










มุมมองนี้ไม่ได้เกิดขึ้นโดยไม่มีพื้นฐานใดๆ เขาได้ดูเอกสารอ้างอิงสาธารณะจำนวนมาก และพบว่า AI กำลังพัฒนาอย่างรวดเร็วในงานที่เกี่ยวข้องกับการวิจัยและพัฒนา AI
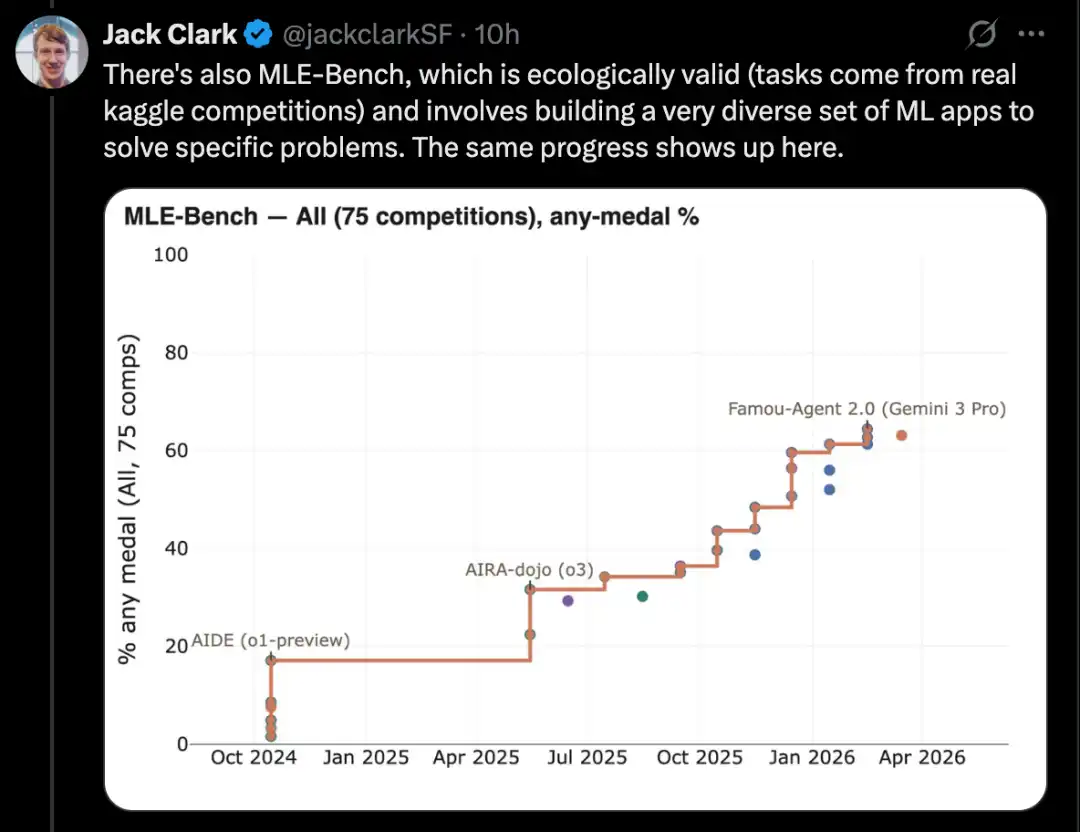
ตัวอย่างเช่น CORE-Bench ประเมินความสามารถของ AI ในการดำเนินการตามงานวิจัยของผู้อื่น ซึ่งเป็นส่วนสำคัญยิ่งในงานวิจัยด้าน AI
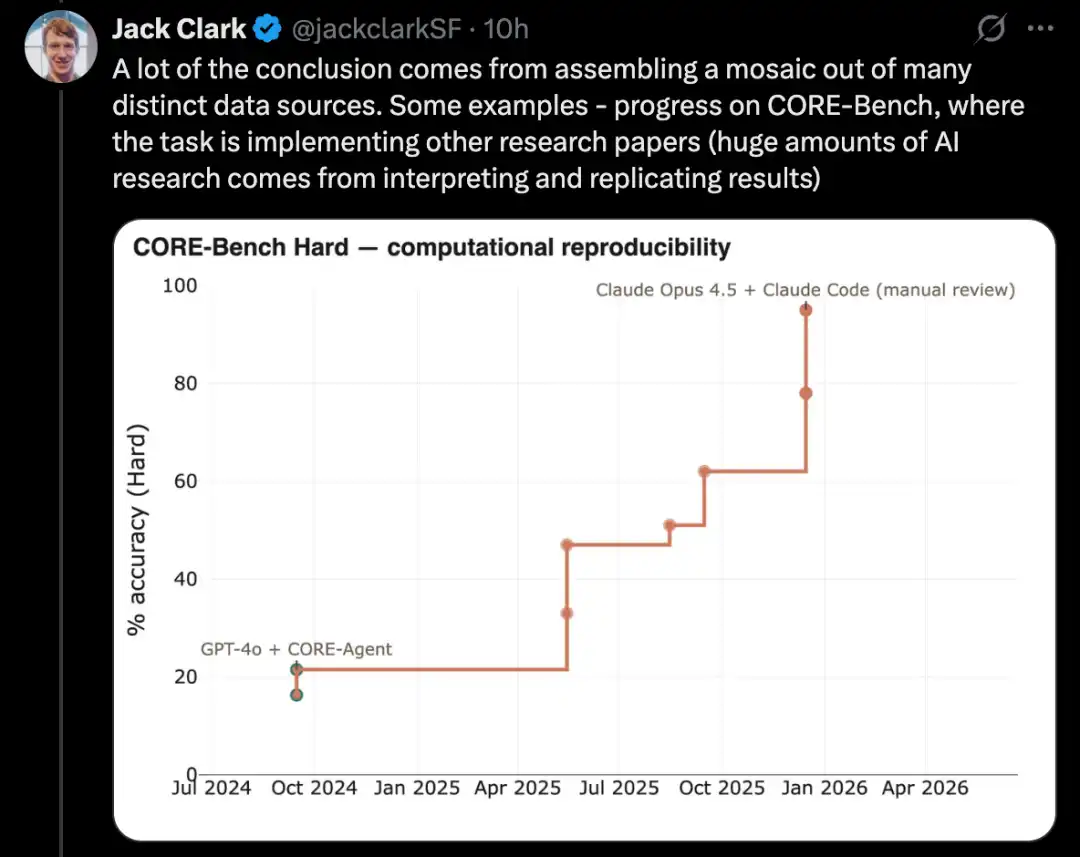
PostTrainBench ทดสอบว่าโมเดลที่มีพลังสูงสามารถปรับแต่งโมเดลโอเพ่นซอร์สที่อ่อนแอกว่าด้วยตนเองเพื่อเพิ่มประสิทธิภาพหรือไม่ ซึ่งเป็นส่วนย่อยสำคัญของงานวิจัยและพัฒนา AI
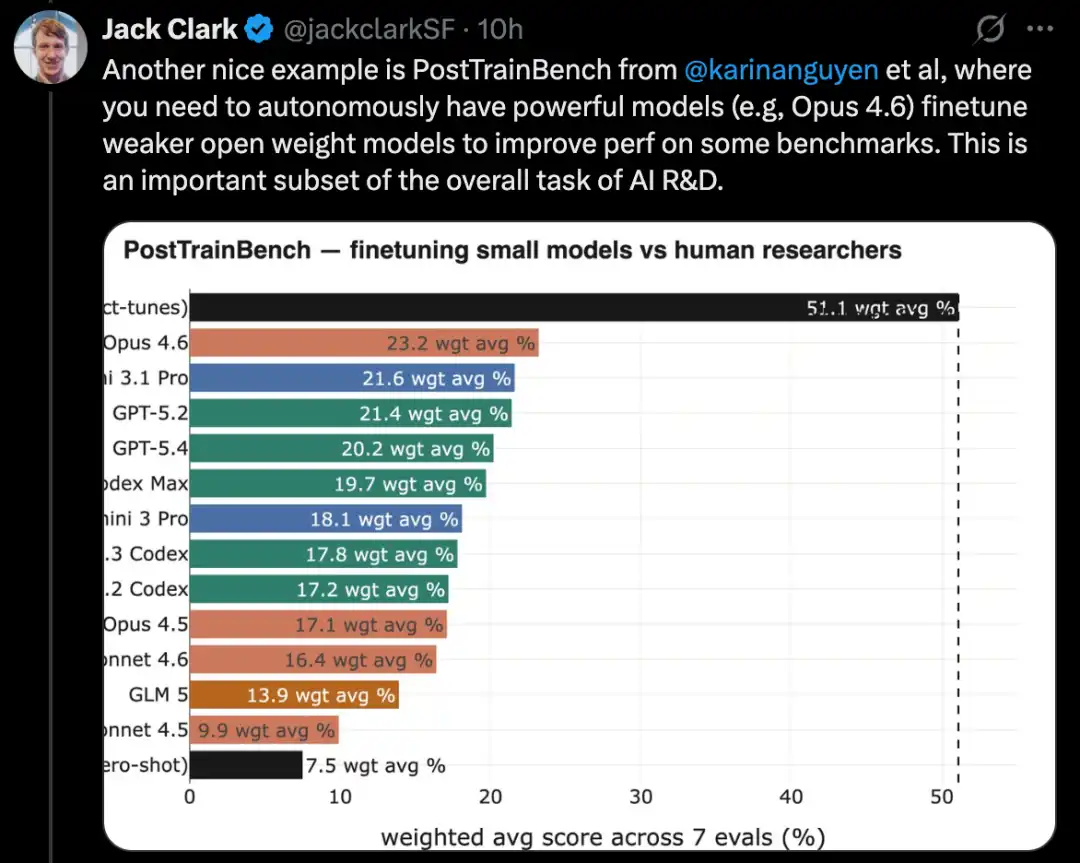
MLE-Bench ใช้ภารกิจการแข่งขันจริงจาก Kaggle ซึ่งต้องการการสร้างแอปพลิเคชันการเรียนรู้ของเครื่องที่หลากหลายเพื่อแก้ไขปัญหาเฉพาะเจาะจง นอกจากนี้ เบิร์นช์การเขียนโค้ดที่รู้จักกันดีอย่าง SWE-Bench ก็แสดงความก้าวหน้าในลักษณะเดียวกัน
แจ็ค คลาร์ก อธิบายปรากฏการณ์นี้ว่าเป็นแนวโน้มที่มีลักษณะแบบ "แฟรคทัล" ที่เลื่อนขึ้นและไปทางขวา ซึ่งสามารถสังเกตเห็นความก้าวหน้าที่มีความหมายได้ในทุกระดับความละเอียดและขนาด เขาเชื่อว่า AI กำลังเข้าใกล้ความสามารถในการพัฒนาแบบอัตโนมัติแบบครบวงจร และเมื่อถึงจุดนั้น AI จะสามารถสร้างระบบ successors ของตัวเองได้อย่างอิสระ นำไปสู่วัฏจักรการปรับปรุงตัวเอง

คำพูดนี้ทำให้เกิดการอภิปรายจำนวนมากบนโซเชียลมีเดีย
บางคนมองว่ามันเป็นขั้นตอนสำคัญแรกสู่ ASI และจุดสุดยอด ซึ่งอาจเปลี่ยนแปลงจังหวะการพัฒนาเทคโนโลยีอย่างสิ้นเชิง

อย่างไรก็ตาม ยังมีเสียงที่แตกต่างกัน
ศาสตราจารย์ด้านวิทยาการคอมพิวเตอร์ของมหาวิทยาลัยวอชิงตัน ปิเอโด โดมิงโกส ชี้ให้เห็นว่า ระบบ AI ตั้งแต่ยุคทศวรรษที่ 50 ตั้งแต่ภาษา LISP ถูกคิดค้นขึ้น ก็มีความสามารถในการ “สร้างตัวเอง” ปัญหาที่แท้จริงคือ能否ได้รับผลตอบแทนแบบเพิ่มขึ้นอย่างต่อเนื่อง แต่ขณะนี้ยังไม่มีหลักฐานที่ชัดเจนสนับสนุนจุดนี้

มีผู้ใช้งานตั้งข้อสงสัยว่า ความน่าจะเป็นเพิ่มขึ้นทันที 30% จากปี 2027 ถึง 2028 ซึ่งบ่งชี้ว่าความสามารถของ AI จะเกิดการก้าวกระโดดอย่างสำคัญใกล้ปลายปี 2027 จุดหมายหรือเหตุการณ์เฉพาะใดที่จะทำให้ความน่าจะเป็นของการปรับปรุงตนเองแบบวนซ้ำของ AI เพิ่มขึ้นอย่างมากในระยะเวลาสั้นๆ?

ผู้ใช้งานรายอื่นยังระบุว่า แจ็ค คลาร์ก ได้รับแต่งตั้งเป็นหัวหน้าฝ่ายประชาสัมพันธ์คนใหม่ของ Anthropic ซึ่งเป็นส่วนหนึ่งของกลยุทธ์ใหม่ของพวกเขา: เราไม่ได้พูดเพื่อสร้างความตื่นตระหนก มีเอกสารวิจัยจำนวนมากที่ยืนยันสิ่งที่เราเตือนคุณมาโดยตลอด
แจ็ค คลาร์ก เขียนบทความยาวโดยละเอียดในนิตยสาร Import AI ฉบับที่ 455
ต่อไป เราจะดูบทความนี้อย่างครบถ้วน
ระบบ AI จะเริ่มสร้างตัวเองขึ้นมา นั่นหมายความว่าอย่างไร?
คลาร์กกล่าวว่าเขาเขียนบทความนี้เพราะหลังจากทบทวนข้อมูลทั้งหมดที่มีอยู่อย่างเปิดเผย เขาต้องสรุปว่าความเป็นไปได้ที่จะเกิดการวิจัยและพัฒนาโดย AI โดยไม่มีมนุษย์มีส่วนร่วมก่อนสิ้นปี 2028 นั้นสูงมาก อาจเกิน 60%
การวิจัย AI ที่ไม่มีมนุษย์มีส่วนร่วมในที่นี้หมายถึงระบบ AI ที่มีความแข็งแกร่งเพียงพอ: ไม่เพียงแต่สามารถช่วยมนุษย์ในการวิจัยเท่านั้น แต่ยังอาจดำเนินกระบวนการวิจัยที่สำคัญด้วยตนเอง หรือแม้แต่สร้างระบบรุ่นถัดไปของตนเอง
ในมุมมองของคลาร์ก นี่เป็นเรื่องใหญ่ชัดเจน
เขาเปิดเผยว่า เขาเองก็ยากที่จะเข้าใจความหมายของเรื่องนี้อย่างสมบูรณ์
การตัดสินใจนี้จึงถูกเรียกว่าเป็นการตัดสินใจที่ไม่เต็มใจ เพราะผลกระทบด้านหลังมีขนาดใหญ่เกินไปจนทำให้เขารู้สึกยากที่จะจับต้องได้ คลาร์กยังไม่แน่ใจว่าสังคมโดยรวมพร้อมรับกับการเปลี่ยนแปลงเชิงลึกที่เกิดจากการอัตโนมัติในการวิจัยและพัฒนา AI หรือไม่
เขาเชื่อตอนนี้ว่ามนุษย์อาจกำลังอาศัยอยู่ในช่วงเวลาพิเศษ: การวิจัยด้าน AI จะถูกอัตโนมัติแบบครบวงจรในไม่ช้า หากช่วงเวลานี้เกิดขึ้นจริง มนุษย์ก็เหมือนข้ามแม่น้ำรูบิคอนไปสู่อนาคตที่แทบจะคาดเดาไม่ได้
คลาร์กกล่าวว่า จุดประสงค์ของบทความนี้คืออธิบายว่าทำไมเขาจึงเชื่อว่า การขึ้นสู่การวิจัย AI แบบอัตโนมัติเต็มรูปแบบกำลังเกิดขึ้น
เขาจะพูดถึงผลลัพธ์บางประการที่อาจเกิดขึ้นจากแนวโน้มนี้ แต่ส่วนใหญ่ของบทความจะมุ่งเน้นไปที่หลักฐานที่สนับสนุนการตัดสินนี้ ส่วนผลกระทบเชิงลึกอื่นๆ คลาร์กวางแผนที่จะศึกษาต่อไปในช่วงส่วนใหญ่ของปีนี้
จากมุมมองของเวลา คลาร์กไม่เชื่อว่าเหตุการณ์นี้จะเกิดขึ้นจริงในปี 2026 แต่เขาเชื่อว่าในอีกหนึ่งถึงสองปีข้างหน้า เราอาจเห็นตัวอย่างของโมเดลที่ฝึกตนเองให้เป็นผู้สืบทอดแบบ end-to-end อย่างน้อยในระดับโมเดลที่ไม่ใช่ขั้นสูงสุด การพิสูจน์แนวคิดนี้มีความเป็นไปได้สูง; ส่วนโมเดลขั้นสูงสุดนั้นจะยากกว่า เนื่องจากมีต้นทุนสูงมากและพึ่งพาความพยายามอย่างหนักของนักวิจัยมนุษย์จำนวนมาก
การตัดสินใจของคลาร์กมาจากการใช้ข้อมูลสาธารณะ: รวมถึงบทความบน arXiv, bioRxiv และ NBER รวมถึงผลิตภัณฑ์ที่บริษัท AI ชั้นนำได้ดำเนินการใช้งานในโลกแห่งความเป็นจริง บนพื้นฐานของข้อมูลเหล่านี้ เขาสรุปว่ากระบวนการผลิตอัตโนมัติสำหรับแต่ละส่วนที่จำเป็นต่อระบบ AI ในปัจจุบัน โดยเฉพาะส่วนด้านวิศวกรรมในกระบวนการพัฒนา AI นั้น มีความพร้อมแล้วโดยพื้นฐาน
หากแนวโน้มการปรับขนาดยังคงดำเนินต่อไป เราควรเริ่มเตรียมตัวรับมือกับสถานการณ์ที่ว่า แบบจำลองจะมีความสร้างสรรค์เพียงพอที่ไม่เพียงแต่สามารถปรับปรุงวิธีการที่รู้จักอยู่แล้วอัตโนมัติ แต่ยังอาจแทนที่นักวิจัยมนุษย์ในการเสนอทิศทางการวิจัยใหม่ๆ และแนวคิดดั้งเดิม จึงสามารถขับเคลื่อนขอบเขตของ AI ต่อไปได้ด้วยตนเอง
Coding Singularity: How Abilities Change Over Time
ระบบ AI ถูกดำเนินการผ่านซอฟต์แวร์ ซึ่งประกอบด้วยโค้ด
ระบบ AI ได้เปลี่ยนแปลงวิธีการผลิตโค้ดอย่างสิ้นเชิง ซึ่งมีแนวโน้มที่เกี่ยวข้องกันสองประการ: ประการแรก ระบบ AI กำลังเชี่ยวชาญขึ้นในการเขียนโค้ดจริงที่ซับซ้อน; ประการที่สอง ระบบ AI ยังเชี่ยวชาญขึ้นในการเชื่อมต่อภารกิจการเขียนโค้ดแบบเชิงเส้นหลายขั้นตอนให้ทำงานร่วมกันโดยแทบไม่ต้องพึ่งการควบคุมจากมนุษย์ เช่น เขียนโค้ดก่อน แล้วจึงทดสอบ
ตัวอย่างที่เด่นชัดสองตัวอย่างที่แสดงแนวโน้มนี้คือ SWE-Bench และ METR time horizons plot
แก้ปัญหาวิศวกรรมซอฟต์แวร์ในโลกแห่งความเป็นจริง
SWE-Bench เป็นการทดสอบการเขียนโปรแกรมที่ใช้กันอย่างแพร่หลายในการประเมินความสามารถของระบบ AI ในการแก้ไขปัญหาจริงบน GitHub
เมื่อ SWE-Bench เปิดตัวในปลายปี 2023 โมเดลที่มีประสิทธิภาพดีที่สุดในเวลานั้นคือ Claude 2 โดยอัตราความสำเร็จโดยรวมมีเพียงประมาณ 2% ในขณะที่ Claude Mythos Preview ทำคะแนนได้ถึง 93.9% ใกล้เคียงกับการทำคะแนนเต็มใน benchmark นี้
แน่นอน ค่า benchmark ทั้งหมดล้วนมีเสียงรบกวนอยู่บ้าง ดังนั้นจึงมักเกิดช่วงหนึ่งที่เมื่อคะแนนสูงถึงระดับหนึ่ง ปัญหาที่คุณพบอาจไม่ใช่ข้อจำกัดของวิธีการเอง แต่เป็นข้อจำกัดของ benchmark นั้นๆ เช่น ในชุดข้อมูล ImageNet validation set มีป้ายกำกับประมาณ 6% ที่ผิดหรือคลุมเครือ
SWE-Bench สามารถถือเป็นตัวชี้วัดที่เชื่อถือได้สำหรับการวัดความสามารถในการเขียนโปรแกรมทั่วไป รวมถึงผลกระทบของ AI ต่อวิศวกรรมซอฟต์แวร์ คลาร์กกล่าวว่า ผู้คนส่วนใหญ่ที่เขาได้พบในห้องปฏิบัติการ AI ชั้นนำและซิลิคอนแวลลีย์ตอนนี้แทบจะเขียนโค้ดผ่านระบบ AI ทั้งหมดแล้ว และยิ่งมีคนมากขึ้นเรื่อยๆ ที่เริ่มใช้ระบบ AI เพื่อเขียนการทดสอบและตรวจสอบโค้ด
พูดอีกแบบคือ ระบบ AI มีความแข็งแรงเพียงพอที่จะอัตโนมัติส่วนสำคัญหนึ่งของงานวิจัย AI และเร่งความเร็วอย่างมีนัยสำคัญสำหรับนักวิจัยและวิศวกรทุกคนที่มีส่วนร่วมในการวิจัย AI
วัดความสามารถของระบบ AI ในการดำเนินงานระยะยาว
METR ได้สร้างแผนภูมิเพื่อวัดระดับความซับซ้อนของงานที่ AI สามารถทำได้ โดยความซับซ้อนนี้คำนวณจากเวลาเป็นชั่วโมงที่มนุษย์ผู้มีทักษะใช้ในการทำงานเหล่านั้น
ตัวชี้วัดที่สำคัญที่สุดคือช่วงเวลาของงานที่ระบบที่ AI สามารถบรรลุความน่าเชื่อถือ 50% บนชุดงานหนึ่ง
ในจุดนี้ ความคืบหน้าเป็นที่น่าประทับใจมาก:
ในปี 2022 งานที่ GPT-3.5 สามารถทำได้ ประมาณเทียบเท่ากับงานที่มนุษย์ต้องใช้เวลา 30 วินาที
· ในปี 2023 GPT-4 ได้ยกระดับเวลาดังกล่าวเป็น 4 นาที
· ในปี 2024 o1 ได้ยกระดับเวลาดังกล่าวเป็น 40 นาที
· ในปี 2025 GPT-5.2 High ใช้เวลาประมาณ 6 ชั่วโมง
· ถึงปี 2026 Opus 4.6 ได้ผลักเวลาดังกล่าวให้สูงขึ้นอีกเป็นประมาณ 12 ชั่วโมง
Ajeya Cotra ซึ่งทำงานที่ METR และติดตามการพยากรณ์ด้าน AI มาอย่างยาวนาน มองว่า การที่ระบบ AI สามารถทำงานที่มนุษย์ต้องใช้เวลา 100 ชั่วโมงได้ ภายในสิ้นปี 2026 ไม่ใช่ความคาดหวังที่ไม่สมเหตุสมผล
ช่วงเวลาที่ระบบ AI สามารถทำงานได้อย่างอิสระได้เพิ่มขึ้นอย่างมีนัยสำคัญ และสอดคล้องอย่างมากกับการระเบิดของเครื่องมือ agentic coding เครื่องมือ agentic coding คือการผลิตระบบ AI ที่สามารถทำงานแทนมนุษย์ให้เป็นผลิตภัณฑ์: เครื่องมือเหล่านี้สามารถดำเนินการแทนมนุษย์และขับเคลื่อนงานได้อย่างอิสระในช่วงเวลาที่ค่อนข้างยาว
สิ่งนี้ยังกลับมาชี้ไปที่การวิจัยและพัฒนา AI เอง การสังเกตอย่างละเอียดถึงงานประจำวันของนักวิจัย AI จำนวนมากจะพบว่า งานจำนวนมากสามารถแยกออกเป็นงานที่ใช้เวลาไม่เกินไม่กี่ชั่วโมง เช่น การทำความสะอาดข้อมูล การอ่านข้อมูล การเริ่มต้นการทดลอง เป็นต้น
และงานประเภทนี้ ตอนนี้อยู่ในช่วงเวลาที่ระบบ AI สมัยใหม่สามารถครอบคลุมได้
ยิ่งระบบ AI ชำนาญมากเท่าใด ก็ยิ่งสามารถทำงานได้อย่างอิสระจากมนุษย์ และยิ่งสามารถช่วยในการอัตโนมัติบางส่วนของการวิจัยและพัฒนา AI
ปัจจัยหลักในการมอบหมายงานมีสองประการ:
· ประการแรกคือความเชื่อมั่นในความสามารถของผู้รับมอบหมาย
· ประการที่สองคือคุณเชื่อว่าอีกฝ่ายสามารถทำงานให้เสร็จตามเจตนาของคุณได้อย่างอิสระ โดยไม่ต้องพึ่งพาการตรวจสอบอย่างต่อเนื่องจากคุณ
เมื่อผู้ใช้สังเกตความสามารถของ AI ในด้านการเขียนโปรแกรม จะพบว่าระบบ AI ไม่เพียงแต่กลายเป็นเชี่ยวชาญมากขึ้นเรื่อยๆ แต่ยังสามารถทำงานได้นานขึ้นโดยไม่ต้องให้มนุษย์ปรับเทียบใหม่
สิ่งนี้สอดคล้องกับสิ่งที่กำลังเกิดขึ้นรอบตัวเรา วิศวกรและนักวิจัยกำลังมอบงานที่มีขนาดใหญ่ขึ้นเรื่อยๆ ให้ระบบ AI ดำเนินการ พร้อมกับที่ความสามารถของ AI ยังคงพัฒนาอย่างต่อเนื่อง งานที่ได้รับมอบหมายให้ AI ทำก็ยิ่งซับซ้อนและสำคัญมากขึ้น
ปัญญาประดิษฐ์กำลังเชี่ยวชาญทักษะทางวิทยาศาสตร์หลักที่จำเป็นสำหรับการวิจัยและพัฒนาปัญญาประดิษฐ์
คิดถึงวิธีการที่งานวิจัยทางวิทยาศาสตร์สมัยใหม่ดำเนินการ โดยส่วนใหญ่ของงานจะเริ่มจากการกำหนดทิศทางที่ชัดเจน และระบุให้แน่ชัดว่าต้องการข้อมูลเชิงประจักษ์ประเภทใด จากนั้นจึงออกแบบและดำเนินการทดลองเพื่อสร้างข้อมูลเหล่านั้น และสุดท้ายจึงตรวจสอบความสมเหตุสมผลของผลการทดลอง
ด้วยความสามารถในการเขียนโปรแกรมของ AI ที่เพิ่มขึ้นอย่างต่อเนื่อง ร่วมกับความสามารถในการสร้างแบบจำลองโลกที่แข็งแกร่งขึ้นของโมเดลภาษาขนาดใหญ่ ขณะนี้ได้เกิดเครื่องมือชุดหนึ่งที่สามารถช่วยนักวิทยาศาสตร์มนุษย์เร่งความเร็วและอัตโนมัติบางขั้นตอนในบริบทการวิจัยและพัฒนาที่กว้างขวางยิ่งขึ้น
ที่นี่ เราสามารถสังเกตความก้าวหน้าของ AI ในทักษะทางวิทยาศาสตร์หลักหลายด้าน ซึ่งทักษะเหล่านี้เองก็เป็นส่วนสำคัญของการวิจัย AI:
· ประการแรกคือการจำลองผลการวิจัย;
· ประการที่สองคือการเชื่อมโยงเทคโนโลยีการเรียนรู้ของเครื่องเข้ากับวิธีการอื่นๆ เพื่อแก้ไขปัญหาทางเทคนิค;
· ประการที่สาม คือการปรับปรุงระบบ AI ของตนเอง
ดำเนินการเขียนบทความวิจัยฉบับเต็มและดำเนินการทดลองที่เกี่ยวข้อง
งานหลักอย่างหนึ่งในการวิจัยปัญญาประดิษฐ์คือการอ่านบทความวิชาการและทำซ้ำผลลัพธ์ที่ระบุไว้ในนั้น ในด้านนี้ ปัญญาประดิษฐ์ได้บรรลุความก้าวหน้าอย่างเด่นชัดบนชุดการทดสอบหลายชุด
ตัวอย่างที่ดีคือ CORE-Bench หรือ Computational Reproducibility Agent Benchmark
การทดสอบนี้ต้องการให้ระบบ AI สามารถทำซ้ำผลลัพธ์ของบทความเมื่อได้รับบทความและที่เก็บรหัสของมัน โดยเฉพาะอย่างยิ่ง ตัวแทนต้องติดตั้งไลบรารี แพ็กเกจ และการพึ่งพาที่เกี่ยวข้อง แล้วรันรหัส; หากรหัสรันสำเร็จ ตัวแทนยังต้องค้นหาผลลัพธ์ทั้งหมด และตอบคำถามในงาน
CORE-Bench ถูกเสนอในเดือนกันยายน 2024 ระบบที่มีประสิทธิภาพดีที่สุดในเวลานั้นคือโมเดล GPT-4o ที่ทำงานบนโครงสร้าง CORE-Agent โดยได้คะแนนประมาณ 21.5% บนชุดงานที่ยากที่สุดของ benchmark นี้
ในเดือนธันวาคม 2025 หนึ่งในผู้เขียน CORE-Bench ประกาศว่า benchmark นี้ได้รับการแก้ไขแล้ว: โมเดล Opus 4.5 ได้คะแนน 95.5%
สร้างระบบการเรียนรู้ของเครื่องอย่างสมบูรณ์เพื่อแก้ปัญหาการแข่งขันบน Kaggle
MLE-Bench เป็น benchmark ที่ OpenAI สร้างขึ้นเพื่อทดสอบความสามารถของระบบ AI ในการเข้าร่วมการแข่งขันบน Kaggle ในสภาพแวดล้อมแบบออฟไลน์
มันครอบคลุมการแข่งขัน Kaggle 75 ประเภทที่แตกต่างกัน ซึ่งเกี่ยวข้องกับหลายสาขา เช่น การประมวลผลภาษาธรรมชาติ การมองเห็นของเครื่อง และการประมวลผลสัญญาณ เป็นต้น
MLE-Bench ออกในเดือนตุลาคม 2024 เมื่อเปิดตัว ระบบที่มีประสิทธิภาพดีที่สุดคือโมเดล o1 ที่ทำงานบน agent scaffold โดยได้คะแนน 16.9%
จนถึงเดือนกุมภาพันธ์ 2026 ระบบที่มีประสิทธิภาพดีที่สุดได้กลายเป็น Gemini 3 ที่ทำงานบน agent harness ที่มีความสามารถในการค้นหา โดยได้คะแนน 64.4%
การออกแบบ Kernel
งานที่ยากกว่าอย่างหนึ่งในการพัฒนา AI คือการปรับแต่ง kernel การปรับแต่ง kernel หมายถึงการเขียนและปรับปรุงโค้ดระดับล่างเพื่อแมปการคำนวณเฉพาะ เช่น การคูณเมทริกซ์ ให้มีประสิทธิภาพสูงขึ้นบนฮาร์ดแวร์ระดับล่าง
การปรับแต่ง Kernel เป็นหัวใจสำคัญของการพัฒนา AI เพราะมันกำหนดประสิทธิภาพของการฝึกอบรมและการให้บริการ: ในด้านหนึ่ง มันส่งผลต่อปริมาณพลังการประมวลผลที่คุณสามารถใช้ประโยชน์ได้อย่างมีประสิทธิภาพขณะพัฒนาระบบ AI และในอีกด้านหนึ่ง เมื่อการฝึกอบรมโมเดลเสร็จสิ้น มันก็กำหนดว่าคุณจะสามารถแปลงพลังการประมวลผลเป็นความสามารถในการให้บริการได้อย่างมีประสิทธิภาพเพียงใด
ในช่วงไม่กี่ปีที่ผ่านมา การใช้ AI ในการออกแบบ kernel ได้เปลี่ยนจากทิศทางเล็กๆ ที่น่าสนใจ ให้กลายเป็นพื้นที่วิจัยที่มีการแข่งขันสูง และมี benchmark หลายตัวเกิดขึ้น อย่างไรก็ตาม ปัจจุบัน benchmark เหล่านี้ยังไม่เป็นที่นิยมอย่างกว้างขวาง จึงทำให้เราพบความยากในการสร้างแบบจำลองความก้าวหน้าระยะยาวของมันอย่างชัดเจนเหมือนกับสาขาอื่นๆ ในทางกลับกัน เราสามารถรับรู้ถึงความเร็วในการพัฒนาของทิศทางนี้ผ่านงานวิจัยที่กำลังดำเนินอยู่
งานที่เกี่ยวข้องรวมถึง:
· ใช้โมเดลของ DeepSeek เพื่อพยายามสร้าง GPU kernel ที่ดีกว่า;
แปลงโมดูล PyTorch เป็นรหัส CUDA อัตโนมัติ
· เมตาใช้ LLM สร้างและปรับปรุง kernel Triton อัตโนมัติ และปรับใช้บนโครงสร้างพื้นฐานของตนเอง;
· และปรับแต่งน้ำหนักโมเดลแบบเปิดแหล่งที่มาสำหรับ GPU kernel เช่น Cuda Agent
ต้องเสริมอีก一点: การออกแบบ kernel มีคุณสมบัติบางอย่างที่เหมาะอย่างยิ่งสำหรับการวิจัยและพัฒนาที่ขับเคลื่อนด้วย AI เช่น ผลลัพธ์ตรวจสอบได้ง่ายและสัญญาณรางวัลชัดเจน
ปรับแต่งโมเดลภาษาผ่าน PostTrainBench
เวอร์ชันที่ยากกว่าของการทดสอบประเภทนี้คือ PostTrainBench ซึ่งทดสอบว่าโมเดลชั้นนำต่างๆ สามารถรับโมเดลน้ำหนักเปิดแหล่งที่มาขนาดเล็กและปรับปรุงประสิทธิภาพของพวกมันบน benchmark บางอย่างผ่านการปรับแต่งได้หรือไม่
ข้อดีอย่างหนึ่งของ benchmark นี้คือมีฐานมนุษย์ที่แข็งแกร่งมาก: เวอร์ชันที่ปรับแต่งด้วยคำสั่งที่มีอยู่แล้วของโมเดลเล็กๆ เหล่านี้ โดยเวอร์ชันเหล่านี้มักถูกพัฒนาโดยนักวิจัย AI ที่เก่งกาจในห้องปฏิบัติการชั้นนำ ผ่านการปรับแต่งโดยนักวิจัยและวิศวกรที่มีความสามารถสูง และถูกนำไปใช้งานในโลกจริง ดังนั้นจึงสร้างฐานมนุษย์ที่ยากจะเกินข้าม
จนถึงเดือนมีนาคม 2026 ระบบ AI สามารถทำการฝึกต่อแบบจำลองได้ และได้รับการปรับปรุงประสิทธิภาพประมาณครึ่งหนึ่งของผลลัพธ์ที่ได้จากการฝึกของมนุษย์
คะแนนการประเมินเฉพาะมาจากการเฉลี่ยถ่วงน้ำหนัก: รวมผลจากโมเดลภาษาขนาดใหญ่หลังการฝึกหลายตัว ได้แก่ Qwen 3 1.7B, Qwen 3 4B, SmolLM3-3B, Gemma 3 4B และชุดการทดสอบหลายชุด ได้แก่ AIME 2025, Arena Hard, BFCL, GPQA Main, GSM8K, HealthBench, HumanEval
ในแต่ละครั้งที่รัน ผู้ประเมินจะขอให้ CLI agent พยายามปรับปรุงประสิทธิภาพของโมเดลพื้นฐานเฉพาะเจาะจงบน benchmark เฉพาะเจาะจง
จนถึงเดือนเมษายน 2026 ระบบ AI ที่มีคะแนนสูงที่สุดอยู่ที่ประมาณ 25% ถึง 28% ซึ่งรวมถึงโมเดลเช่น Opus 4.6 และ GPT 5.4; ในทางกลับกัน คะแนนของมนุษย์อยู่ที่ 51%
นี่เป็นผลลัพธ์ที่มีความหมายอย่างมากแล้ว
ปรับปรุงการฝึกโมเดลภาษา
ในปีที่ผ่านมา Anthropic ได้รายงานประสิทธิภาพของระบบในภารกิจการฝึกอบรม LLM ภารกิจนี้ต้องการให้โมเดลปรับปรุงการดำเนินการฝึกอบรมโมเดลภาษาขนาดเล็กที่ใช้ CPU เพียงอย่างเดียว เพื่อให้ทำงานได้เร็วที่สุดเท่าที่จะเป็นไปได้
วิธีการให้คะแนนคือ: จำนวนเท่าที่โมเดลเร่งความเร็วโดยเฉลี่ยเมื่อเปรียบเทียบกับรหัสเริ่มต้นที่ไม่ได้แก้ไข
ผลลัพธ์นี้มีความก้าวหน้าอย่างมาก:
· ในเดือนพฤษภาคม 2025, Claude Opus 4 บรรลุความเร็วเฉลี่ยเพิ่มขึ้น 2.9 เท่า;
· ในเดือนพฤศจิกายน 2025, Opus 4.5 เพิ่มขึ้นเป็น 16.5 เท่า;
· ในเดือนกุมภาพันธ์ 2026, Opus 4.6 แตะระดับ 30 เท่า;
· ในเดือนเมษายน 2026 Claude Mythos Preview แตะระดับ 52 เท่า
เพื่อเข้าใจความหมายของตัวเลขเหล่านี้ สามารถเปรียบเทียบได้ว่า งานนี้โดยทั่วไปใช้เวลา 4 ถึง 8 ชั่วโมงในการทำงานของนักวิจัยมนุษย์ เพื่อให้ได้ความเร็วเพิ่มขึ้น 4 เท่า
ทักษะพื้นฐาน: การจัดการ
ระบบปัญญาประดิษฐ์กำลังเรียนรู้วิธีจัดการระบบปัญญาประดิษฐ์อื่นๆ
จุดนี้สามารถเห็นได้แล้วในผลิตภัณฑ์บางอย่างที่ถูกนำไปใช้งานอย่างกว้างขวาง เช่น Claude Code หรือ OpenCode ในผลิตภัณฑ์เหล่านี้ ตัวแทนหลักสามารถดูแลตัวแทนย่อยหลายตัว
สิ่งนี้ทำให้ระบบ AI สามารถจัดการโครงการขนาดใหญ่ขึ้น: โครงการอาจต้องการตัวแทนหลายตัวที่มีความเชี่ยวชาญต่างกันทำงานพร้อมกัน โดยทั่วไปจะมีผู้จัดการ AI เพียงหนึ่งรายที่ประสานงานพวกเขา ผู้จัดการนี้เองก็เป็นระบบ AI
การวิจัยด้านปัญญาประดิษฐ์คล้ายกับการค้นพบทฤษฎีสัมพัทธภาพทั่วไป หรือการเล่นเลโก้?
คำถามสำคัญประการหนึ่งคือ: ปัญญาประดิษฐ์สามารถสร้างแนวคิดใหม่ๆ ที่ช่วยปรับปรุงตัวเองได้หรือไม่? หรือระบบเหล่านี้เหมาะกับงานที่ไม่ได้โดดเด่นแต่จำเป็นต้องค่อยๆ ก้าวไปทีละขั้นตอนในงานวิจัยมากกว่า?
คำถามนี้สำคัญมาก เพราะเกี่ยวข้องกับระดับที่ระบบ AI สามารถอัตโนมัติการวิจัย AI แบบครบวงจรได้ถึงไหน
การตัดสินของผู้เขียนคือ: ปัจจุบัน AI ยังไม่สามารถเสนอความคิดใหม่ที่รุนแรงได้จริง แต่เพื่อให้บรรลุการอัตโนมัติในการวิจัยและพัฒนาของตนเอง มันอาจไม่จำเป็นต้องทำเช่นนั้น
ในแง่ของสาขา ความก้าวหน้าของ AI ขึ้นอยู่กับการทดลองที่มีขนาดใหญ่ขึ้นเรื่อยๆ และการรับข้อมูลที่เพิ่มขึ้น เช่น ข้อมูลและกำลังการประมวลผล
บางครั้งมนุษย์เสนอแนวคิดที่เปลี่ยนแปลงรูปแบบ ทำให้ประสิทธิภาพการใช้ทรัพยากรในทั้งสาขาเพิ่มขึ้นอย่างมาก สถาปัตยกรรม Transformer เป็นตัวอย่างที่ดี และโมเดลผู้เชี่ยวชาญแบบผสม หรือ mixture-of-experts ก็เป็นอีกตัวอย่างหนึ่ง
แต่ในหลายครั้ง การพัฒนาในด้านปัญญาประดิษฐ์กลับมีวิธีการที่เรียบง่ายกว่า: มนุษย์จะนำระบบที่ทำงานได้ดีมาขยายด้านใดด้านหนึ่ง เช่น ข้อมูลการฝึกอบรมและพลังการคำนวณ; สังเกตว่าเมื่อขยายขนาดแล้วเกิดปัญหาที่ไหน; หาวิธีแก้ไขทางวิศวกรรมเพื่อให้ระบบสามารถขยายขนาดต่อไปได้; จากนั้นจึงขยายขนาดอีกครั้ง
ในกระบวนการนี้ ส่วนที่ต้องการความเข้าใจลึกซึ้งจริงๆ มีไม่มากนัก งานส่วนใหญ่คล้ายกับวิศวกรรมพื้นฐานที่ไม่ได้โดดเด่น แต่มั่นคงและแน่นหนา
ในทำนองเดียวกัน การวิจัยด้าน AI ส่วนใหญ่เป็นการดำเนินการทดลองที่มีอยู่ในรูปแบบต่างๆ เพื่อสำรวจว่าการตั้งค่าพารามิเตอร์ที่แตกต่างกันจะส่งผลลัพธ์อย่างไร ความเข้าใจเชิงสัญชาตญาณของมนุษย์แน่นอนว่าสามารถช่วยเลือกพารามิเตอร์ที่คุ้มค่าในการทดลอง แต่กระบวนการนี้เองก็สามารถถูกอัตโนมัติได้ โดยให้ AI ตัดสินเองว่าพารามิเตอร์ใดควรปรับเปลี่ยน การค้นหาสถาปัตยกรรมประสาทเทียมในระยะเริ่มต้น เป็นหนึ่งในเวอร์ชันของแนวคิดนี้
เอ็ดดิสันเคยกล่าวว่า: ความเป็นอัจฉริยะคือ 1% ของแรงบันดาลใจ บวกกับ 99% ของเหงื่อ แม้จะผ่านไป 150 ปีแล้ว คำพูดนี้ก็ยังคงเหมาะสมอยู่
บางครั้ง อาจมีการค้นพบใหม่ที่เปลี่ยนแปลงทั้งอุตสาหกรรมอย่างสิ้นเชิง แต่ส่วนใหญ่แล้ว ความก้าวหน้าของอุตสาหกรรมเกิดจากการทำงานอย่างหนักของมนุษย์ในการปรับปรุงและแก้ไขระบบต่างๆ อย่างค่อยเป็นค่อยไป
ข้อมูลสาธารณะที่กล่าวถึงก่อนหน้านี้แสดงให้เห็นว่า AI ได้เชี่ยวชาญในการดำเนินงานที่จำเป็นแต่หนักหน่วงมากมายในการพัฒนา AI
ในขณะเดียวกัน มีแนวโน้มที่ใหญ่กว่านั้นอีก: ทักษะพื้นฐาน เช่น ทักษะการเขียนโปรแกรม กำลังถูกผสานเข้ากับช่วงเวลาของงานที่ขยายตัวอย่างต่อเนื่อง ซึ่งหมายความว่าระบบ AI สามารถเชื่อมโยงงานประเภทนี้จำนวนมากเข้าด้วยกัน เพื่อสร้างลำดับงานที่ซับซ้อน
ดังนั้น แม้ว่าระบบปัญญาประดิษฐ์ในปัจจุบันจะมีความคิดสร้างสรรค์ค่อนข้างน้อย ก็ยังมีเหตุผลที่เชื่อว่ามันยังสามารถผลักดันตัวเองให้ก้าวหน้าต่อไปได้ เพียงแต่ความเร็วในการก้าวหน้านี้อาจช้ากว่าเมื่อเทียบกับกรณีที่สามารถสร้างความเข้าใจใหม่ๆ ได้
แต่หากยังคงสังเกตข้อมูลสาธารณะต่อไป จะพบสัญญาณที่น่าสนใจอีกประการหนึ่ง: ระบบ AI อาจกำลังแสดงความคิดสร้างสรรค์บางอย่าง ซึ่งอาจทำให้พวกมันผลักดันการพัฒนาของตนเองในวิธีที่น่าประหลาดใจยิ่งขึ้น
ผลักดันขอบเขตของวิทยาศาสตร์ให้ก้าวหน้าต่อไป
ขณะนี้มีสัญญาณเริ่มต้นบางประการที่แสดงว่าระบบ AI ทั่วไปมีศักยภาพในการผลักดันขอบเขตของวิทยาศาสตร์มนุษย์ให้ก้าวหน้าต่อไป อย่างไรก็ตาม จนถึงขณะนี้ สถานการณ์ดังกล่าวเกิดขึ้นเฉพาะในบางสาขาเท่านั้น โดยส่วนใหญ่คือวิทยาการคอมพิวเตอร์และคณิตศาสตร์ และในหลายกรณี ไม่ใช่ระบบ AI ที่บรรลุความก้าวหน้าเพียงลำพัง แต่เกิดขึ้นผ่านความร่วมมือระหว่างมนุษย์กับเครื่องจักร ร่วมกับนักวิจัยมนุษย์ในการผลักดันให้เกิดความก้าวหน้า
แม้เช่นนั้น แนวโน้มเหล่านี้ยังคงน่าจับตา:
ปัญหาของ Erdős: กลุ่มนักคณิตศาสตร์ร่วมมือกับโมเดล Gemini เพื่อทดสอบความสามารถของมันในการแก้ปัญหาคณิตศาสตร์ของ Erdős พวกเขาได้แนะนำระบบให้ลองแก้ปัญหาประมาณ 700 ข้อ และได้คำตอบที่สำเร็จ 13 ข้อ ในจำนวนนี้ มี 1 ข้อที่พวกเขาพิจารณาว่าน่าสนใจ
นักวิจัยเขียนว่า พวกเขาเชื่อเบื้องต้นว่า การแก้ปัญหา Erdős-1051 โดย Aletheia (ระบบ AI ที่อิงจาก Gemini 3 Deep Think) ถือเป็นกรณีตัวอย่างเบื้องต้น: ระบบ AI ที่สามารถแก้ปัญหา Erdős แบบเปิดที่มีความไม่ธรรมดาเล็กน้อยและมีความสนใจทางคณิตศาสตร์ในวงกว้างมากขึ้น ปัญหานี้ก่อนหน้านี้มีเอกสารวิจัยที่เกี่ยวข้องใกล้เคียงอยู่แล้ว
หากตีความในเชิงบวก กรณีเหล่านี้สามารถมองว่าเป็นสัญญาณว่า ระบบ AI กำลังพัฒนาความรู้สึกเชิงสร้างสรรค์ที่สามารถผลักดันขอบเขตของสาขาให้ก้าวหน้า ซึ่งในอดีตเป็นสิ่งที่มนุษย์เป็นผู้มีเพียงผู้เดียว
แต่ก็สามารถตีความอีกมุมหนึ่งได้ว่า คณิตศาสตร์และวิทยาการคอมพิวเตอร์อาจเป็นสาขาที่เหมาะกับการค้นพบที่ขับเคลื่อนด้วย AI โดยเฉพาะ ดังนั้นอาจเป็นเพียงข้อยกเว้น และไม่ได้แสดงว่าการวิจัยทางวิทยาศาสตร์ในวงกว้างอื่นๆ จะถูกขับเคลื่อนโดย AI ด้วยวิธีเดียวกัน
ตัวอย่างที่คล้ายกันคือการเดินที่ 37 ของ AlphaGo อย่างไรก็ตาม คลาร์กเชื่อว่า แม้จะผ่านมาแล้วสิบปีนับตั้งแต่ผลลัพธ์ของ AlphaGo แต่การเดินที่ 37 ยังไม่ถูกแทนที่ด้วยการค้นพบที่ทันสมัยหรือประทับใจกว่า ซึ่งเองก็สามารถถือเป็นสัญญาณที่ค่อนข้างมองโลกในแง่ร้าย
AI สามารถทำงานจำนวนมากในวิศวกรรม AI ได้โดยอัตโนมัติ
หากนำหลักฐานทั้งหมดข้างต้นมารวมกัน เราจะเห็นภาพรวมดังนี้:
ระบบ AI ได้รับการพัฒนาให้สามารถเขียนโค้ดสำหรับโปรแกรมเกือบทุกประเภท และระบบเหล่านี้สามารถเชื่อถือได้ในการดำเนินงานบางอย่างด้วยตนเอง; งานเหล่านี้หากมอบให้คนทำ จะต้องใช้แรงงานที่ต้องมุ่งความสนใจอย่างเข้มข้นเป็นเวลาหลายสิบชั่วโมง
ระบบ AI กำลังเชี่ยวชาญขึ้นในการดำเนินงานหลักๆ ของการพัฒนา AI ตั้งแต่การปรับแต่งโมเดลจนถึงการออกแบบเคอร์เนล ซึ่งกำลังถูกครอบคลุมทีละขั้นตอน
ระบบ AI ได้รับความสามารถในการจัดการระบบ AI อื่นๆ สร้างเป็นทีมสังเคราะห์จริงๆ: AI หลายตัวสามารถแยกกันจัดการปัญหาที่ซับซ้อน โดยบางตัวทำหน้าที่เป็นผู้นำ ผู้วิจารณ์ และผู้แก้ไข ส่วนอีกบางตัวทำหน้าที่เป็นวิศวกร
ระบบ AI บางครั้งสามารถทำผลงานเกินมนุษย์ในงานด้านวิศวกรรมและวิทยาศาสตร์ที่ยากลำบาก แม้ว่าในปัจจุบันยังยากที่จะระบุว่า สิ่งนี้เกิดขึ้นเพราะพวกมันมีความคิดสร้างสรรค์ที่แท้จริง หรือเพราะพวกมันเชี่ยวชาญในการใช้ความรู้แบบรูปแบบต่างๆ อย่างชำนาญ
ในมุมมองของคลาร์ก หลักฐานเหล่านี้แสดงให้เห็นอย่างมีน้ำหนักว่า AI ในปัจจุบันสามารถอัตโนมัติงานจำนวนมากในวงจรวิศวกรรม AI ได้ แม้แต่อาจครอบคลุมทุกขั้นตอน
อย่างไรก็ตาม ขณะนี้ยังไม่ชัดเจนว่า AI สามารถอัตโนมัติการวิจัย AI เองได้มากเพียงใด เพราะบางส่วนของการวิจัยอาจแตกต่างจากทักษะด้านวิศวกรรมบริสุทธิ์ และยังคงต้องพึ่งการตัดสินใจระดับสูง ความตระหนักในปัญหา และความคิดสร้างสรรค์
แต่ไม่ว่าอย่างไร สัญญาณที่ชัดเจนได้ปรากฏขึ้นแล้ว: AI ในวันนี้กำลังเร่งความเร็วอย่างมากในการพัฒนา AI ทำให้นักวิจัยและวิศวกรเหล่านี้สามารถขยายความสามารถของตนเองได้ผ่านการร่วมมือกับเพื่อนร่วมงานเสมือนจำนวนมาก
สุดท้าย อุตสาหกรรม AI เองก็แทบจะพูดตรงๆ ว่า การพัฒนา AI อัตโนมัติคือเป้าหมายของพวกเขา
OpenAI ต้องการสร้างผู้ช่วยวิจัย AI อัตโนมัติให้เสร็จก่อนเดือนกันยายน 2026 Anthropic กำลังเผยแพร่งานวิจัยเกี่ยวกับการสร้างนักวิจัยการจัดแนว AI อัตโนมัติ ส่วน DeepMind ดูเหมือนระมัดระวังที่สุดในสามห้องปฏิบัติการหลัก แต่ก็ระบุว่าควรผลักดันการอัตโนมัติของการวิจัยการจัดแนวเมื่อเป็นไปได้
การพัฒนา AI อัตโนมัติก็ได้กลายเป็นเป้าหมายของบริษัทสตาร์ทอัพหลายแห่ง Recursive Superintelligence เพิ่งระดมทุนได้ 5 พันล้านดอลลาร์สหรัฐ โดยมีเป้าหมายเพื่อการวิจัย AI อัตโนมัติ
พูดอีกแบบหนึ่ง ทุนขนาดหลายพันพันล้านดอลลาร์สหรัฐทั้งทุนเดิมและทุนใหม่ กำลังไหลเข้าสู่องค์กรจำนวนมากที่มีเป้าหมายในการพัฒนา AI อัตโนมัติ
ดังนั้น เราจึงควรคาดหวังว่าทิศทางนี้จะบรรลุความคืบหน้าอย่างน้อยในระดับหนึ่ง
ทำไมสิ่งนี้จึงสำคัญ
ผลกระทบจากสิ่งนี้มีความลึกซึ้ง แต่กลับได้รับการพูดถึงน้อยมากในสื่อมวลชนที่รายงานข่าวเกี่ยวกับการวิจัยและพัฒนา AI ต่อไปนี้คือประเด็นที่สะท้อนถึงความท้าทายอันยิ่งใหญ่ที่เกิดจากการพัฒนา AI
1. เราต้องจัดการเรื่องการจัดแนวให้ดี: เทคนิคการจัดแนวที่มีประสิทธิภาพในปัจจุบันอาจล้มเหลวในการปรับปรุงตนเองแบบวนซ้ำ เพราะระบบ AI จะกลายเป็นฉลาดกว่าบุคคลหรือระบบผู้กำกับดูแลอย่างมาก นี่เป็นพื้นที่ที่ได้รับการศึกษาอย่างกว้างขวาง ดังนั้นเขาจึงสรุปประเด็นบางประการอย่างสั้นๆ:
การฝึกฝนระบบปัญญาประดิษฐ์ให้ไม่โกงหรือหลอกลวงเป็นกระบวนการที่ละเอียดอ่อนอย่างไม่คาดคิด (ตัวอย่างเช่น แม้จะพยายามสร้างการทดสอบสภาพแวดล้อมที่ดี แต่บางครั้งวิธีที่ดีที่สุดของปัญญาประดิษฐ์ในการแก้ปัญหาคือการโกง ซึ่งทำให้มันเรียนรู้ว่าการโกงเป็นไปได้)
· ระบบ AI อาจหลอกเราโดยการ “แสดงพฤติกรรมที่ดูเหมือนสอดคล้อง” เพื่อส่งคะแนนที่ทำให้เราคิดว่ามันทำงานได้ดี แต่แท้จริงแล้วซ่อนเจตนาที่แท้จริงของมันไว้ (โดยทั่วไป ระบบ AI สามารถรับรู้ได้ว่ามันกำลังถูกทดสอบเมื่อใด)
· เมื่อระบบ AI เริ่มมีส่วนร่วมมากขึ้นในการวิจัยพื้นฐานที่เกี่ยวข้องกับการฝึกฝนตนเอง เราอาจเปลี่ยนวิธีการฝึกฝนระบบ AI โดยรวมอย่างมาก โดยไม่มีสัญชาตญาณหรือพื้นฐานเชิงทฤษฎีที่ดีในการเข้าใจว่าสิ่งนี้หมายถึงอะไร
· เมื่อคุณวางระบบใดระบบหนึ่งไว้ในวัฏจักรการเรียกซ้ำ จะเกิดปัญหา「การสะสมข้อผิดพลาด」พื้นฐานอย่างรุนแรง ซึ่งอาจส่งผลกระทบต่อปัญหาทั้งหมดที่กล่าวถึงข้างต้นและปัญหาอื่นๆ: หากวิธีการจัดแนวของคุณไม่ได้「แม่นยำ 100%」และไม่สามารถรักษาความแม่นยำนั้นไว้ได้ในระบบที่ชาญฉลาดยิ่งขึ้นตามทฤษฎี สถานการณ์ต่างๆ ก็อาจผิดพลาดได้อย่างรวดเร็ว ตัวอย่างเช่น ความแม่นยำเริ่มต้นของเทคโนโลยีคือ 99.9% หลังจาก 50 รุ่นอาจลดลงเหลือ 95.12% และหลังจาก 500 รุ่นอาจลดลงเหลือ 60.5%
ทุกสิ่งที่เกี่ยวข้องกับ AI จะได้รับการเพิ่มประสิทธิภาพการผลิตอย่างมหาศาล: เช่นเดียวกับที่ AI เพิ่มประสิทธิภาพการผลิตของวิศวกรซอฟต์แวร์อย่างมีนัยสำคัญ เราควรคาดหวังว่าสาขาอื่นๆ ที่เกี่ยวข้องกับ AI ก็จะเช่นกัน ซึ่งนำไปสู่คำถามหลายประการที่ต้องรับมือ:
· ความไม่เท่าเทียมในการเข้าถึงทรัพยากร: หากความต้องการ AI ยังคงเกินกว่าปริมาณทรัพยากรการคำนวณที่มีอยู่ เราจะต้องตัดสินใจว่าจะจัดสรร AI อย่างไรเพื่อให้ได้ผลประโยชน์สูงสุดต่อสังคม ฉันสงสัยว่าแรงจูงใจจากตลาดจะสามารถรับประกันได้ว่าเราจะได้รับผลประโยชน์ทางสังคมสูงสุดจากทรัพยากรการคำนวณ AI ที่จำกัด การกำหนดวิธีการจัดสรรความสามารถในการเร่งความเร็วที่เกิดจากการวิจัยและพัฒนา AI จะเป็นปัญหาที่มีลักษณะทางการเมืองอย่างมาก
· กฎของอัมดาห์ทางเศรษฐกิจ: เมื่อ AI ไหลเข้าสู่เศรษฐกิจ เราจะพบว่าบางขั้นตอนจะเกิดข้อจำกัดเมื่อเผชิญกับการเติบโตอย่างรวดเร็ว จำเป็นต้องหาวิธีแก้ไขจุดอ่อนในห่วงโซ่นี้ ซึ่งอาจชัดเจนเป็นพิเศษในสาขาที่ต้องประสานโลกดิจิทัลที่เร็วเข้ากับโลกทางกายภาพที่ช้า เช่น การทดลองทางคลินิกของยาใหม่
3. การก่อตัวของเศรษฐกิจที่ใช้ทุนหนักและใช้แรงงานเบา: หลักฐานทั้งหมดที่กล่าวถึงข้างต้นเกี่ยวกับการวิจัยและพัฒนา AI ยังแสดงให้เห็นว่า ระบบ AI กำลังมีความสามารถเพิ่มขึ้นในการดำเนินธุรกิจด้วยตนเอง
นี่หมายความว่าเราสามารถคาดการณ์ได้ว่าส่วนหนึ่งของเศรษฐกิจจะถูกครอบครองโดยบริษัทรุ่นใหม่ ซึ่งอาจเป็นประเภทที่ใช้ทุนหนัก (เนื่องจากมีคอมพิวเตอร์จำนวนมาก) หรือใช้ค่าใช้จ่ายในการดำเนินงานหนัก (เนื่องจากใช้จ่ายจำนวนมากสำหรับบริการ AI และสร้างมูลค่าบนพื้นฐานนั้น) เมื่อเทียบกับบริษัทในปัจจุบัน ซึ่งมีการพึ่งพาแรงงานน้อยกว่า—เพราะเมื่อความสามารถของระบบ AI ยังคงเพิ่มขึ้น คุณค่าขอบเขตของการลงทุนใน AI จะเพิ่มขึ้นอย่างต่อเนื่อง
ในความเป็นจริง สิ่งนี้จะปรากฏขึ้นในรูปแบบของ “เศรษฐกิจของเครื่องจักร” ที่ค่อยๆ ก่อตัวขึ้นภายใน “เศรษฐกิจของมนุษย์” ที่กว้างกว่า ตามเวลาที่ผ่านไป บริษัทที่ดำเนินการโดย AI อาจเริ่มทำการซื้อขายกันเอง ซึ่งจะเปลี่ยนโครงสร้างทางเศรษฐกิจและก่อให้เกิดคำถามต่างๆ เกี่ยวกับความไม่เท่าเทียมและการกระจายรายได้ใหม่ สุดท้ายแล้ว อาจมีการเกิดขึ้นของบริษัทที่ดำเนินการโดยระบบ AI อย่างสมบูรณ์แบบ ซึ่งจะยิ่งทวีความรุนแรงของปัญหาข้างต้น พร้อมทั้งสร้างความท้าทายด้านการกำกับดูแลใหม่ๆ อีกมากมาย
มองไปที่หลุมดำ
จากวิเคราะห์ข้างต้น ผู้เขียนเชื่อว่าความน่าจะเป็นที่เราจะเห็นการวิจัยและพัฒนาโดยอัตโนมัติของ AI (นั่นคือ แบบจำลองชั้นนำสามารถฝึกอบรมรุ่นถัดไปของตนเองได้อย่างอิสระ) ภายในสิ้นปี 2028 อยู่ที่ประมาณ 60% ทำไมจึงไม่คาดการณ์ว่ามันจะเกิดขึ้นในปี 2027?
เนื่องจากผู้เขียนเชื่อว่าการวิจัยด้าน AI ยังคงต้องการความคิดสร้างสรรค์และมุมมองที่แตกต่างเพื่อก้าวหน้า จนถึงขณะนี้ ระบบ AI ยังไม่ได้แสดงให้เห็นถึงสิ่งนี้ในลักษณะที่เปลี่ยนแปลงและมีนัยสำคัญ (แม้ว่าผลลัพธ์บางอย่างในการเร่งการวิจัยทางคณิตศาสตร์จะมีความหมายชี้นำ)
หากบังคับให้เขาให้ความน่าจะเป็นสำหรับปี 2027 เขาจะบอกว่า 30%
หากยังไม่เกิดขึ้นภายในสิ้นปี 2028 เราอาจเปิดเผยข้อบกพร่องพื้นฐานบางประการในรูปแบบเทคโนโลยีปัจจุบัน ซึ่งต้องการการค้นพบของมนุษย์เพื่อขับเคลื่อนการพัฒนาต่อไป