









แบบจำลองขนาดใหญ่ยังคงเติบโตขึ้นเรื่อยๆ และความเห็นที่แพร่หลายเชื่อว่าพารามิเตอร์ของแบบจำลองยิ่งมากเท่าใด ก็จะยิ่งใกล้เคียงกับวิธีคิดของมนุษย์ อย่างไรก็ตาม ทีมงานจากมหาวิทยาลัยเจ้อเจียงได้เผยแพร่บทความหนึ่งบน Nature Communications เมื่อวันที่ 1 เมษายน ซึ่งเสนอความเห็นที่ต่างออกไป (ลิงก์บทความต้นฉบับ: https://www.nature.com/articles/s41467-026-71267-5) พวกเขาพบว่าเมื่อขนาดของแบบจำลอง (ส่วนใหญ่เป็น SimCLR, CLIP, DINOv2) เพิ่มขึ้น ความสามารถในการระบุสิ่งของเฉพาะเจาะจงยังคงเพิ่มขึ้น แต่ความสามารถในการเข้าใจแนวคิดเชิงนามธรรมไม่ได้ดีขึ้น กลับลดลงด้วยซ้ำ เมื่อพารามิเตอร์เพิ่มจาก 22.06 ล้านเป็น 304.37 ล้าน งานเกี่ยวกับแนวคิดเฉพาะเจาะจงเพิ่มจาก 74.94% เป็น 85.87% ในขณะที่งานเกี่ยวกับแนวคิดเชิงนามธรรมลดจาก 54.37% เป็น 52.82%
ความแตกต่างระหว่างวิธีคิดของมนุษย์และโมเดล
เมื่อมนุษย์ประมวลผลแนวคิด พวกเขาจะสร้างระบบการจัดหมวดหมู่ความสัมพันธ์ขึ้นก่อน แม้วงค์และนกฮูกจะดูต่างกัน แต่มนุษย์ยังคงจัดให้พวกมันอยู่ในหมวดหมู่ “นก” จากนั้นในระดับที่สูงขึ้น นกและม้าก็สามารถจัดอยู่ในหมวด “สัตว์” ได้อีก เมื่อเห็นสิ่งใหม่ๆ มนุษย์มักจะคิดก่อนว่า สิ่งนี้คล้ายกับสิ่งที่เคยเห็นมาก่อน และอยู่ในหมวดใด โดยมนุษย์จะเรียนรู้แนวคิดใหม่ๆ อย่างต่อเนื่อง และจัดระเบียบประสบการณ์เหล่านั้นเพื่อใช้ระบุสิ่งใหม่ๆ และปรับตัวเข้ากับสถานการณ์ใหม่ๆ ตามระบบความสัมพันธ์นี้
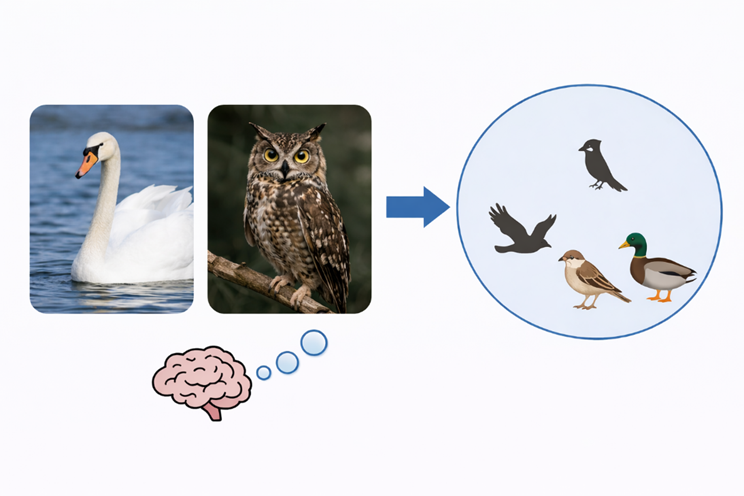
แบบจำลองก็สามารถจัดหมวดหมู่ได้ แต่วิธีการสร้างนั้นต่างกัน มันขึ้นอยู่กับรูปแบบที่เกิดซ้ำๆ ในชุดข้อมูลขนาดใหญ่ วัตถุเฉพาะเจาะจงยิ่งปรากฏบ่อยเท่าใด แบบจำลองก็ยิ่งง่ายต่อการรับรู้ เมื่อถึงขั้นตอนของหมวดหมู่ที่กว้างขึ้น แบบจำลองจะทำงานได้ยากขึ้น มันต้องจับจุดร่วมระหว่างวัตถุหลายอย่าง และจัดกลุ่มจุดร่วมเหล่านั้นไว้ในหมวดเดียวกัน แบบจำลองปัจจุบันยังมีข้อบกพร่องชัดเจนในจุดนี้ เมื่อพารามิเตอร์เพิ่มขึ้นเรื่อยๆ งานที่เกี่ยวข้องกับแนวคิดเฉพาะเจาะจงจะดีขึ้น แต่บางครั้งงานที่เกี่ยวข้องกับแนวคิดเชิงนามธรรมกลับลดลง

สมองมนุษย์และแบบจำลองมีจุดร่วมคือภายในจะสร้างระบบการจัดหมวดหมู่ขึ้นเอง แต่ทั้งสองฝ่ายมีจุดเน้นที่ต่างกัน บริเวณการรับรู้ภาพขั้นสูงของสมองมนุษย์จะแยกออกเป็นหมวดใหญ่เช่น สิ่งมีชีวิตและสิ่งไม่มีชีวิตโดยธรรมชาติ ในขณะที่แบบจำลองสามารถแยกวัตถุเฉพาะเจาะจงได้ แต่ยากที่จะสร้างการจัดหมวดหมู่ขนาดใหญ่เช่นนี้อย่างมั่นคง ความแตกต่างนี้ทำให้สมองมนุษย์สามารถนำประสบการณ์เดิมไปใช้กับวัตถุใหม่ได้ง่ายกว่า ดังนั้นเมื่อเผชิญกับสิ่งที่ไม่เคยเห็นมาก่อน เราจึงสามารถจัดหมวดหมู่ได้อย่างรวดเร็ว ในขณะที่แบบจำลองจะพึ่งพาความรู้ที่มีอยู่มากกว่า จึงมักยึดติดกับลักษณะภายนอกเมื่อเจอวัตถุใหม่ วิธีการที่เสนอในงานวิจัยนี้เน้นที่จุดนี้ โดยใช้สัญญาณจากสมองมาควบคุมโครงสร้างภายในของแบบจำลอง เพื่อให้มันใกล้เคียงกับวิธีการจัดหมวดหมู่ของสมองมนุษย์มากขึ้น
โซลูชันของทีมจากมหาวิทยาลัยเจ้อเจียง
วิธีแก้ปัญหาที่ทีมเสนอมา cũngมีความเฉพาะตัว โดยไม่ได้เพิ่มพารามิเตอร์ต่อไป แต่ใช้สัญญาณสมองจำนวนน้อยมาเป็นข้อมูลกำกับ สัญญาณสมองเหล่านี้มาจากบันทึกกิจกรรมของสมองขณะมนุษย์ดูภาพ บทความต้นฉบับเขียนว่า โอน human conceptual structures ไปยัง DNNs ซึ่งหมายความว่า พยายามสอนโมเดลให้เรียนรู้วิธีการจัดหมวดหมู่ สรุป และจัดกลุ่มแนวคิดที่ใกล้เคียงกันของสมองมนุษย์
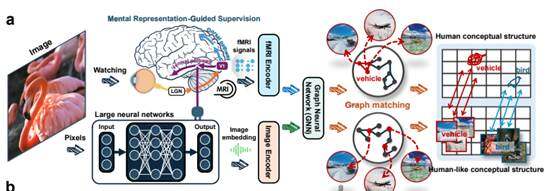
ทีมงานทำการทดลองด้วย 150 หมวดหมู่การฝึกที่รู้จักกันดีและ 50 หมวดหมู่การทดสอบที่ไม่เคยเห็นมาก่อน ผลลัพธ์แสดงให้เห็นว่า ตามการดำเนินการฝึกอบรม ระยะห่างระหว่างแบบจำลองและการแทนค่าของสมองลดลงอย่างต่อเนื่อง การเปลี่ยนแปลงนี้เกิดขึ้นในทั้งสองหมวดหมู่ ซึ่งบ่งชี้ว่าแบบจำลองไม่ได้เรียนรู้เฉพาะตัวอย่างเดียว แต่เริ่มเรียนรู้วิธีจัดระเบียบแนวคิดที่ใกล้เคียงกับวิธีที่สมองมนุษย์ทำงาน
หลังจากการฝึกอบรมชุดนี้ โมเดลมีความสามารถในการเรียนรู้ที่ดีขึ้นเมื่อมีตัวอย่างน้อย และแสดงผลลัพธ์ที่ดีขึ้นเมื่อเผชิญกับสถานการณ์ใหม่ ในภารกิจที่ให้ตัวอย่างน้อยมากแต่ต้องการให้โมเดลแยกแยะระหว่างสิ่งมีชีวิตและสิ่งไม่มีชีวิต ซึ่งเป็นแนวคิดเชิงนามธรรม โมเดลสามารถเพิ่มประสิทธิภาพโดยเฉลี่ย 20.5% และยังเหนือกว่าโมเดลเปรียบเทียบที่มีพารามิเตอร์มากกว่ามาก ทีมงานยังได้ทำการทดสอบเพิ่มเติมอีก 31 ชุด โดยโมเดลแต่ละประเภทต่างก็แสดงการปรับปรุงใกล้เคียงกับ 10%
ในช่วงไม่กี่ปีที่ผ่านมา เส้นทางที่อุตสาหกรรมโมเดลคุ้นเคยคือการขยายขนาดโมเดลให้ใหญ่ขึ้น ทีมจากมหาวิทยาลัยเจ้อเจียงกลับเลือกแนวทางที่ต่างออกไป คือก้าวจาก “ยิ่งใหญ่ยิ่งดี” สู่ “มีโครงสร้างยิ่งฉลาด” การขยายขนาดนั้นมีประโยชน์จริง แต่ส่วนใหญ่ช่วยเพิ่มประสิทธิภาพในงานที่คุ้นเคยเท่านั้น ความสามารถในการเข้าใจเชิงนามธรรมและการถ่ายโอนความรู้แบบมนุษย์นั้นสำคัญไม่แพ้กันสำหรับ AI และต้องได้รับการพัฒนาในอนาคตให้โครงสร้างการคิดของ AI ใกล้เคียงกับสมองมนุษย์มากขึ้น คุณค่าของแนวทางนี้อยู่ที่การช่วยดึงความสนใจของอุตสาหกรรมกลับมาที่โครงสร้างการรับรู้เอง แทนที่จะเน้นแค่การขยายขนาดอย่างเดียว
Neosoul และอนาคต
สิ่งนี้เปิดโอกาสให้เกิดความเป็นไปได้ที่ใหญ่กว่า: การวิวัฒนาการของ AI ไม่จำเป็นต้องเกิดขึ้นแค่ในขั้นตอนการฝึกโมเดลเท่านั้น การฝึกโมเดลสามารถกำหนดว่า AI จะจัดระเบียบแนวคิดอย่างไร และสร้างโครงสร้างการตัดสินใจที่มีคุณภาพสูงขึ้นอย่างไร แต่เมื่อเข้าสู่โลกแห่งความเป็นจริง การวิวัฒนาการอีกระดับหนึ่งของ AI จึงเพิ่งเริ่มต้นขึ้น: วิธีที่ AI agent บันทึกการตัดสินใจ ตรวจสอบ และเติบโตอย่างต่อเนื่องผ่านการแข่งขันจริง คล้ายกับการเรียนรู้และวิวัฒนาการด้วยตนเองของมนุษย์ ซึ่ง Neosoul กำลังทำอยู่ในขณะนี้ Neosoul ไม่ได้แค่ให้ AI agent สร้างคำตอบเท่านั้น แต่ยังวาง AI agent ไว้ในระบบที่มีการพยากรณ์อย่างต่อเนื่อง การตรวจสอบอย่างต่อเนื่อง การปิดการซื้อขายอย่างต่อเนื่อง และการคัดกรองอย่างต่อเนื่อง เพื่อให้มันปรับปรุงตนเองอย่างต่อเนื่องผ่านการเปรียบเทียบระหว่างการพยากรณ์กับผลลัพธ์ ทำให้โครงสร้างที่ดีกว่าถูกเก็บรักษาไว้ และโครงสร้างที่แย่กว่าถูกกำจัดออกไป ทีมจากมหาวิทยาลัยเจ้อเจียงและ Neosoul ต่างมุ่งไปสู่เป้าหมายเดียวกัน: ทำให้ AI ไม่ใช่แค่สามารถทำข้อสอบได้ แต่ต้องมีความสามารถในการคิดอย่างรอบด้าน และสามารถวิวัฒนาการอย่างต่อเนื่อง