










Автор оригіналу: KarenZ, Foresight News
20 березня 2026 року в подкасті All-In Ventures відбувся незвичайний діалог.
Інвестор-венчурник Чамат Паліхапітія передав слово генеральному директору NVIDIA Хуану Ренсюню, сказавши, що на Bittensor існує проект, який «здійснив досить божевільне технічне досягнення» — навчив велику мовну модель за допомогою розподілених обчислювальних ресурсів у Інтернеті, повністю децентралізовано, без участі будь-яких централизованих центрів обробки даних.
Хуан Ренсюнь не уникав цього. Він порівняв це з «сучасною версією Folding@home» — розподіленим проектом, який у 2000-х роках дозволяв звичайним користувачам вносити свій внесок у вирішення проблеми згортання білків, надаючи вільну обчислювальну потужність.
За 4 дні до цього, 16 березня, співзасновник Anthropic Джек Кларк у звіті про прогрес у дослідженнях ШІ також детально розглянув і посилався на цей прорив: екосистема Bittensor підмережа Templar (SN3) завершила розподілене навчання великої моделі з 72 мільярдами параметрів (Covenant 72B), продуктивність якої порівнянна з LLaMA-2, опублікованим Meta у 2023 році.
Джек Кларк назвав цей розділ «Виклик політичної економії ШІ за допомогою розподіленого навчання» і підкреслив у своєму аналізі, що це технологія, яку варто постійно стежити — він може уявити майбутнє, коли пристроєвий ШІ широко використовуватиме моделі, навчені за допомогою децентралізованого навчання, тоді як хмарний ШІ продовжуватиме запускати власні великі моделі.
Реакція ринку трохи запізнюється, але дуже сильна: SN3 за останній місяць зросла більше ніж на 440%, за останні два тижні — більше ніж на 340%, а її ринкова капіталізація досягла 130 мільйонів доларів США. Народження історії про субсети безпосередньо передається як тиск на покупку TAO. Тому TAO швидко зросла, досягнувши 377 доларів США, подвоївшись за останній місяць, а FDV досягла приблизно 7,5 мільярда доларів США.
З’являється питання: що саме зробило SN3? Чому його вивели на перший план? Як змінюватиметься історія цінності розподіленого навчання та децентралізованого ШІ?
Той модель на 72B
Щоб відповісти на це питання, спочатку треба уважно подивитися на результати SN3.
10 березня 2026 року команда Covenant AI опублікувала технічний звіт на arXiv, офіційно оголосивши про завершення навчання Covenant-72B. Це велика мова модель з 72 мільярдами параметрів, яка була попередньо навчена на корpusі з приблизно 1,1 трильйона токенів за допомогою більше ніж 70 незалежних вузлів-пірів (приблизно 20 вузлів синхронізувалися на кожному етапі, кожен вузол був оснащений 8 картами B200).
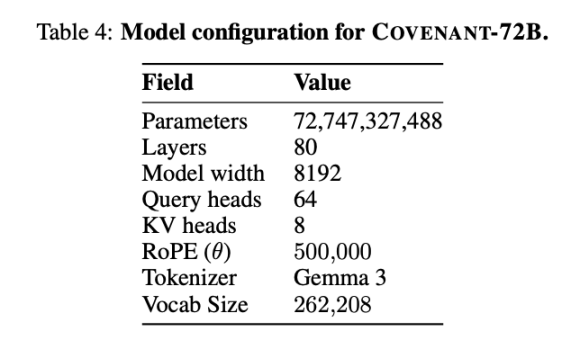
Templar навів деякі дані щодо тестування, при цьому порівнюваний LLaMA-2-70B — це велика модель, випущена Meta у 2023 році. Як зазначив співзасновник Anthropic Джек Кларк, Covenant-72B у 2026 році може виглядати застарілим. Результат Covenant-72B у 67,1 бала на MMLU приблизно відповідає результату LLaMA-2-70B, випущеного Meta у 2023 році (65,6 бала).
А передові моделі 2026 року — будь то серія GPT, Claude чи Gemini — вже навчалися на десятках тисяч GPU з параметрами, що перевищують 100 мільярдів; різниця в здатностях до висновків, кодування та математики — це питання порядків величини, а не відсотків. Цю реальну різницю не слід заглушати ринковими настроїми.
Але в контексті «навчання за допомогою розподілених обчислювальних потужностей відкритого Інтернету» це має зовсім інший зміст.
Порівняйте: INTELLECT-1 (від команди Prime Intellect, 10 мільярдів параметрів) має результат MMLU 32,7 при децентралізованому навчанні; інший проект з розподіленим навчанням серед учасників з білого списку — Psyche Consilience (40 мільярдів параметрів) — набрав 24,2. Covenant-72B з масштабом 72B та результатом MMLU 67,1 є вражаючим показником у сфері децентралізованого навчання.
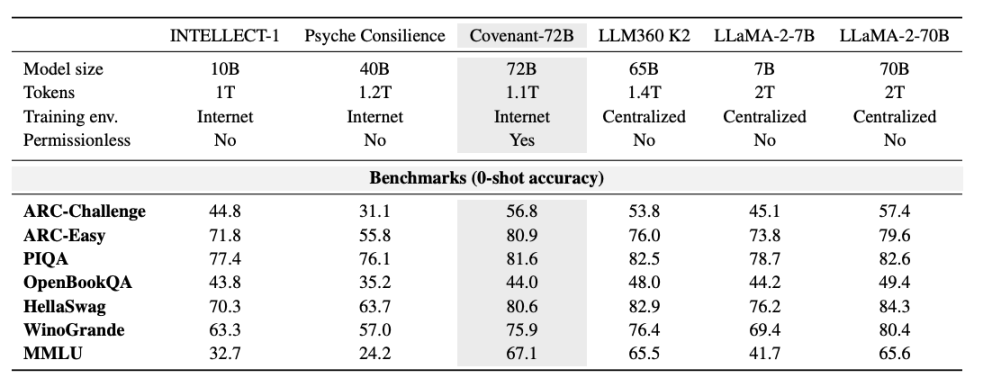
Ще важливіше, це навчання є «без дозволу». Будь-хто може підключитися як вузол-учасник, без попереднього розгляду чи додавання до білого списку. Більше 70 незалежних вузлів взяли участь у оновленні моделі, надаючи обчислювальну потужність з усього світу.
Що сказав Хуан Ренсюнь, а що не сказав
Відновлення деталей того подкаст-діалогу допоможе скоригувати зовнішнє тлумачення цього «підтримки».
Чамат Паліхапітія під час діалогу представив технічні досягнення Bittensor перед Хуань Ренсюнем, описавши їх як навчання моделі Llama за допомогою розподілених обчислювальних ресурсів, при цьому процес був «повністю розподілений, зі збереженням стану». Реакція Хуань Ренсюня полягала у порівнянні цього з «сучасною версією Folding@home» та розгортанні дискусії про необхідність паралельного існування відкритих та пропрієтарних моделей.
Варто зауважити, що Хуан Ренсюнь не згадував безпосередньо токен Bittensor чи будь-які інвестиційні аспекти, а також не продовжував обговорення децентралізованого навчання штучного інтелекту.
Розуміння підмереж Bittensor та SN3
Щоб зрозуміти прорив SN3, спочатку потрібно зрозуміти логіку роботи Bittensor та його субсетів. Просто кажучи, Bittensor можна розглядати як блокчейн та платформу для ШІ, а кожна субсіть — як окрема «лінія виробництва ШІ» з чітко визначеними основними завданнями та механізмами стимулювання, що разом утворюють децентралізовану екосистему ШІ.
Його робочий процес є чітким та децентралізованим: власники підмереж визначають цілі підмережі та розробляють моделі стимулювання; майни надають обчислювальну потужність у підмережі та виконують завдання, пов’язані з ШІ (наприклад, висновки, навчання, зберігання тощо); верифікатори оцінюють внесок майнерів та завантажують оцінки до консенсусного рівня Bittensor; нарешті, алгоритм консенсусу Yuma Bittensor розподіляє відповідні винагороди учасникам підмережі на основі накопичених нагород у кожній підмережі.
На Bittensor зараз існує 128 підмереж, які охоплюють різноманітні завдання штучного інтелекту, такі як висновок, серверна AI-хмарна служба, зображення, анотація даних, підсилене навчання, зберігання та обчислення.
SN3 — це одна з підмереж. Вона не створює оболонку рівня застосунків і не орендує готові API великих моделей, а напряму звертається до одного з найдорожчих і найзакритіших сегментів цілого ланцюжка ІШ: до попереднього навчання великих моделей.
SN3 прагне використовувати мережу Bittensor для координації розподіленого навчання з використанням гетерогенних обчислювальних ресурсів, довівши, що за допомогою стимульованого розподіленого навчання великих моделей можна створювати потужні базові моделі без дорогих централизованих кластерів суперкомп’ютерів. Основна привабливість полягає у «рівності» — зламати монополію централизованого навчання на ресурси і дозволити звичайним особам чи малим та середнім організаціям брати участь у навчанні великих моделей, одночасно знижуючи витрати на навчання завдяки розподіленій обчислювальній потужності.
Основною силою, що розвиває SN3, є Templar, за яким стоїть дослідницька команда Covenant Labs. Ця команда також керує ще двома підмережами: Basilica (SN39, зосереджена на обчислювальних послугах) та Grail (SN81, зосереджена на RL-післянавчанні та оцінці моделей). Три підмережі утворюють вертикально інтегровану систему, яка повністю охоплює весь цикл розробки великих моделей — від попереднього навчання до оптимізації згідності, створюючи повноцінну екосистему децентралізованого навчання великих моделей.
Зокрема, майни вносять обчислювальні ресурси, завантажуючи градієнтні оновлення (напрямок і сила налаштування параметрів моделі) до мережі; верифікатори оцінюють якість внеску кожного майна, надаючи на ланцюзі оцінки залежно від ступеня покращення похибки. Результат визначає вагу нагород, яка автоматично розподіляється без необхідності довіряти будь-якій третій стороні.
Ключ до дизайну мотиваційної системи полягає в тому, що винагорода безпосередньо пов’язана з «наскільки ваш внесок покращив модель», а не просто з відвідуванням обчислювальних ресурсів. Це фундаментально вирішує найскладнішу проблему в децентралізованих сценаріях: як запобігти ліні з боку майнерів.
Як Covenant-72B вирішує проблеми ефективності зв’язку та відповідності стимулів?
Скоординувати навчання однієї моделі між десятками вузлів, які не довіряють один одному, мають різне обладнання та різну якість мережі, — це дві виклики: перший — ефективність зв’язку, стандартні схеми розподіленого навчання вимагають високої пропускної здатності та низької затримки між вузлами; другий — відповідність інcentивів, як запобігти зловмисним вузлам, що надсилають неправильні градієнти? Як забезпечити, щоб кожен учасник справді навчався, а не копіював результати інших?
SN3 вирішує ці дві проблеми за допомогою двох основних компонентів: SparseLoCo та Gauntlet.
SparseLoCo вирішує проблему ефективності зв’язку. У традиційному розподіленому навчанні на кожному кроці синхронізуються повні градієнти, що призводить до величезного обсягу даних. Підхід SparseLoCo полягає в тому, що кожен вузол виконує 30 внутрішніх оптимізацій (AdamW) локально, а потім стискає та завантажує «псевдоградієнти» іншим вузлам. Методи стиснення включають Top-k розрідження (зберігання лише найважливіших компонентів градієнта), зворотний зв’язок по помилці (збереження відкинутих частин для накопичення у наступному циклі) та 2-бітне квантування. Кінцевий коефіцієнт стиснення перевищує 146 разів.
Іншими словами, замість передачі 100 МБ тепер достатньо менше ніж 1 МБ.
Це дозволяє системі підтримувати використання обчислювальних ресурсів на рівні приблизно 94,5% при обмеженнях пропускної здатності звичайного інтернету (110 Мбіт/с вгору, 500 Мбіт/с вниз) — 20 вузлів, по 8 B200 на вузол, кожна комунікаційна ітерація триває лише 70 секунд.
Gauntlet вирішує проблему стимулів. Він працює на блокчейні Bittensor (Subnet 3) і відповідає за перевірку якості псевдоградієнтів, наданих кожним вузлом. Це здійснюється шляхом тестування невеликою вибіркою даних: «наскільки знизилася втрата моделі після застосування градієнта цього вузла» — цей результат називається LossScore. Крім того, система перевіряє, чи вузол навчається саме на виділених йому даних — якщо втрата на випадкових даних зменшується краще, ніж на виділених даних, вузол отримує негативний бал.
На завершальному етапі кожного циклу навчання до агрегації підключаються градієнти лише тих вузлів, які отримали найвищий рейтинг, інші вузли виключаються з цього циклу. Зайві учасники замінюються в реальному часі, щоб забезпечити стабільність системи. Протягом усього процесу навчання в середньому на кожному циклі до агрегації підключаються градієнти 16,9 вузлів, а загальна кількість унікальних ID вузлів, які брали участь, перевищує 70.
Ціннісна історія децентралізованого ШІ зазнає фундаментальної зміни
З технічної та галузевої точок зору, напрямок, який представляє Covenant-72B, має кілька реальних значень.
По-перше, було зруйновано припущення, що розподілене навчання підходить лише для невеликих моделей. Хоча ще далеко до передових моделей, це підтвердило масштабованість цього напрямку.
Друге, бездозвольна участь є реальністю. Цей аспект недооцінено. Попередні проекти розподіленого навчання залежали від білого списку — лише схвалені учасники могли надавати обчислювальну потужність. У цьому навчанні SN3 будь-хто з достатньою обчислювальною потужністю може підключитися, а механізм перевірки відповідає за фільтрацію зловмисних внесків. Це конкретний крок до «справжньої децентралізації».
Третє, механізм dTAO Bittensor робить можливим ринкове визначення вартості підмереж. dTAO дозволяє кожній підмережі випускати власний токен Alpha, за допомогою механізму AMM ринок визначає, які підмережі отримують більше TAO. Це надає таким підмережам, як SN3, які досягли конкретних результатів, схему грубої, але ефективної механізми захоплення вартості. Звичайно, цей механізм також піддається впливу історій та емоцій, оскільки якість результатів навчання LLM важко оцінити незалежно звичайним учасникам ринку.
Четверте, політико-економічні наслідки децентралізованого навчання ШІ. Джек Кларк у Import AI підняв це питання до рівня «Хто володіє майбутнім ШІ?». Поточне навчання передових моделей монополізоване невеликою кількістю інституцій, що володіють величезними центрами обробки даних, і це не лише бізнесова, а й проблема структури влади. Якщо розподілене навчання зможе постійно досягати технологічного прогресу, воно може сформувати справжньо децентралізовану екосистему розробки для певних типів моделей (наприклад, невеликих передових моделей у спеціалізованих галузях). Однак ця перспектива наразі ще дуже віддалена.
Підсумок: справжній етап, а також купа справжніх проблем
Хуан Ренсюнь сказав, що це схоже на «сучасну версію Folding@home». Folding@home зробив реальний внесок у сферу молекулярного моделювання, але не ставив під загрозу ключову дослідницьку позицію великих фармацевтичних компаній. Ця аналогія дуже точна.
SN3 успішно реалізував протокол і підтвердив перспективність розподілених обчислень. Але з технічної та галузевої точок зору, за цим результатом приховано багато питань, про які майже ніхто не хоче серйозно говорити:
MMLU сам по собі є спірним показником у науковому середовищі, оскільки існує ризик витоку питань та відповідей з публічних тестів до тренувальних наборів. Ще більш важливим є вибір базових моделей для порівняння: у статті порівнюються LLaMA-2-70B та LLM360 K2 — обидві старі моделі 2023–2024 років, тоді як результати в діапазоні 65–70 балів у запитах до Grok та DouBao вважаються середніми або початковими, а в оцінці Claude — серйозно відсталими. Якщо ці моделі порівняти з динамічно оновлюваними рейтингами або новими базами, розробленими з урахуванням захисту від забруднення, висновки можуть бути набагато чеснішими.
Ще важливіше, що якісні дані, які визначають межі можливостей моделей — діалоги, код, математичні доведення, наукові публікації — найімовірніше знаходяться у власності великих компаній, видавництв та академічних баз даних. Обчислювальні ресурси демократизувалися, але в сфері даних залишається олігополістична структура — цей конфлікт ніколи не обговорювався.
Щодо безпеки, участь без дозволу означає, що ви не знаєте, хто стоїть за цими 70+ вузлами, і які дані вони використовують для навчання. Gauntlet може фільтрувати очевидно аномальні градієнти, але не може запобігти тонкому отруюванню даних — якщо один з вузлів систематично навчається кілька додаткових ітерацій на певному типі шкідливого контенту, зміни градієнтів будуть достатньо дрібними, щоб пройти перевірку за оцінкою втрат, але спричинити накопичувальне зміщення поведінки моделі. Остаточне питання: які ризики виникають при використанні моделі, навченої за участю невеликої кількості анонімних вузлів із неповною відстежуваністю джерел даних, у сценаріях з високими вимогами до відповідності та безпеки, таких як фінанси, охорона здоров’я та право?
Існує ще одна структурна проблема, яку варто висловити прямо: Covenant-72B сам по собі є відкритим кодом за ліцензією Apache 2.0 і не використовує токени SN3. Утримання токенів SN3 дає доступ до частки від емісійного доходу, що генерується майбутнім безперервним виведенням нових моделей цим субнетом, а не до будь-якого прямого доходу від використання моделі. Ця ланцюжкова цінність залежить від безперервного навчання та здорового функціонування загальної механіки емісії мережі Bittensor. Якщо в майбутньому навчання зупиниться або якість нових результатів навчання не відповідатиме очікуванням, логіка оцінки токенів почне руйнуватися.
Ці питання наведено не для того, щоб заперечувати значення Covenant-72B. Він довів, що те, що раніше вважалося неможливим, можливе — цей факт не зникне. Але зробити це і зрозуміти, що це означає, — це дві різні речі.
Токен SN3 за останній місяць зрос на 440%. Ця відстань, можливо, не є просто спекуляцією, а відображає те, що нарратив завжди рухається швидше, ніж реальність. Те, чи буде ця відстань врешті-решт заповнена реальністю, чи поглинена ринком, залежить від того, що команда Covenant AI насправді представить далі.
Варто звернути увагу, що Grayscale подала заявку на TAO ETF у січні 2026 року, що вказує на сигнал входу інституційного капіталу в цей сектор. Крім того, у грудні 2025 року Bittensor зменшив щоденний випуск TAO наполовину, і структурне звуження пропозиції продовжує розвиватися.
Посилання для довідки:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95