









การปรับราคาครั้งนี้ของ DeepSeek ได้บังคับให้อุตสาหกรรมเข้าสู่ยุคต้นทุนใหม่ผ่านการลดลงแบบเฉียบพลันที่ไม่เป็นเชิงเส้น
ผู้เขียนบทความ แหล่งที่มา: 0x9999in1, ME News
สรุปสั้น
- ราคาพุ่งต่ำกว่าระดับพื้นฐาน: ปลายเดือนเมษายน 2026 DeepSeek ได้ลดราคาการส่งออกของโมเดล V4-Pro เหลือ 0.878 ดอลลาร์สหรัฐต่อหนึ่งล้านโทเค็น โดยการรวมส่วนลดชั่วคราวกับการลดราคาแบบแคช ขณะที่ราคาการป้อนข้อมูลที่แคชตรงตามเงื่อนไขลดลงเหลือ 0.0037 ดอลลาร์สหรัฐ (ประมาณ 0.025 หยวนจีน) ทำลายจุดอ้างอิงด้านราคาของอุตสาหกรรมโมเดลขนาดใหญ่โดยสิ้นเชิง
- การกำหนดราคาของจีนและสหรัฐอเมริกาเกิดช่องว่าง: เมื่อเปรียบเทียบกับผู้ผลิตชั้นนำระดับโลก ต้นทุนรวมในการเรียกใช้ API ของ DeepSeek-V4-Pro อยู่ที่ประมาณหนึ่งในสามสิบของ OpenAI GPT-5.5 และ Anthropic Claude Opus 4.7 สร้างความได้เปรียบด้านต้นทุนที่ชัดเจนยิ่ง
- แรงกดดันจากสถานการณ์การแข่งขันในประเทศ: ภายใต้การตั้งราคาอย่างรุนแรงของ DeepSeek โมเดลหลักในประเทศ เช่น Zhipu GLM 5.1 และ Moonshot Kimi K2.6 กำลังเผชิญกับแรงกดดันทางการค้าอย่างหนัก และอาจถูกบังคับให้ตามลดราคา ทำให้อัตราการชำระหนี้ของอุตสาหกรรมเร่งตัวขึ้นอย่างมาก
- การเข้าถึงแคชกลายเป็นเศรษฐศาสตร์หลัก: DeepSeek ลดราคาการเข้าถึงแคชลงเหลือหนึ่งในสิบของราคาเดิม กลยุทธ์นี้ส่งผลดีอย่างมากต่อการประมวลผลข้อความยาว การสร้างแบบเสริมการค้นหา (RAG) และสถานการณ์การโต้ตอบแบบหลายรอบอย่างต่อเนื่องของตัวแทน (Agent)
- ข้อสรุปของการวิเคราะห์จากหน่วยงานวิจัย: โมเดลพื้นฐานขนาดใหญ่กำลังเร่งกระบวนการกลายเป็นโครงสร้างพื้นฐานเช่น น้ำและไฟฟ้า จุดแข็งในการแข่งขันในอนาคตจะเปลี่ยนจากความขัดแย้งเรื่องขนาดพารามิเตอร์ของโมเดลเพียงอย่างเดียว ไปสู่การแข่งขันในด้านความสามารถในการปรับปรุงต้นทุนการให้เหตุผลและส่วนแบ่งตลาดของระบบนิเวศนักพัฒนา
บทนำ: จุดสุดยอดของต้นทุนกำลังการประมวลผลของโมเดลขนาดใหญ่
การพัฒนาทางเทคโนโลยีมักมาพร้อมกับต้นทุนที่ลดลงแบบก้าวกระโดด ซึ่งเป็นขั้นตอนที่จำเป็นสำหรับเทคโนโลยีที่ disruptive ทุกชนิดในการเข้าสู่การใช้งานอย่างแพร่หลาย ระหว่างวันที่ 25 ถึง 26 เมษายน 2026 วงการ AI ได้ก้าวเข้าสู่ช่วงเวลาที่มีความหมายอย่างยิ่ง: ผู้ผลิตโมเดลขนาดใหญ่ชั้นนำ DeepSeek ได้เปิดตัว “ระเบิดใต้น้ำ” สองลูกต่อเนื่องกัน ก่อนอื่นประกาศลดราคา API ของโมเดล DeepSeek-V4-Pro เป็นพิเศษเพียง 25% สำหรับช่วงเวลาจำกัด จากนั้นจึงประกาศลดราคาสำหรับการเข้าถึงแคชอินพุตในบริการ API ทั้งหมดให้เหลือเพียง 1/10 ของราคาเดิม
หลังจากดำเนินกลยุทธ์การปรับราคาแบบทับซ้อนสองรอบ ราคาการเข้าถึงแคชการป้อนข้อมูลของ DeepSeek-V4-Flash ได้ลดลงเหลือเพียง 0.0029 ดอลลาร์สหรัฐต่อหนึ่งล้านโทเค็น (ประมาณ 0.02 หยวนจีน) ก่อนวันที่ 5 พฤษภาคม 2026 ในขณะที่ DeepSeek-V4-Pro ซึ่งเทียบเท่ากับระดับชั้นนำของโลก มีราคาการเข้าถึงแคชการป้อนข้อมูลเพียง 0.0037 ดอลลาร์สหรัฐ (ประมาณ 0.025 หยวนจีน)
ก่อนหน้านี้ อุตสาหกรรมคาดการณ์กันทั่วไปว่าต้นทุนการให้บริการโมเดลขนาดใหญ่จะลดลงประมาณ 50% ต่อปี แต่การปรับราคาครั้งนี้ของ DeepSeek ได้ผลักดันให้ต้นทุนลดลงอย่างเฉียบพลันแบบไม่เป็นเชิงเส้น บังคับให้อุตสาหกรรมก้าวเข้าสู่ยุคต้นทุนใหม่ เราเชื่อว่านี่ไม่ใช่เพียงกิจกรรมการตลาดทั่วไปหรือ “สงครามราคา” ระยะสั้น แต่เป็นผลลัพธ์ที่หลีกเลี่ยงไม่ได้จากความก้าวหน้าของสถาปัตยกรรมอัลกอริทึมพื้นฐาน (เช่น กลไกการให้ความสำคัญแบบบางส่วน การพัฒนาอย่างสุดขีดของสถาปัตยกรรม MoE) รวมถึงความสามารถทางวิศวกรรมของคลัสเตอร์การประมวลผล รายงานนี้จะวิเคราะห์อย่างลึกซึ้งถึงผลกระทบจากการลดราคาของ DeepSeek โดยอิงจากข้อมูลราคาล่าสุดของอุตสาหกรรมทั้งหมด และเปรียบเทียบเชิงแนวตั้งถึงความสามารถทางการแข่งขันเชิงพาณิชย์ของโมเดลขนาดใหญ่รายหลักทั่วโลก เพื่อจัดทำแผนที่ทางวิวัฒนาการของอุตสาหกรรมที่ชัดเจนสำหรับผู้กำหนดนโยบาย
ปรากฏการณ์หลัก: การทะลุขีดจำกัดของระบบราคาในซีรีส์ DeepSeek-V4
เพื่อเข้าใจความรุนแรงของการลดราคาครั้งนี้ เราต้องวิเคราะห์มิติหลักสามประการของการคิดค่าบริการ API แบบโมเดลขนาดใหญ่: ราคาอินพุต (ไม่พบในแคช), ราคาอินพุต (พบในแคช), และราคาเอาต์พุต รูปแบบการคิดค่าบริการในอดีตมักจะแยกเพียงอินพุตและเอาต์พุตเท่านั้น แต่ด้วยความก้าวหน้าของเทคโนโลยีบริบทยาว (Long-Context) “อัตราการพบในแคช (Cache Hit)” กำลังกลายเป็นตัวแปรสำคัญที่เปลี่ยนแปลงเศรษฐศาสตร์ของ API
การวิเคราะห์กลยุทธ์การตั้งราคา: การทับซ้อนส่วนลดและเลเวอเรจแบบแคช
ตามข้อมูลล่าสุดที่เปิดเผย DeepSeek ได้ใช้กลยุทธ์สามประการคือ การลดราคาพื้นฐาน พร้อมส่วนลดชั่วคราว และเลเวอเรจแบบแคชชิ่ง
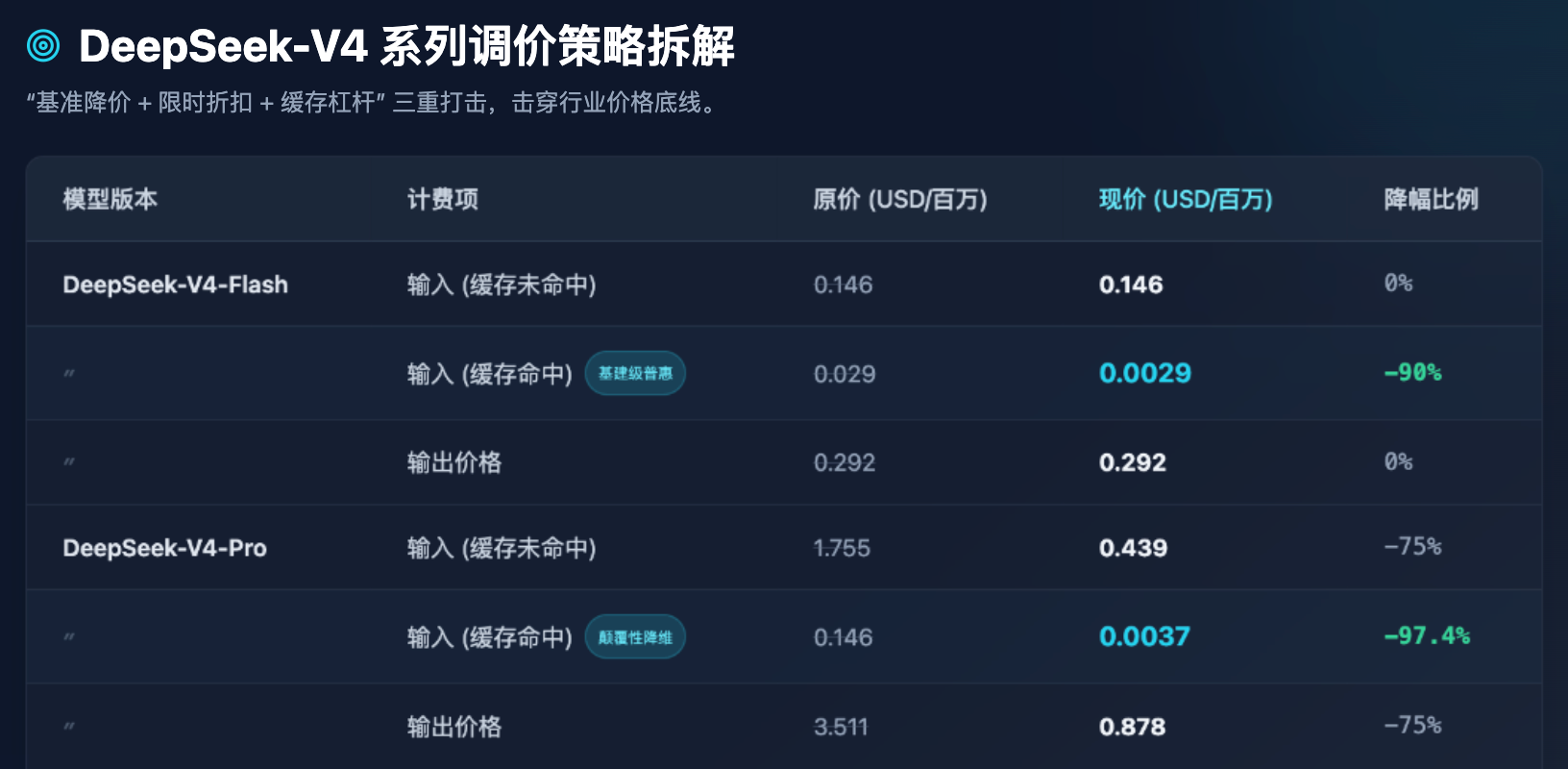
ตารางที่ 1: เปรียบเทียบราคา API ล่าสุดของซีรีส์ DeepSeek-V4 ก่อนและหลังการปรับราคา (หน่วย: ดอลลาร์สหรัฐ/ล้านโทเค็น)
จากตารางที่ 1 เราสามารถสรุปการสังเกตอุตสาหกรรมที่ชัดเจนหลายประการ:
ประการแรก การทำให้โมเดล Flash เข้าถึงได้ทั่วถึงได้แตะระดับต่ำสุดแล้ว สำหรับโมเดล Flash ที่เน้นการประมวลผลแบบพร้อมกันสูงและหน่วงเวลาต่ำ ราคาการส่งออกยังคงอยู่ที่ 0.292 ดอลลาร์สหรัฐต่อหนึ่งล้านโทเค็น ซึ่งใกล้เคียงกับต้นทุนทางกายภาพของพลังการประมวลผลเซิร์ฟเวอร์อย่างสุดขีด DeepSeek ไม่ได้ดำเนินการปรับเปลี่ยนราคาพื้นฐานของ Flash แต่กลับลดราคา “การเข้าถึงแคช” ลง 90% อย่างชาญฉลาด สิ่งนี้หมายความว่า ในกรณีที่จัดการกับคำสั่งระบบ (System Prompt) จำนวนมากที่ซ้ำกัน หรือคำถามคำตอบจากเอกสารคงที่ ต้นทุนของโมเดล Flash จะแทบไม่มีนัยสำคัญ
ที่สอง การลดมิติของโมเดล Pro โมเดล V4-Pro ซึ่งถูกออกแบบให้เทียบเท่ากับกลุ่มชั้นนำระดับโลก (เช่น ระดับ GPT-5) ได้ลดราคาเอาต์พุตจาก 3.511 ดอลลาร์สหรัฐลงเหลือเพียง 0.878 ดอลลาร์สหรัฐ ยิ่งไปกว่านั้น ราคาการป้อนข้อมูลที่เคยอยู่ที่ 0.146 ดอลลาร์สหรัฐ เมื่อรวมกับส่วนลดพิเศษ 2.5 ชั่วโมงและลดราคาอีก 1/10 ได้ลดลงเหลือเพียง 0.0037 ดอลลาร์สหรัฐ นี่เป็นตัวเลขที่น่าตกใจอย่างยิ่ง—ซึ่งหมายความว่าต้นทุนในการเรียกใช้ปัญญาชั้นยอดระดับโลกได้ถูกลดลงจนถึงระดับที่ธุรกิจขนาดเล็กและกลาง หรือแม้แต่นักพัฒนาส่วนตัว ก็สามารถเรียกใช้งานได้อย่างไม่ต้องกังวลในความถี่สูง
ที่สาม บังคับให้นักพัฒนาปรับปรุงการวิศวกรรม Prompt การตั้งราคาที่ถูกเรียกจากแคชให้อยู่ที่หนึ่งในสิบหรือร้อยของราคาที่ไม่ถูกเรียกจากแคช (ตัวอย่างในรุ่น Pro: 0.0037 ดอลลาร์สหรัฐ vs 0.439 ดอลลาร์สหรัฐ ต่างกันประมาณ 118 เท่า) นี่ไม่ใช่เพียงกลยุทธ์การตั้งราคา แต่ยังเป็นการใช้กลไกทางธุรกิจเพื่อชี้นำระบบนิเวศทางเทคโนโลยี DeepSeek กำลังแจ้งชัดเจนแก่นักพัฒนาว่า: หากคุณออกแบบสถาปัตยกรรมให้เหมาะสม (เช่น วางบริบทยาวคงที่ไว้ด้านหน้า และคำถามสั้นที่เปลี่ยนแปลงไว้ด้านหลัง) คุณจะได้รับพลังการประมวลผลสำหรับอินพุตเกือบฟรี
การเปรียบเทียบในแนวนอน: ความแตกต่างอย่างรุนแรงระหว่างราคาโมเดลขนาดใหญ่ระดับโลกกับระดับท้องถิ่น
การเปรียบเทียบเฉพาะการลดราคาของ DeepSeek เองนั้นไม่เพียงพอที่จะเห็นภาพรวมทั้งหมด เมื่อเราวางมันไว้ในระบบพิกัดของตลาดโมเดลขนาดใหญ่ระดับโลกปี 2026 ความแตกต่างอย่างรุนแรงที่กลยุทธ์การตั้งราคาสร้างขึ้นจึงแท้จริงแล้วทำให้ขนลุก
โดยอิงจาก OpenRouter และข้อมูลสาธารณะจากแต่ละราย เราได้รวบรวมข้อมูลราคา API ล่าสุดของโมเดลขนาดใหญ่ 9 รุ่นที่เป็นตัวแทนที่สุดในตลาดทั้งในและต่างประเทศ

ตารางที่ 2: การเปรียบเทียบราคา API ของโมเดลขนาดใหญ่หลักทั่วโลกในปี 2026 (หน่วย: ดอลลาร์สหรัฐ/ล้านโทเค็น)
ต่อสู้กับยักษ์ใหญ่ระดับโลก: ทำลายอคติเรื่อง “สติปัญญาสูงและมูลค่าสูง”
ในสองปีที่ผ่านมาของเรื่องราวเกี่ยวกับ AI OpenAI และ Anthropic ได้รักษาความเข้าใจร่วมกันว่า โมเดลที่ฉลาดที่สุดควรได้รับอัตรากำไรขั้นต้นสูงสุด ปัจจุบัน ราคาการส่งออกของ GPT-5.5 และ Claude Opus 4.7 อยู่ที่ระดับสูงถึง 30 ดอลลาร์และ 25 ดอลลาร์ต่อล้านโทเค็น บริษัทยักษ์ใหญ่จากซิลิคอนแวลลีย์ทั้งสองแห่งนี้พยายามรักษาภาษีพลังการคำนวณอันสูงลิ่วของตนโดยผูกขาดความสามารถในการประมวลผลระดับสูงสุด
อย่างไรก็ตาม การปรากฏตัวของ DeepSeek-V4-Pro พร้อมราคาการสร้างเอาต์พุตที่ 0.878 ดอลลาร์สหรัฐ ได้เจาะทะลุผ่านแผ่นกระจกใบนี้โดยตรง สมมติว่า V4-Pro สามารถบรรลุหรือใกล้เคียงระดับของ GPT-5.5 ในการทดสอบมาตรฐานหลัก (Benchmarks) และประสบการณ์จริง ความแตกต่างของราคาการสร้างเอาต์พุตที่สูงถึง 34 เท่าระหว่างสองระบบจะทำลายตรรกะการตั้งราคาส่วนเกินของผู้เล่นรายใหญ่ต่างประเทศในตลาด B2B อย่างสิ้นเชิง
«ME News智库» คำนวณว่า สำหรับบริษัทที่พึ่งพาเนื้อหาที่สร้างโดย AI อย่างหนัก หากใช้พลังการสร้างผลลัพธ์ 1 พันล้านโทเค็นต่อเดือน ต้นทุนคงที่เมื่อใช้ GPT-5.5 จะอยู่ที่ 30,000 ดอลลาร์สหรัฐฯ แต่หากเปลี่ยนไปใช้ DeepSeek-V4-Pro ต้นทุนนี้จะลดลงเหลือเพียง 878 ดอลลาร์สหรัฐฯ ความแตกต่างของต้นทุนในระดับนี้สามารถส่งผลต่อความอยู่รอดของบริษัทสตาร์ทอัพได้ ซึ่งแสดงให้เห็นว่าบริษัท AI ของจีนได้เดินทางบนเส้นทางที่ต่างจากซิลิคอนแวลลีย์อย่างสิ้นเชิง โดยเน้นทั้ง “ความงามแบบใช้กำลัง” และ “วิศวกรรมระดับสูงสุด” ในการฝึกโมเดลพื้นฐานและการปรับแต่งคลัสเตอร์การอนุมาน
ล้อมจัดการคู่แข่งในประเทศ: เร่งกระบวนการปรับโครงสร้างอุตสาหกรรม
หาก DeepSeek ถือเป็นการตีถล่มคู่แข่งต่างประเทศอย่างถล่มทลาย สำหรับคู่แข่งในประเทศแล้ว นี่คือการแข่งขันแบบศูนย์สุทธิที่โหดเหี้ยม
จากตารางที่ 2 สามารถเห็นได้ว่า ผู้ผลิตชั้นนำในประเทศ เช่น Zhipu (GLM 5.1 ราคาเอาต์พุต 4.4 ดอลลาร์) และ Moonshot (Kimi K2.6 ราคาเอาต์พุต 4 ดอลลาร์) อยู่ในสถานการณ์ที่ยุ่งยากในด้านการตั้งราคา ราคาเหล่านี้เมื่อไม่กี่เดือนก่อนยังถือว่า “สมเหตุสมผลและคุ้มค่า” แต่เมื่อเทียบกับ DeepSeek-V4-Pro (ราคาเอาต์พุต 0.878 ดอลลาร์) กลับสูญเสียเส้นแบ่งราคาทั้งหมดทันที แม้แต่ Alibaba Cloud ซึ่งมีชื่อเสียงด้านการเปิดแหล่งที่มาและราคาต่ำ (Qwen3.6 Plus ราคาเอาต์พุต 1.96 ดอลลาร์) ก็ดูไม่ได้ “ถูก” อีกต่อไป
ในสนามแข่งของโมเดล Flash แบบเบา ความต่อสู้ก็รุนแรงไม่แพ้กัน Step 3.5 Flash ของ Jiepiao Xingchen มีต้นทุนการป้อนข้อมูลต่ำถึง 0.028 ดอลลาร์ และต้นทุนการส่งออกเพียง 0.299 ดอลลาร์ ซึ่งแข่งขันอย่างดุเดือดกับ DeepSeek-V4-Flash (ส่งออก 0.292 ดอลลาร์) นี่แสดงให้เห็นว่าในสาขาโมเดลขนาดเล็ก การบีบอัดต้นทุนการประมวลผลได้ถึงระดับนาโน ทุกค่ายต่างบินอยู่ใกล้เส้นต้นทุนอย่างใกล้ชิด
โดยรวมแล้ว DeepSeek กำลังใช้ความสามารถระดับ Pro เพื่อแข่งขันกับราคาของคู่แข่งในประเทศที่อยู่ในระดับ Plus หรือแม้แต่รุ่นมาตรฐาน; พร้อมใช้ราคาในระดับ Flash เพื่อดึงดูดปริมาณการใช้งานระยะยาวที่มีความหนาแน่นของมูลค่าต่ำจำนวนมาก กลยุทธ์ “กักขังทั้งสองด้าน” นี้ได้บีบอัดพื้นที่การอยู่รอดของบริษัทโมเดลขนาดใหญ่อื่นๆ อย่างมาก และการแข่งขันเพื่อคัดออกของโมเดล AI ขนาดใหญ่ในประเทศจะถูกเร่งความเร็วขึ้นหลังจากการลดราคาครั้งนี้
การวิเคราะห์เชิงลึก: เทคโนโลยีและตรรกะทางธุรกิจเบื้องหลังราคาต่ำสุด
ราคาต่ำที่ไม่ได้ยึดตามพื้นฐานจะไม่ยั่งยืน DeepSeek กล้าใช้กลยุทธ์ลดราคาอย่างเด็ดขาดในปี 2026 เพราะมีการสนับสนุนทางเทคโนโลยีที่แข็งแกร่งและแผนธุรกิจที่ทะเยอทะยานอย่างมาก
เทคนิคเชิงตรรกะ: จาก “แรงมาก อิฐบิน” สู่ การชนะด้วยโครงสร้าง
การลดลงอย่างรุนแรงของราคา โดยพื้นฐานแล้วคือการปลดปล่อยผลประโยชน์จากการพัฒนาโครงสร้างเทคโนโลยี
- ผลประโยชน์เชิงลึกของสถาปัตยกรรม MoE (Mixture of Experts): ต่างจากโมเดลหนาแน่นขนาดใหญ่ของ OpenAI ในช่วงต้น โมเดลขั้นสูงปัจจุบันส่วนใหญ่ใช้สถาปัตยกรรม MoE ที่ได้รับการปรับแต่งอย่างสูง DeepSeek มีแนวโน้มสูงมากที่จะลดสัดส่วนพารามิเตอร์ที่เปิดใช้งานเพิ่มเติมในสถาปัตยกรรม V4 ซึ่งหมายความว่าแม้จำนวนพารามิเตอร์ทั้งหมดจะมาก แต่ในแต่ละครั้งที่ทำการประมวลผล จะมีเพียง “ผู้เชี่ยวชาญ” จำนวนน้อยมากที่ถูกเรียกใช้งาน ทำให้ลดปริมาณการคำนวณ (FLOPs) และแรงกดดันต่อแบนด์วิดธ์หน่วยความจำกราฟิกในการเรียกใช้งานแต่ละครั้งอย่างมาก
- การก้าวกระโดดครั้งใหญ่ในการจัดการ KV Cache: จุดเด่นที่สำคัญที่สุดของการปรับราคาครั้งนี้คือ “อัตราการเข้าถึงแคชการป้อนข้อมูลลดลงเหลือ 1/10” ในสถาปัตยกรรม Transformer ข้อจำกัดหลักของการประมวลผลข้อความยาวไม่ใช่การคำนวณ แต่คือ KV Cache ที่จัดเก็บข้อมูลบริบทซึ่งใช้หน่วยความจำ GPU จำนวนมาก DeepSeek ดูเหมือนจะบรรลุเทคโนโลยีการรวมกลุ่ม KV Cache แบบข้ามคำขอและแบบสากลในระดับระบบ (เช่น รุ่นที่พัฒนาต่อจาก RadixAttention) เมื่อคำขอพร้อมกันจากผู้ใช้นับไม่ถ้วนมีการตั้งค่าระบบหรือฐานความรู้พื้นฐานเดียวกัน โมเดลจะไม่ต้องคำนวณ Token เหล่านี้ซ้ำอีก แต่สามารถอ่านโดยตรงจากหน่วยความจำหรือแม้แต่จากบ่อน้ำหน่วยความจำ GPU แบบกระจาย ทำให้ต้นทุนขอบเขตของการป้อนข้อมูลแบบข้อความยาวเข้าใกล้ศูนย์
ธุรกิจโลจิสติกส์: แลกกำไรเพื่อพื้นที่ สร้างใหม่ซึ่งแนวป้องกันระบบนิเวศ
「ME News智库」เชื่อว่า กลยุทธ์ส่วนลดจำกัดเวลาและราคาต่ำสุดของ DeepSeek มีจุดประสงค์ทางธุรกิจที่ชัดเจนและเด็ดขาด:
ก่อนอื่น ทำลายระบบนิเวศการปรับแต่งแบบห่อหุ้มให้สิ้นซาก เพื่อบังคับให้เกิดการระเบิดของแอปพลิเคชันที่สร้างขึ้นมาเพื่อ AI โดยเฉพาะ เมื่อต้นทุนในการเรียกใช้โมเดลพื้นฐานที่ทรงพลังที่สุดเข้าใกล้ศูนย์อย่างไม่มีที่สิ้นสุด การใช้เงินจำนวนมากในการฝึกหรือปรับแต่งโมเดลขนาดเล็กของตัวเองในอุตสาหกรรมเฉพาะจะไม่มีความหมายทางเศรษฐศาสตร์อีกต่อไป DeepSeek กำลังใช้ราคาต่ำเพื่อดึงดูดนักพัฒนา AI ทั้งหมดในสังคมให้เข้ามาอยู่ในระบบนิเวศ API ของตน ทำให้มันกลายเป็น “สาธารณูปโภคพื้นฐานของยุค AI” แบบเดียวกับ Amazon AWS หรือ Microsoft Azure
ถัดมา คือยุคฟ้าสางของการระเบิดของตัวแทนอัจฉริยะ (Agent) การใช้งานแบบตัวแทนที่แท้จริงต้องการให้โมเดลดำเนินการคิดวิเคราะห์ด้วยตนเอง ทบทวน วางแผน และเรียกใช้งานแบบวนซ้ำหลายรอบ (Loop) ในกระบวนการนี้ จะเกิดการใช้ Token แบบแฝงจำนวนมาก การใช้ API ที่มีราคาแพงคืออุปสรรคใหญ่ที่สุดต่อการแพร่หลายของตัวแทนอัจฉริยะ DeepSeek ได้ลดราคาการเข้าถึงแคชให้เหลือเพียง 0.0037 ดอลลาร์สหรัฐ ซึ่งจริงๆ แล้วกำลังสร้างความเป็นไปได้ทางเศรษฐกิจสำหรับ “การให้ AI วิ่งวนหนึ่งหมื่นรอบ” ผู้ที่ให้ต้นทุนในการทดลองผิดพลาดที่ต่ำที่สุด จะเป็นผู้สร้างสรรค์ซูเปอร์แอปพลิเคชันแบบ AI-native ที่ยิ่งใหญ่ที่สุด
ผลกระทบและแนวโน้มอุตสาหกรรม: จากการแข่งขันแบบ “โมเดล” สู่การแข่งขันแบบ “ระบบนิเวศ”
เพื่อแสดงให้เห็นอย่างชัดเจนถึงผลกระทบของความเปลี่ยนแปลงราคาต่อการตัดสินใจขององค์กร เราได้ดำเนินการจำลองต้นทุนของการใช้งานในระดับองค์กร
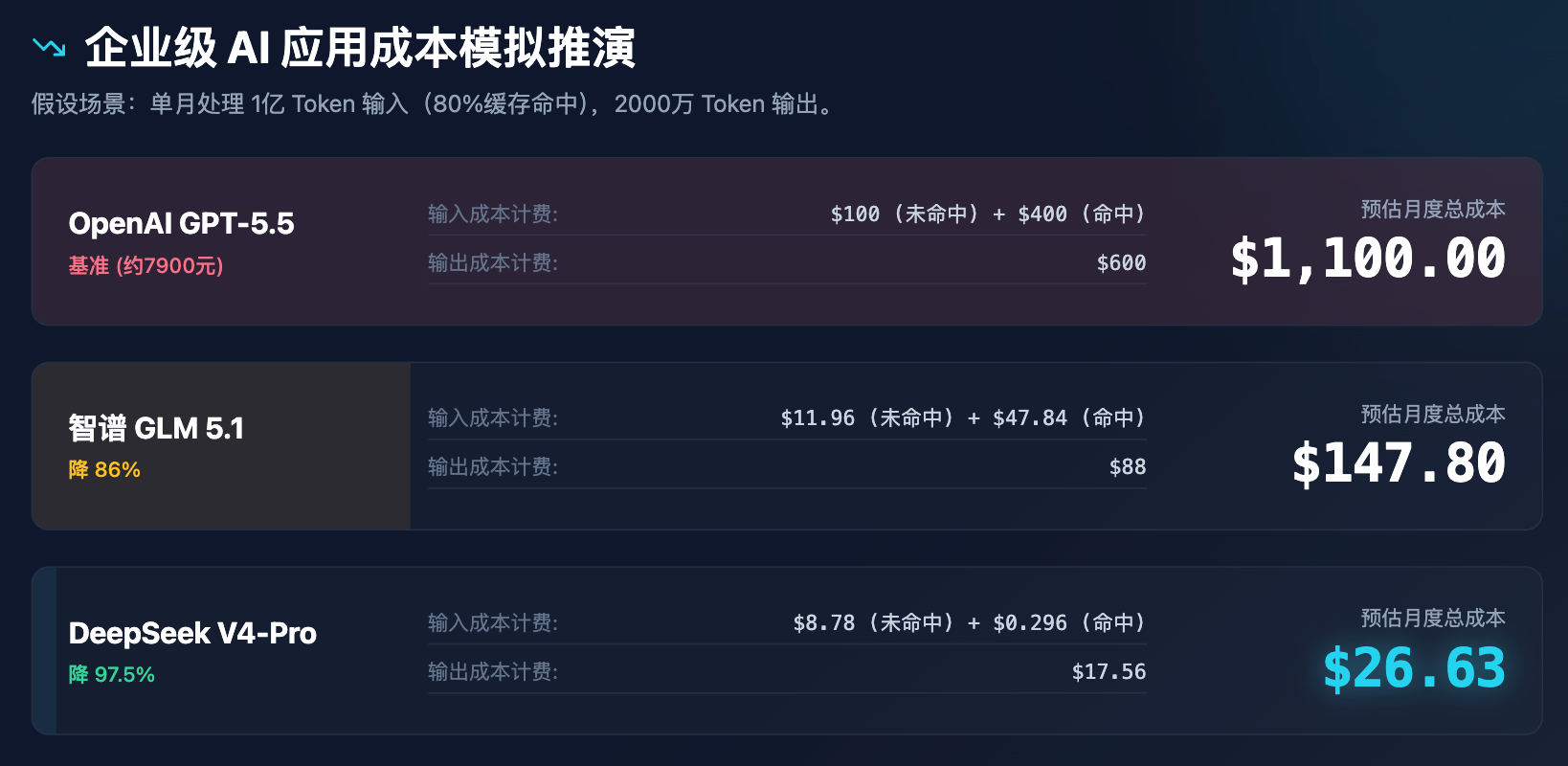
ตารางที่ 3: การวิเคราะห์จำลองต้นทุนการใช้งาน AI ระดับองค์กร (สมมติว่าประมวลผล Token ขาเข้า 100 ล้านต่อเดือน และ Token ขาออก 20 ล้านต่อเดือน)
ผ่านการจำลองข้างต้น สามารถเห็นได้อย่างชัดเจนว่า การกำหนดราคาของ DeepSeek ไม่เพียงแต่ลดราคา แต่ยังกำลังรีโมเดลโมเดลต้นทุน ด้วยต้นทุนน้อยกว่า 30 ดอลลาร์สหรัฐต่อเดือน สามารถรองรับความต้องการทั้งหมดขององค์กรขนาดกลาง ได้แก่ การช่วยเหลือด้านบริการลูกค้า การวิเคราะห์เอกสาร และการตรวจสอบโค้ด ซึ่งจะก่อให้เกิดปฏิกิริยาลูกโซ่ต่างๆ:
- การเปลี่ยนแปลงพื้นฐานของตรรกะการลงทุนด้าน AI: ทุนจะสูญเสียความสนใจอย่างสมบูรณ์ในการสร้างโมเดลขนาดใหญ่ทั่วไปอีกครั้ง นอกเหนือจากกลุ่มรัฐหรือผู้เล่นอินเทอร์เน็ตรายใหญ่เพียงไม่กี่ราย ประตูสำหรับโมเดลพื้นฐานขนาดใหญ่ทั่วไปได้ถูกเชื่อมติดแน่นแล้ว การลงทุนในอนาคตจะไหลเวียนอย่างครอบคลุมไปยังชั้นแอปพลิเคชัน (Application Layer) และตัวกลางโครงสร้างพื้นฐาน (ตัวเชื่อมต่อโครงสร้างพื้นฐาน, AI gateway ฯลฯ)
- กลยุทธ์การกำหนดเส้นทางแบบหลายโมเดล (LLM Routing) กลายเป็นมาตรฐาน: บริษัทจะไม่ยึดติดกับโมเดลเดียวอีกต่อไป ระบบจะจัดสรรงานอัตโนมัติตามความซับซ้อนของงาน ตัวอย่างเช่น 90% ของการทำความสะอาดข้อมูลรายวันและการจัดหมวดหมู่แบบง่ายจะถูกส่งให้ DeepSeek-V4-Flash หรือ Step 3.5 Flash ดำเนินการด้วยต้นทุนต่ำมาก; ส่วน 10% ของการให้เหตุผลเชิงตรรกะที่ซับซ้อนและการสร้างรายงานผู้บริหารจะเรียกใช้ DeepSeek-V4-Pro หรือเรียกใช้ GPT-5.5 ตามความต้องการ
- แอปพลิเคชันสำหรับข้อความยาวกำลังเข้าสู่จุดเปลี่ยนเชิงพาณิชย์ที่แท้จริง: ก่อนหน้านี้ การอัปโหลดรายงานทางการเงินหลายล้านตัวอักษรเพื่อให้ AI สรุปดูเหมือนเป็นเรื่องที่น่าพึงพอใจ แต่ค่าใช้จ่าย API ที่แต่ละครั้งสูงถึงไม่กี่ดอลลาร์ทำให้ธุรกิจ B2B ละเว้นไป พร้อมกับราคาการเข้าถึงแคชอินพุตที่ลดลงเหลือระดับ 0.02 หยวนจีนต่อหนึ่งล้านโทเค็น การอ่านเอกสารทั้งหมดของคลังข้อมูลและมีปฏิสัมพันธ์แบบเรียลไทม์จะกลายเป็นฟีเจอร์มาตรฐานในซอฟต์แวร์ OA และ ERP ของทุกองค์กร
ข้อสรุปและคำแนะนำเชิงกลยุทธ์
พายุลดราคาในเดือนเมษายน 2026 ได้ทำเครื่องหมายการจากไปอย่างเป็นทางการของยุคโรแมนติกคลาสสิกของอุตสาหกรรมโมเดลขนาดใหญ่ ซึ่งเคยเน้นการแข่งขันด้านพารามิเตอร์และการแสดงผลคะแนน ไปสู่ยุคอุตสาหกรรมที่โหดเหี้ยมซึ่งเน้นการแข่งขันด้านต้นทุน การแย่งชิงพลังการคำนวณ และการครองระบบนิเวศ DeepSeek ผ่านกลยุทธ์การตั้งราคาที่กดดันอย่างสุดขีด ไม่เพียงแต่แสดงให้โลกเห็นถึงความเชี่ยวชาญอันลึกซึ้งของบริษัทปัญญาประดิษฐ์จีนในด้านวิศวกรรมโมเดล แต่ยังได้กระตุ้นอย่างตั้งใจให้ฟองสบู่ราคาสูงเกินจริงของพลังการคำนวณปัญญาประดิษฐ์ระเบิดลง
สำหรับเรื่องนี้ 「ME News智库」มีข้อเสนอแนะสามประการ:
- สำหรับนักพัฒนาแอปพลิเคชัน: ละทิ้งความกลัวต่อค่าใช้จ่ายในการเรียกใช้โมเดลขนาดใหญ่ หยุดการสร้างและปรับแต่งโมเดลพื้นฐานที่มีพารามิเตอร์น้อยกว่าหมื่นล้านทันที และนำทรัพยากรการพัฒนาทั้งหมดไปใช้กับประสบการณ์ผลิตภัณฑ์ การปรับให้เข้ากับอุปกรณ์ปลายทาง การสร้างอุปสรรคข้อมูลเฉพาะตัว และการปรับแต่งกระบวนการทำงานของ Agent ใช้ประโยชน์จากโอกาส “พลังการประมวลผลปัญญาประดิษฐ์ราคาถูกแต่ทรงพลัง” ครั้งนี้เพื่อครองพื้นที่ใช้งานอย่างรวดเร็ว
- สำหรับซีไอโอ/ซีทีโอขององค์กรดั้งเดิม: ทบทวนกลยุทธ์การนำปัญญาประดิษฐ์มาใช้ในองค์กรใหม่ โครงการต่างๆ เช่น ระบบตอบคำถามจากฐานความรู้ บริการลูกค้าอัตโนมัติ และโค้ด Copilot ที่เคยถูกเลื่อนออกไปเนื่องจากพิจารณาจากต้นทุน ตอนนี้มี ROI (อัตราผลตอบแทนการลงทุน) สูงมากภายใต้ราคา API ปัจจุบัน แนะนำให้นำแพลตฟอร์ม LLMOps ที่สุกงอมมาใช้ เพื่อสร้างเกตเวย์ปัญญาประดิษฐ์ระดับองค์กร ซึ่งจะช่วยเชื่อมต่อกับโมเดลที่มีประสิทธิภาพทางต้นทุนสูงสุดได้อย่างยืดหยุ่น
- สำหรับคู่แข่งที่ใช้โมเดลพื้นฐาน: ต้องละทิ้งกลยุทธ์การตามรอย ในการเผชิญกับสงครามราคา ต้องเลือกหนึ่งในสองทาง: Either ปรับปรุงการประสานงานระหว่างชิปและเฟรมเวิร์กให้สุดขั้วเพื่อลดต้นทุนให้ต่ำกว่าเดิม หรือสร้างกำแพงทางเทคโนโลยีที่ไม่สามารถแทนที่ได้ในด้านที่แตกต่าง เช่น ปัญญาเชิงร่างกาย หลายโมดัลแบบดั้งเดิม (การสร้างวิดีโอ/3D) และการให้เหตุผลเชิงลึกเฉพาะอุตสาหกรรม โมเดลภาษาขนาดใหญ่แบบธรรมดาได้หมดทางออกแล้ว
แบบจำลองขนาดใหญ่ไม่ใช่เทพเจ้าที่ถูกประดิษฐานไว้ในห้องแล็บอีกต่อไป มันกำลังร่วงหล่นจากบัลลังก์ด้วยความเร็วที่ไม่เคยมีมาก่อน และกลายเป็นกระแสคลื่นยักษ์ที่ขับเคลื่อนปัญญาของทุกสิ่ง และทั้งหมดนี้ เพิ่งเริ่มต้นขึ้นเท่านั้น
อ้างอิงจาก:
- OpenRouter. (2026). ฐานข้อมูลเปรียบเทียบราคา API.
- ประกาศอย่างเป็นทางการจาก DeepSeek (25 เมษายน 2026) แผนส่วนลดจำกัดเวลาสำหรับ API DeepSeek-V4-Pro.
- ประกาศอย่างเป็นทางการจาก DeepSeek. (2026, เมษายน 26) การเข้าถึงพลังการประมวลผลอย่างทั่วถึงในยุคโมเดลขนาดใหญ่: แผนการปรับราคาการเข้าถึงแคช API แบบทั่วโลก.