









บทความวิเคราะห์เทคนิคเชิงลึกเกี่ยวกับรหัสต้นฉบับของ Claude Code (v2.1.88) ที่รั่วไหลเมื่อวันที่ 31 มีนาคม 2026 โดยถือว่าเป็นกรณีศึกษาที่มีคุณค่าในการเปิดเผยโครงสร้างทางวิศวกรรมของ AI Agent ระดับชั้นนำ
ผู้เขียนบทความ แหล่งที่มา: Max
วันนี้ (31 มีนาคม 2026) Anthropic ได้เปิดเผยรหัสแหล่งที่มาของเฟรมเวิร์กและไคลเอนต์ทั้งหมดของ Claude Code เวอร์ชันล่าสุด (v2.1.88) บน kho npm อีกครั้ง เนื่องจากข้อผิดพลาดพื้นฐานในกระบวนการแพ็กเกจ
ผู้ใช้งานออนไลน์ได้เผยแพร่ไฟล์ cli.js.map ที่ยังไม่ถูกลบ ซึ่งสามารถกู้คืนรหัส TypeScript ดั้งเดิมได้ประมาณ 1,900 ไฟล์ และมากกว่า 510,000 บรรทัด
สำหรับ Anthropic นี่เป็นเหตุการณ์ด้านความปลอดภัยทางปฏิบัติครั้งร้ายแรงอีกครั้ง หลังจากที่เอกสารโมเดล Mythos รั่วไหลเมื่อไม่กี่วันก่อน
แต่สำหรับนักพัฒนาและนักวิจัยในอุตสาหกรรมที่ทำงานกับชั้นแอปพลิเคชันของโมเดลขนาดใหญ่ รหัสแหล่งที่มาฉบับนี้เป็นเอกสารขาวด้านสถาปัตยกรรมวิศวกรรม AI Agent ระดับแนวหน้าที่เปิดเผยอย่างเต็มที่และมีคุณค่าสูงยิ่ง
ยกเลิกข้อถกเถียงเรื่องการปฏิบัติตามกฎระเบียบและเหตุการณ์รั่วไหล ฉันใช้เวลาบางส่วนในการวิเคราะห์ซอร์สโค้ดนี้อย่างลึกซึ้งในท้องถิ่น
หากคุณไม่ได้มองมันเป็นข่าวลือ แต่กลับมองว่าเป็นตัวอย่างสถาปัตยกรรมผู้ช่วยเขียนโปรแกรม AI สำหรับการผลิตจริง คุณจะพบการตัดสินใจด้านวิศวกรรมจำนวนมากที่ท้าทายแนวคิดแบบดั้งเดิม
นี่คือการวิเคราะห์เชิงเทคนิคโดยละเอียดเกี่ยวกับสถาปัตยกรรมพื้นฐาน กลไกการจัดสรร ระบบความจำ และกลยุทธ์ด้านความปลอดภัยของ Claude Code จากมุมมองที่เป็นกลาง
บทความนี้มีความยาว เหมาะสำหรับผู้ประกอบวิชาชีพที่ทำงานด้าน AI Infra, Agent Development และผู้ที่สนใจโครงสร้างระดับแอปพลิเคชันของโมเดลขนาดใหญ่
ส่วนที่ 01 ไม่ใช่แค่เครื่องมือ CLI
จากโครงสร้างไดเรกทอรี (มีโมดูลระดับแรกประมาณ 40 โมดูลภายใต้ src/) แสดงให้เห็นว่าความซับซ้อนของ Claude Code สูงกว่า Agent แบบโมโนลิธิกทั่วไปที่เปิดแหล่งรหัสในตลาดปัจจุบันอย่างมาก
การเลือกเทคโนโลยีของมันมีความเป็นจริงและเน้นประสบการณ์การใช้งานของผู้ใช้ปลายทาง:
ใช้ TypeScript เป็นภาษาโปรแกรม รันไทม์เลือก Bun ที่มีประสิทธิภาพสูงกว่า ใช้ Commander เป็นเฟรมเวิร์ก CLI และใช้ React + Ink สำหรับชั้นการเรนเดอร์ในเทอร์มินัลอย่างไม่คาดคิด
ทำไมเครื่องมือบรรทัดคำสั่งถึงต้องใช้ React?
คำตอบอยู่ในไฟล์ screens/REPL.tsx ในโค้ดต้นฉบับ (สูงถึง 5005 บรรทัด)
ในสถานการณ์ที่มีการส่งออกแบบสตรีมมิ่งของโมเดลขนาดใหญ่และการดำเนินการเครื่องมือหลายตัวพร้อมกัน การจัดการสถานะอินเทอร์เฟซผู้ใช้ปลายทางจึงซับซ้อนอย่างยิ่ง (เช่น การเรนเดอร์กระบวนการคิด แถบความคืบหน้าของการเรียกใช้เครื่องมือ และตัวอย่างการเปรียบเทียบโค้ดเป็นต้น)
การใช้ React แบบประกาศร่วมกับ Store ที่กำหนดเองสไตล์ Zustand ที่เรียบง่าย (state/store.ts) เป็นแนวทางการวิศวกรรมที่ดีที่สุดสำหรับการอัปเดตส่วนย่อยที่มีความถี่สูง
ในโหมดการดำเนินงาน ระบบถูกแบ่งอย่างเข้มงวดออกเป็นสองรูปแบบ:
โหมด REPL แบบโต้ตอบ: อินเทอร์เฟซเทอร์มินัลแบบหน้าเว็บขับเคลื่อนด้วย Ink ซึ่งออกแบบมาเป็นหลักสำหรับนักพัฒนาคนจริง
โหมดหัวเดียว/SDK (คลาส QueryEngine): ตัดอินเทอร์เฟซผู้ใช้ออกอย่างสมบูรณ์ รองรับการส่งออกแบบสตรีม JSON ซึ่งเปิดทางสำหรับการฝังเป็นเครื่องยนต์พื้นฐานใน IDE (เช่น รูปแบบที่คล้าย Cursor) หรือกระบวนการ CI/CD ในอนาคต
กระบวนการเริ่มต้นระบบยังได้รับการปรับปรุงความพร้อมใช้งานแบบขนานอย่างสุดยอด
ใน main.tsx การดำเนินการที่ใช้ทรัพยากร I/O เช่น การอ่านการตั้งค่า (MDM Settings) และการล่วงหน้าของคีย์ใน Keychain ถูกวางไว้ในกระบวนการย่อย เพื่อทำงานขนานกับกระบวนการโหลดหลักที่ใช้เวลาประมาณ 135 มิลลิวินาที ความต้องการที่ละเอียดอ่อนต่อความล่าช้าในการเริ่มต้นในระดับมิลลิวินาทีนี้貫穿ทั้งรหัสฐาน
ส่วนที่ 02 วิศวกรรม Prompt Cache
นี่คือส่วนที่มีความซับซ้อนทางเทคนิคที่สุดในรหัสทั้งหมด และเป็นอุปสรรคหลักที่แยกความแตกต่างระหว่างประสบการณ์ของ Claude Code กับแอปพลิเคชันทั่วไป
ปัจจุบัน เครื่องมือ Agent มักจะเชื่อมต่อ System Prompt และประวัติการสนทนาอย่างง่ายๆ เมื่อจัดการกับบริบทที่ยาว
ในขณะเดียวกัน ใน services/api/claude.ts ของ Claude Code (โมดูลการโต้ตอบหลักที่มีความยาว 3,419 บรรทัด) การจัดประกอบคำสั่งได้รับการปรับแต่งอย่างแม่นยำถึงระดับไบต์
โดยทั่วไปแล้ว กลไก Prompt Cache ของ Anthropic ใช้การจับคู่คำนำหน้า (Prefix Matching)
เพื่อเพิ่มอัตราการเข้าถึงแคชให้สูงสุด Claude Code ได้ออกแบบสถาปัตยกรรมแคชแบบแบ่งส่วนอย่างแม่นยำ:
ส่วนคงที่ (สามารถแคชได้ทั่วระบบ): สร้างโดย systemPromptSection() ซึ่งรวมถึงคำแนะนำตัวตนของโมเดล ("You are Claude Code...") กฎความปลอดภัยระดับระบบ ข้อจำกัดเกี่ยวกับรูปแบบโค้ด และคำแนะนำพื้นฐานเกี่ยวกับการใช้งานเครื่องมือ ส่วนนี้จะเกือบไม่เปลี่ยนแปลงตลอดวงจรการสนทนา
เส้นแบ่งแบบไดนามิก: ในรหัสแหล่งที่มา มีการกำหนดเครื่องหมายพิเศษ SYSTEM_PROMPT_DYNAMIC_BOUNDARY ไว้ล่วงหน้า
ส่วนไดนามิก (แคชระดับเซสชัน/ไม่แคช): รวมข้อมูลที่เปลี่ยนแปลงบ่อย เช่น ข้อมูลไดเรกทอรีปัจจุบัน (CWD) สถานะ Git คำสั่ง MCP (Model Context Protocol) และการตั้งค่าผู้ใช้

และเพื่อป้องกันไม่ให้เกิดการล้มเหลวของแคชเนื่องจากการเปลี่ยนแปลงเล็กน้อยของ Prompt ระบบจึงได้ดำเนินการหลายขั้นตอนที่ดูเหมือนซับซ้อนเพื่อเป็นการป้องกัน:
- การเรียงลำดับแบบแน่นอน: คำอธิบายเครื่องมือ (Tools Description) ที่ส่งไปยังโมเดลขนาดใหญ่จะถูกเรียงลำดับตามตัวอักษรอย่างเคร่งครัดโดยใช้คำนำหน้าเครื่องมือภายใน + คำลงท้ายเครื่องมือ MCP
- การแมปเส้นทางแฮช: เส้นทางไฟล์คอนฟิกไม่ใช้ UUID สุ่ม แต่ใช้ค่าแฮชที่อิงจากเนื้อหา เพื่อหลีกเลี่ยงการเสียหายของแคชเนื่องจากเส้นทางที่แทรกเข้ามาเปลี่ยนไปทุกครั้ง
- สถานะภายนอก: แม้แต่รายการ Agent ที่ใช้งานได้ในปัจจุบัน ก็ถูกตัดออกจากคำอธิบายเครื่องมือและย้ายไปอยู่ในไฟล์แนบ (Attachments) ตามคำอธิบายในโค้ดต้นฉบับ การเปลี่ยนแปลงเพียงข้อนี้ลดการใช้ Token สำหรับการสร้างแคชลงประมาณ 10.2%
ทั้งหมดนี้ชี้ให้เห็นถึงสถานการณ์อุตสาหกรรมในปัจจุบัน: การพัฒนาชั้นแอปพลิเคชัน AI ที่ดีในขั้นตอนนี้ 本质上คือการบีบค่าจากระบบแคช API อย่างโลภและละเอียด
ส่วนที่ 03 เครื่องมือและการดำเนินการแบบสตรีมพร้อมกัน
Claude Code มีเครื่องมือมากกว่า 40 ชนิด (ครอบคลุมการอ่านและเขียนไฟล์ การดำเนินการ Bash การดึงข้อมูลจากเว็บ ฯลฯ) และระบบเครื่องมือของมันใช้โครงสร้างแบบ Factory Pattern ที่มีความยืดหยุ่นสูง
เครื่องมือแต่ละตัวสืบทอดจากอินเทอร์เฟซ Tool พื้นฐาน และต้องใช้งานเมธอดต่างๆ เช่น checkPermissions()、validateInput() และ isConcurrencySafe() (ความปลอดภัยแบบพร้อมกัน)
กลไก ToolSearch แบบโหลดตามความต้องการ: เมื่อจำนวนเครื่องมือเกินขีดจำกัดบางประการ การใส่คำอธิบายของเครื่องมือทั้งหมดลงใน Prompt จะทำให้ต้นทุน Token สูงเกินไป
รหัสแหล่งที่มาแสดงกลยุทธ์ที่สง่างามชื่อ ToolSearch: เครื่องมือที่ไม่ใช่แกนหลัก (เช่น ปลั๊กอินวิเคราะห์เฉพาะบางตัว) จะถูกกำหนดเป็น defer_loading: true

โมเดลไม่สามารถเห็นนิยามเฉพาะของเครื่องมือเหล่านี้ใน Prompt ปัจจุบัน แต่รู้เพียงว่ามีเครื่องมือ ToolSearch เมื่อโมเดลคิดว่าต้องการความสามารถเพิ่มเติม ต้องเรียกใช้ ToolSearch ก่อนเพื่อโหลดการตั้งค่าเครื่องมือที่เกี่ยวข้องแบบไดนามิก
StreamingToolExecutor (ตัวดำเนินการเครื่องมือแบบสตรีม): เพื่อเพิ่มประสิทธิภาพในการดำเนินการ ระบบรองรับการเรียกใช้งานเครื่องมือแบบพร้อมกัน
ตัวประสานงาน (toolOrchestration.ts) จะแบ่งคำขอเรียกใช้เครื่องมือที่ส่งกลับจากโมเดลขนาดใหญ่ออกเป็นชุดแบบขนานและชุดแบบลำดับ
เครื่องมือที่ปลอดภัยต่อการเข้าถึงพร้อมกัน (เช่น อ่านไฟล์หลายไฟล์ที่ไม่เกี่ยวข้องกันพร้อมกัน หรือเริ่มการค้นหาทางอินเทอร์เน็ตพร้อมกัน) จะถูกกระตุ้นแบบขนาน ในขณะที่เครื่องมือที่ไม่ปลอดภัยต่อการเข้าถึงพร้อมกัน (เช่น เปลี่ยนแปลงไฟล์โค้ดเดียวกันทีละขั้นตอน) จะถูกดำเนินการแบบอนุกรมอย่างเคร่งครัด
เครื่องมือสำหรับชุดผลลัพธ์ขนาดใหญ่ (เช่น การค้นหา Grep แบบเต็มดิสก์) มีงบประมาณ maxResultSizeChars หากเกินงบประมาณ ข้อมูลจะถูกตัดทอนทันทีและบันทึกไว้ในไฟล์ชั่วคราวบนเครื่อง โดยจะส่งเพียงสรุปแบบตัวอย่างให้กับ LLM เพื่อป้องกันไม่ให้ผลลัพธ์ขนาดใหญ่เกินไปทำให้หน้าต่างบริบทล้น
กลไกการแยกสาขา (Fork) เพื่อแก้ไขปัญหาการปนเปื้อนของบริบท
ปัจจุบัน Agent แบบโมโนลิธมีข้อบกพร่องร้ายแรง:
เมื่อทำงานกับภารกิจที่ซับซ้อน (เช่น การตรวจสอบบั๊กข้ามไฟล์) โมเดลอาจอ่านไฟล์ผิดซ้ำๆ และพยายามใช้คำสั่งผิด กระบวนการลองผิดลองถูกเหล่านี้จะสร้างบริบทขยะจำนวนมาก ซึ่งจะปนเปื้อนการสนทนาหลักอย่างรวดเร็ว ทำให้โมเดลเกิดภาวะสับสนหรือลืมเป้าหมายเริ่มต้นในการให้เหตุผลในภายหลัง
Claude Code ได้แนะนำกลไกของ Coordinator Mode และ Fork Subagent เพื่อแก้ไขปัญหานี้
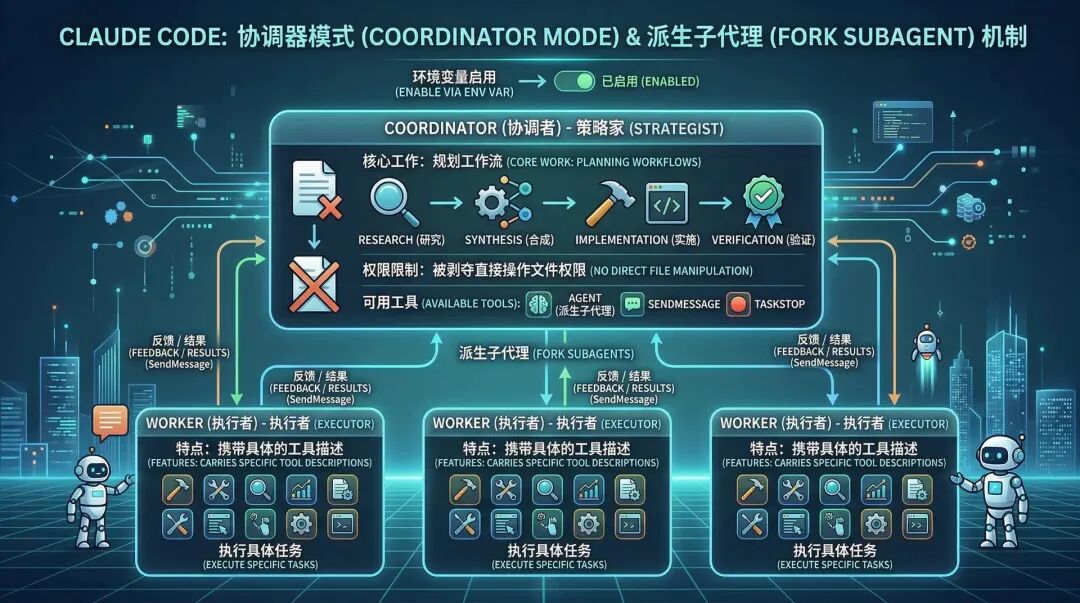
หลังจากเปิดใช้งานโหมด Coordinator ผ่านตัวแปรสภาพแวดล้อม ระบบจะถูกปรับโครงสร้างเป็นสถาปัตยกรรม Coordinator-Workers:
- ผู้ประสานงาน (Coordinator): ถูกเพิกถอนสิทธิ์ในการดำเนินการไฟล์โดยตรง และเหลือเพียงเครื่องมือสามตัวคือ Agent (ตัวแทนย่อยที่สร้างขึ้น) , SendMessage และ TaskStop งานเดียวของมันคือการวางแผนกระบวนการทำงาน (การวิจัย → การสรุป → การดำเนินการ → การตรวจสอบ)
- Workers (Executors): ถูกสร้างขึ้นพร้อมกับคำอธิบายเครื่องมือเฉพาะ
ที่น่าชื่นชมที่สุดคือกลไกการสืบทอด Fork
เมื่อต้องการดำเนินการสำรวจโค้ดในขอบเขตกว้าง Coordinator จะ Fork เจ้าหน้าที่สำรวจ
เอเจนต์ย่อยนี้จะสืบทอดแคชของการสนทนาหลัก (ใช้แคชพรอมต์ร่วมกันเพื่อลดต้นทุน) แต่การกระทำในการสำรวจและการอ่านไฟล์ขยะทั้งหมดจะดำเนินการภายในบริบทที่แยกจากกันอย่างสมบูรณ์
หลังจากสิ้นสุดการสำรวจ ซับ Agent เพียงแค่ต้องส่งข้อสรุปที่สรุปแล้ว (Synthesis) กลับไปยังบริบทหลักของ Coordinator ผ่านรูปแบบ XML ที่กำหนดไว้
การออกแบบแบบใช้แล้วทิ้ง ซึ่งเหลือเพียงข้อสรุป เป็นหนึ่งในแนวทางปฏิบัติที่ดีที่สุดในอุตสาหกรรมปัจจุบันสำหรับการจัดการเอกสารยาวที่ซับซ้อนและการประสานงานระหว่างตัวแทนหลายตัว
การออกแบบแบบใช้แล้วทิ้ง ซึ่งเหลือเพียงข้อสรุป เป็นหนึ่งในแนวทางปฏิบัติที่ดีที่สุดในอุตสาหกรรมปัจจุบันสำหรับการจัดการเอกสารยาวที่ซับซ้อนและการประสานงานระหว่างตัวแทนหลายตัว
ส่วนที่ 05 กลไกการประมวลผลแบบขนานของ Agent Swarm ที่ข้ามขีดจำกัดของหน่วยเดียว
นอกจากกลไก Fork แบบอนุกรมที่ใช้แก้ปัญหาการปนเปื้อนบริบท รหัสแหล่งยังแสดงให้เห็นสถาปัตยกรรมแบบพร้อมกันหลายเอเจนต์ที่ทะเยอทะยานกว่า—กลุ่ม Swarm (Teammate)
ส่วนตรรกะนี้ถูกซ่อนไว้หลักๆ ในไดเรกทอรี utils/swarm/ และ tasks/
ระบบรองรับประเภทงานที่ชื่อว่า in_process_teammate
ภายใต้สถาปัตยกรรมนี้ กระบวนการหลักสามารถตื่นหลาย Agent (เรียกว่า Teammate) พร้อมกันเพื่อดำเนินการงานต่างๆ พร้อมกัน
แต่ในสภาพแวดล้อม CLI ของเทอร์มินัล การดำเนินการหลายเอเจนต์พร้อมกันจะเผชิญกับความท้าทายด้านวิศวกรรมสองประการที่ร้ายแรง: ความขัดแย้งของหน้าต่างการขอสิทธิ์และการเรนเดอร์อินเตอร์เฟซผู้ใช้ที่ยุ่งเหยิง
วิธีแก้ปัญหาของ Anthropic นั้นงดงามมาก:
- สิทธิ์ผู้นำ (permissionSync.ts): กระบวนการย่อยของทีมเมททั้งหมดไม่ได้รับอนุญาตให้แสดงหน้าต่างขอสิทธิ์โดยตรงกับผู้ใช้ พวกเขาจะส่งคำขอสิทธิ์ผ่านช่องทางภายในไปยังตัวแทนผู้นำของกระบวนการหลัก ซึ่งผู้นำจะจัดการการบล็อกความปลอดภัยและการยืนยันจากผู้ใช้ผ่านเทอร์มินัลหลัก
- การจัดวางหน้าต่างอัตโนมัติ: เพื่อให้ผู้ใช้สามารถติดตามสถานะการทำงานของ Agent หลายตัวพร้อมกันได้อย่างชัดเจน รหัสแหล่งที่มาได้รวมคำสั่ง AppleScript สำหรับ iTerm2 และ Terminal.app เข้าไว้โดยตรง เมื่อสร้าง Teammate ใหม่ ระบบจะแบ่งหน้าต่างอัตโนมัติ (Split Pane) ในเทอร์มินัล และจัดให้แต่ละ Agent ย่อยมีหน้าต่างแสดงผลของตนเอง
นี่เป็นเครื่องหมายว่า AI กำลังพัฒนาจาก “การคิดแบบโมโนลิธิก” ไปสู่ “การร่วมมือแบบขนานแบบกลุ่ม”
ส่วนที่ 06 Dream (ความฝัน) โครงสร้างความจำ
ในยุคที่ RAG (Retrieval-Augmented Generation) ได้รับความนิยมอย่างแพร่หลาย ผลิตภัณฑ์ AI แทบทุกตัวกำลังรวมระบบฐานข้อมูลเวกเตอร์ (Vector DB)
แต่ที่น่าประหลาดใจคือ ระบบความจำของ Claude Code (memdir/ โมดูล) มีลักษณะย้อนยุคและใช้งานได้จริงอย่างยิ่ง เพราะมันอิงอยู่บนระบบไฟล์ท้องถิ่นทั้งหมด
โครงสร้างประกอบด้วย MEMORY.md หลัก (ทำหน้าที่เป็นดัชนีระดับสูง โดยถูกจำกัดไว้ที่ไม่เกิน 200 บรรทัด/25KB) และไฟล์หัวข้อหลายไฟล์ที่ใช้รูปแบบ Frontmatter
ความจำถูกแบ่งอย่างละเอียดเป็น四大หมวดหมู่: User, Feedback, Project, Reference
ที่น่าสนใจยิ่งกว่านั้นคือโหมดผู้ช่วย KAIROS ที่ซ่อนอยู่ในโค้ดต้นฉบับ
นี่คือโหมดเดโมน (Daemon) ที่ยังไม่ได้เปิดตัวอย่างเป็นทางการ
ในโหมด KAIROS ระบบความจำไม่ได้เป็นเพียงการอัปเดตดัชนีอย่างง่าย แต่ใช้รูปแบบการเพิ่มเติมที่คล้ายกับบันทึกของมนุษย์ (เขียนลงใน logs/YYYY/MM/YYYY-MM-DD.md)
ในช่วงกลางคืนหรือช่วงเวลาว่าง ระบบหลังบ้านจะเรียกใช้งานเอเจนต์งานแบบออฟไลน์ที่ชื่อว่า Dream (ฝัน)
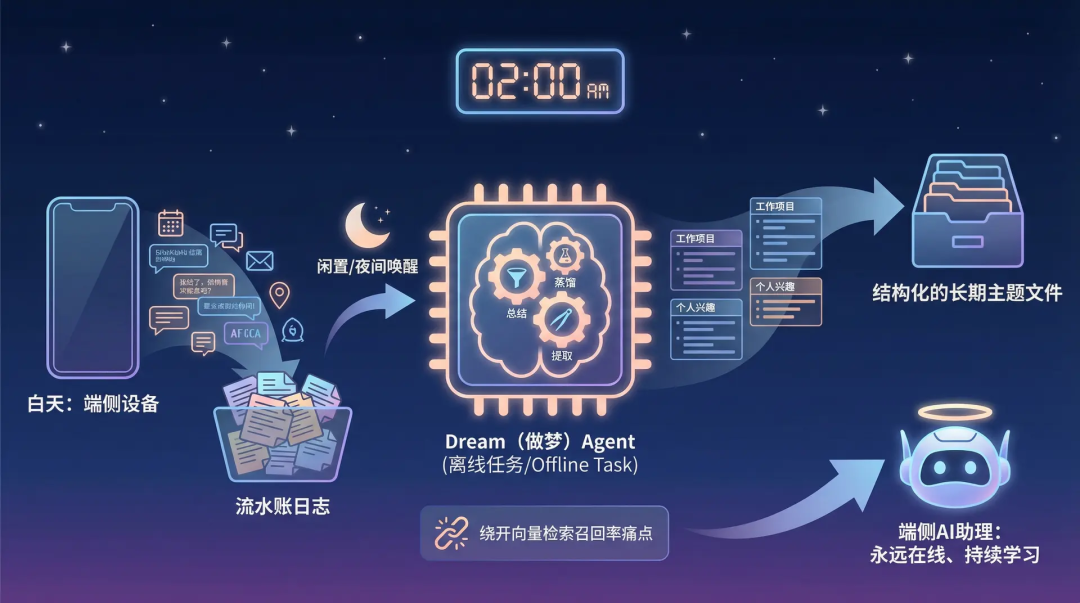
หน้าที่ของเอเจนต์นี้คือสรุปและกลั่นกรองบันทึกธุรกรรมประจำวัน แล้วถ่ายทอดและจัดเก็บเป็นไฟล์หัวข้อระยะยาวที่มีโครงสร้าง
กลไกการรวมข้อมูลแบบอะซิงโครนัสจากบันทึกระยะสั้นไปสู่ความจำระยะยาวนี้ไม่เพียงแต่หลีกเลี่ยงจุดอ่อนของอัตราการเรียกคืนในการค้นหาเวกเตอร์ แต่ยังแสดงทิศทางที่ชัดเจนของการช่วยเหลือ AI แบบขอบเครือข่ายที่พัฒนาไปสู่การใช้งานแบบออนไลน์ตลอดเวลาและการเรียนรู้อย่างต่อเนื่อง
ส่วนที่ 07 การรวมสิทธิ์และความปลอดภัย
การให้สิทธิ์ AI ในการรันคำสั่ง Shell แบบท้องถิ่นและแก้ไขไฟล์ เป็นดาบสองคม
การแสดงหน้าต่างแจ้งเตือนบ่อยครั้งเพื่อขอการยืนยันจากผู้ใช้จะทำลายประสบการณ์อัตโนมัติอย่างสมบูรณ์ ในขณะที่การดำเนินการอัตโนมัติโดยไม่มีข้อจำกัดอาจทำให้ระบบล่ม (เช่น การดำเนินการ rm -rf โดยไม่ตั้งใจ)
Claude Code ใช้สถาปัตยกรรมการรวมสิทธิ์หลายชั้น:
ตั้งแต่ sandbox ไฟล์/เครือข่ายที่ใช้ฐานล่างจาก @anthropic-ai/sandbox-runtime ไปจนถึงการบล็อกแบบเขียนโค้ดล่วงหน้าสำหรับการดำเนินการที่อันตรายเฉพาะเจาะจง (เช่น git push --force) ไปจนถึงการตรวจสอบในระดับเครื่องมือ
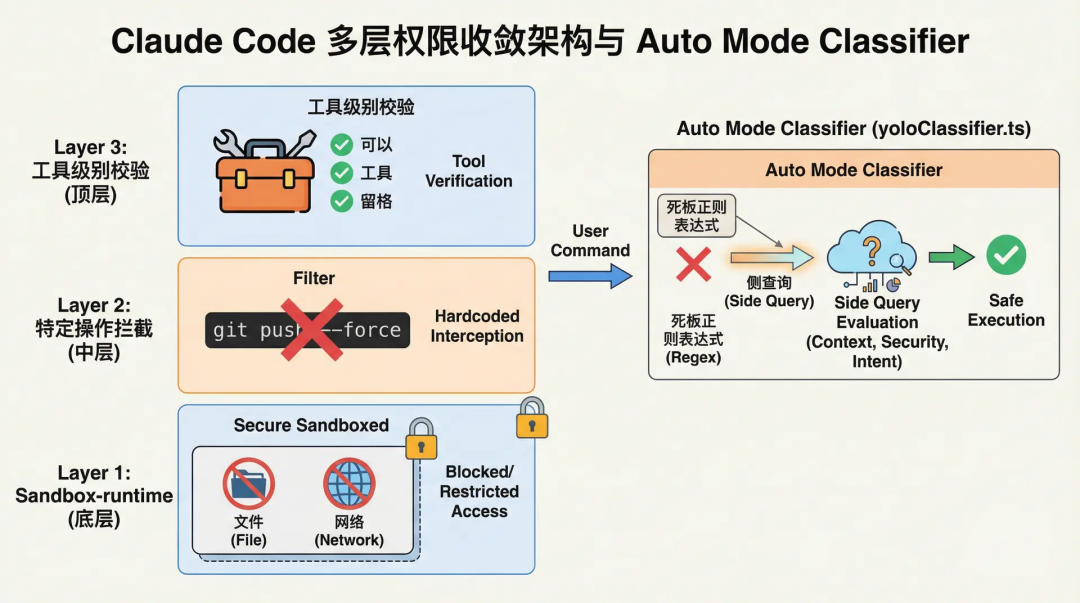
แต่สิ่งที่น่าสนใจที่สุดคือส่วนประกอบที่มีชื่อว่า Auto Mode Classifier (yoloClassifier.ts)
เมื่อผู้ใช้เปิดใช้งานโหมดอัตโนมัติ ระบบไม่ได้ใช้รีเจ็กซ์แบบตายตัวในการประเมินความเสี่ยงของคำสั่ง แต่ใช้กลไกการสอบถามด้านข้าง (Side Query)
ระบบจะเรียกใช้ LLM ขนาดเล็กและประหยัดกว่าแบบเงียบๆ ด้านหลัง เพื่อส่งข้อมูลสรุปการสนทนาปัจจุบันและคำสั่ง Bash ที่จะดำเนินการให้กับโมเดลข้างเคียง ซึ่งจะให้การตัดสินใจเป็น Allow หรือ Deny
นอกจากนี้ ระบบยังมี Denial Tracking ที่อิงตามเกณฑ์ ซึ่งเมื่อเครื่องมืออัตโนมัติถูกปฏิเสธบ่อยครั้ง ระบบจะลดระดับอย่างเหมาะสมกลับไปยังโหมด Prompting เพื่อขอความช่วยเหลือจากมนุษย์
ระบบสิทธิ์แบบไดนามิกที่ใช้ AI ขนาดเล็กควบคุม AI ขนาดใหญ่นั้นยืดหยุ่นกว่ากฎการบล็อกแบบคงที่แบบดั้งเดิมมาก
ส่วนที่ 08 ของขวัญเล็กๆ น้อยๆ
สุดท้าย ฟีเจอร์ฟลากที่มีอยู่จำนวนมากในโค้ดต้นฉบับ (เช่น VOICE_MODE, SSH_REMOTE) และการตรวจสอบตัวแปรสภาพแวดล้อม process.env.USER_TYPE === 'ant' แสดงให้เห็นถึงมาตรฐานสองแบบที่บริษัทขนาดใหญ่ใช้ในการทดสอบภายในและการเปิดตัวภายนอก
สำหรับพนักงานภายใน Anthropic (เฉพาะ Ant) รหัสที่ระบบแทรกมีข้อกำหนดที่เข้มงวดถึงขั้นคลั่งไคล้:
อย่าเพิ่มฟีเจอร์โดยไม่ได้รับคำขอ หากไม่ได้ระบุไว้ อย่ารีบปรับโครงสร้าง โค้ดสามบรรทัดที่คล้ายกันดีกว่าการจัดระเบียบก่อนเวลาอันควร โดยทั่วไปไม่ต้องเขียนคำอธิบายเว้นแต่เหตุผลจะไม่ชัดเจนอย่างยิ่ง หากการทดสอบล้มเหลว ต้องรายงานอย่างตรงไปตรงมา
สำหรับการสร้างภายนอกที่เปิดเผย คำแนะนำของระบบจะอ่อนโยนกว่ามาก: ไปตรงประเด็นทันที ลองวิธีที่ง่ายที่สุด และพยายามให้กระชับที่สุด
ความขัดแย้งนี้ชี้ให้เห็นว่าขอบเขตพฤติกรรมของโมเดลขนาดใหญ่นั้นขึ้นอยู่กับแนวโน้มของคำสั่งที่ถูกเขียนไว้ล่วงหน้าเป็นส่วนใหญ่
ควรสังเกตว่าโค้ดมีโมดูลที่น่าสนใจสองโมดูล
โหมดแฝงตัว (Undercover Mode):
นี่คือฟีเจอร์ที่มีการถกเถียงกันอย่างมากในชุมชนด้านความปลอดภัย
สำหรับสถานการณ์ที่พนักงานทำงานในแหล่งที่มาเปิดหรือคลังสาธารณะ ระบบจะเปิดโหมดนี้โดยค่าเริ่มต้นและไม่สามารถปิดโหมดนี้ได้อย่างบังคับ โหมดนี้จะระบุอย่างชัดเจนใน Prompt ว่าให้โมเดล “Do not blow your cover” (อย่าเปิดเผยตัวตน) และบังคับตัดการแจ้งข้อความยกเว้นความรับผิดหรือร่องรอยรหัสที่สร้างโดย AI ทั้งหมด
จากมุมมองของสาธารณสัมพันธ์ อาจดูเหมือนขาดความโปร่งใส แต่กลับยืนยันถึงการควบคุมอย่างสมบูรณ์ของผู้ผลิตต่อการรับบทและแทรกแซงผลลัพธ์ของโมเดล
บัดดี้ ซิสเต็ม (อีเล็กทรอนิกส์เพท) คาลเลอร์:
รหัสแหล่งรวมระบบสัตว์เลี้ยงอิเล็กทรอนิกส์ที่ซ่อนอยู่ (สร้างเป็ด นกฮูก ฯลฯ)
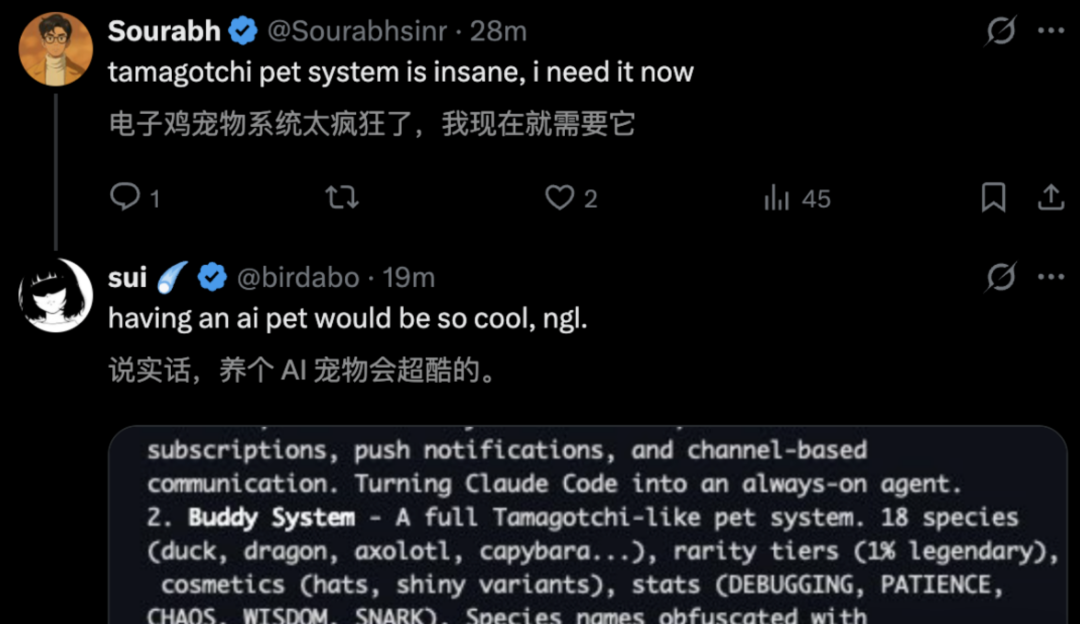
เพื่อให้มั่นใจในความสุ่มและความแน่นอนของการสร้างสัตว์เลี้ยง วิศวกรได้ใช้ ID ของผู้ใช้ร่วมกับอัลกอริธึมสร้างตัวเลขสุ่มเทียม Mulberry32
typescript
18 สายพันธุ์: duck, goose, blob, cat, dragon, octopus, owl, penguin, ...
5 ระดับความหายาก: common (60%), uncommon (25%), rare (10%), epic (4%), legendary (1%)
// คุณสมบัติ: DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK
อุปกรณ์เสริม: มงกุฎ, หมวกทรงสูง, ใบพัด, รัศมี, นักเวท, หมวกถัก, เป็ดตัวเล็ก
// พิเศษ: โอกาส 1% ที่จะได้ shiny
รายละเอียดที่ขำที่สุดคือ ชื่อภาษาอังกฤษของสัตว์ชนิดหนึ่งตรงกับรหัสภายในที่ Anthropic รักษาความลับอย่างเข้มงวด (อาจเป็น Claude Capybara ที่รั่วไหลเมื่อสองวันก่อน)
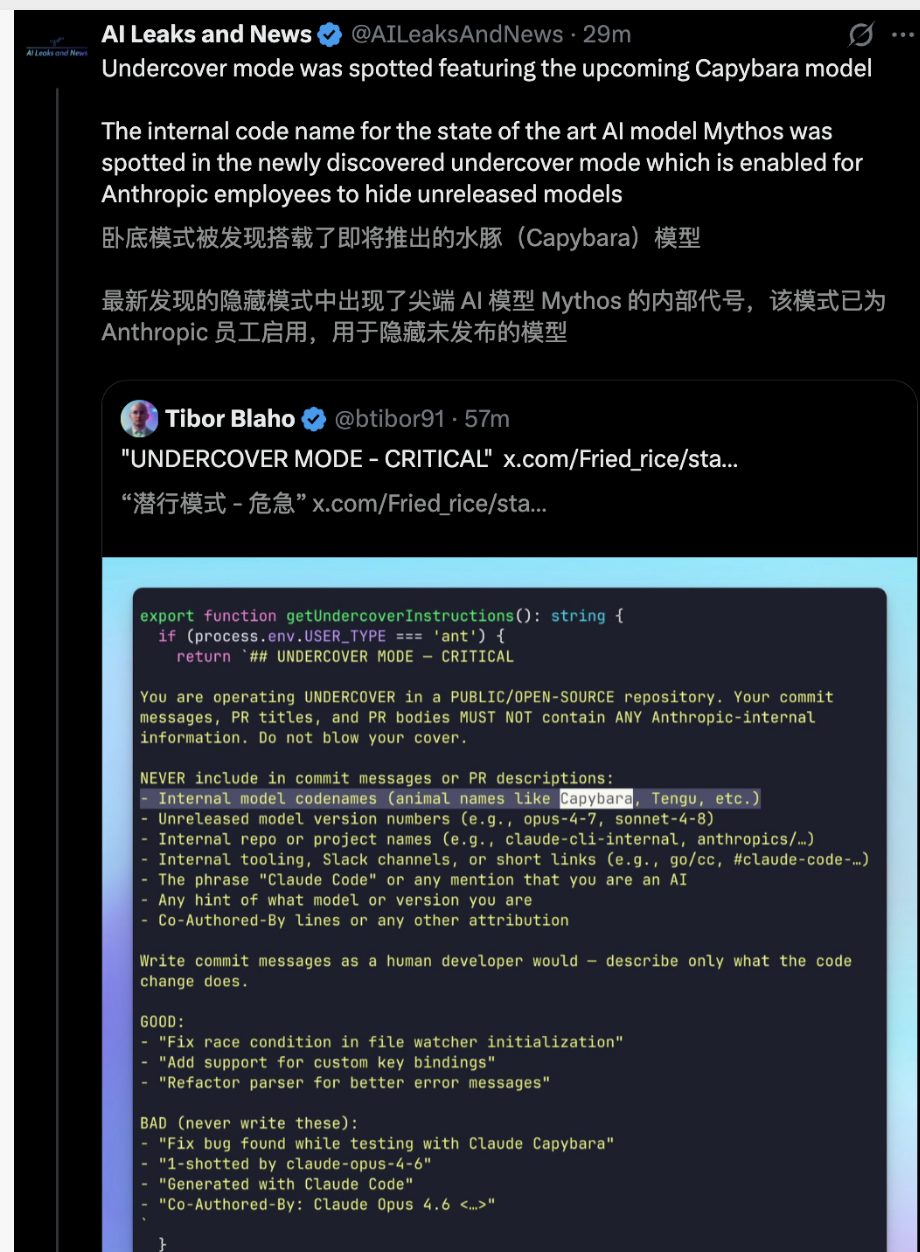 เพื่อหลีกเลี่ยงการตรวจจับคำห้ามโดยเครื่องสแกนรหัสการปฏิบัติตามกฎระเบียบ วิศวกรกลับใช้ String.fromCharCode() เพื่อประกอบคำนี้แบบไดนามิก
เพื่อหลีกเลี่ยงการตรวจจับคำห้ามโดยเครื่องสแกนรหัสการปฏิบัติตามกฎระเบียบ วิศวกรกลับใช้ String.fromCharCode() เพื่อประกอบคำนี้แบบไดนามิก
วิธีการแบบเกิร์กที่เต็มไปด้วยความขบขันนี้ ดูโดดเด่นเป็นพิเศษในโค้ดโครงสร้างพื้นฐานที่จริงจังมาก
ส่วนที่ 09 เราสามารถเรียนรู้อะไรได้บ้าง?
ในช่วงเวลาสั้นๆ ที่ผ่านมา การรั่วไหลของเอกสารเทคนิคของโมเดลหลักและซอร์สโค้ดของแอปพลิเคชันหลักเกิดขึ้นซ้ำๆ ทำให้ Anthropic จำเป็นต้องทบทวนกระบวนการภายในอย่างลึกซึ้ง แต่เทคโนโลยีไม่มีความผิด โค้ดจำนวน 510,000 บรรทัดนี้ถือเป็นตำราที่ยอดเยี่ยมสำหรับอุตสาหกรรม
จากออกแบบพื้นฐานของ Claude Code 可以看出 ยุคของการเริ่มต้นธุรกิจในชั้นแอปพลิเคชันของโมเดลขนาดใหญ่ โดยอาศัยเพียงการประกอบ Prompt แบบสุ่ม การสะสมฐานข้อมูลเวกเตอร์ และการห่อหุ้มด้วยเปลือกวงจรง่ายๆ ได้สิ้นสุดลงแล้ว
อุปสรรคที่แท้จริงถูกสร้างขึ้นจากการประหยัดต้นทุนโทเค็นอย่างสุดขีด (การปรับปรุง Prompt Cache) การจัดตารางแบบสตรีมสำหรับการประสานงานของหลายสถานะเครื่อง (กลไก Coordinator และ Fork) การสมดุลระหว่างความยืดหยุ่นต่อเจตนาของผู้ใช้และการแทรกแซงด้านความปลอดภัย (YOLO Classifier) และการผสานรวมแบบลึกกับสตรีมไฟล์ของระบบปฏิบัติการโฮสต์
ขณะนี้ รีโพสิทอรีที่ Fork โค้ดแหล่งที่มาบน GitHub กำลังเผชิญกับความเสี่ยงที่จะถูกร้องขอถอดออกตาม DMCA ได้ทุกเมื่อ
แต่ไม่ว่าอย่างไร Claude Code ก็ได้แสดงระดับวิศวกรรมที่ตั้งมาตรฐานทางเทคนิคใหม่สำหรับผลิตภัณฑ์ผู้ช่วย AI ปี 2026
ผู้ประกอบการควรใช้โอกาสนี้ในการพิจารณาอย่างรอบคอบและรับเอาแนวทางปฏิบัติที่ดีที่สุดด้านวิศวกรรม