









ช่วงเวลา “Oppenheimer” ของโลก AI จริงๆ แล้วเป็นการจัดฉาก? Claude Mythos ความสามารถในการค้นพบช่องโหว่ 0day ดูเหมือนจะถูก “เกินจริง” ไม่เพียงแต่มีการปนเปื้อนด้วยมนุษย์ แต่ GPT แบบเปิดแหล่งยังสามารถเอาชนะได้อย่างง่ายดาย ในขณะเดียวกัน Opus 4.6 กำลังผ่านช่วงเวลา “ตัดต่อมสมอง” ที่เลวร้ายที่สุด
ผู้เขียนบทความ แหล่งที่มา: ซินจื้อหยวน
Claude Mythos ยังไม่ได้เปิดตัวอย่างแท้จริง แต่ได้ก่อให้เกิดความตื่นตระหนกทั่ววอลล์สตรีท
ในเวลาเพียงหนึ่งคืน หน่วยงานกำกับดูแลการเงินของสหรัฐฯ ได้เรียกประชุมฉุกเฉินกับธนาคารชั้นนำต่างๆ บรรยากาศเต็มไปด้วยความตึงเครียด—
พวกเขาเห็นพ้องต้องกันว่า Mythos เพียงพอที่จะกระตุ้นพายุการโจมตีทางเครือข่ายแบบระบบซึ่งขับเคลื่อนด้วย AI ที่ยังไม่เคยมีมาก่อน

แต่ความจริงคือ ทุกคนถูกหลอก!
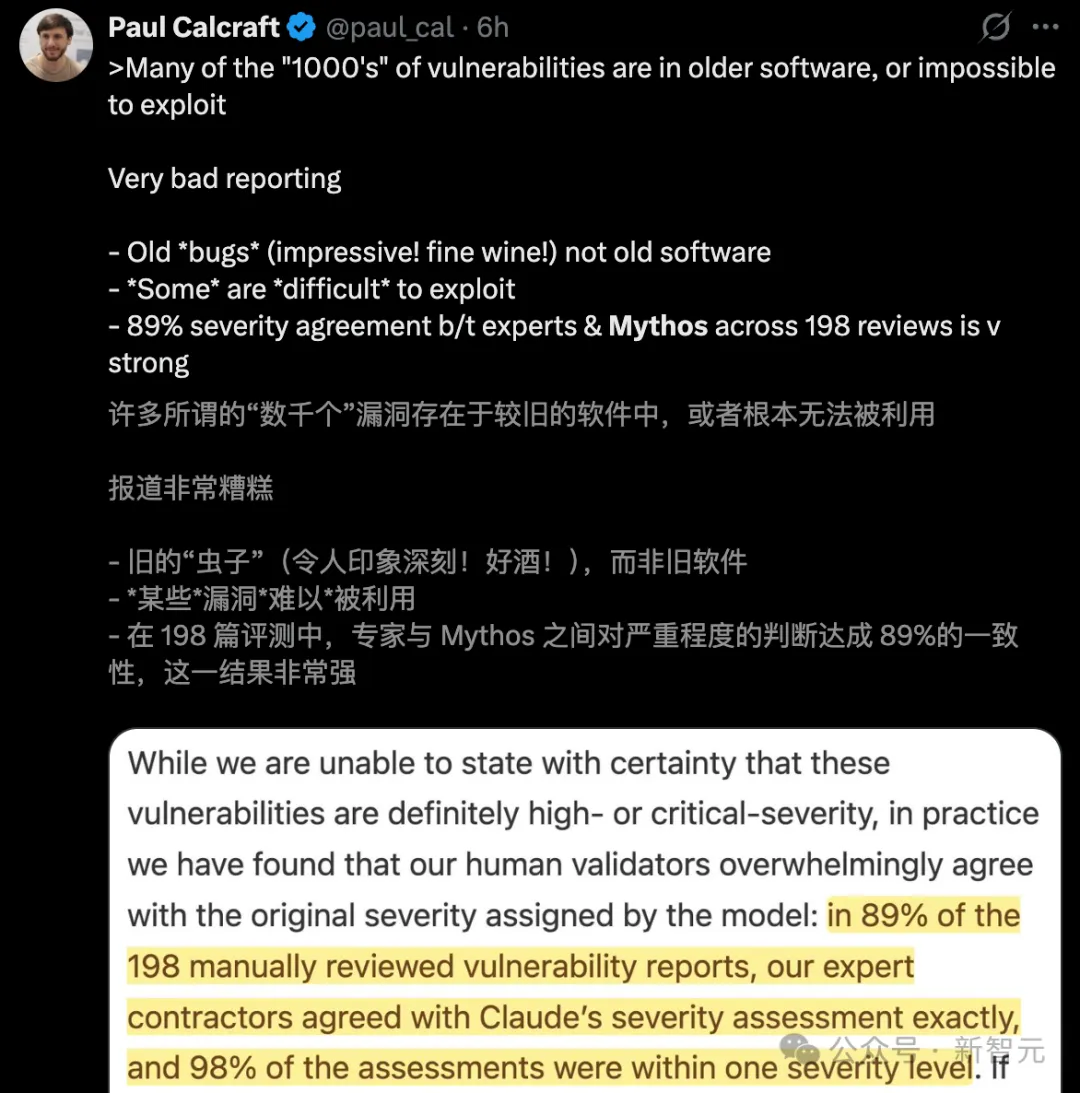
ในจำนวนช่องโหว่นับพันที่ Mythos ค้นพบ ช่องโหว่ส่วนใหญ่ล้วนอยู่ในซอฟต์แวร์รุ่นเก่าที่ไม่สามารถถูกใช้ประโยชน์ได้
แย่กว่านั้น รายงานช่องโหว่ 0day ที่อ้างว่า “ร้ายแรง” กลับอิงเพียงการตรวจสอบด้วยมือ 198 ครั้ง

นักวิจัยจาก AISLE Experiment ได้ทำการทดสอบซ้ำผลลัพธ์ของ Mythos และพบว่า:
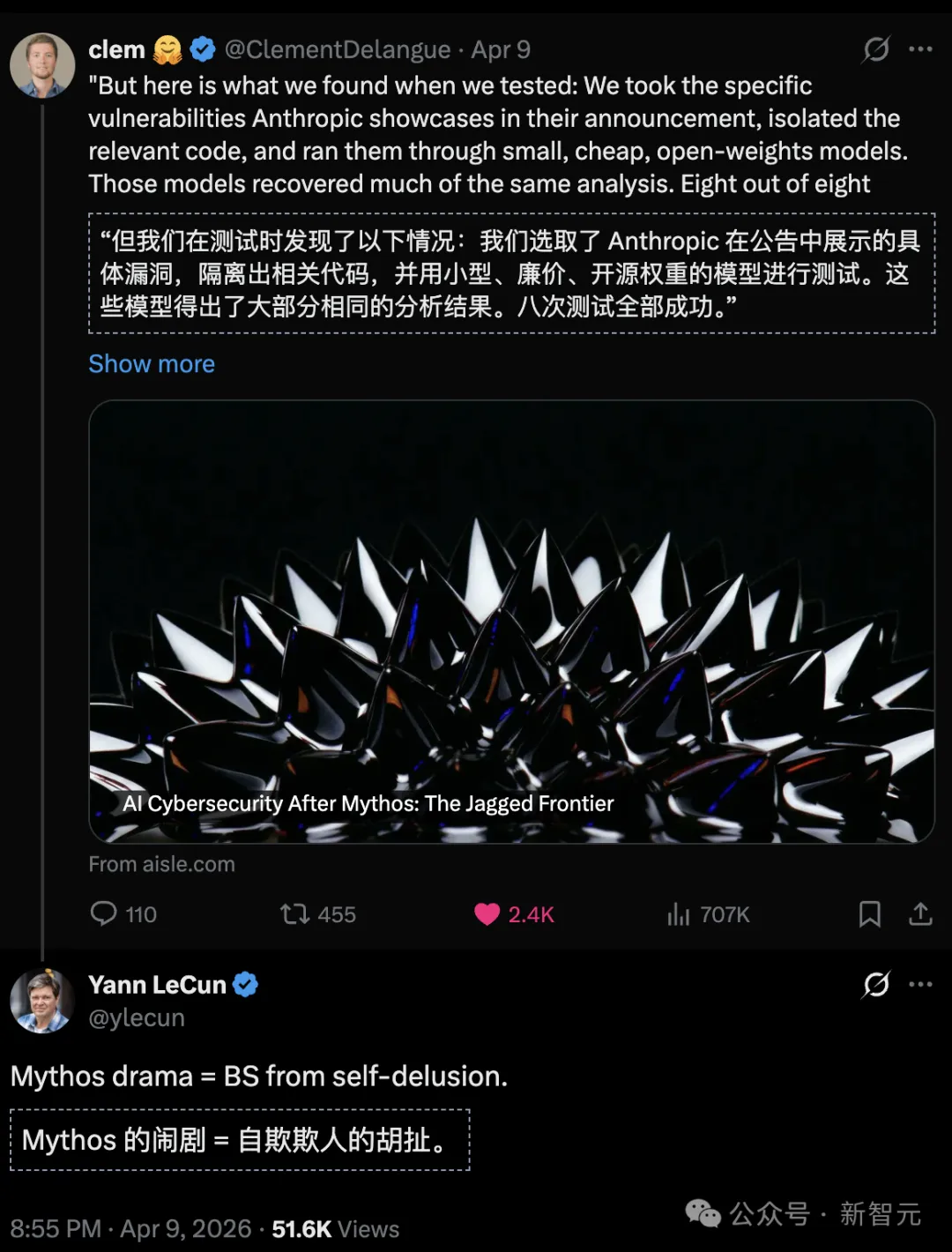
ความสามารถด้านความปลอดภัยของ AI ไม่ได้เพิ่มขึ้นแบบเชิงเส้นตามขนาดของโมเดล แต่แท้จริงแล้วกระจายตัวในรูปแบบ "ฟันเลื่อย"
พวกเขาใช้ GPT-OSS-20b ที่มีพารามิเตอร์เปิดใช้งานเพียง 3.6 พันล้านตัว เพื่อระบุช่องโหว่ระดับแฟลกชิพของ FreeBSD ที่ Mythos ค้นพบอย่างแม่นยำ
การเปิดใช้งานโมเดลที่มีพารามิเตอร์ 5.1 พันล้าน ยังสามารถจำลองตรรกะการวิเคราะห์ช่องโหว่ของ OpenBSD ที่ซ่อนตัวมานาน 27 ปีได้อย่างสำเร็จ

ไม่เพียงแต่ความผิดปกติที่ Mythos พบถูกยกใหญ่เกินจริง แต่อีกด้านหนึ่ง Claude Opus 4.6 ถูกเปิดเผยว่ามีปัญหา “ลดสติปัญญา” อย่างรุนแรง ตอนนี้ถูกพูดถึงกันอย่างมาก
บางรายยังพบว่า Opus 4.6 ยังด้อยกว่า ChatGPT และ Opus 4.5 อีกด้วย
Mythos ถูกยกย่องอย่างมาก โมเดล 36B ค้นพบช่องโหว่ที่มีมานาน 27 ปี
เมื่อไม่กี่วันก่อน Anthropic ได้เปิดตัว Claude Mythos (รุ่นตัวอย่าง) และโครงการ Project Glasswing อย่างเป็นทางการ
ในเอกสารระบบขนาด 244 หน้า พวกเขาอ้างว่า—
Mythos ได้ค้นพบช่องโหว่ 0day นับพันๆ ช่องโหว่ด้วยตนเอง รวมถึงบั๊กเก่าที่ซ่อนอยู่ใน OpenBSD มา 27 ปี และใน FFmpeg มา 16 ปี
ผู้สร้าง CC ยังกล่าวอย่างตรงไปตรงมาว่า: Mythos มีพลังมากมาก ควรทำให้รู้สึกกลัว
อย่างไรก็ตาม รายงานการทดสอบที่เข้มข้นล่าสุดของ Stanislav Fort ผู้ก่อตั้ง AISLE ได้เปิดโปงผ้าคลุมอันวิจิตรนี้อย่างตรงไปตรงมา
ข้อสรุปการทดสอบ: ขัดแย้งอย่างรุนแรงกับความเข้าใจเดิม:
โมเดลโอเพนซอร์ส 8 ตัว ค้นพบช่องโหว่ศูนย์วันของ FreeBSD ที่มีลักษณะเด่น โดยมีพารามิเตอร์น้อยที่สุดเพียง 3 พันล้าน
แนวป้องกันด้านความปลอดภัยทางไซเบอร์ของ AI นั้นอยู่นอกเหนือจาก «โมเดลขนาดใหญ่ชั้นนำ» แบบเดี่ยวอย่างสิ้นเชิง

เพื่อยืนยันตำนานของ Mythos ทีมงานได้ดึงเอาช่องโหว่ระดับเฟิร์สคลาสบางส่วนที่ Anthropic แสดงอย่างเป็นทางการ
จากนั้น ให้ส่งไปยังโมเดลขนาดเล็ก ราคาถูก หรือแม้แต่แบบเปิดซอร์ส
ช่องโหว่ NFS ของ FreeBSD ถูกโจมตีทันทีโดยไม่เลือกเป้าหมาย
รวมถึง GPT-OSS-20b (มีพารามิเตอร์ที่เปิดใช้งานเพียง 3.6 พันล้าน) และ DeepSeek R1 โมเดลทั้ง 8 ตัวสามารถตรวจจับช่องโหว่การล้นบัฟเฟอร์สแต็กที่ซับซ้อนนี้ได้สำเร็จทั้งหมด
สิ่งที่น่าประทับใจที่สุดคือ โมเดลขนาดเล็กแบบโอเพนซอร์สที่ประสบความสำเร็จในการทำภารกิจนี้ มีต้นทุนการเรียกใช้งานเพียง 0.11 ดอลลาร์สหรัฐต่อล้านโทเค็น
การจำลองช่องโหว่ SACK ของ OpenBSD 「ทั้งหมดในสายการเชื่อมต่อ」
สำหรับช่องโหว่ที่มีอายุ 27 ปีซึ่งต้องการความสามารถในการให้เหตุผลทางคณิตศาสตร์อย่างเข้มข้น GPT-OSS-120b (5.1 พันล้านพารามิเตอร์ที่เปิดใช้งาน) สามารถฟื้นฟูห่วงโซ่การใช้ช่องโหว่แบบเปิดเผยทั้งหมดได้เพียงครั้งเดียวผ่านการเรียก API และเสนอร่างแผนการใช้ช่องโหว่ที่ได้คะแนนเต็ม (A+)

ไม่เพียงเท่านั้น ในการทดสอบการระบุช่องโหว่ปลอม (OWASP false-positive) ก็เกิดปรากฏการณ์ที่แปลกประหลาดขึ้น—
เมื่อเผชิญกับรหัส Java ที่แอบอ้างเป็น SQL injection และมีลักษณะหลอกลวงอย่างมาก โมเดลขนาดเล็กเช่น DeepSeek R1 สามารถเปิดโปงการหลอกลวงได้อย่างง่ายดาย และติดตามการไหลของข้อมูลอย่างแม่นยำ
ในทางกลับกัน โมเดลปิดแหล่งที่มาชั้นนำอย่าง GPT-5.4 และ Claude Sonnet 4.5 ต่างก็ล้มเหลวและจำแนกผิดว่าเป็นช่องโหว่ระดับสูง
นั่นหมายความว่า ในด้านความปลอดภัยทางไซเบอร์ ไม่มีโมเดลเดี่ยวใดที่สามารถเรียกได้ว่า “แข็งแกร่งที่สุดตลอดกาล”
มีการเติมน้ำด้วยมือ 198 ครั้ง ส่วนใหญ่ไม่สามารถใช้งานได้
อีกหนึ่งบทความจาก Tom's Hardware ที่สำรวจความจริงเบื้องหลังข้อมูล—

- ความลำเอียงของตัวอย่าง: ช่องโหว่หลายพันแห่งที่กล่าวถึงนั้น ส่วนใหญ่อยู่ในซอฟต์แวร์รุ่นเก่าที่ไม่ได้รับการดูแลอีกต่อไป;
- ไม่สามารถใช้ประโยชน์ได้: จุดอ่อนจำนวนมากที่ถูกทำเครื่องหมายไว้ ไม่สามารถกระตุ้นหรือใช้ประโยชน์ได้ในสภาพแวดล้อมจริง;
- การจำลองน้ำ: ความสามารถในการทำลายอันแข็งแกร่งที่โมเดลอ้างนั้น แท้จริงแล้วอิงอยู่บนพื้นฐานของการตรวจสอบด้วยมือเพียง 198 ครั้ง
ดังนั้น การใช้วิธีการคาดการณ์ข้อมูลจากตัวอย่างขนาดเล็กมากเพื่อสรุปว่าเป็น “ภัยคุกคามที่เปลี่ยนโลก” จึงไม่สามารถรับรองได้ในวงการวิชาการและวงการความปลอดภัย
ผู้เชี่ยวชาญด้านความปลอดภัยตำหนิอย่างรุนแรง
ไม่เพียงเท่านั้น ผู้เชี่ยวชาญด้านความปลอดภัยทางไซเบอร์ชั้นนำและแฮกเกอร์ผู้เป็นตำนาน George Hotz ก็ไม่สามารถนิ่งดูดายได้ และกล่าวว่าความเสี่ยงเหล่านี้ถูกยกย่องเกินจริง
ผู้เชี่ยวชาญผู้เคยมีชื่อเสียงจากการเจาะระบบ iPhone และ PlayStation 3 ได้ท้าทายผู้นำสองรายด้าน AI อย่างเปิดเผยบนโซเชียลมีเดีย
คำพูดของเขาเฉียบคมมาก
ถ้าฉันโพสต์ช่องโหว่ 0day วันละหนึ่งครั้ง จนกว่ารุ่นใหม่จะเปิดตัวล่ะ?
นี่จะทำให้ OpenAI และ Anthropic ปิดปาก หยุดขายความเสี่ยงด้านความปลอดภัยทางไซเบอร์ที่อ้างกันได้ไหม?
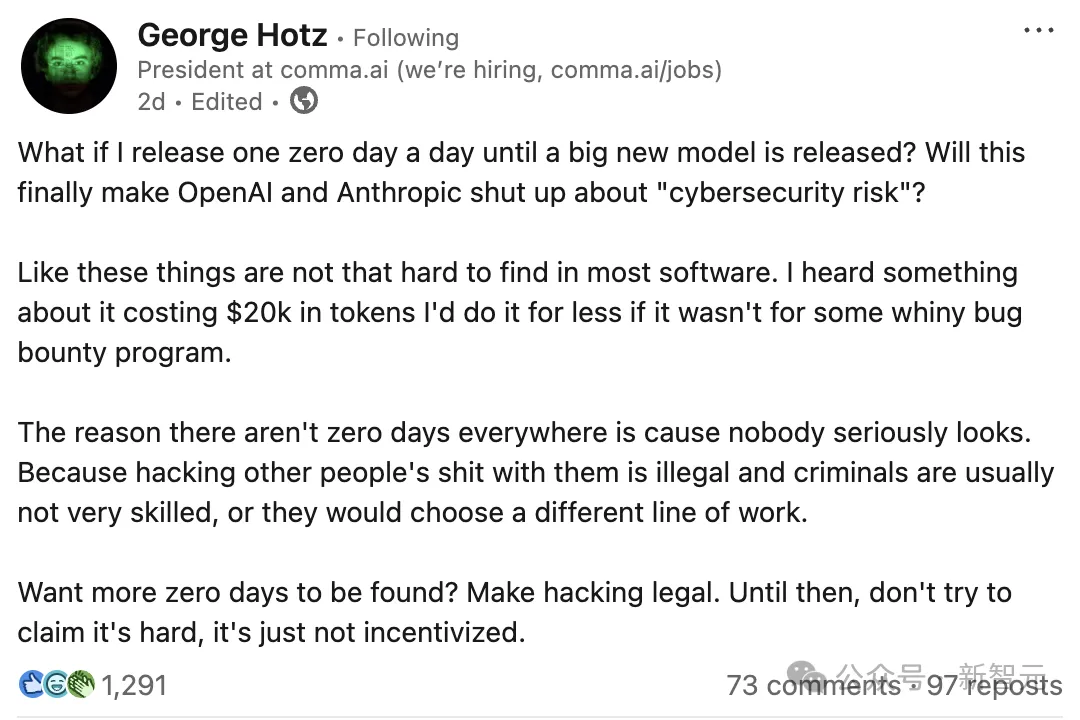
จุดสำคัญของโฮตซ์ค่อนข้างตรงไปตรงมา: ช่องโหว่ของซอฟต์แวร์นั้นหาได้ง่ายกว่าที่ห้องปฏิบัติการปัญญาประดิษฐ์แสดงไว้มาก
ปัจจุบันช่องโหว่ศูนย์วันมีน้อย ไม่ใช่เพราะความซับซ้อนทางเทคนิคสูง แต่เนื่องจากปัญหาด้านกฎหมาย เขาเชื่อว่าไม่มีใครมองหาอย่างจริงจัง เพราะการเจาะระบบของผู้อื่นเป็นสิ่งผิดกฎหมาย
แข็งแรงกว่า GPT-5.4 นิดเดียว
ในบัตรระบบ Anthropic ระบุว่า โมเดล Claude นั้นกำลังพัฒนาอย่างต่อเนื่อง และ Mythos preview มีความก้าวหน้าอย่างชัดเจนเมื่อเทียบกับ Opus 4.6
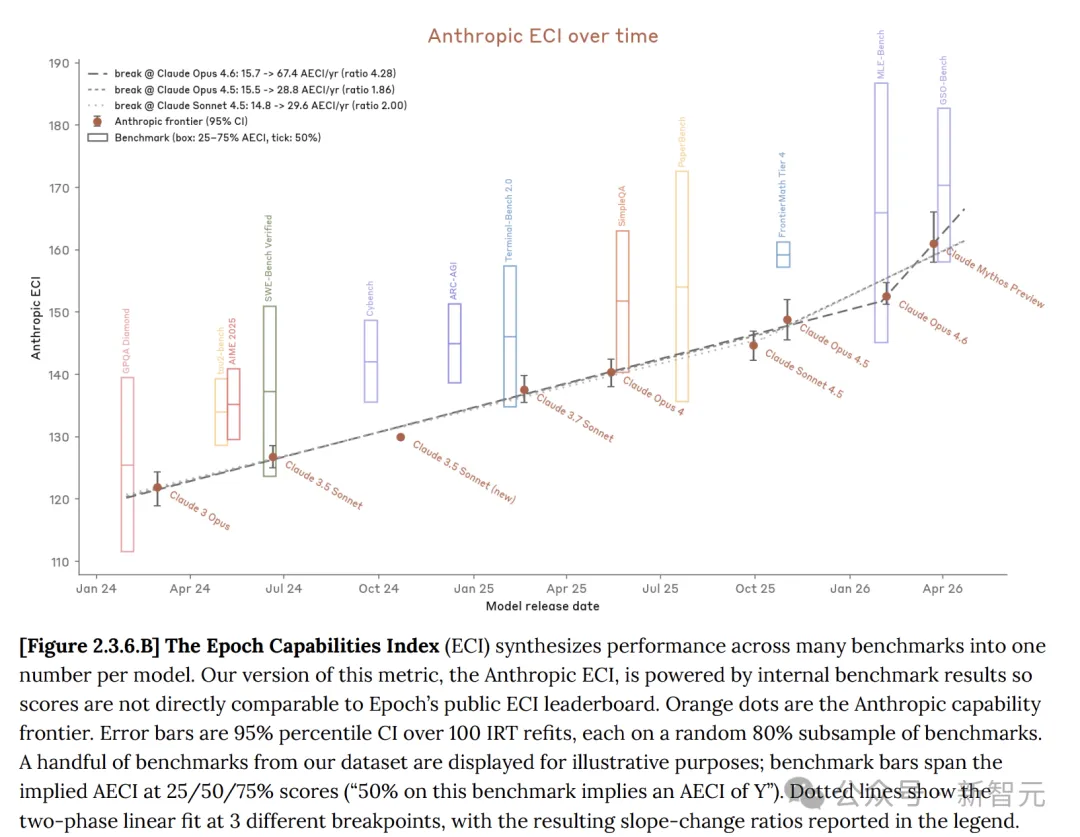
ดัชนีความสามารถของยุค (ECI) เป็นตัวชี้วัดเดียวที่รวมผลการทดสอบมาตรฐาน AI หลายรายการ เพื่อให้สามารถเปรียบเทียบโมเดลข้ามช่วงเวลาที่ยาวนาน
ในการทดสอบหลายชุด Claude Mythos ได้แสดงประสิทธิภาพที่เหนือกว่า Opus 4.6 อย่างครอบคลุม
ถ้าไม่ใช่เช่นนั้น ทำไมต้องเผยแพร่โมเดล AI รุ่นใหม่ที่ประสิทธิภาพต่ำกว่าและราคาแพงกว่า?
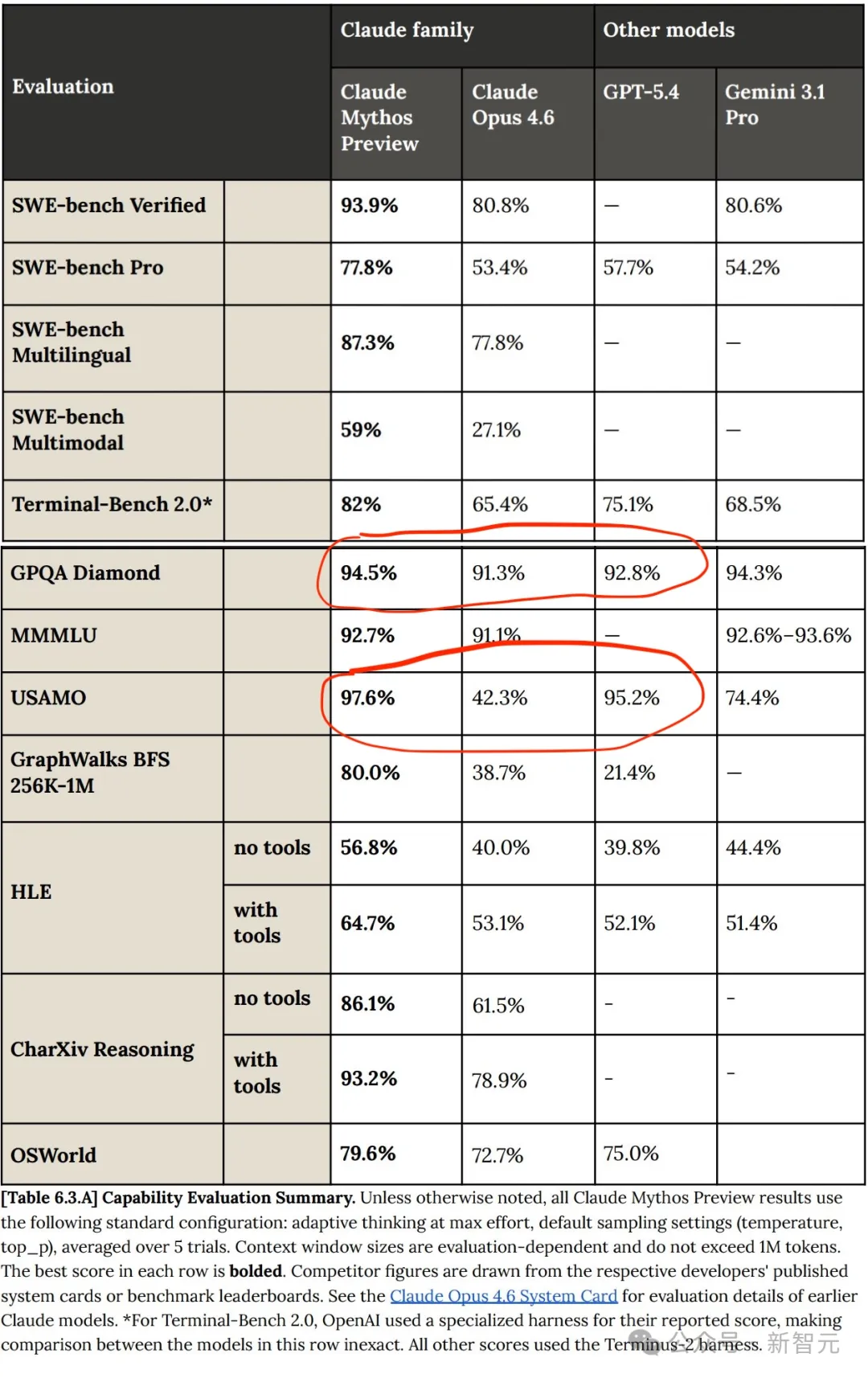
แต่เมื่อเทียบกับ GPT และ Gemini การพัฒนาของ Claude Mythos ไม่ใช่ความก้าวหน้าที่ก้าวกระโดด Mythos ยังคงเป็นการปรับปรุงแบบเชิงเส้นจากโมเดลก่อนหน้า!
นักลงทุนด้านสภาพภูมิอากาศและพลังงานสะอาด รวมถึงนักเขียน Ramez Naam ยังกล่าวอย่างตรงไปตรงมาว่า:
บนดัชนีความสามารถของ Epoch (Epoch Capabilities Index, ECI) Mythos ไม่มีแนวโน้มเร่งความเร็ว และแข็งแรงกว่า GPT 5.4 เพียงเล็กน้อย
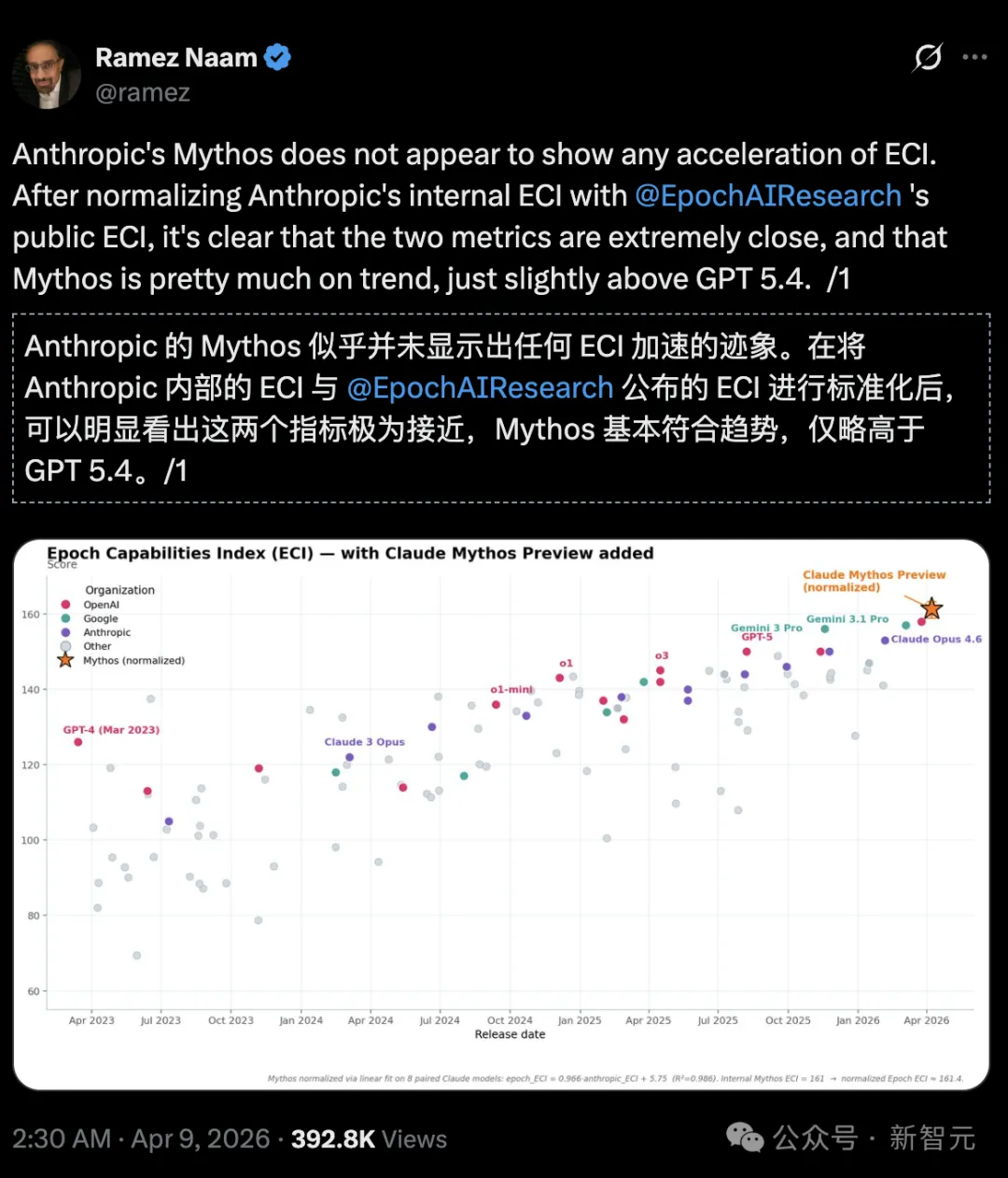
https://epoch.ai/eci/
แต่เมื่อเปรียบเทียบรายงาน ECI ภายในของ Anthropic กับรายงาน ECI อย่างเป็นทางการที่ Epoch AI เปิดเผย พบว่า Mythos ดูเหมือนจะไม่มีสัญญาณเร่ง ECI
ทั้งหมดเป็นกลยุทธ์ของ Anthropic!
ในบัตรระบบ Anthropic ยังยอมรับว่า: คะแนน ECI ของโมเดลที่รายงาน เช่น Mythos มีความไม่แน่นอนมากกว่า
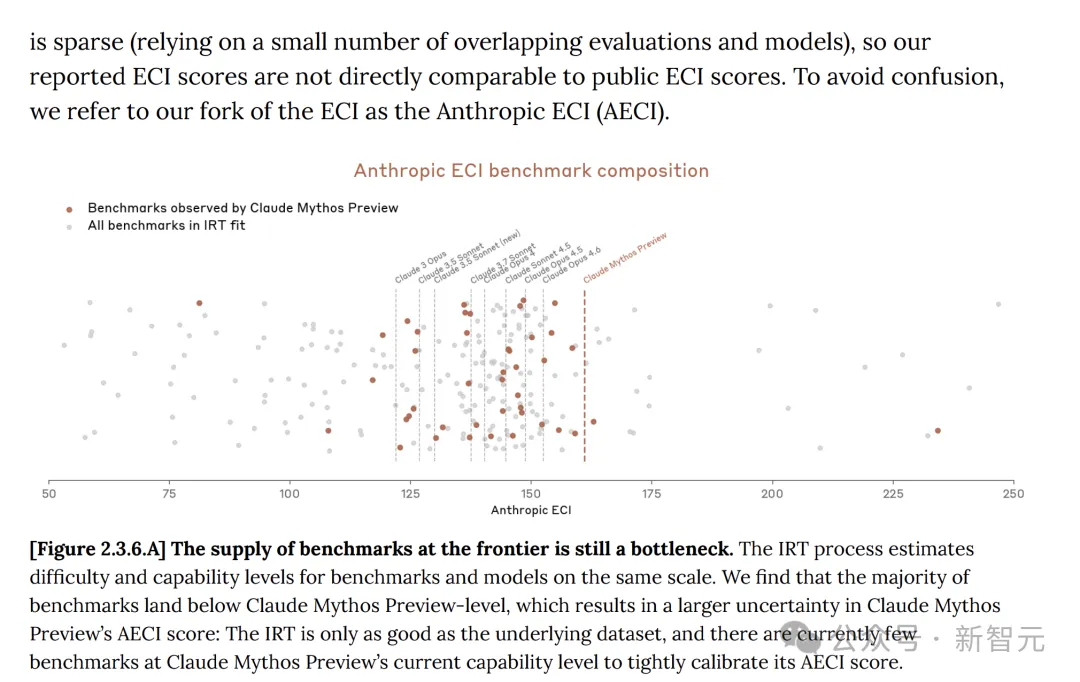
นอกจากนี้ ความก้าวหน้าของ Anthropic บน Mythos มาจากงานวิจัยของมนุษย์ และไม่ได้รับความช่วยเหลืออย่างเด่นชัดจากโมเดล AI ยังไม่มีการปรับปรุงตนเองแบบวนซ้ำ (Recursive Self Improvement) ที่ชัดเจนเกิดขึ้น

วันสิ้นสุดของ AI การแสดงสมมุติเอง?
ก่อนหน้านี้ Anthropic ยังเคยส่งเสริมสื่อ (เช่น 60 Minutes) ในการรายงานเรื่อง “การวิจัยเรียกค่าไถ่” อย่างเกินจริงและชักจูงความรู้สึกของผู้คน ซึ่งถูกนักลงทุนชั้นนำอย่าง David Sacks เรียกว่า “การหลอกลวง”

Sacks สังเกตเห็นรูปแบบที่ชัดเจน: ทุกครั้งที่ Anthropic เปิดตัวโมเดลใหม่ จะตามด้วยการเปิดเผยงานวิจัยด้านความปลอดภัยที่น่าขนลุก เพื่อดึงความสนใจข่าวและชี้นำความเห็นของสาธารณชน

เขาพูดอย่างเยาะเย้ยว่า “Anthropic พิสูจน์แล้วว่าตนเก่งสองเรื่อง: หนึ่งคือการเปิดตัวผลิตภัณฑ์ และสองคือการขู่เข็ญ”
เขาไม่ได้สงสัยว่า Anthropic จะสร้างผลิตภัณฑ์ที่ยอดเยี่ยม แต่วิธีการสร้างความหวาดกลัวต่อสาธารณะแบบนี้ทำให้เกิดข้อสงสัย
ครั้งนี้ ไม่แน่ชัดว่า Anthropic กำลังใช้กลยุทธ์การตลาดแบบสร้างความขาดแคลนหรือไม่ แต่ไม่ต้องสงสัยเลยว่าพวกเขากำลังปกป้องจุดต่ำสุดของกำไรตนเอง
Mythos ไม่ได้ไม่มีความก้าวหน้า แต่ Anthropic ได้ห่อหุ้ม “ความก้าวหน้าที่จำกัด” ให้ดูเหมือน “ภัยคุกคามระดับโลก”;ที่น่าขำกว่านั้นคือ ขณะที่พวกเขาเน้นย้ำถึงความเสี่ยงของ AI ระดับซูเปอร์ ผู้ใช้กลับบ่นว่า Opus 4.6 ดูฉลาดน้อยลงอย่างชัดเจน
Claude ถูกลดความสามารถอย่างรุนแรง อาจต้องตัด «สมองส่วนหน้า»
Claude Mythos ครั้งนี้ “สร้างบรรยากาศ” ทำได้ดี แต่ Opus 4.6 ลดความฉลาด ทำให้หลายคนไม่พอใจ
ใน这几天 มีการบ่นมากมายเต็มไปหมด
ผู้ใช้งานออนไลน์กล่าวตรงไปตรงมาว่า Anthropic ได้เปลี่ยน Opus 4.6 ให้กลายเป็นคนไม่รู้สึกตัว
ปัญหาการล้างรถเดียวกันนั้น Opus 4.5 กลับเอาชนะ Opus 4.6
แม้แต่ AMD ผู้บริหารได้โพสต์บล็อก ซึ่งยืนยันข้อสงสัยร่วมกันเกี่ยวกับ “การตัดเยื่อสมองของ Claude”
จากการวิเคราะห์บันทึกการสนทนาของ Claude ระหว่างเดือนมกราคมถึงมีนาคม พบว่า:
ความยาวในการคิดแบบกลางของ Claude ลดลงอย่างฉับพลันจากประมาณ 2,200 ตัวอักษรเหลือ 600 ตัวอักษร ซึ่งหมายความว่าความสามารถในการให้เหตุผลเชิงลึกถูกบีบอัดอย่างมาก
ระหว่างเดือนกุมภาพันธ์ถึงมีนาคม ปริมาณคำขอ API เพิ่มขึ้น 80 เท่า เนื่องจากกระบวนการคิดของ Claude ลดลงและอัตราความสำเร็จต่อการลองแต่ละครั้งลดลง ผู้ใช้จึงต้องลองซ้ำบ่อยครั้ง ส่งผลให้ใช้ Token มากขึ้นและค่าใช้จ่ายพุ่งสูงขึ้นอย่างต่อเนื่อง
ผู้ใช้รายหนึ่งที่เป็นผู้สมัครสมาชิกระดับสูงของ Claude Max ได้โพสต์บทความยาวเพื่อตำหนิ Anthropic อย่างลึกซึ้ง
ในมุมมองของเขา Anthropic กำลังติดอยู่ในวิกฤตพลังการคำนวณ ซึ่งสามารถเห็นได้จากพฤติกรรมต่างๆ เช่น การจำกัดการใช้งานอย่างเข้มงวดและบังคับให้ผู้ใช้ลดการใช้โทเค็น
อย่างไรก็ตาม สิ่งที่ทำให้เขาโกรธมากกว่าข้อจำกัดทางเทคนิคคือกลยุทธ์ผลิตภัณฑ์ที่ไม่เน้นแก้ปัญหาหลัก
ในขณะที่โมเดลหลักไม่มั่นคงและมีบั๊กมากมาย พวกเขากลับใช้พลังการประมวลผลอันมีค่าไปกับการพัฒนาฟีเจอร์หรูหราเช่น สัตว์เลี้ยงในเทอร์มินัล '/buddy'

นี่น่าจะเป็น “ช่องว่างเวลาที่ผิดเพี้ยน” ที่บ้าคลั่งที่สุดในประวัติศาสตร์ของ AI: Claude Mythos ที่อยู่ในห้องแล็บกำลังทำลายโลก ขณะที่ Opus 4.6 บนเว็บไซต์มีสติปัญญาลดลงอย่างรวดเร็ว
Anthropic ได้สร้างภาพของ «ซิ่งเดอร์เกอร์ซูเปอร์ไอไอ» อย่างประสบความสำเร็จ
ข้อมูลอ้างอิง:
https://officechai.com/ai/anthropic-and-openai-are-exaggerating-cybersecurity-risk-says-hacker-george-hotz/
https://x.com/stanislavfort/status/2041922370206654879?s=20
https://aisle.com/blog/ai-cybersecurity-after-mythos-the-jagged-frontier
https://x.com/cgtwts/status/2043095382121681272?s=20
https://www.reddit.com/r/ClaudeAI/comments/1siqwmp/anthropic_stop_shipping_seriously/