









Чи можуть роботи мріяти? Якщо вони мріють, то чи бачать вони електричних овець?

Кадр із фільму «Бегець з майбутнього»
У 1968 році, коли автор науково-фантастичного роману, на якому заснований фільм «Бегець з майбутнього», Філіп К. Дік, набирав це абстрактне й попереднє питання на машинці, він, напевно, не міг уявити, що напіввіку пізніше титани технологій з Сіліконової долини серйозно дадуть на нього відповідь.
Так, вони не лише бачать сни про електронних овець, а й можуть візуалізувати ці сни.
Вчора Anthropic на конференції розробників у Сан-Франциско представила серію нових функцій для платформи створення агентів Managed Agents: розширення пам’яті, виведення результатів, співпраця між кількома агентами та «сон (Dreaming)».
За словами Anthropic, «пам’ять та мрії разом утворюють стійку систему пам’яті агента, здатного до самовдосконалення».

Знову сни, знову пам’ять — друзі, які не дуже стежать за розвитком ІІ, напевно, зіткнуться зі здивуванням: коли ж ці людські слова почали так плавно застосовуватися до ІІ?
Ще в 2024 році, коли OpenAI представила серію o1, «серію моделей ШІ, розроблених так, щоб витрачати більше часу на міркування перед відповіддю», слово «міркування» використовувалося дуже природно, настільки природно, що ніхто не зупинився, щоб запитати: як же програма, яка статистично передбачає наступний токен, може називатися міркуванням?
За ними йдуть reasoning (міркування), memory (пам’ять), reflection (рефлексія), Imagining (уява) — по черзі переносячи речі, які здатні робити лише люди, на презентації продуктів.

Знімки з фільму «Червона міністр» про сни
«Мислення» ще можна трактувати як метафору, «пам’ять» теж можна вважати розширенням технічного жаргону, але «сон» — це вже трохи багато. Тисячі років філософія, історія та література не змогли цього зрозуміти, а компанії з ШІ прямо кажуть: ми не лише створили машини, що мислять, ми створили машини, що сплять.
Що таке мріяти, чи немає жодного іншого інженерного терміну, який би точно описував цей процес, крім мрії?
Штучний інтелект мріє — і це коштує грошей
Ще до витіку коду Claude Code користувачі виявили, що Anthropic готує функцію під назвою Auto Dreaming. Тоді всі думали: чи потребує ШІ, як і ми, люди, сну та достатнього відпочинку, щоб стати більш зосередженим і розумнішим?
Але достатньо зрозуміти, як працюють сьогоднішні AI-агенти, щоб зрозуміти, що так зване «сон» насправді є лише автоматизованим пакетним обробленням офлайн-журналів.
AI-агент тепер добре впорядається зі складними завданнями з довгим ланцюжком, наприклад: «Допоможи мені дослідити останні фінансові звіти цих п’яти конкурентів і оформити їх у таблицю». У цьому процесі агент повинен переключатися між різними веб-сторінками, читати кілька документів, використовувати різні інструменти та навіть може зіткнутися з механізмами захисту від парсингу, що вимагає повторних спроб.
Після завершення цієї довгої серії складних онлайн-завдань, фонові процеси агента залишать величезну кількість журналів роботи.
Зображення згенероване штучним інтелектом
Функція «сон» від Anthropic полягає у тому, що агент під час простою переглядає ці історичні записи, шукає в них закономірності, наприклад, виявляє, що «кожного разу, коли з’являється таке вікно, його можна закрити, натиснувши на правий верхній кут», і таким чином оптимізує шлях наступної дії.
«Пам’ять» відповідає за захоплення вивченого під час роботи, а «сон» — за витончення цих пам’ятей між сесіями та їх обмін між різними агентами.
Простими словами, це механізм підсиленого навчання на основі історичних даних і самокорекції.

Опис сну: https://platform.claude.com/docs/en/managed-agents/dreams
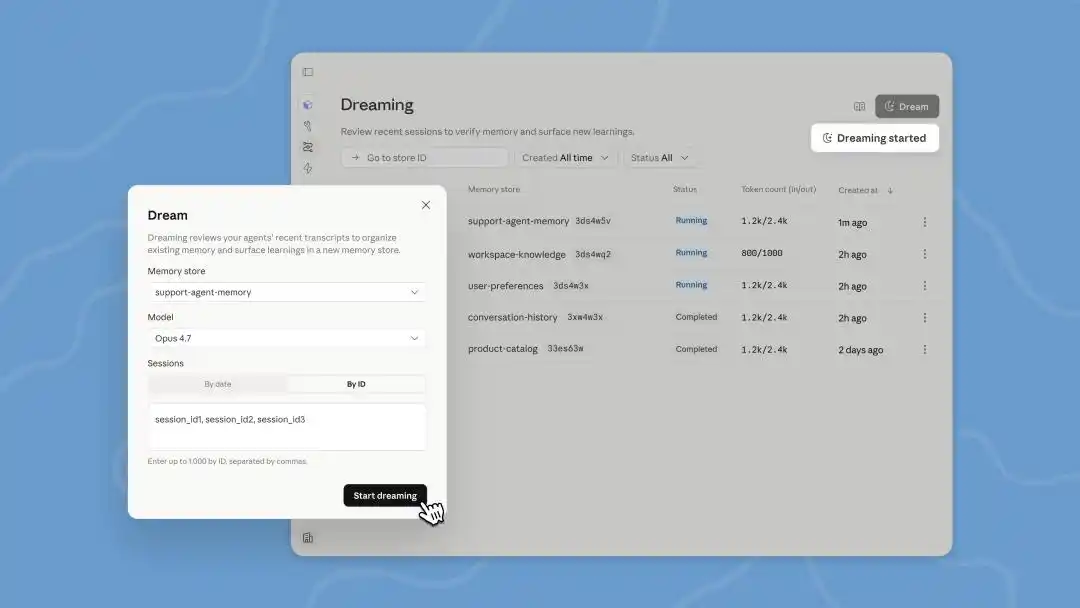
На цій розробницькій конференції оновлено Dreams у Managed Agents — це завдання, яке обробляється у фоновому режимі, і нам потрібно запускати його вручну. Claude може одночасно прочитати історію діалогів до 100 сесій, а потім згенерувати нову версію пам’яті, яку ми можемо перевірити, перш ніж вирішити, чи використовувати її.
AutoDream, який раніше був тихо запущений у Claude Code, після кожного циклу розмови з агентом перевіряє в фоновому режимі, чи варто «приснитися» — за замовчуванням раз на 24 години.
Функція, подібна до сну, також є у Hermes Agent. Hermes Agent зосереджений на здатності самонавчання та еволюції — він підтримує автоматичне виведення досвіду з минулих завдань та зберігає його у файлі пам’яті.

Одна з функцій під назвою Curator може автоматично перетворювати ці витягнуті керівництва на Skill.
Ці навички отримують оцінки, дублікати об’єднуються, а ті, що довго не використовуються, автоматично архівуються, і навіть мають життєвий цикл: active, stale, archived. Ми також можемо закріпити важливі навички, щоб система не видаляла їх автоматично.
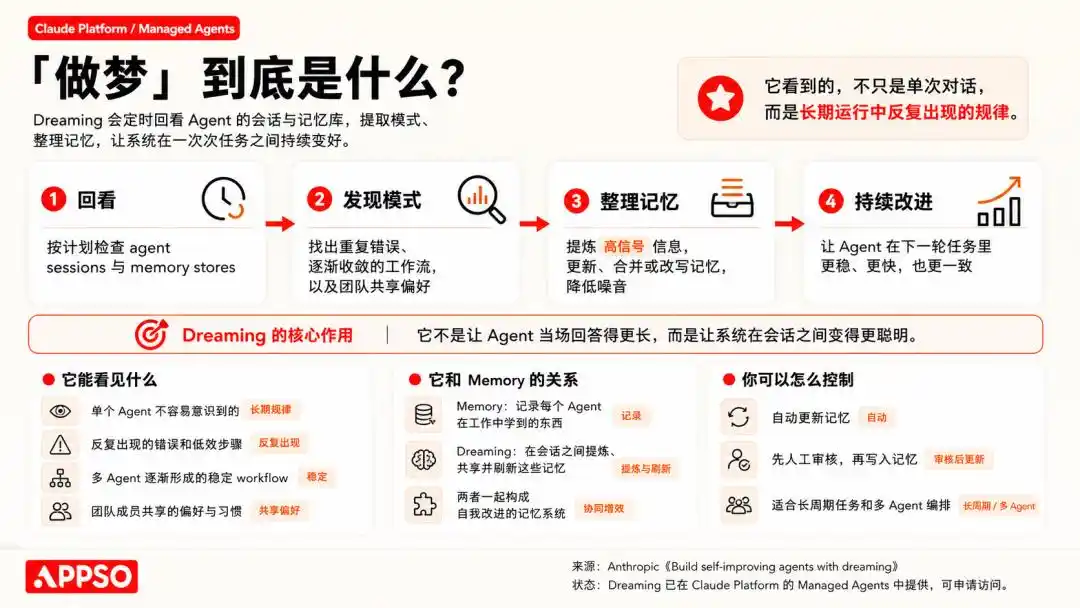
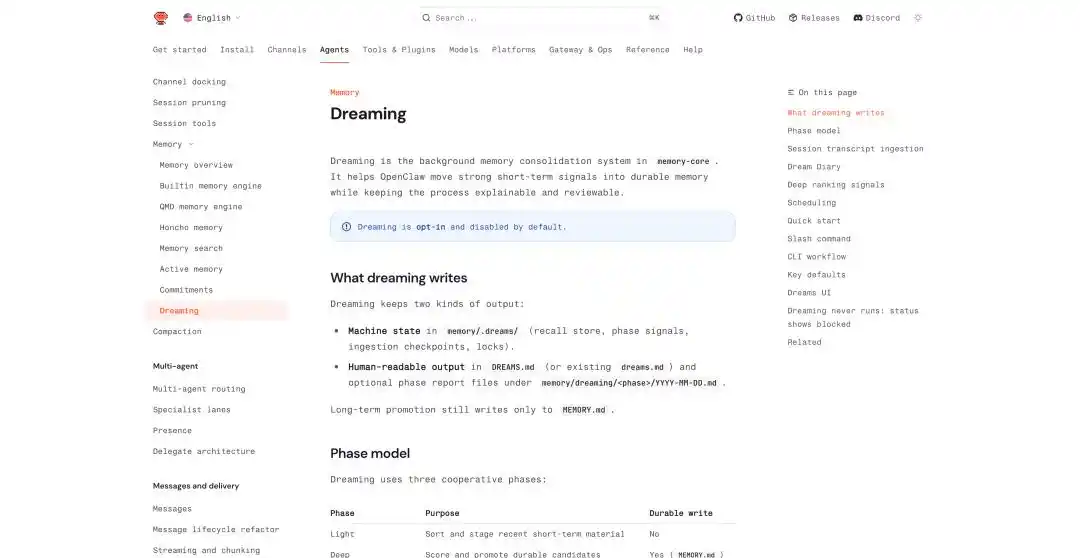
OpenClaw у останніх оновленнях також додав відповідні механізми, такі як тривала пам’ять між діалогами, планування завдань за розкладом, ізольоване виконання під-Agent’ів та функція мріяння, прямо названа Dreaming.
Мрії OpenClaw: https://docs.openclaw.ai/concepts/dreaming
У механізмі мрій OpenClaw він розбиває подорожі мрій на три етапи: light, REM, deep. Перші два відповідають за організацію, рефлексію та узагальнення тем, а deep справді записує вміст у довготривалу пам’ять MEMORY.md.
Закріплення на етапі глибокого сну визначається шістьма зваженими сигналами, чи потрібно записувати їх у довготривалу пам'ять. Ці шість сигналів включають частоту, релевантність, різноманітність запитів, актуальність, повторюваність протягом днів та концептуальну багатість.

Зображення згенероване штучним інтелектом
Запис у довготривалу пам’ять створює два файли: файл стану для машини у memory/.dreams/ та читабельний запис для користувача у DREAMS.md і звітах, згенерованих за етапами.
Крім того, Dreaming може автоматично запускатися за розкладом: за замовчуванням повний цикл виконується щодня о 3:00, у порядку light → REM → deep.
Окрім виводу мрій, OpenClaw підтримує документ під назвою Dream Diary, у якому система автоматично генерує «діарій мрій», що нарисово фіксує процес упорядкування пам’яті, з акцентом на пояснюваність та перевіряємість, а не на чорній скринці.
У нейронауці існує дуже класичне розуміння: інформація, отримана людиною протягом дня, спочатку потрапляє до системи, що працює як тимчасове сховище; під час сну мозок повторно відтворює, закріплює та очищає цю інформацію, залишаючи важливе та відкидаючи беззмістовне.
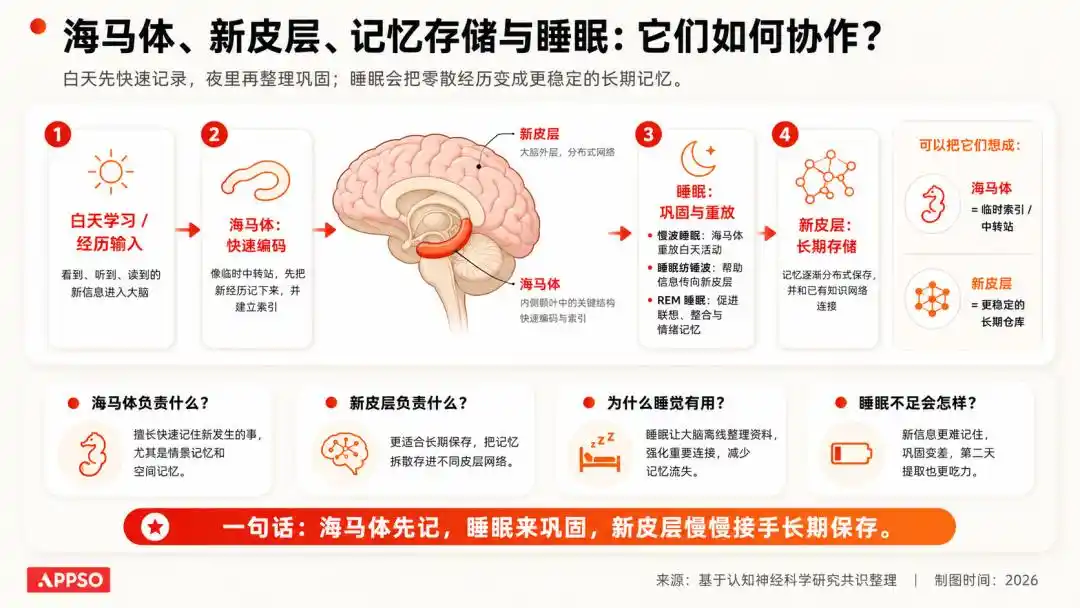
Зображення згенероване штучним інтелектом
Ми не запам’ятаємо кольори кожної машини, з якими зустрілися вчора по дорозі на роботу, але запам’ятаємо, як дістатися до компанії.
Ці сни, звучать так само, як і сни людей, і якщо шукати різницю, то, мабуть, в тому, що коли Claude спить, він все ще споживає наші токени.
Але Anthropic та OpenClaw не вибрали назви на кшталт «оптимізація на основі сеансів» або «післязавданняна настройка», які були б більш інженерно орієнтованими.
В кінці кінців, коли складні назви прямо перетворюються на «мрії», ми відчуваємо не функції програмного забезпечення, а скоріше «цифрове життя з внутрішнім світом».
Пам’ять ШІ — це дрібні контексти
Оскільки згадано «сон», не можна не згадати його передумову — пам’ять (Memory).
За останній час найпопулярнішим терміном у світі ШІ змінився з інженерії підказок на інженерію контексту, інженерію навичок та інженеріюHarness, але незалежно від змін, найбільш цінною залишається інженерія контексту.
Системні підказки, вхідні дані користувача, короткостроковий діалог, довгострокова пам’ять, витягнуті документи, вивід викликів інструментів та навичок, поточний стан користувача — ці шари разом утворюють «контекст», який дійсно використовує агент.
Завжди було складно зробити так, щоб агент міг пам’ятати більше та запам’ятовувати більш корисну інформацію.
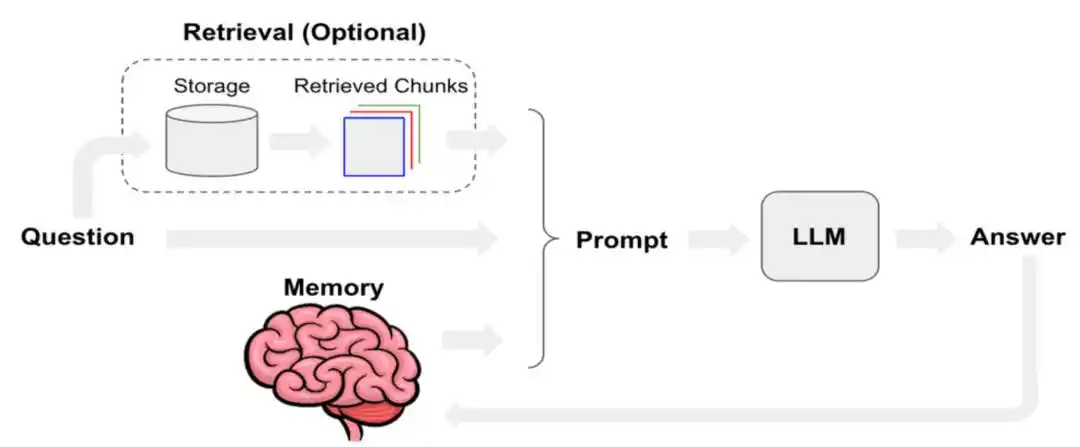
Рік тому Manus опублікував технічний блог, присвячений тому, як Manus оптимізує інженерію контексту. У ньому згадувалося, що коефіцієнт успішності кешу KV визначається як один із найважливіших окремих показників для AI-агентів у виробничому середовищі. Крім того, на рівні викликів інструментів пріоритет надається «закриттю», а не «видаленню»; а також використанню файлової системи як остаточного контексту.
Щоб зрозуміти так званий KV Cache (кеш ключ-значення), уявіть велику модель як людину з надмірною манією, яка може читати лише по одному символу за раз.
Коли він обробляє речення, він обчислює вектори Key (ключ) і Value (значення) для кожного згенерованого токена. Щоб не обчислювати їх знову кожного разу, він зберігає ці пари (K, V) — це і є KV Cache.
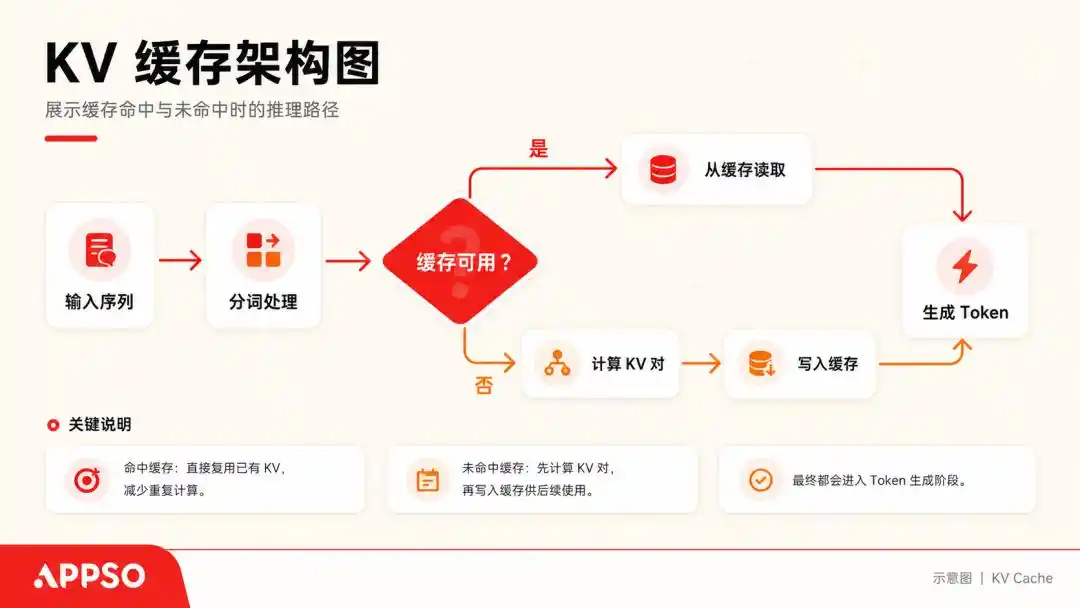
KV Cache (кеш ключ-значення) — це нижчорівнева технологія прискорення, яку велика модель використовує під час генерації тексту для «обміну простору на час». Кеш дозволяє моделі не перераховувати всі попередні слова при прогнозуванні наступного слова. Зображення згенероване ШІ.
Поки діалог триває, KV Cache постійно зберігається. Зазвичай, при роботі з великою моделлю з контекстом 128k, модель з 70 млрд параметрів, що використовує повний контекст 128k, може споживати лише KV Cache до 64 ГБ відеопам’яті.
Також саме тому контекстне вікно більшості моделей наразі становить максимум мільйони.
Вчора нова компанія Subquadratic, яка отримала посівне фінансування на 29 мільйонів доларів США, опублікувала нову модель SubQ на X, з акцентом на довші контексти.

SubQ стверджує, що підтримує контекстне вікно до 12 мільйонів токенів — найбільше з усіх сучасних великих моделей.
Хоча ще немає технічної статті чи документації з описом моделі, у представницькому відео зазначено, що ключова технологічна лінія SubQ полягає у переході від «щільної уваги» традиційного Transformer до архітектури з «півквадратичною / лінійною масштабованою» розрідженою увагою. Нова архітектура має потенціал вирішити проблему експоненційного зростання обчислювальних витрат із збільшенням довжини контексту.

Отримані результати тестування також дуже вражаючі: при 1 мільйоні токенів швидкість зростає більше ніж у 50 разів, а витрати зменшуються більше ніж у 50 разів; при 12 мільйонах токенів потреба у обчислювальних ресурсах зменшується майже в 1000 разів порівняно з передовими моделями.
На бенчмарку RULER 128K довгого контексту Subquadratic заявляє, що SubQ досягає 95% точності при вартості 8 доларів, порівняно з 94% точністю Claude Opus при вартості близько 2600 доларів, що становить зниження витрат приблизно в 300 разів.
Або збільшити вікно контексту, або навчити модель мріяти та самостійно відкидати деякі речі.
Тому продукти агентів, такі як Anthropic, зараз повинні запровадити функцію Dreaming. При обмеженому контекстному вікні розумніші штучні інтелекти не можуть просто додавати більше контенту — їм потрібно діяти цілеспрямовано.
Признати, що машини — це лише машини, складніше, ніж здається
Зрозумівши механізми снів і пам’яті штучного інтелекту, ми, можливо, зможемо з’ясувати його зв’язок із людською діяльністю.
Але, зібравши разом усі ці терміни, створені AI-компаніями для машин: thinking (мислення) від OpenAI, загальноприйняті memory (пам’ять) та hallucination (галюцинації), dreaming (мрії) від Anthropic цього разу, а також добродії та мудрість з конституції Anthropic.
Ми бачимо, що компанії з ІІ далеко не просто продають продукти — вони перерозподіляють власність на слова, що стосуються поняття «людина». Кожне захоплення слова розмиває кордон між машинами та людьми.

Мова формує очікування, очікування формують толерантність, а толерантність визначає, скільки ми готові передати їй. Це довгий ланцюжок, але початок — це безпечні слова з презентації.
Більш прихований вплив полягає у розподілі відповідальності. Коли інструмент описують як сутність, що «мислить», «пам’ятає» і має «цінності», ми природньо сприймаємо його як незалежного «суб’єкта дії» і вважаємо, що цьому ШІ потрібно «навчати», «налаштовувати» або «калібрувати».
Насправді слід запитати компанію, яка розгорнула цю програму в наш робочий процес, та продуктова команда, яка написала слово «dreaming». Як тільки слово змінюється, людина на лаві підсудних також змінюється.
А коли ми бачимо машину, яка «міркує», «пам’ятає» і зараз навіть «спить», ми починаємо несвідомо вірити, що всередині щось є. Бо признати, що це просто машина, — означає втратити досвід «я розмовляю з існуванням, яке міркує», і повернутися до холодних інструментальних відносин.

Опис функції White Day Dream | Зображення створене за допомогою ШІ
Я вже подумав про це: Dreaming (мріяти) — це обробка минулого, а далі компанія AI випустить Daydreaming (деньові мрії), щоб передбачати майбутнє.
Суть полягає в тому, що мрії або відволікання дозволяють агенту у активному стані використовувати невелику частину вільних обчислювальних ресурсів, поєднуючи їх із поточним проектом, щоб одночасно проводити експериментальну генерацію та готуватися до майбутніх завдань.
Цей матеріал з іншого каналу WeChat «APPSO», автор: APPSO — відкриває продукти завтрашнього дня