










ลองจินตนาการถึงสถานการณ์นี้:
คุณให้ AI Agent ช่วยแก้บั๊กในโค้ด มันเปิดโปรเจกต์ อ่านไฟล์ 20 ไฟล์ แก้ไขบางส่วน รันการทดสอบ แต่ไม่ผ่าน จึงแก้ใหม่ รันอีกครั้ง ก็ยังไม่ผ่าน… ลองผิดลองถูกหลายสิบรอบ สุดท้าย—ก็ยังแก้ไม่สำเร็จ
คุณปิดคอมพิวเตอร์และผ่อนคลายใจ แล้วก็ได้รับใบแจ้งหนี้ API
ตัวเลขด้านบนอาจทำให้คุณต้องตะลึง—การที่ AI Agent ซ่อมบั๊กเองภายใต้ API อย่างเป็นทางการของต่างประเทศ งานที่ยังไม่ได้รับการซ่อมแซมแต่ละครั้งมักใช้โทเค็นมากกว่าหนึ่งล้าน ค่าใช้จ่ายอาจสูงถึงหลายสิบถึงกว่าหนึ่งร้อยดอลลาร์
ในเดือนเมษายนปี 2026 งานวิจัยที่เผยแพร่ร่วมโดยสแตนฟอร์ด MIT และมหาวิทยาลัยมิชิแกน ได้เปิดเผยครั้งแรกซึ่งเป็นระบบการ “เปิดกล่องดำ” ของการใช้งาน AI Agent ในการทำงานด้านโค้ด—ว่าเงินถูกใช้ไปที่ไหน คุ้มค่าหรือไม่ และสามารถคาดการณ์ล่วงหน้าได้หรือไม่ คำตอบทำให้ตกใจ
การค้นพบที่หนึ่ง: ต้นทุนการเขียนโค้ดของ Agent รวดเร็วถึง 1,000 เท่าของการสนทนาด้วย AI ทั่วไป
ผู้ใช้บางคนอาจคิดว่า การให้ AI เขียนโค้ดให้คุณ และการให้ AI พูดคุยกับคุณเกี่ยวกับโค้ด ควรใช้เงินเท่ากัน
เอกสารวิจัยแสดงการเปรียบเทียบว่า:
การใช้โทเค็นสำหรับงานเขียนโค้ดแบบ Agentic ใช้ประมาณ 1,000 เท่าของงานคำถามและเหตุผลเกี่ยวกับโค้ดทั่วไป
ต่างกันสามระดับของจำนวนเต็ม
ทำไมถึงเป็นเช่นนี้? วิทยานิพนธ์ชี้ให้เห็นข้อเท็จจริงหนึ่งว่า เงินไม่ได้ถูกใช้ไปกับ “การเขียนโค้ด” แต่ถูกใช้ไปกับ “การอ่านโค้ด”
ที่นี่คำว่า “อ่าน” ไม่ได้หมายถึงมนุษย์อ่านโค้ด แต่หมายถึง Agent ในกระบวนการทำงานต้อง continuously “ป้อน” บริบททั้งหมดของโปรเจกต์ ประวัติการดำเนินการก่อนหน้า ข้อผิดพลาด และเนื้อหาไฟล์ทั้งหมดให้กับโมเดล ทุกครั้งที่มีการสนทนาเพิ่มเติม บริบทนี้จะยาวขึ้นอีกหนึ่งรอบ; และโมเดลคิดค่าบริการตามจำนวน Token — คุณป้อนมากเท่าไหร่ คุณก็ต้องจ่ายมากเท่านั้น
ตัวอย่างเช่น: มันเหมือนกับการจ้างช่างซ่อมที่ต้องให้คุณอ่านแผนทั้งตึกทุกหน้าให้เขาฟังก่อนที่เขาจะขยับประแจแม้แต่ครั้งเดียว—ค่าใช้จ่ายในการอ่านแผนนั้นแพงกว่าค่าใช้จ่ายในการขันสกรูมาก
กระดาษวิจัยสรุปปรากฏการณ์นี้เป็นประโยคเดียว: ต้นทุนของตัวแทนถูกขับเคลื่อนโดยการเติบโตแบบเลขชี้กำลังของโทเค็นขาเข้า ไม่ใช่โทเค็นขาออก
การค้นพบที่สอง: บั๊กเดียวกัน รันสองครั้ง ค่าใช้จ่ายอาจต่างกันเป็นสองเท่า—และยิ่งบั๊กที่มีราคาสูงเท่าไหร่ ก็ยิ่งไม่เสถียรเท่านั้น
สิ่งที่น่าปวดหัวมากกว่านั้นคือความสุ่ม
นักวิจัยให้เอเจนต์เดียวกันดำเนินการเดียวกันเป็นเวลา 4 ครั้ง และพบว่า:
- ระหว่างงานต่างๆ งานที่แพงที่สุดใช้ Token มากกว่างานที่ถูกที่สุดประมาณ 7 ล้านโทเค็น (รูปที่ 2a)
- ในการรันหลายครั้งด้วยโมเดลเดียวกันและงานเดียวกัน ค่าใช้จ่ายสูงสุดอยู่ที่ประมาณสองเท่าของค่าใช้จ่ายต่ำสุด (รูปที่ 2b)
- ในขณะเดียวกัน หากเปรียบเทียบงานเดียวกันข้ามโมเดล ความแตกต่างระหว่างการใช้งานสูงสุดและต่ำสุดสามารถสูงถึง 30 เท่า
ตัวเลขสุดท้ายนี้น่าสนใจเป็นพิเศษ: หมายความว่า ความแตกต่างของต้นทุนระหว่างการเลือกโมเดลที่ถูกต้องกับการเลือกโมเดลที่ผิดพลาด ไม่ใช่แค่ “แพงกว่านิดหน่อย” แต่คือ “แพงกว่าหนึ่งระดับขนาด”
ที่น่าเจ็บใจกว่านั้นคือ—การใช้จ่ายมากไม่ได้หมายความว่าทำได้ดี
การวิจัยพบเส้นโค้งรูปตัว U กลับด้าน:
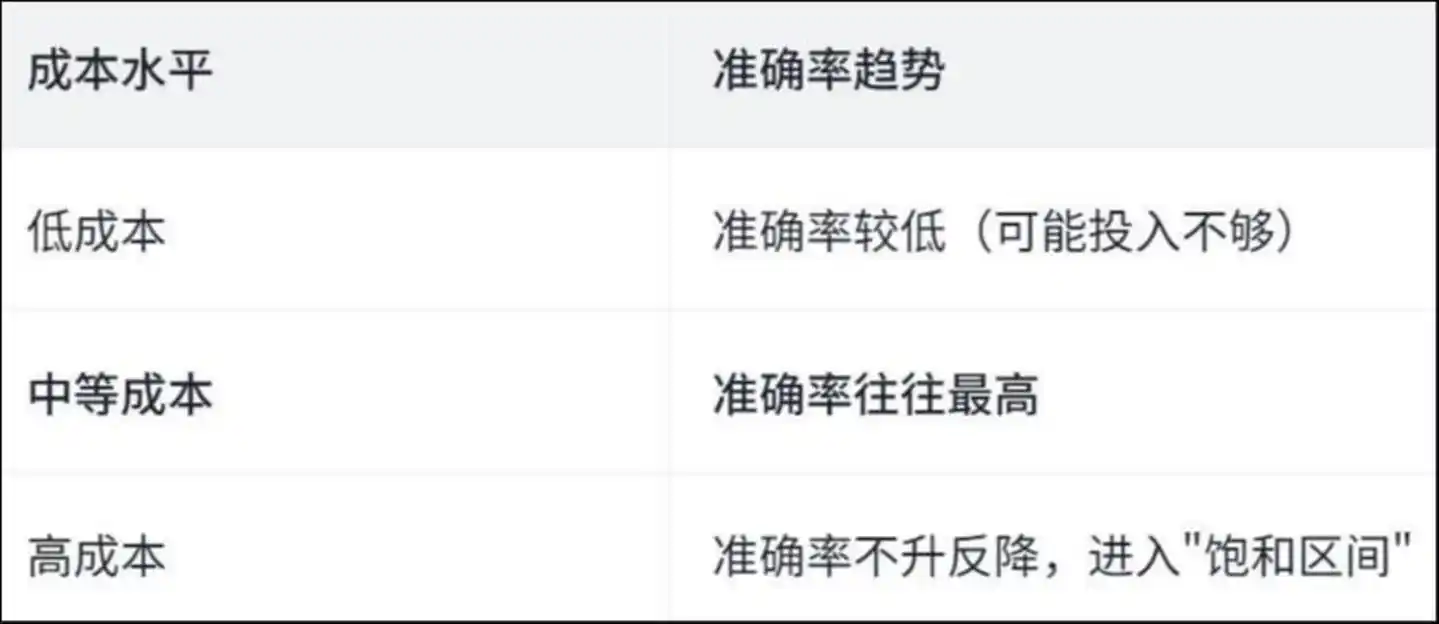
แนวโน้มความแม่นยำของระดับต้นทุน: ต้นทุนต่ำ ความแม่นยำต่ำ (อาจมีการลงทุนไม่เพียงพอ) ต้นทุนปานกลาง ความแม่นยำมักสูงที่สุด ต้นทุนสูง ความแม่นยำไม่เพิ่มขึ้นกลับลดลง 進入 "ช่วงอิ่มตัว"
ทำไมถึงเป็นเช่นนี้? วิทยานิพนธ์ให้คำตอบผ่านการวิเคราะห์การดำเนินการที่เฉพาะเจาะจงของ Agent —
ในระหว่างการดำเนินงานที่มีต้นทุนสูง ตัวแทนใช้เวลาจำนวนมากไปกับ “งานซ้ำซ้อน”
การวิจัยพบว่าในการดำเนินการที่มีต้นทุนสูง ประมาณ 50% ของการดูไฟล์และการแก้ไขไฟล์เป็นการซ้ำซ้อน—กล่าวคือ ตัวแทนอ่านไฟล์เดียวกันซ้ำแล้วซ้ำเล่าและแก้ไขบรรทัดโค้ดเดียวกันซ้ำๆ เหมือนคนที่เดินวนอยู่ในห้อง ยิ่งเดินยิ่งงุนงง ยิ่งงุนงงยิ่งเดินวน
เงินไม่ได้ใช้เพื่อแก้ปัญหา แต่ใช้ไปกับการหลงทาง
พบสาม: ประสิทธิภาพการใช้พลังงานระหว่างโมเดลต่างกันอย่างมาก—GPT-5 ประหยัดที่สุด บางโมเดลใช้ Token เพิ่มขึ้นถึง 1.5 ล้าน
การวิจัยได้ทดสอบประสิทธิภาพของตัวแทนจากโมเดลขนาดใหญ่ชั้นนำ 8 รุ่นบน SWE-bench Verified ซึ่งเป็นมาตรฐานอุตสาหกรรม (500 ปัญหา GitHub จริง) เมื่อแปลงเป็นดอลลาร์ โมเดลที่มีประสิทธิภาพด้านโทเค็นสูงสามารถใช้จ่ายเงินเพิ่มขึ้นหลายสิบดอลลาร์ต่อภารกิจ เมื่อนำไปใช้ในแอปพลิเคชันระดับองค์กร—ซึ่งรันภารกิจหลายร้อยรายการต่อวัน—ความแตกต่างนี้จึงกลายเป็นเงินจริง
การค้นพบที่น่าสนใจอีกประการหนึ่งคือ: ประสิทธิภาพของโทเค็นเป็น “บุคลิกภาพที่เป็นธรรมชาติ” ของโมเดล ไม่ใช่ผลมาจากงานนั้นๆ
นักวิจัยแยกงานที่โมเดลทั้งหมดแก้ได้สำเร็จ (230 งาน) และงานที่โมเดลทั้งหมดล้มเหลว (100 งาน) มาเปรียบเทียบ และพบว่าอันดับสัมพัทธ์ของโมเดลแทบไม่เปลี่ยนแปลง
นี่แสดงว่า: บางโมเดลมีธรรมชาติที่ “พูดมาก” โดยไม่เกี่ยวข้องกับความยากของงาน
ยังมีการค้นพบที่น่าพิจารณาอีกประการหนึ่ง: แบบจำลองขาดความตระหนักเรื่องการตั้งจุดตัดขาด
เมื่อเผชิญกับงานที่ยากจนโมเดลทั้งหมดไม่สามารถแก้ไขได้ ตัวแทนที่สมบูรณ์ควรยอมแพ้ตั้งแต่เนิ่นๆ แทนที่จะใช้จ่ายเงินต่อไป แต่ในความเป็นจริง โมเดลส่วนใหญ่ใช้โทเค็นมากขึ้นในงานที่ล้มเหลว—พวกมันไม่เคย “ยอมแพ้” แต่กลับยังคงค้นหา ลองใหม่ และอ่านบริบทซ้ำๆ เหมือนรถยนต์ที่ไม่มีไฟเตือนระดับน้ำมัน ขับไปจนกระทั่งเสียกลางทาง
การค้นพบที่สี่: สิ่งที่มนุษย์รู้สึกว่ายาก ตัวแทนอาจไม่รู้สึกว่าแพง—การรับรู้ถึงความยากลำบากผิดเพี้ยนอย่างสมบูรณ์
คุณอาจคิดว่า: อย่างน้อยฉันก็สามารถคาดการณ์ต้นทุนตามความยากง่ายของงานได้ใช่ไหม?
นำงาน 500 ชิ้นไปให้ผู้เชี่ยวชาญด้านมนุษย์ให้คะแนนความยาก จากนั้นเปรียบเทียบกับการใช้โทเค็นจริงของเอเจนต์—
ผลลัพธ์: มีความสัมพันธ์อ่อนระหว่างทั้งสองอย่าง
พูดให้เข้าใจง่ายๆ: งานที่มนุษย์คิดว่ายากมากและต้องใช้ทรัพยากรเยอะ ตัว Agent อาจจัดการได้ง่ายๆ โดยไม่ต้องใช้เงินมากนัก; แต่งานที่มนุษย์คิดว่าง่ายๆ ตัว Agent อาจใช้ทรัพยากรจนแทบจะสูญเสียความเชื่อมั่น
นี่เป็นเพราะความยากที่มนุษย์และ AI “เห็น” นั้นไม่เหมือนกันเลย:
- มนุษย์มองที่: ความซับซ้อนของตรรกะ ความยากของอัลกอริทึม และอุปสรรคในการเข้าใจธุรกิจ
- ตัวแทนพิจารณา: ขนาดของโครงการ จำนวนไฟล์ที่ต้องอ่าน ความยาวของเส้นทางการสำรวจ และจะมีการแก้ไขไฟล์เดียวกันซ้ำๆ หรือไม่
ข้อบกพร่องที่มนุษย์คิดว่า “แก้แค่บรรทัดเดียว” ตัวแทนอาจต้องอ่านโครงสร้างของโค้ดทั้งหมดก่อนจึงจะสามารถระบุบรรทัดนั้นได้—การ “อ่าน” เพียงอย่างเดียวอาจใช้โทเค็นจำนวนมาก ในขณะที่ปัญหาอัลกอริธึมที่มนุษย์คิดว่า “ตรรกะซับซ้อน” ตัวแทนอาจรู้วิธีแก้มาตรฐานอยู่แล้ว และแก้ไขได้อย่างรวดเร็ว
นี่ทำให้เกิดความจริงที่อึดอัด: นักพัฒนาแทบเป็นไปไม่ได้ที่จะคาดการณ์ต้นทุนการดำเนินงานของ Agent ด้วยสัญชาตญาณ
การค้นพบที่ห้า: แม้แต่โมเดลเองก็คำนวณค่าใช้จ่ายของตัวเองไม่ถูก
ถ้ามนุษย์คาดเดาไม่ได้ แล้วให้ AI ทำนายเองล่ะ?
นักวิจัยออกแบบการทดลองที่ชาญฉลาด: ให้ Agent ตรวจสอบโค้ดเบสก่อนเริ่มซ่อมบั๊กจริง และประมาณจำนวน Token ที่จะใช้ — แต่ไม่ได้ดำเนินการซ่อมจริง
ผลลัพธ์เป็นอย่างไร?
ทุกโมเดล ล้มหายตายจากทั้งหมด
ผลลัพธ์ที่ดีที่สุดคือความสัมพันธ์ของการทำนายโทเค็นของ Claude Sonnet-4.5 — 0.39 (เต็ม 1.0) โมเดลส่วนใหญ่มีความสัมพันธ์ในการทำนายอยู่ระหว่าง 0.05 ถึง 0.34 โดย Gemini-3-Pro ต่ำที่สุดที่เพียง 0.04 — ใกล้เคียงกับการเดาแบบสุ่ม
ที่น่าประหลาดยิ่งกว่านั้น: แบบจำลองทั้งหมดลดค่าการใช้โทเค็นของตนเองอย่างเป็นระบบ จุดข้อมูลในแผนภาพกระจายของรูปที่ 11 แทบทั้งหมดอยู่ด้านล่าง “เส้นการทำนายที่สมบูรณ์แบบ” — แบบจำลองรู้สึกว่า “ไม่ได้ใช้มากขนาดนั้น” แต่จริงๆ แล้วกลับใช้มากกว่า และอคติในการลดค่านี้รุนแรงยิ่งขึ้นเมื่อไม่ได้ให้ตัวอย่าง
ที่น่าขำกว่านั้นคือ—การพยากรณ์เองก็ต้องเสียเงิน
ต้นทุนการพยากรณ์ของ Claude Sonnet-3.7 และ Sonnet-4 สูงถึงมากกว่าสองเท่าของต้นทุนงานเอง กล่าวคือ การให้พวกมัน “ประเมินราคา” ก่อน ยังแพงกว่าการลงมือทำงานโดยตรง
ข้อสรุปของงานวิจัยนั้นตรงไปตรงมา:
ในขณะนี้ แบบจำลองขั้นสูงไม่สามารถคาดการณ์การใช้งานโทเค็นของตนเองได้อย่างแม่นยำ การคลิกที่ “รัน Agent” ก็เหมือนเปิดกล่องของขวัญ—คุณต้องรอจนได้ใบแจ้งหนี้จึงจะรู้ว่าใช้ไปเท่าใด
เบื้องหลังบัญชีที่สับสนนี้ ซ่อนอยู่ปัญหาอุตสาหกรรมที่ใหญ่กว่า
อ่าน到这里,你可能会问:这些发现对企业意味着什么?
รูปแบบการกำหนดราคาแบบสมัครรายเดือน กำลังถูก Agent ทำให้เกิดรอยร้าว
เอกสารวิจัยชี้ว่า โมเดลแบบสมัครสมาชิกเช่น ChatGPT Plus สามารถดำเนินการได้เพราะการใช้ Token สำหรับการสนทนาทั่วไปมีความควบคุมและคาดการณ์ได้ค่อนข้างดี แต่ภารกิจของ Agent ทำลายสมมติฐานนี้อย่างสมบูรณ์—ภารกิจหนึ่งอาจใช้ Token ปริมาณมหาศาลได้เพราะ Agent ติดอยู่ในวัฏจักร
นั่นหมายความว่า ราคาแบบสมัครสมาชิกแบบบริสุทธิ์อาจไม่ยั่งยืนสำหรับสถานการณ์ของ Agent และการคิดค่าบริการตามการใช้งาน (Pay-as-you-go) จะยังคงเป็นตัวเลือกที่เป็นจริงที่สุดในระยะยาว แต่ปัญหาของการคิดค่าบริการตามการใช้งานคือ—ปริมาณการใช้งานนั้นไม่สามารถคาดการณ์ได้
2. ประสิทธิภาพของโทเค็นควรเป็น “ตัวชี้วัดที่สาม” ในการเลือกรุ่น
โดยทั่วไป บริษัทเลือกโมเดลด้วยสองมิติ: ความสามารถ (ทำได้หรือไม่) และความเร็ว (ทำเร็วแค่ไหน) บทความนี้ได้เสนอมิติที่สามที่มีความสำคัญเท่าเทียมกัน: ประสิทธิภาพด้านพลังงาน (ใช้ค่าใช้จ่ายเท่าใดจึงจะสำเร็จ)
โมเดลที่มีความสามารถน้อยกว่าเล็กน้อยแต่มีประสิทธิภาพสูงกว่าสามเท่า อาจมีมูลค่าทางเศรษฐกิจมากกว่าโมเดลที่ “แข็งแกร่งที่สุดแต่ใช้ทรัพยากรมากที่สุด” ในสถานการณ์ที่ต้องขยายขนาด
3. ตัวแทนต้องการ “มาตรวัดน้ำมัน” และ “เบรก”
เอกสารวิจัยกล่าวถึงทิศทางในอนาคตที่น่าสนใจ—นโยบายการใช้เครื่องมือที่รับรู้งบประมาณ (Budget-aware tool-use policies) กล่าวคือ การติดตั้ง “มาตรวัดน้ำมัน” ให้กับตัวแทน: เมื่อการใช้โทเค็นใกล้ถึงงบประมาณที่กำหนด ให้บังคับให้มันหยุดการสำรวจที่ไม่มีประสิทธิภาพ แทนที่จะใช้จ่ายจนหมด
ในปัจจุบัน โครงสร้างพื้นฐานของ Agent หลักๆ แทบทั้งหมดขาดกลไกนี้
ปัญหาการใช้จ่ายเงินของตัวแทน ไม่ใช่บั๊ก แต่เป็นความเจ็บปวดที่อุตสาหกรรมต้องผ่านไป
เอกสารวิจัยนี้เปิดเผยไม่ใช่ข้อบกพร่องของโมเดลใดโมเดลหนึ่ง แต่เป็นความท้าทายเชิงโครงสร้างของรูปแบบ Agent ทั้งหมด—เมื่อ AI ก้าวข้ามจากการตอบคำถามแบบหนึ่งต่อหนึ่งไปสู่การวางแผนด้วยตนเอง การดำเนินการหลายขั้นตอน และการปรับแก้ซ้ำๆ การใช้ Token ที่ไม่สามารถคาดเดาได้แทบจะเป็นเรื่องที่หลีกเลี่ยงไม่ได้
ข่าวดีคือ นี่เป็นครั้งแรกที่มีใครสักคนเปิดเผยและคำนวณบัญชีที่ยุ่งเหยิงนี้อย่างเป็นระบบ ด้วยข้อมูลนี้ นักพัฒนาสามารถเลือกโมเดล ตั้งงบประมาณ และออกแบบกลไกการตัดขาดทุนได้อย่างชาญฉลาดยิ่งขึ้น ในขณะเดียวกัน ผู้ผลิตโมเดลก็มีทิศทางการปรับปรุงใหม่—ไม่ใช่แค่ทำให้แข็งแกร่งขึ้น แต่ยังต้องทำให้ประหยัดมากขึ้น
ในที่สุดแล้ว ก่อนที่ AI Agent จะเข้าสู่สภาพแวดล้อมการผลิตในอุตสาหกรรมต่างๆ อย่างแท้จริง การใช้จ่ายเงินทุกบาททุกสตางค์อย่างมีเหตุผล สำคัญกว่าการเขียนโค้ดแต่ละบรรทัดให้สวยงาม (บทความนี้เผยแพร่ครั้งแรกบนแอป Taimeiti ผู้เขียน | Silicon Valley Tech news บรรณาธิการ | Zhao Hongyu)
หมายเหตุ: บทความนี้อ้างอิงจากบทความต้นฉบับที่เผยแพร่บน arXiv เมื่อวันที่ 24 เมษายน 2026 เรื่อง *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei) ผู้เขียนมาจากสถาบันต่างๆ เช่น มหาวิทยาลัยเวอร์จิเนีย มหาวิทยาลัยสแตนฟอร์ด MIT และมหาวิทยาลัยมิชิแกน การศึกษานี้ยังไม่ผ่านการทบทวนโดยผู้เชี่ยวชาญ