










ที่มา: สถาบันวิจัย CoinW
สรุป
Gradients เป็นเครือข่ายย่อยสำหรับการฝึกอบรม AI แบบกระจายศูนย์ที่สร้างขึ้นบน Bittensor (SN56) โดยมีแกนหลักอยู่ที่การแปลงกระบวนการฝึกอบรมโมเดลที่ซับซ้อนให้กลายเป็นกระบวนการร่วมมือผ่านเครือข่ายที่ขับเคลื่อนโดยตลาดผ่านกลไกต่างๆ เช่น การเผยแพร่ภารกิจ การแข่งขันของ miner และการตรวจสอบคัดเลือก ในด้านสถาปัตยกรรม มันผสานรวม AutoML กับพลังการประมวลผลแบบกระจาย เพื่อสร้างตลาดการฝึกอบรมที่มีแรงจูงใจเป็นศูนย์กลาง ซึ่งไม่เพียงแต่ลดอุปสรรคในการใช้งาน AI แต่ยังเพิ่มประสิทธิภาพในการใช้พลังการประมวลผล จากมุมมองของระบบนิเวศและข้อมูลเชิงสถิติ Gradients ได้สร้างโครงสร้างพื้นฐานของเครือข่ายพื้นฐานแล้ว แต่ในขณะนี้น้ำหนักแรงจูงใจและการไหลเข้าของทุนยังค่อนข้างจำกัด Gradients ช่วยเติมเต็มโครงสร้างพื้นฐานด้านการฝึกอบรมในระบบนิเวศของ TAO และสำรวจรูปแบบใหม่ของ “การปรับปรุง AI ที่ขับเคลื่อนโดยตลาด” ซึ่งมีศักยภาพในระยะยาวที่จะกลายเป็นชั้นการเข้าถึงสำคัญสำหรับการฝึกอบรม AI แบบกระจายศูนย์
1. เริ่มจาก Web2 AutoML: สถานการณ์และข้อจำกัดของการฝึกฝน AI
1.1 AutoML คืออะไร
ในมุมมองแบบดั้งเดิม การฝึกโมเดล AI เป็นเรื่องที่มีอุปสรรคสูง ต้องใช้วิศวกรจัดการข้อมูล เลือกโมเดล ปรับพารามิเตอร์ซ้ำแล้วซ้ำเล่า และประเมินผลลัพธ์ กระบวนการทั้งหมดซับซ้อนและใช้เวลานาน แต่การมาของ AutoML (การเรียนรู้ของเครื่องอัตโนมัติ) 本质上คือการ “แพ็คและอัตโนมัติ” ขั้นตอนที่ยุ่งยากเหล่านี้ สามารถเข้าใจมันได้ว่าเป็น “เครื่องมืออัตโนมัติในการสร้างโมเดล”: ผู้ใช้เพียงแค่ให้ข้อมูลและแจ้งระบบถึงเป้าหมายที่ต้องการ เช่น การจำแนกประเภท การทำนาย หรือการรับรู้ ส่วนกระบวนการที่เหลือทั้งหมดรวมถึงการเลือกโมเดล การปรับพารามิเตอร์ การฝึกและปรับปรุง จะถูกดำเนินการโดยระบบอัตโนมัติ ทำให้ AI ค่อยๆ เปลี่ยนจากเครื่องมือของวิศวกรผู้เชี่ยวชาญจำนวนน้อย เป็นความสามารถที่นักพัฒนาทั่วไปหรือแม้แต่ธุรกิจสามารถใช้งานได้ ซึ่งเป็นก้าวสำคัญในการทำให้ AI เข้าถึงได้กว้างขวางยิ่งขึ้น
1.2 ข้อจำกัดหลักของ AutoML แบบดั้งเดิม
ปัจจุบัน การดำเนินการหลักของ AutoML มุ่งเน้นที่แพลตฟอร์มของผู้ให้บริการคลาวด์ เช่น Google Vertex AI และ AWS SageMaker ซึ่งเสนอ “การฝึกอบรม AI เป็นบริการ” แม้ว่า Web2 AutoML จะลดอุปสรรคในการใช้งาน AI อย่างมีนัยสำคัญ แต่รูปแบบพื้นฐานยังคงมีข้อจำกัดชัดเจน ประการแรกคือปัญหาการรวมศูนย์ กำลังประมวลผล ราคา และกฎเกณฑ์ทั้งหมดถูกควบคุมโดยแพลตฟอร์ม ผู้ใช้จึงพึ่งพาผู้ให้บริการรายเดียวอย่างมาก และขาดความสามารถในการต่อรอง ประการที่สองคือต้นทุนสูงและไม่โปร่งใส ทรัพยากร GPU ที่ใช้ในการฝึกอบรม AI ส่วนใหญ่อยู่ในมือของผู้ให้บริการคลาวด์ และกลไกราคาขาดการแข่งขันตามตลาด ยิ่งไปกว่านั้น ประสิทธิภาพในการปรับปรุงมีขีดจำกัด AutoML แบบดั้งเดิมยังคงเป็น “ระบบหนึ่งระบบช่วยคุณหาคำตอบที่ดีที่สุด” ไม่ว่าระบบจะซับซ้อนเพียงใด มันก็ยังเป็นการปรับปรุงตามเส้นทางเทคโนโลยีเดียวเท่านั้น พื้นที่การสำรวจของมันจึงจำกัด และยากที่จะทดลองแนวคิดที่ต่างกันอย่างสิ้นเชิงพร้อมกัน ดังนั้น การฝึกอบรม AI แบบ Web2 ปัจจุบันจึงเป็น “ระบบที่ปิด” การฝึกอบรม การปรับปรุง และการจัดสรรทรัพยากรของโมเดลทั้งหมดเกิดขึ้นภายในสภาพแวดล้อมที่ถูกควบคุมโดยแพลตฟอร์มเดียว รูปแบบนี้แม้จะมีประสิทธิภาพ แต่เมื่อความต้องการเพิ่มขึ้น ขอบเขตของมันกำลังเริ่มปรากฏชัด
2. Gradients: ใช้ “เครือข่าย” ในการสร้างใหม่การฝึกอบรม AI
2.1 Gradients คืออะไร: แพลตฟอร์ม AutoML แบบกระจายศูนย์
ในบทก่อนหน้า เราได้กล่าวถึงปัญหาหลักของ AutoML แบบดั้งเดิมใน Web2 คือ “ระบบที่ปิดกั้น” โดยการฝึกโมเดลขึ้นอยู่กับแพลตฟอร์ม ทางเลือกในการปรับแต่งมีจำกัด และการไหลเวียนของทรัพยากรถูกจำกัด Gradients เป็นการรีคอนสตรัคชันรูปแบบนี้ Gradients เกิดขึ้นจากชุมชนวิศวกรแบบกระจายศูนย์ที่ก่อตั้งโดย WanderingWeights และถูกสร้างขึ้นบนเครือข่าย Bittensor เป็นเครือข่ายย่อยสำหรับการฝึก AI ที่ทำงานบน Subnet 56 ต่างจากแพลตฟอร์มแบบดั้งเดิม ซึ่งไม่ได้ให้บริการแบบรวมศูนย์ แต่แบ่งกระบวนการฝึกออกและมอบหมายให้เครือข่ายเปิดดำเนินการ ผู้ใช้เพียงแค่กำหนดเป้าหมายงาน เช่น ประเภทโมเดลและข้อมูล ส่วนกระบวนการที่เหลือรวมถึงการดำเนินการฝึก การปรับแต่งพารามิเตอร์ และการคัดเลือกผลลัพธ์ จะถูกเครือข่ายดำเนินการอัตโนมัติ ในรูปแบบนี้ การฝึก AI ถูกนามธรรม화จากกระบวนการวิศวกรรมที่ซับซ้อนให้กลายเป็นกระบวนการง่ายๆ คือ “ส่งคำขอและรับผลลัพธ์” ซึ่งใกล้เคียงกับความสามารถทั่วไปมากกว่าการทำงานทางเทคนิคที่มีอุปสรรคสูง
2.2 จากระบบปิดสู่การร่วมมือแบบเปิด: Gradients แก้ปัญหาอะไร
การเปลี่ยนแปลงหลักของ Gradients คือการเปลี่ยนกระบวนการฝึกอบรมที่เคยถูกจำกัดอยู่ภายในแพลตฟอร์มเดียวให้กลายเป็นกระบวนการเครือข่ายที่เปิดกว้างและร่วมมือกัน งานฝึกอบรมไม่ได้ถูกดำเนินการโดยระบบเดียวอีกต่อไป แต่ถูกกระจายไปยังผู้เข้าร่วมหลายรายเพื่อทดลองพร้อมกัน จากนั้นจึงคัดเลือกผลลัพธ์ที่ดีที่สุดผ่านกลไกการประเมินแบบรวมศูนย์ โครงสร้างนี้ไม่เพียงลดการพึ่งพาผู้ให้บริการแบบกลางศูนย์ แต่ยังทำให้การฝึกอบรมอิงบนพลังการประมวลผลแบบกระจาย พร้อมกันนี้ ทรัพยากร GPU ที่กระจายอยู่ถูกผสานเข้าเป็นเครือข่ายเดียวกัน และเกิดการจัดสรรทรัพยากรที่ใกล้เคียงกับกลไกตลาดผ่านการแข่งขัน ยิ่งไปกว่านั้น การปรับปรุงโมเดลไม่ได้ถูกจำกัดอยู่เพียงเส้นทางเดียว แต่ดำเนินการไปพร้อมกันในหลายวิธีเพื่อค้นหาทางออกที่ดีขึ้นอย่างต่อเนื่อง จึงช่วยเพิ่มขีดจำกัดสูงสุดของการปรับปรุงโดยรวม
2.3 การเปลี่ยนแปลงพื้นฐาน: จากเครื่องมือสู่ “ตลาดการฝึกอบรม”
ใน AutoML แบบดั้งเดิม แพลตฟอร์มมีลักษณะเหมือนเครื่องมือที่ช่วยผู้ใช้ค้นหาคำตอบที่ดีที่สุดผ่านอัลกอริธึมภายใน ในขณะที่ใน Gradients กระบวนการนี้ใกล้เคียงกับ “ตลาด” ที่ทำงานอย่างต่อเนื่อง: ผู้ใช้ประกาศความต้องการ ผู้เข้าร่วมต่างๆ แข่งขันกันเพื่อแก้ไขงานเดียวกัน และผลลัพธ์จะถูกคัดเลือกผ่านกลไกการประเมิน ดังนั้น ประสิทธิภาพของโมเดลจึงไม่ได้ขึ้นอยู่กับความสามารถของระบบเดียว แต่เกิดจากการแข่งขันและการปรับปรุงอย่างต่อเนื่องจากหลายฝ่าย AutoML จึงเปลี่ยนจากปัญหาการปรับปรุงเทคโนโลยีที่ค่อนข้างปิด เป็นกระบวนการเชิงพลวัตที่ขับเคลื่อนด้วยแรงจูงใจ ทำให้ความสามารถในการปรับปรุงสามารถขยายตัวได้ตามจำนวนผู้เข้าร่วมที่เพิ่มขึ้น การเปลี่ยนแปลงนี้ทำให้การฝึกฝน AI เริ่มมีคุณลักษณะของการวิวัฒนาการด้วยตนเองเหมือนตลาด
2.4 บทบาทในระบบนิเวศของ TAO: ชั้นโครงสร้างพื้นฐานการฝึกอบรม AI
ในระบบเครือข่ายย่อยของ Bittensor เครือข่ายย่อยต่างๆ รับผิดชอบหน้าที่ที่แตกต่างกัน เช่น การให้เหตุผล การประมวลผลข้อมูล และการฝึกอบรม โดย Gradients อยู่ในชั้นการฝึกอบรม มันรับผิดชอบในการแปลงพลังการประมวลผลที่กระจายตัวให้กลายเป็นผลลัพธ์แบบโมเดลจริง ผ่านกลไกการแจกจ่ายงานและการประเมินผล เพื่อให้ทรัพยากรเหล่านี้สามารถถูกจัดสรรและปรับปรุงอย่างต่อเนื่อง พร้อมกันนี้ มันยังเชื่อมโยงระหว่างอุปทานพลังการประมวลผลกับความต้องการโมเดล ทำให้กระบวนการฝึกอบรมเปลี่ยนจากกระบวนการใช้ทรัพยากรเพียงอย่างเดียว ให้กลายเป็นกระบวนการร่วมมือกันแบบเครือข่ายที่สามารถจัดระเบียบและปรับปรุงได้ ในระบบนี้ Gradients ทำหน้าที่เหมือนจุดเชื่อมกลาง แปลงทรัพยากรแบบกระจายให้กลายเป็นความสามารถด้าน AI ที่ใช้งานได้ และสนับสนุนการพัฒนาของแอปพลิเคชันระดับบน
3. โครงสร้างหลัก: การฝึกฝน AI ทำได้อย่างไรในเครือข่าย
ในบทก่อนหน้า เราได้กล่าวถึงว่า Gradients เปลี่ยนการฝึกอบรม AI จาก “การดำเนินการภายในแพลตฟอร์ม” เป็น “การร่วมมือกันผ่านเครือข่าย” แล้วเครือข่ายนี้ทำงานอย่างไรอย่างแท้จริง? หัวใจหลักของบทนี้คือการแยกกระบวนการนี้ออกให้ชัดเจนและเข้าใจง่ายยิ่งขึ้น
3.1 การฝึกแบบกระจาย: งานหนึ่งงานจะถูก “ทำร่วมกันโดยหลายคน” ได้อย่างไร
คุณสามารถนึกภาพ Gradients ว่าเป็นเครือข่ายการร่วมมือในการฝึกอบรมที่ทำงานต่อเนื่อง เมื่อผู้ใช้ส่งงานฝึกอบรม งานนั้นจะไม่ถูกมอบหมายให้ระบบใดระบบหนึ่งดำเนินการเพียงระบบเดียว แต่จะถูกส่งไปยังผู้เข้าร่วมหลายรายในเครือข่ายพร้อมกัน ผู้เข้าร่วมเหล่านี้จะใช้ข้อมูลและเป้าหมายเดียวกัน แต่ทดลองวิธีการฝึกอบรมที่ต่างกัน และส่งผลลัพธ์ภายในเวลาที่กำหนด จากนั้นระบบจะประเมินผลลัพธ์เหล่านี้อย่างเป็นระบบ เพื่อคัดเลือกวิธีที่มีประสิทธิภาพดีที่สุด สุดท้าย ผลลัพธ์ที่ดีกว่าจะได้รับรางวัล ในขณะที่วิธีอื่นๆ จะถูกตัดออก จากมุมมองของผู้ใช้ กระบวนการนี้ต้องการเพียงการส่งงานเพียงครั้งเดียว ซึ่งเทียบเท่ากับการ “เรียกใช้” แนวทางการปรับปรุงหลายแบบพร้อมกัน และเลือกคำตอบที่ดีที่สุดโดยอัตโนมัติ จุดสำคัญของวิธีนี้ไม่ได้อยู่ที่ความแข็งแกร่งของแต่ละโหนด แต่อยู่ที่การทดลองแบบขนานโดยหลายฝ่าย + การคัดเลือกอัตโนมัติ เพื่อให้ผลลัพธ์เข้าใกล้ค่าที่ดีที่สุดอย่างต่อเนื่อง
ในเครือข่ายนี้ มีผู้เข้าร่วมหลักสามประเภท ได้แก่ ผู้ใช้ ผู้ขุด และผู้ตรวจสอบ ผู้ใช้รับผิดชอบในการเสนอความต้องการการฝึกอบรม ผู้ขุดจัดหาพลังการประมวลผลและทดลองวิธีการฝึกอบรมต่างๆ ส่วนผู้ตรวจสอบรับผิดชอบในการประเมินผลและคัดเลือกโมเดลที่ดีที่สุด การแบ่งหน้าที่นี้ทำให้กระบวนการฝึกอบรมสามารถดำเนินต่อไปได้อย่างต่อเนื่องและคัดเลือกโซลูชันที่ดีขึ้นเรื่อยๆ โดยรวมแล้ว มันสร้างเครือข่ายความร่วมมือที่ขับเคลื่อนโดย “ความต้องการ อุปทาน และการประเมิน”
3.2 AutoML ที่ขับเคลื่อนโดยตลาด
จากโครงสร้างกลไกที่อธิบายไว้ก่อนหน้านี้ สามารถเห็นได้ว่า Gradients ไม่ได้เป็นเพียงการนำ AutoML มาใช้งานบนบล็อกเชนอย่างง่ายๆ แต่เปลี่ยนตรรกะพื้นฐานของการปรับปรุงโมเดลโดยการแนะนำการมีส่วนร่วมจากหลายฝ่ายและกลไกการให้รางวัล ระบบ AutoML แบบดั้งเดิมพึ่งพาเพียงระบบเดียวในการค้นหาคำตอบที่ดีที่สุดในเส้นทางที่จำกัด ในขณะที่ Gradients ขยายกระบวนการนี้ไปยังเครือข่ายทั้งหมด: ผู้เข้าร่วมต่างๆ ทดลองวิธีการต่างๆ อย่างต่อเนื่องสำหรับงานเดียวกัน และกรองและปรับปรุงอย่างต่อเนื่องผ่านการประเมินแบบเดียวกัน สิ่งนี้ทำให้การปรับปรุงโมเดลไม่ใช่กระบวนการคำนวณแบบครั้งเดียว แต่เป็นกระบวนการเชิงพลวัตที่สามารถพัฒนาซ้ำได้ ในกลไกนี้ ผลลัพธ์ที่มีประสิทธิภาพดีกว่าจะได้รับผลตอบแทนสูงกว่า ซึ่งดึงดูดผู้เข้าร่วมให้ปรับปรุงกลยุทธ์อย่างต่อเนื่อง และผลักดันให้ประสิทธิภาพโดยรวมดีขึ้นเรื่อยๆ
4. กลไกการกระตุ้นและการแข่งขัน: การฝึกฝน AI สร้างวัฏจักรเชิงบวกได้อย่างไร
4.1 กลไกการให้รางวัล (ขับเคลื่อนด้วย TAO): จากพฤติกรรมการฝึกอบรมไปสู่ผลตอบแทน
กุญแจสำคัญที่ทำให้ Gradients สามารถทำงานได้อย่างยั่งยืนคือกลไกการให้รางวัลที่อยู่เบื้องหลัง ซึ่งอิงตามระบบการให้รางวัลแบบดั้งเดิมของ Bittensor โดย TAO เป็นโทเค็นพื้นฐานของเครือข่าย Bittensor และทำหน้าที่เป็น “ตัวกลางของค่า” ภายในเครือข่าย: 一方面ใช้เพื่อให้รางวัลแก่ผู้เข้าร่วมที่ให้พลังการประมวลผลและมีส่วนร่วมในการพัฒนาโมเดล อีก方面หนึ่งยังมีส่วนร่วมในการจัดสรรน้ำหนักของซับเน็ตผ่านการstaking ฯลฯ ซึ่งส่งผลต่อการไหลเวียนของทรัพยากรระหว่างซับเน็ตต่างๆ
บิตเทนเซอร์เน็ตเวิร์กจะสร้างการจ่ายรางวัลใหม่อย่างต่อเนื่องในรูปของ TAO (ปัจจุบันปริมาณที่เหมาะสมต่อวันอยู่ที่ประมาณ 3,600 TAO) และแจกจ่ายตามกฎเกณฑ์ที่กำหนดให้กับเครือข่ายย่อยต่างๆ จำนวน TAO ที่แต่ละเครือข่ายย่อยได้รับขึ้นอยู่กับ “ประสิทธิภาพ” ของเครือข่ายนั้นในระบบโดยรวม เช่น ระดับความกระตือรือร้น คุณภาพของผลงานที่สร้างขึ้น และสถานะการสนับสนุนทางการเงิน เป็นต้น สำหรับเครือข่ายย่อยที่ Gradients อยู่ จำนวน TAO ที่ได้รับจะถูกแจกจ่ายอีกครั้งภายในเครือข่ายให้กับผู้เข้าร่วม โดยเกณฑ์หลักคือผู้ที่สร้างโมเดลที่ดีกว่าจะได้รับผลตอบแทนมากกว่า
โดยรายละเอียด ผู้ขุดจะส่งผลลัพธ์การฝึกอบรม ผู้ตรวจสอบจะรับผิดชอบทดสอบและให้คะแนนผลลัพธ์เหล่านี้ ระบบจะคำนวณ “น้ำหนักการมีส่วนร่วม” ของผู้เข้าร่วมแต่ละรายตามคะแนนที่ได้รับ แล้วแจกจ่ายรางวัลตามน้ำหนักนี้ โมเดลที่แสดงผลงานดีกว่า (เช่น มีความสามารถทั่วไปสูงกว่าและผลลัพธ์เสถียรกว่า) จะได้รับผลตอบแทนสูงกว่า ในขณะเดียวกัน ผู้ตรวจสอบที่ให้คะแนนแม่นยำยิ่งขึ้นและสะท้อนคุณภาพที่แท้จริงได้ดีกว่า ก็จะได้รับแรงจูงใจเพิ่มเติม การออกแบบนี้ทำให้ “ทำได้ดีขึ้น” สอดคล้องโดยตรงกับ “หารายได้มากขึ้น” ซึ่งผลักดันให้ผู้เข้าร่วมปรับปรุงโมเดลอย่างต่อเนื่อง
4.2 การแข่งขันระหว่างซับเน็ต: ไม่ใช่แค่การแข่งขันภายใน แต่ยังรวมถึงการจัดอันดับภายนอก
นอกเหนือจากการแข่งขันภายในเครือข่ายย่อยแล้ว Gradients ยังต้องเผชิญกับการแข่งขันแบบแนวนอนภายในเครือข่าย Bittensor ทั้งหมด เนื่องจากการแจกจ่าย TAO เป็นแบบไดนามิก เครือข่ายย่อยต่างๆ จึงแข่งขันกันเพื่อให้ได้คะแนนน้ำหนักที่สูงกว่า เฉพาะเครือข่ายย่อยที่สามารถผลิตผลลัพธ์คุณภาพสูงอย่างต่อเนื่องและดึงดูดผู้เข้าร่วมจำนวนมากเท่านั้นจึงจะได้รับส่วนแบ่งรางวัลที่ใหญ่กว่า ดังนั้นแรงจูงใจของ Gradients ไม่ได้ขึ้นอยู่กับประสิทธิภาพของโมเดลภายในเท่านั้น แต่ยังขึ้นอยู่กับความสามารถในการแข่งขันเมื่อเทียบกับระบบนิเวศโดยรวม ระบบทั้งหมดจึงสร้างกลไกวงจรหลายชั้น: มีการแข่งขันระหว่างโมเดลภายในเครือข่ายย่อย และมีการแข่งขันด้านประสิทธิภาพโดยรวมระหว่างเครือข่ายย่อยต่างๆ สุดท้ายแล้ว การลงทุนด้านกำลังการประมวลผล ประสิทธิภาพของโมเดล และผลตอบแทนทางเศรษฐกิจถูกผูกไว้ด้วยกัน สร้างกลไกป้อนกลับในเชิงบวกที่หมุนเวียนอย่างต่อเนื่อง
4.3 กราเดียนต์ 5.0: จากการแข่งขันสู่ "กลไกการแข่งขัน"
บนพื้นฐานของการแข่งขันอย่างต่อเนื่องในระยะเริ่มต้น Gradients ได้พัฒนาเป็นกลไกที่มีโครงสร้างชัดเจนยิ่งขึ้น ซึ่งเรียกว่า “การฝึกอบรมแบบการแข่งขัน” สามารถเข้าใจได้ว่าเป็นการแข่งขันแบบเป็นช่วงๆ: ในแต่ละรอบการฝึกอบรมจะมีช่วงเวลาที่กำหนด ผู้เข้าร่วมหลายคนจะแข่งขันกันบนงานเดียวกัน และผ่านกระบวนการคัดออกหลายรอบ เพื่อคัดเลือกแนวทางที่ดีที่สุด รูปแบบนี้เน้นการเปรียบเทียบตามระยะและประเมินอย่างเข้มข้น การเปลี่ยนแปลงสำคัญอย่างหนึ่งคือ ผู้ขุดไม่ได้ส่งผลลัพธ์การฝึกอบรมโดยตรงอีกต่อไป แต่จะส่ง “วิธีการฝึกอบรม” (โค้ด) แทน โดยโหนดตรวจสอบจะดำเนินการร่วมกัน วิธีนี้ไม่เพียงแต่เพิ่มความเป็นธรรม โดยลดผลกระทบจากสภาพแวดล้อมการคำนวณที่แตกต่างกัน แต่ยังช่วยปกป้องความเป็นส่วนตัวของข้อมูลและกระบวนการฝึกอบรมได้ดียิ่งขึ้น นอกจากนี้ แนวทางที่ชนะมักจะถูกเก็บรักษาไว้เป็นวิธีการที่สามารถนำกลับมาใช้ใหม่ได้ เหมือนกับการสะสม “แนวทางปฏิบัติที่ดีที่สุด” อย่างต่อเนื่อง ในระยะยาว กลไกนี้ไม่เพียงแต่คัดเลือกรุ่นที่ดีที่สุด แต่ยังสร้างคลังวิธีการฝึกอบรมที่พัฒนาอย่างต่อเนื่อง
5. สถานะของระบบนิเวศ
5.1 โครงสร้างผู้เข้าร่วม: เครือข่ายร่วมมือที่ประกอบด้วยความต้องการ อุปทาน และการประเมิน
ระบบนิเวศของ Gradients ประกอบด้วยบทบาทหลักสามประเภท: ผู้ใช้ (ด้านความต้องการ) ผู้ขุด (ด้านอุปทาน) และผู้ตรวจสอบ (ด้านการประเมิน) ผู้ใช้ส่วนใหญ่ประกอบด้วยนักพัฒนา AI องค์กรขนาดเล็กและกลาง และผู้สร้าง Web3 กลุ่มนี้มักมีพื้นฐานทางเทคนิคบางประการ แต่ขาดพลังการประมวลผลหรือความสามารถในการฝึกโมเดลอย่างสมบูรณ์ จึงมีแนวโน้มที่จะใช้ Gradients เพื่อสร้างโมเดลด้วยต้นทุนต่ำกว่า ผู้ขุดให้พลังการประมวลผล GPU และเข้าร่วมการแข่งขันภารกิจการฝึกอบรม โดยแรงจูงใจหลักคือการรับผลตอบแทน TAO ส่วนผู้ตรวจสอบมีหน้าที่ประเมินและจัดอันดับผลลัพธ์การฝึกอบรม ซึ่งเป็นปัจจัยสำคัญในการรับประกันคุณภาพของโมเดลและการทำงานของกลไกอย่างมีประสิทธิภาพ
จากภาพผู้ใช้ที่ละเอียดยิ่งขึ้น กลุ่มผู้ใช้จริงของ Gradients มีลักษณะ “กึ่งนักพัฒนา” อย่างชัดเจน: ไม่เหมือนห้องปฏิบัติการ AI ระดับสูงสุด แต่ก็ไม่ใช่ผู้ใช้ทั่วไปที่ไม่มีพื้นฐานทางเทคนิค แต่เป็นนักพัฒนาและผู้ใช้เทคโนโลยี Web3 ที่มีความสามารถด้านวิศวกรรมบางประการ จุดนี้ยังสะท้อนให้เห็นในโครงสร้างชุมชนของมัน โดยระบบนิเวศปัจจุบันมีภาษาอังกฤษเป็นหลัก ผู้ใช้หลักกระจุกตัวอยู่ในกลุ่มนักพัฒนาของอเมริกาเหนือและยุโรป พร้อมครอบคลุมช่างขุดบางส่วนในเอเชียตะวันออกเฉียงใต้และผู้ให้ทรัพยากร GPU ทั่วโลก โดยรวมแล้วใกล้เคียงกับชุมชนนักพัฒนาที่ขับเคลื่อนด้วยเทคโนโลยี
5.2 สถานะการดำเนินงานของระบบนิเวศ
ณ วันที่ 12 พฤษภาคม ราคาโทเค็น alpha ของ Gradients อยู่ที่ประมาณ 0.0255 TAO มีที่อยู่ผู้ถือโทเค็นประมาณ 4,890 แห่ง ผู้ขุด 243 คน และผู้ตรวจสอบ 12 คน โดยสัดส่วนการปล่อยโทเค็นอยู่ที่ 1.61% ในขณะเดียวกัน สัดส่วนของ TAO ในสระสภาพคล่องอยู่ที่ 2.19% และสัดส่วนของ Alpha อยู่ที่ 97.81% จากราคาและจำนวนที่อยู่ผู้ถือ ดูเหมือน Gradients จะมีฐานผู้ใช้และความสนใจในระดับหนึ่ง แต่โดยรวมยังอยู่ในระยะเริ่มต้นของการแพร่กระจาย เมื่อเปรียบเทียบกับโครงการชั้นนำในระบบนิเวศ TAO อย่าง Chutes ราคาโทเค็น alpha ในวันเดียวกันอยู่ที่ 0.0877 TAO และมีที่อยู่ผู้ถือโทเค็น 13,409 แห่ง
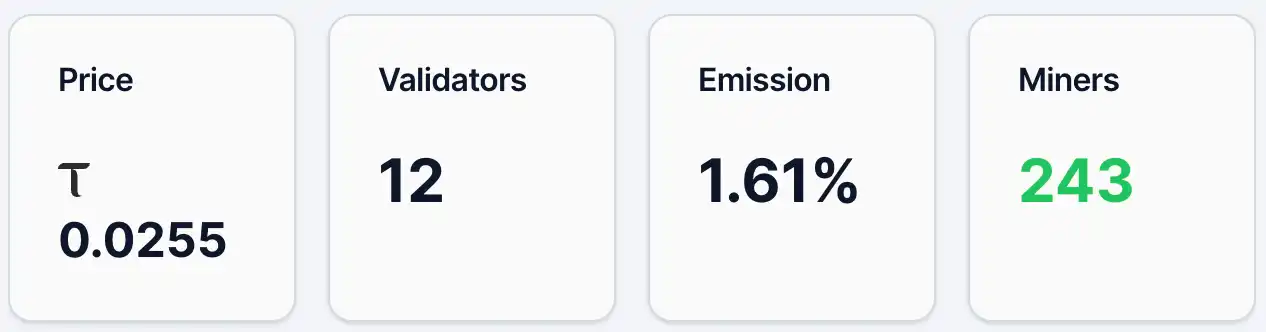
รูปที่ 1. ข้อมูลกราเดียนต์
ที่มา:https://bittensormarketcap.com/subnets/56
ถัดมาคือกลไกการกระตุ้นการปล่อยออก (Emission) ในระบบ Bittensor Emission หมายถึงน้ำหนักการจัดสรรแบบเรียลไทม์ของเครือข่ายย่อยต่างๆ จากรางวัลใหม่ทั้งหมดของเครือข่าย Bittensor จะสร้าง TAO ใหม่อย่างต่อเนื่องและแจกจ่ายให้กับเครือข่ายย่อยต่างๆ ตามน้ำหนัก ขณะนี้ Gradients มีสัดส่วน 1.61% ซึ่งหมายความว่ามันได้รับส่วนแบ่งเพียงเล็กน้อยจากรางวัลใหม่ทั้งหมดของเครือข่าย ตัวชี้วัดนี้สะท้อนพื้นฐานว่าตลาดกำลัง “ลงคะแนนเสียง” ผ่านการไหลเวียนของทุน (เช่น การ staking) สำหรับเครือข่ายย่อยต่างๆ ดังนั้นระดับ 1.61% มักบ่งชี้ว่าการรับรู้ของตลาดและการไหลเข้าของทุนในปัจจุบันยังค่อนข้างจำกัด ในทางกลับกัน ก็หมายความว่ายังมีพื้นที่สำหรับการเพิ่มขึ้นของน้ำหนักในอนาคต จากมุมมองโครงสร้างทุน (สระสภาพคล่อง) สัดส่วนของ TAO มีเพียง 2.19% ในขณะที่ Alpha สูงถึง 97.81% แสดงว่าการไหลเข้าของทุนจากภายนอกยังคงจำกัด และปัจจุบันมีอุปทานภายในเครือข่ายย่อยเป็นหลัก ราคาจะตอบสนองต่อทุนใหม่ที่ไหลเข้าอย่างไว หากมี TAO เพิ่มเติมไหลเข้ามา อาจเกิดผลกระทบแบบขยายตัวอย่างชัดเจนยิ่งขึ้น
6. โครงสร้างการแข่งขันและข้อได้เปรียบ/ข้อเสียเปรียบ
6.1 การกำหนดตำแหน่งอุตสาหกรรม: โครงสร้างพื้นฐานการฝึกอบรม AutoML แบบกระจายศูนย์
Gradients 专注于“AI 训练基础设施 + 去中心化 AutoML”这一细分领域。它旨在将模型训练从中心化平台中解放出来,并通过网络化机制实现更高效的资源利用与模型优化。在 Web2 体系中,这一领域已相对成熟,典型代表包括 Google Vertex AI 和 AWS SageMaker。这些平台通过云计算为开发者提供一站式模型训练与部署服务,但其本质仍是中心化架构。相比之下,Gradients 的差异不在于“功能更多”,而在于底层逻辑不同:它将训练从“平台服务”转变为“网络协作”,并通过竞争机制筛选最优结果,使其更接近一个市场化运作的训练系统。
6.2 การเปรียบเทียบในแนวนอน: ความแตกต่างระหว่าง Web2 กับ Web3 AutoML
ในมุมมองที่กว้างกว่า ความแตกต่างระหว่าง Web2 และ Web3 ในทิศทางของ AutoML 本质上คือการเปรียบเทียบระหว่างสองรูปแบบที่ต่างกัน โดยรูปแบบ Web2 มุ่งเน้นที่ประสิทธิภาพและความเสถียร ผ่านการรวมทรัพยากรและการปรับปรุงด้านวิศวกรรม เพื่อให้บริการที่ควบคุมได้และมีความเป็นผู้เชี่ยวชาญ ในขณะที่รูปแบบ Web3 มุ่งเน้นที่ความเปิดกว้างและกลไกการให้รางวัล โดยการนำผู้มีส่วนร่วมหลายฝ่ายเข้ามา ทำให้การปรับปรุงโมเดลพัฒนาต่อเนื่องผ่านการแข่งขัน โดยเฉพาะอย่างยิ่ง AutoML แบบ Web2 คล้ายกับ “เครื่องมือที่ทรงพลัง” ผู้ใช้ส่งงานให้แพลตฟอร์ม และระบบจะค้นหาคำตอบที่ดีที่สุดภายในตัวเอง ขณะที่ AutoML แบบ Web3 ที่มี Gradients เป็นตัวแทน คล้ายกับ “ตลาดเปิด” ผู้ใช้ประกาศความต้องการ และผู้เข้าร่วมต่างๆ นำเสนอวิธีแก้ปัญหา จากนั้นจึงคัดเลือกผลลัพธ์ผ่านกลไกการประเมิน ความแตกต่างนี้ส่งผลโดยตรงต่อ: รูปแบบแรกมีความเสถียรและควบคุมได้ดี แต่มีขอบเขตการปรับปรุงที่จำกัด ในขณะที่รูปแบบหลังมีพื้นที่ในการสำรวจมากกว่าและมีศักยภาพสูงกว่า แต่ยังมีช่องว่างในการปรับปรุงด้านความเสถียรและความเป็นผู้เชี่ยวชาญ
6.3 ความแตกต่างของ Gradients ใน Web3
ในสนาม Web3 AI ปัจจุบัน โครงการส่วนใหญ่ยังคงมุ่งเน้นที่ชั้นการให้เหตุผลหรือ AI Agent ขณะที่โครงการที่เน้นไปที่ “โครงสร้างพื้นฐานการฝึกอบรม” มีจำนวนน้อยกว่า บางโครงการพยายามผสานเครือข่ายการประมวลผลหรือเครือข่ายข้อมูลเพื่อให้ความสามารถในการฝึกอบรม แต่โดยรวมแล้ว ส่วนใหญ่ยังคงอยู่ในระดับการจัดสรรทรัพยากรหรือตลาดการประมวลผล ความแตกต่างของ Gradients อยู่ที่มันไม่ได้แค่จับคู่ทรัพยากรการประมวลผลเท่านั้น แต่ยังขยายไปสู่ “กลไกการปรับปรุงโมเดล” โดยตรง ผ่านการนำระบบการประเมินและการแข่งขันมาใช้ เพื่อให้กระบวนการฝึกอบรมมีความสามารถในการพัฒนาอย่างต่อเนื่อง นั่นหมายความว่า มันไม่เพียงแต่แก้ปัญหา “แหล่งที่มาของทรัพยากรการประมวลผล” แต่ยังแก้ปัญหา “วิธีใช้ทรัพยากรเหล่านี้ให้มีประสิทธิภาพมากขึ้น” ในแง่ของการกำหนดตำแหน่ง Gradients จึงใกล้เคียงกับเครือข่ายที่มุ่งเน้นผลลัพธ์ของการฝึกอบรม มากกว่าแค่ตลาดทรัพยากรการประมวลผลหรือแพลตฟอร์มเครื่องมือ ซึ่งเป็นจุดแตกต่างหลักจากโครงการ Web3 AI ส่วนใหญ่
6.4 ข้อได้เปรียบหลัก: การเพิ่มประสิทธิภาพที่ขับเคลื่อนด้วยกลไก
โดยรวมแล้ว ข้อได้เปรียบของ Gradients ส่วนใหญ่แสดงให้เห็นผ่านการออกแบบกลไกของมัน ก่อนอื่น มันลดอุปสรรคในการใช้งานผ่านการจัด abstraction ของงาน ทำให้ผู้ใช้สามารถได้รับผลลัพธ์ของโมเดลโดยไม่จำเป็นต้องมีส่วนร่วมอย่างลึกซึ้งในกระบวนการฝึกอบรมที่ซับซ้อน ซึ่งช่วยขยายกลุ่มผู้ใช้ที่อาจใช้งานได้ ที่สอง ในด้านทรัพยากร การนำระบบการประมวลผลแบบกระจายมาใช้ ทำให้การฝึกอบรมไม่ต้องพึ่งพาผู้ให้บริการคลาวด์รายเดียว และในทางทฤษฎีสามารถสร้างโครงสร้างต้นทุนที่ยืดหยุ่นมากขึ้นผ่านการแข่งขัน ที่สำคัญยิ่งกว่านั้นคือการเปลี่ยนแปลงวิธีการปรับปรุง โดยการให้ผู้เข้าร่วมหลายคนสำรวจแบบขนานกันพร้อมกับกลไกการคัดกรอง Gradients นำเสนอทางเลือกที่ต่างจากแนวทางการปรับปรุงแบบเส้นทางเดียวแบบดั้งเดิม ทำให้โมเดลมีโอกาสบรรลุประสิทธิภาพที่ดีกว่าในระยะเวลาที่สั้นกว่า รูปแบบการปรับปรุงที่ขับเคลื่อนด้วยการแข่งขันนี้ คือข้อได้เปรียบหลักที่สุดของมัน
6.5 ความท้าทายที่อาจเกิดขึ้น
คุณภาพของโมเดลอาจมีปัญหาด้านความเสถียร การฝึกแบบกระจายศูนย์ขึ้นอยู่กับการมีส่วนร่วมจากหลายฝ่าย แม้จะสามารถเพิ่มขีดจำกัดสูงสุดได้ แต่ก็อาจก่อให้เกิดความผันผวนของผลลัพธ์ เมื่อเทียบกับระบบแบบศูนย์กลาง จึงมีความไม่แน่นอนในด้านการควบคุม ต่อมาคือปัญหาความเชื่อมั่นระดับองค์กร สำหรับผู้ใช้งานองค์กร ความปลอดภัยของข้อมูลและความสามารถในการตรวจสอบกระบวนการฝึกอบรมมีความสำคัญอย่างยิ่ง แต่ในสภาพแวดล้อมแบบกระจายศูนย์ การรับประกันว่าข้อมูลจะไม่ถูกใช้ในทางที่ผิดและผลลัพธ์สามารถตรวจสอบได้ยังคงเป็นการทดสอบที่สำคัญ สุดท้ายคือการพึ่งพาเศรษฐกิจโทเค็น การทำงานของ Gradients ขึ้นอยู่กับกลไกการให้รางวัลอย่างมาก หากผลตอบแทนจาก TAO ลดลง อาจส่งผลต่อระดับการมีส่วนร่วมของผู้ขุดและความกระตือรือร้นของเครือข่ายโดยรวม ดังนั้น ความยั่งยืนในระยะยาวของมันจึงขึ้นอยู่กับว่าแบบจำลองทางเศรษฐกิจสามารถสร้างวัฏจักรเชิงบวกที่มั่นคงได้หรือไม่
7. ทัศนคติในอนาคต: AutoML แบบกระจายศูนย์สามารถเกิดขึ้นได้หรือไม่?
ในขั้นตอนปัจจุบัน Gradients ยังอยู่ในระยะเริ่มต้น และอนาคตของมันจะประสบความสำเร็จจริงหรือไม่นั้น ขึ้นอยู่กับปัจจัยสำคัญบางประการ จุดสำคัญที่สุดคือ能否ดึงดูดความต้องการฝึกอบรมที่แท้จริงอย่างต่อเนื่อง ไม่ใช่แค่การมีส่วนร่วมที่ขับเคลื่อนด้วยแรงจูงใจ; ต่อมาคือคุณภาพของโมเดล ว่ารูปแบบแบบกระจายศูนย์สามารถผลิตผลลัพธ์ที่ใช้งานได้ หรือแม้แต่ดีกว่าอย่างมั่นคงได้หรือไม่; และกลไกทางเศรษฐกิจสามารถสร้างวัฏจักรเชิงบวกได้หรือไม่ เพื่อให้การจัดหาหน่วยประมวลผลและผลตอบแทนคงสมดุลในระยะยาว
ในบริบทของอุตสาหกรรมที่กว้างขึ้น การฝึกอบรม AI กำลังแยกออกเป็นสองเส้นทาง ทางแรกคือรูปแบบ Web2 ที่ถูกนำโดยบริษัทเทคโนโลยีชั้นนำ ซึ่งใช้ทรัพยากรและความสามารถด้านวิศวกรรมแบบรวมศูนย์เพื่อเสริมสร้างประสิทธิภาพของโมเดลอย่างต่อเนื่อง ข้อได้เปรียบอยู่ที่ความมั่นคงและสุกงอม ทางที่สองคือเส้นทาง Web3 ที่มี Gradients เป็นตัวแทน ซึ่งใช้เครือข่ายเปิดและการกระตุ้นแรงจูงใจให้ผู้เข้าร่วมจำนวนมากช่วยกันปรับปรุงโมเดล และเพิ่มขีดจำกัดสูงสุดอย่างต่อเนื่องผ่านการแข่งขัน ทางแรกคือการ “สร้างระบบที่แข็งแกร่งขึ้น” ในขณะที่ทางหลังดูเหมือนการ “สร้างเครือข่ายที่สามารถพัฒนาตัวเองได้”
ในมุมมองนี้ การสำรวจของ Gradients แสดงถึงความเป็นไปได้ใหม่: การฝึกฝน AI ไม่ใช่เพียงปัญหาทางเทคนิค แต่เป็นการรวมกันของ “พลังการคำนวณ + ข้อมูล + cơ chếตลาด” หากโมเดลนี้สามารถใช้งานได้ มันมีศักยภาพที่จะกลายเป็นช่องทางการฝึกฝน AI แบบกระจายศูนย์ และทำหน้าที่เป็นโครงสร้างพื้นฐานหลักในระบบนิเวศ Bittensor แน่นอนว่าทิศทางนี้ยังต้องใช้เวลาในการพิสูจน์ แต่มันได้เปิดทางวิวัฒนาการใหม่ให้กับ AutoML ที่ต่างจากเส้นทางดั้งเดิม
การอ้างอิง
1. เอกสาร Bittensor:https://docs.learnbittensor.org
2. เว็บไซต์ Gradients:https://www.gradients.io/
3. เกรเดียนต์:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart