









Автор: Shenchao TechFlow
Стаття від Google, яка стверджує, що «зменшила використання пам’яті AI до 1/6», на тиждень спричинила втрату ринкової капіталізації понад 90 мільярдів доларів США для глобальних акцій чипів пам’яті, таких як Micron і SanDisk.
Однак лише через два дні після публікації статті докторант Політехнічного інституту Цюриха Гао Цзяньян опублікував відкритий лист обсягом у десять тисяч слів, звинувачуючи команду Google у тому, що вони тестували суперника за допомогою Python-скрипта на одному ядрі CPU, а себе — на GPU A100, і відмовилися виправити це, навіть після того, як їм уже повідомили про проблему до подання статті. Читання на Zhihu швидко перевищило 4 мільйони, офіційний аккаунт Stanford NLP репостив пост, і академічна спільнота та ринок одночасно здригнулися.
(Для довідки: стаття, яка вплинула на ціни на зберігання акцій)
Суть цієї суперечки не складна: чи систематично викривила стаття з найбільшого AI-конференції, яку офіційно активно просував Google і яка безпосередньо викликала панічну продажу акцій чіпів у всьому світі, вже опубліковану попередню роботу та шляхом навмисно створених несправедливих експериментів сформувала хибний нарратив про переваги в продуктивності?
TurboQuant зробив: зменшив «чернетку» ШІ до шостої частини оригіналу
Під час генерації відповідей велика мовна модель повинна писати, одночасно повертаючись і перевіряючи попередні обчислення. Ці проміжні результати тимчасово зберігаються у відеопам’яті, і в галузі їх називають «KV Cache» (кеш ключ-значення). Чим довша діалог, тим товщою стає ця «чернетка», тим більше відеопам’яті витрачається, і тим вищими стають витрати.
Алгоритм TurboQuant, розроблений дослідницькою командою Google, головною перевагою якого є стиснення цього чернетки до 1/6 від початкового розміру при одночасному заявленні відсутності втрат точності та прискорення виведення до 8 разів. Стаття була вперше опублікована 2025 року в квітні на академічній платформі передруків arXiv, у січні 2026 року прийнята на найвищому конференційному форумі з штучного інтелекту ICLR 2026 та 24 березня повторно презентована через офіційний блог Google.
З технічної точки зору, підхід TurboQuant можна спростити так: спочатку за допомогою математичного перетворення сирі дані «підготувуються» до єдиного формату, потім вони стискаються за допомогою заздалегідь обчислених оптимальних таблиць стиснення, а на останньому етапі застосовується корекційний механізм з 1 бітом для виправлення обчислювальних похибок, викликаних стисненням. Незалежна реалізація спільнотою підтвердила, що ефект стиснення є справжнім, а математичний внесок у алгоритм є дійсним.
Суперечка не в тому, чи можна використовувати TurboQuant, а в тому, що Google зробив, щоб довести, що він «значно перевершує конкурентів».
Відкритий лист Гао Цзяньяна: три звинувачення, кожне з яких влучає в суть
27 березня о 22:00 Гао Цзяньян опублікував довгу статтю на Zhihu та одночасно подав офіційний коментар на платформі ICLR OpenReview. Гао Цзяньян є першим автором алгоритму RaBitQ, який був опублікований у 2024 році на провідній конференції з баз даних SIGMOD і вирішує ту саму проблему — ефективне стиснення високовимірних векторів.
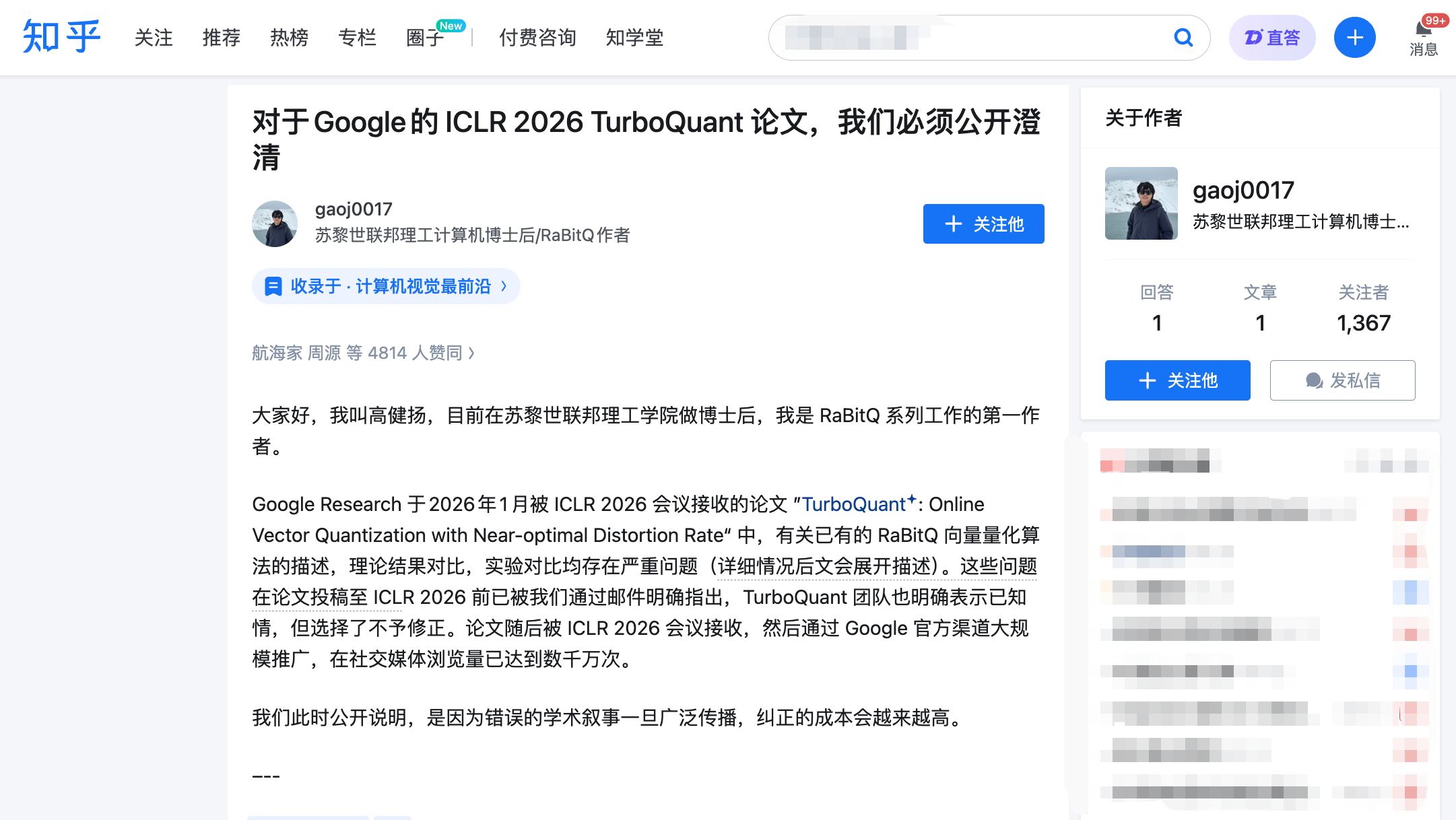
Його звинувачення поділено на три пункти, кожен з яких підтверджено електронними листами та хронологією.
Звинувачення 1: Використано чужий основний метод, без згадки в тексті.
Ключовим спільним кроком у технічній основі TurboQuant і RaBitQ є «випадкове обертання» даних перед їх стисненням. Ця операція перетворює нерівномірно розподілені дані на передбачуване рівномірне розподілення, що значно зменшує складність стиснення. Це найбільш суттєва і найбільш схожа частина обох алгоритмів.
Автор TurboQuant сам підтвердив це у відповіді на рецензії, але ніде в повному тексті статті не згадав зв’язок цього методу з RaBitQ. Ще важливішим контекстом є те, що другий автор TurboQuant Маджид Далірі у січні 2025 року сам звернувся до команди Гао Цзяньяна з проханням допомогти налагодити його Python-версію, написану на основі вихідного коду RaBitQ. У листі детально описано кроки відтворення та повідомлення про помилки — іншими словами, команда TurboQuant добре знайома з технічними деталями RaBitQ.
Один із анонімних рецензентів ICLR також самостійно зазначив, що обидві роботи використовують однакову технологію, і вимагав повного обговорення цього. Однак у фінальній версії статті команда TurboQuant не додала жодного обговорення, а навпаки, перемістила в додаток початковий опис RaBitQ (який і так був неповний).
Друге звинувачення: безпідставно називати теорію іншої сторони «другорядною».
Стаття TurboQuant присвоїла RaBitQ мітку «теоретично субоптимальний» через те, що математичний аналіз RaBitQ був «досить грубим». Однак Гао Цзяньян зазначив, що розширена версія статті RaBitQ строго довела, що похибка стиснення досягає математично оптимальної межі — цей висновок було опубліковано на провідній конференції з теоретичної інформатики.
У травні 2025 року команда Гао Цзяньяна детально пояснила оптимальність теорії RaBitQ через кілька електронних листів. Далірі, другий автор TurboQuant, підтвердив, що повідомив усіх авторів. Однак у фінальній версії статті зберігся вираз «підоптимальний», без будь-яких аргументів проти.
Звинувачення 3: У експериментальному порівнянні «ліва рука прив’язана до людини, права тримає ніж».
Це найбільш руйнівний пункт у повному тексті. Гао Цзяньян зазначив, що в експериментах з порівняння швидкості в статті TurboQuant було накладено два нечесні умови:
По-перше, офіційний RaBitQ надав оптимізований код на C++ (за замовчуванням підтримує багатопотоковість), але команда TurboQuant не використала його, а замість цього протестувала RaBitQ за допомогою власного перекладеного варіанту на Python. По-друге, під час тестування RaBitQ використовувався одноядерний CPU з вимкненою багатопотоковістю, тоді як TurboQuant використовував NVIDIA A100 GPU.
Ефект комбінації цих двох умов полягає в тому, що читачі роблять висновок, що «RaBitQ повільніший за TurboQuant на кілька порядків», але не мають можливості знати, що цей висновок базується на тому, що команда Google зв’язала супернику руки і ноги перед тим, як вони почали бігти. У статті недостатньо розкрито ці відмінності в експериментальних умовах.
Відповідь Google: «Випадкове обертання — це універсальна технологія, неможливо посилатися на кожен випадок»
За словами Гао Цзяньяна, команда TurboQuant у відповіді на електронний лист у березні 2026 року зазначила: «Використання випадкового обертання та перетворення Джонсона-Ліндембера вже є стандартною технікою в цій галузі, і ми не можемо цитувати кожну статтю, де використовуються ці методи.»
Команда Гао Цзяньяна вважає, що це спроба змінити суть питання: проблема не в тому, чи треба посилатися на всі статті, що використовували випадкове обертання, а в тому, що RaBitQ — це перша робота, яка поєднала цей метод із векторною компресією та довела його оптимальність за тих самих умов, і стаття TurboQuant мала б точно описати зв’язок між ними.
Офіційний обліковий запис Stanford NLP Group у X перепостував заяву Гао Цзяньяна. Команда Гао Цзяньяна опублікувала публічний коментар на платформі ICLR OpenReview та подала офіційну скаргу голові конференції ICLR та етичному комітету, а також планує опублікувати детальний технічний звіт на arXiv.
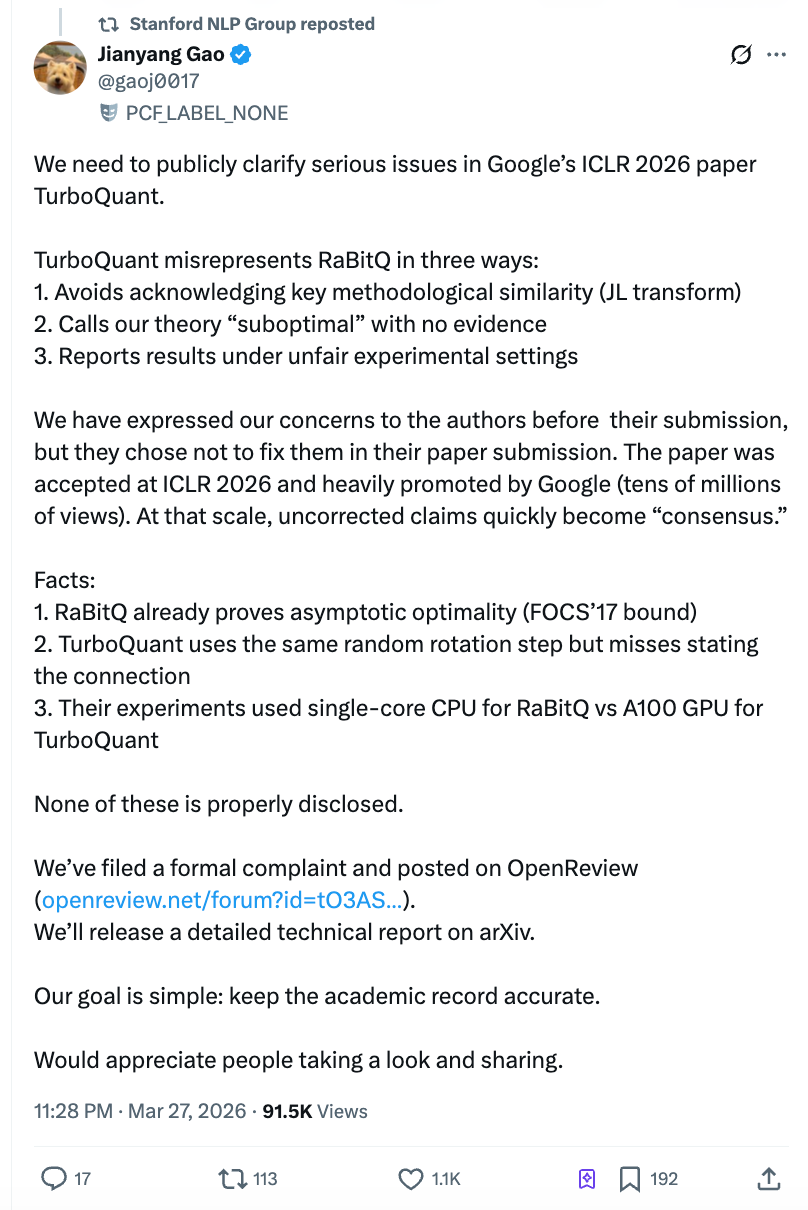
Незалежний технічний блогер Даріо Сальваті у своєму аналізі дав відносно нейтральну оцінку: TurboQuant справді внесв реальний внесок у математичний підхід, але зв’язок з RaBitQ набагато тісніший, ніж це зазначено у статті.
Зникло 90 мільярдів доларів США ринкової капіталізації: суперечки щодо статті посилюють паніку на ринку
Точка часу, коли відбулася ця академічна суперечка, надзвичайно тонка. Після того як Google 24 березня опублікував TurboQuant у своєму офіційному блозі, глобальний сектор чипів пам’яті зазнав сильного продажу. За повідомленнями CNBC та інших ЗМІ, Micron Technology знизилася протягом шести торгівельних днів поспіль, загальний спад склав понад 20%; SanDisk впала на 11% за один день; південнокорейська SK Hynix знизилася приблизно на 6%, Samsung Electronics — майже на 5%, японська Kioxia — приблизно на 6%. Ринкова паніка базується на простій і грубій логіці: програмне стиснення може зменшити вимоги до пам’яті для AI-виведення в 6 разів, що призведе до структурного зниження перспектив попиту на чипи пам’яті.
Аналітик Morgan Stanley Джозеф Мур у звіті від 26 березня заперечив цю логіку, зберігши рейтинг «покупка» для Micron і SanDisk. Мур зазначив, що TurboQuant стискає лише певний тип кешу — KV Cache, а не загальний обсяг використання пам’яті, і класифікував це як «нормальне покращення продуктивності». Аналогічно, аналітик Wells Fargo Ендрю Роча посилається на парадокс Джевонса, стверджуючи, що зростання ефективності та зниження витрат можуть стимулювати більш масштабне розгортання ШІ, що в кінцевому підсумку підвищить попит на пам’ять.
Старі дослідження, нова упаковка: ризики передачі від досліджень ШІ до ринкових нарративів
За аналізом технічного блогера Бена Пуладіана, стаття TurboQuant була опублікована в квітні 2025 року і не є новим дослідженням. 24 березня Google повторно представила її через офіційний блог, а ринок оцінив її як новий прорив. Така стратегія продвиження «старої статті з новим анонсом», поєднана з можливими експериментальними зміщеннями в статті, відображає системні ризики в ланцюжку передачі AI-досліджень від академічних публікацій до ринкових нарративів.
Для інвесторів у інфраструктуру ШІ, коли стаття стверджує про досягнення «кількох порядків» підвищення продуктивності, перше, що слід запитати — чи є умови порівняння базових показників справедливими.
Команда Гао Цзяньяна чітко заявила, що продовжить просування офіційного вирішення цього питання. Google ще не надав офіційної відповіді на конкретні звинувачення у відкритому листі.