
Quer saber qual modelo grande é realmente o melhor nas tarefas de agente de mundo real do OpenClaw?
MyToken, com base em avaliações de sites, desenvolveu um conjunto de benchmarks transparentes focados na avaliação da capacidade real de agentes de codificação AI, considerando apenas o sucesso como dimensão central (velocidade e custo são dimensões independentes e serão analisadas separadamente posteriormente). Totalmente aberto e reprodutível, apresenta apenas critérios rigorosos de avaliação + a lista dos 10 principais agentes com maior taxa de sucesso mais recente.
I. Critério de avaliação: Taxa de sucesso
Critério específico: A proporção de tarefas concluídas de forma completa e precisa pelos agentes de IA. Cada tarefa segue um processo altamente padronizado:
Prompt do usuário preciso
Enviar ao agente completo para simular o cenário de solicitação do usuário real
Comportamento esperado
Indica as abordagens aceitáveis e os pontos-chave de decisão
Critérios de avaliação (checklist)
Liste um checklist de critérios de sucesso atomizados e verificáveis individualmente
II. Três métodos de avaliação
Esta avaliação utiliza principalmente três métodos de pontuação
Verificação automática: Script Python valida diretamente o conteúdo do arquivo, registros de execução, chamadas de ferramentas e outros resultados objetivos.
Juiz de modelo LLM: Claude Opus atribui notas conforme escala detalhada (qualidade do conteúdo, adequação, completude, etc.)
Modo híbrido: combinação de verificação objetiva automatizada e avaliação qualitativa por LLM como árbitro
Todas as definições de tarefas, prompts e lógicas de avaliação são totalmente divulgadas para permitir revalidação e verificação.
Três: Tarefas para avaliação
Este benchmark abrange 23 categorias diferentes de tarefas, cobrindo múltiplos aspectos, como interações básicas, operações com arquivos/código, criação de conteúdo, análise de pesquisa, chamadas de ferramentas do sistema e persistência de memória, alinhando-se fortemente aos cenários cotidianos de uso do OpenClaw por desenvolvedores:
Verificação de sanidade (automatizada) — processar instruções simples e responder corretamente às saudações
Criação de Evento no Calendário (automação) — Geração automática de arquivo de calendário ICS em linguagem natural
Pesquisa de Preço de Ações (automatizada) — Consulta em tempo real de preços de ações e geração de relatórios formatados
Blog Post Writing (LLM Judge) — Escreva um post de blog estruturado em Markdown de aproximadamente 500 palavras
Criação de Script de Clima (automação) — Escreva um script Python para API de clima com tratamento de erros
Resumo de Documentos (Avaliação por LLM) — Resumo conciso em três partes do tema central
Pesquisa de Conferência de Tecnologia (Árbitro de LLM) — Pesquisa e organização de informações de 5 conferências de tecnologia reais (nome, data, local, link)
Redação de e-mail profissional (juiz LLM) — recusar educadamente a reunião e propor uma alternativa
Recuperação de memória a partir do contexto (automatizada) — extração precisa de datas, membros, tecnologias, etc., das anotações do projeto
Criação da Estrutura de Arquivos (automação) — geração automática de diretórios padrão do projeto, README, .gitignore
Fluxo de API de múltiplos passos (híbrido) — ler configuração → escrever script de chamada → documentação completa
Instale a habilidade ClawdHub (automação) — instale e verifique a disponibilidade a partir do repositório de habilidades
Pesquisar e instalar habilidade (automação) — procurar e instalar corretamente habilidades relacionadas ao clima
Geração de Imagem por IA (Mista) — Gere e salve imagens com base na descrição
Humanize o blog gerado por IA (julgamento de LLM) — transforme conteúdo com cheiro de máquina em linguagem natural e conversacional
Resumo Diário de Pesquisa (Juiz LLM) – Síntese diária coerente de múltiplos documentos
Triagem da Caixa de Entrada por E-mail (Mista) — Analisar vários e-mails e organizar um relatório por prioridade
Busca e resumo de e-mails (híbrido) — procure e-mails arquivados e extraia informações-chave
Pesquisa de Mercado Competitiva (Mista) — Análise de Concorrentes no Campo de APM Empresarial
Resumo em CSV e Excel (misto) — analise arquivos de tabela e gere insights
Resumo em PDF ELI5 (Árbitro LLM) — Explique PDFs técnicos em linguagem que uma criança de 5 anos entenda
Compreensão do Relatório OpenClaw (automatizado) — responder com precisão perguntas específicas a partir de relatórios em PDF
Persistência de Conhecimento do Segundo Cérebro (Misto) — Armazenamento entre sessões e recordação precisa de informações
Quatro: Conclusão principal: Classificação dos 10 principais modelos por taxa de sucesso (Melhor % / Média %)
Dados atualizados até 7 de abril de 2026
O % melhor é a maior taxa de sucesso individual, e o % médio é a taxa média de sucesso em múltiplas tentativas, refletindo melhor a estabilidade
Aqui estão os dez modelos com maior taxa de sucesso
anthropic/claude-opus-4.6 (Anthropic) —— 93,3% / 82,0%
arcee-ai/trinity-large-thinking (Arcee AI) — 91,9% / 91,9%
openai/gpt-5.4 (OpenAI) —— 90,5% / 81,7%
qwen/qwen3.5-27b (Qwen) — 90,0% / 78,5%
minimax/minimax-m2.7 (MiniMax) — 89,8% / 83,2%
anthropic/claude-haiku-4.5 (Anthropic) —— 89,5% / 78,1%
qwen/qwen3.5-397b-a17b (Qwen) —— 89,1% / 80,4%
xiaomi/mimo-v2-flash (Xiaomi) —— 88,8% / 70,2%
qwen/qwen3.6-plus-preview (Qwen) — 88,6% / 84,0%
nvidia/nemotron-3-super-120b-a12b (NVIDIA) —— 88,6% / 75,5%
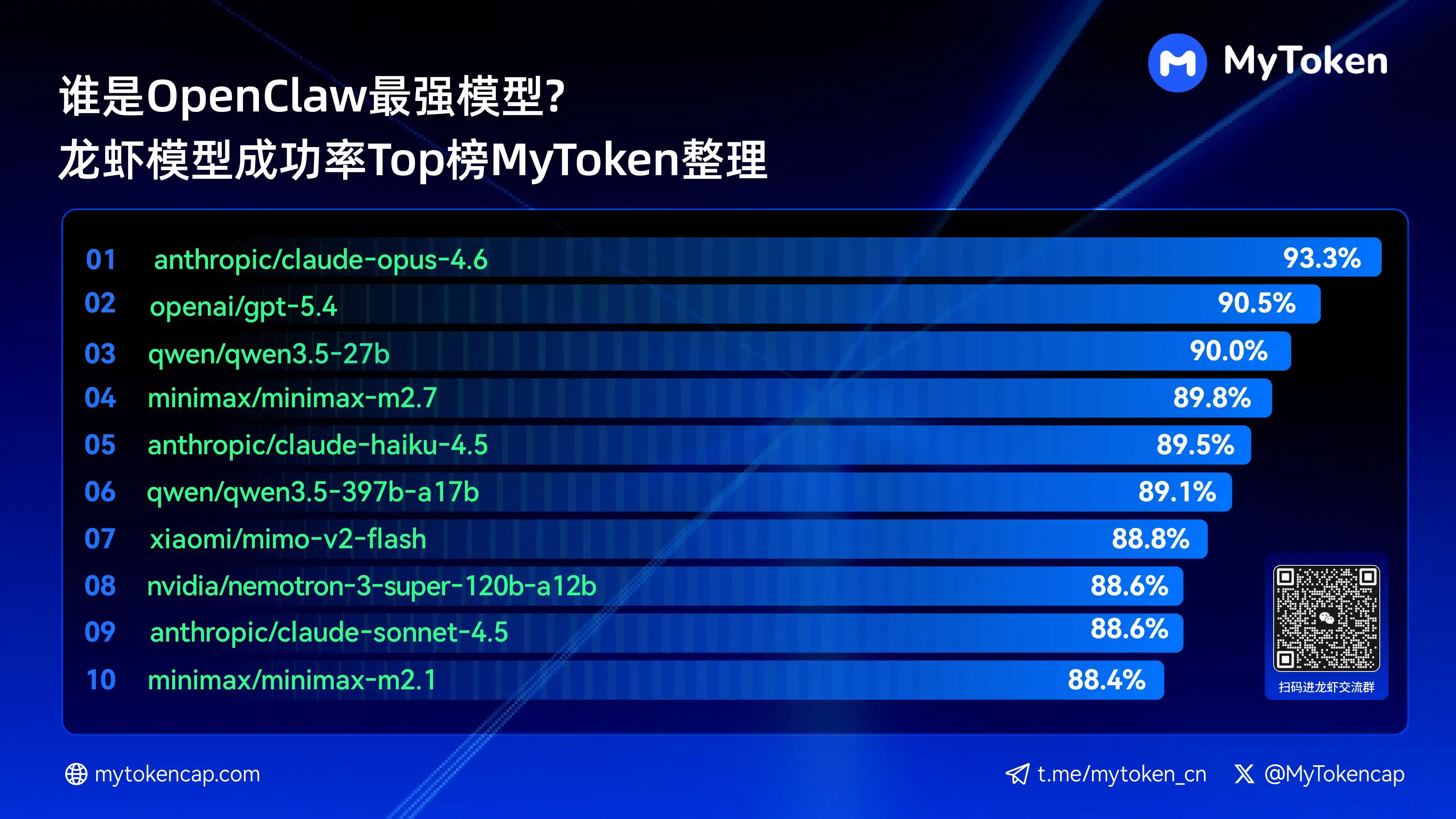
Claude Opus 4.6 atualmente lidera com uma taxa de sucesso máxima de 93,3%, mas o Trinity da Arcee se destaca em estabilidade média, e várias versões da série Qwen também entraram entre as dez melhores, demonstrando grande potencial de custo-benefício. A taxa de sucesso é um limiar básico; a velocidade e o custo serão os próximos fatores a influenciar a experiência prática.
Este conjunto de 23 tarefas de referência é totalmente transparente; recomenda-se fortemente que todos o testem em seus próprios cenários reais. Para mais classificações de outros modelos, fique atento à próxima funcionalidade de ranking de agentes que o MyToken lançará em breve.
(Dados provenientes do benchmark público OpenClaw da PinchBench, em atualização contínua.)