










Imagine este cenário:
Você pediu ao Agente de IA para consertar um bug no código. Ele abriu o projeto, leu 20 arquivos, fez algumas alterações, executou os testes — falharam — fez mais alterações, executou novamente — ainda falharam... Depois de dezenas de tentativas, finalmente — ainda não consertou.
Você desliga o computador e solta um suspiro de alívio. Em seguida, recebe a fatura da API.
Os números acima podem deixar você com um frio na barriga — agentes de IA que corrigem bugs automaticamente, sob a API oficial no exterior, frequentemente consomem mais de um milhão de tokens por tarefa não corrigida, com custos que podem variar de dezenas a mais de cem dólares.
Em abril de 2026, um artigo de pesquisa publicado conjuntamente por Stanford, MIT, Universidade de Michigan e outros abriu pela primeira vez de forma sistemática a "caixa preta" do consumo de AI Agents em tarefas de código — onde exatamente o dinheiro está sendo gasto, se vale a pena e se pode ser previsto antecipadamente; as respostas são surpreendentes.
Descoberta 1: A taxa de gasto de código pelo Agent é 1000 vezes maior do que a de uma conversa comum de IA
As pessoas podem achar que gastar dinheiro para fazer o AI escrever código para você e para conversar com você sobre código deve ser mais ou menos o mesmo.
O artigo apresenta uma comparação mostrando:
O consumo de tokens para tarefas de codificação agêntica é aproximadamente 1.000 vezes maior do que para tarefas comuns de perguntas e respostas de código e raciocínio de código.
Diferença de exatamente três ordens de grandeza.
Por que isso acontece? O artigo aponta um fato: o dinheiro não é gasto em "escrever código", mas sim em "ler código".
Aqui, "ler" não se refere a humanos lendo código, mas sim ao fato de que o Agente, durante seu funcionamento, precisa constantemente "alimentar" o modelo com todo o contexto do projeto, histórico de operações, informações de erros e conteúdo dos arquivos. A cada nova rodada de diálogo, esse contexto se torna ainda mais longo; e o modelo é cobrado com base no número de tokens — quanto mais você alimentar, mais pagará.
Por exemplo: é como contratar um encanador que, antes de girar cada chave, exige que você leia toda a planta da construção desde o início — o custo de ler a planta é muito maior do que o de apertar os parafusos.
O artigo resume esse fenômeno em uma frase: o que impulsiona o custo do Agente é o crescimento exponencial dos Tokens de entrada, e não dos Tokens de saída.
Descoberta 2: O mesmo bug, executado duas vezes, pode custar o dobro — e quanto mais caro o bug, menos estável ele é
O que é ainda mais frustrante é a aleatoriedade.
Os pesquisadores fizeram o mesmo agente executar a mesma tarefa quatro vezes e descobriram:
- Entre tarefas diferentes, a tarefa mais cara queima cerca de 7 milhões de tokens a mais que a mais barata (Figura 2a)
- Em múltiplas execuções do mesmo modelo e da mesma tarefa, a mais cara foi aproximadamente o dobro da mais barata (Figura 2b)
- E, ao comparar o mesmo trabalho entre modelos diferentes, o consumo máximo pode ser até 30 vezes maior que o mínimo.
O último número é especialmente notável: isso significa que a diferença de custo entre escolher o modelo correto e o incorreto não é apenas "um pouco mais caro", mas "uma ordem de grandeza mais caro".
O que é ainda mais doloroso — gastar mais não significa fazer melhor.
O estudo descobriu uma curva em "U invertido":
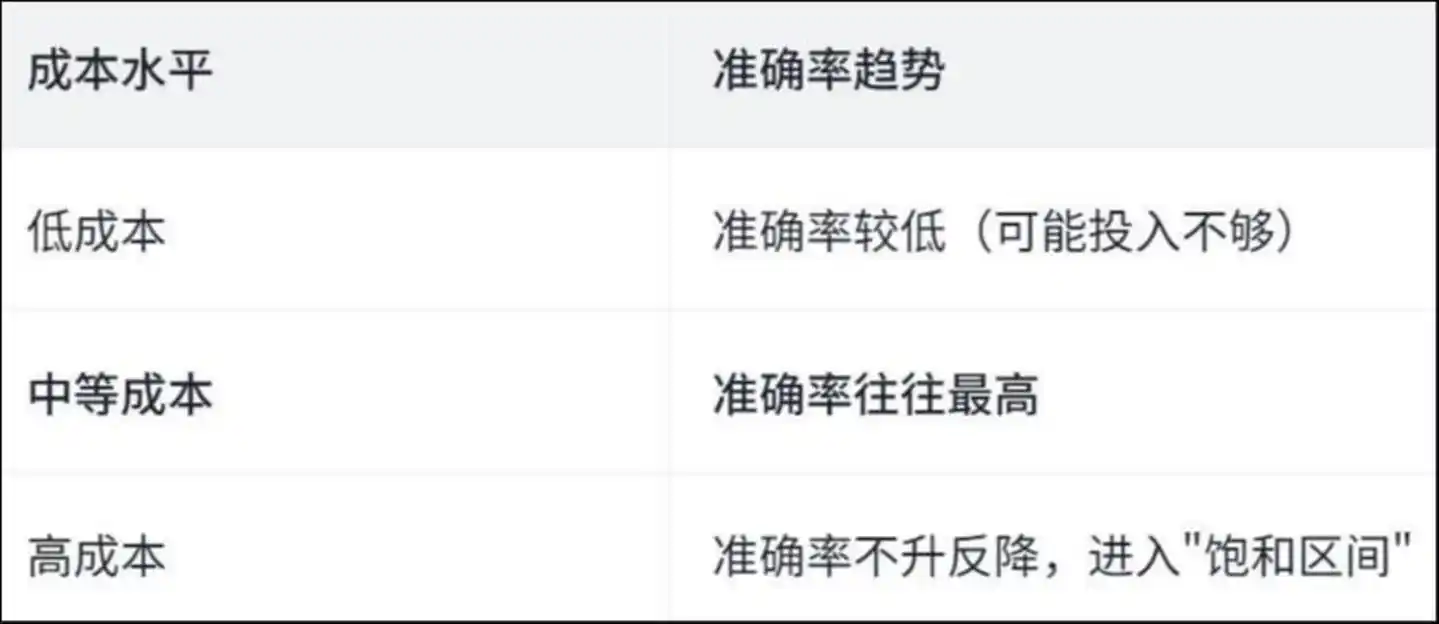
Tendência de precisão dos níveis de custo: custo baixo, precisão mais baixa (possivelmente investimento insuficiente); custo médio, precisão geralmente mais alta; custo alto, precisão não aumenta, mas diminui, entrando na "zona de saturação"
Por que isso acontece? O artigo fornece a resposta por meio da análise das operações específicas do Agente—
Em operações de alto custo, o agente gasta grande parte do tempo em "trabalho repetitivo".
Estudos revelam que, em operações de alto custo, cerca de 50% das operações de visualização e modificação de arquivos são repetitivas — ou seja, o agente lê repetidamente o mesmo arquivo e altera repetidamente a mesma linha de código, como uma pessoa girando em círculos dentro de um quarto, cada vez mais tonta e mais confusa.
O dinheiro não foi gasto para resolver o problema, mas para se perder.
Descoberta três: a eficiência energética varia drasticamente entre modelos — o GPT-5 é o mais econômico, enquanto alguns modelos consomem até 1,5 milhão de tokens a mais
O artigo avaliou o desempenho de oito modelos de linguagem avançados em relação a agentes, utilizando o SWE-bench Verified, um padrão da indústria com 500 issues reais do GitHub. Em termos de dólares, modelos com maior eficiência de tokens podem gastar dezenas de dólares a mais por tarefa. Em aplicações empresariais — onde centenas de tarefas são executadas por dia — essa diferença se traduz em dinheiro real.
Uma descoberta ainda mais interessante é que a eficiência do token é uma "característica inerente" do modelo, e não resultado da tarefa.
Os pesquisadores separaram as tarefas que todos os modelos resolveram com sucesso (230) das tarefas que todos os modelos falharam (100) para comparação e descobriram que a classificação relativa dos modelos quase não mudou.
Isso indica que alguns modelos são naturalmente "verbosos", independentemente da dificuldade da tarefa.
Outra descoberta reflexiva: o modelo carece de "consciência de stop-loss".
Diante de tarefas difíceis que nenhum modelo consegue resolver, um agente ideal deveria desistir o mais cedo possível, em vez de continuar gastando dinheiro. Mas na realidade, os modelos geralmente consomem mais tokens em tarefas falhas — eles não "desistem", apenas continuam explorando, tentando novamente e relendo o contexto, como um carro sem luz de aviso de combustível, dirigindo até parar.
Descoberta quatro: O que os humanos acham difícil, o agente nem sempre considera caro — a percepção de dificuldade está completamente desalinhada
Você pode estar pensando: pelo menos consigo estimar o custo com base na dificuldade da tarefa?
Foram consultados especialistas humanos para avaliar a dificuldade de 500 tarefas e comparar com o consumo real de tokens do Agente—
Result: Only a weak correlation exists between the two.
Em linguagem simples: tarefas que os humanos acham extremamente difíceis podem ser resolvidas facilmente e barato pelo agente; já tarefas que os humanos acham fáceis podem fazer o agente gastar uma fortuna e entrar em crise.
Isso ocorre porque a dificuldade que humanos e IA “enxergam” é totalmente diferente:
- O que os humanos veem é: complexidade lógica, dificuldade algorítmica e barreira de compreensão de negócios
- O agente analisa: o tamanho do projeto, quantos arquivos precisam ser lidos, o comprimento do caminho de exploração e se o mesmo arquivo será modificado repetidamente.
Um especialista humano pode achar que um bug exige apenas alterar uma linha — mas o agente pode precisar primeiro compreender toda a estrutura do código-base para localizar essa linha; apenas “ler” consome uma grande quantidade de tokens. Já um problema algorítmico que um humano considera “logicamente confuso” pode ser exatamente o tipo de problema que o agente conhece a solução padrão, resolvendo-o rapidamente.
Isso leva a uma realidade desconfortável: os desenvolvedores quase não conseguem estimar intuitivamente o custo de execução do Agente.
Descoberta cinco: até o próprio modelo não consegue calcular com precisão quanto irá gastar
Se os humanos não conseguem prever com precisão, e se a IA fizer a previsão por conta própria?
Os pesquisadores projetaram um experimento engenhoso: fazer com que o Agente primeiro "inspecione" o repositório de código antes de começar realmente a corrigir o bug, e então estime quantos tokens precisará consumir — sem executar efetivamente a correção.
How did it turn out?
Todos os modelos, derrotados completamente.
O melhor desempenho foi do Claude Sonnet-4.5, com uma correlação de previsão de tokens de saída de 0,39 (máximo de 1,0). A maioria dos modelos apresentou correlações de previsão entre 0,05 e 0,34, sendo o Gemini-3-Pro o mais baixo, com apenas 0,04 — praticamente equivalente a um palpite aleatório.
Mais absurdo ainda: todos os modelos subestimaram sistematicamente o consumo de seus tokens. No gráfico de dispersão da Figura 11, quase todos os pontos de dados estão localizados abaixo da “linha de previsão perfeita” — os modelos acreditavam que “não gastariam tanto”, mas na realidade gastaram mais. Além disso, esse viés de subestimação é ainda mais acentuado quando não são fornecidos exemplos.
Mais ironicamente — prever também custa dinheiro.
O custo de previsão do Claude Sonnet-3.7 e do Sonnet-4 pode ser mais de duas vezes o custo da própria tarefa. Ou seja, pedir que eles primeiro "dêem uma estimativa" é mais caro do que fazer o trabalho diretamente.
A conclusão do artigo é direta:
Nesta fase, os modelos avançados não conseguem prever com precisão o uso de seus próprios tokens. Clicar em "Executar Agente" é como abrir uma caixa surpresa — só se sabe o quanto foi gasto quando a fatura chega.
Por trás dessa “conta confusa” esconde-se um problema maior da indústria
Ao ler isso, você pode se perguntar: o que essas descobertas significam para as empresas?
O modelo de precificação "assinatura mensal" está sendo fissurado pelo Agent
O artigo aponta que modelos de assinatura como o ChatGPT Plus são viáveis porque o consumo de tokens em conversas comuns é relativamente controlável e previsível. No entanto, tarefas de Agentes quebram completamente essa suposição — uma única tarefa pode consumir uma quantidade massiva de tokens devido a ciclos em que o agente fica preso.
Isso significa que, para cenários de Agent, a precificação por assinatura pura pode não ser sustentável, e o pagamento conforme o uso (Pay-as-you-go) permanecerá, por um longo período, a opção mais realista. Mas o problema com o pagamento conforme o uso é que o próprio consumo é imprevisível.
2. A eficiência do token deve se tornar o "terceiro critério" na seleção de modelos
Tradicionalmente, as empresas avaliam modelos em dois aspectos: capacidade (se conseguem fazer) e velocidade (se fazem rápido). Este artigo apresenta um terceiro dimensionamento igualmente importante: eficiência energética (quanto custa para conseguir fazer).
Um modelo ligeiramente menos potente, mas três vezes mais eficiente, pode ter mais valor econômico em cenários de escala do que o modelo “mais forte, mas mais caro”.
3. O agente precisa de "medidor de combustível" e "freio"
O artigo menciona uma direção futura digna de atenção: políticas de uso de ferramentas conscientes de orçamento. Em termos simples, trata-se de equipar o agente com um "medidor de combustível": quando o consumo de tokens se aproximar do orçamento, forçá-lo a parar a exploração ineficaz, em vez de continuar gastando até o fim.
Atualmente, quase todos os principais frameworks de Agentes carecem desse mecanismo.
O "problema de gasto de dinheiro" do agente não é um bug, mas sim uma dor inevitável da indústria
O artigo revela não uma falha de um determinado modelo, mas sim um desafio estrutural de todo o paradigma de Agentes — quando a IA evolui de “pergunta-resposta” para “planejamento autônomo, execução em múltiplos passos e depuração repetida”, a imprevisibilidade do consumo de tokens é quase uma consequência inevitável.
A boa notícia é que, pela primeira vez, alguém sistematicamente trouxe à tona e calculou este caos financeiro. Com esses dados, os desenvolvedores podem escolher modelos, definir orçamentos e projetar mecanismos de stop-loss de forma mais inteligente; os fornecedores de modelos também têm uma nova direção de otimização — não apenas tornar os modelos mais poderosos, mas também mais econômicos.
Após tudo, antes que os Agentes de IA realmente entrem nos ambientes de produção de inúmeras indústrias, gastar cada centavo com clareza é mais importante do que escrever cada linha de código de forma elegante. (Este artigo foi publicado originalmente no app Titanium Media, autor | Silicon Valley Tech News, editor | Zhao Hongyu)
Nota: Este artigo é baseado no artigo pré-impresso publicado no arXiv em 24 de abril de 2026, intitulado *How Do AI Agents Spend Your Money? Analyzing and Predicting Token Consumption in Agentic Coding Tasks* (Bai, Huang, Wang, Sun, Mihalcea, Brynjolfsson, Pentland, Pei). Os autores são das instituições Universidade da Virgínia, Stanford, MIT, Universidade de Michigan, entre outras. Este estudo ainda não passou por revisão por pares.