









Автор: Літера AI
Google справді панікує.
Лише що з’явилася інформація, що співзасновник Google Сергій Брин відновив «режим засновника», особисто керує процесом та створює елітну «штурмову групу» для того, щоб усунути розрив у ключових здібностях Gemini, таких як AI-програмування та автономні агенти, у порівнянні з такими суперниками, як Anthropic.
Незабаром після цього Google оголосив велике оновлення вночі, запустивши два нові автономні дослідницькі агенти, побудовані на основі моделі Gemini 3.1 Pro: Deep Research та Deep Research Max.
Не лише підсилюючи міркувальні здібності в основі моделі, але й активно розвиваючи автономні інтелектуальні агенти у напрямку підприємств та платформ для розробників, через відкриття API, підтримку приватних даних, асинхронні завдання у фоновому режимі та інші засоби, намагаючись зайняти лідируючі позиції у високодоходній сфері «AI-досліджень/аналітичних інструментів» та протистояти конкуренції з боку таких суперників, як OpenAI (Hermes) та Perplexity.

Ці два агенти вперше дозволяють розробникам за допомогою одного виклику API поєднувати дані відкритої мережі з власною корпоративною інформацією, нативно генерувати діаграми та інфографіки у звітах, а також підключати будь-які сторонні джерела даних за допомогою Model Context Protocol (MCP).
Дві агенти з 1 січня доступні у вигляді публічного попереднього огляду через платні тарифи Gemini API і можуть бути використані через Interactions API, вперше запущений Google у грудні 2025 року.
Так, ці нові агенти наразі доступні лише через API, звичайні користувачі не можуть скористатися ними в додатку Gemini, навіть якщо вони мають платну підписку. Деякі користувачі, побачивши оновлення, але не зможучи його використати, висловили розчарування: «Google якимось чином продовжує покарувати нас, підписників Pro у додатку Gemini…»

Генеральний директор Google Сундар Пічай також особисто зауважив у X: «Коли вам потрібна швидкість та ефективність, використовуйте Deep Research; коли ви прагнете до найвищої якості збирання та синтезу контексту, використовуйте версію Max — вона досягла результатів 93,3% у DeepSearchQA та 54,6% у HLE завдяки збільшенню обчислень під час тестування».
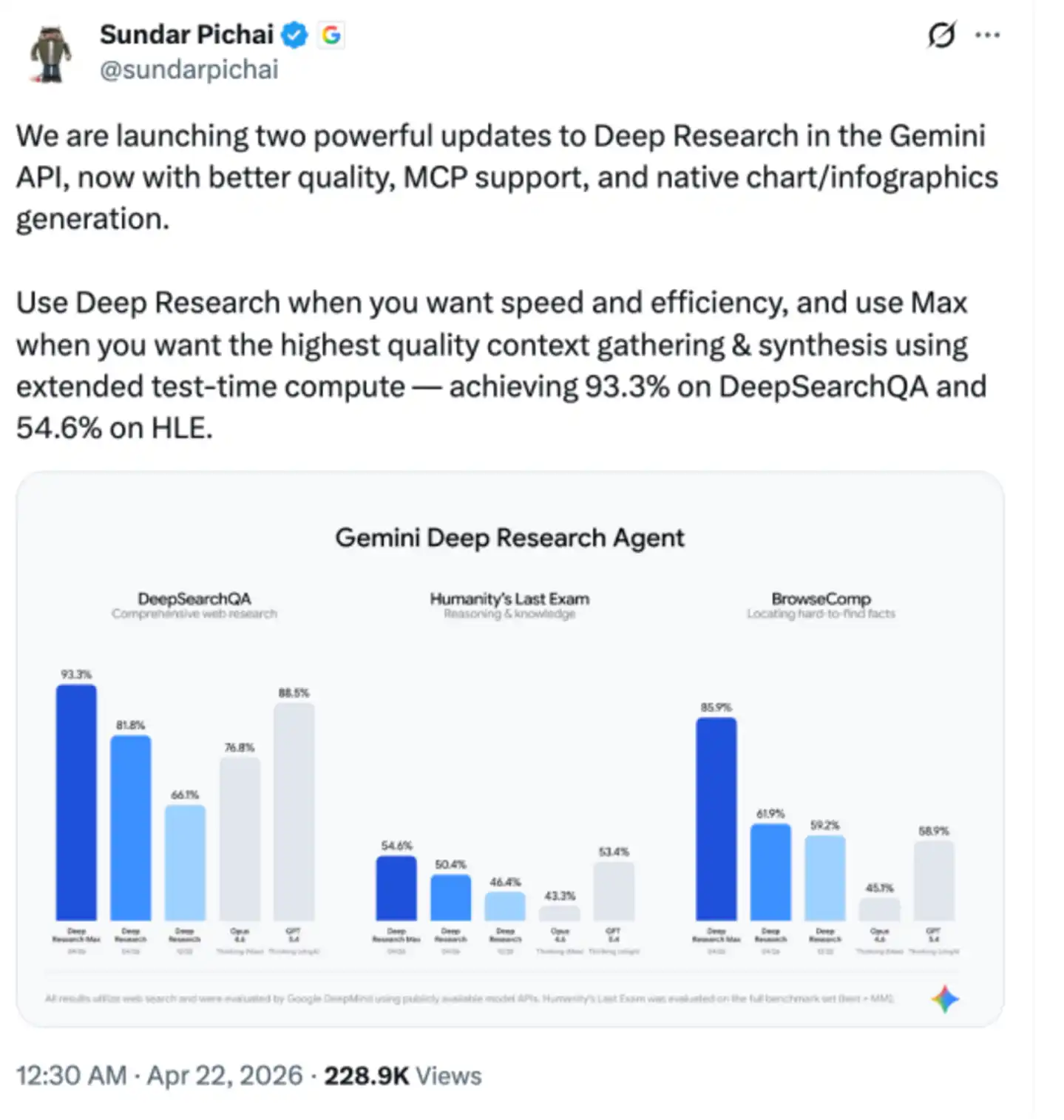
18 місяців тому метою Google Deep Research було допомогти аспірантам уникнути затоплення великою кількістю вкладок браузера. Зараз Google сподівається, що він зможе замінити базові дослідницькі завдання молодших аналітиків інвестиційних банків.
Різниця між цими двома цілями — а також чи зможе ця технологія справді заповнити цю різницю — вирішить, чи стануть автономні дослідницькі агенти справді трансформаційним продуктом у сфері корпоративного програмного забезпечення, чи просто ще одним шикарним, але розчаровуючим на конференціях демонстраційним штучним інтелектом.
Дві версії, оптимізовані під різні навантаження
Стандартна версія Deep Research має меншу затримку та нижчі витрати, що робить її ідеальною для сценаріїв, де важлива швидкість.
Deep Research Max пріоритезує глибину, а не швидкість. Цей агент проводить глибоке міркування, пошук та ітерації за допомогою розширеного обчислення під час тестування (extended test-time compute), щоб у кінцевому підсумку створити звіт.
Google вказує, що асинхронні фонові робочі процеси є ідеальним сценарієм використання, наприклад, запуск через планувальник завдань (cron job) у нічний час, щоб наступного ранку надати команді аналітиків повний звіт з ділової перевірки.
У власних тестах Google, Deep Research Max досяг значного прогресу в завданнях пошуку та міркування. Цей агент може отримувати інформацію з більшої кількості джерел, ніж попередні версії, і виявляти нюанси, які попередні моделі часто не помічали.
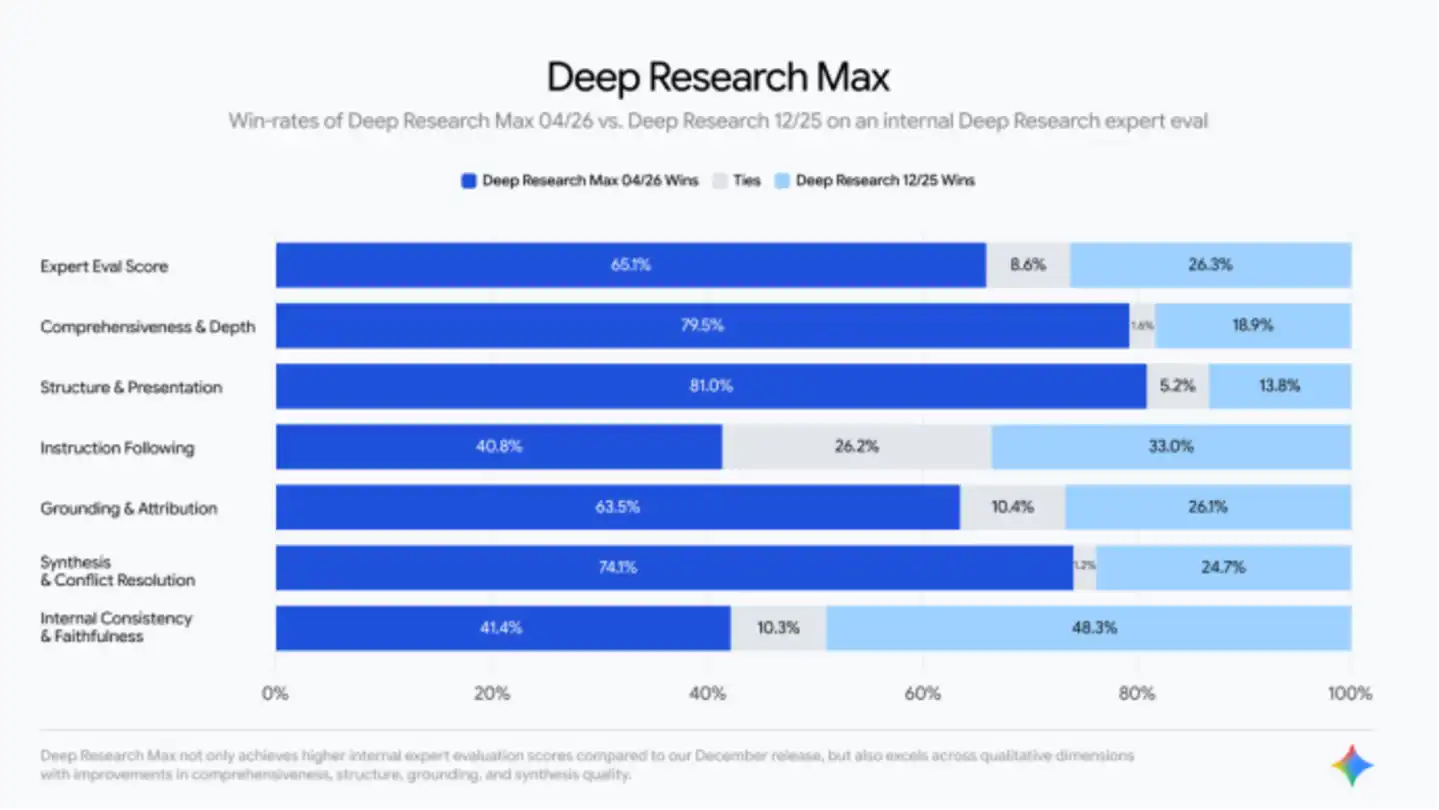
Google також надав порівняння з конкурентами.
Проте порівнювати це з OpenAI GPT-5.4 та Anthropic Opus 4.6 не зовсім справедливо. GPT-5.4 добре впорався з автономним веб-пошуком, але не був спеціально оптимізований для глибоких досліджень. Для цього OpenAI надала власний DR-агент, який після оновлення у лютому перейшов на GPT-5.2, а не на GPT-5.4. Найпотужнішою пошуковою моделлю OpenAI насправді є GPT-5.4 Pro, але Google, очевидно, не включив її до порівняння.
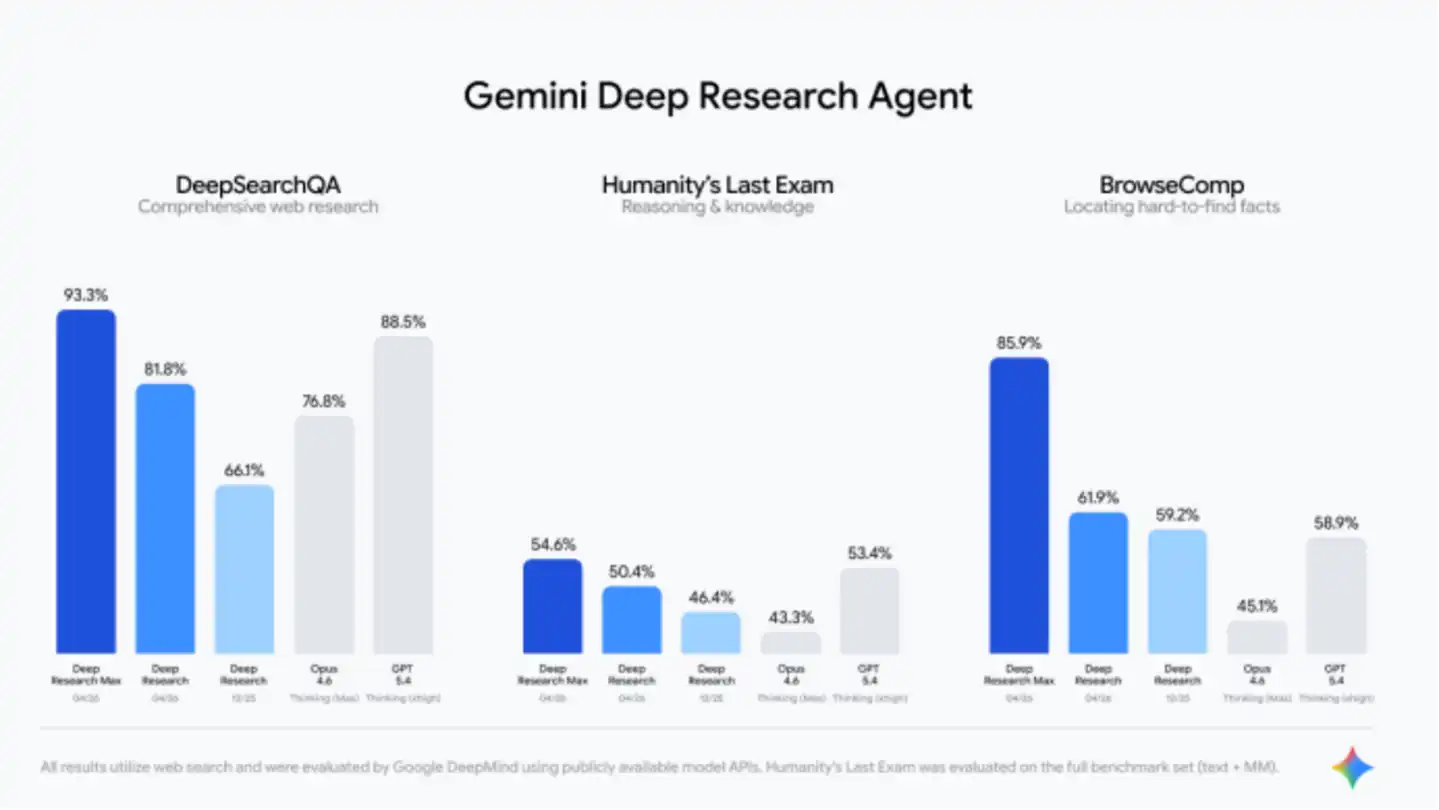
За даними OpenAI, GPT-5.4 Pro показав найвищий результат 89,3% у тесті на пошук агентів BrowseComp, тоді як GPT-5.4 набрав 82,7%.
Згідно з власним звітом Anthropic, Opus 4.6 показав результат 84% у BrowseComp, що вище за значення, продемонстроване Google. Цей результат було отримано при вимкненій функції міркувань, при цьому модель продемонструвала кращу продуктивність, ніж Google у своїх інтенсивних тестах на API.
Ці розбіжності, ймовірно, пояснюються різними методами тестування — чи оцінювалася модель через оригінальний API, чи була вона обгорнута в інструменти кожного лабораторії окремо. Дані Google не обов’язково помилкові, але їх варто інтерпретувати обережно. Будь-яким чином, їхнє представлення не забезпечує достатньої прозорості.
Підтримка MCP
Найбільш впливовою функцією цього випуску, ймовірно, є додавання підтримки Model Context Protocol (MCP). Ця функція перетворює Deep Research з потужного інструменту веб-досліджень у сутність, більш схожу на «універсального аналітика даних».
MCP — це нова відкрита стандартна система для підключення моделей ШІ до зовнішніх джерел даних. Вона дозволяє Deep Research безпечно запитувати приватні бази даних, внутрішні архіви документів та професійні сторонні сервіси даних — усі ці операції проводяться без виходу чутливих даних за межі їх початкового середовища.
У практичному застосуванні це означає, що хедж-фонд може одночасно спрямувати Deep Research до своєї внутрішньої бази даних торгівельних потоків та фінансових терміналів, а потім вимагати, щоб агент поєднав обидва джерела з публічною інформацією з мережі, щоб синтезувати глибокі висновки.
Google розкриває, що активно співпрацює з FactSet, S&P та PitchBook для розробки свого MCP-сервера, що чітко свідчить про те, що Google прагне до глибокої інтеграції з постачальниками даних, на які щоденно опираються Уолл-стріт та ширший фінансовий сектор.
Згідно з блогом, написаним продукт-менеджерами Google DeepMind Лукасом Хассом і Срінівасом Тадепаллі, їхня мета — «дозволити спільним клієнтам інтегрувати фінансові дані в робочі процеси, що базуються на Deep Research, і досягти стрибка в продуктивності завдяки швидкому збиранню контексту зі своєї величезної всесвітньої мережі даних».
Ця функція безпосередньо вирішує одну з найбільш стійких проблем при впровадженні ШІ компаніями: величезна різниця між інформацією, доступною відкритому інтернеті, і інформацією, необхідною для реальних рішень організації. Раніше для заповнення цієї прогалини потрібно було виконувати великий обсяг індивідуальної інженерної роботи.
MCP підтримує поєднання автономного перегляду та міркувань Deep Research, спрощуючи більшість складностей до одноразової конфігурації. Розробники тепер можуть дозволити Deep Research використовувати одночасно пошук Google, віддалені сервери MCP, контекст URL, виконання коду та пошук файлів — або повністю вимкнути доступ до мережі та проводити пошук лише на користувальницьких даних.
Система також підтримує мультимодальні вхідні дані, включаючи PDF, CSV, зображення, аудіо та відео, як grounding (контекст grounding).
Нативні графіки
Другою ключовою функцією є нативне створення графіків та інфографік.
Попередня версія Deep Research могла генерувати лише текстові звіти. Якщо користувачеві потрібна візуалізація, він мусив експортувати дані та створювати графіки самостійно. Цей недолік значно послаблював позицію «енд-ту-енд автоматизації».
Зараз нове покоління агентів може нативно вбудовувати якісні діаграми та інфографіки у звіти, динамічно відображаючи складні набори даних у форматі HTML або Google Nano Banana, щоб вони безпосередньо ставали частиною аналітичного розповіді.
Для корпоративних користувачів — зокрема тих, хто працює у фінансовій та консалтинговій галузях і має потребу у створенні результатів, які можна безпосередньо передавати зацікавленим сторонам, — ця функція перетворює Deep Research з інструменту, що прискорює етап дослідження, на інструмент, здатний генерувати аналітичні продукти, близькі до фінального варіанту.
Крім того, нова система, поєднуючи додану функцію спільного планування (яка дозволяє користувачам перевіряти, керувати та оптимізувати дослідницькі плани агентів до виконання) та потокову передачу проміжних кроків міркувань у реальному часі, дає розробникам можливість точного контролю над діапазоном дослідження, зберігаючи при цьому високий рівень прозорості, вимаганий регулюючими органами.
Deep Research стає частиною інфраструктури, яку Google надає компаніям
Офіційний блог Google чітко зазначає, що розробники, використовуючи агента Deep Research для створення, звертаються до тієї самої автономної інфраструктури досліджень, яка забезпечує дослідницькі можливості для багатьох популярних продуктів Google, таких як Gemini App, NotebookLM, Google Search і Google Finance. Це свідчить про те, що агент, наданий через API, не є спрощеною версією внутрішньої системи Google, а є тією самою системою, яка надається на платформовому рівні.
Цей еволюційний процес розвивається надзвичайно швидко.
Google вперше запровадив Deep Research у додатку Gemini у грудні 2024 року як функцію для кінцевих користувачів, яка працювала за допомогою Gemini 1.5 Pro. Google описав його як персонального AI-допоміжника для досліджень, який може за кілька хвилин агрегувати інформацію з мережі, щоб допомогти користувачам зекономити кілька годин роботи.
У березні 2025 року Google оновив Deep Research за допомогою Gemini 2.0 Flash Thinking Experimental і відкрив його для всіх у режимі тестування. Пізніше він був оновлений до Gemini 2.5 Pro Experimental, і Google повідомив, що експерти віддають перевагу його звітам у співвідношенні 2:1 порівняно з конкурентами.
Грудень 2025 року став важливим переломним моментом: Google запровадив Interactions API, що вперше дозволив програмно отримувати доступ до Deep Research, який працює на основі Gemini 3 Pro, і одночасно опублікував відкритий базис DeepSearchQA.
Основною моделлю, що лежить в основі цих покращень, є Gemini 3.1 Pro, яка була випущена 19 лютого 2026 року. Вона досягла значного стрибка в основних здібностях міркування: у тесті ARC-AGI-2, що оцінює здатність моделі вирішувати нові логічні шаблони, Gemini 3.1 Pro набрала 77,1%, що більше ніж у два рази вище, ніж у Gemini 3 Pro.