









DeepSeek V4 нарешті запущений. Це момент, якого чекали майже п’ять місяців. Основна модель MoE з 1 трлн параметрів + версія Flash з 285 млрд параметрів, повний Pro-версія з 1,6 трлн параметрів — усі моделі повністю відкриті на GitHub за ліцензією Apache 2.0, ваги та код розгортання опубліковані одночасно.
Як тільки модель з’явилася, фінансові ринки надали їй відповідь трьома взаємно незалежними, але взаємопов’язаними способами.
Різні реакції ринків капіталу
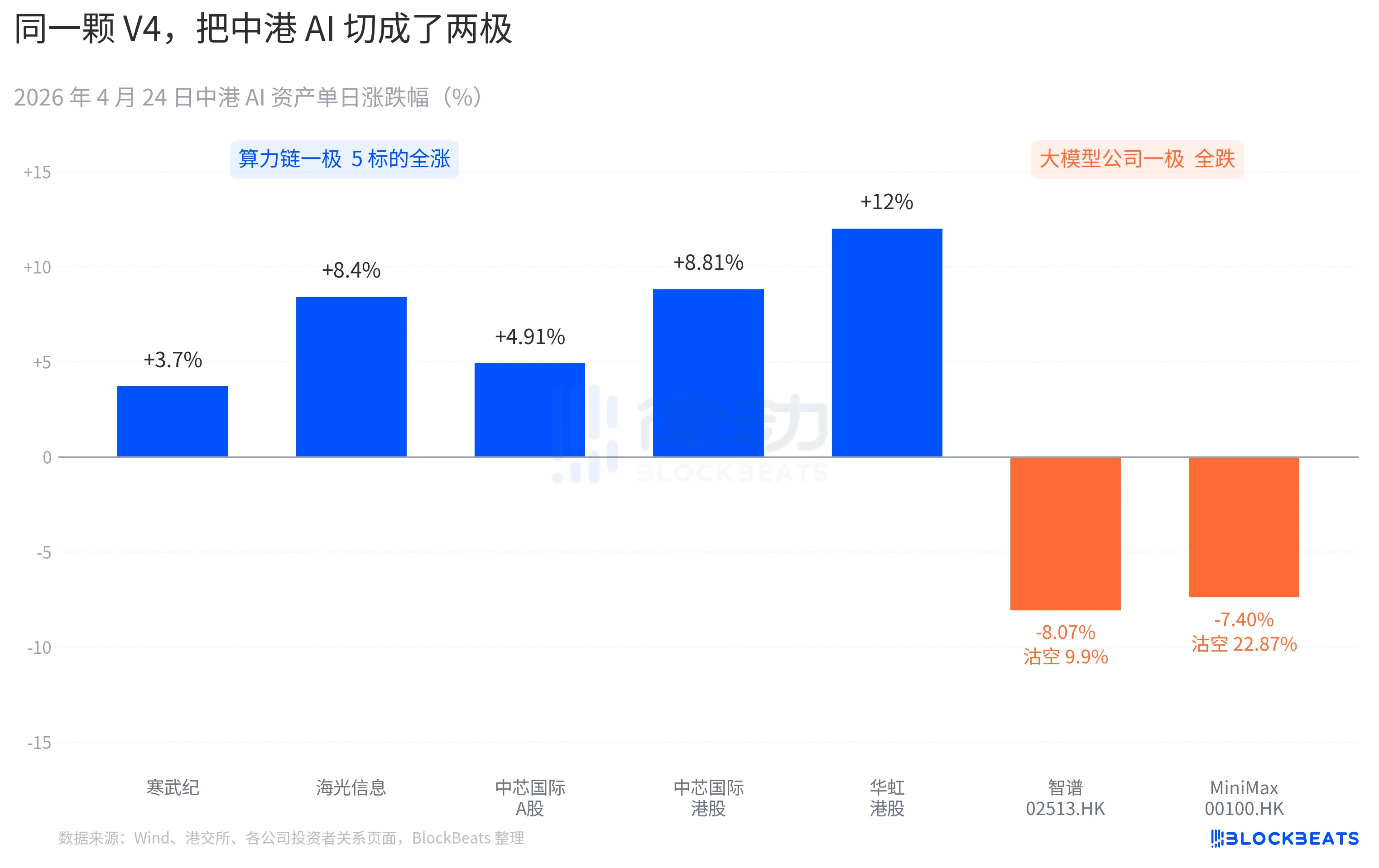
Майже всі акції ланцюга обчислювальної потужності показали стрімкий ріст. Cambricon продовжила серію з 11 зростань поспіль, зростання за день — 3,7%, загальний приріст за місяць перевищив 60%. Higon Information досягла підйому на 10% у ході торгів, закрилася з ростом на 8,4%. SMIC (A-акції) +4,91%, HK +8,81%. Hua Hong (HK) досягла максимуму +18%, закрилася з ростом на 12%. ETF iShares China Semiconductor витягнув 2,4 млрд юаней за день, обсяг досяг історичного максимуму.
Ця сторона компаній з великими моделями на гонконгському ринку має інший колір. Zhipu (02513.HK) впала на 8,07%, частка продажів у короткі продажі — 9,9%. MiniMax (00100.HK) впала на 7,40%, частка продажів у короткі продажі стрімко зросла до 22,87%. Остання має найвищий одноденний показник коротких продажів за останні три місяці серед компаній AI на Гонконзькій біржі. Обидві компанії є представниками хвилі IPO в сфері AI на Гонконзькій біржі в другій половині 2025 року, а їхні проспекти IPO містять однакове твердження про ключову перевагу: «власна базова велика модель».
На іншому кінці Тихого океану реакція була такою ж конкретною. Акції NVIDIA відкрилися 24 квітня з падінням на 1,8%, у ході торгів спадали до -2,6%, а на закритті закінчилися без змін. Блумберг у своєму швидкому аналізі ринку порівняв цю корекцію з «моментом DeepSeek V3» 27 січня. Різниця полягала в тому, що в січні мали місце панічні продажі, що призвели до знищення 600 мільярдів доларів ринкової капіталізації за один день. Цього разу це було більше схоже на перез цінування — помірне за обсягом, але чітко спрямоване. У дослідницьких звітах інституційних покупців з’явилася нова формулювання: «Потреба в AI-виведенні в Китаї починає відокремлюватися від потреби в AI-виведенні в Північній Америці».
Накладення цих трьох графіків разом — це перше рішення ринку, написане протягом 24 годин після запуску V4. Після перемоги відкритого коду гроші почали вибирати нові боки: ціну більше не визначає сама модель, а те, на якому чіпі вона працює та в який ланцюжок виробництва вона вбудована.
30 днів, 11 нових моделей, V4 підсилює відкритий код
Часове вікно випуску V4 само по собі є частиною причини посилення цієї реакції.
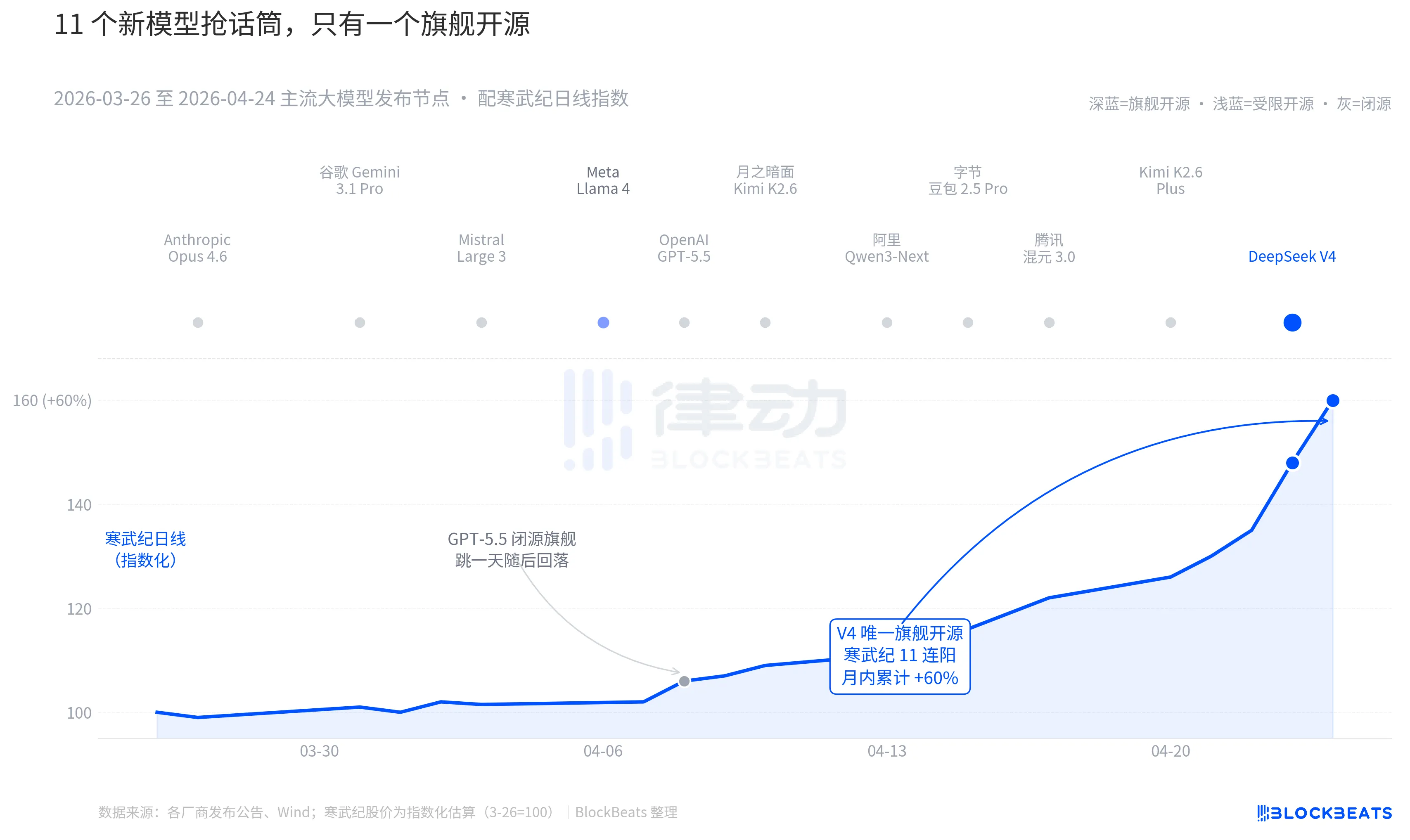
Повернімося до минулих 30 днів. З 26 березня по 24 квітня по всьому світу було анонсовано або значно оновлено щонайменше 11 великих моделей зі значним впливом — у список потрапили майже всі основні гравці. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent HunYuan 3.0, Kimi K2.6 Plus, а також DeepSeek V4, опублікований о 00:00 23 квітня.
У середньому кожні 2,7 дні виходить нова модель. Це швидкість, з якою навіть менеджери інвестиційних фондів не встигають прочитати прес-релізи. Але, проаналізувавши кінцеві дані 30 днів з AI-активами Китаю та Гонконгу, лише одне ім’я залишило постійний слід на графіку. 8 квітня GPT-5.5 спричинив зростання NVIDIA на 4,2% за один день, після чого вона досягла піку. Потім — DeepSeek V4 з 23 по 24 квітня, який сприяв безперервному стрибку цін у ланцюжку обчислювальних потужностей Китаю та Гонконгу.
Різниця не в самій здатності моделей. Різниця між цими 11 моделями у рейтингу LMArena в більшості випадків не перевищує 50 балів і знаходиться в вузькому діапазоні «одного рівня». Різниця полягає у поєднанні двох факторів.
Перша річ — це відкрите програмне забезпечення. Серед перших 10 моделей лише Llama 4 є відкритим, але його протокол вагів містить довгий список обмежень для комерційного використання, і спільнота розробників у Європі та США віднеслася до нього холодно — на третій день після запуску на OpenRouter він випав із топ-10. Протокол V4 — це Apache 2.0, ваги без обмежень, комерційне використання без обмежень, код інференсу публікується одночасно. Це перша флагманська відкрита модель за останні шість місяців, яка одночасно створила тиск на закриті моделі за трьома параметрами: продуктивністю, ціною та відкритістю.
Друге — це час. На тлі постійного розгортання заходів закритими командами, опен-сурсна історія постійно стискається. Opus 4.6 підняв SWE-Bench для завдань з кодом до нового рівня, а GPT-5.5 встановив ціну в 1,25 долара за мільйон токенів як нову нижню межу. Дискусія про те, чи зможе опен-сурс наздогнати закриті рішення, триває в Сіліконовій долині вже два роки. V4 з місячною оцінкою в 90 мільйонів активних користувачів призупинив цю суперечку.
За словами одного з великих національних інвестиційних менеджерів на презентації: «До V4 ми застосовували знижку до оцінки відкритих великих моделей, а після V4 ця знижка почала зворотньо використовуватися».
DeepSeek змінила цінову таблицю на постачанні обчислювальних потужностей
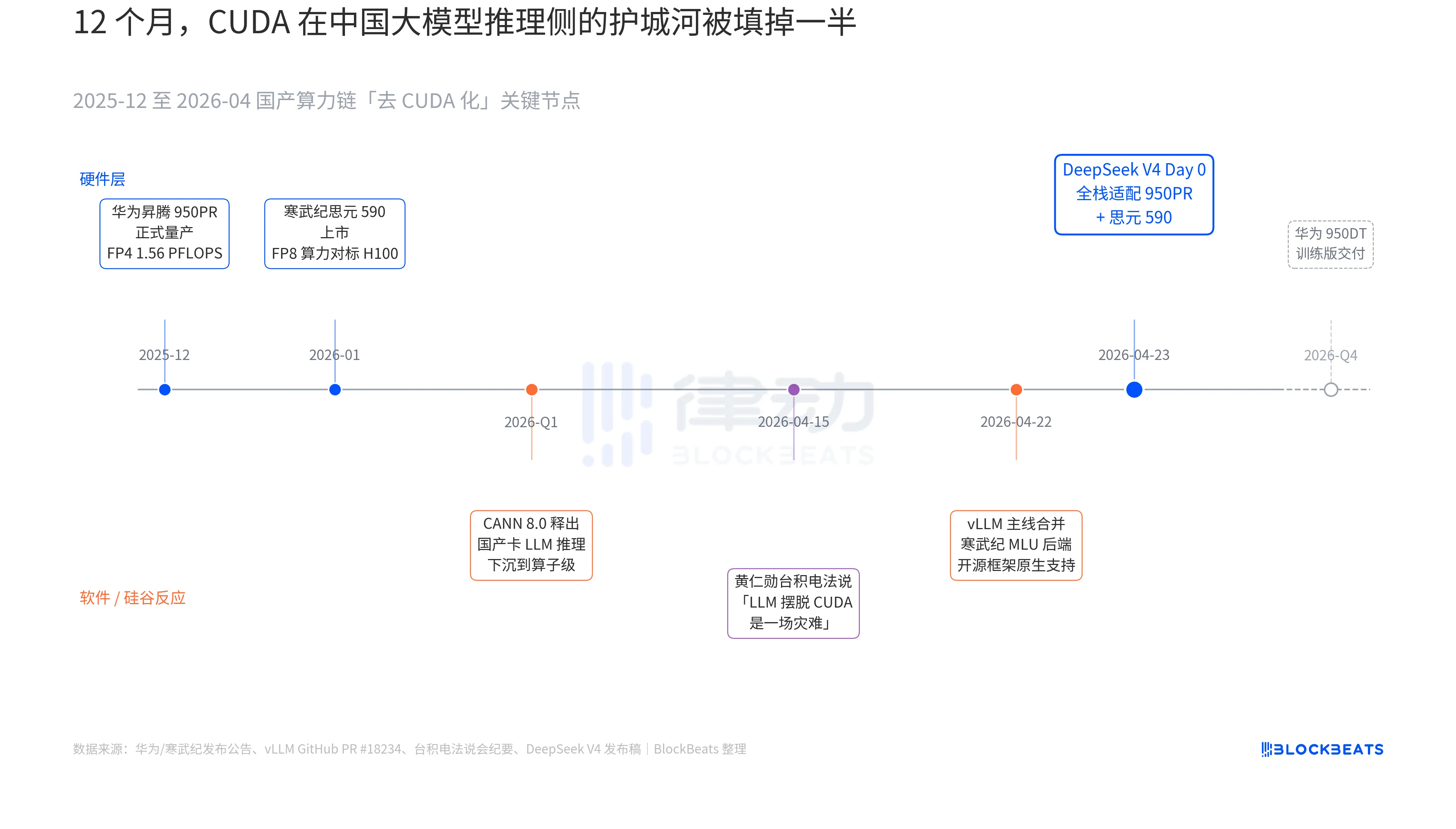
У випуску V4 є рядок, який раніше ніколи не з’являвся в офіційних документах жодного китайського великої мовної моделі: «День 0: повна сумісність з Cambricon MLU590 та Huawei Ascend 950PR, код розгортання відкрито опубліковано». Значення цього рядка можна зрозуміти лише, з’єднавши три паралельні лінії, що розвивалися протягом останніх 12 місяців: апаратне забезпечення, програмне забезпечення та реакція Сіліконової долини.
Перша таємна лінія — на стороні чіпа. Huawei Ascend 950PR офіційно вийшов на масове виробництво у грудні 2025 року, має FP4 продуктивність 1,56 PFLOPS та об’єм HBM 112 ГБ — це перший китайський AI-чіп, який за ключовими технічними показниками порівнюється з серією B від NVIDIA. У завданнях інференсу MoE з параметрами 1T, такими як V4, пропускна здатність однієї карти зростає у 2,87 рази порівняно з H20. Супутній програмний стек CANN 8.0 оптимізує фреймворки інференсу LLM на рівні операторів; публічні Benchmark DeepSeek показують, що V4 на супервузлі Ascend (8 карт 950PR) має кінцеву затримку інференсу на 35% нижчу, ніж кластер H100 аналогічного розміру. Дані про чіп Cambricon MLU590 ще більш агресивні: продуктивність FP8 на одному чипі порівнянна з H100, а ціна — менше половини.
Друга прихована лінія — на стороні програмного забезпечення. Основна гілка vLLM об’єднала PR з MLU-бекендом Cambricon 22 квітня, і це перший раз, коли відкритий фреймворк інференсу нативно підтримує китайські GPU, що не виробляються NVIDIA. DCU від Hygon проходить іншим шляхом через екосистему ROCm, але здатна повністю запустити роутинговий шар MoE V4. Це означає, що розгортання V4 більше не є «можливим лише на певній китайській карті», а стає «вибором між кількома китайськими картами». Залежність екосистеми від одного постачальника зламана — це ключовий переломний момент для production.
Третя таємна нитка походить з Сіліконової долини. 15 квітня Хуан Ренсюнь на зустрічі з інвесторами TSMC був змушений відповідати на питання аналітиків про прогрес китайських власних обчислювальних потужностей — його слова були холодними й конкретними: «Якщо вони справді зможуть позбутися CUDA для LLM, це буде для нас катастрофою (a disaster)». Дев’ять днів потому DeepSeek надав відповідь одним повідомленням Day 0.
Ці чотири слова «вітчизняна заміна» протягом останніх трьох років були використані надто часто й втратили свій зміст. Але після 24 квітня вранці ця справа вперше отримала конкретні дані, які можна оцінити на ринку капіталу. Пропускна здатність однієї карти, затримка кінцевого висновку, вартість висновку та комерційно придатний код розгортання незамітно перенесли цю довгу боротьбу за словесні формулювання за межу виробництва.
Логіка 11-денної зростання акцій Wudaiji тут. Вона більше не є просто «акцією з концепції китайських GPU», а «постачальником інфраструктури для висновку DeepSeek V4». Та сама логіка пояснює 12%-ий стрибок акцій Hua Hong у Гонконзі — вона виробляє 7-нм еквівалентну технологію для 950PR. Кожен токен V4, що запускається на китайському Ascend, означає, що частина потужностей, які раніше йшли до NVIDIA та TSMC, тепер залишаються в Південній Дельті Янцзи.
Наступний крок вже підготовлено. У дорожній карті Huawei планується поставити 950DT (навчальна версія) у четвертому кварталі 2026 року, з метою «повної стекової навчання моделей V5 або еквівалентного рівня на кластері з 10 000 пристроїв». Якщо цей шлях вдасться реалізувати, CUDA в Китаї на стороні навчання великих моделей знизить свій статус з «необхідного» на «додатковий».
Джерело:律動 BlockBeats