










ผู้เขียน: Max ที่เดินทางตลอดเวลา, 01Founder
หากต้องเขียนสรุปเชิงระยะกลางสำหรับ OpenAI ในปี 2025 ผู้คนจำนวนมากอาจใช้คำว่าเฉยๆ หรือแม้แต่ค่อนข้างเฉยชาก็ได้
ในช่วงกว่าหนึ่งปีที่ผ่านมา พวกเขาได้ดำเนินการตามขั้นตอนอย่างเป็นระบบเพื่อเชื่อมโยงเส้นทางการให้เหตุผล โดยเปิดตัวรุ่นการให้เหตุผลอย่างต่อเนื่องตั้งแต่ o3pro ถึง o4mini และยังเปิดตัวโมเดลพื้นฐานใหม่ๆ เช่น GPT-4.5 และ GPT-5
แต่ในด้านการสร้างภาพที่ผู้ใช้ทั่วไปรับรู้ได้ง่ายที่สุดและ最容易形成自发传播,他们的存在感却在渐渐减弱。
หลังจากความตื่นเต้นในช่วงเริ่มต้นของ Sora OpenAI ดูเหมือนจะเข้าสู่ช่วงเงียบเหงาอย่างยาวนานในเส้นทางนี้
ในขณะเดียวกัน ผู้เล่นคนอื่นๆ บนโต๊ะก็ไม่ได้นั่งเฉย
ในระบบนิเวศแบบเปิดแหล่งที่มา โมเดลเช่น Flux ได้ทำลายขีดจำกัดของการสร้างภาพคุณภาพสูงแบบโลคัลอย่างสิ้นเชิง;
ในเชิงธุรกิจ ไม่เพียงแต่คู่แข่งเก่าจะครองขอบเขตความงามที่สูงสุด แต่ยังมีผู้เล่นใหม่ที่มีฟังก์ชันค้นหาออนไลน์แบบอัตโนมัติ เช่น Nano-banana
ในทางตรงกันข้าม โมเดลหลักในการสร้างภาพของ OpenAI ที่ผ่านมาอย่าง GPT-Image-1.5 ดูเหมือนล้าสมัยไปแล้ว:
คุณภาพภาพไม่ดี การจัดวางแบบยึดติด และมักล่มเมื่อเจอข้อความที่ซับซ้อน
ค่อยๆ แล้ว อุตสาหกรรมก็เกิดความเห็นพ้องต้องกันว่า
OpenAI ประสบกับข้อจำกัดทางเทคนิคในด้านการสร้างภาพ และดูเหมือนจะรับมือกับคู่แข่งหลายรายได้ยาก
จนถึงไม่กี่สัปดาห์ที่ผ่านมา จุดเปลี่ยนได้ปรากฏขึ้นในลักษณะที่ซ่อนเร้นมาก
บนแพลตฟอร์มการทดสอบแบบเบลินด์สำหรับโมเดลขนาดใหญ่ที่มีชื่อเสียง LM Arena ได้มีการแทรกโมเดลภาพลับที่มีรหัสชื่อ Duct Tape
ผู้ใช้ที่เข้าร่วมการทดสอบแบบไม่เปิดเผย很快就发现事情不太对劲:
โมเดลนี้ไม่เพียงแต่ควบคุมรูปแบบภาพสุดขั้วได้อย่างแม่นยำยิ่ง แต่ยังสามารถสร้างโปสเตอร์ที่มีข้อความหลายภาษาจำนวนมากได้อย่างสมบูรณ์แบบ แม้แต่ก่อนการสร้างภาพดูเหมือนจะมีกระบวนการวางแผนเชิงตรรกะที่ซ่อนอยู่
ในขณะนั้น ชุมชนเทคนิคต่างๆ ต่างก็เดาไปว่านี่คือกลยุทธ์ลับที่บริษัทใดบริษัทหนึ่งเปิดตัวอย่างเงียบๆ แต่ทาง OpenAI ยังคงเงียบเฉย
ในคืนนี้ รองเท้าก็ได้ตกถึงพื้นสุดท้าย
ไม่มีงานเปิดตัวที่ยาวเหยียด ไม่มีการตลาดโปรโมตแบบท่วมท้น OpenAI ได้ตั้งชื่ออย่างเป็นทางการให้กับโมเดลที่มีรหัสลับว่า “เทป” ว่า ChatGPT GPT-Image-2 และเปิดตัวอย่างเต็มรูปแบบสู่ตลาด
ที่ตามมาด้วยตารางคะแนนการแข่งขัน Text-to-Image ที่ดูเหมือนทำให้หายใจไม่ออก
GPT-Image-2 ด้วยคะแนนสูงถึง 1512 ได้รับตำแหน่งอันดับหนึ่งทันที โดยนำหน้าอันดับสอง (ซึ่งก็คือ Nano-banana-2 ที่มีฟังก์ชันค้นหาออนไลน์) อยู่ถึง 242 คะแนน
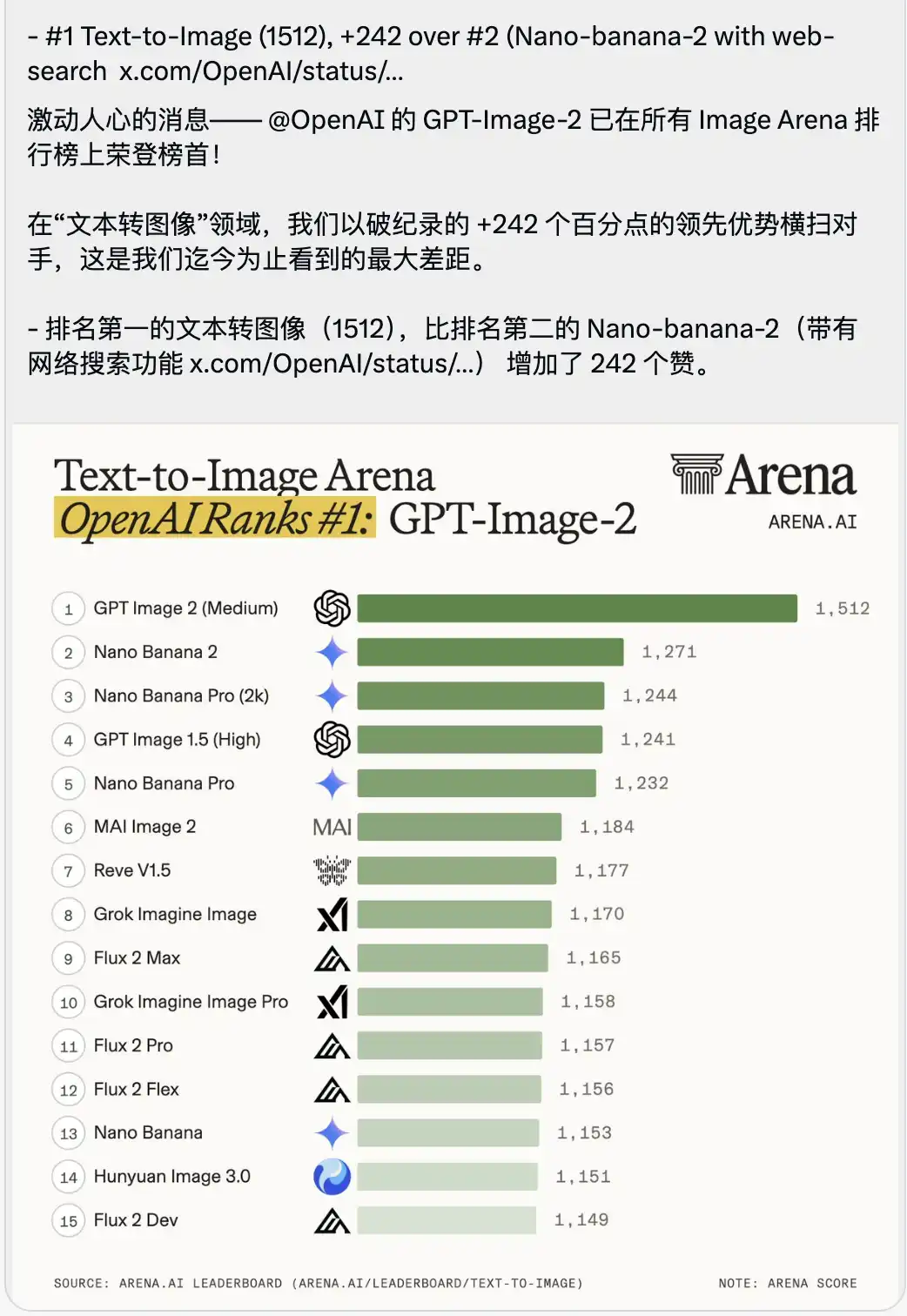
ในบริบทของการทดสอบประสิทธิภาพของโมเดลขนาดใหญ่ ผู้คนมักจะเน้นย้ำอย่างมากเกี่ยวกับการเอาชนะที่มีความแตกต่างเพียงไม่กี่ทศนิยมหรือหลักหน่วย โดยคะแนนระหว่างโมเดลชั้นนำมักใกล้เคียงกันมาก
ความได้เปรียบ 242 คะแนน เป็นครั้งแรกในประวัติศาสตร์ของสนามแข่ง
นี่ไม่ใช่การอัปเดตเวอร์ชันเล็กๆ แต่เป็นการกดขี่แบบข้ามรุ่นอย่างหยาบคาย
ฉันใช้เวลาครึ่งวันในการทบทวนอย่างละเอียดถึงขีดจำกัดต่างๆ ของมันและเอกสาร API ล่าสุด
ความรู้สึกที่ใหญ่ที่สุดมีเพียงหนึ่งเดียว:
OpenAI ยังคงเป็น OpenAI แบบเดิม
เมื่อมันตัดสินใจที่จะยึดคืนพื้นที่ที่สูญเสียไป มันก็เลือกวิธีการพลิกโต๊ะเก่าออกไปทันที
ต่อหน้าโมเดลนี้ งานออกแบบเชิงภาพที่เราคิดว่ายังต้องใช้เวลาอีกสองถึงสามปีกว่าจะถูก AI เปลี่ยนแทนอย่างสมบูรณ์ วันนี้แทบจะสรุปได้ว่าจบลงแล้ว
ส่วนที่ 01 การสร้างภาพจากโมเดลเป็นตัวแทนทางภาพ
เพื่อเข้าใจว่าทำไม GPT-Image-2 ถึงสามารถสร้างช่องว่างคะแนนที่ใหญ่โตเช่นนี้ คุณต้องละทิ้งความเข้าใจเดิมๆ เกี่ยวกับโมเดลการสร้างภาพจากข้อความ
ก่อนหน้านี้ เราใช้ AI วาดภาพ โดยพื้นฐานแล้วเหมือนการจับของขวัญแบบสุ่ม ใส่คำใบ้ไม่กี่คำ进去 แล้วรอให้มันจัดเรียงพิกเซลให้เป็นรูปแบบที่คุณต้องการ
แต่ GPT-Image-2 ดูเหมือนเป็นตัวแทนที่มีเครื่องยนต์ภาพรวมอยู่ภายใน
การเปลี่ยนแปลงที่ชัดเจนที่สุดคือมันได้แบ่งกลไกออกเป็นสองรูปแบบที่แตกต่างกันโดยสิ้นเชิง
หนึ่งคือโหมดทันที (Instant Mode) ที่เปิดให้ผู้ใช้ทุกคนเข้าถึง
รูปแบบนี้เน้นการตอบสนองอย่างรวดเร็วและการเชื่อมต่ออย่างราบรื่นกับกระบวนการทำงานและชีวิตประจำวัน
ตัวอย่างเช่น คุณส่งคำสั่งไปที่มันผ่านโทรศัพท์มือถือ มันจะสามารถให้ภาพที่มีโครงสร้างสมบูรณ์แก่คุณภายในไม่กี่วินาที
ความสามารถในการเข้าใจภาพพื้นฐานของมันแข็งแกร่งมาก แต่ส่วนใหญ่ใช้แก้ไขความต้องการในการแปลงภาพแบบความถี่สูงและแต่ละครั้ง
โหมดการคิด (Thinking Mode) ที่เปิดให้ผู้ใช้ที่ชำระเงินเข้าถึง
ก่อนที่มันจะเริ่มเรนเดอร์พิกเซลใดๆ แม้แต่พิกเซลเดียว มันจะต้องผ่านกระบวนการให้เหตุผลเชิงตรรกะและการค้นหาผ่านอินเทอร์เน็ตเป็นเวลาสิบกว่าวินาที
正是这个模式,解决了一个极其核心但也极其困难的命题:
โมเดลรู้เป็นครั้งแรกว่าควรวาดอะไร
ตัวอย่างที่ตรงที่สุด
พิมพ์ในกล่องแชท:
ช่วยทำโปสเตอร์ให้ฉัน ค้นหาบนอินเทอร์เน็ตเกี่ยวกับความคิดเห็นของผู้คนต่อโมเดลลับ Duct Tape และแนบคิวอาร์โค้ดของ ChatGPT

หากใช้รุ่นเก่า มันจะไม่รู้เลยว่าผู้ใช้อินเทอร์เน็ตพูดอะไร แค่สร้างโปสเตอร์ที่มีตัวอักษรไร้ความหมาย และรหัส QR ก็เป็นภาพหลอกที่สแกนไม่ได้
แต่ในโหมดการคิด กระบวนการของมันเป็นดังนี้:
มันจะหยุดการวาดภาพชั่วคราว แล้วเปิดใช้งานเครื่องมือค้นหาออนไลน์ เพื่อดึงรีวิวจากผู้ใช้จริงบน Reddit, Threads หรือ LinkedIn;
จากนั้น มันเริ่มวางแผนการจัดวางโปสเตอร์ ช่องว่าง และลำดับตัวอักษร;
สุดท้าย มันจะสร้างรหัส QR ที่ใช้งานได้จริงและสามารถสแกนเพื่อไปยังลิงก์ได้ทันที แล้วแสดงภาพทั้งหมดออกมา

นี่ไม่ใช่แค่การวาดภาพอีกต่อไป แต่เป็นการทำงานแบบครบวงจรที่ดำเนินการวิจัยด้วยตนเอง วางแผน ดึงข้อความ และออกแบบเค้าโครง
ต้องทำการเปรียบเทียบแบบคู่ขนาน
ทุกคนที่ติดตามวงการโมเดลขนาดใหญ่รู้ดีว่า โมเดลสร้างภาพที่มีความสามารถในการเชื่อมต่ออินเทอร์เน็ตและค้นหา ไม่ได้ถูกสร้างขึ้นครั้งแรกโดย OpenAI
ผู้ชนะอันดับสองของ Nano-banana มีกลไกนี้อยู่แล้ว
แต่เมื่อคุณใช้งาน Nano-banana จริงๆ คุณจะพบว่ามันดูค่อนข้างล้าสมัยในหลายสถานการณ์
การคิดของ Nano-banana มักเป็นตรรกะการเชื่อมต่อแบบเครื่องจักร
ตัวอย่างเช่น คุณให้มันค้นหาแนวโน้มอุตสาหกรรมเพื่อทำโปสเตอร์ มันก็ไปค้นหาจริง แต่มักจะดึงข้อความจากวิกิพีเดียมาอย่างไม่เป็นธรรมชาติ และบังคับแปะลงบนภาพ
เมื่อต้องรับคำสั่งที่ต้องตีความความต้องการทางธุรกิจที่เป็นนามธรรม มันจะง่ายมากที่จะสับสน

รู้สึกเหมือนคนฝึกงานที่เข้าใจคำสั่งแต่ไม่มีประสบการณ์เลย เข้าใจว่าต้องทำอะไร แต่ไม่เข้าใจกลยุทธ์เลย
แต่ GPT-Image-2 ในด้านนี้ สามารถอธิบายได้ว่าโดดเด่นเกินจริง
การคิดของมันไม่ใช่แค่ทำตามขั้นตอน แต่เข้าใจอย่างแท้จริงถึงบริบททางวัฒนธรรมและเจตนาทางธุรกิจที่อยู่เบื้องหลัง
ขณะทดสอบ ฉันพิมพ์คำสั่งภาษาจีนที่เรียบง่ายมาก: ช่วยวาดหน้าจอภาพที่มัสก์กำลังขาย豆包ผ่านการไลฟ์สดบน Douyin
หากใช้โมเดลการวาดภาพรุ่นเก่า ความเป็นไปได้สูงที่จะได้ภาพคนผิวขาวที่ดูเหมือนมัสก์ ถือ包子 ฉากหลังเบลอๆ และไม่รู้ว่า抖音ดูเป็นอย่างไร
แต่ในโหมดการคิด GPT-Image-2 ให้ผลลัพธ์ที่ทำให้รู้สึกตกใจเล็กน้อย
มันไม่ได้แค่ประกอบองค์ประกอบต่างๆ อย่างง่ายๆ แต่ได้เรียกใช้ความเข้าใจเกี่ยวกับอินเทอร์เน็ตจีนอย่างอิสระ เพื่อสร้างหน้าจอภาพที่จำลอง UI ของห้องสตรีมมิ่งบน Douyin ได้ละเอียดถึงระดับพิกเซล
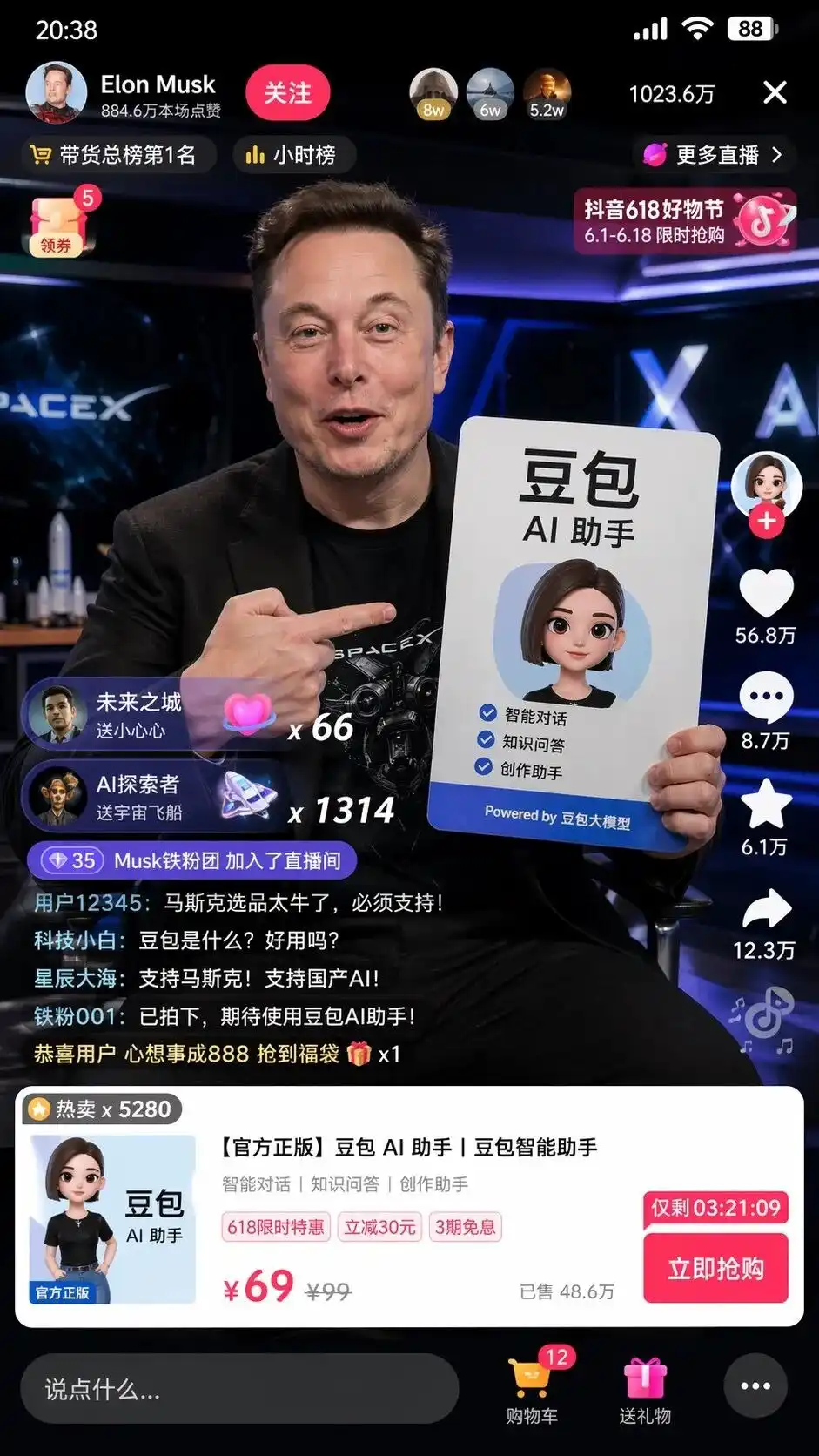
บนหน้าจอไม่เพียงแต่มีภาพมาสก์ที่ดูสมจริงถือป้ายโฆษณาตัวช่วย AI DouBao ที่จัดวางข้อความอย่างสมบูรณ์แบบ แต่ยังมีรายละเอียดอื่นๆ ที่ไม่ได้ระบุไว้ในคำสั่งอีกด้วย:
ปุ่มติดตามที่มุมซ้ายบน พร้อมตารางชั่วโมง จำนวนผู้ใช้งานออนไลน์ 10.23 ล้านที่มุมขวาบน บัตรสินค้ามาตรฐานที่ปรากฏด้านล่าง รวมถึงการระบุราคาเดิม 99 ราคาพิเศษ 69 และปุ่มซื้อทันทีพร้อมตัวนับถอยหลัง
สิ่งที่ทำให้ขนลุกที่สุดคือข้อความแสดงความคิดเห็นของผู้ใช้ที่เลื่อนขึ้นด้านล่างซ้ายอย่างสมจริงยิ่ง:
ผู้เริ่มต้นด้านเทคโนโลยี: โดว์บาคืออะไร? ใช้งานดีไหม?
ดวงดาวและทะเลกว้าง: สนับสนุนมัสก์! สนับสนุน AI ของประเทศ!
ไม่มีใครบอกมันว่าควรเขียนข้อความลอยบนหน้าจออย่างไร หน้าตาอินเทอร์เฟซสินค้าควรเป็นอย่างไร หรือควรตั้งราคาเท่าไหร่
นี่คือการออกแบบอินเตอร์เฟซธุรกิจและการวางแผนการดำเนินงานที่สมบูรณ์ซึ่งโมเดลได้สร้างขึ้นและดำเนินการแทนมนุษย์หลังจากวิเคราะห์แท็กสองแท็กคือการขายสินค้าผ่าน Douyin และโมเดลใหญ่ของ DouBao
มิติการประเมินโมเดลขนาดใหญ่ในการสร้างภาพ ณ ขณะนี้ได้ก้าวข้ามจากแค่能否วาดให้สวย ไปสู่การเข้าใจกลยุทธ์และตรรกะการจัดวาง
ส่วนที่ 02 การทดสอบความสามารถหลัก
เพื่อทดสอบขีดจำกัดของมัน ฉันจึงใช้สถานการณ์ที่พบบ่อยและซับซ้อนหลายกรณีตามมาตรฐานการออกแบบเชิงพาณิชย์เพื่อทดสอบ
ผลลัพธ์ที่ได้คือ ระดับความละเอียดในการแก้ปัญหานั้นละเอียดจนน่าขนลุก
ฉากแรก: การเข้าใจภาพและการปิดวงจรธุรกิจ (การแต่งตัวให้กับแบบ)
ในแง่ของภาพลักษณ์การค้าปลีกแบบดั้งเดิมหรือการวางแผนแฟชั่น ต้นทุนในการดำเนินการระหว่างการมีไอเดียกับการเห็นผลลัพธ์จริงบนร่างกายสูงมาก
คุณต้องการหาโมเดล ยืมเสื้อผ้า จัดตั้งสตูดิโอถ่ายรูป และแต่งภาพขั้นสูง
ต่อมาเมื่อเกิด AI ขึ้น ผู้คนเริ่มฝึกโมเดล LoRA เพื่อคงรูปหน้าของบุคคล แต่ก็ยังต้องการวัสดุภาพถ่ายหลายสิบรูปและต้นทุนการเรียนรู้ที่สูง
ใน GPT-Image-2 กระบวนการนี้ถูกบีบอัดให้สุดขีด
ฉันได้ลองอัปโหลดรูปถ่ายตัวเองในชีวิตประจำวัน แล้วบอกมันว่าฉันจะไปพักผ่อนบนเกาะเดือนหน้า ให้มันช่วยจัดชุดให้ฉัน vàiชุด
มันให้ฉันก่อนหน้านี้ถึง 8 ชุดภาพรวมเสื้อผ้าฤดูร้อนที่มีสไตล์ต่างกันโดยสิ้นเชิง รูปแบบการจัดวางดูเหมือน Lookbook ของร้านค้าออนไลน์มืออาชีพ และแต่ละชิ้นยังมีป้ายข้อความที่ถูกต้องติดไว้ข้างๆ
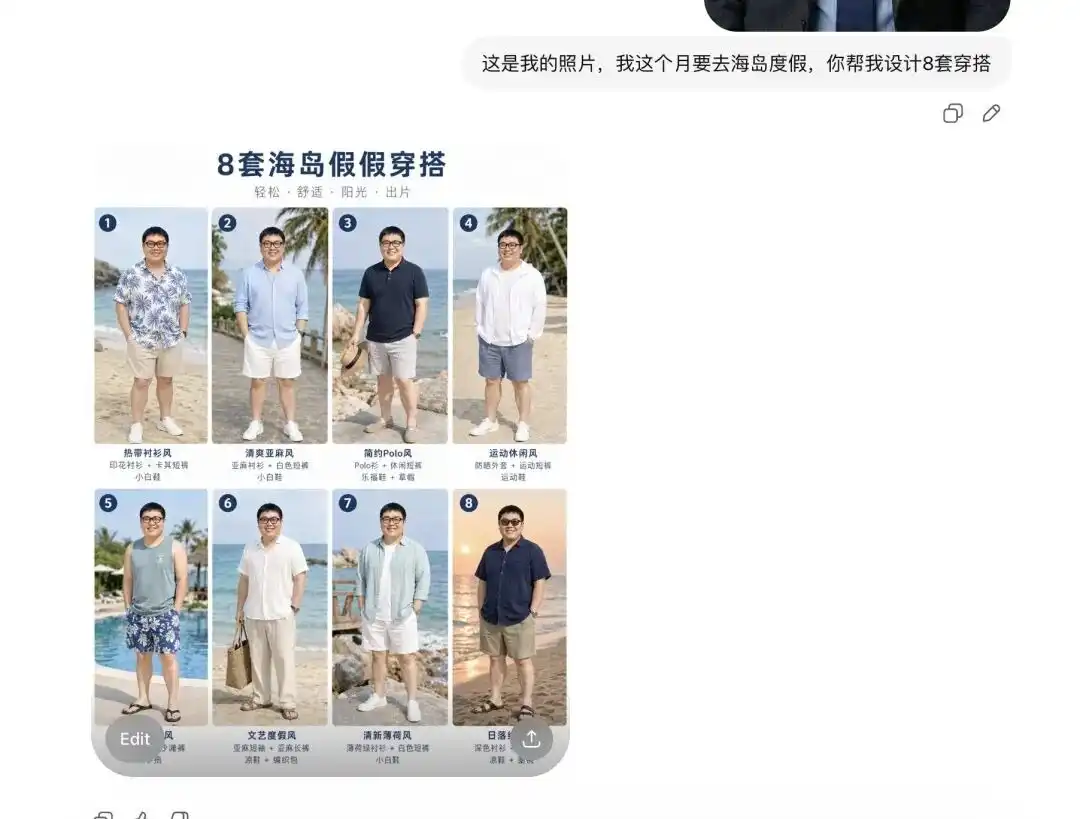
ที่สำคัญกว่านั้น มันได้วิเคราะห์ลักษณะใบหน้าและสัดส่วนร่างกายของฉันอย่างแม่นยำในทันทีนั้น
เมื่อฉันบอกมันว่าฉันอยากดูผลลัพธ์ของการใส่ชุดชุดแรก และขอรูปรายละเอียดจากมุมต่างๆ มันก็ดึงภาพตัวเองจากภาพถ่ายของฉันออกมา แล้วสวมชุดฤดูร้อนให้ พร้อมส่งรูปมุมข้าง รูปครึ่งตัว และมุมอื่นๆ ออกมา

การเปลี่ยนแปลงนี้ราบรื่นมาก ซึ่งหมายความว่า กำแพงป้องกันสำหรับงานเรนเดอร์การแต่งตัวระดับพื้นฐาน หรืองานจ้างภายนอกเพื่อให้แบบลองเสื้อผ้า ได้รับผลกระทบอย่างสิ้นเชิง
ฉากที่สอง: แก้ไขปัญหาความสอดคล้องและการเล่าเรื่องอย่างต่อเนื่อง (สร้างการ์ตูนจากประโยคเดียว)
ผู้ที่เคยใช้งาน AI สร้างภาพรู้ดีว่า การให้ AI วาดภาพที่สวยงามไม่ใช่เรื่องยาก แต่สิ่งที่ยากคือการให้มันวาดภาพสิบภาพของบุคคลเดียวกัน โดยท่าทางและมุมมองต้องสอดคล้องกัน
นี่คือปัญหาความสอดคล้อง (Consistency) ที่ว่ากัน
แต่ในการทดสอบครั้งนี้ ฉันได้เห็นกรณีที่ขัดแย้งอย่างรุนแรงกับประสบการณ์ในอดีต
คุณสามารถอัปโหลดรูปถ่ายกับเพื่อนเมื่อวานเพียงรูปเดียว แล้วพิมพ์คำสั่งง่ายๆ มาก:
แปลงเราสองคนให้เป็นตัวเอก วาดสามภาพสามหน้าการ์ตูนสไตล์ญี่ปุ่น 剧情คุณกำหนด
หลังจากไม่กี่วินาที มันก็ส่งออกการ์ตูนขาวดำสามหน้าที่มีสตอรี่บอร์ดมาตรฐาน
ที่น่ากลัวที่สุดคือ ตัวละครการ์ตูนที่สร้างจากบุคคลจริง这两个 อยู่ในฉากต่างกันบนสามหน้ากระดาษ

ไม่ว่าจะเป็นภาพใกล้ ภาพวิ่งไกล หรือเงาหลัง แม้แต่ลักษณะใบหน้า รายละเอียดทรงผม และรอยยับบนเสื้อผ้า ล้วนรักษาความสอดคล้องกันอย่างสมบูรณ์แบบ
น่าประหลาดยิ่งกว่านั้น บทภาพยนตร์การ์ตูนนั้นเชื่อมโยงกันอย่างสมบูรณ์ แม้แต่ข้อความในกล่องพูดก็สร้างตรรกะเรื่องราวที่สมบูรณ์

ความสามารถในการรักษาความสอดคล้องทั้งในด้านเวลาและพื้นที่ แสดงว่ามันได้หลุดพ้นจากกรอบของการสร้างภาพเดี่ยว และมีความสามารถในการกำกับการเล่าเรื่องอย่างต่อเนื่อง
ฉากที่สาม: การข้ามอุปสรรคสุดท้ายของการเรนเดอร์ข้อความ (การจัดรูปแบบหลายภาษา)
หากความสม่ำเสมอแก้ปัญหาการเล่าเรื่อง แล้วการเรนเดอร์ข้อความหลายภาษาอย่างแม่นยำ ก็คือสิ่งที่ผลักดันนักออกแบบกราฟิกให้ติดอยู่ในมุม
ก่อนหน้านี้ แค่ภาพมีข้อความเล็กน้อย โมเดลขนาดใหญ่ก็เริ่มเขียนเหมือนวาดรูปไร้ความหมาย
เนื่องจากโมเดลเข้าใจข้อความในรูปแบบของ Token (หน่วยความหมาย) ขณะที่ภาพที่สร้างขึ้นเป็นพิกเซล ทั้งสองสิ่งนี้ในอดีตถูกแยกจากกัน
GPT-Image-2 แก้ปัญหานี้อย่างสิ้นเชิง
ฉันให้มันสร้างปกนิตยสารแฟชั่นภาษาฝรั่งเศส ทำเมนูร้านอาหารภาษาญี่ปุ่นที่มีอักษรฮิรางานะและคันจิเต็มไปหมด และยังลองจัดแนวข้อความภาษารัสเซียที่มีความหนาแน่นสูงมาก

ผลลัพธ์คือสำเร็จในครั้งเดียว ไม่มีข้อผิดพลาดในการพิมพ์
สิ่งที่น่าสิ้นหวังที่สุดคือ มันไม่เพียงแต่เขียนตัวอักษรให้ถูกต้อง แต่ยังรู้จักจับคู่กับรสนิยมทางวัฒนธรรมและดีไซน์ตัวอักษรตามภาษาท้องถิ่น
ตัวอักษรจีนในใบปลิวภาษาญี่ปุ่นใช้ตัวอักษรศิลปะแบบดั้งเดิมของญี่ปุ่น และการจัดเรียงฮิรางานะก็สอดคล้องกับนิสัยการอ่านแบบตั้งของภาษาญี่ปุ่น
การออกแบบเค้าโครงเคยเป็นพื้นที่ส่วนตัวของนักออกแบบกราฟิก
การปรับช่องว่างระหว่างตัวอักษร การจัดลำดับความสำคัญ และการสร้างสมดุลทางภาพระหว่างข้อความกับพื้นหลัง ล้วนต้องใช้การฝึกฝนอย่างมาก
แต่เมื่อ AI สามารถจัดการภาษาเหล่านี้ได้โดยไม่มีข้อผิดพลาด และมีการออกแบบที่มีรสนิยมขั้นสูงอยู่แล้ว โปสเตอร์ แผ่นพับ และโฆษณาในฟีดที่ใช้ในชีวิตประจำวัน ก็แทบไม่จำเป็นต้องมีคนมาจัดแนวเส้นอ้างอิงด้วยตนเองอีกต่อไป
ฉากที่สี่: อัตราส่วนภาพที่ผิดปกติและการควบคุมระดับจุลภาคอย่างรุนแรง (การแกะสลักตัวอักษรบนเมล็ดข้าว)
สุดท้าย เพื่อดูว่าระดับความเชื่อฟังของมันรุนแรงแค่ไหน ฉันจึงให้คำสั่งที่ยากและซับซ้อนหลายข้อ
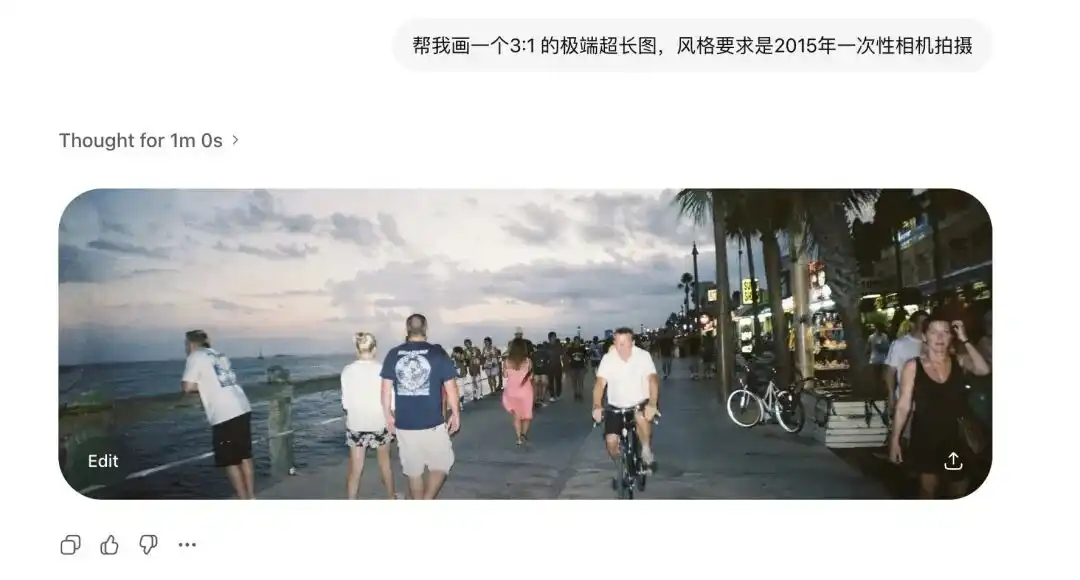
ฉันทดสอบอัตราส่วนภาพสุดขั้วของมันก่อน
แบบจำลองการแพร่กระจายแบบดั้งเดิมกลัวสัดส่วนที่ไม่เป็นมาตรฐานอย่างมาก
ก่อนหน้านี้ ถ้าดึงรูปให้ยืดออกเล็กน้อย ภาพก็จะมีหัวสองหัวโผล่ขึ้นมา
แต่ฉันขอให้ Images 2.0 สร้างภาพอัตราส่วน 3:1 ที่กว้างมากและภาพอัตราส่วน 1:3 ที่ยาวแนวตั้ง มันไม่เพียงแต่ไม่พัง แต่ยังสร้างภาพพาโนรามา 360 องศาที่เชื่อมต่อระหว่างจุดเริ่มต้นและจุดสิ้นสุดอย่างสมบูรณ์
หลังจากเพิ่มข้อมูลเกี่ยวกับกล้องใช้แล้วทิ้งปี 2015 ความผิดเพี้ยนของเลนส์เก่าและการสะท้อนแสงแฟลชที่ผนังคุณภาพต่ำก็ถูกจำลองได้อย่างชัดเจน
อีกตัวอย่างหนึ่งที่แสดงให้เห็นถึงความสามารถในการควบคุมระดับจุลภาคของมันคือการทดสอบเมล็ดข้าวที่ดูเหมือนบ้าคลั่งซึ่งทางบริษัทได้แสดงในงานเปิดตัว
นักวิจัยเรียกใช้ API แบบทดลองที่ยังอยู่ในขั้นตอนการทดสอบภายใน โดยไม่ได้ใช้คำอธิบายเสริมใดๆ เช่น ถ่ายภาพมาโคร หรือความละเอียด 8K แต่ให้คำสั่งที่เรียบง่ายและเป็นนามธรรมมากเพียงประโยคเดียว:
กองข้าวสาร บนเมล็ดข้าวหนึ่งเมล็ดในกองข้าวนี้เขียนว่า GPT Image 2
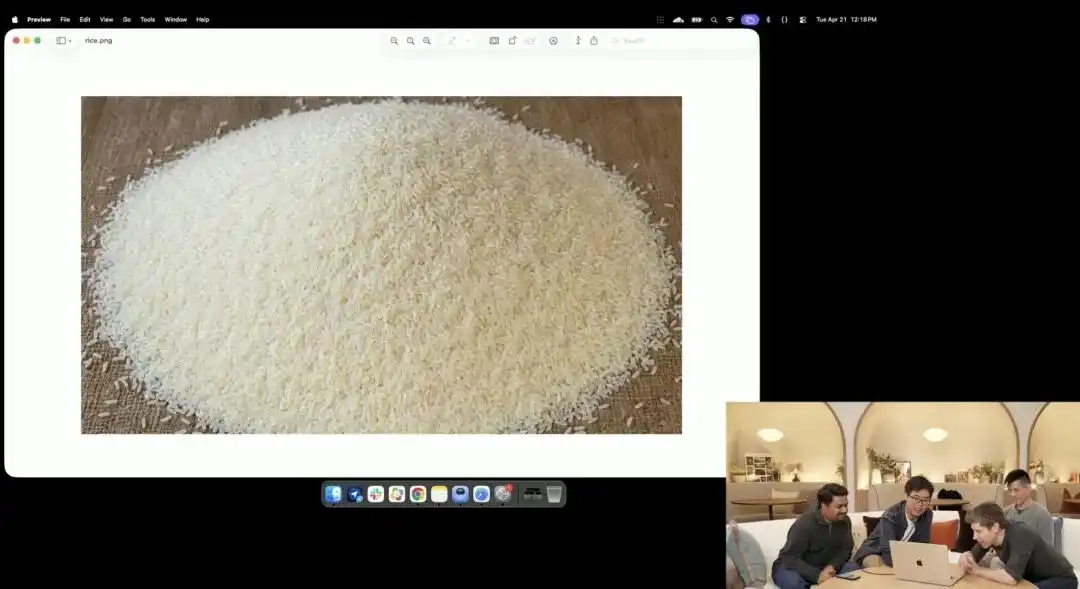
เมื่อภาพถูกขยายออกเป็นสิบเท่าหรือแม้แต่ปรากฏเป็นเม็ดพิกเซล คุณยังสามารถหาเม็ดเล็กๆ ที่มีตัวอักษรจารึกอยู่ในกองข้าวได้จริงๆ
เนื้อสัมผัสของข้าวเมล็ดนี้ยังคงสอดคล้องกับกฎทางฟิสิกส์ ข้อความถูกฝังอย่างแม่นยำตามความโค้งเล็กๆ ของเมล็ดข้าว
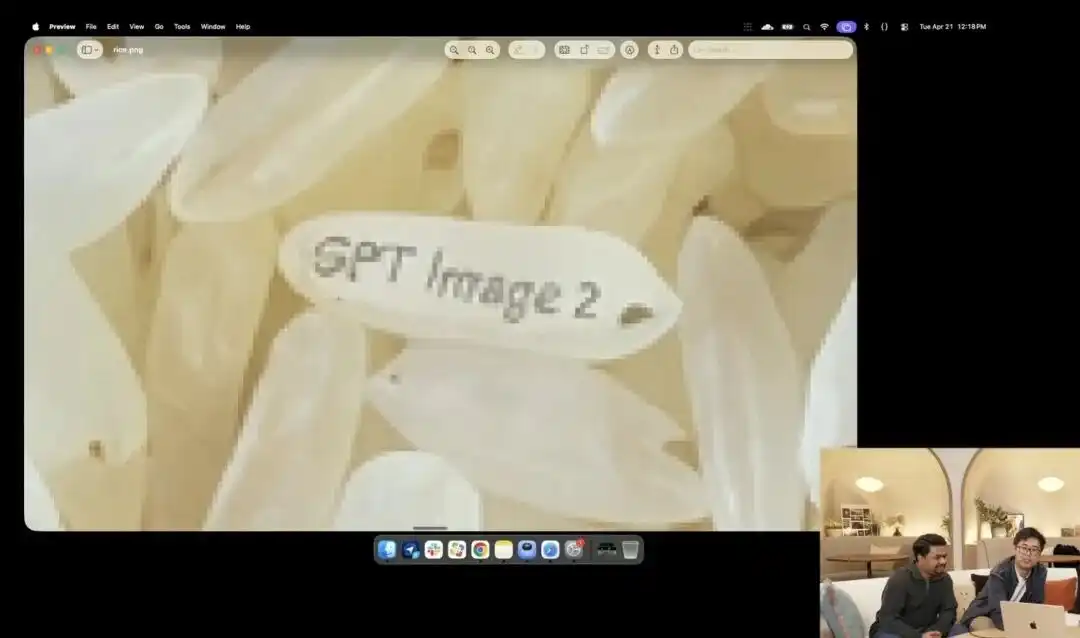
งานทั้งหมดที่เหลือ—การเรียกใช้มุมมองมาโคร การคำนวณความลึกของสนามภาพ การค้นหาพิกัดทางกายภาพของเมล็ดข้าวในพื้นที่ซ่อน และการพิมพ์ตัวอักษรลงไป—ล้วนถูกสร้างขึ้นและดำเนินการโดยโมเดลขนาดใหญ่ในโหมดการคิดอัตโนมัติ
ตัวอย่างนี้แสดงให้เห็นอย่างชัดเจนว่า แบบจำลองมีความแม่นยำระดับพิกเซลในการเข้าใจตำแหน่งเชิงพื้นที่
นี่หมายความว่าในอนาคตในการทำงานจริง คุณสามารถแก้ไขส่วนเล็กๆ ใดๆ ในไฟล์ดีไซน์ได้อย่างแม่นยำ ชี้ที่ไหนแก้ที่นั่น แทนที่จะเหมือนก่อนหน้านี้ที่เวลาต้องการแก้คอเสื้อ ทั้งภาพกลับเปลี่ยนไปหมด
ส่วนที่ 03 รายละเอียดทางเทคนิคบางประการ
ความสามารถในการควบคุมอย่างสุดขั้วและปัญญาเชิงกลยุทธ์แบบนี้ ไม่อาจสร้างขึ้นได้แค่โดยการสะสมพลังการประมวลผลแบบไม่คำนึงถึงอะไร
เพื่อให้เข้าใจว่ามันมีไพ่ล่างสุดอะไรบ้าง ฉันได้ทำการทดสอบเชิงรุกกับ GPT-Image-2
พบจุดที่น่าสนใจมาก
แม้ว่าเอกสารอย่างเป็นทางการจะระบุว่าวันที่อัปเดตฐานความรู้โดยรวมของ GPT-Image-2 ไปยังเดือนธันวาคม 2025 แต่ในการทดสอบของฉันจริงๆ
วันที่สิ้นสุดข้อมูลการฝึกอบรมของโหมดทันที (Instant Mode) ยังคงอยู่ที่ปลายเดือนพฤษภาคม 2024;

และโหมดการคิด (Thinking Mode) ที่ต้องใช้เวลาคิดนานนั้น ฐานความรู้ดั้งเดิมอยู่ที่ประมาณเดือนมิถุนายน 2024 (แต่สามารถรับข้อมูลปัจจุบันได้ผ่านการเชื่อมต่ออินเทอร์เน็ตแบบเรียลไทม์)

จากการคำนวณจากจุดเวลาทั้งสองจุดนี้ ดูเหมือนว่าพื้นฐานของ GPT-Image-2 จะมีร่องรอยที่สามารถสังเกตได้
เริ่มต้นด้วยโหมดทันทีที่เน้นการสร้างภาพความถี่สูง
วันที่สิ้นสุดในเดือนพฤษภาคม 2024 หมายความว่ามันน่าจะใช้ o4-mini โดยตรง หรือเป็นรุ่นที่มีน้ำหนักเบาในตระกูล GPT-5 (เช่น GPT-5 mini หรือแม้แต่ GPT-5 nano ที่มีพารามิเตอร์น้อยมาก)
เนื่องจากฐานรากแบบเบาชุดนี้มีความสามารถในการวางแผนพื้นที่อย่างแข็งแกร่งและเข้าใจคำสั่งที่ซับซ้อน จึงทำให้การสร้างภาพระดับบนสามารถรักษาความมั่นคงและไม่ยุ่งเหยิง
แต่รูปแบบการคิดที่ชาญฉลาดอย่างยิ่งและเข้าใจกลยุทธ์ทางธุรกิจนั้น ไม่สามารถเป็นโมเดลหลักของ GPT-5 ได้
เนื่องจากฐานความรู้พื้นฐานของ GPT-5 หยุดที่เดือนกันยายน 2024
โหมดการคิดมีแนวโน้มสูงมากที่เชื่อมต่อกับโมเดลการให้เหตุผลซีรีส์ O ที่กำลังปรับปรุงอย่างต่อเนื่องในพื้นหลัง (เช่น o4 หรือ o3 รุ่นอัปเดต)
แบบจำลองขนาดใหญ่ใช้กลไกการคิดลึกเฉพาะของซีรีส์ O ก่อน เพื่อคำนวณตรรกะทางธุรกิจ จิตวิทยาของผู้รับสาร และพิกัดการจัดวางอย่างชัดเจนในพื้นที่ซ่อนเร้น ก่อนส่งต่อให้โมดูลภาพสำหรับการเรนเดอร์พิกเซลสุดท้าย
แน่นอน ยังมีอีกทางเลือกหนึ่ง:
ภายใต้กลไกการจัดสรรทรัพยากรการประมวลผลที่ละเอียดอ่อนภายใน OpenAI โหมดเร็วอาจใช้ GPT-5 nano เป็นพื้นฐานโดยตรง ขณะที่โหมดคิดจะใช้ GPT-5 mini ที่มีขนาดใหญ่กว่าเล็กน้อยร่วมกับเครื่องมือภายนอก
แต่ไม่ว่าจะเป็นการจัดรวมพื้นฐานแบบใดก็ตาม หากคุณติดตามระบบนิเวศ API ของ OpenAI มาโดยตลอด คุณจะเห็นว่าตรรกะการสร้างพื้นฐานของมันนั้นต่างจาก Midjourney ไปไกลมากแล้ว
ส่วนที่ 04 ราคาที่ทุกคนให้ความสนใจมากที่สุด
แต่เมื่อเทียบกับการเดาพื้นฐาน สำหรับนักพัฒนาและองค์กรที่ต้องการเชื่อมต่อเข้ากับกระบวนการทำงานจริง นั้นคือตารางราคา API ที่มีความเป็นจริงสูงและขัดกับสัญชาตญาณ
ก่อนหน้านี้ DALL-E 3 คิดค่าบริการตามภาพ (เช่น 0.04 ดอลลาร์ต่อภาพ)
แต่ตั้งแต่รุ่นแรก GPT-Image-1 OpenAI ก็ได้เปลี่ยนเป็นโครงสร้างการคิดค่าบริการตาม Token อย่างสมบูรณ์
GPT-Image-2 ครั้งนี้ยังคงรักษามาตรฐานนี้ไว้ ไม่เพียงเท่านั้น ยังเพิ่มปริมาณและลดราคาอีกด้วย
ตามตารางราคาที่เปิดเผยอย่างเป็นทางการเมื่อเร็วๆ นี้ ราคาต่อหนึ่งล้านโทเค็นมีดังนี้
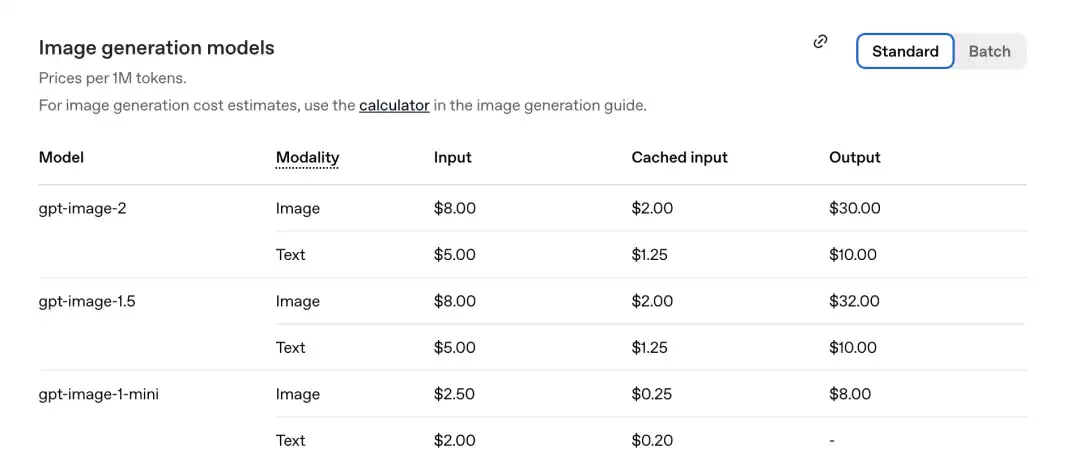
ส่วนภาพของ GPT-Image-2: ป้อน 8.00, ป้อนที่แคช (Cached inputs) 2.00, ผลลัพธ์ $30.00
เมื่อเปรียบเทียบกับรุ่นก่อนหน้า gpt-image-1.5: ผลลัพธ์คือ $32.00
โมเดลใหม่กลับถูกลง
เรามาคำนวณกันดูเถอะ
ในโมเดลก่อนหน้า การสร้างภาพคุณภาพสูงหนึ่งภาพมักใช้ทรัพยากรประมาณ 1,000 ถึง 1,500 Token ในการสร้าง
โดยคำนวณจากราคา 30 ดอลลาร์สหรัฐต่อโทเค็นหนึ่งล้านชิ้น ต้นทุนในการสร้างภาพหนึ่งภาพอยู่ที่ประมาณ 0.03 ถึง 0.045 ดอลลาร์สหรัฐ (ประมาณ 2 ถึง 3 สตางค์จีน)
หากคุณไม่ต้องการการตอบกลับแบบเรียลไทม์ แต่ใช้โหมด API แบบ Batch ที่ทางฝั่งทางการให้มา ราคาจะลดลงอีกครึ่งหนึ่งทันที (ลดลงเหลือ $15.00)
คำนวณแล้ว ค่าใช้จ่ายต่ำสุดในการสร้างภาพหนึ่งภาพอยู่ที่มากกว่า 1 หยวนเล็กน้อย
ราคาของใบเดียวนี้มีความคุ้มค่าอยู่แล้ว แต่จุดเด่นที่แท้จริงของมันอยู่ที่การป้อนข้อมูลที่เก็บไว้ (Cached inputs) ในตารางราคา
ก่อนหน้านี้ เมื่อคุณวาดการ์ตูนเรื่องยาวหรือออกแบบโปสเตอร์ชุดเดียวกัน ทุกครั้งที่สร้างใหม่ คุณต้องอัปโหลดรูปอ้างอิงตัวละครจำนวนมาก บทสรุปเหตุการณ์ก่อนหน้า และคำสั่งยาวๆ ซ้ำๆ ทำให้ต้นทุนการป้อนข้อมูลสูงมาก
แต่ในรูปแบบการคิดค่าบริการตามโทเค็นในปัจจุบัน เมื่อคุณให้มันสร้างการ์ตูน 8 ภาพที่เชื่อมต่อกัน องค์ประกอบภาพของภาพแรกจะถูกเก็บเป็นข้อมูลบริบททันที
ตั้งแต่รูปที่สองเป็นต้นไป ต้นทุนการป้อนภาพลดลงอย่างฉับพลันจาก $8.00 เป็น $2.00 (คิดเพียง 25% ของราคา)
นั่นหมายความว่า เมื่อทำการผลิตภาพจำนวนมากในเชิงพาณิชย์ หรือต้องการความสอดคล้องของตัวละครอย่างสูงในการสร้างต่อเนื่อง ต้นทุนเพิ่มเติมจะลดลงอย่างรวดเร็ว
ยิ่งโมเดลฉลาดมากขึ้นและสร้างภาพมากขึ้น ต้นทุนเฉลี่ยต่อภาพก็ยิ่งต่ำลง
ตรรกะการเรียกเก็บเงินแบบอุตสาหกรรมนี้才是真正能把流水线画师逼上绝路的东西。
ส่วนที่ 05 เปิดโปงทีมงานเบื้องหลัง
สุดท้ายนี้ เรามาดูทีมวิชวลอันยอดเยี่ยมจาก OpenAI ที่มาแสดงในงานเปิดตัวแบบสดอีกครั้ง ฟังก์ชันต่างๆ ที่ก่อนหน้านี้หลายคนคิดว่าแปลกประหลาด ก็สามารถอธิบายได้อย่างสมเหตุสมผลแล้ว
ตัวอย่างเช่น มันแก้ไขปัญหาการจัดรูปแบบหลายภาษาที่ซับซ้อนและตัวอักษรที่ดูเหมือนภาพเขียนลึกลับได้อย่างไร
ไม่สามารถทำได้โดยไม่มีนักวิทยาศาสตร์ผู้เชี่ยวชาญในทีม Gabriel Goh

ในวงการวิชาการ เขาเป็นที่รู้จักมากที่สุดในบทบาทผู้แต่งหลักของโมเดลหลายรูปแบบเชิงนวัตกรรม CLIP
CLIP ได้สร้างรากฐานที่สำคัญในการทำให้ AI สมัยใหม่เข้าใจว่าภาษาของมนุษย์และพิกเซลของภาพสัมพันธ์กันอย่างไร
ด้วยการนำทีมของนักวิชาการด้านการแมปความหมายข้ามโมดัลities นี้ GPT-Image-2 ไม่ได้เดารูปร่างข้อความแบบสุ่มอีกต่อไป แต่สามารถเขียนจริงๆ ในระดับพิกเซล
ตัวอย่างอื่นคือ มันจะเข้าใจความสัมพันธ์ในพื้นที่สามมิติได้อย่างไร จนสามารถสร้างภาพพาโนรามา 360 องศาที่มีอัตราส่วนกว้างยาวสุดขั้ว แถมยังเข้าใจแสงและเงาในมุมใกล้ที่อยู่บนเมล็ดข้าว
นี่เป็นเพราะสมาชิกหลักอีกคนหนึ่งคือ Alex Yu

ก่อนเข้าร่วม OpenAI เขาเป็นผู้ร่วมก่อตั้งและอดีต CTO ของบริษัทสตาร์ทอัพชื่อดังในด้านการสร้าง 3D ชื่อ Luma AI และยังเป็นนักวิชาการชั้นนำที่เชี่ยวชาญในการพัฒนาการเรนเดอร์เชิงประสาทแบบ 3D (เช่น NeRF)
ด้วยการมีเขาอยู่ GPT-Image-2 ได้ก้าวพ้นการระบายพิกเซลแบบ 2D แบบดั้งเดิมไปแล้ว
มันน่าจะสร้างฉากสามมิติในจิตใจก่อน จัดแสงให้เรียบร้อย แล้วจึงเรนเดอร์ภาพตัดขวาง 2D ที่แม่นยำให้คุณ
พวกเขาทำให้การสอดคล้องกันของการ์ตูนหลายหน้าที่น่ากลัวมากได้อย่างไร
นี่คือคู่หูหนุ่มสาวคู่หนึ่งที่เพิ่งสำเร็จการศึกษาจาก MIT CSAIL ในทีม:
Boyuan Chen (ซ้าย) และ Kiwhan Song (ขวา)
ทิศทางหลักในวงการวิชาการของพวกเขาคือโลกแบบจำลอง (World Models) และปัญญาเชิงร่างกาย
การสอนให้เครื่องจักรเข้าใจว่าโลกทางกายภาพทำงานอย่างไร เพื่อให้ตัวละครมีลักษณะคงที่และไม่เกิดการบิดเบี้ยวภายใต้ฉากต่างๆ ในเวลาและพื้นที่ต่างกัน นั่นคือประเด็นที่นักวิชาการทั้งสองคนพยายามแก้ไขมาโดยตลอด
สุดท้าย ขอขอบคุณ Nithanth Kudige (ซ้าย ผู้แต่งหลักของโมเดลการให้เหตุผลซีรีส์ O) และ Kenji Hata (ขวา นักวิจัยเดิมของกูเกิล สำเร็จการศึกษาจากห้องปฏิบัติการภาพถ่ายของสแตนฟอร์ด) ที่มุ่งมั่นเชื่อมโยงโมเดลการให้เหตุผลขนาดใหญ่กับตรรกะพื้นฐานด้านภาพ

เมื่อกลุ่มคนเหล่านี้มารวมกัน ตรรกะพื้นฐาน การเรนเดอร์พื้นที่สามมิติ การจัดแนวภาพและข้อความอย่างสมบูรณ์แบบ และกฎของโลกทางกายภาพ ถูกผสานเข้าด้วยกันอย่างเป็นธรรมชาติในโมเดลเดียวกัน
ส่วนที่ 06 ขอบเขตของ GPT-Image-2
ทุกโมเดลมีขีดจำกัด
ทางฝ่ายอย่างเป็นทางการก็ยอมรับว่า ยังคงมีปัญหาเมื่อเผชิญกับสถานการณ์สุดขั้วบางประการ
ตัวอย่างเช่น คู่มือการพับกระดาษที่ต้องการการพลิกกลับในพื้นที่ทางกายภาพอย่างเข้มงวด การแก้ปริศนาลูกบาศก์ฮังการี หรือรายละเอียดที่ซ้ำซากอย่างมากเช่นเม็ดทรายที่หนาแน่นมาก ก็ยังคงแตะถึงขีดจำกัดของความสามารถของมัน
แต่ในบริบทของการใช้งานเชิงพาณิชย์ นี่ถือเป็นข้อบกพร่องที่เล็กมาก
สำหรับอุตสาหกรรมการออกแบบทั้งหมด เราไม่จำเป็นต้องสร้างความวิตกกังวล เพราะสิ่งนี้ไม่ได้หมายความถึงการสูญสิ้นของความงาม
ผู้ที่มีรสนิยม มีความเข้าใจทางธุรกิจ และเข้าใจกลยุทธ์ ยังสามารถใช้มันสร้างสิ่งที่ยอดเยี่ยมได้
แต่ความจริงที่มีอยู่อย่างเป็นรูปธรรมคือ กำแพงป้องกันของอาชีพนักออกแบบได้ถูกทำลายอย่างแท้จริงแล้ว
ก่อนหน้านี้ ฉันใช้ชีวิตโดยการท่องปุ่มลัดของซอฟต์แวร์ออกแบบ รู้วิธีจัดเรียงตัวอักษรให้ตรงระนาบและแนวนอน รู้วิธีจัดการจัดเรียงข้อความตามภาษา และรู้วิธีแต่งภาพและตัดภาพอย่างละเอียด
แต่ในอนาคตจะยากขึ้น เพราะทักษะที่เคยสามารถระบุราคาและซื้อขายได้ในอดีต ตอนนี้กลายเป็นคำสั่งพื้นฐานที่ทุกคนสามารถเรียกใช้ได้ฟรีด้วยเพียงหนึ่งประโยค
หลังจากเงียบไปสักพัก โอเพนเอไอได้พิสูจน์อีกครั้งว่าใครคือผู้ถือไพ่ล่างที่แท้จริงบนโต๊ะนี้ โดยใช้วิธีที่เงียบสงบแต่มีพลังทำลายล้างอย่างยิ่ง
เครื่องมือการดำเนินการเก่ากำลังพังทลาย คำถามที่เหลืออยู่สำหรับอุตสาหกรรมไม่ใช่ว่า AI จะมาแทนที่เราหรือไม่ แต่คือเราจะปรับตัวให้เข้ากับสายการผลิตใหม่นี้อย่างไร