










Autor: Max, sempre a caminho, 01Founder
Se fosse para fazer um balanço intermediário da OpenAI em 2025, muitas pessoas provavelmente o descreveriam como tranquilo e até ligeiramente passivo.
Ao longo dos últimos mais de um ano, eles realmente seguiram passo a passo o caminho de raciocínio lógico, lançando密集mente modelos de inferência desde o o3pro até o o4mini, além de lançar novos modelos base como o GPT-4.5 e o GPT-5.
Mas no campo da geração visual, onde os usuários comuns mais facilmente percebem e mais facilmente formam propagação espontânea, sua presença está diminuindo gradualmente.
Após o impacto inicial do Sora, a OpenAI parece ter entrado em um longo período de silêncio nesse segmento.
Ao mesmo tempo, os outros jogadores na mesa não estavam ociosos.
Na ecossistema de código aberto, modelos como o Flux derrubaram completamente as barreiras para geração local de imagens de alta qualidade;
No lado comercial, não apenas rivais estabelecidos mantêm barreiras estéticas extremas, mas também surgiram novos concorrentes como o Nano-banana, que possui funcionalidade de busca online integrada.
Em comparação, o antigo modelo principal de geração de imagens da OpenAI, GPT-Image-1.5, já parece obsoleto:
Além da qualidade de imagem ruim e do layout rígido, frequentemente trava ao lidar com textos complexos.
Gradualmente, o setor formou um consenso:
OpenAI enfrentou uma barreira técnica na linha de geração visual e já parece estar perdendo terreno diante da concorrência.
Até algumas semanas atrás, o ponto de virada apareceu de forma muito sutil.
Na plataforma cega de grandes modelos renomada LM Arena, um misterioso modelo de imagem com o codinome Duct Tape foi discretamente inserido.
Os usuários que participaram do teste cego logo perceberam que algo estava errado:
Este modelo não apenas controla com extrema precisão formatos extremos, mas também produz pôsteres com layout de grande quantidade de texto em múltiplos idiomas sem falhas, como se houvesse um processo de planejamento lógico invisível antes da geração da imagem.
Por um tempo, várias comunidades técnicas especulavam qual empresa havia lançado secretamente essa grande novidade, mas a OpenAI permaneceu em silêncio.
Esta madrugada, a bota finalmente caiu.
Sem lançamentos longos nem campanhas de marketing massivas, a OpenAI nomeou oficialmente o modelo codificado como “Fit Tape” como ChatGPT GPT-Image-2 e o lançou amplamente no mercado.
Junto com isso, foi divulgada uma classificação do campo de batalha Text-to-Image que parece um pouco sufocante.
GPT-Image-2 alcançou o primeiro lugar com uma pontuação extremamente alta de 1512, liderando o segundo lugar (ou seja, o Nano-banana-2 com função de busca online) por 242 pontos.
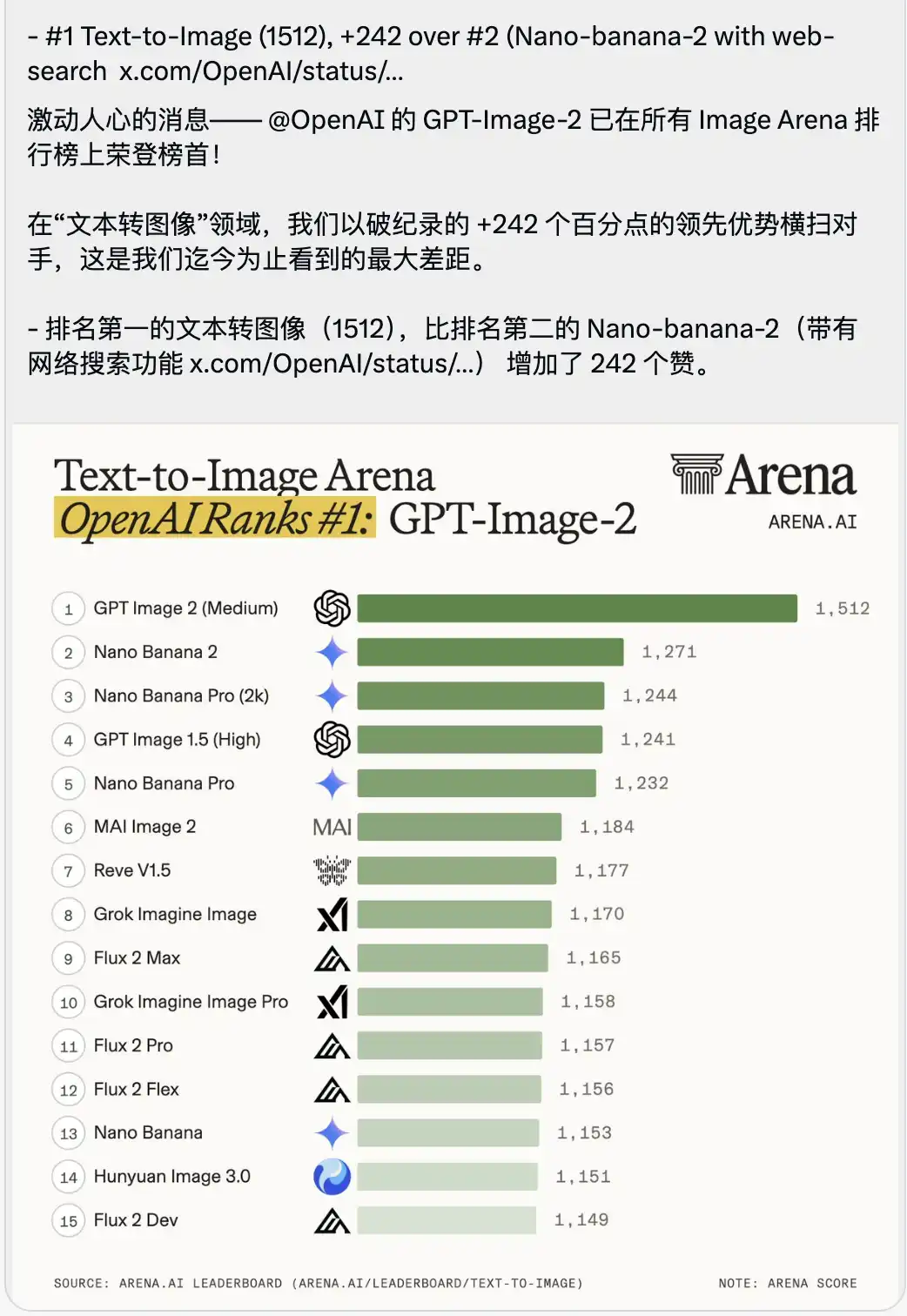
No contexto de avaliação de grandes modelos, as pessoas geralmente destacam muito as superações de frações de ponto ou dígitos unitários, pois as pontuações entre os modelos líderes são extremamente apertadas.
Uma vantagem de 242 pontos é inédita na história da arena.
This is not a minor version update—it's a brutal generational overhaul.
Passei a maior parte do dia revisando cuidadosamente todas as suas capacidades extremas e a documentação mais recente da API.
A única sensação mais importante é:
OpenAI ainda é o mesmo OpenAI.
Quando decidiu recuperar o terreno perdido, fez isso virando diretamente a mesa antiga.
Diante deste modelo, os trabalhos de design visual que acreditávamos ainda precisariam de dois ou três anos para serem totalmente substituídos por IA hoje basicamente chegaram ao fim.
PART.01 Geração de imagens, do modelo ao agente visual
Para entender por que o GPT-Image-2 consegue alcançar uma diferença tão extrema na pontuação, é necessário abandonar as percepções anteriores sobre modelos de geração de imagens a partir de texto.
Antes, usávamos IA para criar imagens, essencialmente como abrir uma caixa surpresa: inseríamos algumas palavras-chave e esperávamos que ela organizasse os pixels da maneira que queríamos.
Mas o GPT-Image-2 é mais como um agente com um motor visual integrado.
A mudança mais evidente é que, em termos de mecanismo, ela dividiu diretamente dois modos completamente diferentes.
Um modo instantâneo (Instant Mode) aberto a todos os usuários.
Este modelo destaca-se pela resposta ultra-rápida e integração perfeita com fluxos de trabalho e vida cotidiana.
Por exemplo, se você enviar um comando para ele pelo celular, ele poderá gerar em poucos segundos uma imagem com estrutura completa.
Sua capacidade subjacente de compreensão visual é extremamente forte, mas resolve principalmente necessidades de conversão visual frequentes e individuais.
O modo de pensamento (Thinking Mode) disponível para usuários pagantes.
Antes de começar a renderizar sequer um único pixel, ele entra em um processo de raciocínio lógico e busca online que dura mais de dez segundos.
É exatamente esse padrão que resolve uma proposição extremamente central, mas também extremamente difícil:
O modelo soube, pela primeira vez, exatamente o que deveria desenhar.
Por exemplo, o mais direto.
Digite na caixa de diálogo:
Faça um pôster para mim; pesquise na internet as avaliações sobre o modelo misterioso Duct Tape e inclua o código QR do ChatGPT.

Com o modelo anterior, ele simplesmente não sabia o que os internautas disseram, e só lhe mostraria um pôster com caracteres aleatórios e um código QR falso, que não pode ser escaneado.
Mas no modo de pensamento, seu fluxo de trabalho é assim:
Ele primeiro pausará o desenho, iniciará a ferramenta de busca online e coletará as avaliações reais dos usuários no Reddit, Threads ou LinkedIn;
Em seguida, começou a planejar o layout do pôster, o espaço em branco e a hierarquia tipográfica;
Por fim, ele gera um código QR real e funcional, diretamente escaneável para redirecionamento, e renderiza a imagem inteira.

Isso já não é apenas desenhar; na verdade, é realizar autonomicamente todo o processo de pesquisa, planejamento, extração de texto e design de layout.
É necessário fazer uma comparação paralela.
Todos que acompanham o ecossistema de grandes modelos sabem que modelos de geração de imagens com capacidade de conexão à internet e busca não foram criados pela OpenAI.
O Nano-banana em segundo lugar no ranking já possuía esse mecanismo.
Mas ao usar o Nano-banana na prática, você perceberá que ele parece um pouco lento em muitos lugares.
O pensamento do Nano-banana muitas vezes é uma lógica mecânica de montagem.
Por exemplo, se você pedir a ele para pesquisar tendências do setor para criar um pôster, ele realmente pesquisa, mas geralmente apenas copia frases rígidas da Wikipedia e as cola forçadamente na imagem.
Quando confrontado com instruções que exigem interpretar demandas comerciais abstratas, ele facilmente se perde.

É como se fosse um estagiário que entende instruções, mas não tem nenhuma experiência prática — sabe executar, mas não entende estratégia alguma.
Mas o desempenho do GPT-Image-2 nesse aspecto só pode ser descrito como exagerado.
Sua reflexão não foi meramente formal, mas sim uma verdadeira compreensão do contexto cultural e das intenções comerciais por trás.
During testing, I entered a minimal Chinese instruction: Help me take a screenshot of Musk live streaming on TikTok selling Doubao.
Se usar o modelo de geração de imagens anterior, provavelmente lhe mostrará um homem branco parecido com Musk segurando um baozi, com o fundo desfocado e sem nem saber como o TikTok parece.
Mas no modo de pensamento, os resultados do GPT-Image-2 são um pouco assustadores.
Ele não simplesmente montou elementos, mas autonomamente aplicou seu entendimento da internet chinesa para gerar uma captura de tela da interface de uma transmissão ao vivo no Douyin, perfeitamente replicada em nível de pixel.
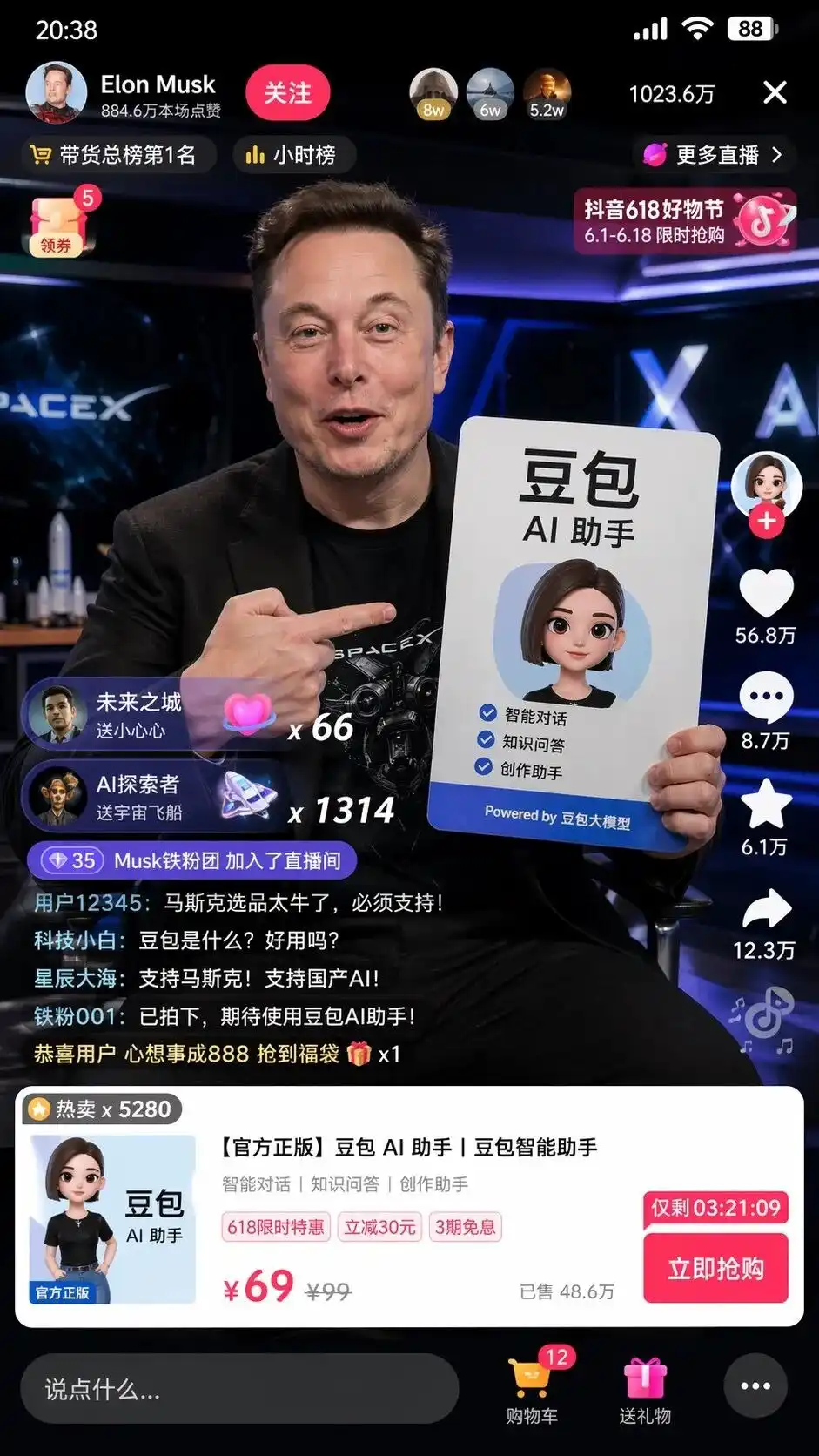
Na tela, não há apenas um Musk realista segurando um cartaz de publicidade do assistente de IA DouBao com uma formatação perfeita, mas também detalhes ainda mais assustadores que não estavam presentes no prompt:
Botão de seguir no canto superior esquerdo, ranking horário, 10,236,000 usuários online no canto superior direito, cartão de produto padrão pop-up na parte inferior, e até mesmo o preço original de 99, preço promocional de 69 e botão de compra imediata com contagem regressiva.
O mais arrepiante é a legenda de comentários dos usuários rolando na parte inferior esquerda, extremamente realista:
Novato em tecnologia: O que é Doubao? É bom de usar?
Estrelas e mares distantes: Apoie Musk! Apoie a IA nacional!
Ninguém disse a ele o que escrever nos comentários, como deve ser a interface do produto ou como definir os preços.
Este é o design completo de interface e estratégia operacional que o modelo elaborou e executou após analisar as tags de vendas no Douyin e o grande modelo DouBao.
Os critérios de avaliação de grandes modelos na geração de imagens cruzaram, neste momento, a fronteira de simplesmente saber se conseguem desenhar bonito, para incluir a compreensão de estratégias e lógica de layout.
PART.02 Teste prático das capacidades principais
Para testar seus limites, eu usei alguns cenários frequentes e complexos, seguindo os padrões de design comercial.
Descobriu-se que o nível de detalhe com que resolve o problema é tão fino que é assustador.
Primeiro cenário: compreensão visual e闭环 de negócios (vestir o modelo)
Na visão tradicional do comércio eletrônico ou no planejamento de moda, o custo de execução entre ter uma ideia e ver o efeito final vestido é muito alto.
Você precisa encontrar modelos, emprestar roupas, montar um estúdio e fazer retouching profissional.
Depois, com a chegada da IA, as pessoas começaram a treinar modelos LoRA para fixar a estrutura facial das pessoas, mas isso ainda exigia dezenas de imagens como base e um alto custo de aprendizado.
No GPT-Image-2, esse processo foi comprimido ao máximo.
Eu tentei enviar uma foto minha do dia a dia, disse a ele que vou tirar férias na ilha no próximo mês e pedi que me ajudasse a montar alguns conjuntos de roupas.
Primeiro, ele me deu oito conjuntos de catálogos de roupas de verão com estilos completamente diferentes, com layout que parecia um Lookbook profissional de e-commerce, e ao lado de cada peça havia até rótulos textuais corretos.
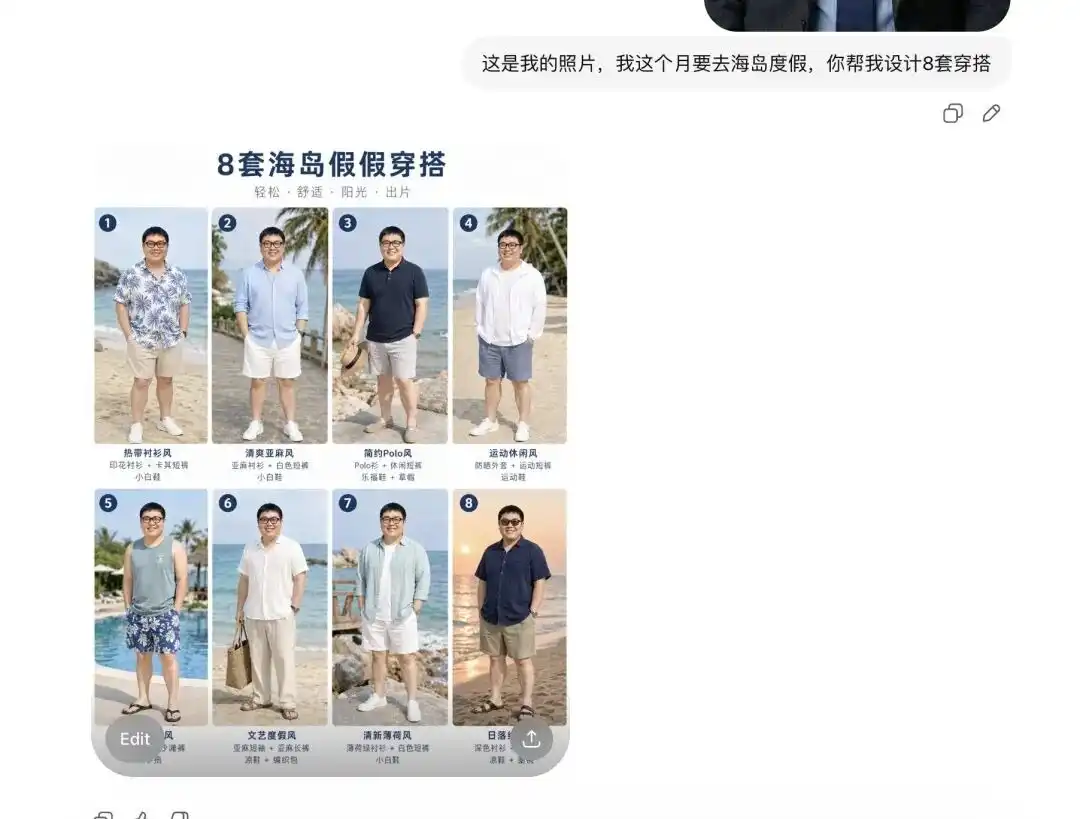
Mais importante ainda, nesse exato momento, ele já analisou com precisão minhas características faciais e proporções corporais.
Quando disse a ele que gostaria de ver como o primeiro conjunto ficaria vestido e pedi algumas imagens detalhadas sob diferentes ângulos, ele extraiu diretamente a pessoa da minha selfie, trocou pelo conjunto de verão e gerou imagens sob diferentes perspectivas, como lateral e meio corpo.

Esta transição foi muito suave. Isso significa que a barreira protetora para renderizações básicas de combinações de roupas ou para o trabalho terceirizado de modelos vestindo roupas foi completamente eliminada.
Segundo cenário: resolver consistência e narrativa contínua (gerar quadrinhos em uma frase)
Todos que já usaram IA para gerar imagens sabem que é fácil pedir à IA para desenhar uma imagem bonita, mas difícil é pedir para ela desenhar dez imagens da mesma pessoa, com movimentos e ângulos coerentes.
Este é o chamado problema da consistência (Consistency).
Mas neste teste prático, vi um caso extremamente contrário à experiência passada.
Você pode fazer o upload de apenas uma foto sua com um amigo de ontem e inserir uma instrução extremamente simples:
Transforme-nos em protagonistas, crie três histórias em quadrinhos japonesas de três páginas cada, com enredo à sua escolha.
Após alguns segundos, ele gerou diretamente três páginas de uma história em quadrinhos em preto e branco com cenas padrão.
O mais assustador é que esses dois personagens de quadrinhos gerados por pessoas reais aparecem em cenas diferentes em três páginas.

Tanto os close-ups, as cenas de corrida em longa distância, quanto as silhuetas, além dos traços faciais, detalhes dos cabelos e vincos nas roupas, mantiveram uma consistência perfeita.
Mais ainda, a trama da tirinha é completamente coerente, e até mesmo o texto dentro das balões forma uma lógica narrativa completa.

A capacidade de manter consistência no tempo e no espaço indica que já ultrapassou o domínio da geração de imagens individuais e possui a habilidade de direção de narrativas contínuas.
Terceiro cenário: Ultrapassando o último limite da renderização de texto (tipografia multilíngue)
Se a consistência resolveu o problema narrativo, então a renderização precisa de textos multilíngues é o que realmente empurrou os designers gráficos para a parede.
Antes, sempre que a imagem contivesse algum texto, o modelo grande começava a fazer rabiscos.
Como o modelo entende texto como tokens (bloco semântico) e gera imagens como pixels, esses dois elementos estavam anteriormente desconectados.
GPT-Image-2 resolveu completamente essa questão.
Eu gerei uma capa de revista de moda em francês, um cardápio de restaurante japonês cheio de hiragana e kanji e até experimentei notas em russo com densidade de layout extremamente alta.

O resultado é um único processo, sem erros de digitação.
O mais desesperador é que não apenas escreveu os caracteres corretamente, mas também entende como alinhar a estética cultural local e o design tipográfico conforme o idioma.
Por exemplo, os ideogramas no folheto japonês usam uma tipografia artística japonesa autêntica e vintage, e a disposição dos kana hiragana segue o hábito de leitura vertical do japonês.
O design de layout era um território exclusivo dos designers gráficos.
Ajustar o espaçamento entre letras, definir hierarquia e alcançar equilíbrio visual entre texto e fundo exigem muita prática.
Mas quando a IA puder processar tantos idiomas sem erros e ainda incluir um senso avançado de tipografia e estética, aqueles cartazes, folhetos e anúncios de feed diários realmente não precisarão mais de pessoas para alinhar manualmente as linhas de referência.
Cena quatro: Proporções distorcidas e controle microscópico extremo (inscrição em um grão de arroz)
Por fim, para ver o quão terrível é sua obediência, dei a ele algumas instruções muito difíceis.
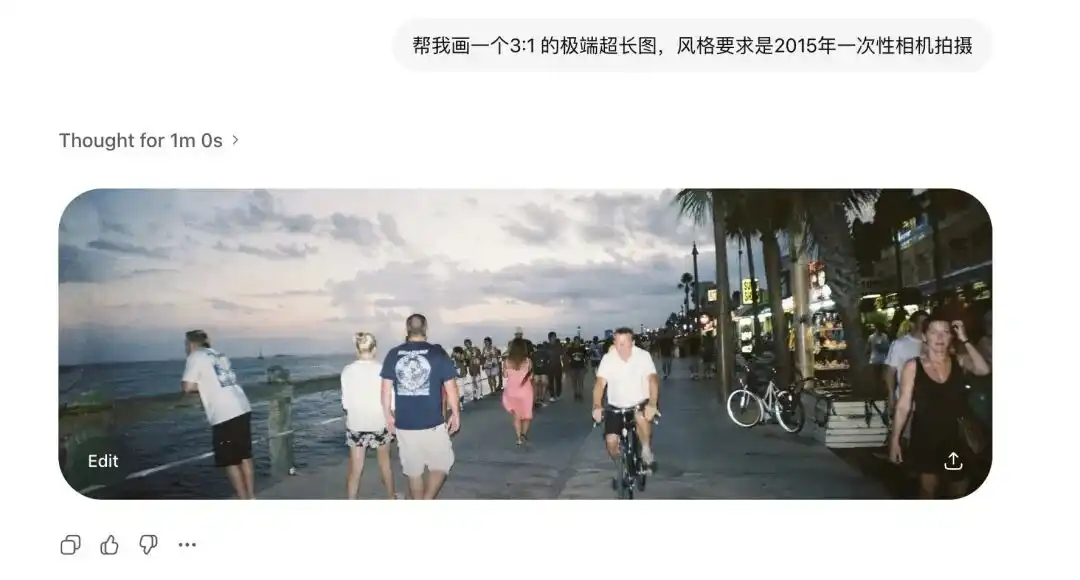
I first tested its extreme aspect ratio.
Os modelos de difusão tradicionais têm medo extremo de proporções não padrão.
Antes, ao alongar ligeiramente a imagem, dois cabeças surgiam na tela.
Mas eu solicitei ao Images 2.0 para gerar imagens ultra-largas de 3:1 e imagens verticais longas de 1:3, e não apenas não houve distorção, mas ele gerou até uma imagem panorâmica de 360 graus com extremidades conectadas e lógica fechada.
Após adicionar a entrada da câmera descartável de 2015, até mesmo a distorção das lentes antigas e o reflexo de baixa qualidade da lâmpada de flash na parede foram reproduzidos com total clareza.
Outro exemplo que demonstra melhor seu controle microscópico é o teste de grão de arroz ligeiramente louco apresentado pela equipe oficial durante a apresentação.
Os pesquisadores chamaram a API experimental 4K ainda em teste interno; eles não usaram nenhum termo como fotografia macro ou ultra HD 8K, apenas deram uma instrução extremamente abstrata em linguagem simples:
Um monte de arroz. Em um único grão de arroz nesse monte, está escrito GPT Image 2.
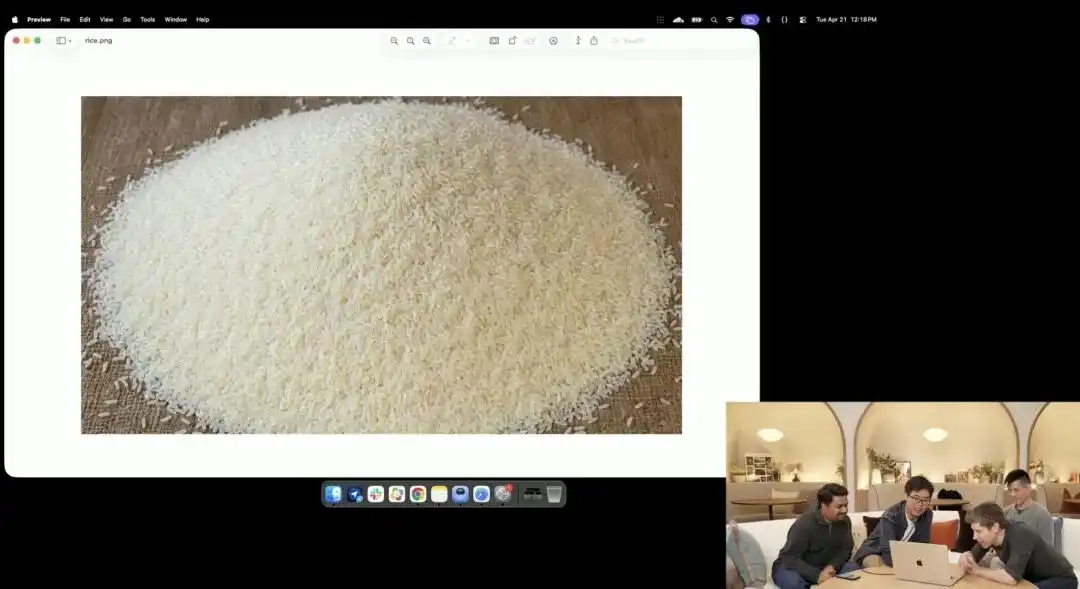
Quando a imagem é ampliada dezenas de vezes na tela e até mesmo aparecem grãos de pixel, você realmente consegue encontrar aquele grão minúsculo com uma inscrição em meio a um monte de arroz.
A textura deste arroz ainda está em conformidade com as leis da física, e o texto foi precisamente incrustado ao longo das pequenas curvas dos grãos.
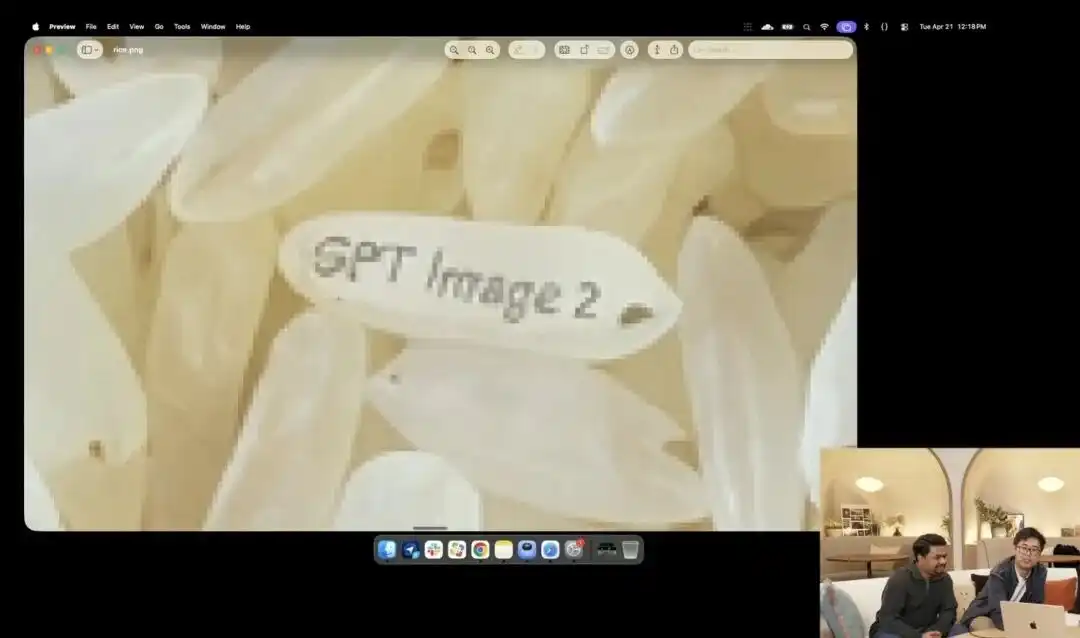
Todo o trabalho restante — chamar a visão macro, calcular a profundidade de campo, encontrar as coordenadas físicas do grão de arroz no espaço latente e imprimir as letras — foi automaticamente imaginado e concluído pelo grande modelo no modo de pensamento.
Este caso demonstra intuitivamente que o modelo compreende a posição espacial com precisão cirúrgica ao nível de pixels.
Isso significa que, no futuro, no trabalho prático, você poderá modificar com precisão qualquer pequena parte do design, apontar e corrigir, em vez de, como antes, querer alterar apenas o colarinho e acabar mudando toda a imagem.
PART.03 Alguns detalhes técnicos
Esse nível extremo de controle e inteligência estratégica não pode ser alcançado apenas com poder de computação cego.
Para descobrir quais são suas cartas na manga, fiz alguns testes de sondagem com o GPT-Image-2.
Descobriu-se um ponto muito interessante.
Embora a documentação oficial afirme que a data de corte do banco de conhecimento geral do GPT-Image-2 foi atualizada para dezembro de 2025, em meus testes práticos.
A data de corte dos dados de treinamento do Modo Instantâneo (Instant Mode) ainda permanece em maio de 2024;

E o modo de pensamento (Thinking Mode), que requer reflexão prolongada, tem sua base de conhecimento nativa aproximadamente até junho de 2024 (mas pode obter a data atual por meio de conexão em tempo real).

Ao calcular a partir desses dois pontos no tempo, parece haver pistas sobre a base do GPT-Image-2.
Primeiro, fale sobre o modo instantâneo, focado em geração frequente de imagens.
A data limite de maio de 2024 sugere que foi provavelmente diretamente baseada no o4-mini ou é uma versão leve da família GPT-5 (GPT-5 mini ou até mesmo uma versão de parâmetros extremamente pequenos, GPT-5 nano).
É exatamente porque essa base leve já possui uma capacidade extremamente forte de planejamento espacial e compreensão de instruções complexas que a geração de imagens superior consegue manter a estabilidade e não se desorganizar.
E o modelo de pensamento extremamente inteligente e voltado para estratégia comercial não pode ser baseado no modelo principal do GPT-5.
Porque a base de conhecimento básica do GPT-5 é até setembro de 2024.
O modo de pensamento provavelmente está integrado ao modelo de inferência da série O, que está em constante iteração em segundo plano (por exemplo, o o4 ou uma versão atualizada do o3).
O modelo grande primeiro utiliza o mecanismo de reflexão prolongada exclusivo da série O, calculando cuidadosamente na espaço latente a lógica comercial, a psicologia do público-alvo e as coordenadas de layout, antes de passar para o módulo visual realizar a renderização final de pixels.
Claro, também há outro caminho possível:
Sob um mecanismo de alocação de poder computacional extremamente refinado dentro da OpenAI, o modo rápido pode estar diretamente utilizando o GPT-5 nano como fallback, enquanto o modo de pensamento utiliza um GPT-5 mini ligeiramente maior combinado com ferramentas externas.
Mas, independentemente da combinação de base, se você acompanhar constantemente o ecossistema da API da OpenAI, perceberá que sua lógica de geração subjacente já está em uma dimensão completamente diferente da do Midjourney.
PART.04 A precificação mais importante para todos
Mas, em vez de adivinhar a base, o que realmente importa para desenvolvedores e empresas que realmente pretendem integrá-la ao seu fluxo de trabalho é aquela tabela de preços de API extremamente realista e contra-intuitiva.
Anteriormente, o DALL-E 3 era cobrado por imagem (por exemplo, 0,04 dólares por imagem).
Mas desde a primeira geração GPT-Image-1, a OpenAI já a transformou completamente em um modelo de cobrança por Token.
O GPT-Image-2 desta vez mantém esse padrão e, além disso, oferece mais recursos por um preço mais baixo.
De acordo com a tabela de preços divulgada oficialmente há pouco, o preço por milhão de tokens é o seguinte.
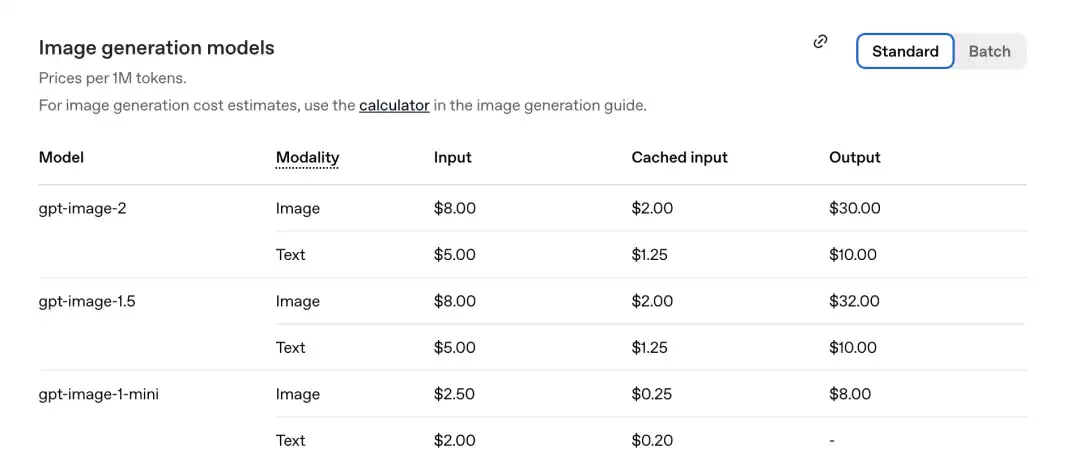
GPT-Image-2 Parte da imagem: entrada 8,00, entradas em cache (Cached inputs) 2,00, saída $30,00.
Comparado com a geração anterior gpt-image-1.5: o custo é de $32.00.
O novo modelo ficou até mais barato.
Vamos fazer as contas.
Nos modelos anteriores, gerar uma imagem de alta qualidade consumia aproximadamente 1.000 a 1.500 tokens de saída.
Calculando o preço de 30 dólares por milhão de tokens gerados, o custo real de criar uma imagem varia entre aproximadamente 0,03 e 0,045 dólares (equivalente a cerca de 2 a 3 centavos de yuan chinês).
Se você não precisar de respostas em tempo real, mas usar o modo API Batch (lote) fornecido oficialmente, esse preço ainda será reduzido pela metade (o custo cairá diretamente para US$ 15,00).
Calculando, gerar uma imagem custa apenas mais de 10 centavos.
Este preço já é bastante vantajoso, mas seu verdadeiro trunfo está na entrada em cache (Cached inputs) na tabela de preços.
Anteriormente, ao criar quadrinhos ou projetar cartazes de uma mesma série, a cada nova geração, você precisava carregar novamente inúmeras imagens de referência de personagens, resumos anteriores e prompts longos, resultando em um custo de entrada muito alto.
Mas, no atual modelo de cobrança por token, ao solicitá-lo para gerar oito quadrinhos contínuos de uma só vez, os elementos visuais da primeira imagem serão armazenados diretamente como contexto em cache.
A partir da segunda imagem, o custo de entrada da imagem caiu diretamente de US$8,00 para US$2,00 (ou seja, apenas 25% do valor).
Isso significa que, ao realizar grandes lotes comerciais de geração de imagens ou quando é exigida alta consistência de personagens em gerações contínuas, seu custo marginal cai drasticamente.
Quanto mais inteligente o modelo e mais imagens ele gerar, menor será o custo médio por imagem.
Essa lógica de cobrança industrializada é o que realmente levará os artistas de linha de produção ao limite.
PART.05 Revelação da equipe de bastidores
Por fim, vamos revisitar a equipe visual sonhada da OpenAI que fez a demonstração no lançamento ao vivo; muitas funcionalidades que antes pareciam absurdas agora ficam totalmente explicáveis.
Por exemplo, como ele resolve exatamente os desafios de layout multilíngue e caracteres ilegíveis.
Isso não seria possível sem o cientista sênior da equipe, Gabriel Goh.

Neste meio acadêmico, sua identidade mais famosa é a de autor principal do modelo multimodal inovador CLIP.
CLIP established the foundation for understanding how modern AI correlates human language with image pixels.
Com este especialista em mapeamento semântico multimodal à frente, o GPT-Image-2 já não adivinha mais formas de texto aleatoriamente, mas realmente escreve ao nível dos pixels.
Por exemplo, como ele entende relações espaciais tridimensionais, consegue criar panoramas 360 graus com proporções extremas e ainda compreende jogos de luz e sombra em microscopia de grãos de arroz?
Isso é graças a outro membro-chave, Alex Yu.

Antes de se juntar à OpenAI, foi cofundador e ex-CTO da Luma AI, uma startup estrela no campo da geração 3D, e também um acadêmico de ponta especializado em renderização neural 3D (como NeRF).
Com ele, o GPT-Image-2 já ultrapassou a pintura tradicional de pixels 2D.
É muito provável que tenha primeiro criado mentalmente uma cena tridimensional, posicionado as luzes e, em seguida, gerado uma fatia 2D precisa.
Como é feita aquela consistência de história em quadrinhos de várias páginas tão aterrorizante.
This corresponds to the young duo from MIT CSAIL who just graduated:
Boyuan Chen (esquerda) e Kiwhan Song (direita).
Eles têm como direção principal na academia modelos mundiais (World Models) e inteligência embodiada.
Ensinar máquinas a compreender como o mundo físico funciona, mantendo os personagens com características perfeitamente consistentes e sem deformação em diferentes cenas ao longo do tempo e do espaço, é exatamente o problema que esses dois acadêmicos têm tentado resolver.
Por fim, inclua Nithanth Kudige (esquerda, autor importante do modelo de inferência da série O), que sempre se dedicou a conectar modelos de inferência de grande porte com a lógica subjacente da visão, e Kenji Hata (direita, ex-pesquisador do Google, formado no Laboratório de Visão da Stanford).

Quando esse grupo se reúne, a lógica de raciocínio de baixo nível, a renderização espacial 3D, o alinhamento perfeito entre texto e imagem e as leis do mundo físico são naturalmente integradas em um único modelo.
PART.06 Limite do GPT-Image-2
Qualquer modelo tem limites.
O oficial também reconheceu que ainda enfrenta dificuldades diante de certas situações extremas.
Por exemplo, instruções de origami que exigem inversão física rigorosa, resolver o cubo Mágico ou detalhes extremamente densos e repetitivos, como grãos de areia, ainda atingem seus limites de capacidade.
Mas, no contexto de aplicações comerciais, essa já é uma imperfeição extremamente pequena.
Para toda a indústria de design, não precisamos vender ansiedade; isso não representa a morte da estética.
Pessoas com gosto, visão comercial e compreensão de estratégia ainda conseguem criar coisas excelentes com ele.
Mas o fato objetivo é que a barreira protetora do designer como profissão foi substancialmente destruída.
Antes, vivia decorando atalhos de softwares de design, sabendo alinhar fontes horizontal e verticalmente, entendendo como fazer a tipografia conforme o idioma e dominando o retrato fino e o recorte de imagens.
Mas será muito mais difícil no futuro, pois essas habilidades que anteriormente podiam ser comercializadas abertamente agora se tornaram instruções básicas que qualquer pessoa pode chamar gratuitamente com uma única frase.
Após um período de silêncio, a OpenAI realmente usou uma maneira muito tranquila, mas de grande impacto, para mais uma vez provar quem realmente tem as cartas na mão nesta mesa.
A antiga cadeia de ferramentas de execução está se quebrando; a questão que permanece para a indústria não é mais se a IA nos substituirá, mas como nos adaptaremos a esta nova linha de produção.