









Автор | Sleepy.txt
Вісім років тому Zhongxing зупинився.
16 квітня 2018 року заборона, видана Бюро промисловості та безпеки Міністерства торгівлі США, призупинила діяльність ZTE — глобального четвертого за величиною виробника телекомунікаційного обладнання з 80 000 працівників та річним доходом понад 100 мільярдів юанів. Заборона була простою: протягом наступних семи років будь-яким американським компаніям заборонялося продавати ZTE компоненти, товари, програмне забезпечення та технології.
Без чіпів Qualcomm базові станції припинили виробництво. Без ліцензії Google на Android смартфони не мали робочої операційної системи. Через 23 дні ZTE опублікувала оголошення, в якому зазначила, що основна діяльність компанії припинилася.
Але згодом ZTE вижив, але за ціну 1,4 мільярда доларів США.
Штраф у розмірі 1 мільярда доларів США, сплачується одноразово; 400 мільйонів доларів США як гарантійний внесок, розміщений на депозитному рахунку в американському банку. Крім того, повна зміна керівництва та введення команди з контролю за дотриманням правил з боку американських органів. За весь 2018 рік ZTE зазнала чистого збитку в розмірі 7 мільярдів юанів, а виручка знизилася на 21,4% у порівнянні з попереднім роком.
Тодішній голова ZTE Інь Їм написав у внутрішньому листі: «Ми знаходимося в галузі, яка є складною та високо залежною від глобальних ланцюгів постачання». Це твердження на той час звучало як рефлексія, а також як безсилия.
Вісім років потому, 26 лютого 2026 року, китайський AI-унікорн DeepSeek оголосив, що його майже випущений багатомодальний великий модуль V4 буде співпрацювати з китайськими виробниками чіпів, вперше забезпечивши повний цикл — від попереднього навчання до доналаштування — без використання продуктів NVIDIA.
Ми більше не використовуємо NVIDIA.
Після оголошення першою реакцією ринку була сумнів. Чи має сенс відмовитися від NVIDIA, яка має більше 90% ринку чипів для навчання штучного інтелекту?
Але за вибором DeepSeek криється питання, що перевищує комерційну логіку: якою повинна бути незалежність у обчислювальних потужностях для китайського ШІ?
Що саме знаходиться під задушливим захопленням
Багато хто вважає, що заборона на чіпси блокує апаратне забезпечення. Але справжнім фактором, що душить китайські компанії зі штучним інтелектом, є річ під назвою CUDA.
CUDA, повна назва Compute Unified Device Architecture, — це паралельна обчислювальна платформа та модель програмування, розроблена NVIDIA у 2006 році. Вона дозволяє розробникам безпосередньо використовувати обчислювальну потужність GPU NVIDIA для прискорення різноманітних складних обчислювальних завдань.
До настання ери штучного інтелекту це був лише інструмент для невеликої групи гіків. Але коли хвиля глибокого навчання охопила світ, CUDA перетворилася на фундамент усього індустрії штучного інтелекту.
Навчання великих моделей ШІ суттєво полягає у масових матричних обчисленнях. А це саме та робота, яку GPU виконує найкраще.
NVIDIA, завдяки своїй стратегії, розробленій понад десятиліття тому, створила повний інструментарій для глобальних розробників ШІ, що охоплює все — від нижчого рівня апаратного забезпечення до верхнього рівня застосунків, заснований на CUDA. Сьогодні всі основні платформи ШІ, від TensorFlow від Google до PyTorch від Meta, глибоко інтегровані з CUDA на нижчому рівні.
Докторант зі штучним інтелектом з першого дня навчання вивчає, програмує та проводить експерименти в середовищі CUDA. Кожен рядок його коду підсилює конкурентну перевагу NVIDIA.

На 2025 рік екосистема CUDA налічує понад 4,5 мільйона розробників, охоплює понад 3000 GPU-прискорених додатків, і більше 40 000 компаній по всьому світу використовують CUDA. Ці цифри означають, що понад 90% розробників штучного інтелекту по всьому світу залежать від екосистеми NVIDIA.
Сила CUDA полягає в тому, що це маховик. Чим більше розробників його використовують, тим більше інструментів, бібліотек і коду з’являється — екосистема стає краще; чим краще екосистема, тим більше розробників вона приваблює. Коли цей маховик починає обертатися, його майже неможливо зупинити.
В результаті Nvidia продавала вам найдорожчі лопати та визначила єдиний спосіб копання. Хотіли б змінити лопату? Звісно. Але спочатку вам доведеться переписати всі досвід, інструменти та код, які десятки тисяч найрозумніших розумів світу накопичили за останні роки саме в цьому стилі.
Хто має сплатити цю вартість?
Отже, коли 7 жовтня 2022 року були введені перші обмеження БІС, що забороняли експорт графічних процесорів NVIDIA A100 і H100 до Китаю, китайські компанії з області ШІ вперше відчули подібне задуху, як у випадку з ZTE. Пізніше NVIDIA представила «китайську версію» A800 і H800, зменшивши пропускну здатність з’єднання між чіпами, щоб лише тримати постачання.
Але лише через рік, 17 жовтня 2023 року, другий раунд обмежень був ще більш посилено: A800 та H800 також були заборонені, а 13 китайських компаній були включені до списку суб’єктів. NVIDIA знову була змушена випустити подальше зменшену версію H20. До грудня 2024 року останній раунд обмежень за часів адміністрації Байдена набув сили, і експорт H20 був строго обмежений.
Три етапи обмежень, поступове посилення.
Але на цей раз історія розвивалася інакше, ніж у випадку з ZTE тоді.
Асиметричний прорив
Незважаючи на заборону, всі вважали, що мрія Китаю про великі моделі ШІ завершиться.
Вони всі помилялися. Перед обмеженнями китайські компанії не вибрали прямого зіткнення, а розпочали вибивання шляху. Першим полем битви цього вибивання став не чіп, а алгоритм.
З кінця 2024 року до 2025 року китайські компанії з ІО разом змінили напрямок розробки на гібридні моделі експертів.
Просто кажучи, велику модель розбивають на багато невеликих експертів, і під час обробки завдання активуються лише найбільш відповідні з них, а не вся модель цілком.
DeepSeek V3 є типовим прикладом цього підходу. Він має 671 мільярда параметрів, але під час висновку активується лише 37 мільярдів, що становить лише 5,5% від загальної кількості. Щодо витрат на навчання, він використовував 2048 GPU NVIDIA H800 протягом 58 днів, загальні витрати склали 5,576 мільйона доларів США. Як порівняння, оцінки витрат на навчання GPT-4 ззовні становлять близько 78 мільйонів доларів США. Різниця в одному порядку величини.
Оптимізація на алгоритмічному рівні безпосередньо відобразилася на цінах. Ціна API DeepSeek: вхід — від 0,028 до 0,28 долара за мільйон токенів, вихід — 0,42 долара. Ціна вводу GPT-4o — 5 доларів, виводу — 15 доларів. Claude Opus ще дорожчий: вхід — 15 доларів, вихід — 75 доларів. У перерахунку DeepSeek дешевший за Claude у 25–75 разів.
Ця цінова різниця викликала величезний резонанс на глобальному ринку розробників. У лютому 2026 року на OpenRouter — найбільшій у світі платформі агрегації API для AI-моделей — тижневий обсяг викликів китайських AI-моделей збільшився на 127% за три тижні і вперше перевищив американські. Рік тому частка китайських моделей на OpenRouter становила менше 2%. Через рік вона зросла на 421% і наблизилася до шестидесяти відсотків.
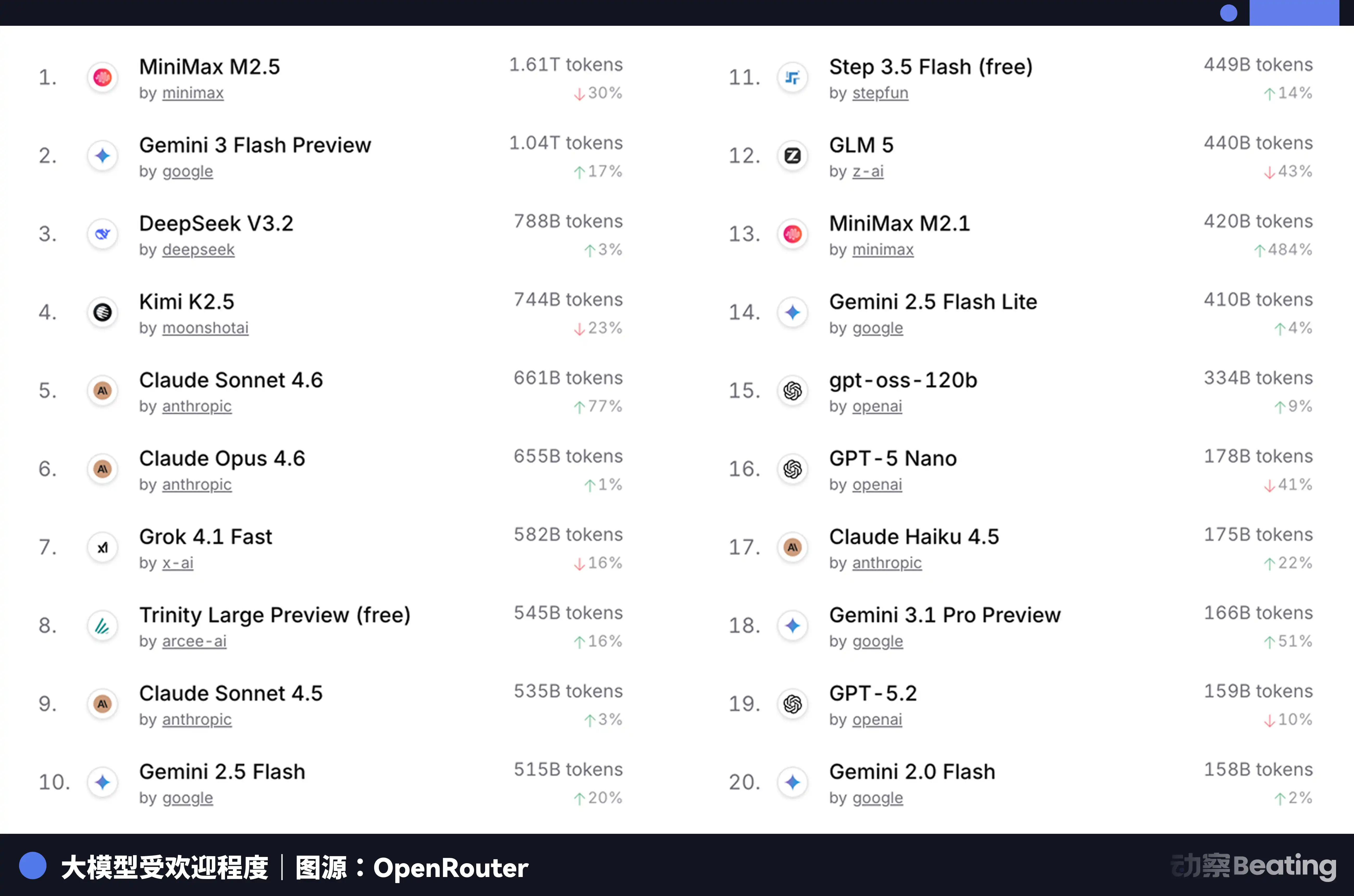
За цими даними криється структурна зміна, яку легко не помітити. З другої половини 2025 року основні сценарії застосування ШІ змістилися з чатів на агентів. У сценаріях з агентами споживання токенів на одну завдання становить від 10 до 100 разів більше, ніж у простому чаті. Коли споживання токенів зростає експоненційно, ціна стає вирішувальним фактором. Надзвичайна цінова перевага китайських моделей ідеально потрапила у це вікно.
Але проблема в тому, що зниження вартості висновків не вирішує фундаментальної проблеми навчання. Якщо велика модель не може постійно навчатися та ітерувати на найновіших даних, її здатності швидко деградують. А навчання залишається тим самим непереборним чорною дірою обчислювальних ресурсів.
Тоді, звідки беруться навчені «лопати»?
Переход з резервного на основний
Цзянсу, Сяньхуа, невелике місто на півдні Су, відоме нержавіючою сталлю та здоровим харчуванням, раніше не мало ніякого відношення до ШІ. Але в 2025 році тут було побудовано та запущено виробничу лінію з виробництва серверів з обчислювальною потужністю вітчизняного виробництва завдовжки 148 метрів — від підписання угоди до запуску пройшло лише 180 днів.
Основою цієї лінії є дві повністю вітчизняні чіпси: процесор Loongson 3C6000 та AI-акселератор Taichu Yuanqi T100. Процесор Loongson 3C6000 має повністю власну архітектуру та інструкційний набір. Taichu Yuanqi розроблений командою Національного суперкомп’ютерного центру в Усі та Тсінхуа, використовує гетерогенну багатоядерну архітектуру.
Коли ця лінія працює на повну потужність, один сервер збирається кожні 5 хвилин. Загальні інвестиції в цю виробничу лінію становлять 1,1 млрд юанів, і передбачається виробництво 100 000 одиниць на рік.
Ще важливіше, що на основі цих національних чіпів сформовані кластери з мільйоном прискорювачів, які вже виконують справжні завдання навчання великих моделей.
У січні 2026 року Zhipu AI у співпраці з Huawei випустила GLM-Image — першу SOTA модель генерації зображень, повністю навчену на китайських чіпах. У лютому кількісна модель «Сінчжень» від China Telecom була повністю навчена на китайському обчислювальному кластері з мільйоном прискорювачів у Лінгані, Шанхай.

Значення цих прикладів полягає в тому, що вони підтверджують одне: китайські чіпи вже перейшли від «можливості використання для висновків» до «можливості використання для навчання». Це якісна зміна. Для висновків потрібно лише запускати вже навчені моделі, і вимоги до чіпа відносно низькі; а для навчання необхідно обробляти величезний обсяг даних, виконувати складні обчислення градієнтів та оновлення параметрів, що вимагає від чіпа обчислювальної потужності, пропускної здатності зв’язку та програмної екосистеми на порядок вищих.
Основною силою, що виконує ці завдання, є чіпси серії Ascend від Huawei. На кінець 2025 року кількість розробників у екосистемі Ascend перевищила 4 мільйони, кількість партнерів — понад 3000, 43 основні великомасштабні моделі від галузі були попередньо навчені на базі Ascend, а більше 200 відкритих моделей були адаптовані. На MWC 2 березня 2026 року Huawei представила на міжнародних ринках нове покоління інфраструктури обчислювальних потужностей SuperPoD.
FP16-потужність Ascend 910B вже відповідає потужності NVIDIA A100. Хоча розрив все ще існує, він перетворився з непридатного на придатний, а з придатного — на той, що поступово стає зручним. Розробка екосистеми не може чекати доки чіп не буде ідеальним — її потрібно масово розгорнути ще на етапі достатньої придатності, використовуючи реальні бізнес-потреби для стимулювання ітерацій чіпа та програмного забезпечення. Цілі ByteDance, Tencent та Baidu щодо впровадження серверів з китайськими обчислювальними рішеннями у 2026 році загалом подвоються порівняно з попереднім роком. Дані Міністерства промисловості та інформатизації Китаю показують, що обчислювальна потужність Китаю в галузі штучного інтелекту вже досягла 1590 EFLOPS. 2026 рік стає роком масового розгортання китайських обчислювальних потужностей.
Перебої з електроенергією в США та виїзд китайських компаній за кордон
На початку 2026 року Вірджинія, яка несе велику частину трафіку центрів обробки даних світу, призупинила затвердження нових проектів будівництва центрів обробки даних. Джорджія слідує за нею, призупиняючи схвалення до 2027 року. Іллінойс і Мічиган також ввели обмеження.
За даними Міжнародного енергетичного агентства, у 2024 році споживання електроенергії центрами обробки даних у США досягло 183 ТВт·год, що становить близько 4% від загального обсягу споживання електроенергії в країні. До 2030 року ця цифра, як очікується, подвоїться до 426 ТВт·год, і частка може перевищити 12%. Генеральний директор компанії Arm навіть передбачає, що до 2030 року центри обробки даних з використанням ШІ споживатимуть 20–25% електроенергії США.
Електромережі США вже не витримують навантаження. Електромережа PJM, яка охоплює 13 штатів східного узбережжя США, стикається з дефіцитом потужності в 6 ГВт. До 2033 року США в цілому будуть мати дефіцит електроенергії в 175 ГВт, що відповідає споживанню електроенергії 130 мільйонами домогосподарств. Витрати на оптову електроенергію в регіонах з концентрацією центрів обробки даних зросли на 267% порівняно з п’ятьма роками тому.
Кінцевою межею обчислювальної потужності є енергія. І в цьому аспекті розрив між Китаєм і США ще більший, ніж у чіпах, лише напрямок зворотній.
Річний обсяг виробництва електроенергії в Китаї становить 10,4 трильйона кіловат-годин, у США — 4,2 трильйона кіловат-годин, тобто Китай в 2,5 рази більше, ніж США. Ще важливіше те, що електропостачання для побутових потреб у Китаї становить лише 15% від загального споживання, тоді як у США цей показник становить 36%. Це означає, що в Китаї є значно більший потенціал промислового електроспоживання, який можна спрямувати на розвиток обчислювальних потужностей.
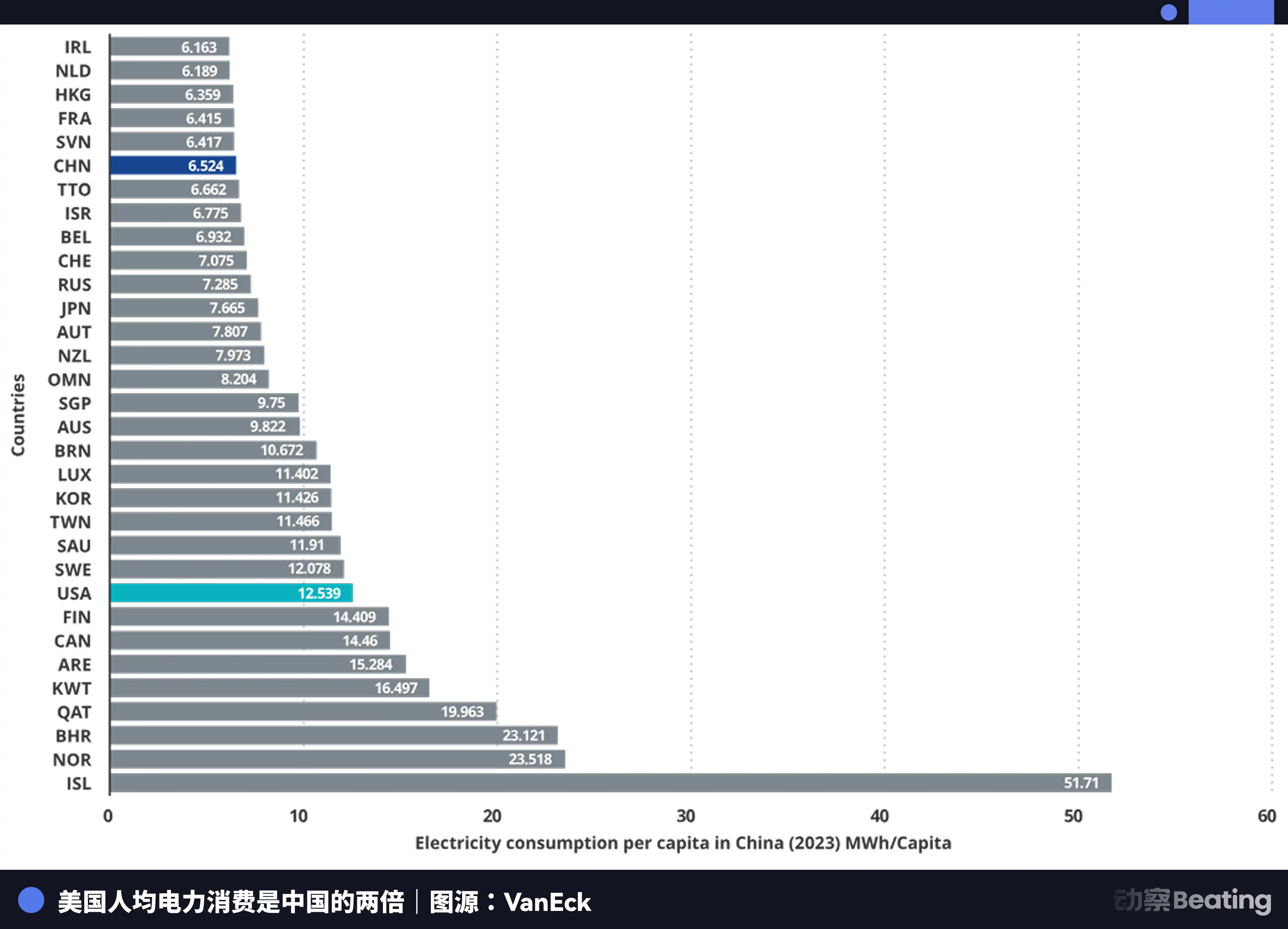
Щодо цін на електроенергію, ціни на електроенергію в районах США, де зосереджені AI-компанії, становлять від 0,12 до 0,15 долара США за кВт·год, тоді як промислові ціни на електроенергію в західному Китаї становлять близько 0,03 долара США — лише чверть або п’ята частина від цін у США.
Збільшення виробництва електроенергії в Китаї досягло семикратного рівня США.
Поки США стурбовані електроенергією, китайські AI тихо розширюються за кордон. Але на цей раз за кордон виходить не продукт, не завод, а токен.
Токен, найменша одиниця інформації, що обробляється моделями ШІ, стає новим цифровим товаром. Він виробляється у китайських фабриках обчислювальних потужностей і доставляється по підводним кабелям по всьому світу.
Дані про розподіл користувачів DeepSeek дуже показові: Китай — 30,7%, Індія — 13,6%, Індонезія — 6,9%, США — 4,3%, Франція — 3,2%. Він підтримує 37 мов і користується популярністю на нових ринках, таких як Бразилія. Глобально 26 000 компаній відкрили облікові записи, а 3200 організацій розгорнули корпоративну версію.
У 2025 році 58% нових AI-стартапів включили DeepSeek до свого технічного стеку. У Китаї DeepSeek займає 89% ринкової частки. У інших країнах, що підлягають санкціям, частка ринку варіюється від 40% до 60%.
Ця сцена нагадує іншу війну за промислову автономію, яка відбувалася чотири десятиліття тому.
У Токіо 1986 року, під сильним тиском США, японський уряд підписав Угоду про напівпровідники між Японією та США. Основні положення угоди: вимога відкрити японський ринок напівпровідників, частка американських чіпів на японському ринку має становити більше 20%; заборона на експорт японських напівпровідників за цінами нижчими за собівартість; накладення 100% каральних мит на 300 мільйонів доларів США експортованих чіпів з Японії. Крім того, США заборонили придбання Fushitsu компанії Fairchild Semiconductor.
У цей рік японська напівпровідникова галузь перебувала на піку. У 1988 році Японія контролювала 51% світового ринку напівпровідників, а США — лише 36,8%. З десяти найбільших напівпровідникових компаній світу шість були японськими: NEC на другому місці, Toshiba на третьому, Hitachi на п’ятому, Fujitsu на сьомому, Mitsubishi на восьмому та Panasonic на дев’ятому. У 1985 році Intel зазнала збитків у розмірі 173 мільйони доларів США у боротьбі за ринок між США та Японією і опинилася на межі банкрутства.
Але після підписання угоди все змінилося.
США застосували всебічне тиснення на японські напівпровідникові підприємства за допомогою розслідувань розділу 301 та інших засобів. Водночас вони підтримували корейські Samsung і SK Hynix, щоб знизити ціни та вплинути на японський ринок. Доля Японії на ринку DRAM впала з 80% до 10%. До 2017 року частка Японії на ринку ІС становила лише 7%. Колишні гіганти, які раніше були неперевершеними, були або розділені, або поглинуті, або вийшли з ринку в результаті безперервних збитків.
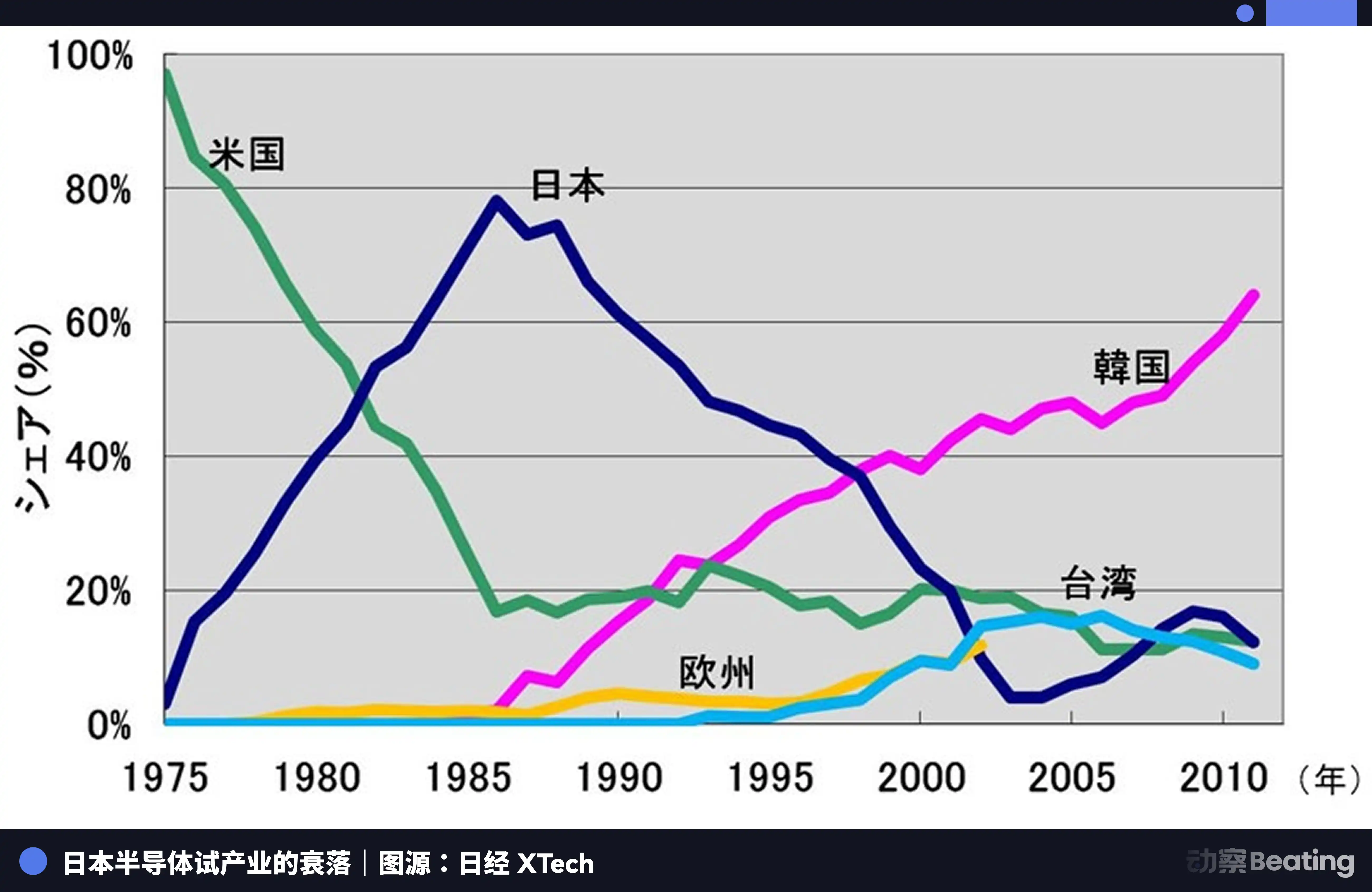
Трагедія японської напівпровідникової промисловості полягає в тому, що вона задовольнялася роллю найкращого виробника в глобальній системі розподілу праці, що керується однією зовнішньою силою, і ніколи не намагалася створити власну, незалежну екосистему. Коли відплив виявився, виявилось, що крім виробництва, у неї нічого немає.
Сьогодні китайська галузь ШІ стоїть на схожому, але повністю іншому розгалуженні.
Подібним чином, ми також стикаємося з величезним тиском ззовні. Три цикли обмежень на чіпи, поступове посилення, бар’єри екосистеми CUDA залишаються високими.
Відмінність у тому, що на цей раз ми обрали більш складний шлях: від екстремальної оптимізації на рівні алгоритмів, до переходу від висновку до навчання на китайських чіпах, до накопичення 4 мільйонів розробників у екосистемі Ascend, до проникнення Token на глобальні ринки. Кожен крок цього шляху будує незалежну промислову екосистему, якої Японія коли-небудь не мала.
Фінал
27 лютого 2026 року три проміжні звіти про фінансові результати від місцевих компаній з виробництва AI-чіпів були опубліковані в один день.
Wudangji, дохід збільшився на 453%, вперше досягнув прибутку за рік. Moerxianshu, дохід збільшився на 243%, але чистий збиток склав 1 млрд. Muqi, дохід збільшився на 121%, чистий збиток майже 800 млн.
Половина — вогонь, половина — море.
Пожежа — це крайній голод ринку. Ті 95% порожніх місць, що їх залишив Хуан Ренсюнь, поступово заповнюються доходами цих місцевих компаній. Незалежно від продуктивності чи екосистеми, ринок потребує другого варіанту крім NVIDIA. Це геополітично відкритий безпрецедентний структурний шанс.
Морська вода — це величезна вартість екологічного розвитку. Кожна втрата — це реальні гроші, витрачені на те, щоб наздогнати екосистему CUDA. Це інвестиції в розробку, субсидії на програмне забезпечення, витрати на інженерів, яких направляють на місця клієнтів, щоб індивідуально вирішувати проблеми компіляції. Ці втрати — не результат поганого менеджменту, а необхідний «воєнний податок» за створення незалежної екосистеми.
Ці три фінансові звіти чесніше за будь-який галузевий звіт документують справжній обличчя цієї війни за хеш-потужність. Це не перемога з піднятими прапорами, а жорстока позиційна битва, де бійці йдуть у атаку, проливаючи кров.
Але форма війни справді змінилася. Вісім років тому ми обговорювали питання «чи зможемо вижити». Сьогодні ми обговорюємо питання «яку ціну доведеться заплатити за виживання».
Ціна сама по собі — це прогрес.
Натисніть, щоб дізнатися про вакансії в律動BlockBeats
Вступайте до офіційного спільноти律动 BlockBeats:
Телеграм-канал з підпискою: https://t.me/theblockbeats
Telegram-чат: https://t.me/BlockBeats_App
Офіційний аккаунт Twitter: https://twitter.com/BlockBeatsAsia