









DeepSeek V4 ได้เปิดตัวแล้ว นี่คือช่วงเวลาที่รอคอยมาเกือบห้าเดือน โมเดลหลัก MoE ขนาด 1T พารามิเตอร์ พร้อมเวอร์ชัน Flash ขนาด 285B พารามิเตอร์ ตามด้วยเวอร์ชัน Pro แบบครบชุดขนาด 1.6T พารามิเตอร์ เปิด-source อย่างสมบูรณ์บน GitHub ภายใต้ใบอนุญาต Apache 2.0 โดยน้ำหนักและรหัสการปรับใช้ถูกเปิดเผยพร้อมกัน
เมื่อโมเดลถูกเปิดตัว ตลาดทุนได้ให้คำตอบของพวกเขาผ่านสามวิธีที่แยกจากกันแต่เชื่อมโยงกัน
การตอบสนองที่แตกต่างกันของตลาดทุน
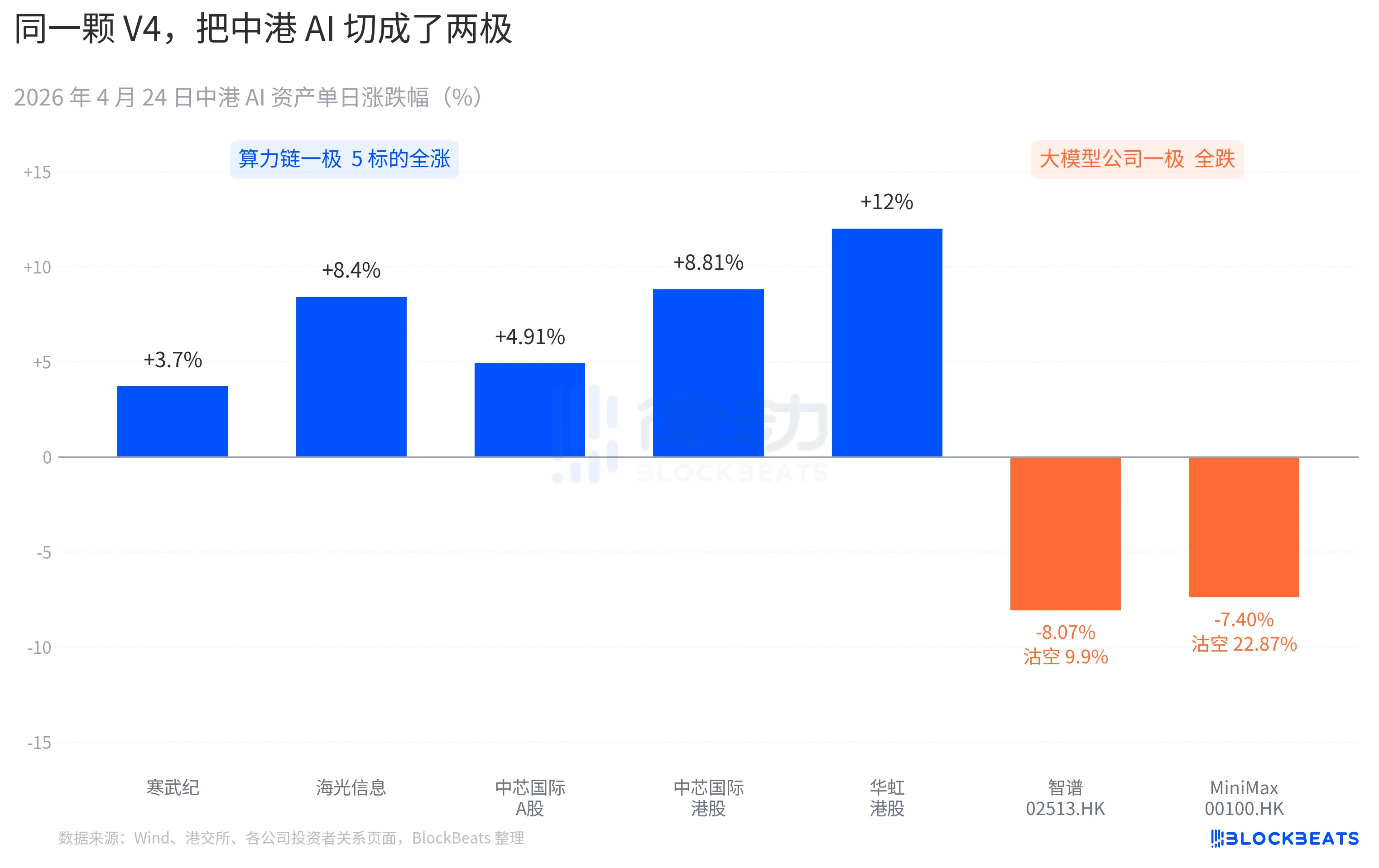
ห่วงโซ่พลังการคำนวณของหุ้น A แทบจะพุ่งขึ้นทั้งหมด บริษัท Cambricon ประสบกับการปิดบวกต่อเนื่อง 11 วันติดต่อกัน โดยเพิ่มขึ้น 3.7% ในวันเดียว และรวมผลตอบแทนในเดือนนี้เกิน 60% บริษัท Hygon Information แตะระดับเพิ่มขึ้นสูงสุด 10% ระหว่างการซื้อขาย และปิดที่ +8.4% บริษัท SMIC หุ้น A เพิ่มขึ้น +4.91% และหุ้นฮ่องกงเพิ่มขึ้น +8.81% หุ้นฮ่องกงของ Huahong สูงสุดถึง +18% และปิดที่ +12% ETF กองทุนรวมดัชนีชิปวิทยาศาสตร์และเทคโนโลยีของกวางตุ้งดูดซับเงินทุน 2.4 พันล้านหยวนในวันเดียว และขนาดกองทุนแตะระดับสูงสุดเป็นประวัติการณ์
บริษัทโมเดลขนาดใหญ่ของตลาดหุ้นฮ่องกงมีสีอีกสีหนึ่ง ซีจี (02513.HK) ร่วงลง 8.07% อัตราการขายสั้นอยู่ที่ 9.9% ไมนิแม็กซ์ (00100.HK) ร่วงลง 7.40% อัตราการขายสั้นพุ่งขึ้นเป็น 22.87% ซึ่งเป็นข้อมูลการขายสั้นรายวันสูงสุดในกลุ่ม AI ของตลาดหุ้นฮ่องกงในช่วงสามเดือนที่ผ่านมา ทั้งสองบริษัทนี้เป็นตัวแทนของคลื่นการระดมทุนครั้งใหญ่ในตลาดหุ้นฮ่องกงด้าน AI ในครึ่งหลังของปี 2025 และคำอธิบายเกี่ยวกับข้อได้เปรียบหลักในเอกสารการเสนอขายหุ้นครั้งแรกคือประโยคเดียวกันว่า “โมเดลพื้นฐานที่พัฒนาด้วยตนเอง”
อีกด้านหนึ่งของมหาสมุทรแปซิฟิกก็มีปฏิกิริยาที่ชัดเจนเช่นกัน NVIDIA เปิดตลาดในวันที่ 24 เมษายนลดลง 1.8% ลดลงสูงสุดถึง -2.6% ระหว่างวัน และปิดตลาดที่ระดับเดิม Bloomberg Market Quick Take ได้เปรียบเทียบการปรับตัวครั้งนี้กับ “ช่วงเวลา DeepSeek V3” เมื่อวันที่ 27 มกราคม ความแตกต่างคือ ครั้งที่แล้วเป็นการขายอย่างตื่นตระหนก โดยมีมูลค่าตลาดหายไป 6 แสนล้านดอลลาร์สหรัฐในหนึ่งวัน แต่ครั้งนี้ดูเหมือนเป็นการประเมินมูลค่าใหม่ ซึ่งมีขนาดเล็กกว่าแต่มีทิศทางชัดเจน ในรายงานการวิจัยของสถาบันผู้ซื้อปรากฏประโยคใหม่ว่า “ความต้องการการประมวลผล AI ของจีนเริ่มแยกตัวออกจากความต้องการการประมวลผล AI ของอเมริกาเหนือ”
การวางหน้าจอทั้งสามนี้ซ้อนกัน คือคำตัดสินชิ้นแรกที่ตลาดเขียนขึ้นภายใน 24 ชั่วโมงหลัง V4 ถูกเปิดใช้งาน หลังจากโอเพ่นซอร์สชนะ เงินเริ่มเลือกข้างใหม่ ราคาไม่ได้ถูกกำหนดโดยโมเดลเองอีกต่อไป แต่ถูกกำหนดโดยว่าโมเดลถูกประมวลผลบนการ์ดใด และติดตั้งอยู่ในห่วงโซ่อุตสาหกรรมใด
30 วัน 11 โมเดลใหม่ V4 ช่วยเติมเชื้อไฟให้กับชุมชนโอเพนซอร์ส
ช่วงเวลาที่เปิดตัว V4 ก็เป็นหนึ่งในสาเหตุที่ทำให้ปฏิกิริยานี้ขยายตัว
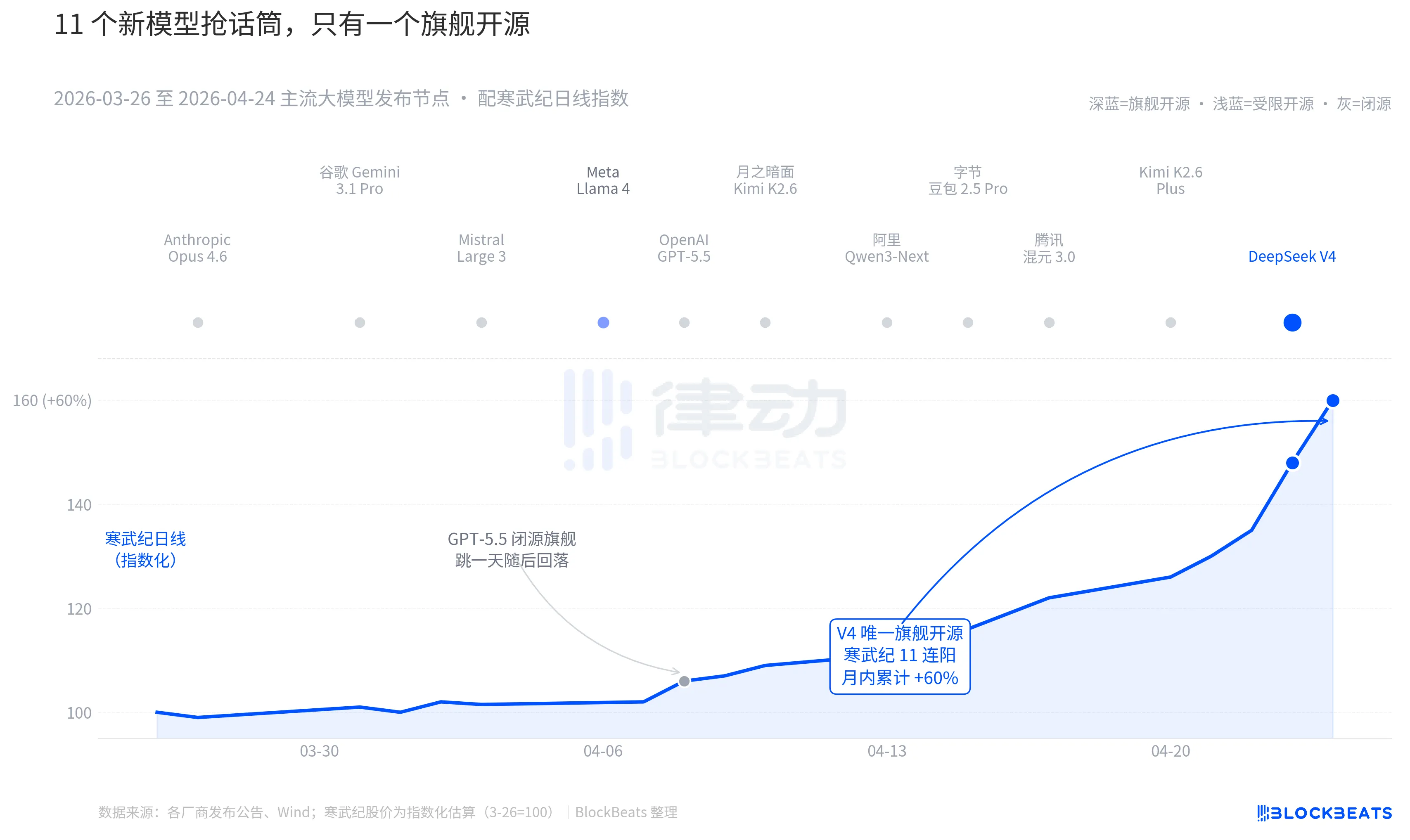
ย้อนกลับไปที่ 30 วันที่ผ่านมา ระหว่างวันที่ 26 มีนาคมถึง 24 เมษายน มีการเปิดตัวหรืออัปเดตแบบสำคัญของโมเดลขนาดใหญ่อย่างน้อย 11 โมเดลทั่วโลก ซึ่งครอบคลุมผู้เล่นหลักเกือบทั้งหมด: Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonshot Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus และสุดท้ายคือ DeepSeek V4 ที่เปิดตัวในคืนวันที่ 23 เมษายน
โดยเฉลี่ยทุก 2.7 วันจะมีโมเดลใหม่ออกมาหนึ่งตัว ซึ่งเร็วจนกองทุนการลงทุนไม่ทันอ่านคำแถลงการเปิดตัว แต่เมื่อพิจารณากราฟ K ของสินทรัพย์ AI จีนและฮ่องกงในช่วง 30 วันที่ผ่านมา มีเพียงชื่อเดียวเท่านั้นที่ทิ้งร่องรอยอย่างต่อเนื่องบนกราฟ คือ GPT-5.5 เมื่อวันที่ 8 เมษายน ซึ่งผลักดันให้นิวไดอาเพิ่มขึ้น 4.2% ในหนึ่งวันและแตะจุดสูงสุดในวันนั้น ตามด้วย DeepSeek V4 ในวันที่ 23-24 เมษายน ที่ผลักดันโซ่พลังการคำนวณของจีนและฮ่องกงให้พุ่งขึ้นอย่างต่อเนื่อง
ความแตกต่างไม่ได้อยู่ที่ความสามารถของโมเดลเอง โมเดลทั้ง 11 ตัวนี้มีช่องว่างในตารางคะแนน LMArena ส่วนใหญ่ไม่เกิน 50 คะแนน และอยู่ในช่วง “ระดับเดียวกัน” ความแตกต่างเกิดจากการทับซ้อนของสองสิ่ง
สิ่งแรกคือการเปิดแหล่งที่มา ภายใน 10 อันดับแรก มีเพียง Llama 4 เท่านั้นที่เปิดแหล่งที่มา แต่ข้อกำหนดใบอนุญาตของน้ำหนัก Llama 4 มีข้อจำกัดด้านการใช้งานเชิงพาณิชย์จำนวนมาก ทำให้ชุมชนนักพัฒนาในยุโรปและอเมริกาตอบรับอย่างเย็นชา และตกลงจากตำแหน่ง top 10 ภายในวันที่สามหลังเปิดตัวบน OpenRouter ส่วนข้อกำหนดของ V4 คือ Apache 2.0 น้ำหนักไม่มีข้อจำกัด การใช้งานเชิงพาณิชย์ไม่มีข้อจำกัด และรหัสการให้บริการแบบอินเฟอร์เรนซ์ถูกเปิดเผยพร้อมกัน นี่คือโมเดลโอเพ่นซอร์สระดับฟลากชิพตัวแรกในหกเดือนที่ผ่านมาที่ทำให้กลุ่มปิดแหล่งที่มาต้องรับแรงกดดันในสามมิติ: ประสิทธิภาพ ราคา และความเปิดกว้าง
ข้อที่สองคือช่วงเวลา ในบริบทที่ฝ่ายปิดแหล่งที่มาได้เปิดตัวนวัตกรรมอย่างต่อเนื่อง แนวคิดเรื่องแหล่งที่มาเปิดกำลังถูกบีบอัดซ้ำแล้วซ้ำเล่า Opus 4.6 ได้ผลักดันการทดสอบงานด้านรหัส SWE-Bench ไปสู่ระดับใหม่ ส่วน GPT-5.5 ได้กำหนดราคาที่ 1.25 ดอลลาร์สหรัฐต่อล้านโทเค็นเป็นจุดอ้างอิงต่ำสุด การอภิปรายว่าแหล่งที่มาเปิดจะสามารถตามทันแหล่งที่มาปิดได้หรือไม่ ได้รับการถกเถียงกันในซิลิคอนแวลลีย์มานานสองปีแล้ว V4 ได้ใช้การคาดการณ์ผู้ใช้งานรายเดือนที่สูงถึง 90 ล้านคนเพื่อผลักดันโครงการแหล่งที่มาเปิดชั้นนำ ทำให้การอภิปรายนี้หยุดชั่วคราว
ตามคำพูดของผู้จัดการกองทุนขนาดใหญ่ในประเทศหนึ่งในการนำเสนอโครงการ «ก่อน V4 เราได้ให้ส่วนลดในการประเมินมูลค่าของโมเดลขนาดใหญ่แบบเปิดแหล่งที่มา แต่หลังจาก V4 ส่วนลดนี้เริ่มกลับมาเป็นการเรียกเก็บเพิ่ม»
DeepSeek เปลี่ยนตารางราคาห่วงโซ่อุปทานกำลังการประมวลผล
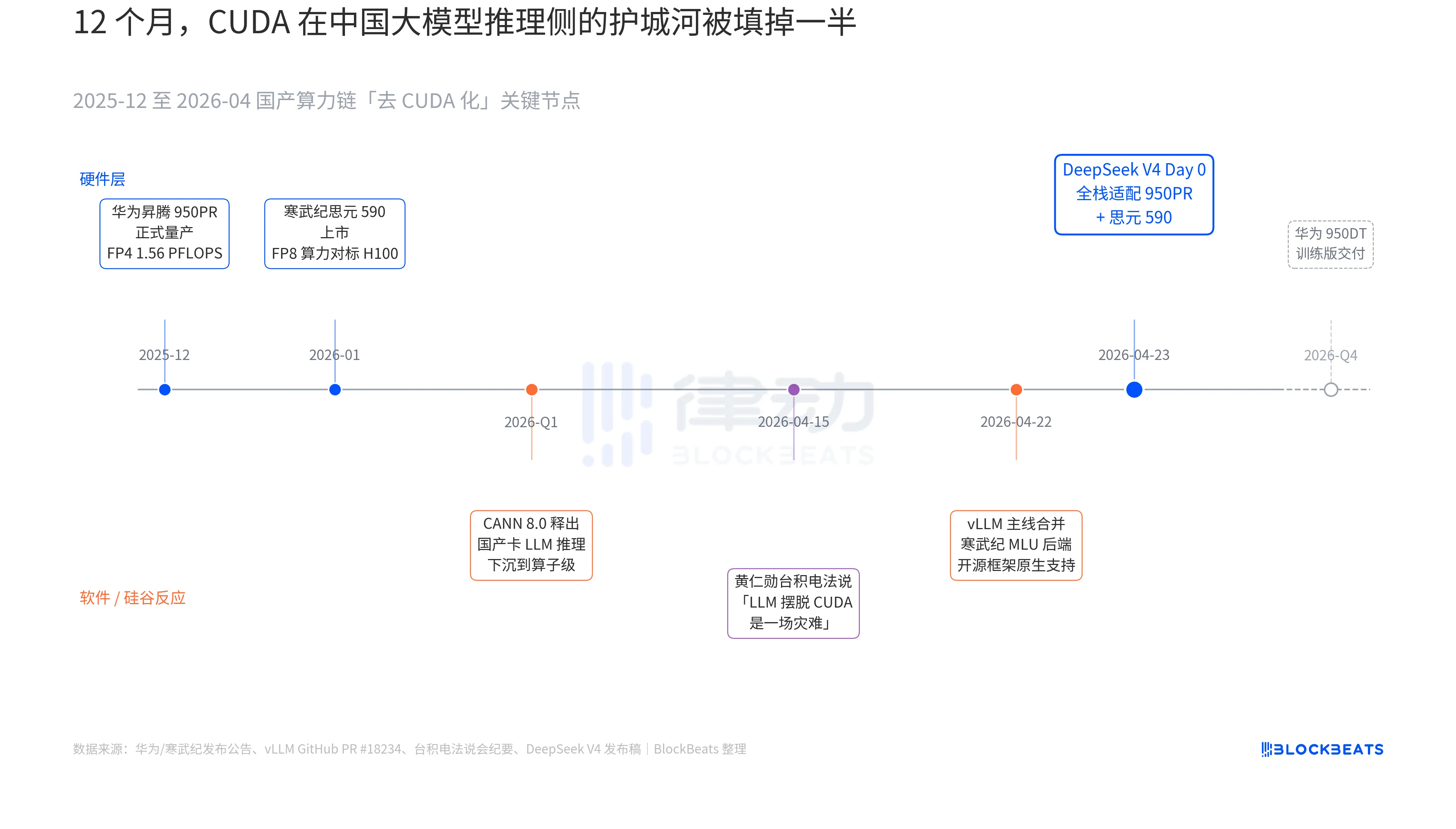
ในเอกสารเผยแพร่เวอร์ชัน V4 มีประโยคหนึ่งที่ไม่เคยปรากฏมาก่อนในเอกสารทางการของโมเดลขนาดใหญ่ใดๆ ในจีน: 「วันที่ 0 ปรับให้เข้ากับ Full Stack กับ Cambricon MLU590 และ Huawei Ascend 950PR พร้อมเปิดรหัสการปรับใช้แบบโอเพนซอร์ส」 น้ำหนักของประโยคนี้จะเข้าใจได้ชัดเจนก็ต่อเมื่อเชื่อมโยงสามเส้นทางลับที่ดำเนินไปพร้อมกันในช่วง 12 เดือนที่ผ่านมา เส้นทางเหล่านี้แต่ละเส้นอยู่ในหมวดฮาร์ดแวร์ ซอฟต์แวร์ และปฏิกิริยาจากซิลิคอนแวลลีย์
เส้นลับ第一条อยู่ที่ด้านชิป ชิป Huawei Ascend 950PR จะเริ่มผลิตเชิงพาณิชย์อย่างเป็นทางการในเดือนธันวาคม 2025 มีพลังการประมวลผล FP4 ที่ 1.56 PFLOPS และความจุ HBM 112GB ซึ่งเป็นชิป AI ของจีนครั้งแรกที่สามารถเทียบเท่ากับซีรีส์ B ของ NVIDIA ในด้านตัวเลขเชิงเทคนิค โดยในงานประมวลผล MoE ที่มีพารามิเตอร์ 1T เช่น V4 ความเร็วในการรับส่งข้อมูลต่อการ์ดเดียวเพิ่มขึ้น 2.87 เท่าเมื่อเทียบกับ H20 ส่วนซอฟต์แวร์สแต็ก CANN 8.0 ที่มาพร้อมกันได้ปรับปรุงโครงสร้างการประมวลผล LLM ลงถึงระดับโอเปอเรเตอร์ โดยผลการทดสอบ Benchmark ที่ DeepSeek เปิดเผยแสดงว่า V4 บนโหนด超级 (8 การ์ด 950PR) มีความล่าช้าในการประมวลผลแบบ end-to-end ต่ำกว่าคลัสเตอร์ H100 ขนาดเท่ากันถึง 35% ส่วนข้อมูลของ Cambricon Siyuan 590 ยิ่งรุนแรงกว่า โดยพลังการประมวลผล FP8 ต่อชิปเดียวเทียบเท่า H100 แต่มีราคาต่ำกว่าครึ่งหนึ่ง
เส้นที่สองอยู่ที่ด้านซอฟต์แวร์: vLLM ได้รวม PR สำหรับแบ็กเอนด์ MLU ของ Cambricon เมื่อวันที่ 22 เมษายน ทำให้กรอบงานการอนุมานแบบเปิดแหล่งที่มาสามารถรองรับ GPU ของจีนที่ไม่ใช่ NVIDIA ได้เป็นครั้งแรก สำหรับ DCU ของ Hygon ได้ใช้ทางเลือกอีกเส้นผ่านระบบนิเวศ ROCm แต่สามารถรันชั้นการจัดเส้นทาง MoE ของ V4 ได้อย่างสมบูรณ์ ซึ่งหมายความว่าการปรับใช้ V4 ไม่ได้จำกัดอยู่แค่ “ต้องรันบนการ์ดจีนแบรนด์เดียวเท่านั้น” แต่กลายเป็น “สามารถเลือกรันบนการ์ดจีนหลายแบรนด์ได้” ความพึ่งพาต่อผู้จัดจำหน่ายรายเดียวถูกทำลายลง นี่คือจุดเปลี่ยนสำคัญสำหรับการผลิตจริง
เส้นที่สามมาจากซิลิคอนแวลลีย์ เมื่อวันที่ 15 เมษายน ฮวง เหรินหยุน ถูกนักวิเคราะห์ซักถามถึงความคืบหน้าของพลังการประมวลผลภายในประเทศจีนในการประชุมรายงานผลของ TSMC คำตอบของเขาเย็นชาและเฉพาะเจาะจง: “หากพวกเขาสามารถทำให้ LLM หลุดพ้นจาก CUDA ได้จริง มันจะเป็นหายนะสำหรับเรา (a disaster)” เก้าวันต่อมา DeepSeek ได้ให้คำตอบผ่านประกาศ Day 0 เพียงหนึ่งบรรทัด
คำว่า “การแทนที่ของประเทศเอง” ถูกพูดซ้ำๆ จนสูญเสียความหมายไปในสามปีที่ผ่านมา แต่หลังจากวันที่ 24 เมษายน ความเป็นจริงครั้งแรกที่มีข้อมูลเฉพาะเจาะจงที่ตลาดทุนสามารถกำหนดมูลค่าได้ก็เกิดขึ้น ปริมาณการรับส่งข้อมูลต่อการ์ดเดียว ความล่าช้าในการประมวลผลแบบ end-to-end ต้นทุนการประมวลผล และรหัสการปรับใช้ที่สามารถใช้งานเชิงพาณิชย์ได้ ได้ผลักดันการต่อสู้ด้วยถ้อยคำอันยาวนานนี้ให้ก้าวเข้าสู่ขีดจำกัดของการผลิตอย่างเงียบๆ
เหตุผลเบื้องหลังการปิดราคาเพิ่มขึ้น 11 วันติดต่อกันของ Wuhanji ซ่อนอยู่ที่นี่ มันไม่ใช่แค่หุ้นแนวคิด GPU ของจีนอีกต่อไป แต่เป็น “ผู้จัดหาโครงสร้างพื้นฐานสำหรับการให้บริการ DeepSeek V4” เหตุผลเดียวกันนี้ยังอธิบายการเพิ่มขึ้น 12% ของหุ้น Hua Hong ในตลาดฮ่องกง เพราะบริษัทผลิตกระบวนการที่เทียบเท่า 7nm สำหรับ 950PR ทุกโทเค็น V4 ที่รันบน Ascend ของจีน หมายถึงกำลังการผลิตที่เคยไหลไปยัง NVIDIA และ TSMC ถูกดูดซับกลับมาบางส่วนในเขตสามเหลี่ยมแม่น้ำเพิร์ล
ขั้นตอนถัดไปได้รับการเตรียมการไว้ล่วงหน้าแล้ว ในแผนภาพเส้นทางของฮัวเวย 950DT (รุ่นฝึกอบรม) กำหนดส่งมอบในไตรมาสที่สี่ของปี 2026 โดยมีเป้าหมายคือ “การฝึกอบรมแบบเต็มสแต็กบนคลัสเตอร์ 10,000 หน่วยสำหรับโมเดล V5 หรือโมเดลที่มีขนาดเทียบเท่า” หากเส้นทางนี้สามารถดำเนินการได้สำเร็จ ความได้เปรียบของ CUDA ในการฝึกอบรมโมเดลขนาดใหญ่ในจีน จะลดระดับจาก “จำเป็น” เป็น “ตัวเลือก”
ที่มา: ลู่ตง BlockBeats