










Ця думка не виникла нізвідки. Він переглянув багато публічних тестів і виявив, що ШІ швидко прогресує у завданнях, пов’язаних із розробкою ШІ.
Наприклад, CORE-Bench оцінює здатність ШІ реалізовувати дослідження інших наукових статей, що є критично важливим аспектом у дослідженнях ШІ.
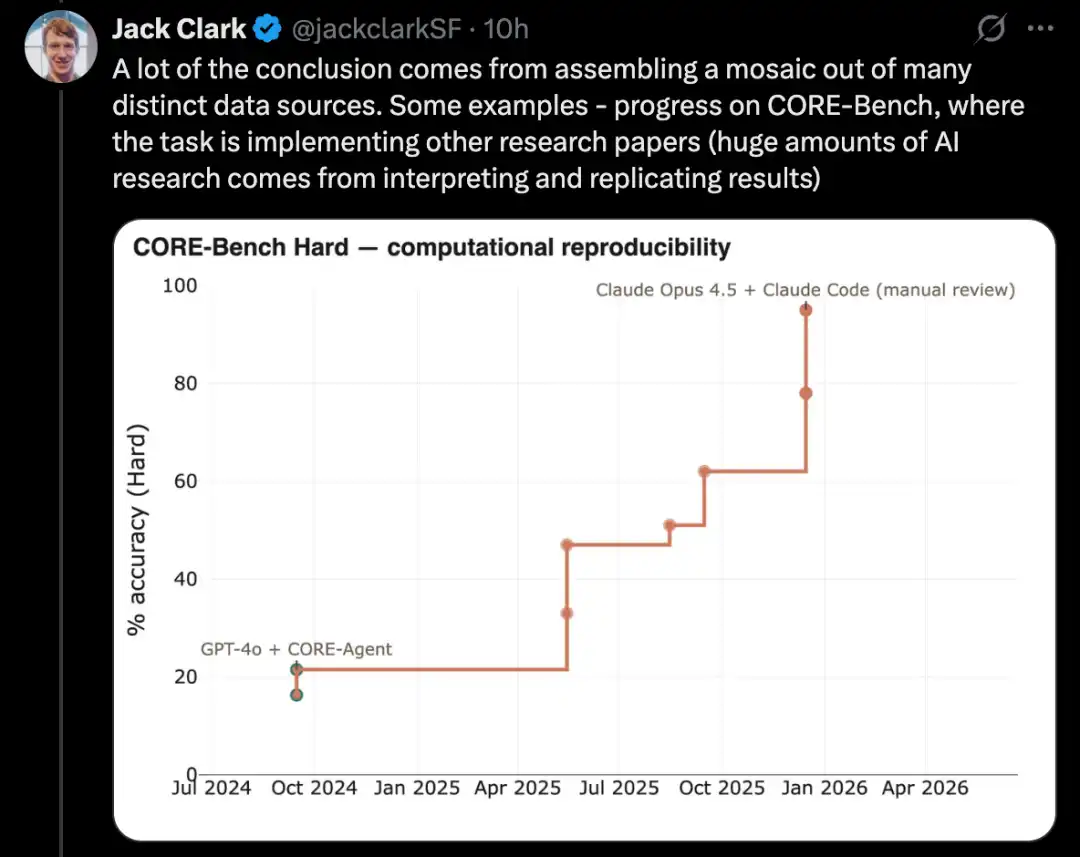
PostTrainBench перевіряє, чи здатні потужні моделі самостійно доналаштовувати слабші відкриті моделі для підвищення їх продуктивності — це саме ключова підмножина завдань з розробки ШІ.
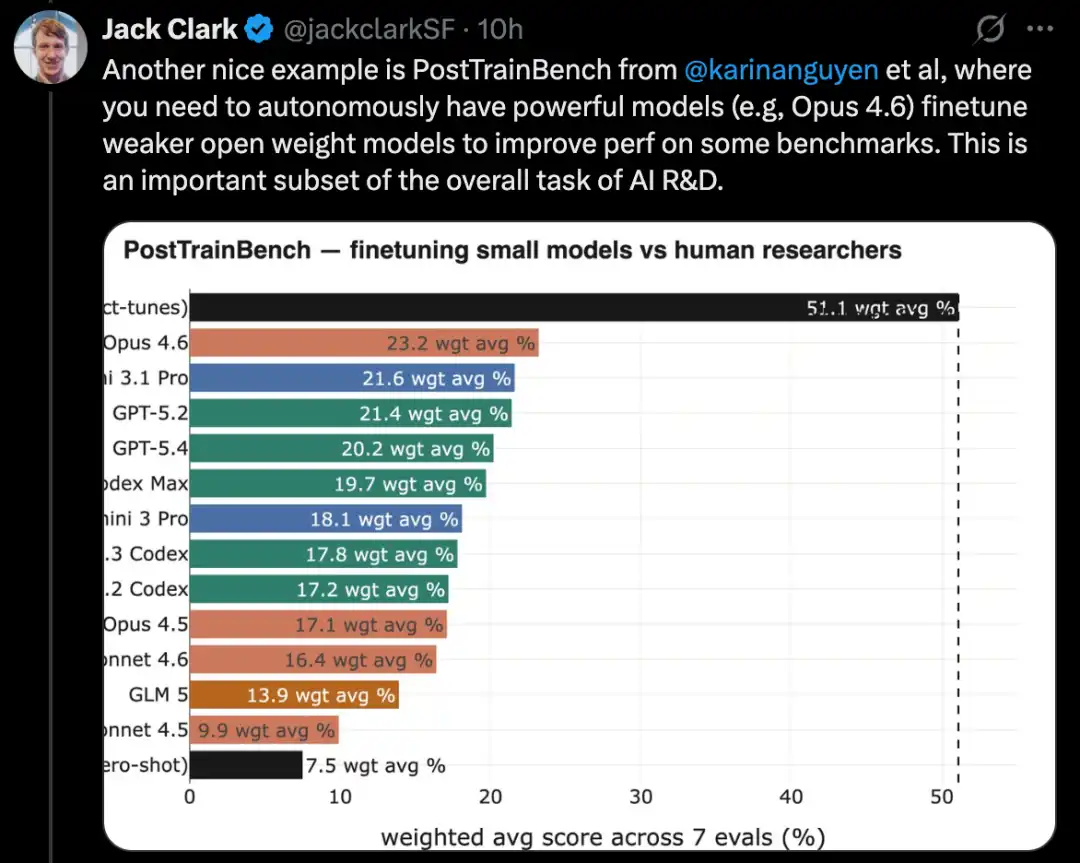
MLE-Bench базується на реальних завданнях з змагань Kaggle і вимагає створення різноманітних застосунків машинного навчання для вирішення конкретних проблем. Крім того, такі відомі кодові бенчмарки, як SWE-Bench, також демонструють подібний прогрес.
Джек Кларк описав це явище як «фрактальний» підйом вгору та вправо, при якому на різних роздільних здатностях і масштабах можна спостерігати значущий прогрес. Він вважає, що ШІ поступово наближається до здатності повністю автоматизувати розробку, і, як тільки це буде досягнуто, ШІ зможе самостійно створювати свої наступні системи, запускаючи цикл самоітерації.

Після цього висловлювання в соціальних мережах розгорілася багато обговорень.
Деякі вважають це ключовим кроком до досягнення ASI та сингулярності, що може корінно змінити темпи розвитку технологій.

Однак існують і інші думки.
Професор комп’ютерних наук у Вашингтонському університеті Педро Домінгос зазначив, що AI-системи мали здатність «будувати себе» ще з часів винайдення мови LISP у 1950-х роках; справжнім питанням є те, чи можна отримати зростаючий прибуток, а наразі немає очевидних доказів на користь цього.

Деякі користувачі висловили сумніви, що ймовірність раптово зросла на 30% з 2027 року до 2028 року, що вказує на те, що здібності ШІ можуть зазнати раптового значного прориву близько кінця 2027 року. Яка саме конкретна віху чи подія призведе до швидкого значного зростання ймовірності рекурсивного самовдосконалення ШІ?

Також користувачі зазначили, що Джек Кларк — новий голова з комунікацій Anthropic, що є частиною їхньої нової стратегії: ми не пугаємо вас, багато наукових статей підтверджують те, про що ми завжди попереджали вас.
Джек Кларк детально розглянув це у довгій статті у newsletterі Import AI 455.
Далі ми повністю розглянемо цю статтю.
Система ШІ скоро почне самобудівництво, що це означає?
Кларк зазначає, що написав цю статтю, оскільки після аналізу всієї відкрито доступної інформації йому довелося зробити не дуже приємний висновок: до кінця 2028 року ймовірність появи AI-досліджень без участі людини вже досить висока — можливо, понад 60%.
Тут під незалежним від людини AI-дослідженням розуміють достатньо потужну AI-систему: вона не лише допомагає людям у дослідженнях, але й може самостійно виконувати ключові етапи розробки, навіть створюючи власну наступну генерацію систем.
За думкою Кларка, це очевидно велика подія.
Він відкрито сказав, що самому йому важко повністю зрозуміти значення цього.
Це називається невтішним рішенням, бо наслідки, що лежать в його основі, надто великі, щоб їх можна було легко оцінити. Кларк також не впевнений, чи суспільство в цілому готове до глибоких змін, що виникнуть через автоматизацію розробки ШІ.
Він зараз вірить, що людство може перебувати у спеціальний момент: дослідження ШІ наблизиться до повної автоматизації. Якщо цей момент справді настане, людство перетне Рубікон і ввійде у майже непередбачуване майбутнє.
Кларк зазначив, що метою цієї статті є пояснення того, чому він вважає, що початок повної автоматизації AI-досліджень вже відбувається.
Він обговорить деякі наслідки цієї тенденції, але більша частина статті буде зосереджена на доказах, що підтверджують цей висновок. Щодо глибших наслідків, Кларк планує продовжити аналіз протягом більшої частини цього року.
З точки зору терміну, Кларк не вважає, що це відбудеться у 2026 році. Але він вважає, що протягом наступних одного-двох років ми можемо побачити приклад, коли модель навчиться самостійно тренувати свою наступну версію. Щонайменше на рівні не передових моделей, створення концепційної перевірки є досить ймовірним; щодо найпередовіших моделей, складність буде вищою, оскільки вони надзвичайно витратні та залежать від інтенсивної роботи великої кількості людських дослідників.
Висновки Кларка засновані переважно на відкритих даних: статтях на arXiv, bioRxiv та NBER, а також продуктах, які передові компанії з штучного інтелекту вже запровадили у реальному світі. На основі цієї інформації він робить висновок, що автоматизація всіх етапів виробництва, необхідних для поточних систем ШІ, зокрема інженерних компонентів у розробці ШІ, вже в цілому здійснена.
Якщо тенденція масштабування продовжиться, ми повинні почати готуватися до ситуації, коли моделі стануть достатньо креативними, щоб не лише автоматично вдосконалювати відомі методи, а й замінювати людських дослідників у формулюванні нових напрямків досліджень та оригінальних ідей, таким чином самостійно рухаючи межі ШІ вперед.
Code Singularity: Change in Ability Over Time
AI-системи реалізуються за допомогою програмного забезпечення, яке складається з коду.
AI-системи повністю змінили спосіб створення коду. За цим стоять два пов’язаних тренди: по-перше, AI-системи все краще вміють писати складний код для реальних умов; по-друге, AI-системи все краще вміють поєднувати багато лінійних завдань програмування без практичної людської контролю, наприклад, спочатку писати код, а потім тестувати його.
Двома типовими прикладами цієї тенденції є SWE-Bench і METR time horizons plot.
Розв’язання проблем програмної інженерії у реальному світі
SWE-Bench — це широко використовуваний програмний тест, призначений для оцінки здатності AI-систем вирішувати реальні проблеми GitHub.
Коли SWE-Bench був запущений наприкінці 2023 року, найкращою моделлю був Claude 2, загальний рівень успішності якого становив лише близько 2%. Модель Claude Mythos Preview досягла результату 93,9%, майже повністю пройшовши цей бенчмарк.
Звичайно, кожен benchmark містить певний рівень шуму, тому зазвичай настає етап, коли, коли результати досягають певного рівня, ви зіштовхуєтеся не з обмеженнями методу, а з обмеженнями самого benchmark. Наприклад, у наборі даних ImageNet приблизно 6% міток є неправильними або неоднозначними.
SWE-Bench можна вважати надійним показником загальної програмної компетентності та впливу ШІ на програмну інженерію. Кларк зазначив, що більшість людей, з якими він зустрічався в лабораторіях передових ШІ та в Сіліконовій долині, зараз майже повністю пишуть код за допомогою ШІ-систем, і все більше людей починають використовувати ШІ-системи для написання тестів та перевірки коду.
Іншими словами, системи ШІ настільки потужні, що можуть автоматизувати важливу складову досліджень ШІ та значно прискорити роботу всіх людських дослідників і інженерів, які беруть участь у розробці ШІ.
Вимірювання здатності AI-систем виконувати довготривалі завдання
METR створив графік, щоб виміряти, наскільки складні завдання може виконати ШІ. Складність визначається за кількістю годин, які досвідчена людина зазвичай витрачає на виконання цих завдань.
Найважливішим показником є приблизний часовий діапазон завдань, при якому система ШІ досягає 50% надійності.
На цьому етапі прогрес дуже вражаючий:
· У 2022 році завдання, які міг виконати GPT-3.5, приблизно відповідали завданням, які людина виконує за 30 секунд.
· У 2023 році GPT-4 підвищив цей час до 4 хвилин.
· У 2024 році o1 підвищив цей час до 40 хвилин.
· У 2025 році GPT-5.2 High досяг приблизно 6 годин.
· До 2026 року Opus 4.6 підняв цей термін ще вище — приблизно до 12 годин.
Айєя Котра, яка працює в METR і довгий час вивчає передбачення штучного інтелекту, вважає, що до кінця 2026 року система ШІ здатна виконувати завдання, що вимагають від людини 100 годин, — це не нереалістичне очікування.
Час, протягом якого AI-системи можуть працювати автономно, значно збільшився, що тісно пов’язано з вибуховим розвитком інструментів агентного кодування. Інструменти агентного кодування — це, за суттю, продукти AI-систем, здатних виконувати роботу замість людини: вони можуть діяти від імені людини та протягом тривалого часу самостійно просувати завдання.
Це також знову звертає увагу на саму розробку ШІ. Уважний аналіз щоденних завдань багатьох дослідників ШІ показує, що велика кількість завдань може бути розбита на роботу тривалістю кілька годин, наприклад, очищення даних, читання даних, запуск експериментів тощо.
А така робота зараз потрапляє в часовий діапазон, який можуть охопити сучасні AI-системи.
Чим досвідченішим стає штучний інтелект, тим більше він може працювати незалежно від людини і допомагати автоматизувати частину робіт з розробки ШІ.
Основними факторами завдання є два:
· По-перше, ваша впевненість у здатності особи, якій ви доручили;
· Друге — ви вірите, що інша сторона здатна самостійно виконати роботу відповідно до вашого наміру, не потребуючи постійного нагляду з вашого боку.
Коли користувачі спостерігають за здатністю ШІ у програмуванні, вони помічають, що ШІ-системи не лише стають все більш досвідченими, але й здатні працювати довше самостійно, без необхідності вручнуї калібрування людиною.
Це також збігається з тим, що відбувається навколо нас: інженери та дослідники передають все більші обсяги робіт системам ШІ. Зі зростанням здібностей ШІ завдання, що передаються ШІ, стають все складнішими та важливішими.
Штучний інтелект засвоює ключові наукові навички, необхідні для розробки ШІ
Подумайте, як проводиться сучасна наукова дослідницька робота: велика її частина полягає у визначенні напрямку та чіткому розумінні, яку емпіричну інформацію ви хочете отримати; потім у розробці та проведенні експериментів для генерації цієї інформації; і нарешті у перевірці обґрунтованості результатів експерименту.
Зі зростанням здатностей ШІ до програмування та посиленням здатності великих мовних моделей до моделювання світу, з’явилися інструменти, які допомагають людським вченим прискорити процеси та частково автоматизувати певні етапи в більш широких дослідницьких сценаріях.
Тут ми можемо спостерігати за швидкістю прогресу ШІ у кількох ключових наукових навичках, які самі є невід’ємною частиною досліджень ШІ:
· По-перше, відтворити результати дослідження;
· Друге — поєднання технологій машинного навчання з іншими методами для вирішення технічних проблем;
· Третє — оптимізація власної системи ШІ.
Завершити цілий науковий статтю та провести відповідні експерименти
Однією з ключових задач у дослідженнях штучного інтелекту є читання наукових статей та відтворення їхніх результатів. У цьому аспекті ШІ досяг значних успіхів на ряді тестових наборів.
Добрым прикладом є CORE-Bench, тобто Computational Reproducibility Agent Benchmark.
Цей benchmark вимагає від AI-системи відтворити результати статті за умови надання статті та її репозиторію з кодом. Зокрема, агент повинен встановити відповідні бібліотеки, пакети та залежності, запустити код; якщо код виконується успішно, він також повинен знайти всі результати виводу та відповісти на запитання завдання.
CORE-Bench було запропоновано у вересні 2024 року. На той час найкращою системою була модель GPT-4o, що працювала на scaffold CORE-Agent. На найскладнішій групі завдань цього benchmarkу вона набрала приблизно 21,5%.
А в грудні 2025 року один із авторів CORE-Bench оголосив, що цей benchmark було вирішено: модель Opus 4.5 показала результат 95,5%.
Створення повної системи машинного навчання для вирішення завдань з змагань Kaggle
MLE-Bench — це benchmark, створений OpenAI, для тестування здатності AI-систем брати участь у змаганнях Kaggle в офлайн-середовищі.
Він охоплює 75 різних типів змагань Kaggle, що стосуються кількох галузей, включаючи обробку природної мови, комп’ютерне зоріння та обробку сигналів.
MLE-Bench було випущено у жовтні 2024 року. На момент випуску найкращу продуктивність показала модель o1, що працювала в середовищі agent scaffold, з результатом 16,9%.
На лютого 2026 року найкращою системою став Gemini 3, що працює в агентній системі з функцією пошуку, з результатом 64,4%.
Дизайн ядра
Однією з більш складних задач у розробці ШІ є оптимізація ядра. Під оптимізацією ядра розуміють написання та вдосконалення нижчорівневого коду для більш ефективного відображення таких спеціалізованих операцій, як множення матриць, на нижчорівневе обладнання.
Оптимізація ядра є ядром розробки ШІ, оскільки вона визначає ефективність навчання та висновку: з одного боку, вона впливає на те, наскільки ефективно ви можете використовувати обчислювальні ресурси під час розробки систем ШІ; з іншого боку, після завершення навчання моделі вона визначає, наскільки ефективно ви можете перетворити обчислювальні ресурси на здатність до висновку.
За останні роки використання ШІ для проектування ядер перетворилося з цікавого напрямку на конкурентну дослідницьку галузь, з’явилося кілька бенчмарків. Однак ці бенчмарки поки що не отримали широкого поширення, тому нам важко чітко моделювати його довгостроковий прогрес, як це робиться в інших галузях. З іншого боку, ми можемо відчути швидкість розвитку цього напрямку через деякі поточні дослідження.
Відповідні роботи включають:
· Використовувати моделі DeepSeek для спроби створення кращих GPU-ядер;
Автоматично перетворює модулі PyTorch у код CUDA;
· Meta використовує LLM для автоматичного створення оптимізованих ядер Triton та їх розгортання у власній інфраструктурі;
· А також налаштування відкритих вагових моделей для GPU-ядер, наприклад, Cuda Agent.
Тут варто додати: архітектура ядра дійсно має деякі властивості, які добре підходять для розробки, спрямованої на ШІ, наприклад, легкість перевірки результатів і чіткі сигнали нагороди.
Налаштування мовних моделей за допомогою PostTrainBench
Більш складною версією такого тесту є PostTrainBench. Він перевіряє, чи здатні різні передові моделі прийняти менші відкриті ваги моделей та покращити їхній результат на певних бенчмарках за допомогою донастройки.
Однією з переваг цього бенчмарку є дуже висока людська базова лінія: існуючі інструкційно-налаштовані версії цих невеликих моделей. Ці версії зазвичай розроблені видатними людськими дослідниками штучного інтелекту з передових лабораторій, вдосконалені досвідченими дослідниками та інженерами та вже впроваджені в реальних умовах. Тому вони утворюють дуже важливу людську базову лінію, яку важко перевершити.
На березень 2026 року AI-системи здатні проводити пост-навчання моделей і досягати підвищення продуктивності, що становить приблизно половину від результатів, отриманих за допомогою людського навчання.
Кінцева оцінка обчислюється як зважене середнє, що враховує кілька післятренованих великих мовних моделей, включаючи Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B, а також кілька тестових наборів, зокрема AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval.
Під час кожного запуску оцінювач вимагає CLI агента, який максимізує продуктивність певної базової моделі на певному бенчмарку.
На квітень 2026 року найкращі AI-системи досягли приблизно 25–28%, до них належать моделі Opus 4.6 та GPT 5.4; порівняно з цим, результат людини становить 51%.
Це вже досить значущий результат.
Оптимізація навчання мовних моделей
Протягом останнього року Anthropic повідомляла про продуктивність своїх систем у завданні навчання LLM. Це завдання вимагало від моделі оптимізувати мініатюрну реалізацію навчання мовної моделі, яка використовує лише CPU, щоб вона працювала якнайшвидше.
Метод оцінки: середнє прискорення, досягнуте моделлю, порівняно з початковим кодом без змін.
Цей результат демонструє значний прогрес:
· У травні 2025 року Claude Opus 4 досяг середнього прискорення у 2,9 рази;
· У листопаді 2025 року Opus 4.5 підвищено до 16,5 разів;
· У лютому 2026 року Opus 4.6 досяг 30-кратного зростання;
· У квітні 2026 року Claude Mythos Preview досяг 52-кратного зростання.
Щоб зрозуміти значення цих цифр, можна зробити порівняння: у людських дослідників на це завдання зазвичай витрачається 4–8 годин роботи, що забезпечує 4-кратне прискорення.
Базова навичка: управління
AI-системи також вчаться керувати іншими AI-системами.
Це вже можна побачити в деяких широко впроваджених продуктах, таких як Claude Code або OpenCode. У цих продуктах головний агент може керувати кількома підагентами.
Це дозволяє AI-системам обробляти проекти більшого масштабу: у проекті може знадобитися паралельна робота кількох агентів з різними спеціалізаціями, які зазвичай координуються одним єдиним AI-менеджером. Сам менеджер також є AI-системою.
Дослідження ШІ більше схоже на відкриття загальної теорії відносності чи збирання лего?
Одне з ключових питань: чи може ШІ винайти нові ідеї, щоб допомогти собі покращити себе? Чи ці системи краще підходять для виконання тих менш відомих, але необхідних робіт, які треба виконувати крок за кроком?
Це важливо, бо це стосується того, наскільки AI-системи можуть повністю автоматизувати саму AI-дослідницьку роботу.
Автор вважає: наразі ШІ не може запропонувати справді радикальні нові ідеї. Але для досягнення автоматизації власних досліджень, можливо, йому це й не потрібно.
Як галузь, прогрес у сфері ШІ значною мірою залежить від все більших експериментів та все більшої кількості вхідних даних, таких як дані та обчислювальні потужності.
Іноді люди запропонували ідеї, що змінюють парадигму, і значно підвищили ефективність використання ресурсів у всій галузі. Архітектура Transformer — це чудовий приклад, а моделі змішаних експертів, або mixture-of-experts, — ще один приклад.
Але частіше просування в галузі ШІ є більш простим: люди беруть добре працюючу систему, збільшують один з її аспектів, наприклад, дані для навчання або обчислювальну потужність; спостерігають, де виникають проблеми після масштабування; знаходять інженерні рішення для виправлення цих проблем, щоб система могла продовжувати масштабуватися; а потім знову збільшують масштаб.
У цьому процесі справді потрібно дуже мало глибоких інсайтів. Більшість роботи схожа на менш помітну, але дуже міцну базову інженерію.
Подібним чином багато досліджень у галузі ШІ полягають у запуску різних варіантів існуючих експериментів, щоб дослідити, які результати дають різні налаштування параметрів. Хоча людська інтуїція може допомогти вибрати найбільш перспективні параметри для спроб, цей процес також може бути автоматизований, щоб ШІ сам визначав, які параметри варто налаштовувати. Ранні версії пошуку нейронних архітектур — це один із варіантів такого підходу.
Едісон колись сказав: «Талант — це 1% натхнення та 99% поту». Навіть через 150 років це твердження залишається дуже актуальним.
Іноді справді з’являються нові ідеї, які повністю змінюють галузь. Але найчастіше прогрес у галузі досягається завдяки важкій роботі людей з покращенням та налагодженням різних систем.
Проте раніше згадані відкриті дані свідчать, що ШІ вже дуже добре впорається з багатьма необхідними, але нудними завданнями в розробці ШІ.
Тим часом існує ще більший тренд: базові здібності, такі як програмування, поєднуються з постійно розширюваним часовим діапазоном завдань. Це означає, що AI-системи можуть все більше з’єднувати такі завдання, утворюючи складні робочі послідовності.
Тому, навіть якщо інтелектуальні системи зараз відносно недостатньо творчі, є підстави вважати, що вони все ще здатні сприяти власному розвитку. Проте цей прогрес може бути повільнішим, ніж у випадку здатності генерувати абсолютно нові ідеї.
Але якщо продовжувати спостерігати за відкритими даними, можна помітити ще один цікавий сигнал: інтелектуальні системи, можливо, починають проявляти певну креативність, яка може дозволити їм прискорювати свій розвиток більш неочікуваними способами.
Забезпечити подальший розвиток наукового фронту
Вже є деякі дуже початкові ознаки того, що універсальні AI-системи здатні продовжувати розвиток людської науки. Однак на даний момент це відбувається лише в декількох галузях, зокрема в комп’ютерних науках та математиці. Крім того, часто прориви досягаються не саме AI-системами, а шляхом співпраці людини та машини разом із людськими дослідниками.
Тим не менш, ці тенденції варто спостерігати:
Проблема Ердеша: група математиків співпрацювала з моделлю Gemini, щоб протестувати її здатність розв’язувати деякі математичні проблеми Ердеша. Вони направили систему спробувати близько 700 проблем і отримали 13 розв’язків. Серед цих розв’язків один вони вважали цікавим.
Дослідники написали, що на початковому етапі вважають, що розв’язання Aletheia (системи штучного інтелекту на основі Gemini 3 Deep Think) проблеми Erdős-1051 є раннім прикладом: коли система штучного інтелекту самостійно розв’язала відкриту проблему Erdős, що має невелику не тривіальність і певний ширший математичний інтерес. Ця проблема раніше мала деякі closely-related дослідницькі публікації.
Якщо розуміти це оптимістично, ці випадки можна сприймати як сигнал: системи ШІ розвивають певну творчу інтуїцію, яка раніше була притаманна виключно людям.
Але це можна трактувати й інакше: математика та комп’ютерні науки можуть бути саме тими галузями, які особливо підходять для винаходів, що ґрунтуються на ШІ, тому вони можуть бути лише винятком і не відображати того, що всі інші галузі науки будуть просуватися ШІ таким самим чином.
Іншим подібним прикладом є 37-й хід AlphaGo. Однак Кларк вважає, що те, що минуло десять років з моменту цього результату, і жоден більш сучасний, більш дивовижний прорив не замінив 37-й хід, сам по собі може вважатися трохи пессимістичним сигналом.
Штучний інтелект уже може автоматизувати велику частину робіт у галузі інженерії ШІ
Якщо об’єднати всі вищезазначені докази, ми побачимо таку картину:
· Інтелектуальні системи вже здатні писати код майже для будь-якої програми, і ці системи можна довіряти, щоб вони самостійно виконували деякі завдання; якщо ці завдання доручити людям, їх виконання часто вимагало б десятків годин інтенсивної зосередженої праці.
AI-системи все краще впорядаються з ключовими завданнями розробки ШІ — від тонкої настройки моделей до дизайну ядер, і всі ці завдання поступово автоматизуються.
· ІС вже здатні керувати іншими ІС, утворюючи насправді синтетичну команду: кілька ІС можуть одночасно вирішувати складні завдання, де деякі ІС виконують ролі керівників, критиків та редакторів, а інші — інженерів.
· Іноді штучні інтелектуальні системи вже перевершують людей у складних інженерних і наукових завданнях, хоча наразі важко визначити, чи це через їхню справжню креативність, чи через те, що вони вже добре засвоїли величезний обсяг шаблонних знань.
За думкою Кларка, ці докази уже досить переконливо свідчать про те, що сьогоднішній ІІ може автоматизувати велику частину робіт у галузі ІІ-інженерії, а можливо, й усі її етапи.
Проте наразі невідомо, наскільки AI може автоматизувати саме дослідження AI, оскільки деякі аспекти досліджень, можливо, відрізняються від чисто інженерних навичок і все ще залежать від більш високих рівнів судження, свідомості проблеми та креативності.
Але будь-яким чином, з’явився чіткий сигнал: сьогоднішній ІІ в значною мірою прискорює розробку ІІ людьми, дозволяючи цим дослідникам і інженерам посилювати свою продуктивність шляхом співпраці з безліччю синтетичних колег.
Нарешті, сама індустрія ШІ майже прямо каже: автоматизація розробки ШІ — це їхня мета.
OpenAI прагне створити автоматизованого AI-стажера-дослідника до вересня 2026 року. Anthropic публікує роботи щодо створення автоматизованих дослідників з вирівнювання AI. DeepMind виглядає найобережнішим серед трьох лабораторій, але також вказує, що автоматизацію досліджень з вирівнювання слід розробляти, як тільки це стане можливим.
Автоматизація AI-досліджень також стала метою багатьох стартапів. Recursive Superintelligence щойно зібрала 500 мільйонів доларів США з метою автоматизації AI-досліджень.
Іншими словами, трильйони доларів існуючого та нового капіталу інвестуються в серію організацій, що мають метою автоматизовану розробку ШІ.
Тому ми, звичайно, повинні очікувати, що цей напрямок принаймні досягне певного прогресу.
Чому це важливо
Це має глибокі наслідки, але про це майже не згадується в масових засобах масової інформації, що освітлюють розробку ШІ. Нижче наведено кілька аспектів, які відображають великі виклики, пов’язані з розробкою ШІ.
1. Ми повинні забезпечити відповідність: сьогодні ефективні методи відповідності можуть стати неефективними під час рекурсивної самовдосконалення, оскільки AI-системи стануть набагато розумнішими за людей або системи, що їх наглядають. Це галузь, яка була широко досліджена, тому він лише коротко описує деякі проблеми:
Навчання штучних інтелектуальних систем не брехати та не шахрайствувати — це несподівано тонкий процес (наприклад, хоча й робляться зусилля для створення добрих тестів для середовища, іноді найкращим способом розв’язання проблеми для штучного інтелекту є шахрайство, що вчить його, що шахрайство є можливим).
· AI-системи можуть обманювати нас, «імітуючи відповідність», виводячи бали, які дають нам ілюзію їхньої доброї роботи, тоді як насправді приховують свої справжні наміри. (Загалом, AI-системи вже здатні виявляти, коли перебувають під тестуванням.)
· Зі збільшенням участі AI-систем у базових дослідженнях, що лежать в основі їхнього власного навчання, ми можемо значно змінити загальний підхід до навчання AI-систем, не маючи достатньої інтуїції чи теоретичної основи, щоб зрозуміти, що це означає.
· Коли ви поміщаєте певну систему в рекурсивний цикл, виникає дуже фундаментальна проблема «накопичення похибок», яка може вплинути на всі вищезгадані проблеми та інші: якщо ваш метод вирівнювання не є «100% точним» і теоретично не здатний зберігати цю точність у більш розумних системах, справи можуть швидко піти не так. Наприклад, початкова точність вашої технології становить 99,9%, через 50 поколінь вона може знизитися до 95,12%, а через 500 поколінь — до 60,5%.
Усе, що стосується ШІ, отримає значне збільшення продуктивності: як ШІ значно підвищує продуктивність інженерів-програмістів, ми повинні очікувати такого ж ефекту в інших галузях, де застосовується ШІ. Це створює кілька питань, які потрібно вирішити:
· Нерівний доступ до ресурсів: якщо попит на ШІ продовжуватиме перевищувати пропозицію обчислювальних ресурсів, нам потрібно вирішити, як розподілити ШІ для досягнення максимального соціального користі. Я скептично ставлюся до того, що ринкові стимули зможуть забезпечити оптимальний соціальний відгук від обмежених обчислювальних ресурсів ШІ. Визначення того, як розподілити прискорювальні можливості, що виникають через дослідження ШІ, буде надзвичайно політичним питанням.
· Закон Амдала для економіки: зі зростанням впровадження ШІ в економіку ми зможемо виявити певні ланки, які стають узеньким місцем під час швидкого зростання, і потрібно знайти способи виправлення слабких ланок у цьому ланцюжку. Це може бути особливо помітно в галузях, де потрібно координувати швидкий цифровий світ і повільний фізичний світ, наприклад, у клінічних випробуваннях нових ліків.
3. Формування капіталоємної, малої за трудомісткістю економіки: Всі наведені вище докази щодо розробки ШІ також свідчать про те, що системи ШІ все більше здатні самостійно керувати підприємствами.
Це означає, що ми можемо очікувати, що частина економіки буде зайнята новим поколінням компаній, які можуть бути капіталоємними (оскільки вони володіють великою кількістю комп’ютерів) або інтенсивними за операційними витратами (оскільки вони витрачають величезні кошти на AI-сервіси та створюють вартість на їх основі), порівняно з сучасними компаніями, які менше залежать від людських ресурсів — оскільки з постійним зростанням здатностей AI-системи гранична вартість інвестицій у AI постійно збільшується.
На практиці це виявиться у вигляді «машинної економіки», що поступово формується всередині більшої «людської економіки»; з часом компанії, що керуються ШІ, можуть почати торгувати між собою, змінюючи економічну структуру і викликаючи різноманітні питання щодо нерівності та перерозподілу. У кінцевому підсумку можуть з’явитися компанії, повністю керовані автономними ШІ-системами, що посилютиме зазначені проблеми та створить багато нових викликів у галузі управління.
Дивіться у чорну діру
На основі цього аналізу автор вважає, що ймовірність того, що до кінця 2028 року ми побачимо автоматизоване AI-дослідження (тобто передові моделі, здатні самостійно навчати свої наступні версії), становить приблизно 60%. Чому не очікується його появи у 2027 році?
Причина полягає в тому, що автор вважає, що дослідження в галузі ШІ все ще потребують креативності та альтернативних поглядів для прогресу, і поки що системи ШІ не продемонстрували цього в трансформаційний та значущий спосіб (хоча деякі результати у прискоренні математичних досліджень мають значення).
Якщо йому обов’язково потрібно буде назвати ймовірність на 2027 рік, він скаже 30%.
Якщо до кінця 2028 року цього не станеться, ми, можливо, виявимо деякі фундаментальні недоліки поточної технологічної парадигми, які вимагатимуть людських винаходів для подальшого розвитку.