









ผู้เขียน: ชินเชียว TechFlow
บทความของกูเกิลที่อ้างว่า “ลดการใช้หน่วยความจำของ AI ลงเหลือ 1/6” เมื่อสัปดาห์ที่แล้วทำให้หุ้นชิปจัดเก็บข้อมูลทั่วโลก เช่น Micron และ SanDisk สูญเสียมูลค่าตลาดเกิน 90,000 ล้านดอลลาร์สหรัฐ
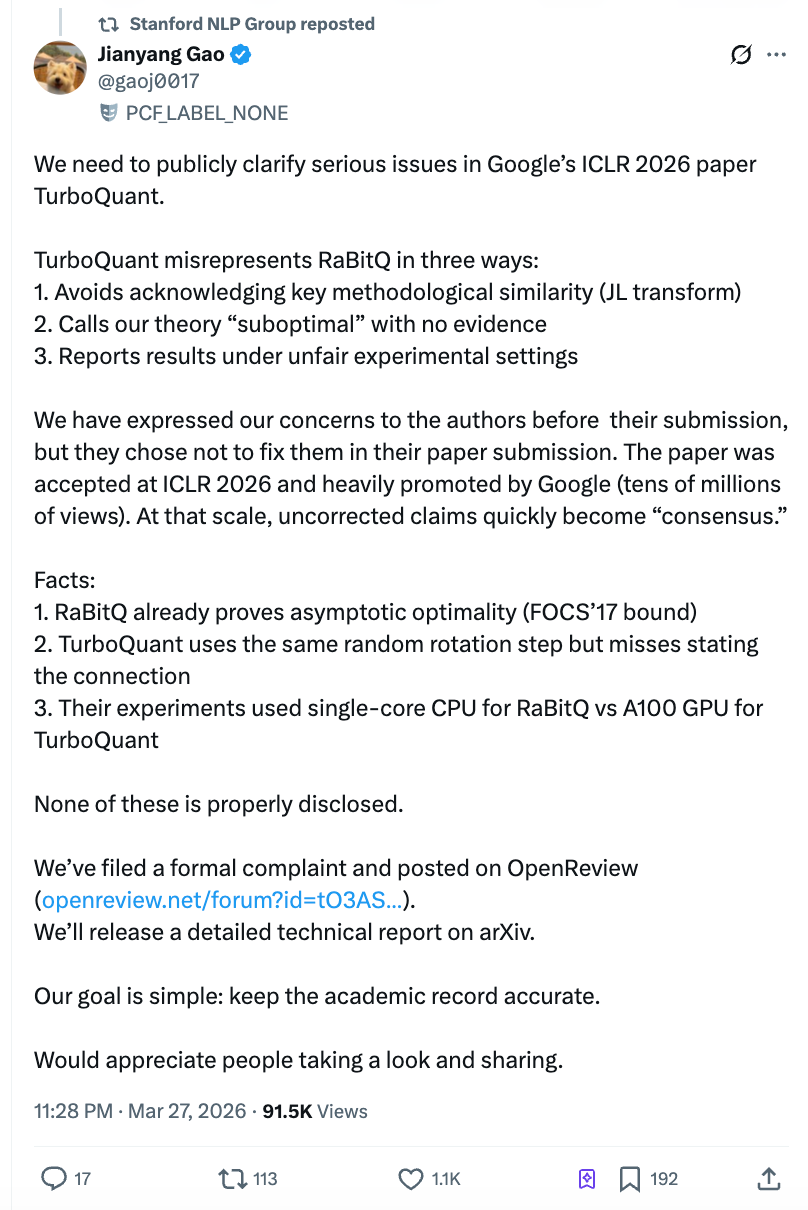
อย่างไรก็ตาม เพียงสองวันหลังจากเผยแพร่เอกสารวิจัย ผู้วิจัยที่ถูกอัลกอริทึมของ “อัลกอริทึม” กล่าวว่าเป็นผู้แพ้—เกาเจียนหยาง นักวิจัยหลังปริญญาเอกจากสถาบันเทคโนโลยีแห่งรัฐซูริก—ได้เผยแพร่จดหมายเปิดผนึกยาวกว่า 10,000 คำ กล่าวหาว่าทีมของกูเกิลทดสอบคู่แข่งด้วยสคริปต์ Python บน CPU เดี่ยว แต่ใช้ GPU A100 ในการทดสอบตัวเอง และยังคงปฏิเสธการแก้ไขแม้จะได้รับการแจ้งเตือนเกี่ยวกับปัญหานี้ก่อนส่งบทความ ปริมาณการอ่านบน Zhihu ทะลุ 4 ล้านครั้งอย่างรวดเร็ว บัญชีทางการของ Stanford NLP ได้แชร์โพสต์นี้ และทั้งชุมชนวิชาการและตลาดต่างตกตะลึง
(อ่านเพิ่มเติม: บทความวิจัยที่ทำให้หุ้นการจัดเก็บตกต่ำ)
ประเด็นหลักของข้อพิพาทนี้ไม่ซับซ้อน: วิจัยฉบับหนึ่งที่谷歌อย่างเป็นทางการส่งเสริมอย่างกว้างขวาง และทำให้เกิดการขายอย่างตื่นตระหนกในภาคชิปทั่วโลก ได้บิดเบือนงานวิจัยก่อนหน้าที่ตีพิมพ์ไปแล้วอย่างเป็นระบบหรือไม่ ผ่านการทดลองที่ออกแบบมาอย่างไม่เป็นธรรมเพื่อสร้างเรื่องเล่าเกี่ยวกับข้อได้เปรียบด้านประสิทธิภาพที่ไม่แท้จริง?
TurboQuant ทำอะไร: ลด "กระดาษร่าง" ของ AI ให้บางลงเหลือเพียงหนึ่งในหกของเดิม
เมื่อโมเดลภาษาขนาดใหญ่สร้างคำตอบ จำเป็นต้องเขียนไปพร้อมกับย้อนกลับไปดูเนื้อหาที่คำนวณไปแล้วก่อนหน้านี้ ผลลัพธ์ชั่วคราวเหล่านี้ถูกเก็บไว้ชั่วคราวในหน่วยความจำ GPU ซึ่งอุตสาหกรรมเรียกว่า “KV Cache” (แคชคีย์-เวลู) ยิ่งการสนทนายาวเท่าใด กระดาษร่างนี้ก็ยิ่งหนาขึ้น ทำให้การใช้งานหน่วยความจำ GPU สูงขึ้นและต้นทุนเพิ่มขึ้น
ทีมวิจัยของกูเกิลพัฒนาอัลกอริทึม TurboQuant ซึ่งจุดขายหลักคือการบีบอัดกระดาษร่างนี้ให้เหลือเพียง 1/6 ของขนาดเดิม โดยอ้างว่าไม่มีการสูญเสียความแม่นยำ และเพิ่มความเร็วในการอนุมานสูงสุดถึง 8 เท่า บทความนี้เผยแพร่ครั้งแรกบนแพลตฟอร์ม preprint ทางวิชาการ arXiv ในเดือนเมษายน 2025 ได้รับการยอมรับโดยการประชุมระดับแนวหน้าด้าน AI ICLR 2026 ในเดือนมกราคม 2026 และได้รับการโปรโมตใหม่โดยบล็อกอย่างเป็นทางการของกูเกิลเมื่อวันที่ 24 มีนาคม
ในเชิงเทคนิค แนวคิดของ TurboQuant สามารถเข้าใจได้อย่างง่ายว่า: ก่อนใช้การแปลงทางคณิตศาสตร์เพื่อทำความสะอาดข้อมูลที่ยุ่งเหยิงให้เป็นรูปแบบเดียวกัน แล้วบีบอัดทีละรายการด้วยตารางการบีบอัดที่คำนวณไว้ล่วงหน้าอย่างเหมาะสม สุดท้ายจึงใช้กลไกแก้ไขข้อผิดพลาด 1 บิตเพื่อแก้ไขความเบี่ยงเบนของการคำนวณที่เกิดจากการบีบอัด ชุมชนได้ดำเนินการพัฒนาอย่างอิสระและยืนยันแล้วว่าผลลัพธ์การบีบอัดนั้นเป็นความจริง และการมีส่วนร่วมทางคณิตศาสตร์ของอัลกอริทึมนี้มีอยู่จริง
ข้อถกเถียงไม่ได้อยู่ที่ว่า TurboQuant ใช้งานได้หรือไม่ แต่อยู่ที่ว่า Google ทำอะไรไปเพื่อพิสูจน์ว่ามัน “เหนือกว่าคู่แข่งอย่างมาก”
จดหมายเปิดของเกาเจี้ยนหยาง: ข้อกล่าวหาสามข้อ แต่ละข้อเจาะจุดสำคัญ
เมื่อวันที่ 27 มีนาคม เวลา 22:00 น. โกว์ เจียนหยางได้เผยแพร่บทความยาวบน Zhihu และส่งความคิดเห็นอย่างเป็นทางการผ่านแพลตฟอร์มรีวิวอย่างเป็นทางการของ ICLR คือ OpenReview โกว์ เจียนหยางเป็นผู้แต่งคนแรกของอัลกอริธึม RaBitQ ซึ่งตีพิมพ์ในปี 2024 ที่การประชุมระดับแนวหน้าด้านฐานข้อมูล SIGMOD และแก้ไขปัญหาประเภทเดียวกัน—การบีบอัดเวกเตอร์มิติสูงอย่างมีประสิทธิภาพ
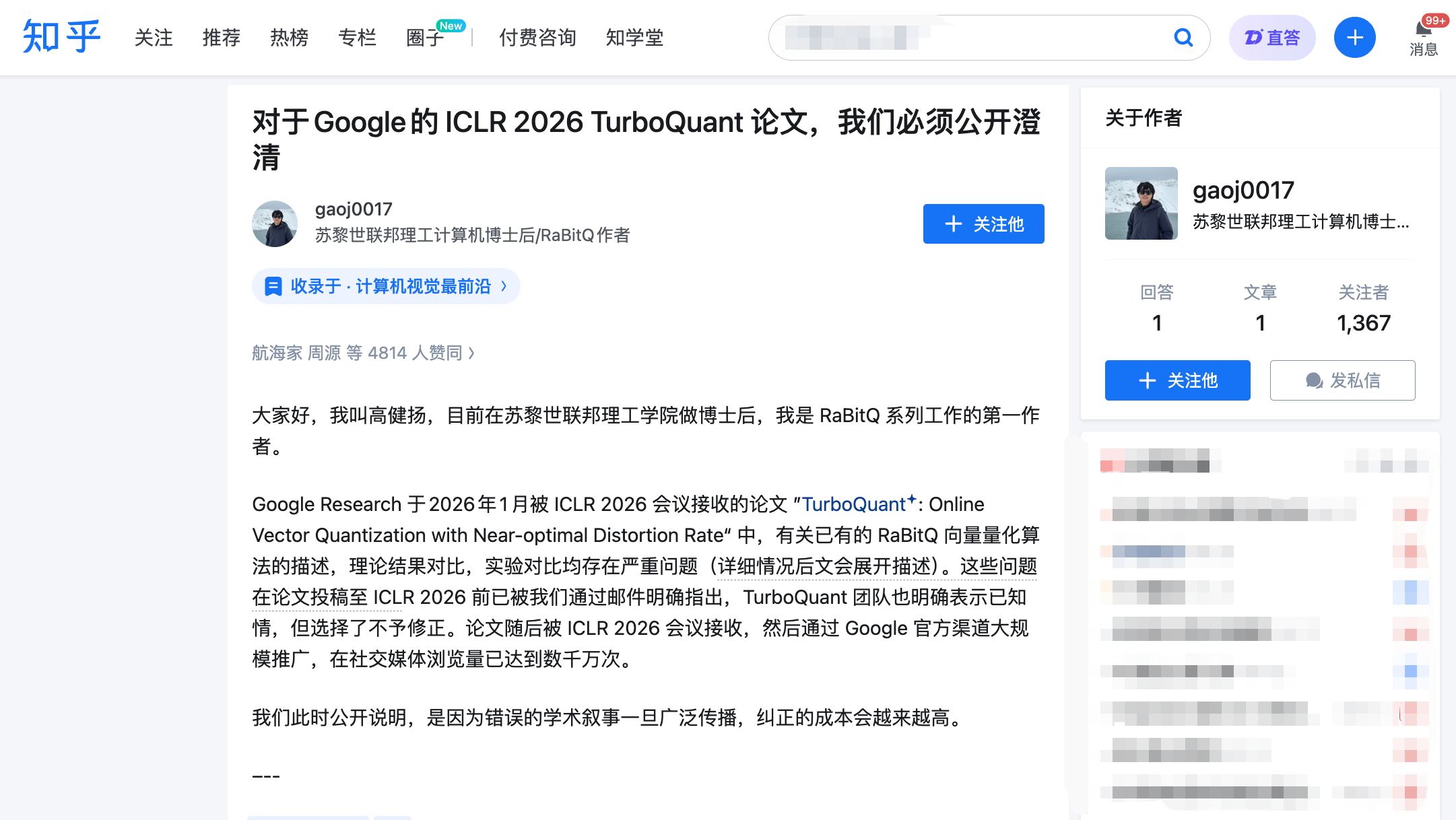
การกล่าวหาของเขาแบ่งเป็นสามข้อ แต่ละข้อมีบันทึกอีเมลและเส้นเวลาสนับสนุน
ข้อกล่าวหาที่หนึ่ง: ใช้วิธีการหลักของผู้อื่น โดยไม่กล่าวถึงในบทความทั้งหมด
ขั้นตอนสำคัญร่วมกันของ TurboQuant และ RaBitQ คือการทำการ "หมุนแบบสุ่ม" บนข้อมูลก่อนที่จะบีบอัดข้อมูล ขั้นตอนนี้มีจุดประสงค์เพื่อเปลี่ยนข้อมูลที่มีการกระจายตัวไม่สม่ำเสมอให้กลายเป็นการกระจายตัวแบบสม่ำเสมอที่สามารถคาดการณ์ได้ ซึ่งช่วยลดความยากในการบีบอัดอย่างมาก นี่คือส่วนที่สำคัญที่สุดและใกล้เคียงกันที่สุดของอัลกอริธึมทั้งสอง
ผู้เขียน TurboQuant ยังยอมรับจุดนี้ในคำตอบการทบทวนของตนเอง แต่ไม่เคยระบุอย่างชัดเจนในบทความเต็มถึงความเกี่ยวข้องของวิธีการนี้กับ RaBitQ บริบทที่สำคัญยิ่งกว่านั้นคือ: ผู้ร่วมเขียนคนที่สองของ TurboQuant คือ Majid Daliri ได้ติดต่อทีม Gao Jianyang โดยสมัครใจในเดือนมกราคม 2025 เพื่อขอความช่วยเหลือในการดีบักเวอร์ชัน Python ที่เขาดัดแปลงจากโค้ดแหล่งที่มาของ RaBitQ อีเมลดังกล่าวอธิบายขั้นตอนการจำลองและข้อผิดพลาดอย่างละเอียด—กล่าวอีกนัยหนึ่ง ทีม TurboQuant มีความเข้าใจอย่างลึกซึ้งเกี่ยวกับรายละเอียดทางเทคนิคของ RaBitQ
ผู้ตรวจทานแบบไม่เปิดเผยตัวตนของ ICLR ยังชี้ให้เห็นอย่างอิสระว่าทั้งสองฝ่ายใช้เทคโนโลยีเดียวกัน และขอให้มีการอภิปรายอย่างเพียงพอ แต่ในเวอร์ชันสุดท้ายของวิจัย ทีม TurboQuant ไม่เพียงแต่ไม่ได้เพิ่มการอภิปราย แต่ยังย้ายคำอธิบายเกี่ยวกับ RaBitQ ซึ่งมีอยู่แล้วไม่สมบูรณ์ จากเนื้อหาหลักไปยังภาคผนวก
ข้อกล่าวหาที่สอง: กล่าวอ้างว่าทฤษฎีของคู่กรณีเป็น “รองสุดท้าย” โดยไม่มีหลักฐาน
เอกสารของ TurboQuant ติดป้ายว่า RaBitQ เป็น “แบบที่ไม่เหมาะสมที่สุดทางทฤษฎี” (suboptimal) โดยอ้างว่าการวิเคราะห์ทางคณิตศาสตร์ของ RaBitQ “ค่อนข้างหยาบ” แต่เกาเจียนหยางชี้ให้เห็นว่า เอกสารฉบับขยายของ RaBitQ ได้พิสูจน์อย่างเข้มงวดแล้วว่าข้อผิดพลาดในการบีบอัดนั้นบรรลุขอบเขตที่ดีที่สุดทางคณิตศาสตร์—ข้อสรุปนี้ได้รับการตีพิมพ์ในงานประชุมชั้นนำด้านวิทยาศาสตร์คอมพิวเตอร์เชิงทฤษฎี
ในเดือนพฤษภาคม 2025 ทีมเกาเจียนหยางเคยอธิบายอย่างละเอียดผ่านอีเมลหลายฉบับเกี่ยวกับความเหมาะสมของทฤษฎี RaBitQ ดาลิรี ผู้ร่วมเขียนคนที่สองของ TurboQuant ยืนยันว่าได้แจ้งให้ผู้ร่วมเขียนทุกคนทราบแล้ว แต่บทความสุดท้ายยังคงใช้ถ้อยคำว่า “รองลงมา” โดยไม่ได้ให้ข้อโต้แย้งใดๆ
ข้อกล่าวหาที่สาม: การเปรียบเทียบการทดลองมี “มือซ้ายผูกคน มือขวาถือมีด”
นี่คือข้อความที่มีผลกระทบมากที่สุดในบทความทั้งหมด โกว์ เจี้ยนหยางชี้ให้เห็นว่า วิจารณ์ของ TurboQuant ในการทดลองเปรียบเทียบความเร็วนั้นได้เพิ่มเงื่อนไขที่ไม่เป็นธรรมสองประการ:
ประการแรก، RaBitQ ให้รหัส C++ ที่ได้รับการปรับปรุง (รองรับการประมวลผลแบบหลายเธรดโดยค่าเริ่มต้น) แต่ทีม TurboQuant ไม่ได้ใช้ กลับใช้เวอร์ชัน Python ที่แปลเองมาทดสอบ RaBitQ ประการที่สอง,在ทดสอบ RaBitQ นั้นใช้ CPU เดียวและปิดการประมวลผลแบบหลายเธรด ในขณะที่ TurboQuant ใช้ GPU NVIDIA A100
ผลของการรวมเงื่อนไขทั้งสองนี้คือ ผู้อ่านจะสรุปว่า “RaBitQ ช้ากว่า TurboQuant หลายระดับความเร็ว” แต่ไม่สามารถรู้ได้ว่าข้อสรุปนี้อิงจากเงื่อนไขที่ทีมกูเกิลผูกมือผูกเท้าคู่แข่งก่อนแข่งวิ่ง ซึ่งบทความไม่ได้เปิดเผยความแตกต่างของเงื่อนไขการทดลองเหล่านี้อย่างเพียงพอ
การตอบกลับของกูเกิล: "การหมุนแบบสุ่มเป็นเทคโนโลยีทั่วไป ไม่สามารถอ้างอิงทุกบทความได้"
ตามที่เกาเจียนหยางเปิดเผย ทีม TurboQuant ได้ตอบกลับทางอีเมลในเดือนมีนาคม 2026 ว่า: «การใช้การหมุนแบบสุ่มและการแปลง Johnson-Lindenstrauss เป็นเทคนิคมาตรฐานในสาขานี้แล้ว เราไม่สามารถอ้างอิงวิจัยทุกชิ้นที่ใช้วิธีเหล่านี้ได้»
ทีมของเกาเจียนหยางเชื่อว่านี่คือการเปลี่ยนประเด็น: ปัญหาไม่ได้อยู่ที่ว่าควรอ้างอิงทุกบทความที่ใช้การหมุนแบบสุ่มหรือไม่ แต่อยู่ที่ว่า RaBitQ เป็นงานชิ้นแรกที่ผสานวิธีนี้เข้ากับการบีบอัดเวกเตอร์และพิสูจน์ความเป็นอุดมคติของมันภายใต้เงื่อนไขปัญหาเดียวกันอย่างสมบูรณ์ บทความของ TurboQuant ควรอธิบายความสัมพันธ์ระหว่างสองสิ่งนี้อย่างถูกต้อง
กลุ่ม Stanford NLP ได้แชร์คำแถลงของเกาเจียนหยางผ่านบัญชี X อย่างเป็นทางการ ทีมงานของเกาเจียนหยางได้เผยแพร่ความคิดเห็นสาธารณะบนแพลตฟอร์ม ICLR OpenReview และได้ยื่นคำร้องอย่างเป็นทางการต่อประธานและคณะกรรมการจริยธรรมของงาน ICLR โดยจะเผยแพร่รายงานเทคนิคฉบับละเอียดเพิ่มเติมบน arXiv ในอนาคต
ผู้เขียนบล็อกเทคโนโลยีอิสระ Dario Salvati ให้การประเมินที่ค่อนข้างเป็นกลางในการวิเคราะห์ของเขา: TurboQuant มีการมีส่วนร่วมที่แท้จริงในด้านวิธีการทางคณิตศาสตร์ แต่ความสัมพันธ์กับ RaBitQ แน่นแฟ้นกว่าที่เอกสารระบุไว้มาก
มูลค่าตลาด 90,000 ล้านดอลลาร์สหรัฐหายไป: ข้อถกเถียงจากงานวิจัยร่วมกับความตื่นตระหนกของตลาด
จุดเวลาที่เกิดข้อพิพาททางวิชาการนี้มีความละเอียดอ่อนอย่างยิ่ง หลังจากกูเกิลเผยแพร่ TurboQuant ผ่านบล็อกอย่างเป็นทางการเมื่อวันที่ 24 มีนาคม ตลาดชิปจัดเก็บข้อมูลทั่วโลกได้รับแรงขายอย่างรุนแรง ตามรายงานจาก CNBC และสื่ออื่นๆ หลายแห่ง Micron Technology ลดลงต่อเนื่องหกวันทำการ รวมลดกว่า 20%;SanDisk ลดลง 11% ในวันเดียว;SK Hynix ของเกาหลีใต้ลดลงประมาณ 6%;Samsung Electronics ลดลงใกล้เคียง 5%;และ Kioxia ของญี่ปุ่นลดลงประมาณ 6% เหตุผลความตื่นตระหนกของตลาดเรียบง่ายและตรงไปตรงมา: ซอฟต์แวร์บีบอัดสามารถลดความต้องการหน่วยความจำสำหรับการให้เหตุผลของ AI ได้ถึง 6 เท่า จึงทำให้แนวโน้มความต้องการชิปจัดเก็บข้อมูลถูกปรับลดแบบโครงสร้าง
นักวิเคราะห์ของ Morgan Stanley โจเซฟ มูร์ ได้โต้แย้งตรรกะนี้ในรายงานเมื่อวันที่ 26 มีนาคม และยังคงให้คะแนนการซื้อต่อสำหรับ Micron และ SanDisk มูร์ชี้ว่า TurboQuant ลดขนาดเฉพาะแค่แคชประเภท KV Cache เท่านั้น ไม่ใช่การใช้งานหน่วยความจำโดยรวม และจัดประเภทว่าเป็น “การปรับปรุงผลผลิตที่เป็นปกติ” นักวิเคราะห์ของ Wells Fargo แอนดรูว์ โรชา ก็อ้างถึงพาราด็อกซ์ของเจวอนส์เช่นกัน โดยระบุว่า การเพิ่มประสิทธิภาพที่ลดต้นทุนอาจกระตุ้นให้มีการปรับใช้ AI ในขนาดที่ใหญ่ขึ้น ซึ่งสุดท้ายจะเพิ่มความต้องการหน่วยความจำ
เอกสารเก่า การห่อหุ้มใหม่: ความเสี่ยงของสายโซ่การถ่ายทอดจากงานวิจัย AI สู่เรื่องเล่าของตลาด
ตามการวิเคราะห์ของผู้เขียนด้านเทคโนโลยี Ben Pouladian กระดาษวิจัย TurboQuant ได้รับการเผยแพร่ตั้งแต่เดือนเมษายน 2025 ไม่ใช่การวิจัยใหม่ โดย Google ได้รีไซเคิลและโปรโมตผ่านบล็อกอย่างเป็นทางการเมื่อวันที่ 24 มีนาคม แต่ตลาดกลับกำหนดราคาเป็นการพัฒนาใหม่ทั้งหมด กลยุทธ์การโปรโมตแบบ “กระดาษเก่า การเปิดตัวใหม่” ร่วมกับความลำเอียงในการทดลองที่อาจมีอยู่ในกระดาษวิจัย สะท้อนถึงความเสี่ยงเชิงระบบในห่วงโซ่การถ่ายทอดจากงานวิจัย AI สู่เรื่องเล่าในตลาด
สำหรับนักลงทุนในโครงสร้างพื้นฐานด้าน AI เมื่อเอกสารวิจัยอ้างว่าบรรลุการเพิ่มประสิทธิภาพในระดับหลายเท่า ควรตั้งคำถามก่อนว่าเงื่อนไขการเปรียบเทียบฐานข้อมูลนั้นเป็นธรรมหรือไม่
ทีมของเกาเจียนหยางได้แสดงอย่างชัดเจนว่าจะดำเนินการต่อไปเพื่อผลักดันการแก้ไขปัญหาอย่างเป็นทางการ ด้านกูเกิลยังไม่ได้ให้การตอบสนองอย่างเป็นทางการต่อข้อกล่าวอ้างในจดหมายเปิดผนึก