
Хотите узнать, какая крупная модель действительно лучше всего справляется с реальными задачами OpenClaw?
MyToken на основе оценочных сайтов создал прозрачный набор стандартов, ориентированных исключительно на оценку реальных возможностей AI-кодирующих агентов, рассматривая только один ключевой показатель —成功率 (успешность). Скорость и стоимость относятся к другим независимым измерениям и будут проанализированы отдельно в будущем. Всё полностью открыто и воспроизводимо: представлены строгие критерии оценки и актуальный рейтинг топ-10 по успешности.
I. Критерий оценки:成功率
Конкретный критерий: доля задач, полностью и точно выполненных ИИ-агентом. Каждая задача выполняется по строго стандартизированному процессу:
Точные пользовательские подсказки (Prompt)
Отправьте полный запрос агенту, чтобы смоделировать реальную ситуацию запроса пользователя
Ожидаемое поведение
Все описывают приемлемые методы реализации и ключевые моменты принятия решений
Критерии оценки (чек-лист)
Составьте список атомарных критериев успешного завершения, подлежащих проверке по пунктам
Два: три способа оценки
В этом обзоре основным образом используются три метода оценки
Автоматическая проверка: скрипт на Python напрямую проверяет содержимое файлов, журналы выполнения, вызовы инструментов и другие объективные результаты.
Судья большой языковой модели: Claude Opus выставляет оценки по подробной шкале (качество контента, уместность, полнота и т. д.)
Гибридный режим: автоматизированная объективная проверка + качественная оценка с использованием LLM в качестве судьи
Все определения задач, промпты и логика оценки полностью открыты для повторного тестирования и верификации.
Три. Задания для оценки
Это тестовое сравнение охватывает 23 категории задач, включая базовые взаимодействия, операции с файлами/кодом, создание контента, исследовательский анализ, вызов системных инструментов, сохранение памяти и другие аспекты, что максимально соответствует повседневному использованию OpenClaw разработчиками:
Проверка на здравый смысл (автоматизация) — обработка простых команд и корректный ответ на приветствие
Создание события в календаре (автоматизация) — генерация стандартного файла календаря ICS на естественном языке
Исследование цен акций (автоматизация) — реальное время запроса цен акций и вывод форматированного отчета
Blog Post Writing (LLM Judge) — Напишите структурированный блог-пост в формате Markdown объемом около 500 слов
Создание скрипта погоды (автоматизация) — написание скрипта Python для API погоды с обработкой ошибок
Резюме документа (оценка на основе ИИ) — трехчастное краткое резюме ключевых тем
Исследование технологической конференции (судья LLM) — сбор и анализ информации о пяти реальных технологических конференциях (название, дата, место, ссылка)
Написание профессионального электронного письма (судья ИИ) — вежливый отказ от встречи с предложением альтернативы
Извлечение памяти из контекста (автоматизация) — точное извлечение дат, участников, стека технологий и т. д. из заметок о проекте
Создание структуры файлов (автоматизация) — автоматическое создание стандартной директории проекта, README, .gitignore
Многоэтапный рабочий процесс API (гибридный) — чтение конфигурации → написание скрипта вызова → полная документация
Установите навык ClawdHub (автоматизация) — установите из репозитория навыков и проверьте доступность
Поиск и установка навыка (автоматизация) — найдите и правильно установите навык для погоды
Генерация изображений ИИ (смешанная) — создание и сохранение изображений по описанию
Оживите AI-сгенерированный блог (судья LLM) — превратите машинный текст в естественный разговорный
Ежедневный исследовательский обзор (LLM-судья) — объединение нескольких документов в единый ежедневный обзор
Сортировка почтового ящика (смешанная) — анализ нескольких писем и составление отчета по уровню срочности
Поиск и суммаризация электронных писем (смешанный) — поиск архивных писем и выделение ключевой информации
Конкурентные рыночные исследования (гибридные) — анализ конкурентов в области корпоративных APM
Сводка в формате CSV и Excel (смешанная) — анализ файлов таблиц и вывод инсайтов
ELI5 Сводка PDF (оценка на основе ИИ) — объяснение технического PDF языком, понятным пятилетнему ребёнку
Понимание отчета OpenClaw (автоматизация) — точный ответ на конкретные вопросы из PDF-отчетов
Постоянство знаний Second Brain (гибридный) — сохранение и точное воспроизведение информации между сессиями
Четвертый: Основные выводы: Топ-10 моделей по проценту успеха (Лучший % / Средний %)
Данные обновлены по состоянию на 7 апреля 2026 года
Best % — это наивысшая успешность за одну операцию, Avg % — средняя успешность за несколько операций, что лучше отражает стабильность
Вот десять моделей с наивысшей успешностью
anthropic/claude-opus-4.6 (Anthropic) — 93,3% / 82,0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91,9% / 91,9%
openai/gpt-5.4 (OpenAI) — 90,5% / 81,7%
qwen/qwen3.5-27b (Qwen) —— 90,0% / 78,5%
minimax/minimax-m2.7 (MiniMax) — 89,8% / 83,2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89,5% / 78,1%
qwen/qwen3.5-397b-a17b (Qwen) — 89,1% / 80,4%
xiaomi/mimo-v2-flash (Xiaomi) — 88,8% / 70,2%
qwen/qwen3.6-plus-preview (Qwen) — 88,6% / 84,0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88,6% / 75,5%
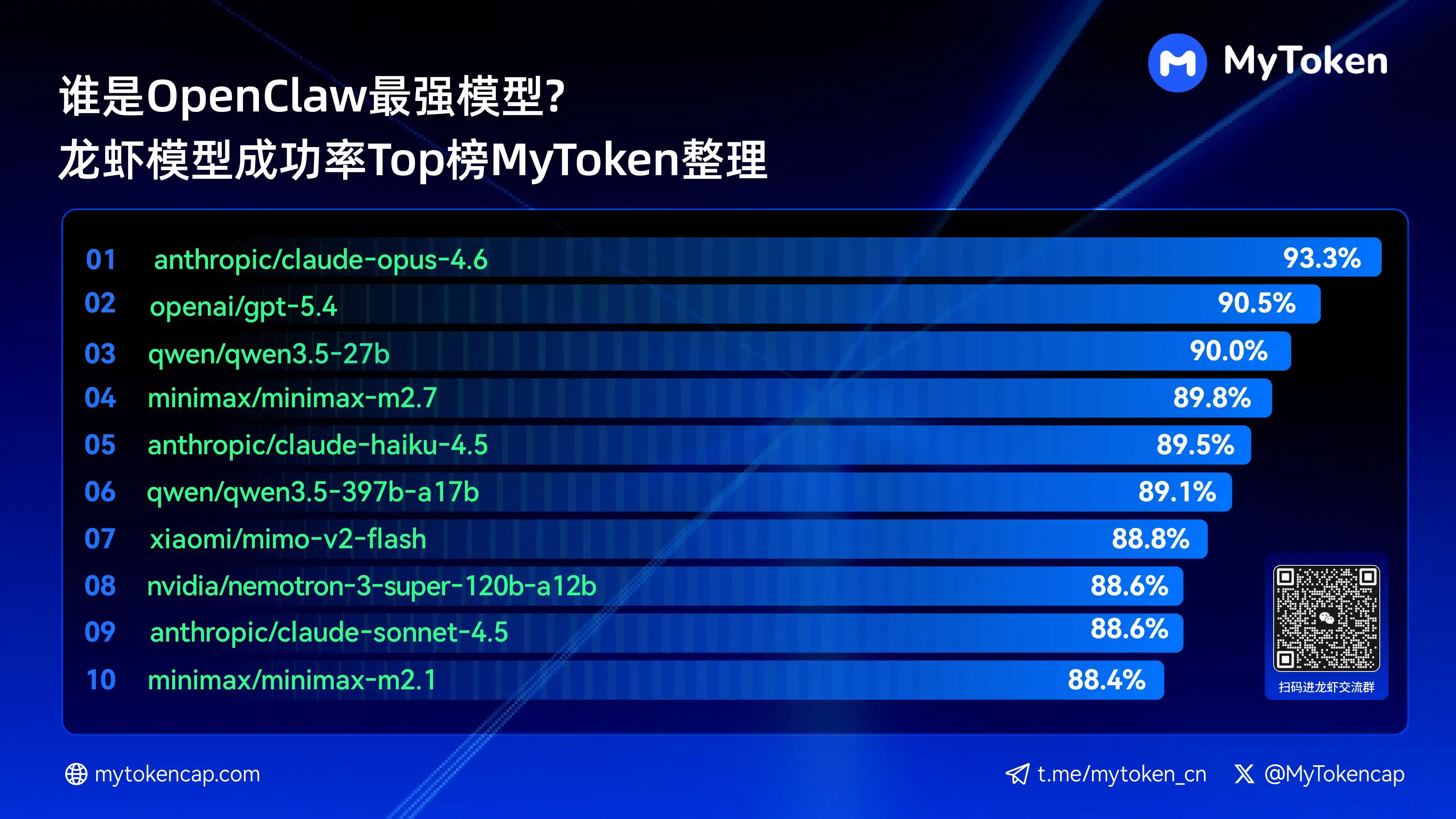
Claude Opus 4.6 сейчас лидирует с наивысшим процентом успешности 93,3%, однако Trinity от Arcee выделяется по средней стабильности, а в топ-10 также вошли несколько моделей серии Qwen, что демонстрирует высокий потенциал соотношения цены и качества. Успешность — это базовый порог, далее на реальный опыт будут влиять скорость и стоимость.
Этот набор из 23 задач полностью прозрачен, настоятельно рекомендуем вам протестировать его в соответствии со своими реальными сценариями. Более ранги других моделей — ожидайте функцию рейтинга агентов, которую вскоре запустит MyToken.
(Данные предоставлены открытым бенчмарком OpenClaw от PinchBench, постоянно обновляются.)