









Ця корекція DeepSeek спричинила нелінійний стрімкий спад, що примусово ввів галузь у нову еру витрат.
Автор статті, джерело: 0x9999in1, ME News
Коротко
- Ціна пробила дно: наприкінці квітня 2026 року DeepSeek знизила ціну за вивід моделі V4-Pro до 0,878 долара США за мільйон токенів шляхом поєднання обмежених за часом знижок та зниження цін на кеш, а ціна за вхід із вдалим кешуванням знизилася до 0,0037 долара США (приблизно 0,025 юаня), повністю зруйнувавши ціновий якір галузі великих моделей.
- У Китаї та США виникла «розрив» у цінах: порівняно з лідерами світового ринку, загальна вартість викликів API DeepSeek-V4-Pro становить лише близько тридцятої частини від вартості OpenAI GPT-5.5 та Anthropic Claude Opus 4.7, що формує дуже значну різницю в витратах.
- Тиск з боку внутрішнього конкурентного середовища: через агресивне ціноутворення DeepSeek, основні моделі, такі як Zhipu GLM 5.1 та Moonshot Kimi K2.6, стикаються з величезним комерційним тиском і можуть бути змушені слідувати за зниженням цін, що значно прискорить очищення ринку.
- «Попадання в кеш» стає ядром економіки: DeepSeek знизив ціну за попадання в кеш до десятої частини початкової, що на фундаментальному рівні значно сприяє обробці довгих текстів, RAG (пошуково-підсилене генерування) та безперервним багатокроковим взаємодіям агентів.
- Висновки дослідницького центру: базові великі моделі прискорюють інфраструктуризацію, подібну до електроенергії та водопостачання; майбутнє конкурентне змагання повністю зміститься з боротьби за розмір параметрів моделі на оптимізацію витрат на виведення та частку ринку розробницької екосистеми.
Вступ: точка “сингулярності” вартості обчислювальних потужностей великих моделей
Розвиток технологій часто супроводжується експоненційним зниженням витрат — це невід’ємна частина шляху будь-якої революційної технології до повсюдного поширення. 25–26 квітня 2026 року індустрія ШІ зустріла надзвичайно знаковий момент: провідний виробник великих моделей DeepSeek випустив дві «глибоководні бомби» поспіль. Спочатку було оголошено про обмежений за часом розпродаж API моделі DeepSeek-V4-Pro зі знижкою 2,5 рази; а потім — про зниження ціни за вхідні кешовані запити в усіх API-сервісах до 1/10 від початкової ціни.
Після двох раундів стратегії коригування цін, ціна за вхідне кешування для DeepSeek-V4-Flash до 5 травня 2026 року впала до дивовижних 0,0029 долара США (приблизно 0,02 юаня), а ціна за вхідне кешування для DeepSeek-V4-Pro, що відповідає світовому рівню, становить лише 0,0037 долара США (приблизно 0,025 юаня).
Раніше галузь загалом передбачала, що вартість висновку великих моделей зменшуватиметься щорічно на 50%, але ці зниження цін DeepSeek спричинили нелінійний, різкий провал, примусово вивівши галузь до нової ери витрат. Ми вважаємо, що це не просто маркетингова акція чи короткострокова «цінова війна», а необхідний результат оптимізації базової архітектури алгоритмів (наприклад, розріджених механізмів уваги, екстремального розвитку архітектури MoE) та підвищення інженерних здібностей обчислювальних кластерів. Цей звіт на основі найновіших даних про ціни в усій галузі глибоко аналізує індустрійні коливання, спричинені зниженням цін DeepSeek, та порівнює комерційну конкурентоспроможність глобальних основних великих моделей, намагаючись надати керівництву чітку карту розвитку галузі.
Ключове явище: Пробій меж цінової системи серії DeepSeek-V4
Щоб зрозуміти масштаб цього зниження цін, ми повинні глибоко проаналізувати три ключові виміри ціноутворення API великих моделей: ціна за вхід (без співпадіння кешу), ціна за вхід (зі співпадінням кешу) та ціна за вихід. Колишні моделі ціноутворення зазвичай розрізняли лише вхід і вихід, але з дозріванням технологій довгого контексту (Long-Context) «частота співпадінь кешу (Cache Hit)» стає ключовим фактором, що перетворює економіку API.
Розбір стратегії ціноутворення: накладання знижок та кешування плеча
Згідно з останніми опублікованими даними, DeepSeek застосував трійчасту стратегію: «зниження базової ціни + обмежений за часом знижка + кешований плече».
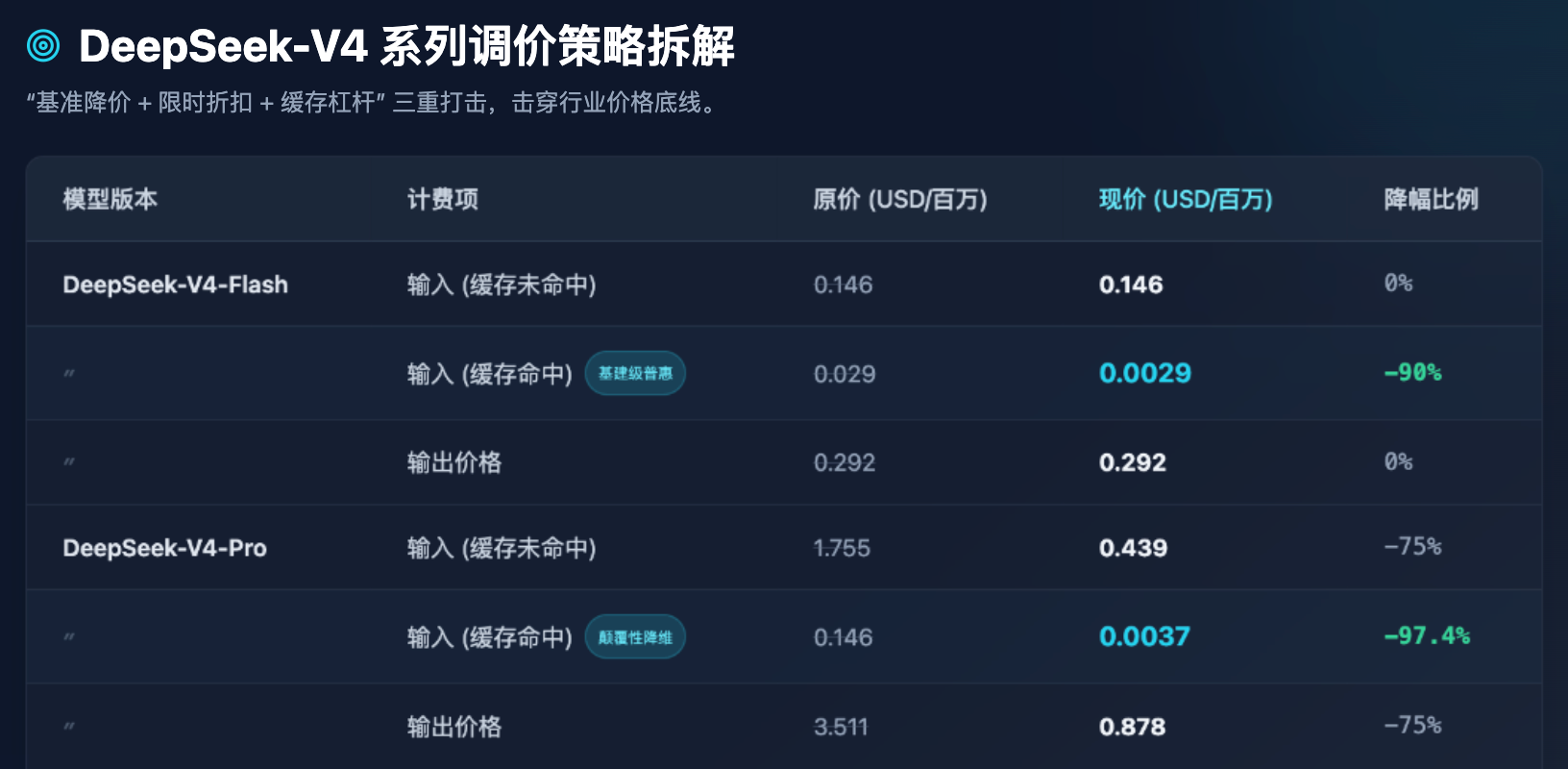
Таблиця 1: Порівняння цін на API серії DeepSeek-V4 до та після зміни (у доларах США за мільйон токенів)
З таблиці 1 ми можемо зробити кілька надзвичайно чітких спостережень щодо галузі:
По-перше, універсальне застосування моделі Flash вже досягло дна. Для моделей Flash, які зосереджені на високій пропускній здатності та низькій затримці, ціна за вивід залишається на рівні 0,292 долара США за мільйон токенів — це вже мінімальний рівень, що майже повністю відповідає жорстким витратам на обчислювальну потужність серверів. DeepSeek не продовжив зниження базової ціни Flash, а замість цього розумно знизив ціну за «попадання у кеш» на 90%. Це означає, що при обробці великої кількості повторюваних системних підказок (System Prompt) або фіксованих документів із запитаннями та відповідями, витрати на модель Flash майже зникають.
Друге, зниження вартості моделі Pro. Модель V4-Pro, яка є флагманською моделлю, що відповідає світовому першому ешелону (наприклад, рівню GPT-5), знизила ціну за вивід з 3,511 долара до 0,878 долара. Ще більш дивовижним є те, що ціна за вхід з використанням кешу, яка раніше становила 0,146 долара, після поєднання обмеженої знижки 2,5 відсотка та знижки на 1/10, тепер становить лише 0,0037 долара. Це надзвичайно неймовірне число — це означає, що вартість виклику найкращого світового інтелекту була зменшена до рівня, коли навіть малі та середні підприємства або окремі розробники можуть без обмежень використовувати його з високою частотою.
Третє — це тиск на розробників щодо оптимізації Prompt-інженерії. Встановлення ціни при спрацьовуванні кешу на кілька десятків разів нижче, ніж при його пропуску (наприклад, у Pro-моделі: 0,0037 долара США проти 0,439 долара США, різниця близько 118 разів) — це не лише стратегія ціноутворення, а й спосіб за допомогою комерційних інструментів впливати на технічну екосистему. DeepSeek чітко повідомляє розробникам: якщо ваша архітектура розроблена правильно (наприклад, фіксований довгий контекст на початку, а змінні короткі запити — після), ви зможете користуватися майже безкоштовними обчислювальними ресурсами для вводу.
Порівняння в поперечному розрізі: різкий контраст цін на глобальні та локальні великі моделі
Порівняння лише зі зниженням цін самого DeepSeek не дає повної картини; коли ми розміщуємо цю цінову стратегію в координатній системі глобального ринку великих моделей 2026 року, цей «розрив» стає справді леденячим.
На основі інформації від OpenRouter та інших публічних джерел, ми зібрали найновіші ціни на API для 9 найбільш представницьких великих моделей, які працюють в Україні та за кордоном.

Таблиця 2: Порівняння цін на API головних світових великих моделей у 2026 році (у доларах США за мільйон токенів)
Бороться з глобальними гігантами: зруйнувати міф про «високий інтелект і високу надбавку»
Протягом останніх двох років у розповіді про ШІ OpenAI та Anthropic підтримували угоду: найрозумніші моделі мають отримувати найвищу маржу. Зараз ціна виводу GPT-5.5 та Claude Opus 4.7 становить відповідно 30 доларів і 25 доларів за мільйон токенів. Ці дві сіліконові долини намагаються підтримувати свою високу «податкову ставку» на обчислювальну потужність, монополізуючи найкращі здібності виведення.
Однак з’явлення DeepSeek-V4-Pro та його ціна за вивід у 0,878 долара США прямо прорвало цю паперову перегородку. Якщо V4-Pro зможе досягти або наблизитися до рівня GPT-5.5 у всіх ключових тестах (Benchmarks) та реальних умовах, то різниця у ціні за вивід у 34 рази між ними повністю зруйнує логіку премії іноземних гігантів на B2B-ринку.
«ME News» оцінив, що для компанії, яка сильно залежить від AI-згенерованого контенту, місячна витрата 1 мільярда токенів виводу коштує 30 000 доларів США за GPT-5.5, а при переключенні на DeepSeek-V4-Pro ця вартість різко знижується до 878 доларів США. Така різниця в витратах на цьому рівні може вирішити долю стартапу. Це свідчить про те, що китайські AI-компанії вже розвинули власний підхід — поєднання «жорсткої естетики» та «екстремального інженерного підходу» у навчанні базових моделей та оптимізації інференс-кластерів, який суттєво відрізняється від підходу Сіліконової долини.
Знищення внутрішніх конкурентів: прискорення великої перебудови галузі
Якщо DeepSeek для зарубіжних гігантів є знищенням на вищому рівні, то для внутрішніх конкурентів це жорстока гра з нульовою сумою.
З таблиці 2 видно, що лідери на внутрішньому ринку, такі як Zhipu (GLM 5.1, вихід 4,4 долара) та Moonshot (Kimi K2.6, вихід 4 долари), знаходяться у складному положенні щодо ціноутворення. Ці ціни кілька місяців тому вважалися «розумними та вигідними», але перед DeepSeek-V4-Pro (вихід 0,878 долара) вони миттєво втратили всі цінові бар’єри. Навіть Alibaba Cloud, яка завжди відома своєю відкритістю та низькими цінами (Qwen3.6 Plus, вихід 1,96 долара), більше не виглядає «дешево».
На полі бою легких моделей Flash битва також набула запеклого характеру. Step 3.5 Flash від Step星辰 має вхідну вартість лише 0,028 долара, а вихідну — 0,299 долара, що дуже близько до DeepSeek-V4-Flash (вихідна вартість 0,292 долара). Це свідчить про те, що в сфері легких моделей витіснення вартості обчислень досягло наномасштабу, і всі учасники літають прямо вздовж лінії витрат.
Загалом, DeepSeek використовує здібності рівня Pro, щоб конкурувати з цінами на Plus або стандартні версії вітчизняних конкурентів, а також застосовує ціни рівня Flash, щоб привабити величезний обсяг довгих хвиль з низькою щільністю цінності. Така тактика «двостороннього тиску» значно стискає простір для виживання інших компаній, що розробляють великі моделі, і після цієї хвилі зниження цін вітчизняний конкурс серед великих моделей ШІ швидко набере темп.
Глибокий аналіз: технологічна та бізнес-логіка за екстремально низькими цінами
Низька ціна без фундаментальних підстав нестійка. DeepSeek наважується застосувати таку рішучу стратегію зниження цін на 2026 рік завдяки глибокій технічній підтримці та надзвичайно амбітним комерційним планам.
Технічна логіка: від «сила — це все» до «перемога за рахунок архітектури»
Різке падіння ціни суттєво є результатом вивільнення переваг, пов’язаних з еволюцією технічної архітектури.
- Глибокі переваги архітектури MoE (мішані експерти): на відміну від ранніх великих щільних моделей від OpenAI, сучасні передові моделі загалом використовують високооптимізовану архітектуру MoE. DeepSeek дуже ймовірно ще більше зменшив пропорцію активованих параметрів у архітектурі V4. Це означає, що навіть при величезній загальній кількості параметрів під час кожного висновку активуються лише дуже незначні частини «експертів», що значно зменшує обчислювальну складність (FLOPs) і навантаження на пропускну здатність відеопам’яті.
- Революційний прорив у керуванні KV Cache: найбільшим досягненням цієї зміни є зменшення співпадінь кешу вводу до 1/10. У архітектурі Transformer найбільшим обмеженням при обробці довгих текстів є не обчислення, а використання великої кількості відеопам’яті для зберігання KV Cache контексту. DeepSeek, очевидно, реалізував на системному рівні технологію пулінгу KV Cache зі спільним доступом між запитами (наприклад, удосконалену версію технології RadixAttention). Коли численні одночасні запити користувачів містять однакові системні налаштування або бази знань, модель більше не повинна повторно обчислювати ці токени — вона просто отримує їх із пам’яті або навіть розподіленого пулу відеопам’яті. Це робить граничну вартість «введення довгих текстів» близькою до нуля.
Бізнес-логіка: обмін прибутку на простір, переформування екосистемного рову
«ME News» вважає, що обмежений за часом знижковий та базовий ціновий стратегії DeepSeek мають чітку й вирішувальну комерційну мету:
Спочатку повністю знищити екосистему «оболонкового доналаштування», щоб примусити виникнути AI-натуральні додатки. Коли вартість виклику найпотужніших базових моделей нескінченно наближається до безкоштовності, підприємцям більше не матиме економічного сенсу витрачати величезні кошти на навчання або доналаштування власних галузевих малих моделей. DeepSeek за допомогою низьких цін намагається привернути всіх AI-розробників суспільства до своєї екосистеми API, перетворивши її на «підставу AI-епохи» — подібно до Amazon AWS чи Microsoft Azure.
Друге, розквіт агента-позиціонера. Справжні агентні застосунки вимагають від моделі величезної кількості самороздумів, рефлексії, планування та багаторазових циклів викликів (Loop). У цьому процесі виникає величезна кількість прихованих витрат токенів. Дорогі API — найбільший бар’єр для поширення агентів. DeepSeek, знизивши ціну за вдалий доступ до кешу до 0,0037 долара, фактично забезпечує економічну доцільність для «побудови тисячі циклів самостійною ІО». Хто забезпечить найнижчі витрати на спроби та помилки, той і створить найвеличніші суперзастосунки, нативні для ІО.
Вплив на галузь та аналіз тенденцій: від «війни моделей» до «війни екосистем»
Щоб більш наочне продемонструвати вплив цінових змін на прийняття рішень підприємствами, ми провели симуляцію витрат для корпоративного застосунку.
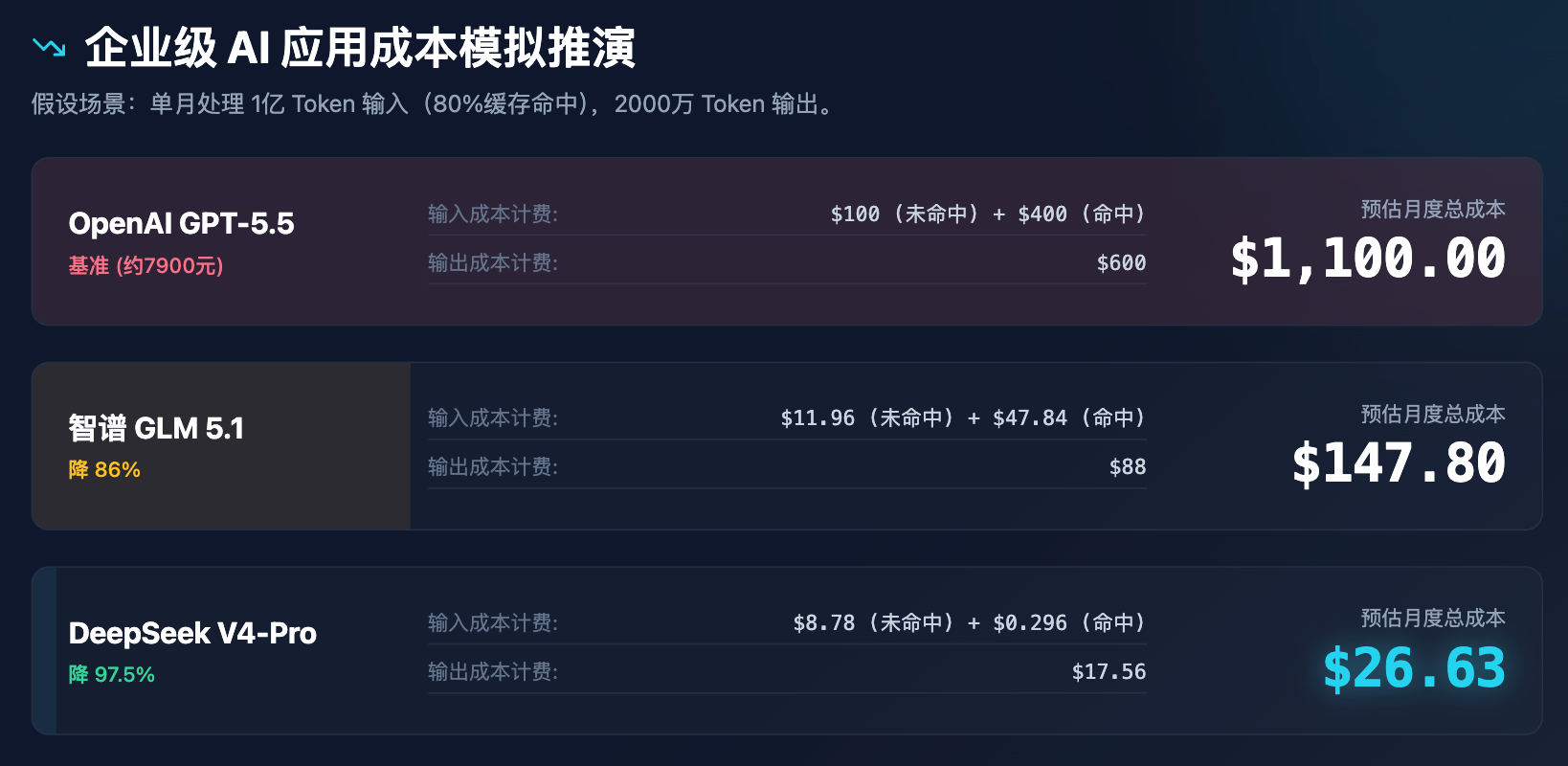
Таблиця 3: Моделювання витрат на корпоративні AI-застосунки (припустимо, що щомісяця обробляється 100 мільйонів вхідних токенів і 20 мільйонів вихідних токенів)
З наведеної симуляції чітко видно, що ціноутворення DeepSeek — це не просто знижка, а перебудова моделі витрат. Витрати менше 30 доларів США на місяць можуть задовольнити всі потреби середнього бізнесу щодо підтримки клієнтів, аналізу документів та перевірки коду, що обов’язково викличе серію наслідків:
- Фундаментальний зсув у логіці інвестування штучного інтелекту: капітал повністю втратить інтерес до «створення ще одного універсального великої моделі». Крім дуже небагатьох державних ініціатив або інтернет-гігантів, двері до універсальних базових великих моделей зачинені назавжди. Майбутні інвестиції повсюдно спрямуються на рівень застосунків (Application Layer) та інфраструктурні проміжні програми (інфраструктурні маршрутизатори, AI-шлюзи тощо).
- Стратегія маршрутизації багатомодельних систем (LLM Routing) стає стандартом: компанії більше не зосереджуватимуться на одній моделі. Система автоматично розподілятиме завдання залежно від їхньої складності. Наприклад, 90% щоденних операцій з очищення даних та простого класифікування виконуватимуться за дуже низькою вартістю за допомогою DeepSeek-V4-Flash або Step 3.5 Flash; 10% складних логічних міркувань та генерації звітів для керівництва будуть виконуватися за допомогою DeepSeek-V4-Pro або за потреби — GPT-5.5.
- Довгі тексти набувають справжнього комерційного переломного моменту: раніше «завантажити звіт у мільйони слів і дати AI зробити висновки» звучало чудово, але витрати на API, що сягали кількох доларів за раз, відлякували бізнес-клієнтів. Зі зниженням ціни за в命中 кешу введення до рівня 0,02 юаня за мільйон токенів, «читання всієї документації та реальний інтерактив» стане стандартною функцією всіх програмних продуктів OA та ERP для підприємств.
Висновки та стратегічні рекомендації
Цей ціновий шторм у квітні 2026 року ознаменував офіційний кінець класичного романтичного періоду галузі великих моделей — періоду «боротьби за параметри та демонстрації результатів» — і початок жорстокої індустріальної ери, де вирішують «вартість, доступ до обчислювальних ресурсів та контроль над екосистемою». DeepSeek за допомогою агресивної цінової стратегії не лише продемонстрував світові глибоку експертизу китайських компаній у галузі інженерії моделей, а й активно лопнув пухир з надмірної надбавки до обчислювальних потужностей штучного інтелекту.
Щодо цього, «ME News Think Tank» має три пропозиції:
- Для розробників додатків: зупиніть страх перед витратами на виклик великих моделей. Негайно припиніть створення та доналаштування базових моделей з параметрами менше 10 млрд, і перенаправте всі розробничі ресурси на покращення користувацького досвіду, адаптацію на кінцевих пристроях, створення бар’єрів власних даних та вдосконалення робочих процесів Agent. Використовуйте цю хвилю «дешевої, потужної обчислювальної потужності», щоб швидко захопити ринкові сценарії.
- Для CIO/CTO традиційних підприємств: переоцініть стратегію AI-трансформації вашої компанії. Проекти, які раніше були відкладені через витрати — такі як питання-відповіді на базі знань, автоматизовані служби підтримки та кодові Copilot — за теперішніх цін на API мають дуже високий ROI (повернення інвестицій). Рекомендується впровадити зрілі платформи LLMOps та створити підприємний AI-шлюз для гнучкого підключення найбільш вигідних на поточний момент моделей.
- Для конкурентів з базовими моделями: потрібно відмовитися від стратегії слідування. Перед ціновою війною або ви повинні за допомогою ще більш глибокої співпраці чіпа та фреймворку знизити витрати, або створити незамінні технологічні бар’єри у диференційованих галузях, таких як ембодід-інтелект, нативна мультимодальність (відео/генерація 3D), сильні логічні міркування у вертикальних галузях. Просто мовні великі моделі стали звичайними і не мають майбутнього.
Великі моделі більше не є божествами, що почитаються в лабораторіях — вони з невідомою раніше швидкістю зходять з п’єдесталу, перетворюючись на потужний потік, що забезпечує інтелект усіх речей. А все це лише починається.
Джерело:
- OpenRouter. (2026). База даних порівняння цін на API.
- Офіційне оголошення DeepSeek. (2026, 25 квітня).Обмежений за часом акційний план API DeepSeek-V4-Pro.
- Офіційне повідомлення DeepSeek. (2026, 26 квітня).Універсальна обчислювальна потужність у епоху великих моделей: схема коригування цін за вдалим попаданням у кеш API.