









หุ่นยนต์เลียนแบบมนุษย์จะฝันไหม? ถ้าพวกเขาฝัน พวกเขาจะฝันถึงแกะอิเล็กทรอนิกส์ไหม?

ภาพหน้าจอจากภาพยนตร์ Blade Runner
ในปี 1968 ขณะที่ฟิลิป ดี. คิก ผู้แต่งนิยายต้นฉบับของภาพยนตร์ไซไฟเรื่อง Blade Runner พิมพ์คำถามที่นามธรรมและล้ำสมัยนี้บนเครื่องพิมพ์ดีด เขาคงไม่เคยคิดเลยว่าอีกกว่าครึ่งศตวรรษต่อมา ยักษ์ใหญ่ด้านเทคโนโลยีจากซิลิคอนแวลลีย์จะให้คำตอบอย่างจริงจัง
ใช่ พวกเขาไม่เพียงแต่ฝันถึงแกะอิเล็กทรอนิกส์ แต่ยังสามารถแสดงผลความฝันนั้นได้
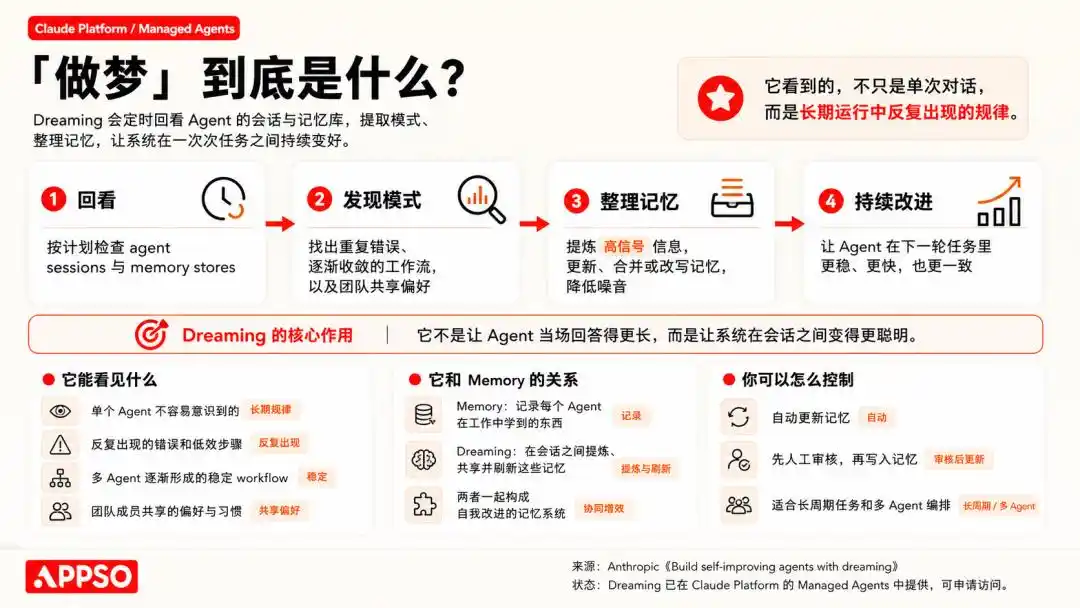
เมื่อวานนี้ Anthropic ได้เปิดตัวฟีเจอร์ใหม่ๆ สำหรับแพลตฟอร์มการสร้างเอเจนต์ Managed Agents ในการประชุมนักพัฒนาที่ซานฟรานซิสโก ได้แก่ การขยายหน่วยความจำ การส่งออกผลลัพธ์ การร่วมมือระหว่างเอเจนต์หลายตัว และการ “ฝัน (Dreaming)”
ตามคำอธิบายของ Anthropic เอง “ความจำและการฝันร่วมกันสร้างระบบความจำที่มั่นคงและสามารถพัฒนาตนเองได้”

อีกครั้งที่ฝัน หรือความทรงจำ เพื่อนๆ ที่ไม่ค่อยสนใจด้าน AI คงจะสับสนอย่างมาก คำศัพท์ที่เป็นของมนุษย์เหล่านี้ ตั้งแต่เมื่อไหร่ถึงได้ถูกใช้กับ AI อย่างลื่นไหลเช่นนี้
ตั้งแต่ปี 2024 เมื่อ OpenAI เปิดตัวซีรีส์ o1 ซึ่งเป็น “ชุดโมเดล AI ที่ออกแบบมาเพื่อใช้เวลามากขึ้นในการคิดก่อนตอบ” คำว่า “คิด” ถูกใช้อย่างเป็นธรรมชาติจนไม่มีใครหยุดถามว่า โปรแกรมที่เป็นเพียงการพยากรณ์สถิติของโทเค็นถัดไป จะเรียกได้อย่างไรว่า “คิด”?
ตามด้วย reasoning (การให้เหตุผล) memory (ความจำ) reflection (การทบทวน) Imagining (การจินตนาการ) นำสิ่งที่มนุษย์เท่านั้นทำได้ มาแสดงทีละขั้นตอนในงานเปิดตัวผลิตภัณฑ์

ภาพหน้าจอจากภาพยนตร์เรื่อง Paprika ของ梦
“การคิด” ยังสามารถตีความเป็นอุปมาได้ “ความจำ” ก็พอจะถือเป็นการขยายความของศัพท์เทคนิคได้ แต่ “ฝัน” นั้นเกินไปจริงๆ ปรัชญา วรรณกรรม และประวัติศาสตร์ศึกษากันมาหลายพันปียังไม่เข้าใจให้ชัดเจน แต่บริษัท AI กลับสามารถพูดตรงๆ ได้ว่า: เราไม่เพียงแต่สร้างเครื่องจักรที่สามารถคิดได้ แต่เรายังสร้างเครื่องจักรที่สามารถฝันได้
อะไรคือการฝัน ไม่มีศัพท์ทางวิศวกรรมใดที่สามารถอธิบายสิ่งนี้ได้อย่างแม่นยำนอกจากการฝันหรือ?
แม้แต่ AI ที่ฝันก็ต้องใช้เงิน
ในเหตุการณ์รั่วไหลของรหัส Claude Code ผู้ใช้อินเทอร์เน็ตพบว่า Anthropic กำลังเตรียมเปิดใช้งานฟีเจอร์ชื่อ Auto Dreaming ในเวลานั้น ทุกคนต่างสงสัยว่า AI จะต้องนอนหลับและพักผ่อนให้เพียงพอ เพื่อให้มีความสนใจและฉลาดขึ้นเหมือนมนุษย์เราหรือไม่
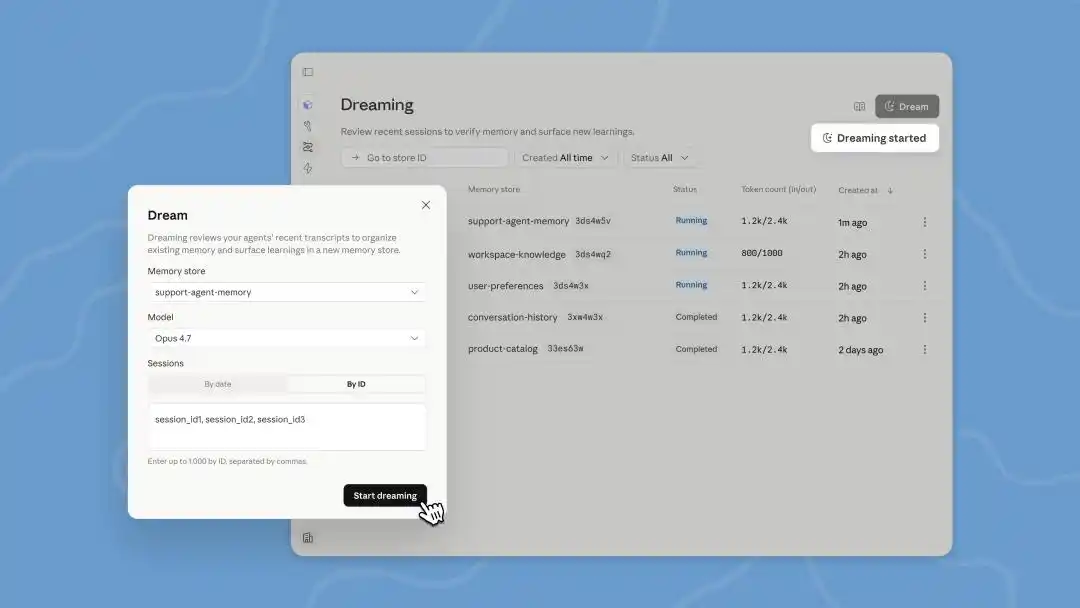
แต่เพียงแค่เข้าใจหลักการทำงานของ AI Agent ในปัจจุบัน ก็จะเห็นว่าสิ่งที่เรียกว่า “ฝัน” นั้น โดยพื้นฐานแล้วเป็นเพียงการประมวลผลแบบแบตช์แบบออฟไลน์อัตโนมัติ
ตัวแทน AI ตอนนี้เชี่ยวชาญในการดำเนินงานที่ซับซ้อนและมีขั้นตอนยาว เช่น “ช่วยฉันศึกษาข้อมูลงบการเงินล่าสุดของคู่แข่งห้ารายนี้ และจัดทำเป็นตาราง” ในกระบวนการนี้ ตัวแทนจำเป็นต้องสลับระหว่างหน้าเว็บต่างๆ อ่านเอกสารหลายชิ้น ใช้งานเครื่องมือต่างๆ รวมถึงอาจต้องเผชิญกับกลไกป้องกันการขูดข้อมูลและต้องลองใหม่
เมื่อภารกิจออนไลน์ที่ยาวเหยียดและซับซ้อนนี้สิ้นสุดลง ระบบหลังบ้านของเอเจนต์จะทิ้งไว้ซึ่งบันทึกการดำเนินงานจำนวนมาก
รูปภาพที่สร้างโดย AI
ฟีเจอร์ “ฝัน” ของ Anthropic คือการให้ Agent ทบทวนประวัติการใช้งานเหล่านี้ในช่วงเวลาที่ว่าง โดยจะค้นหาแบบแผน เช่น พบว่า “ทุกครั้งที่เจอหน้าต่างป๊อปอัพแบบนี้ ให้คลิกที่มุมขวาบนเพื่อปิด” เพื่อปรับปรุงเส้นทางการดำเนินการในครั้งถัดไป
「ความทรงจำ」รับผิดชอบในการจับสิ่งที่เรียนรู้ขณะทำงาน ขณะที่「ฝัน」ช่วยสกัดความทรงจำเหล่านี้ระหว่างการสนทนา และแชร์ระหว่างเอเจนต์ต่างๆ
พูดให้เข้าใจง่ายๆ นี่คือกลไกการเรียนรู้แบบเสริมแรงและการแก้ไขตนเองที่อิงจากข้อมูลในอดีต

คำอธิบายเกี่ยวกับ Dream: https://platform.claude.com/docs/en/managed-agents/dreams
ในการประชุมนักพัฒนาครั้งนี้ มีการอัปเดต Dreams ใน Managed Agents ซึ่งเป็นงานที่ดำเนินการในพื้นหลัง และเราต้องกระตุ้นด้วยตนเอง คลอดสามารถอ่านประวัติการสนทนาได้สูงสุด 100 เซสชันต่อครั้ง แล้วสร้างความจำใหม่ทั้งหมดขึ้นมาเพื่อให้เราตรวจสอบก่อนตัดสินใจว่าจะใช้หรือไม่
ในขณะเดียวกัน AutoDream ซึ่งได้เปิดใช้งานอย่างเงียบๆ ใน Claude Code มาก่อน จะตรวจสอบในพื้นหลังว่า “ควรจะฝันหรือไม่” หลังจากพูดคุยกับ Agent ครบหนึ่งรอบ โดยค่าเริ่มต้นจะรันทุก 24 ชั่วโมง
เช่นเดียวกับฟังก์ชันการฝัน ฮีร์เมส เอเจนต์ก็มีเช่นกัน ฮีร์เมส เอเจนต์เน้นที่การเรียนรู้และพัฒนาด้วยตนเอง โดยไม่เพียงแต่รองรับการสรุปประสบการณ์จากงานก่อนหน้าโดยอัตโนมัติ แต่ยังจัดเก็บไว้ในไฟล์ความจำ

ฟีเจอร์หนึ่งที่ชื่อว่า Curator ยังสามารถจัดระเบียบคู่มือการดำเนินการที่สกัดออกมาเหล่านี้ให้กลายเป็น Skill อัตโนมัติ
ทักษะเหล่านี้จะได้รับการให้คะแนน ทักษะที่ซ้ำกันจะถูกรวมกัน ทักษะที่ไม่ได้ใช้งานเป็นเวลานานจะถูกจัดเก็บอัตโนมัติ และยังมีวงจรชีวิตเช่น active, stale, archived ด้วย เราสามารถปักทักษะที่สำคัญไว้เพื่อไม่ให้ระบบลบทิ้งอัตโนมัติ
OpenClaw ยังได้เพิ่มกลไกที่เกี่ยวข้องในการอัปเดตครั้งล่าสุด เช่น ความจำถาวรข้ามการสนทนา การจัดตารางงานตามเวลา การดำเนินการแยกของ Agent ย่อย และฟีเจอร์การฝันโดยตรงที่เรียกว่า Dreaming
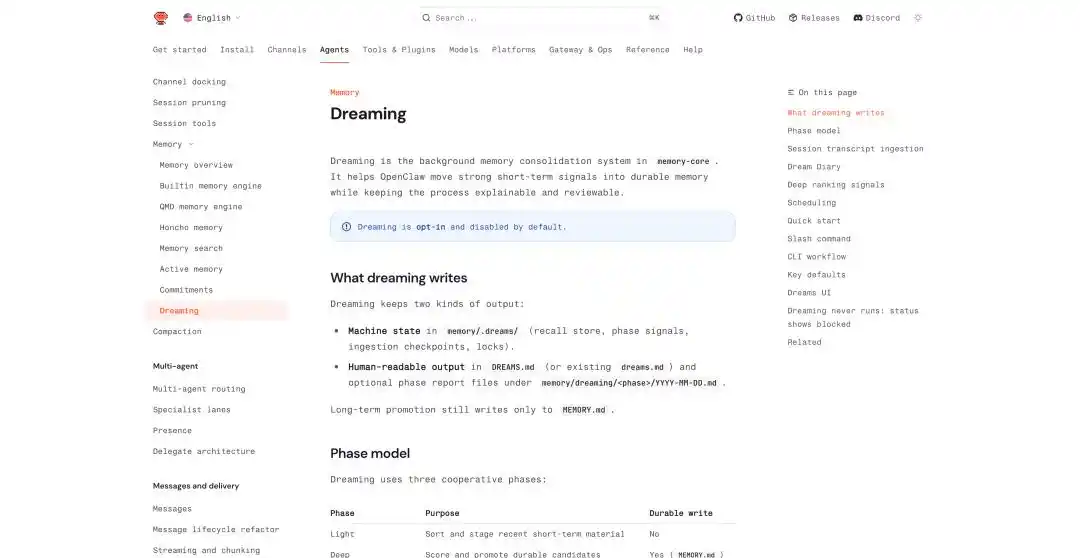
ความฝันของ OpenClaw: https://docs.openclaw.ai/concepts/dreaming
ในกลไกของฝันของ OpenClaw มันสรุปเส้นทางของฝันเป็นสามระยะ คือ light, REM, deep สองระยะแรกมีหน้าที่จัดระเบียบ ทบทวน และสรุปหัวข้อ ส่วน deep จึงเป็นระยะที่แท้จริงในการบันทึกเนื้อหาลงใน MEMORY.md
การยืนยันในระยะการนอนหลับลึกจะถูกตัดสินโดยสัญญาณน้ำหนัก 6 ประเภทว่าควรบันทึกไว้ในหน่วยความจำระยะยาวหรือไม่ สัญญาณทั้งหกประกอบด้วย ความถี่ ความเกี่ยวข้อง ความหลากหลายของการค้นหา ความทันสมัย ความซ้ำซ้อนข้ามวัน และความอุดมสมบูรณ์ของแนวคิด

รูปภาพที่สร้างโดย AI
การเขียนลงหน่วยความจำระยะยาวจะสร้างไฟล์สองฉบับ: ไฟล์สถานะสำหรับเครื่องจักร ซึ่งจะถูกเก็บไว้ที่ memory/.dreams/ และไฟล์บันทึกที่อ่านเข้าใจได้สำหรับผู้ใช้ ซึ่งจะถูกเขียนลงใน DREAMS.md และรายงานที่สร้างตามแต่ละขั้นตอน
นอกจากนี้ Dreaming สามารถตั้งเวลาทำงานอัตโนมัติได้ โดยค่าเริ่มต้นจะรันกระบวนการเต็มรูปแบบทุกวันเวลา 3:00 น. โดยลำดับคือ light → REM → deep
นอกจากผลลัพธ์จากความฝันแล้ว OpenClaw ยังดูแลเอกสารที่ชื่อว่า Dream Diary ซึ่งระบบจะสร้าง “ไดอารี่ความฝัน” อัตโนมัติ โดยบันทึกกระบวนการจัดระเบียบความทรงจำในรูปแบบเรื่องเล่า เพื่อเน้นความสามารถในการอธิบายและตรวจสอบ แทนที่จะเป็นฐานข้อมูลแบบกล่องดำ
ในสาขาประสาทวิทยา มีความเข้าใจที่เป็นที่รู้จักกันดีว่า ข้อมูลที่มนุษย์รับรู้ในระหว่างวันจะถูกส่งเข้าสู่ระบบเก็บข้อมูลชั่วคราวก่อน จากนั้นในระหว่างการนอนหลับ สมองจะทำการเล่นซ้ำ ยืนยัน และทำความสะอาดข้อมูลเหล่านั้น โดยเก็บข้อมูลที่สำคัญไว้และทิ้งข้อมูลที่ไม่มีความหมาย
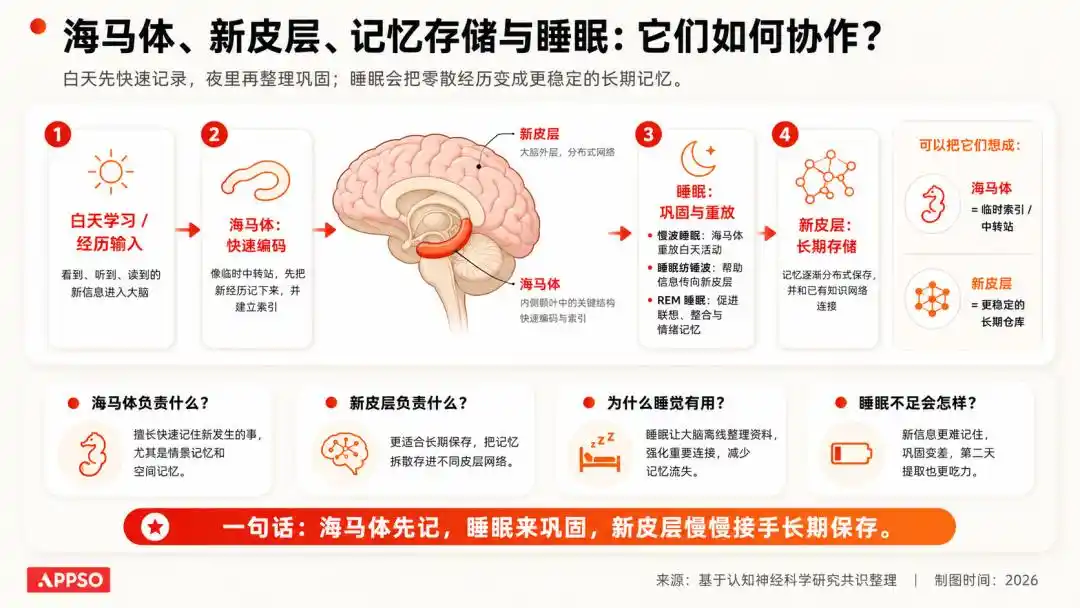
รูปภาพที่สร้างโดย AI
เราไม่จำสีของรถยนต์ทุกคันบนทางไปทำงานเมื่อวาน แต่จะจำทางไปบริษัทได้
ความฝันเหล่านี้ฟังดูเหมือนกับที่มนุษย์ฝันจริงๆ ถ้าจะหาความแตกต่าง ก็คงเป็นแค่ว่าเมื่อ Claude ฝัน มันยังคงใช้ Token ของเราอยู่
แต่ Anthropic และ OpenClaw ไม่ได้เลือกเรียกมันว่า “การปรับปรุงตามเซสชัน” หรือ “การปรับแต่งหลังภารกิจ” ฯลฯ ซึ่งเป็นชื่อที่เน้นด้านวิศวกรรม
ท้ายที่สุด เมื่อเปลี่ยนชื่อที่ซับซ้อนเหล่านั้นให้กลายเป็น「ฝัน」โดยตรง เราจะรู้สึกว่ามันไม่ใช่แค่ฟังก์ชันของซอฟต์แวร์ แต่เหมือนเป็น「ชีวิตดิจิทัลที่มีกิจกรรมภายใน」
ความจำของ AI คือบริบทที่ยุ่งเหยิง
เมื่อพูดถึง「ฝัน」 ก็ต้องพูดถึงเงื่อนไขเบื้องต้นของมัน นั่นคือความจำ (Memory)
ในช่วงไม่กี่ช่วงเวลาที่ผ่านมา คำที่ได้รับความนิยมมากที่สุดในวงการ AI เปลี่ยนจาก prompt engineering เป็น context engineering, skill engineering, harness engineering แต่ไม่ว่าจะเปลี่ยนไปอย่างไร ปัจจุบันสิ่งที่มีคุณค่ามากที่สุดยังคงเป็น context engineering
การแจ้งเตือนระบบ ข้อมูลที่ผู้ใช้ป้อน การสนทนาในระยะสั้น ความจำระยะยาว เอกสารที่เรียกคืน การตอบกลับจากการเรียกใช้งานเครื่องมือและทักษะ สถานะปัจจุบันของผู้ใช้ ชั้นเหล่านี้รวมกันคือ “บริบท” ที่เอเจนต์ใช้งานจริง
การให้ตัวแทนสามารถจดจำได้มากขึ้นและจดบันทึกสิ่งที่มีประโยชน์มากขึ้น เป็นปัญหาที่คงอยู่มานานหลายปี
Manus เมื่อปีที่แล้วได้เผยแพร่บล็อกเทคนิคที่อธิบายอย่างละเอียดว่า Manus ปรับปรุงการวิศวกรรมบริบทอย่างไร โดยระบุว่าอัตราการเข้าถึง KV-Cache ถูกกำหนดให้เป็นหนึ่งในตัวชี้วัดเดียวที่สำคัญที่สุดสำหรับ AI Agent ในสภาพแวดล้อมการผลิต พร้อมทั้งเน้นการใช้การ “ปิดกั้น” แทนการ “ลบออก” ในระดับการเรียกใช้งานเครื่องมือ และการใช้ระบบไฟล์เป็นบริบทสุดท้าย เป็นต้น
เพื่อเข้าใจ KV Cache (คีย์-เวลูแคช) ที่กล่าวถึง เราสามารถจินตนาการว่าแบบจำลองขนาดใหญ่เป็นผู้ป่วยที่มีอาการบังคับให้ต้องอ่านตัวอักษรทีละตัว
เมื่อมันประมวลผลประโยคหนึ่งๆ มันจะคำนวณเวกเตอร์ Key (กุญแจ) และ Value (ค่า) สำหรับแต่ละ Token ที่สร้างขึ้น เพื่อไม่ให้ต้องคำนวณใหม่ทุกครั้ง มันจึงเก็บคู่กุญแจ-ค่า (K, V) เหล่านี้ไว้ ซึ่งเรียกว่า KV Cache
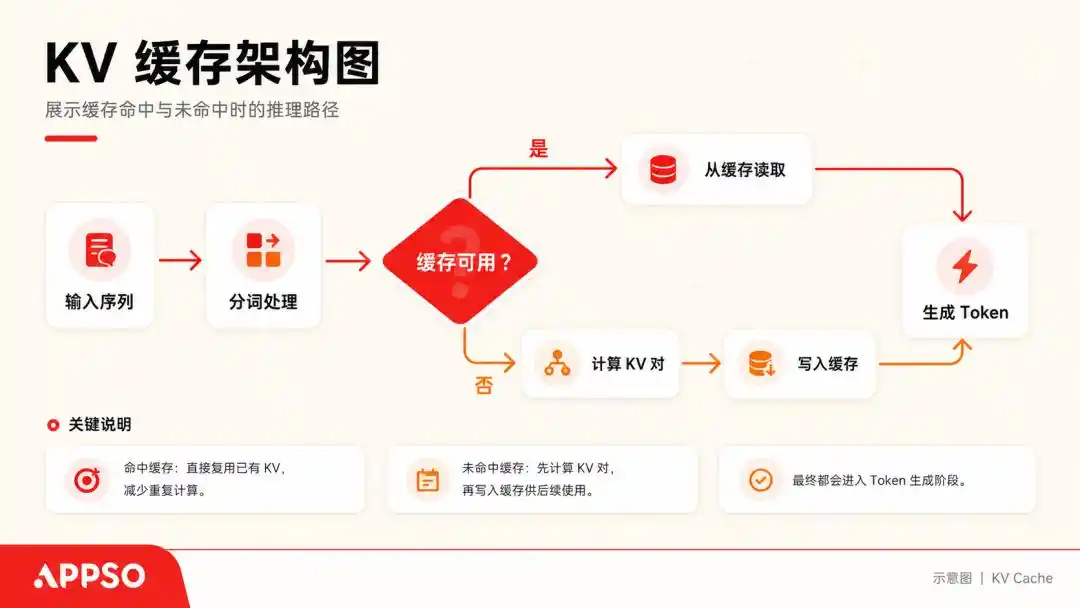
KV Cache (คีย์-เวลูแคช) เป็นเทคโนโลยีเร่งความเร็วระดับพื้นฐานที่ใช้ในโมเดลขนาดใหญ่เพื่อแลกพื้นที่เพื่อแลกเวลาขณะสร้างข้อความ การแคชช่วยให้โมเดลไม่จำเป็นต้องคำนวณคำก่อนหน้าทั้งหมดอีกครั้งเมื่อทำนายคำถัดไป รูปภาพถูกสร้างโดย AI
เมื่อการสนทนาดำเนินต่อไป KV Cache จะถูกบันทึกอย่างต่อเนื่อง โดยทั่วไป เมื่อเผชิญกับโมเดลขนาดใหญ่ที่มีบริบทถึง 128k โมเดลที่มีพารามิเตอร์ 70B เมื่อใช้งานเต็มบริบท 128k จะใช้หน่วยความจำ GPU เพียงสำหรับ KV Cache อย่างเดียวถึง 64 GB
นี่จึงเป็นเหตุผลที่หน้าต่างบริบทของโมเดลส่วนใหญ่ในปัจจุบันมีขนาดสูงสุดอยู่ที่ระดับล้าน
เมื่อวานนี้ บริษัทใหม่ที่ได้รับการระดมทุนแบบ Seed Funding มูลค่า 29 ล้านดอลลาร์สหรัฐฯ ชื่อ Subquadratic ได้เปิดตัวโมเดล SubQ ใหม่บน X โดยเน้นที่บริบทที่ยาวนานขึ้น

SubQ อ้างว่ารองรับหน้าต่างบริบทสูงสุด 12 ล้านโทเค็น ซึ่งเป็นหน้าต่างบริบทที่ใหญ่ที่สุดในโมเดลขนาดใหญ่ทั้งหมดในปัจจุบัน
แม้ยังไม่มีเอกสารวิจัยทางเทคนิคหรือเอกสารคำอธิบายโมเดล แต่ในวิดีโอแนะนำได้กล่าวว่า เส้นทางเทคโนโลยีหลักของ SubQ คือการเปลี่ยนจาก "ความสนใจหนาแน่น" ของ Transformer แบบดั้งเดิม เป็นสถาปัตยกรรมแบบ "รองควอดราติก/เชิงเส้น" ที่มีความสนใจแบบบางเบา สถาปัตยกรรมใหม่นี้มีศักยภาพในการแก้ปัญหาที่ว่า ยิ่งบริบทยาวขึ้น ต้นทุนการประมวลผลก็จะเพิ่มขึ้นอย่างทวีคูณ

ผลการทดสอบที่ให้มา cũngค่อนข้างก้าวหน้า: ภายใต้ 1 ล้านโทเค็น ความเร็วเพิ่มขึ้นกว่า 50 เท่า และต้นทุนลดลงกว่า 50 เท่า; ที่ 12 ล้านโทเค็น ความต้องการหน่วยประมวลผลลดลงใกล้เคียง 1,000 เท่าเมื่อเทียบกับโมเดลชั้นนำ
ในขณะเดียวกันบนเบนช์มาร์ก RULER 128K ระยะบริบทยาว Subquadratic ระบุว่า SubQ มีความแม่นยำ 95% ด้วยต้นทุน 8 ดอลลาร์ ขณะที่ Claude Opus มีความแม่นยำ 94% ด้วยต้นทุนประมาณ 2,600 ดอลลาร์ ลดต้นทุนลงประมาณ 300 เท่า
หรือขยายหน้าต่างบริบท หรือให้โมเดลเรียนรู้การฝันและละทิ้งบางสิ่งบางอย่างเอง
นี่คือเหตุผลที่ผลิตภัณฑ์เอเจนต์อย่าง Anthropic ตอนนี้ต้องเปิดตัว Dreaming ในสถานการณ์ที่หน้าต่างบริบทมีข้อจำกัด AI ที่ชาญฉลาดกว่าไม่สามารถพึ่งแค่การใส่ข้อมูลเพิ่มเติมเข้าไป แต่ต้องมีเป้าหมายชัดเจน
การยอมรับว่าเครื่องจักรก็แค่เครื่องจักร ยากกว่าที่คิด
เมื่อเข้าใจกลไกของการฝันและการจดจำของ AI เราอาจสามารถรู้ความสัมพันธ์ระหว่างมันกับกิจกรรมของมนุษย์ได้
แต่เมื่อนำคำศัพท์ทั้งหมดที่บริษัท AI เหล่านี้สร้างขึ้นเพื่อใช้กับเครื่องจักรมารวมกัน เช่น การคิด (thinking) ของ OpenAI ความจำ (memory) และภาพหลอน (hallucination) ที่ใช้กันทั่วอุตสาหกรรม การฝัน (dreaming) ของ Anthropic ครั้งนี้ และคุณธรรมและปัญญาในรัฐธรรมนูญของ Anthropic
เราสามารถเห็นได้ว่า บริษัท AI ไม่ได้แค่ขายผลิตภัณฑ์ แต่พวกเขากำลังรีดistribute สิทธิ์ในการใช้คำศัพท์ที่เกี่ยวข้องกับ “มนุษย์” ทุกครั้งที่ยืมคำหนึ่งคำ ขอบเขตระหว่างเครื่องจักรกับมนุษย์ก็จะจางลงอีกนิด

ภาษาจะสร้างความคาดหวัง ความคาดหวังจะกำหนดระดับความยอมรับ และความยอมรับจะตัดสินว่าเราเต็มใจมอบสิ่งต่างๆ ให้มันมากน้อยเพียงใด นี่คือโซ่ที่ยาวมาก แต่จุดเริ่มต้นคือคำพูดที่ไร้อันตรายในงานเปิดตัว
ผลกระทบในระดับที่ลึกซึ้งกว่าคือการจัดสรรความรับผิดชอบ เมื่อเครื่องมือถูกอธิบายว่าเป็นหน่วยที่มี “การคิด” “ความจำ” และ “คุณค่า” เราจะมีแนวโน้มที่จะถือว่ามันเป็น “ผู้กระทำอิสระ” และต้องรับผิดชอบเมื่อเกิดปัญหา ว่า AI นี้ควรได้รับ “การสอน” “การปรับแต่ง” หรือ “การปรับเทียบ”
สิ่งที่ควรตั้งคำถามอย่างแท้จริงคือบริษัทที่นำโปรแกรมนี้ไปใช้ในกระบวนการทำงานของเรา และทีมผลิตภัณฑ์ที่เขียนคำว่า “dreaming” คำเปลี่ยน ผู้ที่นั่งอยู่บนเก้าอี้จำเลยก็เปลี่ยนไป
ในขณะที่เราเฝ้าดูเครื่องจักรที่สามารถ “คิด” “จดจำ” และตอนนี้ยัง “ฝัน” ได้ เราจึงเริ่มเชื่อโดยไม่รู้ตัวว่าภายในนั้นมีบางสิ่งบางอย่างอยู่ เพราะการยอมรับว่ามันแค่เครื่องจักรจะทำให้ประสบการณ์ที่ว่า “ฉันกำลังพูดคุยกับสิ่งมีชีวิตที่สามารถคิดได้” จางหายไป และกลับมาอยู่ในความสัมพันธ์แบบเครื่องมือที่เย็นชา

คำอธิบายฟีเจอร์ White Day Dream | รูปภาพสร้างโดย AI
ฉันคิดแล้วว่า Dreaming การฝันกลางคืนใช้จัดการเนื้อหาในอดีต ต่อไปบริษัท AI จะเปิดตัว Daydreaming การฝันกลางวัน เพื่อจำลองอนาคต
การแนะนำคือ การฝันกลางวันหรือคิดฟุ้งซ่าน ช่วยให้ Agent ในสถานะที่ใช้งานอยู่ ใช้ทรัพยากรการประมวลผลที่ว่างอยู่เล็กน้อย ร่วมกับโครงการที่กำลังดำเนินอยู่ในปัจจุบัน เพื่อทำการสร้างแบบสำรวจพร้อมเตรียมงานที่อาจเกิดขึ้นในอนาคต
บทความนี้มาจาก微信号 “APPSO” โดยผู้เขียน: APPSO ผู้ค้นพบผลิตภัณฑ์แห่งอนาคต