










ผู้เขียนต้นฉบับ: KarenZ, Foresight News
วันที่ 20 มีนาคม 2026 มีการสนทนาที่ไม่ธรรมดาในพอดีคของ All-In Ventures
นักลงทุนด้านการลงทุนเชิงเสี่ยง Chamath Palihapitiya ได้ส่งต่อหัวข้อให้กับซีอีโอของ NVIDIA ฮวง เหรินซวิน โดยกล่าวว่าบน Bittensor มีโครงการหนึ่งที่ “บรรลุความสำเร็จทางเทคนิคที่ค่อนข้างบ้าบิ่น” โดยการฝึกโมเดลภาษาขนาดใหญ่บนอินเทอร์เน็ตด้วยพลังการประมวลผลแบบกระจายศูนย์ ทั้งหมดโดยไม่มีศูนย์ข้อมูลแบบรวมศูนย์ใดๆ เข้ามาเกี่ยวข้อง
ฮวง เหรินซวีไม่ได้หลีกเลี่ยงเรื่องนี้ เขาเปรียบเทียบมันกับ “เวอร์ชันสมัยใหม่ของ Folding@home” ซึ่งเป็นโครงการแบบกระจายที่ในช่วงปี 2000 ทำให้ผู้ใช้ทั่วไปสามารถบริจาคพลังการประมวลผลที่ไม่ได้ใช้งานเพื่อร่วมกันแก้ปัญหาการพับโปรตีน
ก่อนหน้านี้เมื่อ 4 วันก่อน เมื่อวันที่ 16 มีนาคม แจ็ค คลาร์ก ผู้ร่วมก่อตั้ง Anthropic ได้เน้นย้ำและอ้างอิงความก้าวหน้าครั้งสำคัญนี้อย่างกว้างขวางในรายงานความคืบหน้าด้าน AI: ซับเน็ตของระบบนิเวศ Bittensor Templar (SN3) ประสบความสำเร็จในการฝึกโมเดลขนาดใหญ่ 72 พันล้านพารามิเตอร์ (Covenant 72B) แบบกระจาย และประสิทธิภาพของโมเดลเทียบเท่ากับ LLaMA-2 ที่ Meta เปิดตัวในปี 2023
แจ็ค คลาร์ก ตั้งชื่อหัวข้อนี้ว่า “ท้าทายการเมืองเศรษฐศาสตร์ของ AI ผ่านการฝึกแบบกระจาย” และเน้นในวิเคราะห์ของเขาว่า นี่เป็นเทคโนโลยีที่ควรติดตามอย่างต่อเนื่อง—he สามารถจินตนาการถึงอนาคตที่อุปกรณ์ปลายทางใช้โมเดลที่ฝึกด้วยวิธีการกระจายอย่างแพร่หลาย ขณะที่ AI บนคลาวด์ยังคงดำเนินการโมเดลขนาดใหญ่แบบเป็นกรรมสิทธิ์
การตอบสนองของตลาดช้าเล็กน้อยแต่รุนแรงมาก: SN3 เพิ่มขึ้นเกิน 440% ในเดือนที่ผ่านมา และเกิน 340% ในสองสัปดาห์ที่ผ่านมา โดยมีมูลค่าตลาดอยู่ที่ 130 ล้านดอลลาร์สหรัฐ การระเบิดของเรื่องราวเกี่ยวกับซับเน็ตจะส่งผลกระทบโดยตรงเป็นแรงกดดันในการซื้อ TAO ดังนั้น TAO จึงพุ่งขึ้นอย่างรวดเร็ว แตะระดับสูงสุดที่ 377 ดอลลาร์สหรัฐ เพิ่มขึ้นเป็นสองเท่าในเดือนที่ผ่านมา และมี FDV อยู่ที่ประมาณ 7.5 พันล้านดอลลาร์สหรัฐ
คำถามมาแล้ว: SN3 ได้ทำอะไรไปบ้าง? ทำไมถึงถูกผลักให้อยู่ในจุดศูนย์กลางของความสนใจ? เรื่องราวคุณค่าของการฝึกแบบกระจายและการปัญญาประดิษฐ์แบบกระจายศูนย์จะพัฒนาไปอย่างไร?
โมเดล 72B นั้น
เพื่อตอบคำถามนี้ ต้องดูผลประกอบการของ SN3 ก่อน
วันที่ 10 มีนาคม 2026 ทีม Covenant AI ได้เผยแพร่รายงานเทคนิคบน arXiv อย่างเป็นทางการเพื่อประกาศว่า Covenant-72B ได้รับการฝึกเสร็จสมบูรณ์แล้ว นี่คือโมเดลภาษาขนาดใหญ่ที่มีพารามิเตอร์ 72 พันล้านตัว โดยใช้โหนดอิสระมากกว่า 70 โหนด (ประมาณ 20 โหนดที่ซิงโครไนซ์ในแต่ละรอบ โดยแต่ละโหนดติดตั้ง GPU B200 8 ตัว) และได้รับการฝึกแบบล่วงหน้าบนข้อมูลตัวอย่างประมาณ 1.1 ล้านล้านโทเค็น
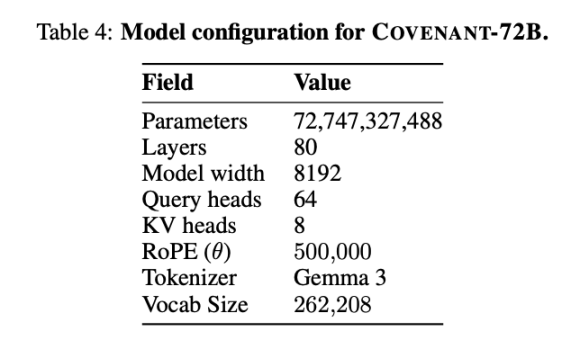
Templar ได้ให้ข้อมูลบางส่วนเกี่ยวกับการทดสอบมาตรฐาน โดยที่ LLaMA-2-70B ที่ใช้เป็นตัวเปรียบเทียบเป็นโมเดลขนาดใหญ่ที่ Meta เปิดตัวในปี 2023 ตามที่ Jack Clark ผู้ร่วมก่อตั้ง Anthropic กล่าวไว้ Covenant-72B อาจล้าสมัยเมื่อเทียบกับปี 2026 คะแนน 67.1 ของ Covenant-72B บน MMLU ใกล้เคียงกับ LLaMA-2-70B ที่ Meta เปิดตัวในปี 2023 (65.6 คะแนน)
ในขณะที่รุ่นล้ำสมัยปี 2026 — ไม่ว่าจะเป็นซีรีส์ GPT, Claude หรือ Gemini — ได้รับการฝึกอบรมด้วยพารามิเตอร์ที่มากกว่า 100 พันล้านแล้วบน GPU หลายแสนหน่วย ช่องว่างด้านการให้เหตุผล รหัส และคณิตศาสตร์เป็นปัญหาในระดับจำนวนครั้ง ไม่ใช่เปอร์เซ็นต์ ความแตกต่างที่แท้จริงนี้ไม่ควรถูกกลืนหายไปโดยอารมณ์ของตลาด
แต่เมื่อพิจารณาในบริบทของ "การฝึกอบรมด้วยพลังการประมวลผลกระจายบนอินเทอร์เน็ตแบบเปิด" ความหมายจะแตกต่างออกไปอย่างสิ้นเชิง
เปรียบเทียบกัน: INTELLECT-1 (ผลิตโดยทีม Prime Intellect, 10 พันล้านพารามิเตอร์) ได้คะแนน MMLU 32.7 ในขณะที่โครงการฝึกแบบกระจายอีกโครงการหนึ่งที่ดำเนินการกับผู้เข้าร่วมในรายการอนุญาตคือ Psyche Consilience (40 พันล้านพารามิเตอร์) ได้คะแนน 24.2 Covenant-72B ด้วยขนาด 72B และคะแนน MMLU 67.1 ถือเป็นตัวเลขที่โดดเด่นในเส้นทางการฝึกแบบกระจาย
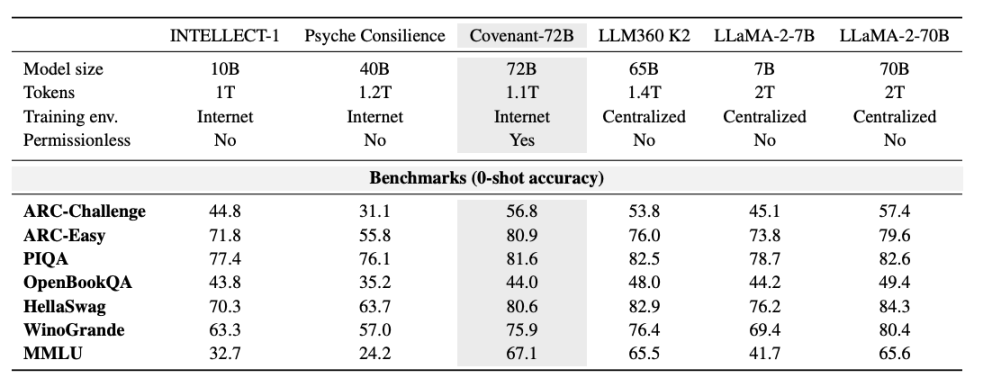
ที่สำคัญกว่านั้น ครั้งนี้เป็นการฝึกแบบ "ไม่ต้องขออนุญาต" ทุกคนสามารถเชื่อมต่อและเป็นโหนดผู้เข้าร่วมได้ โดยไม่จำเป็นต้องผ่านการตรวจสอบล่วงหน้าหรืออยู่ในรายการอนุญาต มากกว่า 70 โหนดอิสระเข้าร่วมในการอัปเดตโมเดล โดยเชื่อมต่อและบริจาคพลังการประมวลผลจากทั่วทุกมุมโลก
ฮuang Renxun พูดอะไร และไม่ได้พูดอะไร
การย้อนกลับไปที่รายละเอียดของการสนทนาในพอดีครั้งนั้น จะช่วยในการปรับความเข้าใจของสาธารณชนเกี่ยวกับการ “รับรอง” ครั้งนี้
ชามาธ ปาลิฮาปิติยา ได้นำเสนอความสำเร็จทางเทคโนโลยีของ Bittensor ให้กับฮวง เรินซุน ในระหว่างการสนทนา โดยอธิบายว่าเป็นการฝึกโมเดล Llama ด้วยพลังการประมวลผลแบบกระจาย ซึ่งกระบวนการนี้ “กระจายอย่างสมบูรณ์และรักษาสถานะไว้” ฮวง เรินซุน ตอบกลับโดยเปรียบเทียบสิ่งนี้กับ “Folding@home ยุคสมัยใหม่” และขยายความถึงความจำเป็นในการมีอยู่พร้อมกันของโมเดลแบบเปิดแหล่งที่มาและโมเดลแบบเป็นกรรมสิทธิ์
ควรสังเกตว่าฮวง เหรินซวีไม่ได้กล่าวถึงโทเค็นของ Bittensor หรือผลกระทบด้านการลงทุนใดๆ โดยตรง รวมถึงไม่ได้พูดถึงการฝึกอบรม AI แบบกระจายศูนย์เพิ่มเติม
เข้าใจซับเน็ตของ Bittensor และ SN3
เพื่อเข้าใจการทะลุของ SN3 ก่อนอื่นต้องเข้าใจตรรกะการทำงานของ Bittensor และเครือข่ายย่อยของมัน โดยสรุปง่ายๆ Bittensor สามารถมองว่าเป็นบล็อกเชนและแพลตฟอร์ม AI หนึ่งเดียว ส่วนเครือข่ายย่อยแต่ละอันก็เหมือนกับ "สายการผลิต AI" ที่แยกจากกัน แต่ละอันมีภารกิจหลักที่ชัดเจน ออกแบบกลไกการให้รางวัล และร่วมกันสร้างระบบนิเวศ AI แบบกระจายศูนย์
กระบวนการดำเนินงานชัดเจนและเป็นแบบกระจายศูนย์: เจ้าของซับเน็ตกำหนดเป้าหมายซับเน็ตและเขียนโมเดลแรงจูงใจ; ผู้ขุดให้พลังการประมวลผลภายในซับเน็ตและดำเนินงานที่เกี่ยวข้องกับ AI (เช่น การให้เหตุผล การฝึกอบรม การจัดเก็บ ฯลฯ); ผู้ตรวจสอบให้คะแนนการมีส่วนร่วมของผู้ขุดและอัปโหลดคะแนนไปยังชั้นการให้ความเห็นชอบของ Bittensor; สุดท้าย อัลกอริธึม Yuma ของ Bittensor จะแจกจ่ายผลตอบแทนที่เหมาะสมให้กับผู้เข้าร่วมซับเน็ตตามรางวัลสะสมของแต่ละซับเน็ต
ปัจจุบัน Bittensor มีเครือข่ายย่อย 128 แห่ง ครอบคลุมงาน AI ต่างๆ เช่น การให้เหตุผล บริการคลาวด์ AI แบบไม่ใช้เซิร์ฟเวอร์ ภาพ การติดป้ายข้อมูล การเรียนรู้แบบเสริมแรง การจัดเก็บ และการคำนวณ
SN3 เป็นหนึ่งในเครือข่ายย่อยเหล่านั้น มันไม่ได้ทำหน้าที่เป็นชั้นแอปพลิเคชัน ไม่เช่า API แบบโมเดลขนาดใหญ่ที่มีอยู่แล้ว แต่กลับมุ่งเป้าไปที่หัวใจของอุตสาหกรรม AI ซึ่งมีต้นทุนสูงที่สุดและปิดกั้นที่สุดหนึ่งแห่ง: การฝึกอบรมโมเดลขนาดใหญ่โดยตรง
SN3 ต้องการใช้เครือข่าย Bittensor เพื่อประสานทรัพยากรการคำนวณที่ไม่เหมือนกันสำหรับการฝึกแบบกระจาย ผ่านการฝึกโมเดลขนาดใหญ่แบบกระจายที่มีแรงจูงใจ เพื่อพิสูจน์ว่าสามารถฝึกโมเดลพื้นฐานที่แข็งแกร่งได้โดยไม่จำเป็นต้องใช้คลัสเตอร์ซูเปอร์คอมพิวเตอร์แบบศูนย์กลางที่มีต้นทุนสูง จุดดึงดูดหลักอยู่ที่ “ความเท่าเทียม” — ทำลายการผูกขาดทรัพยากรของการฝึกแบบศูนย์กลาง ทำให้บุคคลทั่วไปหรือองค์กรขนาดเล็กและกลางสามารถมีส่วนร่วมในการฝึกโมเดลขนาดใหญ่ได้ พร้อมลดต้นทุนการฝึกโดยใช้พลังการคำนวณแบบกระจาย
แรงขับเคลื่อนหลักในการพัฒนา SN3 คือ Templar ซึ่งได้รับการสนับสนุนโดยทีมวิจัย Covenant Labs ทีมนี้ยังดำเนินการสองเครือข่ายย่อยเพิ่มเติมคือ Basilica (SN39) ที่เน้นบริการคำนวณ และ Grail (SN81) ที่เน้นการฝึกอบรมหลังการเรียนรู้แบบ RL และการประเมินโมเดล เครือข่ายทั้งสามแห่งนี้สร้างการบูรณาการแนวตั้ง ครอบคลุมกระบวนการทั้งหมดตั้งแต่การฝึกอบรมเบื้องต้นจนถึงการปรับแต่งความสอดคล้องของโมเดลขนาดใหญ่ สร้างระบบนิเวศการฝึกอบรมโมเดลขนาดใหญ่แบบกระจายศูนย์อย่างสมบูรณ์
โดยเฉพาะอย่างยิ่ง ผู้ขุดจะบริจาคทรัพยากรการคำนวณเพื่ออัปโหลดการอัปเดตเกรดient (ทิศทางและระดับของการปรับพารามิเตอร์แบบจำลอง) ลงในเครือข่าย; ผู้ตรวจสอบจะประเมินคุณภาพของผลงานแต่ละผู้ขุด และให้คะแนนบนบล็อกเชนตามระดับการปรับปรุงความผิดพลาด ผลลัพธ์จะกำหนดน้ำหนักการให้รางวัลและกระจายอัตโนมัติ โดยไม่ต้องพึ่งพาบุคคลที่สาม
กุญแจสำคัญของการออกแบบกลไกการให้รางวัลคือ การให้รางวัลเชื่อมโยงโดยตรงกับ “ระดับที่การมีส่วนร่วมของคุณช่วยปรับปรุงโมเดลให้ดีขึ้น” ไม่ใช่แค่ปริมาณพลังการคำนวณที่ใช้งาน ซึ่งแก้ปัญหาที่ยากที่สุดในบริบทแบบกระจายศูนย์อย่างแท้จริง: วิธีป้องกันไม่ให้ผู้ขุดหลีกเลี่ยงงาน
Covenant-72B แก้ไขปัญหาประสิทธิภาพการสื่อสารและการจูงใจที่สอดคล้องกันได้อย่างไร
การให้โหนดหลายสิบโหนดที่ไม่ไว้วางใจซึ่งกันและกัน มีฮาร์ดแวร์ต่างกัน และคุณภาพเครือข่ายไม่สม่ำเสมอ ร่วมกันฝึกโมเดลเดียวกัน มีความท้าทายสองประการ: หนึ่งคือประสิทธิภาพการสื่อสาร ซึ่งแผนการฝึกแบบกระจายมาตรฐานต้องการการเชื่อมต่อระหว่างโหนดที่มีแบนด์วิดธ์สูงและหน่วงเวลาต่ำ; สองคือความสอดคล้องของแรงจูงใจ วิธีใดที่จะป้องกันไม่ให้โหนดที่มีเจตนาไม่ดีส่งเกรเดียนต์ที่ผิดพลาด? จะรับประกันได้อย่างไรว่าผู้เข้าร่วมทุกคนกำลังฝึกอย่างจริงจัง ไม่ใช่ลอกผลลัพธ์จากผู้อื่น?
SN3 แก้ไขปัญหาทั้งสองข้อนี้ด้วยองค์ประกอบหลักสองประการ: SparseLoCo และ Gauntlet
SparseLoCo แก้ปัญหาประสิทธิภาพการสื่อสาร การฝึกแบบกระจายแบบดั้งเดิมต้องซิงโครไนซ์กราดิเอนต์ทั้งหมดในแต่ละขั้นตอน ซึ่งมีปริมาณข้อมูลมหาศาล SparseLoCo ใช้วิธีการที่ว่า แต่ละโหนดจะดำเนินการเพิ่มประสิทธิภาพภายใน 30 ขั้นตอน (AdamW) แล้วบีบอัด 'กราดิเอนต์เทียม' ที่สร้างขึ้นก่อนส่งไปยังโหนดอื่นๆ วิธีการบีบอัดรวมถึงการลดความหนาแน่นแบบ Top-k (เก็บเฉพาะส่วนกราดิเอนต์ที่สำคัญที่สุด) การส่งคืนข้อผิดพลาด (เก็บส่วนที่ถูกตัดทิ้งไว้เพื่อสะสมในรอบถัดไป) และการควอนไทซ์ 2 บิต สุดท้ายอัตราการบีบอัดเกิน 146 เท่า
พูดอีกแบบคือ สิ่งที่เคยต้องส่ง 100MB ตอนนี้แค่ต้องการน้อยกว่า 1MB
สิ่งนี้ทำให้ระบบสามารถรักษาการใช้งานการคำนวณไว้ที่ประมาณ 94.5% ภายใต้ข้อจำกัดแบนด์วิธของอินเทอร์เน็ตทั่วไป (อัตราการส่งขึ้น 110 Mbps, อัตราการรับลง 500 Mbps) — ด้วยโหนด 20 โหนด แต่ละโหนดมี B200 8 ตัว และใช้เวลาเพียง 70 วินาทีต่อรอบการสื่อสาร
Gauntlet แก้ปัญหาความสอดคล้องของแรงจูงใจ โดยทำงานบนบล็อกเชน Bittensor (Subnet 3) รับผิดชอบในการตรวจสอบคุณภาพของพีชคณิตเทียมที่โหนดแต่ละแห่งส่งเข้ามา โดยวิธีการคือ: ทดสอบด้วยชุดข้อมูลขนาดเล็กเพื่อดูว่า "เมื่อใช้พีชคณิตของโหนดนี้ ความสูญเสียของโมเดลลดลงเท่าใด" ผลลัพธ์นี้เรียกว่า LossScore ในขณะเดียวกัน ระบบยังตรวจสอบว่าโหนดกำลังฝึกด้วยข้อมูลที่ได้รับมอบหมายจริงหรือไม่ — หากโหนดใดมีการปรับปรุงความสูญเสียบนข้อมูลสุ่มดีกว่าบนข้อมูลที่ได้รับมอบหมาย จะได้คะแนนติดลบ
ในที่สุด แต่ละรอบการฝึกจะเลือกใช้กราเดียนต์จากโหนดที่ได้รับคะแนนสูงสุดเท่านั้นในการรวมกัน โหนดอื่นๆ จะถูกตัดออกจากรอบนั้น ผู้เข้าร่วมที่เกินจำนวนจะถูกเติมเต็มทันทีเพื่อให้ระบบคงความมั่นคง ตลอดกระบวนการฝึกอบรม โดยเฉลี่ยแล้วมีโหนด 16.9 โหนดต่อรอบที่กราเดียนต์ของพวกมันถูกรวมเข้าด้วยกัน และจำนวน ID โหนดที่เข้าร่วมอย่างไม่ซ้ำกันเกิน 70 รายการ
เรื่องราวคุณค่าของ AI แบบกระจายศูนย์กำลังเกิดการเปลี่ยนแปลงอย่างพื้นฐาน
จากมุมมองทางเทคนิคและอุตสาหกรรม เรื่องนี้มีความหมายจริงหลายประการที่ Covenant-72B กำลังเดินไปในทิศทางนั้น
ประการแรก ได้ทำลายสมมติฐานที่ว่า “การฝึกแบบกระจายเหมาะสำหรับโมเดลขนาดเล็กเท่านั้น” แม้ยังห่างไกลจากโมเดลชั้นนำ แต่ได้พิสูจน์ถึงความสามารถในการขยายตัวในทิศทางนี้
ประการที่สอง การมีส่วนร่วมโดยไม่ต้องได้รับอนุญาตเป็นไปได้จริง ซึ่งถูกมองข้ามไป โครงการการฝึกอบรมแบบกระจายก่อนหน้านี้ขึ้นอยู่กับรายการอนุญาต—ผู้เข้าร่วมเท่านั้นที่ผ่านการตรวจสอบจึงจะสามารถบริจาคทรัพยากรการประมวลผลได้ ในครั้งนี้ การฝึกอบรม SN3 ผู้ที่มีทรัพยากรการประมวลผลเพียงพอสามารถเชื่อมต่อได้ทันที โดยกลไกการตรวจสอบจะทำหน้าที่กรองการบริจาคที่เป็นอันตราย นี่คือก้าวสำคัญสู่ความ “เป็นกลางอย่างแท้จริง”
ثالثly กลไก dTAO ของ Bittensor ทำให้การค้นพบมูลค่าของเครือข่ายย่อยเป็นไปได้ dTAO อนุญาตให้เครือข่ายย่อยแต่ละแห่งออกโทเค็น Alpha ของตนเอง โดยใช้กลไก AMM เพื่อให้ตลาดตัดสินว่าเครือข่ายย่อยใดควรได้รับการปล่อย TAO มากขึ้น ซึ่งมอบกลไกการจับมูลค่าที่หยาบแต่มีประสิทธิภาพสำหรับเครือข่ายย่อยเช่น SN3 ที่สร้างผลลัพธ์ที่เป็นรูปธรรม อย่างไรก็ตาม กลไกนี้ยังคงไวซึ่งความเสี่ยงจากเรื่องเล่าและอารมณ์ เนื่องจากคุณภาพของผลลัพธ์การฝึก LLM นั้นยากต่อการประเมินอย่างอิสระโดยผู้เข้าร่วมตลาดทั่วไป
สี่ ความหมายทางการเมืองและเศรษฐกิจของการฝึกอบรม AI แบบกระจายศูนย์ แจ็ค คลาร์ก ใน Import AI ได้ยกประเด็นนี้ขึ้นไปสู่ระดับ “ใครเป็นเจ้าของอนาคตของ AI” ปัจจุบัน การฝึกอบรมโมเดลชั้นนำถูกผูกขาดโดยองค์กรไม่กี่แห่งที่มีศูนย์ข้อมูลขนาดใหญ่ ซึ่งไม่ใช่แค่ปัญหาทางธุรกิจ แต่ยังเป็นปัญหาโครงสร้างอำนาจ หากการฝึกอบรมแบบกระจายศูนย์สามารถบรรลุความก้าวหน้าทางเทคนิคอย่างต่อเนื่อง อาจสร้างระบบนิเวศการพัฒนาที่แท้จริงแบบกระจายศูนย์สำหรับโมเดลบางประเภท (เช่น โมเดลชั้นนำขนาดเล็กในสาขาเฉพาะ) อย่างไรก็ตาม แนวโน้มนี้ยังห่างไกลจากความเป็นจริงในขณะนี้
สรุป: จุดเปลี่ยนที่แท้จริง พร้อมกับปัญหาจริงมากมาย
ฮวน เรินซูน กล่าวว่า สิ่งนี้เหมือนกับ “Folding@home ยุคสมัยใหม่” Folding@home ได้สร้างผลงานที่แท้จริงในด้านการจำลองโมเลกุล แต่ไม่ได้คุกคามตำแหน่งหลักของการวิจัยและพัฒนาของบริษัทยาขนาดใหญ่ การเปรียบเทียบนี้แม่นยำมาก
SN3 ได้ดำเนินการโปรโตคอลสำเร็จและยืนยันทิศทางที่เป็นไปได้ของการฝึกอบรมแบบกระจาย แต่จากมุมมองทางเทคนิคและอุตสาหกรรม ผลลัพธ์ที่มันนำเสนอมาพร้อมกับปัญหาอีกมากมายที่แทบไม่มีใครอยากพูดถึงอย่างจริงจัง:
MMLU 本身ในวงการวิชาการก็เป็นตัวชี้วัดที่มีการถกเถียงกันอย่างมาก เนื่องจากคำถามและคำตอบของฐานข้อมูลอ้างอิงสาธารณะมีความเสี่ยงที่จะรั่วไหลเข้าสู่ชุดข้อมูลการฝึกอบรม ยิ่งไปกว่านั้น การเลือกฐานเปรียบเทียบก็น่าสนใจยิ่งกว่า: โมเดลที่ใช้เป็นเกณฑ์เปรียบเทียบในบทความคือ LLaMA-2-70B และ LLM360 K2 ซึ่งเป็นโมเดลรุ่นเก่าตั้งแต่ปี 2023 ถึง 2024 ในขณะที่คะแนนระหว่าง 65 ถึง 70 ในช่วงเวลานั้น เมื่อถามถึง Grok หรือ DouBao จะถูกจัดอยู่ในระดับกลางถึงล่างและระดับเริ่มต้น และเมื่อพิจารณาจาก Claude ถือว่าล้าหลังอย่างรุนแรง หากนำมันไปวางไว้บนรายการอัปเดตแบบไดนามิกหรือฐานข้อมูลอ้างอิงรุ่นใหม่ที่ออกแบบมาเพื่อต้านทานการปนเปื้อน ข้อสรุปอาจเป็นความจริงมากยิ่งขึ้น
ที่สำคัญกว่านั้น ข้อมูลคุณภาพสูงที่กำหนดขีดจำกัดของโมเดล—เช่น ข้อมูลการสนทนา โค้ด การพิสูจน์ทางคณิตศาสตร์ และเอกสารทางวิทยาศาสตร์—มีแนวโน้มที่จะอยู่ในมือของบริษัทใหญ่ สำนักพิมพ์ และฐานข้อมูลทางวิชาการต่างๆ แม้พลังการคำนวณจะถูกทำให้เป็นประชาธิปไตยแล้ว แต่ด้านข้อมูลยังคงอยู่ในโครงสร้างผูกขาด ความขัดแย้งนี้ยังไม่เคยถูกพูดถึง
เกี่ยวกับความปลอดภัย การเข้าร่วมโดยไม่ต้องได้รับอนุญาตหมายความว่าคุณไม่รู้ว่าโหนดกว่า 70 แห่งเหล่านั้นถูกควบคุมโดยใคร และพวกเขากำลังใช้ข้อมูลอะไรในการฝึกอบรม Gauntlet สามารถกรองเกรเดียนต์ที่ผิดปกติชัดเจน แต่ไม่สามารถป้องกันการปลอมปนข้อมูลที่ละเอียดอ่อน—หากโหนดหนึ่งมีการฝึกอบรมอย่างเป็นระบบในทิศทางของเนื้อหาอันตรายบางประเภท เกรเดียนต์ที่เกิดขึ้นจะมีการเปลี่ยนแปลงอย่างละเอียดอ่อนเพียงพอที่จะผ่านการกรองด้วยคะแนนการสูญเสีย แต่ก่อให้เกิดการเบี่ยงเบนสะสมต่อพฤติกรรมของโมเดล คำถามสุดท้ายคือ: ในบริบทที่มีข้อกำหนดด้านการปฏิบัติตามกฎหมายและความปลอดภัยสูง เช่น การเงิน การแพทย์ และกฎหมาย การใช้โมเดลที่ถูกฝึกโดยโหนดไม่กี่แห่งที่ไม่เปิดเผยตัวตนและแหล่งที่มาของข้อมูลไม่สามารถติดตามย้อนกลับได้ จะก่อให้เกิดความเสี่ยงใดบ้าง?
ยังมีปัญหาเชิงโครงสร้างอีกประการที่ควรพูดตรงไปตรงมา: Covenant-72B ถูกเปิดซอร์สภายใต้ใบอนุญาต Apache 2.0 และไม่ได้ใช้โทเค็น SN3 การถือครองโทเค็น SN3 หมายถึงการได้รับส่วนแบ่งจากผลประโยชน์จากการปล่อยออกที่เกิดจากการผลิตโมเดลใหม่อย่างต่อเนื่องของเครือข่ายย่อยนี้ ไม่ใช่ผลประโยชน์โดยตรงจากการใช้งานโมเดล 价值链นี้ขึ้นอยู่กับการผลิตการฝึกอบรมอย่างต่อเนื่องและการทำงานของกลไกการปล่อยออกของเครือข่าย Bittensor โดยรวม หากการฝึกอบรมในอนาคตหยุดชะงัก หรือผลลัพธ์การฝึกอบรมใหม่ไม่เป็นไปตามความคาดหวัง ตรรกะการประเมินมูลค่าของโทเค็นก็จะอ่อนแอลง
การระบุคำถามเหล่านี้ไม่ได้มีจุดประสงค์เพื่อปฏิเสธความหมายของ Covenant-72B มันพิสูจน์ว่าสิ่งที่เคยถือว่าเป็นไปไม่ได้นั้นสามารถทำได้ ความจริงนี้จะไม่หายไป แต่การทำสำเร็จกับสิ่งที่มันหมายถึง เป็นสองเรื่องที่ต่างกัน
สกุลเงิน SN3 เพิ่มขึ้น 440% ในช่วงหนึ่งเดือนที่ผ่านมา ช่องว่างนี้อาจไม่ใช่เพียงแค่การปั่นราคา แต่เป็นเพราะเรื่องราวมักเคลื่อนไหวเร็วกว่าความเป็นจริง แต่ช่องว่างนี้จะถูกเติมเต็มด้วยความเป็นจริง หรือถูกตลาดปรับตัวและดูดซับไป ขึ้นอยู่กับสิ่งที่ทีม Covenant AI จะส่งมอบต่อไป
สิ่งที่ควรให้ความสนใจคือ Grayscale ได้ยื่นคำขอ ETF สำหรับ TAO ในเดือนมกราคม 2026 ซึ่งบ่งชี้ถึงสัญญาณการเข้าสู่ตลาดของทุนจากสถาบัน นอกจากนี้ ในเดือนธันวาคม 2025 Bittensor จะลดการปล่อย TAO รายวันลงครึ่งหนึ่ง ทำให้การลดลงของอุปทานในเชิงโครงสร้างยังคงดำเนินต่อไป
ลิงก์อ้างอิง:
https://arxiv.org/pdf/2603.08163
https://importai.substack.com/p/importai-449-llms-training-other
https://docs.tplr.ai/
https://systems-analysis.ru/int/MMLU_Benchmark_%E2%80%94_MMLU_%E5%9F%BA%E5%87%86%E6%B5%8B%E8%AF%95