









ผู้เขียนต้นฉบับ: David, DeepTide TechFlow
ในช่วงบ่ายของวันที่ 20 มกราคม X ได้เปิดเผยอัลกอริทึมการแนะนำรุ่นใหม่แบบโอเพนซอร์ส
คำตอบที่มัสก์ตอบกลับมาค่อนข้างน่าสนใจ: "เรารู้ว่าอัลกอริทึมนี้โง่ ต้องปรับปรุงให้ดีขึ้นอีกมาก แต่ก็อย่างน้อยคุณก็เห็นได้ว่าเรากำลังพยายามปรับปรุงแบบเรียลไทม์ แพลตฟอร์มโซเชียลมีเดียอื่นไม่กล้าทำแบบนี้"
ประโยคนี้มีสองความหมายประการแรกคือการยอมรับว่าอัลกอริทึมมีปัญหา และประการที่สองคือการใช้ "ความโปร่งใส" เป็นจุดขาย
นี่คือครั้งที่สองที่ X ปล่อยโค้ดอัลกอริทึมแบบโอเพนซอร์ส ฉบับปี 2023 ไม่มีการอัปเดตมาสามปีแล้ว และล้าสมัยเมื่อเทียบกับระบบจริงอยู่แล้ว ครั้งนี้มีการเขียนใหม่ทั้งหมด โดยเปลี่ยนโมเดลหลักจาก Machine Learning แบบดั้งเดิมมาเป็น Grok Transformer ทางฝ่ายผู้พัฒนาอธิบายว่า "ลบล้างการใช้ Feature Engineering แบบทำมือไปอย่างสิ้นเชิง"
ก่อนหน้านี้ ขั้นตอนการคำนวณขึ้นอยู่กับวิศวกรที่ต้องปรับค่าต่างๆ ด้วยตนเอง แต่ตอนนี้เราปล่อยให้ AI ดูประวัติการโต้ตอบของคุณเอง เพื่อตัดสินใจว่าจะแนะนำเนื้อหาของคุณหรือไม่
สำหรับนักสร้างคอนเทนต์แล้ว นี่หมายความว่าศาสตร์ลึกลับเก่าๆ เช่น "โพสต์เวลาไหนดีที่สุด" หรือ "แท็กอะไรเพื่อเพิ่มผู้ติดตาม" อาจไม่เวิร์กอีกต่อไปแล้ว
เราได้ตรวจสอบคลังข้อมูล Github ที่เปิดเผยต่อสาธารณะ และด้วยการช่วยเหลือจาก AI พบว่าจริงๆ แล้วมีตรรกะที่ซ่อนอยู่ในโค้ดบางส่วนที่น่าจะต้องตรวจสอบให้ละเอียดอีกที
การเปลี่ยนแปลงของตรรกะอัลกอริทึม: จากการกำหนดด้วยมือ มาเป็นการตัดสินโดยอัตโนมัติของ AI
ให้พูดให้ชัดเจนก่อนว่าเวอร์ชันใหม่กับเวอร์ชันเก่ามีความแตกต่างกันอย่างไร เพื่อไม่ให้การอภิปรายในขั้นต่อไปสับสน
ในปี 2023 โมเดลที่ Twitter เปิดเผยแหล่งที่มาเรียกว่า Heavy Ranker ซึ่งในความเป็นจริงแล้วเป็นการเรียนรู้เชิงเครื่องแบบดั้งเดิม (Traditional Machine Learning) นักวิศวกรต้องกำหนดคุณลักษณะ (Features) ด้วยตนเองหลายร้อยตัว เช่น โพสต์นี้มีรูปภาพหรือไม่ ผู้โพสต์มีผู้ติดตามกี่คน เวลาที่โพสต์เมื่อเทียบกับปัจจุบันอยู่ที่เท่าไร โพสต์นี้มีลิงก์หรือไม่...
จากนั้นก็กำหนดน้ำหนักให้แต่ละคุณลักษณะ ปรับไปมา ดูว่าชุดใดให้ผลลัพธ์ดีที่สุด
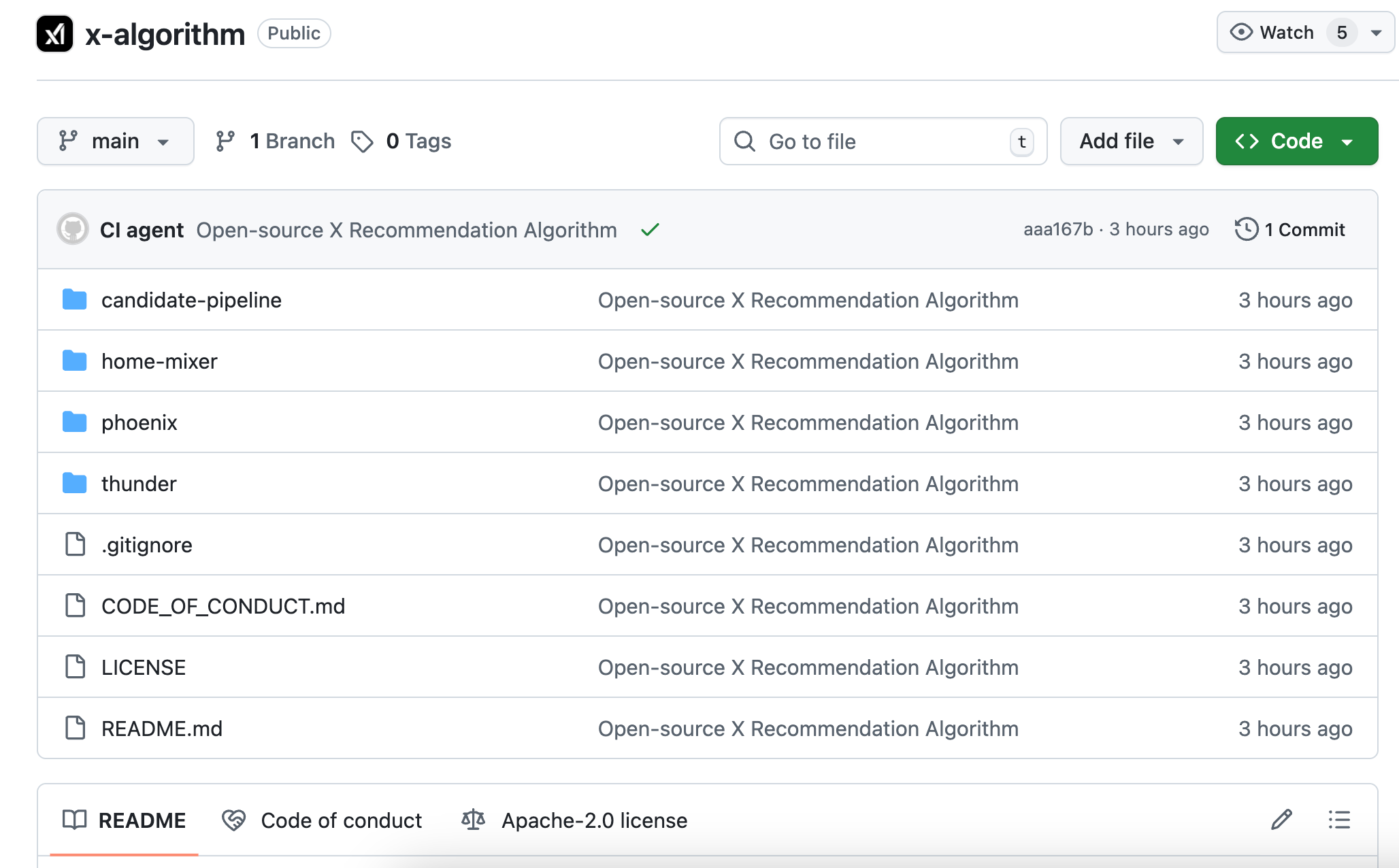
เวอร์ชันใหม่ที่เปิดเผยแหล่งโค้ดครั้งนี้มีชื่อว่า Phoenix ซึ่งมีโครงสร้างที่ต่างออกไปอย่างสิ้นเชิง คุณสามารถเข้าใจได้ว่าเป็นอัลกอริทึมที่พึ่งพาโมเดล AI ขนาดใหญ่มากยิ่งขึ้น โดยแกนหลักใช้โมเดล transformer ของ Grok ซึ่งใช้เทคโนโลยีแบบเดียวกับที่ ChatGPT และ Claude ใช้งานอยู่
ในเอกสาร README ทางการเขียนไว้อย่างชัดเจนว่า "เราได้กำจัดคุณลักษณะที่ออกแบบด้วยมือทุกอย่างไปแล้ว"
กฎเกณฑ์แบบดั้งเดิมที่พึ่งพาการสกัดคุณลักษณะเนื้อหาด้วยมือ ถูกตัดทิ้งไปทั้งหมด ไม่เหลือแม้แต่ข้อเดียว
แล้วตอนนี้ ขั้นตอนวิธีนี้ใช้อะไรเป็นเกณฑ์ในการตัดสินว่าเนื้อหาดีหรือไม่ดีกันแน่?
คำตอบขึ้นอยู่กับคุณเองลำดับการกระทำสิ่งที่คุณเคยกดไลก์ เคยตอบกลับใคร เคยอยู่ในโพสต์ใดเป็นเวลาเกินสองนาที และบล็อกบัญชีประเภทใดไปแล้ว Phoenix นำพฤติกรรมเหล่านี้ไปป้อนให้กับ Transformer เพื่อให้โมเดลเรียนรู้และสรุปกฎเกณฑ์ด้วยตัวเอง
ลองเปรียบเทียบดูนะครับ: อัลกอริทึมเดิมมันเหมือนกับตารางคะแนนที่มนุษย์เขียนขึ้นมา ให้คะแนนทีละข้อเมื่อได้รับการติ๊กแต่ละช่อง
อัลกอริทึมใหม่นี้มีลักษณะเหมือน AI ที่เคยดูประวัติการท่องเว็บของคุณทั้งหมดเดาว่าตรงๆคุณต้องการดูอะไรในอีกไม่กี่วินาทีข้างหน้า
สำหรับผู้สร้างนั้น นี่หมายถึงสองสิ่ง:
ประการแรก เทคนิคเก่าๆ เช่น "เวลาโพสต์ที่ดีที่สุด" หรือ "แท็กทองคำ" ที่เคยมีประโยชน์นั้น คุณค่าในการอ้างอิงลดลงมากเนื่องจากโมเดลไม่ได้พิจารณาคุณลักษณะคงที่เหล่านี้อีกต่อไป แต่มุ่งเน้นไปที่ความชอบส่วนบุคคลของแต่ละผู้ใช้แทน
ประการที่สอง ความสามารถในการเผยแพร่เนื้อหาของคุณนั้น ขึ้นอยู่มากขึ้นเรื่อยๆ ว่า "ผู้ที่ได้เห็นเนื้อหาของคุณจะมีปฏิกิริยาอย่างไร"ปฏิกิริยานี้ถูกวัดออกมาเป็นการพยากรณ์พฤติกรรม 15 ประเภท ซึ่งเราจะอธิบายอย่างละเอียดในบทถัดไป
อัลกอริทึมกำลังทำนายปฏิกิริยา 15 แบบของคุณ
เมื่อ Phoenix ได้รับโพสต์ที่ต้องการแนะนำ จะสามารถทำนายพฤติกรรมที่ผู้ใช้ปัจจุบันอาจมีต่อเนื้อหาดังกล่าวได้ 15 ประเภท ได้แก่
- พฤติกรรมเชิงบวกเช่น การกดไลก์ การตอบกลับ การแชร์ การถูกแชร์ การคลิกที่โพสต์ การคลิกที่หน้าโปรไฟล์ของผู้เขียน การดูวิดีโอเกินครึ่งขึ้นไป การขยายรูปภาพ การแชร์ การอยู่ดูเกินเวลาที่กำหนด และการติดตามผู้เขียน
- พฤติกรรมเชิงลบเช่น แตะที่ "ไม่สนใจ" บล็อกผู้เขียน ปิดการแจ้งเตือนจากผู้เขียน หรือรายงาน
แต่ละพฤติกรรมจะมีความน่าจะเป็นในการทำนายที่สอดคล้องกัน ตัวอย่างเช่น โมเดลจะตัดสินว่าคุณมีโอกาสให้ไลค์โพสต์นี้ 60% หรือมีโอกาสบล็อกผู้เขียนนี้ 5% เป็นต้น
จากนั้นอัลกอริทึมจะทำสิ่งง่ายๆ อย่างหนึ่ง: คูณน้ำหนักของแต่ละความน่าจะเป็นกับค่าที่สอดคล้องกัน รวมค่าทั้งหมดเข้าด้วยกัน เพื่อให้ได้คะแนนรวม
สูตรมีลักษณะดังนี้:
คะแนนสุดท้าย = Σ ( น้ำหนัก × P(การกระทำ) )
น้ำหนักของพฤติกรรมเชิงบวกเป็นจำนวนบวก และน้ำหนักของพฤติกรรมเชิงลบเป็นจำนวนลบ
โพสต์ที่มีคะแนนรวมสูงจะถูกจัดลำดับไว้ด้านหน้า ส่วนที่คะแนนต่ำจะถูกจัดลำดับไว้ด้านล่าง
การหลุดออกจากสูตร กล่าวอย่างตรงไปตรงมาคือ:
ในปัจจุบัน คุณภาพของเนื้อหาดีหรือไม่ดีนั้น ไม่ได้ถูกตัดสินจากเนื้อหาเองว่าเขียนดีหรือไม่ดีอีกต่อไป (แน่นอนว่าความเข้าถึงได้และความเป็นประโยชน์ยังคงเป็นพื้นฐานของการเผยแพร่) แต่สิ่งที่มีผลมากกว่านั้นคือ "ปฏิกิริยาที่เนื้อหานี้จะกระตุ้นให้คุณทำขึ้นมาคืออะไร" ระบบอัลกอริทึมไม่สนใจคุณภาพของโพสต์โดยตรง มันสนใจแต่พฤติกรรมของคุณเท่านั้น
ถ้าคิดในเชิงนี้แล้ว โพสต์ที่ไม่เหมาะสมแต่ทำให้คนไม่สามารถห้ามตัวเองไม่ตอบกลับหรือแสดงความคิดเห็นได้ อาจได้คะแนนสูงกว่าโพสต์ที่มีคุณภาพแต่ไม่มีใครมาร่วมโต้ตอบเลย ระบบแบบนี้อาจมีหลักการพื้นฐานอยู่ในลักษณะนี้ก็ได้
อย่างไรก็ตาม รุ่นที่เปิดเผยแหล่งที่มาใหม่นั้นไม่ได้เปิดเผยค่าความสำคัญของพฤติกรรมที่เฉพาะเจาะจง แต่รุ่นปี 2023 ได้เปิดเผยค่านั้นไว้
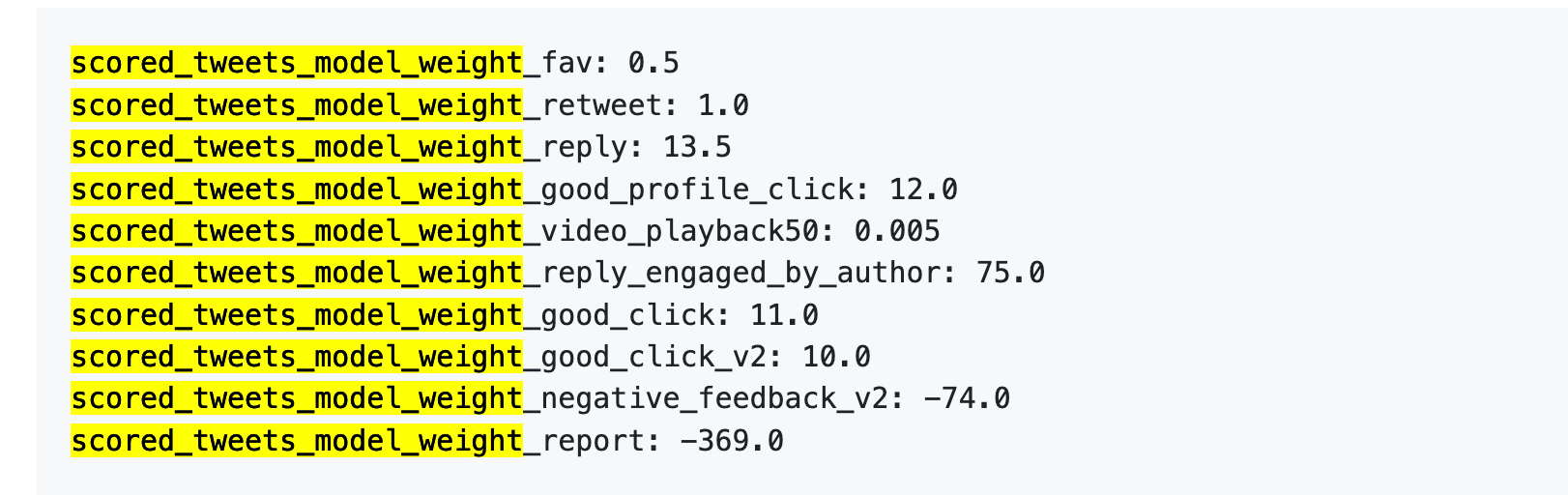
ข้อมูลอ้างอิงรุ่นเก่า: การรายงาน 1 ครั้ง = การไลก์ 738 ครั้ง
จากนี้ไป เราสามารถดูข้อมูลชุดปี 23 ได้ แม้จะเป็นข้อมูลเก่า แต่มันจะช่วยให้คุณเข้าใจความแตกต่างของ "คุณค่า" ที่พฤติกรรมต่างๆ มีต่ออัลกอริทึมได้ค่ะ
เมื่อวันที่ 5 เมษายน ปี 2023 X ได้เปิดเผยชุดข้อมูลน้ำหนักอย่างเป็นทางการบน GitHub จริง
ตัวเลขโดยตรง:
แปลให้ตรงตัวมากขึ้น:
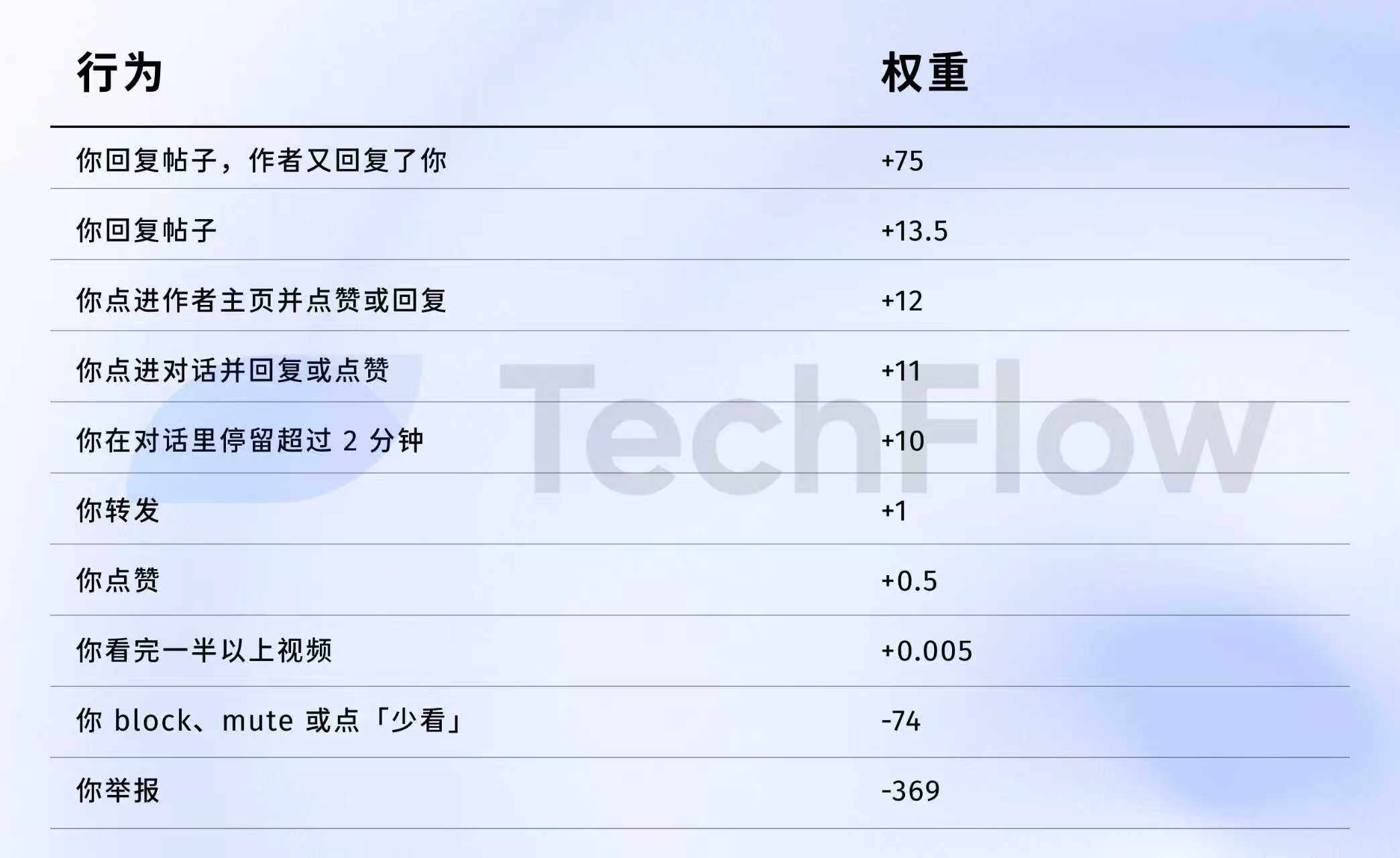
แหล่งข้อมูล: เวอร์ชันเก่า คลังข้อมูล the-algorithm-ml ของ Twitter/GitHubคลิกเพื่อดูอัลกอริทึมต้นฉบับ
ตัวเลขบางตัวน่าจะต้องดูให้ละเอียด
ประการแรก ไลก์เกือบจะไม่มีค่าอะไรเลย น้ำหนักมีเพียง 0.5 เท่านั้น ซึ่งต่ำที่สุดในบรรดาพฤติกรรมเชิงบวกทั้งหมด สำหรับอัลกอริทึมแล้ว คุณค่าของคำชื่นชมหนึ่งครั้งเทียบเท่ากับศูนย์เกือบจะเท่ากัน
ประการที่สอง การโต้ตอบเป็นสิ่งที่มีคุณค่าที่สุด "น้ำหนักของ 'คุณตอบกลับ และผู้เขียนตอบกลับคุณ' คือ 75 ซึ่งมากกว่าการกดไลก์ถึง 150 เท่า ขั้นตอนของอัลกอริทึมต้องการเห็นการสนทนาที่เป็นการโต้ตอบสองทางมากกว่าการกดไลก์แบบเดียวทาง"
ประการที่สาม ต้นทุนของข้อมูลย้อนกลับในแง่ลบสูงมาก การถูกบล็อกหรือมิวท์ (-74) จะต้องมีการไลค์ 148 ครั้งจึงจะสามารถชดเชยได้ และการถูกรายงาน (-369) จะต้องมีการไลค์ 738 ครั้ง ทั้งนี้คะแนนติดลบเหล่านี้จะถูกสะสมเข้าไปในคะแนนความน่าเชื่อถือของบัญชีของคุณ และส่งผลต่อการกระจายโพสต์ทั้งหมดของคุณต่อไป
สี่ ค่าน้ำหนักของการดูวิดีโอจนจบต่ำเกินไปอย่างไม่น่าเชื่อ มันคือ 0.005 เท่านั้น ซึ่งแทบจะไม่ต้องคำนึงถึงเลย ซึ่งแตกต่างอย่างชัดเจนจาก Douyin และ TikTok ที่ใช้อัตราการดูคลิปจบเป็นตัวชี้วัดหลัก
ในเอกสารเดียวกันยังระบุไว้ด้วยว่า "น้ำหนักที่แนบมากับไฟล์สามารถปรับเปลี่ยนได้ตลอดเวลา... นับจากนั้นมา เราได้ปรับน้ำหนักเป็นระยะเพื่อปรับปรุงประสิทธิภาพของแพลตฟอร์ม"
น้ำหนักสามารถปรับเปลี่ยนได้ตลอดเวลา และได้มีการปรับแล้วจริงๆ
เวอร์ชันใหม่ไม่ได้เปิดเผยค่าตัวเลขที่ชัดเจน แต่กรอบแนวคิดที่เขียนใน README นั้นเหมือนเดิม: การเพิ่มคะแนนในทางบวก การหักคะแนนในทางลบ และการคำนวณผลรวมแบบมีน้ำหนัก
ตัวเลขอาจเปลี่ยนไป แต่ความสัมพันธ์ของระดับยังคงเหมือนเดิม การตอบกลับความคิดเห็นของผู้อื่น มีประโยชน์มากกว่าการได้รับไลค์ 100 ครั้ง การที่ทำให้ผู้อื่นอยากบล็อกคุณ แย่กว่าการไม่มีปฏิสัมพันธ์จากผู้อื่นเสียอีก
หลังจากทราบถึงเรื่องเหล่านี้แล้ว ผู้สร้างสรรค์อย่างเราสามารถทำอะไรได้บ้าง
การวิเคราะห์และเปรียบเทียบโค้ดอัลกอริทึมเก่าและใหม่ของ Twitter แล้วสรุปเป็นข้อคิดหรือแนวทางปฏิบัติที่สามารถนำไปใช้ได้บางประการ
1. ตอบกลับผู้แสดงความคิดเห็นของคุณ ในตารางน้ำหนักคะแนน "การตอบกลับผู้แสดงความคิดเห็น" มีคะแนนสูงสุด (+75) ซึ่งสูงกว่าการที่ผู้ใช้กดไลก์เพียงฝ่ายเดียวถึง 150 เท่า นี่ไม่ได้หมายความว่าคุณต้องไปขอให้คนแสดงความคิดเห็น แต่เมื่อมีคนแสดงความคิดเห็นแล้ว คุณควรตอบกลับ แม้เพียงแค่ตอบว่า "ขอบคุณ" ก็ตาม ระบบอัลกอริทึมก็จะบันทึกคะแนนนี้ไว้เช่นกัน
2. อย่าปล่อยให้ใครคิดว่าจะหนีไปได้ การ block หนึ่งครั้งมีผลเสียต่อคุณมากพอที่จะต้องใช้การกดไลก์ 148 ครั้งถึงจะสามารถชดเชยได้ ความขัดแย้งและเนื้อหาที่เป็นที่ถกเถียงนั้นสามารถดึงดูดการมีส่วนร่วมได้จริง แต่ถ้าการมีส่วนร่วมนั้นเป็นการบ่นว่า "คนนี้น่ารำคาญ ไป block เขาเลย" คะแนนความน่าเชื่อถือของบัญชีคุณจะลดลงต่อเนื่อง และส่งผลต่อการกระจายเนื้อหาโพสต์ต่อไปทั้งหมด ความนิยมจากความขัดแย้งเป็นดาบสองคม ดังนั้นก่อนจะตัดสินผู้อื่น ควรตัดสินตัวเองก่อน
3. วางลิงก์ภายนอกในส่วนแสดงความคิดเห็นอัลกอริทึมไม่ต้องการที่จะนำผู้ใช้ไปยังเว็บไซต์ภายนอก ข้อความที่มีลิงก์จะถูกลดความสำคัญสิ่งนี้มัสก์เองก็ได้กล่าวไว้เปิดเผย ถ้าต้องการจะนำผู้อ่านไปยังเนื้อหาอื่น ให้เขียนเนื้อหาหลักในโพสต์ และใส่ลิงก์ไว้ในความคิดเห็นแรก
4. อย่าพิมพ์ข้อความซ้ำๆ จนเต็มหน้าจอ ในเวอร์ชันใหม่มีสิ่งที่เรียกว่า Author Diversity Scorer ซึ่งมีหน้าที่ลดน้ำหนักของโพสต์ที่ผู้ใช้คนเดียวกันโพสต์ติดกันหลายครั้ง จุดประสงค์หลักคือเพื่อให้ฟีดของผู้ใช้มีความหลากหลายมากขึ้น ส่วนผลข้างเคียงคือ การโพสต์ติดกัน 10 ครั้ง ไม่ได้มีประสิทธิภาพเท่ากับการโพสต์เนื้อหาคุณภาพดีเพียงครั้งเดียว
6. ไม่มีเวลาที่ดีที่สุดในการโพสต์แล้ว อัลกอริทึมรุ่นเก่ามีคุณสมบัติของมนุษย์อย่าง "เวลาที่โพสต์" แต่รุ่นใหม่กลับถอดมันออกไปทันที ฟีนิกซ์ (Phoenix) ดูเพียงลำดับพฤติกรรมของผู้ใช้เท่านั้น ไม่ได้ดูเวลาที่โพสต์ไว้ กลยุทธ์ที่เคยแนะนำว่า "โพสต์เวลา 3 ทุ่มวันอังคารจะได้ผลดีที่สุด" ตอนนี้มีคุณค่าในการอ้างอิงน้อยลงทุกวัน
สิ่งที่กล่าวมานี้คือสิ่งที่สามารถอ่านได้จากด้านโค้ดเท่านั้น
ยังมีรายการเพิ่ม-ลดคะแนนอื่น ๆ อีกจากเอกสารสาธารณะของ X ที่ไม่ได้อยู่ในคลังข้อมูลโอเพนซอร์สครั้งนี้: การรับรองด้วยสีน้ำเงินจะได้รับการเพิ่มคะแนน ส่วนข้อความที่พิมพ์ทั้งหมดเป็นตัวพิมพ์ใหญ่จะถูกลดความสำคัญ และเนื้อหาที่เป็นอันตรายจะทำให้อัตราการส่งถึงลดลง 80% กฎเหล่านี้ไม่ได้ถูกเปิดเผยแหล่งที่มา จึงขอไม่ขยายความเพิ่มเติม
สรุปแล้ว ครั้งนี้เปิดเผยแหล่งข้อมูลได้ดีมาก
สถาปัตยกรรมระบบแบบครบวงจร ตรรกะการเรียกคืนเนื้อหาที่เป็นไปได้ ขั้นตอนการจัดลำดับและการให้คะแนน การทำงานของตัวกรองต่างๆ โค้ดส่วนใหญ่เขียนด้วย Rust และ Python โครงสร้างชัดเจน และ README ถูกเขียนอย่างละเอียดมากกว่าโครงการเชิงพาณิชย์หลายโครงการเสียอีก
แต่มีบางสิ่งสำคัญที่ไม่ได้ถูกปล่อยออกมา
1. ยังไม่เปิดเผยพารามิเตอร์น้ำหนัก ในโค้ดมีเพียงการระบุว่า "พฤติกรรมเชิงบวกจะได้คะแนนเพิ่ม ส่วนพฤติกรรมเชิงลบจะถูกลดคะแนน" แต่ไม่ได้ระบุว่าการกดไลก์จะได้คะแนนเท่าไหร่ การบล็อกจะถูกลดคะแนนเท่าไหร่ ฉบับปี 2023 อย่างน้อยก็ได้ระบุตัวเลขชัดเจน แต่ครั้งนี้กลับให้เพียงกรอบสูตรเท่านั้น
2. น้ำหนักโมเดลยังไม่เปิดเผย Phoenix ใช้ Grok transformer แต่ไม่ได้เปิดเผยพารามิเตอร์ของโมเดล คุณสามารถดูได้ว่าโมเดลถูกเรียกใช้อย่างไร แต่ไม่สามารถดูวิธีการคำนวณภายในของโมเดลได้
3. ข้อมูลฝึกอบรมไม่ได้เปิดเผย ไม่มีการกล่าวถึงว่าโมเดลถูกฝึกด้วยข้อมูลใด การเก็บตัวอย่างพฤติกรรมของผู้ใช้ และการสร้างตัวอย่างบวกและตัวอย่างลบ คืออย่างไรบ้าง
ลองเปรียบเทียบให้เห็นภาพง่ายขึ้น ครั้งนี้การเปิดเผยแหล่งข้อมูลแบบเปิด (open source) ก็เหมือนกับการบอกคุณว่า "เราใช้การรวมน้ำหนัก (weighted sum) ในการคำนวณคะแนนรวม" แต่ไม่บอกคุณว่าแต่ละน้ำหนักมีค่าเท่าไร; หรือเหมือนกับการบอกคุณว่า "เราใช้ transformer ในการทำนายความน่าจะเป็นของพฤติกรรม" แต่ไม่บอกคุณว่าภายใน transformer มีลักษณะเป็นอย่างไร
เมื่อเปรียบเทียบกันในระดับเดียวกัน ทั้ง TikTok และ Instagram ยังไม่เคยเปิดเผยข้อมูลเหล่านี้เลย ข้อมูลที่ X ปลดล็อกในครั้งนี้ ถือว่ามีมากกว่าแพลตฟอร์มหลักอื่นๆ อย่างแน่นอน แต่ยังไม่ถึงขั้น "โปร่งใสอย่างสมบูรณ์"
นี่ไม่ได้หมายความว่าโอเพนซอร์สไร้คุณค่า สำหรับนักสร้างสรรค์และนักวิจัยแล้ว การได้เห็นโค้ดย่อมดีกว่าการไม่เห็นเสมอ