненого на одній платформі процесу навчання на відкритий, спільний мережевий процес. Завдання навчання більше не виконуються однією системою, а розподіляються між кількома учасниками для паралельного виконання, після чого найкращі результати відбираються за допомогою єдиної механізму оцінки. Така структура спочатку зменшує залежність від централізованих сервісів, забезпечуючи навчання на основі розподілених обчислювальних потужностей; одночасно розподілені ресурси GPU інтегруються в одну мережу, формуючи більш ринковий підхід до розподілу ресурсів у процесі конкуренції. Ще важливіше те, що оптимізація моделей більше не обмежується однією траєкторією, а постійно наближається до кращих розв’язків шляхом паралельного дослідження кількох методів, що підвищує загальний потенціал оптимізації.
2.3 Суттєва зміна: від інструменту до «ринку навчання»
У традиційному AutoML платформа більше схожа на інструмент, який за допомогою внутрішніх алгоритмів допомагає користувачам знаходити оптимальні рішення. У Gradients цей процес більше нагадує постійно функціонуючий «ринок»: користувачі публікують запити, різні учасники конкурують за одну й ту ж задачу і через механізм оцінки відбирають найкращі результати. Таким чином, продуктивність моделей більше не залежить від здатності однієї системи, а походить із постійної конкуренції та ітерацій, що виникають у результаті участі багатьох. AutoML перетворюється з відносно закритої технічної задачі оптимізації на динамічний процес, спрямований на стимули, що дозволяє збільшувати здатність до оптимізації разом із зростанням кількості учасників. Ця зміна робить навчання ШІ схожим на саморозвиваючийся ринковий механізм.
2.4 Роль у екосистемі TAO: інфраструктура для навчання ШІ
У підмережевій архітектурі Bittensor різні підмережі виконують різні функції, такі як висновок, обробка даних та навчання, а Gradients розташований на рівні навчання. Він відповідає за перетворення розподілених обчислювальних потужностей на реальні вихідні моделі та за допомогою механізмів розподілу завдань та оцінки забезпечує постійне планування та оптимізацію цих ресурсів. Крім того, він з’єднує пропозицію обчислювальних потужностей із потребою в моделях, перетворюючи навчання з простого процесу споживання ресурсів у організований та оптимізований процес мережевої взаємодії. У цій архітектурі Gradients діє як центральний ланцюг, перетворюючи розподілені ресурси на придатну штучну інтелектуальну здатність та підтримуючи розвиток застосунків верхнього рівня.
3. Основна архітектура: як відбувається навчання ШІ в мережі
У попередньому розділі ми згадували, що Gradients перетворює навчання ШІ з «виконання всередині платформи» на «виконання за допомогою мережевої співпраці». Як саме працює ця мережа? Основна ідея цього розділу — розкласти цей процес на більш наочні складові.
3.1 Розподілене навчання: як одне завдання виконується «кількома людьми»
Можна уявити Gradients як постійно працюючу «мережу співпраці з навчання». Після того як користувач надсилає завдання на навчання, воно не передається одній системі для виконання, а одночасно розподіляється між кількома учасниками мережі. Ці учасники, використовуючи одні й ті ж дані та цілі, намагаються застосувати різні методи навчання та протягом встановленого терміну надсилають результати. Потім система оцінює всі ці результати та вибирає найкращий варіант. У кінцевому підсумку, найкращі результати отримують винагороду, а інші варіанти відкидаються. З точки зору користувача, цей процес вимагає лише одного запуску завдання — і він еквівалентний одночасному «виклику» кількох різних підходів до оптимізації з автоматичним вибором найкращого розв’язку. Ключова ідея цього підходу — не в тому, наскільки потужний окремий вузол, а в тому, що шляхом паралельного тестування багатьма учасниками та автоматичного відбору результати поступово наближаються до оптимального розв’язку.
У цій мережі є три основні учасники: користувачі, майни та верифікатори. Користувачі висувають вимоги до навчання; майни надають обчислювальну потужність і пробують різні методи навчання; верифікатори оцінюють результати та відбирають найкращі моделі. Таке розподілення обов’язків дозволяє неперервно проводити навчання та постійно відбирати кращі рішення. У цілому це формує спільну мережу, що працює за принципом «попит, пропозиція, оцінка».
3.2 Автоматизоване машинне навчання, спрямоване на ринок
Як видно з розбору механізму в попередньому розділі, Gradients не просто переносить AutoML на ланцюг, а змінює фундаментальну логіку оптимізації моделей завдяки введенню багатоучасникової взаємодії та стимулів. У традиційному AutoML оптимальний розв’язок шукається однією системою в межах обмеженого набору шляхів, тоді як у Gradients цей процес розширено на всю мережу: різні учасники постійно намагаються різними методами вирішити одну й ту ж задачу, а потім за допомогою єдиної системи оцінки постійно фільтрують та ітерують результати. Це робить оптимізацію моделей не разовою обчислювальною операцією, а динамічним процесом, що може постійно розвиватися. У цьому механізмі кращі результати отримують більший дохід, що постійно привертає учасників до вдосконалення своїх стратегій і підвищує загальну ефективність.
4. Механізми стимулювання та конкуренції: як навчання ШІ формує «позитивний цикл»
4.1 Механізм стимулювання (на основі TAO): від тренування до отримання прибутку
Ключем до тривалої роботи Gradients є механізм стимулювання, який ґрунтується на нативній системі стимулів Bittensor. У цьому контексті TAO є нативною токеном мережі Bittensor і виступає «носієм цінності» у всій мережі: з одного боку, він використовується для нагородження учасників, які надають обчислювальну потужність і вносять внесок у моделі, а з іншого — через стейкінг та інші механізми бере участь у розподілі ваги підмереж, впливаючи на те, як ресурси рухаються між різними підмережами.
Головна мережа Bittensor постійно генерує нові винагороди Emission у вигляді TAO (наразі щодня приблизно 3600 TAO), які розподіляються між різними підмережами за певними правилами. Кількість TAO, що дістається кожній підмережі, залежить від її «продуктивності» в усьому мережі — наприклад, рівня активності, якості внеску та рівня фінансової підтримки. Для підмережі, в якій знаходиться Gradients, ця частина TAO знову розподіляється між учасниками. Основним критерієм розподілу є якість внесених моделей: чим краща модель, тим більше винагороди отримує її автор.
Зокрема, майни відправляють результати навчання, а верифікатори відповідають за тестування та оцінку цих результатів. Система розраховує «вагу внеску» кожного учасника на основі оцінок, а потім розподіляє нагороди відповідно до цієї ваги. Моделі з кращими показниками (наприклад, з більшою узагальнюючою здатністю та стабільнішим результатом) отримують більший дохід, а верифікатори, чиї оцінки точніші та краще відображають справжню якість, також отримують більше стимулів. Такий підхід забезпечує пряму залежність між «кращим виконанням» і «більшим дохodom», що стимулює учасників постійно покращувати моделі.
4.2 Конкуренція між підмережами: не лише внутрішня конкуренція, але й зовнішній рейтинг
Крім внутрішньої конкуренції в підмережі, Gradients стикається з «горизонтальною конкуренцією» в усьому мережі Bittensor. Оскільки розподіл TAO є динамічним, різні підмережі борються за більш високі ваги. Лише ті підмережі, які постійно генерують якісні результати та привертають більше учасників, отримують більшу частку нагород. Отже, стимули для Gradients залежать не лише від внутрішньої продуктивності моделей, а й від їхньої відносної конкурентоспроможності в усьому екосистемі. Вся система утворює багаторівневий цикл: всередині підмережі відбувається конкуренція між моделями; між підмережами — конкуренція за загальну продуктивність. У підсумку інвестиції у обчислювальну потужність, ефективність моделей та економічний дохід пов’язані між собою, утворюючи сталу позитивну зворотній зв’язок.
4.3 Градієнти 5.0: від конкуренції до «турнірного механізму»
На основі ранніх постійних змагань Gradients еволюціонував у більш структурований механізм, відомий як «турнірне навчання». Його можна розуміти як періодичний турнір: кожен цикл навчання має визначений часовий вікно, у якому кілька учасників змагаються за одну задачу, а через кілька етапів відбору поступово виключаються, поки не залишиться найкраще рішення. Такий підхід акцентує увагу на поетапному порівнянні та зосередженій оцінці. Важливою зміною є те, що майни вже не надсилають результати навчання напряму, а замість цього надсилають «методи навчання» (код), які потім одноразово виконуються вузлами перевірки. Це підвищує справедливість, виключаючи вплив різних обчислювальних середовищ, а також краще захищає конфіденційність даних та процесу навчання. Крім того, переможні рішення часто зберігаються як повторно використовувані методи, подібно до поступового накопичення «найкращих практик». У довгостроковій перспективі цей механізм не лише відбирає найкращі моделі, а й формує постійно еволюціонуючу бібліотеку методів навчання.
5. Стан екосистеми
5.1 Структура учасників: спільна мережа, що складається з попиту, пропозиції та оцінки
Екосистема Gradients складається з трьох основних ролей: користувачів (попит), майнерів (пропозиція) та верифікаторів (оцінка). Користувачі в основному — це розробники ШІ, малі та середні підприємства та Web3-розробники, які, як правило, мають певну технічну підготовку, але не мають необхідної обчислювальної потужності чи повної здатності до навчання моделей, тому вони зазвичай використовують Gradients для створення моделей з меншими витратами. Майнери надають GPU-обчислювальну потужність та борються за участь у завданнях навчання, їхнім основним мотивом є отримання прибутку у TAO. Верифікатори відповідають за оцінку та ранжування результатів навчання, що є ключовим елементом для забезпечення якості моделей та ефективного функціонування механізму.
З урахуванням більш детального профілю користувачів, реальна аудиторія Gradients має виражений «напіврозробницький» характер: вона відрізняється від топових лабораторій з ШІ та від повністю нетехнічних звичайних користувачів, а зосереджена переважно на розробниках з певними інженерними навичками та користувачах Web3. Це також відображається в структурі спільноти: наразі екосистема переважно англомовна, основні користувачі розташовані в Північній Америці та Європі серед розробників, а також охоплюють частину східноазіатських шахтарів та глобальних постачальників GPU. У цілому це близько до технічно орієнтованої спільноти розробників.
5.2 Поточний стан екосистеми
На 12 травня ціна альфа-токена Gradients становила близько 0,0255 TAO, кількість адрес з токенами — приблизно 4 890, майнерів — 243, валідаторів — 12, частка Emission — 1,61%. Разом із цим, у ліквіднісному пулі частка TAO становить 2,19%, а Alpha — 97,81%. З точки зору ціни та кількості адрес, Gradients вже має певну базу користувачів та увагу, але загалом перебуває на ранній стадії поширення. У порівнянні з лідером екосистеми TAO — Chutes, ціна альфа-токена на той же день становила 0,0877 TAO, а кількість адрес з токенами — 13 409.
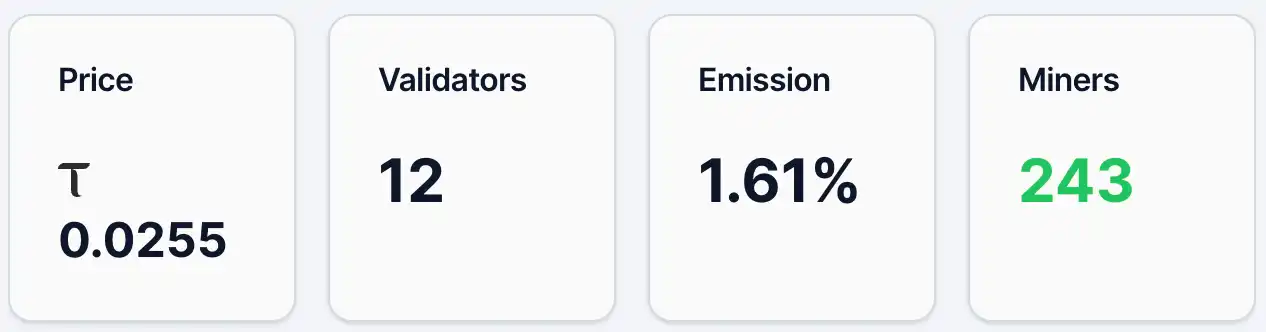
Рисунок 1. Дані градієнтів.
Джерело:https://bittensormarketcap.com/subnets/56
Далі — механізм емісії. У системі Bittensor емісія — це поточна вага розподілу нових нагород, що створюються в мережі, між підмережами. Мережа Bittensor безперервно генерує нові TAO та розподіляє їх між підмережами згідно з вагами. Поточний показник 1,61% для Gradients означає, що він отримує лише невелику частину загальних нових нагород мережі. Цей показник відображає «результат голосування» ринку через потоки коштів (наприклад, стейкінг) між різними підмережами. Тому рівень 1,61% зазвичай свідчить про обмежену поточну ринкову підтримку та обмежений приплив коштів, але одночасно вказує на потенціал зростання ваги у майбутньому. З точки зору структури капіталу (ліквідність), частка TAO становить лише 2,19%, тоді як Alpha досягає 97,81%, що свідчить про обмежений приплив зовнішніх коштів і переважно внутрішнє пропонування підмережі. Ціна чутлива до додаткових коштів — якщо надійде більше TAO, це може спричинити значний ефект підсилення.
6. Конкурентна ситуація та переваги/недоліки
6.1 Позиціонування галузі: інфраструктура для навчання децентралізованого AutoML
Gradients працює в сегменті «інфраструктура для навчання ШІ + децентралізований AutoML». Він намагається звільнити навчання моделей від централізованих платформ і забезпечити більш ефективне використання ресурсів та оптимізацію моделей за допомогою мережевих механізмів. У системі Web2 цей сегмент вже відносно зрілий, до типових представників належать Google Vertex AI та AWS SageMaker. Ці платформи надають розробникам послуги з однокрокового навчання та розгортання моделей за допомогою хмарних обчислень, але їхня суть залишається централізованою архітектурою. У порівнянні з цим, відмінність Gradients полягає не у «більшій кількості функцій», а у іншій основній логіці: він перетворює навчання з «послуги платформи» на «мережеву співпрацю» і за допомогою механізму конкуренції відбирає найкращі результати, наближаючи його до ринково функціонуючої системи навчання.
6.2 Порівняння: Відмінності між Web2 та Web3 AutoML
З більш широкого погляду, різниця між Web2 та Web3 у напрямку AutoML є суттєвою порівнянням двох різних парадигм. Модель Web2 зосереджена на ефективності та стабільності, надаючи контролювану та досконалу досвід послуг завдяки централізованому розподілу ресурсів та інженерній оптимізації; натомість модель Web3 зосереджена на відкритості та механізмах стимулювання, дозволяючи оптимізації моделей постійно розвиватися через участь багатьох сторін у конкуренції. Зокрема, Web2 AutoML схожий на «потужний інструмент», де користувач передає завдання платформі, а система самостійно знаходить оптимальний розв’язок; натомість Web3 AutoML, представлений Gradients, схожий на «відкритий ринок», де користувачі публікують вимоги, а різні учасники пропонують розв’язки, які потім відбираються за допомогою механізму оцінки. Пряме наслідок цієї різниці полягає в тому, що перший підхід більш стабільний та контролюваний, але має обмежені шляхи оптимізації; другий підхід має більший потенціал для досліджень та вищий потенційний ліміт, але все ще потребує покращень у стабільності та зрілості.
6.3 Відмінності Gradients у Web3
У поточному секторі Web3 AI більшість проектів зосереджені на рівні висновків або AI Agent, тоді як проектів, що спеціалізуються на «інфраструктурі навчання», відносно мало. Деякі проекти намагаються поєднати мережі обчислювальних потужностей або мережі даних для надання можливостей навчання, але загалом більшість з них залишаються на рівні планування ресурсів або ринку обчислювальних потужностей. Відмінність Gradients полягає в тому, що вона не обмежується лише зіставленням обчислювальних потужностей, а йде далі — до самого «механізму оптимізації моделей», впроваджуючи системи оцінки та конкуренції, що надають навчальному процесу здатність до постійного розвитку. Це означає, що вона не лише вирішує питання «звідки взяти обчислювальні потужності», а й «як ефективніше використовувати ці потужності». За своєю суттю Gradients ближча до мережі, спрямованої на результат навчання, ніж до простого ринку обчислювальних потужностей чи інструментальної платформи — саме це є ключовою відмінністю від більшості проектів Web3 AI.
6.4 Ключові переваги: підвищення ефективності завдяки механізмам
Загалом, переваги Gradients головним чином полягають у їхньому механізмі дизайну. По-перше, він знижує бар’єри для входу завдяки абстрагуванню завдань, дозволяючи користувачам отримувати результати моделей, не беручи активної участи у складних процесах навчання, що розширює потенційну аудиторію. По-друге, щодо ресурсів, впровадження розподілених обчислювальних потужностей робить навчання незалежним від одного хмарного провайдера, теоретично дозволяючи формувати більш гнучку структуру витрат завдяки конкуренції. Ще важливіше — зміна підходу до оптимізації. Шляхом паралельного дослідження багатьма учасниками та поєднання з механізмом відбору, Gradients пропонує альтернативу традиційній однопотоковій оптимізації, надаючи моделям можливість досягти кращої продуктивності за коротший час. Цей підхід «оптимізація, спричинена конкуренцією», є найважливішою перевагою.
6.5 Потенційні виклики
Якість моделі може мати проблеми зі стабільністю. Децентралізоване навчання залежить від участі багатьох сторін, що, хоча й може підвищити потенціал, також може призводити до коливань результатів; порівняно з централізованими системами, воно має певну невизначеність щодо контролю. Другим питанням є проблема корпоративної довіри. Для корпоративних користувачів безпека даних і перевіряємість процесу навчання є критично важливими, а в децентралізованому середовищі забезпечення того, щоб дані не використовувалися зловживанням, а результати були аудитовані, залишається ключовим викликом. Нарешті, існує залежність від токеноміки. Функціонування Gradients сильно залежить від механізмів стимулювання; якщо прибутковість TAO зменшиться, це може вплинути на участь майнерів і загальну активність мережі. Тому його довгострокова сталість частково залежить від того, чи зможе економічна модель сформувати стабільний позитивний цикл.
7. Майбутнє: чи можливе існування децентралізованого AutoML?
На поточному етапі Gradients все ще знаходиться на початковій стадії, і чи зможе він реально вдалося реалізувати, залежить від кількох ключових факторів. Найважливішим є здатність постійно привертати справжні потреби у навчанні, а не лише участь, спонукану стимулами; далі — якість моделей: чи зможе децентралізований підхід стабільно генерувати придатні, а можливо, навіть кращі результати; а також чи зможе економічна механіка сформувати позитивний цикл, забезпечуючи тривалий баланс між постачанням обчислювальних потужностей і доходами.
У більшому контексті галузі навчання ШІ розділилося на два шляхи. Один — це модель Web2, що домінується провідними технологічними компаніями, які за допомогою концентрації ресурсів та інженерних можливостей постійно підвищують продуктивність моделей — їхня перевага полягає у стабільності та зрілості. Інший — це Web3-шлях, представлений Gradients, який за допомогою відкритої мережі та механізмів стимулювання дозволяє більшій кількості учасників спільно брати участь у оптимізації моделей, постійно піднімаючи межі в умовах конкуренції. Перший підходить до «створення потужніших систем», тоді як другий схожий на «будівництво мережі, що сама себе розвиває».
З цієї точки зору дослідження Gradients відкривають нову можливість: навчання ШІ більше не є лише технічною проблемою, а поєднанням «обчислювальних потужностей + даних + ринкових механізмів». Якщо ця модель виявиться працездатною, вона має потенціал стати вхідним пунктом для децентралізованого навчання ШІ та відіграти ключову роль інфраструктури в екосистемі Bittensor. Звичайно, цей напрямок потребує часу для перевірки, але він вже пропонує AutoML альтернативний шлях розвитку, відмінний від традиційного.
Джерело
1. Документація Bittensor:https://docs.learnbittensor.org
2. Веб-сайт Gradients:https://www.gradients.io/
3. Градієнти:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart