









O modelo é o cérebro do OpenClaw e afeta diretamente o desempenho.
Autor do artigo: Zhang Haining
Fonte do texto: Notas de Henry
Recentemente, experimentei várias maneiras de instalar e implantar o OpenClaw: máquinas físicas, servidores na nuvem, máquinas virtuais, contêineres, modelos nacionais e internacionais, redes, etc. Em geral, é bastante complexo e há muitos fatores a considerar. Estou planejando escrever um artigo de síntese. Este serve como prévia, abordando primeiro um elemento muito importante: a escolha do modelo.
O modelo é o cérebro do OpenClaw e afeta diretamente o desempenho. Atualmente, há consenso de que os modelos estrangeiros são ligeiramente mais inteligentes do que os nacionais, mas exigem acesso à internet com ferramentas de contorno, têm preços mais altos e precisam de meios de pagamento estrangeiros; um pequeno erro pode levar ao bloqueio da conta. Mesmo que existam intermediários que ofereçam serviços mais econômicos, como pertencem a uma área cinza, apresentam fatores incertos. Por isso, usuários que buscam estabilidade no serviço geralmente optam por modelos nacionais.
Este artigo compara o uso e os preços de diversos modelos no país, fornecendo algumas recomendações para referência.
Após o framework de agente de IA de código aberto OpenClaw se tornar extremamente popular no país, trouxe não apenas uma revolução na produtividade, mas também faturas impressionantes.
O modo de funcionamento do OpenClaw é totalmente diferente dos AI conversacionais de navegadores tradicionais ou aplicativos. Após o usuário emitir um comando, a ferramenta aciona automaticamente dezenas ou até centenas de chamadas ao modelo, lendo arquivos, gerando código e depurando execuções — todo o processo consome Token integralmente.
Uma tarefa de desenvolvimento full-stack de complexidade média, com chamadas ao modelo possivelmente entre 10 e 40 rodadas; ao usar o modelo旗舰 que suporta 200K de contexto, o custo por tarefa facilmente atinge dezenas de yuans.
📊 Cálculo do custo real
Como exemplo de uma tarefa de complexidade média: o OpenClaw gera cerca de 30 rodadas de conversa, com uma entrada média de 20.000 tokens e uma saída de 2.000 tokens por rodada, utilizando modelos populares (cerca de 0,005 yuan por mil tokens de entrada, 0,02 yuan por mil tokens de saída):
Custo por tarefa única ≈ 30 × (20.000 × 0,005 ÷ 1000 + 2.000 × 0,02 ÷ 1000) = 30 × (0,1 + 0,04) = 4,2 yuan
Desenvolvedores intensivos concluem 5 a 10 tarefas por dia, com custo mensal de até 630 a 1.260 yuan. Este cálculo considera modelos de nível médio; se forem utilizados modelos de topo, os custos dobrarão.
Neste contexto, as principais empresas de nuvem e de modelos de grande porte da China entraram intensamente no mercado entre o final de 2025 e março de 2026, lançando pacotes de assinatura "Coding Plan" que substituíram a cobrança por Token por uma taxa mensal fixa. O ponto de partida desta guerra de preços foi o GLM Coding Plan lançado pela Zhipu AI no final de 2025, seguido pela Alibaba Cloud Bailian, que entrou no mercado com uma entrada extremamente baixa de "7,9 yuan no primeiro mês", e pela Tencent Cloud, que completou o último pedaço do quebra-cabeça em 5 de março de 2026.
Este artigo apresentará um levantamento sistemático dos Coding Plans das seis principais plataformas domésticas, comparando duas linhas principais: fornecedores de nuvem (Alibaba Cloud Bailian, Volcano Engine da ByteDance, Tencent Cloud) e fornecedores de modelos (Zhipu GLM, Kimi da Moonshot AI, MiniMax), oferecendo referência para usuários do OpenClaw.
OpenClaw precisa comprar o Coding Plan. Sim, exatamente o mesmo modelo de uso dos IDEs que programadores utilizam, como Cursor, Trae, etc., porque OpenClaw e Cursor são essencialmente agentes inteligentes. Se você não comprar o Coding Plan (normalmente chamado de API no exterior), seu dinheiro só poderá ser usado para acessar modelos grandes por meio do navegador.
(Modelos estrangeiros não estão dentro do escopo deste artigo)
Provedor de nuvem
Três grandes provedores de nuvem: a disputa no mercado de modelos
A lógica central da rota dos provedores de nuvem é o "plataforma agregadora": empacotar diversos modelos de linguagem de código aberto, como Qwen, GLM, Kimi e MiniMax, em um único pacote, permitindo que os desenvolvedores alternem livremente usando uma única chave API, sem a necessidade de recarregar separadamente em várias plataformas. Esses pacotes são medidos em "requisições por unidade", e não em Prompts (prompts), apresentando números aparentemente maiores, mas exigindo conversão prática.
As três fornecedoras de nuvem têm os seguintes detalhes:



Fabricantes de grandes modelos
Três principais fornecedores de modelos: a escolha especializada em profundidade
Diferentemente da "loja de modelos" das fornecedoras de nuvem, o plano de modelagem original da Coding segue uma abordagem de "loja especializada": oferece apenas seus próprios modelos, mas com otimizações profundas, resultando em um design mais refinado da capacidade e dos limites do modelo. Esses pacotes geralmente utilizam "Prompts" como unidade de medição, onde 1 Prompt ≈ 15 chamadas de modelo (segundo estimativa da MiniMax), o que faz os números parecerem muito menores, mas cada unidade suporta uma quantidade maior de conversas.



Tabela de comparação dos dados principais das plataformas
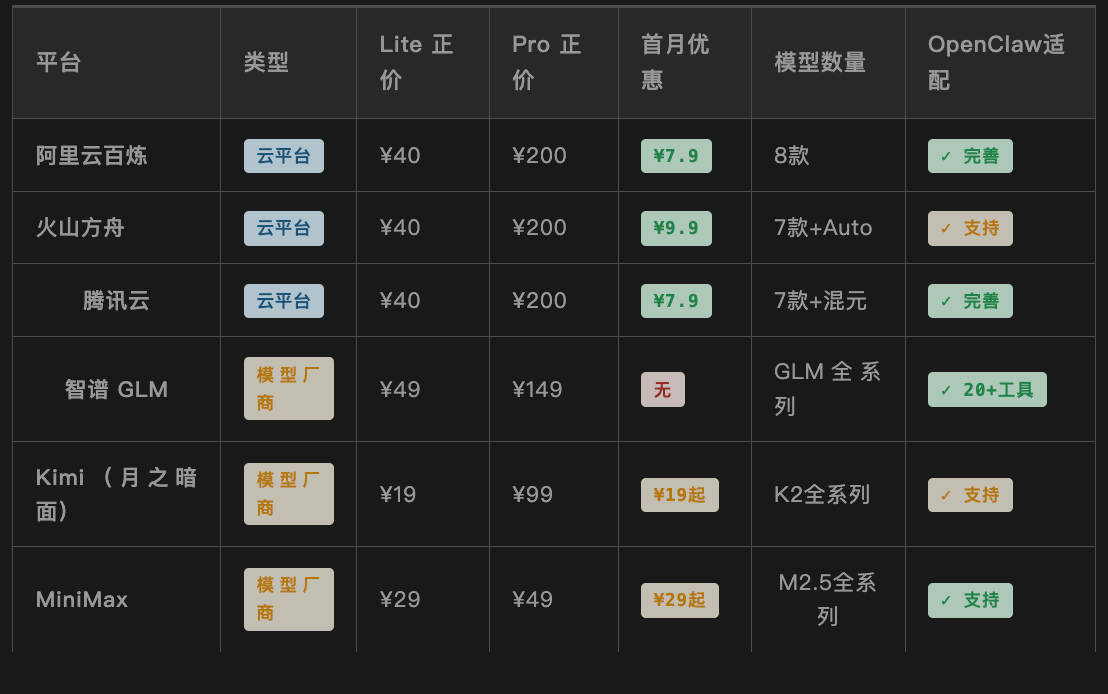
Observação: Os preços são baseados no preço oficial de março de 2026. O desconto do primeiro mês é exclusivo para novos usuários; consulte a página de pedido para detalhes. A classificação de compatibilidade do OpenClaw é baseada na completude da documentação oficial e no feedback da comunidade.
Guia para evitar armadilhas
Estrutura da cobrança: a verdade por trás dos números
O maior obstáculo de informação no mercado reside no fato de que cada plataforma utiliza unidades de medição completamente diferentes, tornando a comparação direta de números sem sentido. Esta seção revisa os três principais pontos de cobrança, ajudando você a tomar uma decisão realista antes da compra.
1. Unidades de medida não padronizadas
Atualmente, existem dois sistemas coexistindo no mercado: provedores de nuvem (Alibaba Cloud, Volcano, Tencent) cobram por "requisição"; fornecedores de modelos (Zhipu, MiniMax) cobram por "Prompts". A relação de conversão chave é: 1 Prompt ≈ 15 chamadas de modelo.
A cobrança é feita por rodada de interação iniciada pelo usuário: uma pergunta, independentemente de quantas vezes o modelo for chamado em segundo plano, conta como uma única utilização. A cobrança por número de chamadas é o modelo tradicional das provedoras de nuvem, baseado no número de chamadas à API; se uma pergunta do usuário acionar múltiplas chamadas ao modelo, várias cobranças serão aplicadas. O primeiro modelo é mais favorável a agentes como o OpenClaw, que realizam chamadas frequentes em segundo plano, oferecendo previsibilidade de custos; já o segundo cobra estritamente conforme o número real de solicitações, podendo gerar faturas inesperadas devido a chamadas internas.
Ambos os métodos são adequados para usuários leves do OpenClaw, pois não contam tokens, apenas o número de vezes, e possuem um limite mensal, eliminando a ansiedade relacionada a tokens.
2. Exemplo de conversão
O plano Alibaba Cloud BAILIAN Pro oferece 90.000 requisições por mês, equivalente a aproximadamente 6.000 Prompts.
O pacote ZhiPu GLM Lite oferece cerca de 120 prompts a cada 5 horas, o que equivale a aproximadamente 1.800 solicitações.
Portanto, "90.000" e "120" não são números diretamente comparáveis.
3. A janela deslizante / 5 horas são o verdadeiro gargalo
Quase todas as plataformas impõem um limite de "5 horas por período", e esse número é o indicador chave para determinar se você pode desenvolver continuamente em alta intensidade, e não o limite total mensal. A janela de 5 horas opera por um mecanismo de recuperação deslizante (não em períodos naturais fixos): se você começar a usar às 14:00 e esgotar o limite às 15:00, precisará esperar até às 19:00 para recuperar o primeiro lote de quota. É muito fácil atingir o limite ao desenvolver continuamente por 2 a 3 horas durante o pico da tarde.
4. Regras ocultas de redução de prioridade do Zhipu GLM-5
O Plano de Codificação GLM da Zhipu possui regras exclusivas: durante os horários de pico (UTC+8 14:00~18:00), o número real de usos disponíveis do GLM-5 é apenas 1/3 do número disponível fora dos horários de pico. Nenhuma outra plataforma possui essa regra no momento; ao fazer sua escolha, preste atenção especial ao seu horário principal de uso.
5. Reembolsos e cancelamentos não são permitidos
Todos os planas acima especificam claramente que não são permitidos reembolsos ou cancelamentos após a assinatura; certifique-se de confirmar suas necessidades antes da compra. Recomenda-se que novos usuários experimentem primeiro o plano de baixo custo do primeiro mês e não adquiram o plano anual de uma só vez.
Guia de Compra Exclusivo para Usuários do OpenClaw
OpenClaw, como um framework de agente autônomo, possui requisitos especiais superiores aos de plugins de IDE comuns para o Coding Plan: tolerância a chamadas de alta concorrência, capacidade estável de processamento de contexto longo e compatibilidade nativa com o protocolo Anthropic (pois o OpenClaw foi projetado com base no protocolo Claude). Abaixo, são fornecidas recomendações específicas classificadas por cenário de uso.
🌱 Tipo de introdução para iniciantes
Recomendação: Alibaba Cloud Bailing Lite, primeiro mês por ¥7,9 (já indisponível), ou Tencent Cloud, primeiro mês por 7,9 yuan
Primeiro contato com o Coding Plan, deseja experimentar o fluxo completo do OpenClaw com o menor custo possível. A diversidade de modelos da Baidu (8 modelos) permite experimentar horizontalmente Qwen, GLM-5 e Kimi em um único pacote, ajudando a construir rapidamente julgamentos intuitivos. Atualmente, a Alibaba Cloud oferece apenas o pacote Pro por 200 yuan/mês, enquanto a Tencent Cloud ainda possui pacotes Lite por 7,9 yuan e 40 yuan; usuários reais relatam que os estoques esgotam em segundos, podendo ser mais fácil obter apenas o pacote de 200 yuan/mês.
💼 Desenvolvedor Diário
Recomendado: MiniMax Plus ¥49/mês
Tarefas de programação diárias fixas, mas não de uso contínuo e intensivo. O plano Starter da MiniMax, com resposta ultra-rápida (101 tokens/s) e sem limite semanal, é o mais adequado para ritmos de desenvolvimento fragmentados, mas frequentes.
⚡ Tipo contínuo pesado
Recomendado: Tencent Cloud ou Alibaba Cloud Pro ¥200/mês
Desenvolvimento contínuo de mais de 6 horas por dia, exigindo processamento de grandes bases de código e fluxos de trabalho de Agent complexos. A cota mensal de 90.000 chamadas e a cota de 6.000 chamadas por janela de 5 horas do Tencent/Bailian Pro oferecem a melhor combinação de custo-benefício e estabilidade entre plataformas em nuvem.
🎨 Front-end / Multimodal
Recomendado: Kimi Moderato ¥99/mês
É necessário frequentemente inserir capturas de tela de protótipos de design e esboços de UI no AI para análise e geração de código. O pacote original Kimi-K2.5 é o único atualmente disponível no mercado Coding Plan que suporta entrada multimodal por captura de tela, sendo ideal para cenários de frontend e Vibe Coding.
🔬 Engenharia complexa
Recomendado: ZhiPu GLM Pro ¥149/mês
Cenários que exigem capacidades de modelos de ponta, como processamento de projetos monolíticos grandes, agendamento complexo de Agentes e testes automatizados de alta concorrência. A escala de 754 bilhões de parâmetros do GLM-5 é a maior entre modelos abertos na China, com capacidade de código próxima à do Claude Opus, e os custos a longo prazo podem ser reduzidos ainda mais com pacotes anuais com 30% de desconto.
Resumo
Estratégia de compra
O mercado de Coding Plan em 2026 já entrou na fase de competição acirrada. Os beneficiários diretos da guerra de preços são os desenvolvedores e os usuários: é possível experimentar diversos modelos de ponta por menos de 10 yuan no primeiro mês, algo impensável há um ano.
No entanto, a redução do valor mínimo do pacote não significa que a dificuldade de escolha diminuiu: diferenças nas unidades de medição, regras ocultas de limites e tendência de aumento de preços são variáveis que precisam ser consideradas cuidadosamente.
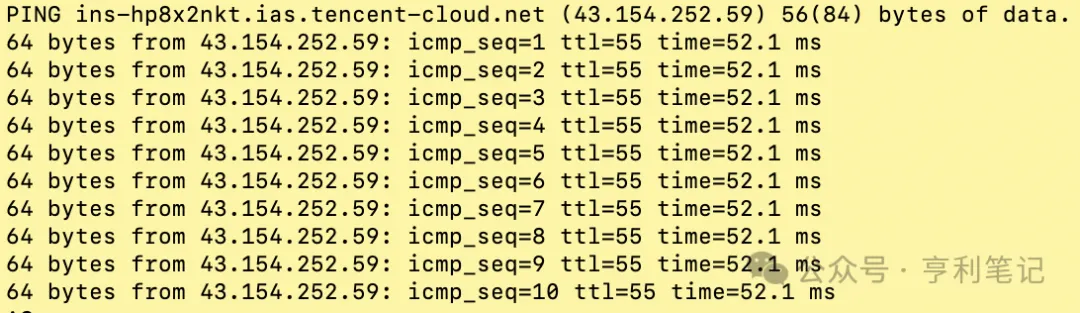
Mais um ponto importante é verificar qual serviço de modelo grande a máquina do OpenClaw acessa mais rapidamente. O método mais simples é usar o comando ping na máquina do OpenClaw para verificar a latência da rede e a taxa de perda de pacotes.
Por exemplo, este é o teste da rede entre o host OpenClaw e o ponto de extremidade do serviço Tencent Cloud; observe se há perda de pacotes icmp_seq e se a latência time é baixa:
$ ping api.lkeap.cloud.tencent.com
Com base na análise anterior, resumimos o seguinte:

📌 Última dica
Os dados deste artigo estão atualizados até o final de março de 2026. Devido às frequentes alterações nas políticas de preços das plataformas (por exemplo, Zhipu já aumentou os preços e o Alibaba Cloud Bailian Lite já encerrou as novas compras), certifique-se de consultar os anúncios mais recentes oficiais de cada plataforma antes da compra. Os pacotes não são reembolsáveis; recomenda-se iniciar com o pacote de preço reduzido do primeiro mês para verificar a compatibilidade da ferramenta e seus hábitos de uso antes de planejar a longo prazo.
Na próxima vez, vamos discutir os diversos pontos de compromisso a serem considerados ao implantar o OpenClaw.