









โมเดลคือสมองของ OpenClaw ซึ่งส่งผลโดยตรงต่อประสิทธิภาพการใช้งาน
ผู้เขียนบทความ: จางไห่หนิง
ที่มาของข้อความ: Henry Notes
ล่าสุดได้ลองวิธีการติดตั้งและปรับใช้ OpenClaw หลายแบบ เช่น เซิร์ฟเวอร์จริง เซิร์ฟเวอร์คลาวด์ เครื่องเสมือน คอนเทนเนอร์ โมเดลจากในและนอกประเทศ รวมถึงเครือข่ายต่างๆ สรุปแล้วค่อนข้างซับซ้อนและมีหลายปัจจัยที่ต้องพิจารณา จึงวางแผนเขียนบทความสรุปเชิงรวมรวม บทความนี้เป็นส่วนก่อนหน้า โดยจะพูดถึงองค์ประกอบที่สำคัญมาก: การเลือกโมเดล
โมเดลคือสมองของ OpenClaw ซึ่งส่งผลโดยตรงต่อประสิทธิภาพการใช้งาน ปัจจุบันมีความเห็นร่วมกันว่า โมเดลจากต่างประเทศมีระดับปัญญาสูงกว่าโมเดลในประเทศ แต่โมเดลจากต่างประเทศต้องใช้การเชื่อมต่ออินเทอร์เน็ตผ่านการเข้าถึงแบบวิทยาศาสตร์ มีราคาสูง และต้องใช้วิธีการชำระเงินจากต่างประเทศ หากไม่ระมัดระวังอาจถูกแบนบัญชี แม้ว่าจะมีจุดกลางที่ให้บริการในราคาที่คุ้มค่ากว่า แต่เนื่องจากอยู่ในเขตสีเทา จึงมีความไม่แน่นอนอยู่บ้าง ดังนั้น ผู้ใช้งานที่ต้องการความเสถียรของบริการส่วนใหญ่จึงเลือกใช้โมเดลในประเทศ
บทความนี้เปรียบเทียบการใช้งานและราคาของโมเดลต่างๆ ในประเทศ พร้อมให้คำแนะนำบางประการสำหรับการอ้างอิง
หลังจาก OpenClaw โครงร่าง AI Agent แบบเปิดแหล่งที่มาได้รับความนิยมอย่างรวดเร็วในประเทศ ได้นำการปฏิวัติด้านผลิตภาพมาพร้อมกับใบแจ้งหนี้ที่น่าตกใจ
โหมดการทำงานของ OpenClaw แตกต่างอย่างสิ้นเชิงจาก AI แบบสนทนาในเบราว์เซอร์หรือแอปแบบดั้งเดิม หลังจากผู้ใช้ส่งคำสั่งหนึ่งคำ ระบบจะทริกเกอร์การเรียกใช้โมเดลหลายสิบถึงหลายร้อยครั้ง โดยอ่านไฟล์ สร้างโค้ด และดีบักการดำเนินการ ทั้งกระบวนการนี้ใช้ Token ตลอดเวลา
งานพัฒนาแบบฟูลสแต็กที่มีความซับซ้อนปานกลาง อาจมีการเรียกใช้โมเดลระหว่าง 10 ถึง 40 รอบ หากใช้โมเดลระดับพรีเมียมที่รองรับบริบทถึง 200K ค่าใช้จ่ายต่องานจะสูงถึงหลายสิบหยวน
📊 การคำนวณต้นทุนที่แท้จริง
ตัวอย่างงานที่มีความซับซ้อนปานกลาง: OpenClaw กระตุ้นการสนทนาประมาณ 30 รอบ แต่ละรอบมีการป้อนข้อมูลเฉลี่ย 20,000 Token และส่งออก 2,000 Token โดยใช้โมเดลหลัก (ประมาณ 0.005 หยวน/พัน Token ที่ป้อน, 0.02 หยวน/พัน Token ที่ส่งออก):
ต้นทุนต่อภารกิจเดียว ≈ 30 × (20,000 × 0.005 ÷ 1000 + 2,000 × 0.02 ÷ 1000) = 30 × (0.1 + 0.04) = 4.2 หยวน
นักพัฒนาที่มีประสบการณ์สูงสามารถทำภารกิจได้ 5 ถึง 10 ภารกิจต่อวัน โดยมีค่าใช้จ่ายรายเดือนอยู่ที่ 630 ถึง 1,260 หยวน นี่ยังเป็นการประมาณการเมื่อใช้โมเดลระดับกลาง; หากเลือกใช้โมเดลระดับพรีเมียม ค่าใช้จ่ายจะเพิ่มเป็นสองเท่า
ในบริบทนี้ ผู้ให้บริการคลาวด์รายใหญ่ของจีนและบริษัทโมเดลขนาดใหญ่ได้เข้าสู่ตลาดอย่างหนาแน่นระหว่างปลายปี 2025 ถึงเดือนมีนาคม 2026 โดยเปิดตัวแพ็กเกจสมัครสมาชิก "Coding Plan" ที่เปลี่ยนจากระบบคิดค่าบริการตาม Token เป็นค่ารายเดือนคงที่ จุดเริ่มต้นของสงครามราคาครั้งนี้คือ Zhipu AI ที่เปิดตัว GLM Coding Plan แรกสุดในปลายปี 2025 ตามด้วย Alibaba Cloud BAILIAN ที่เข้าสู่ตลาดอย่างแข็งแกร่งด้วยข้อเสนอ "7.9 หยวนต่อเดือนแรก" และ Tencent Cloud ได้เสร็จสิ้นการเติมชิ้นส่วนสุดท้ายเมื่อวันที่ 5 มีนาคม 2026
บทความนี้จะสรุปอย่างเป็นระบบเกี่ยวกับ Coding Plan ของแพลตฟอร์มหลักหกแห่งในประเทศ แบ่งเป็นสองเส้นทางหลัก ได้แก่ ผู้ให้บริการคลาวด์ (AliCloud Bailian, Volcano Engine ของ ByteDance, Tencent Cloud) และผู้พัฒนาโมเดล (Zhipu GLM, Kimi ของ Moonshot AI, MiniMax) เพื่อเป็นข้อมูลอ้างอิงสำหรับผู้ใช้ OpenClaw
OpenClaw ต้องการซื้อ Coding Plan ใช่แล้ว คือรูปแบบการใช้งานเดียวกับที่โปรแกรมเมอร์ใช้กับ IDE เช่น Cursor, Trae เพราะ OpenClaw และ Cursor เหล่านั้นโดยพื้นฐานแล้วเป็นตัวแทนปัญญาประดิษฐ์ หากคุณไม่ได้ซื้อ Coding Plan (ในต่างประเทศมักเรียกว่า API) เงินที่คุณจ่ายจะใช้ได้เฉพาะในการเข้าถึงโมเดลขนาดใหญ่ผ่านเบราว์เซอร์เท่านั้น
(โมเดลต่างประเทศไม่อยู่ในขอบเขตของการอภิปรายนี้)
ผู้ให้บริการคลาวด์
ผู้ให้บริการคลาวด์รายใหญ่สามราย: การแข่งขันในร้านค้าโมเดล
แก่นหลักของเส้นทางผู้ให้บริการคลาวด์คือ "แพลตฟอร์มรวมศูนย์": รวมโมเดลขนาดใหญ่แบบเปิดแหล่งที่มาหลายตัว เช่น Qwen, GLM, Kimi, MiniMax เข้าไว้ในแพ็กเกจเดียวกัน นักพัฒนาสามารถสลับระหว่างโมเดลเหล่านี้ได้อย่างอิสระด้วยคีย์ API เพียงหนึ่งคีย์ โดยไม่จำเป็นต้องเติมเงินแยกกันบนแพลตฟอร์มต่างๆ แพ็กเกจเหล่านี้ใช้หน่วยการวัดเป็น "คำขอแต่ละครั้ง" แทนที่จะเป็น Prompts (คำแนะนำ) ตัวเลขจึงดูใหญ่กว่า แต่ต้องพิจารณาการแปลงค่าจริงร่วมด้วย
รายละเอียดของผู้ให้บริการคลาวด์สามรายมีดังนี้:



ผู้ผลิตโมเดลขนาดใหญ่
ผู้ผลิตโมเดลสามรายหลัก: การเลือกที่เชี่ยวชาญในด้านความลึก
ต่างจาก “ร้านค้าโมเดล” ของผู้ให้บริการคลาวด์ แผนการใช้งานแบบผู้ผลิตโมเดลเองของ Coding Plan ใช้แนวทางแบบ “ร้านเฉพาะทาง”: จัดหาเฉพาะโมเดลของตนเองเท่านั้น แต่มีการปรับแต่งอย่างลึกซึ้ง ทำให้ความสามารถของโมเดลและการออกแบบปริมาณการใช้งานมีความละเอียดมากขึ้น แพ็กเกจเหล่านี้มักใช้ “Prompts” เป็นหน่วยการวัด โดย 1 Prompt ≈ การเรียกใช้งานโมเดล 15 ครั้ง (ตามการประมาณการของ MiniMax) จึงดูเหมือนตัวเลขเล็กกว่ามาก แต่สามารถรองรับปริมาณการสนทนาต่อครั้งได้มากกว่า



ตารางเปรียบเทียบข้อมูลหลักของแต่ละแพลตฟอร์ม
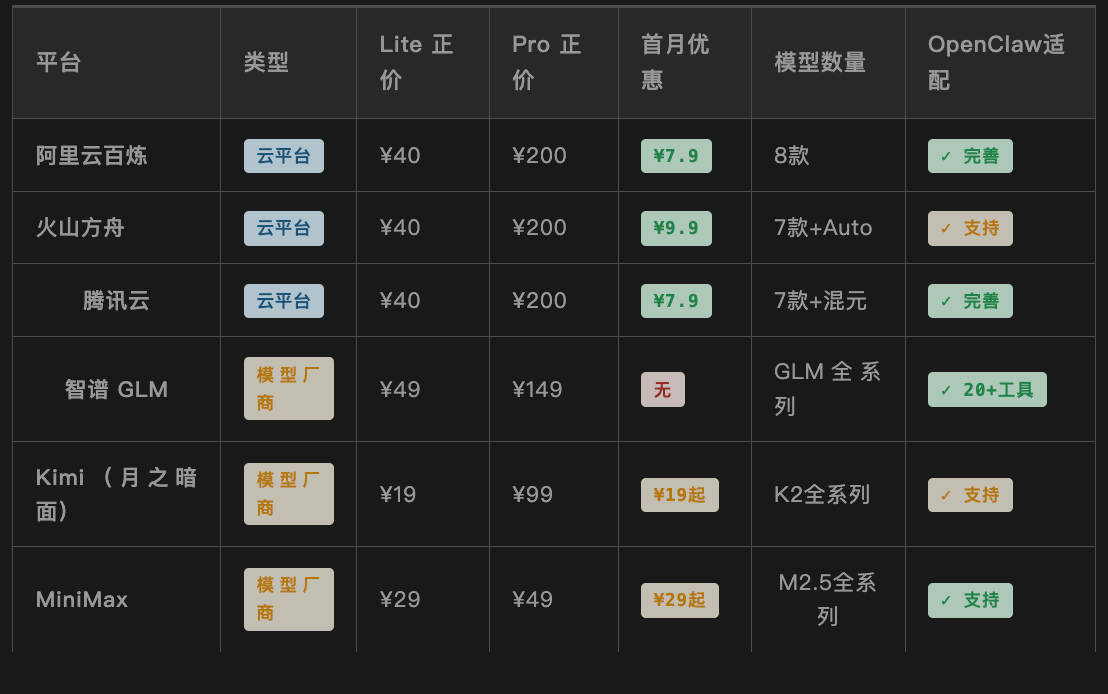
หมายเหตุ: ราคาอ้างอิงจากราคาอย่างเป็นทางการในสิ้นเดือนมีนาคม 2026 ส่วนส่วนลดเดือนแรกเป็นสิทธิพิเศษสำหรับผู้ใช้งานรายใหม่ โดยรายละเอียดให้ดูที่หน้าสั่งซื้อ การประเมินความเข้ากันได้ของ OpenClaw อ้างอิงจากความสมบูรณ์ของเอกสารอย่างเป็นทางการและข้อเสนอแนะจากชุมชน
คู่มือหลีกเลี่ยงกับดัก
การวิเคราะห์รูปแบบการคิดค่าบริการ: ความจริงเบื้องหลังตัวเลข
อุปสรรคข้อมูลที่ใหญ่ที่สุดในตลาดคือแพลตฟอร์มต่างๆ ใช้หน่วยวัดที่แตกต่างกันอย่างสิ้นเชิง การเปรียบเทียบตัวเลขโดยตรงจึงไม่มีความหมาย บทนี้สรุปจุดสำคัญสามประการเกี่ยวกับการคิดค่าบริการ เพื่อช่วยให้คุณตัดสินใจได้อย่างแท้จริงก่อนการซื้อ
หน่วยการวัดไม่สม่ำเสมอ
ในตลาดปัจจุบันมีระบบสองระบบที่ใช้งานพร้อมกัน: ผู้ให้บริการคลาวด์ (AliCloud, Volcano, Tencent) ใช้การวัดเป็น "คำขอครั้งละหนึ่งครั้ง" ในขณะที่ผู้ผลิตโมเดล (Zhipu, MiniMax) ใช้การวัดเป็น "Prompts" ความสัมพันธ์การแปลงที่สำคัญคือ: 1 Prompt ≈ 15 ครั้งของการเรียกใช้งานโมเดล
การคิดค่าบริการแบบแรกคำนวณตามจำนวนรอบการโต้ตอบที่ผู้ใช้เริ่มต้น ไม่ว่าการถามคำถามหนึ่งครั้งจะกระตุ้นการเรียกใช้งานโมเดลกี่ครั้งในเบื้องหลัง ก็จะหักเครดิตเพียงครั้งเดียว การคิดค่าบริการแบบนี้เป็นรูปแบบดั้งเดิมของผู้ให้บริการคลาวด์ ซึ่งคำนวณตามจำนวนครั้งของการเรียกใช้งาน API หากคำถามหนึ่งข้อกระตุ้นให้มีการเรียกใช้งานโมเดลหลายครั้ง จะถูกหักค่าใช้จ่ายหลายครั้ง รูปแบบแรกเหมาะกับเอเจนต์เช่น OpenClaw ที่มีการเรียกใช้งานเบื้องหลังบ่อยครั้ง เพราะค่าใช้จ่ายสามารถคาดการณ์ได้ ส่วนรูปแบบหลังคิดค่าบริการอย่างเข้มงวดตามจำนวนคำขอจริง ซึ่งอาจทำให้เกิดค่าใช้จ่ายที่ไม่คาดคิดเนื่องจากการเรียกใช้งานภายใน
วิธีทั้งสองนี้เหมาะสำหรับผู้ใช้ระดับเบาของ OpenClaw เนื่องจากไม่คำนวณตาม token แต่คำนวณตามจำนวนครั้ง และมีการจำกัดสูงสุดต่อเดือน ทำให้ผู้ใช้ไม่ต้องกังวลเรื่อง token
2. ตัวอย่างการแปลง
แพ็กเกจ Alibaba Cloud Bailing Pro ให้คำขอ 90,000 ครั้งต่อเดือน คิดเป็นประมาณ 6,000 Prompts
แพ็กเกจ ZhiPu GLM Lite ให้ประมาณ 120 คำขอทุก 5 ชั่วโมง หรือเท่ากับประมาณ 1,800 คำขอ
ดังนั้น "90,000" และ "120" จึงไม่ใช่ตัวเลขที่สามารถเปรียบเทียบกันได้โดยตรง
3. หน้าต่างเลื่อน/5 ชั่วโมงคือข้อจำกัดที่แท้จริง
แทบทุกแพลตฟอร์มต่างมีข้อจำกัด “ปริมาณทุก 5 ชั่วโมง” ตัวเลขนี้คือตัวชี้วัดสำคัญที่กำหนดว่าคุณจะสามารถพัฒนาอย่างต่อเนื่องและเข้มข้นได้หรือไม่ ไม่ใช่ปริมาณรวมรายเดือน ช่วงเวลา 5 ชั่วโมงใช้กลไกการคืนปริมาณแบบเลื่อนไหล (ไม่ใช่ช่วงเวลาตามปฏิทินที่แน่นอน): หากคุณเริ่มใช้งานเวลา 14:00 และใช้หมดปริมาณจนหมดเวลา 15:00 คุณจะต้องรอจนถึง 19:00 จึงจะได้รับปริมาณแรกกลับคืนมา การพัฒนาอย่างต่อเนื่องในช่วงเวลาเร่งด่วนตอนบ่ายเป็นเวลา 2-3 ชั่วโมงมีแนวโน้มสูงที่จะถึงขีดจำกัด
4. กฎการลดอันดับแบบซ่อนของ ZhiPu GLM-5
แผนการใช้งาน智谱 GLM Coding มีกฎเฉพาะ: ในช่วงเวลาเร่งด่วน (UTC+8 14:00~18:00) เมื่อใช้ GLM-5 จำนวนครั้งที่สามารถใช้งานได้จริงจะลดเหลือเพียง 1/3 ของจำนวนครั้งในช่วงนอกเวลาเร่งด่วน แพลตฟอร์มอื่นๆ ปัจจุบันไม่มีกฎนี้ โปรดให้ความสนใจเป็นพิเศษกับช่วงเวลาหลักที่คุณใช้งานเมื่อเลือกซื้อ
5. ไม่รองรับการคืนเงินหรือยกเลิกการสมัคร
แพลตฟอร์มทั้งหมดข้างต้นระบุอย่างชัดเจนว่าไม่รองรับการคืนเงินหรือยกเลิกการสมัครหลังจากสมัครแล้ว โปรดยืนยันความต้องการของคุณก่อนการซื้อ แนะนำให้ผู้ใช้งานใหม่ทดลองใช้แพ็กเกจราคาต่ำสำหรับเดือนแรกก่อน อย่าซื้อแผนชำระรายปีทันที
คู่มือการเลือกซื้อเฉพาะสำหรับผู้ใช้ OpenClaw
OpenClaw เป็นกรอบงาน Agent อิสระ ที่มีข้อกำหนดพิเศษเหนือปลั๊กอิน IDE ทั่วไปสำหรับ Coding Plan: ความทนทานต่อการเรียกใช้งานแบบพร้อมกันสูง ความสามารถในการจัดการบริบทยาวอย่างมั่นคง และความเข้ากันได้แบบเนทีฟกับโปรโตคอลของ Anthropic (เนื่องจาก OpenClaw ถูกออกแบบบนพื้นฐานของโปรโตคอล Claude) ด้านล่างนี้เป็นคำแนะนำเฉพาะตามสถานการณ์การใช้งาน
🌱 สำหรับผู้เริ่มต้น
แนะนำ: AliCloud BaiLian Lite เดือนแรก 7.9 หยวน (ได้หยุดให้บริการแล้ว) หรือ Tencent Cloud เดือนแรก 7.9 หยวน
สำหรับผู้เริ่มต้นใช้งาน Coding Plan ที่ต้องการสัมผัสกระบวนการทั้งหมดของ OpenClaw ด้วยต้นทุนต่ำที่สุด โมเดลของ BaiLian (8 รุ่น) สามารถทดลองใช้งานแบบขนานกันได้ภายในแพ็กเกจเดียว รวมถึง Qwen, GLM-5 และ Kimi ช่วยให้คุณสร้างการรับรู้เชิงสัญชาตญาณได้อย่างรวดเร็ว ขณะนี้ Alibaba Cloud มีเพียงแพ็กเกจ Pro ราคา 200 หยวนต่อเดือนเท่านั้น ในขณะที่ Tencent Cloud ยังมีแพ็กเกจ Lite ราคา 7.9 หยวนและ 40 หยวน แต่ผู้ใช้งานจริงรายงานว่าปริมาณการให้บริการหมดภายในไม่กี่วินาที ดังนั้นอาจมีเพียงแพ็กเกจราคา 200 หยวนต่อเดือนเท่านั้นที่เข้าถึงได้ง่ายกว่า
💼 ประเภทพัฒนาประจำวัน
แนะนำ: MiniMax Plus 49 หยวนต่อเดือน
มีงานโปรแกรมที่กำหนดไว้ทุกวัน แต่ไม่ได้ใช้งานอย่างต่อเนื่องหรือหนักหน่วง แพ็กเกจ Starter ของ MiniMax ที่มีความเร็วในการตอบสนองสูงสุด (101 tokens/s) และไม่มีขีดจำกัดรายสัปดาห์ เหมาะที่สุดสำหรับจังหวะการพัฒนาที่กระจายตัวแต่เกิดขึ้นบ่อยครั้ง
⚡ ประเภทต่อเนื่องหนัก
แนะนำ: Tencent Cloud หรือ Alibaba Cloud Pro ¥200/เดือน
ต้องพัฒนาต่อเนื่องมากกว่า 6 ชั่วโมงต่อวัน และจัดการกับรหัสขนาดใหญ่และกระบวนการทำงานของ Agent ที่ซับซ้อน ปริมาณการใช้งานรายเดือน 90,000 ครั้งและขีดจำกัด 6,000 ครั้งต่อช่วงเวลา 5 ชั่วโมงของ Tencent/Bailian Pro ถือเป็นทางเลือกที่มีประสิทธิภาพด้านต้นทุนและเสถียรภาพที่ดีที่สุดในแพลตฟอร์มคลาวด์
🎨 ฟรอนต์เอนด์/มัลติโมเดล
แนะนำ: Kimi Moderato ¥99/เดือน
ต้องการถ่ายภาพหน้าจอแบบออกแบบหรือร่างอินเตอร์เฟซผู้ใช้เพื่อป้อนให้ AI วิเคราะห์และสร้างโค้ดบ่อยครั้ง Kimi-K2.5 เป็นแพ็กเกจจากผู้ผลิตเพียงแพ็กเกจเดียวในตลาด Coding Plan ที่รองรับการป้อนข้อมูลแบบหลายรูปแบบผ่านภาพหน้าจอ เหมาะสำหรับสถานการณ์ Frontend และ Vibe Coding
🔬 โครงการวิศวกรรมที่ซับซ้อน
แนะนำ: ZhiPu GLM Pro 149 หยวน/เดือน
เหมาะสำหรับสถานการณ์ที่ต้องการความสามารถของโมเดลระดับสูงสุด เช่น การจัดการโครงการขนาดใหญ่ การจัดตาราง Agent ที่ซับซ้อน และการทดสอบอัตโนมัติแบบพร้อมกันสูง ขนาดพารามิเตอร์ 754B ของ GLM-5 เป็นขนาดใหญ่ที่สุดในโมเดลโอเพนซอร์สภายในประเทศ และมีความสามารถด้านโค้ดใกล้เคียงกับ Claude Opus ค่าใช้จ่ายระยะยาวสามารถลดได้เพิ่มเติมด้วยแพ็กเกจรายปีส่วนลด 30%
Summary
กลยุทธ์การซื้อ
ตลาด Coding Plan ปี 2026 ได้เข้าสู่ระยะการแข่งขันอย่างดุเดือด ผู้ได้รับประโยชน์โดยตรงจากสงครามราคาคือนักพัฒนาและผู้ใช้: สามารถทดลองใช้งานโมเดลยอดนิยมหลายตัวในเดือนแรกในราคาต่ำกว่า 10 หยวน ซึ่งเมื่อปีที่แล้วยังเป็นสิ่งที่จินตนาการไม่ถึง
อย่างไรก็ตาม การลดขั้นต่ำของแพ็กเกจไม่ได้หมายความว่าความยากในการเลือกจะลดลง: ความแตกต่างของหน่วยการวัด กฎข้อจำกัดที่ซ่อนอยู่ และแนวโน้มการขึ้นราคา ล้วนเป็นตัวแปรที่ต้องพิจารณาอย่างรอบคอบ
อีกจุดหนึ่งที่สำคัญคือ การดูว่าเครื่อง OpenClaw ของคุณเข้าถึงบริการโมเดลขนาดใหญ่ใดได้เร็วกว่า วิธีที่ง่ายที่สุดคือใช้คำสั่ง ping บนเครื่อง OpenClaw เพื่อดูความล่าช้าของเครือข่ายและอัตราการสูญเสียแพ็กเก็ต
ตัวอย่างเช่น นี่คือการตรวจสอบเครือข่ายจากโฮสต์ OpenClaw ไปยังจุดสิ้นสุดของบริการ Tencent Cloud โดยสังเกตว่ามีการสูญเสียแพ็กเก็ต icmp_seq หรือไม่ และค่าความหน่วงเวลา time นั้นต่ำหรือไม่
$ ping api.lkeap.cloud.tencent.com
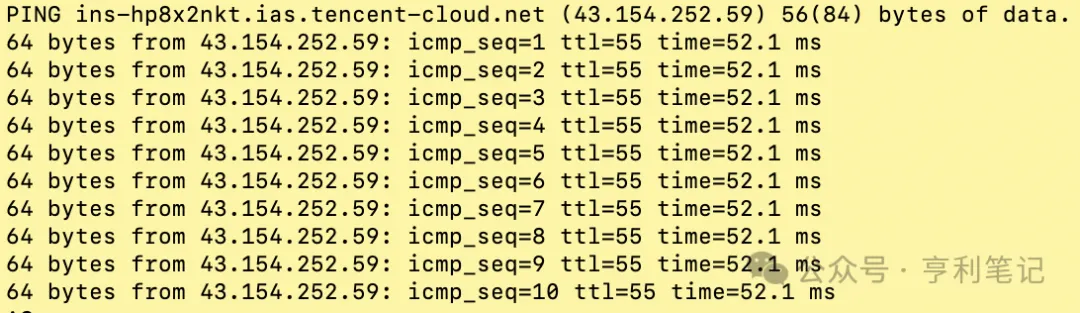
จากการวิเคราะห์ข้างต้น เราสรุปได้ดังนี้:

📌 คำเตือนสุดท้าย
ข้อมูลในบทความนี้อัปเดตถึงสิ้นเดือนมีนาคม 2026 เนื่องจากนโยบายราคาของแพลตฟอร์มต่างๆ มีการปรับเปลี่ยนบ่อยครั้ง (เช่น Zhipu ได้ปรับขึ้นราคาแล้ว และ Alibaba Cloud Bailing Lite ได้หยุดการซื้อใหม่แล้ว) โปรดตรวจสอบประกาศล่าสุดจากทางแพลตฟอร์มอย่างเป็นทางการก่อนการซื้อ แพ็กเกจทั้งหมดไม่สามารถขอคืนเงินได้ แนะนำให้เริ่มต้นด้วยแพ็กเกจราคาต่ำสุดในเดือนแรกเพื่อตรวจสอบความเข้ากันได้ของเครื่องมือและนิสัยการใช้งานส่วนตัวก่อนวางแผนระยะยาว
ครั้งต่อไป เราจะพูดถึงจุดสมดุลต่างๆ ที่ต้องพิจารณาเมื่อปรับใช้ OpenClaw