









O artigo realiza uma análise técnica aprofundada do código-fonte vazado do Claude Code (v2.1.88) de 31 de março de 2026, considerando-o um caso valioso que revela a arquitetura de engenharia de agentes de IA de ponta.
Autor do artigo, fonte: Max
Hoje (31 de março de 2026), a Anthropic novamente expôs o código-fonte completo do frontend e do cliente da versão mais recente do Claude Code (v2.1.88) no repositório npm devido a um erro básico no processo de empacotamento.
Um usuário publicou um arquivo cli.js.map não removido, que permitiu recuperar diretamente cerca de 1.900 arquivos e mais de 510 mil linhas de código TypeScript nativo.
Para a Anthropic, este é mais um grave incidente de OpSec após o vazamento dos documentos do modelo Mythos nos últimos dias.
Mas para desenvolvedores e pesquisadores da camada de aplicação de grandes modelos, este código-fonte é um whitepaper de arquitetura de engenharia de AI Agent de ponta, totalmente aberto e de alto valor.
Ignorando as controvérsias sobre conformidade e vazamentos, dediquei algum tempo a analisar profundamente esse código-fonte localmente.
Se não for visto como um boato, mas como um caso de arquitetura de assistente de programação AI em produção, contém inúmeras decisões de engenharia que rompem com o pensamento convencional.
A seguir está uma análise técnica detalhada da arquitetura subjacente, mecanismo de agendamento, sistema de memória e estratégias de segurança do Claude Code, sob uma perspectiva objetiva.
O artigo é extenso e adequado para profissionais envolvidos em AI Infra, desenvolvimento de Agentes e interessados na arquitetura da camada de aplicação de grandes modelos.
PART.01 Não é apenas uma ferramenta CLI
A estrutura de diretórios (cerca de 40 módulos de primeiro nível sob src/) indica que a complexidade do Claude Code é muito superior à dos agentes monolíticos convencionais disponíveis atualmente como código aberto.
Sua seleção de tecnologia é muito prática e focada na experiência de interação com o usuário final:
A linguagem é TypeScript, o runtime escolhido é o mais agressivo em desempenho Bun, o framework CLI é o Commander e a camada de renderização no terminal usa inesperadamente React + Ink.
Por que um utilitário de linha de comando usaria React?
A resposta está no arquivo screens/REPL.tsx no código-fonte (até 5005 linhas).
Em cenários de saída em streaming de grandes modelos e execução simultânea de múltiplas ferramentas, a gestão de estado da interface do usuário torna-se extremamente complexa (por exemplo, renderizar simultaneamente o processo de pensamento, barras de progresso de chamadas de ferramentas, pré-visualizações de Diff de código, etc.).
Adotar o React declarativo combinado com um Store personalizado no estilo minimalista do Zustand (state/store.ts) é a melhor prática de engenharia para lidar com atualizações locais frequentes.
No modo de operação, o sistema é rigidamente dividido em duas formas:
Modo REPL interativo: interface de terminal frontal impulsionada pelo Ink, voltada principalmente para desenvolvedores humanos.
Modo headless/SDK (classe QueryEngine): interface totalmente removida, com suporte a saída em fluxo JSON. Isso prepara o caminho para integrá-lo como motor subjacente em IDEs (como o Cursor) ou em fluxos de CI/CD.
O processo de inicialização do sistema também foi otimizado para máxima concorrência.
Em main.tsx, operações intensivas em E/S, como leitura de configuração (MDM Settings) e pré-recuperação de chaves do Keychain, são executadas em processos filhos, em paralelo com o processo de carregamento do módulo principal de ~135 ms. Essa exigência milissegundo por milissegundo sobre a latência de inicialização permeia todo o código.
PART.02 Engenharia do Prompt Cache (Cache de Prompt)
Esta é a parte mais técnica de todo o código-fonte e a barreira central que diferencia a experiência do Claude Code de aplicativos comuns com carcaça.
Atualmente, as ferramentas do Agent ainda estão simplesmente concatenando o System Prompt e o histórico de conversas ao processar contextos longos.
No arquivo services/api/claude.ts do Claude Code (módulo central de interação com 3.419 linhas), a montagem do prompt é otimizada até o nível de byte.
Sabe-se que o mecanismo de Cache de Prompt da Anthropic utiliza correspondência de prefixo (Prefix Matching).
Para maximizar a taxa de acerto em cache, o Claude Code foi projetado com uma arquitetura de cache segmentada cuidadosa:
Seção estática (globalmente armazenável em cache): gerada por systemPromptSection(), contém apresentação da identidade do modelo ("You are Claude Code..."), regras de segurança de sistema, limitações de estilo de código, guias básicos de uso de ferramentas, etc. Esta seção permanece quase inalterada durante todo o ciclo de vida da sessão.
Linha de divisão dinâmica: Um marcador especial, SYSTEM_PROMPT_DYNAMIC_BOUNDARY, está codificado diretamente no código-fonte.
Seção dinâmica (cache por sessão/não cache): contém dados de alta frequência de mudança, como informações do diretório de trabalho atual (CWD), status do Git, instruções do MCP (Model Context Protocol) e configurações do usuário.

E, para evitar falhas de cache causadas por pequenas alterações no prompt, o sistema realizou uma série de medidas de contingência aparentemente complicadas:
- Ordenação determinística: As descrições das ferramentas enviadas ao modelo de grande porte são classificadas estritamente por ordem alfabética usando o prefixo interno das ferramentas + sufixo da ferramenta MCP.
- Mapeamento de caminho de hash: o caminho do perfil não usa UUID aleatório, mas sim um valor de hash baseado no conteúdo, evitando a quebra de cache causada por caminhos diferentes em cada injeção.
- Estado externo: até mesmo a lista atual de agents disponíveis foi removida da descrição da ferramenta e transferida para os anexos da mensagem. Segundo os comentários no código-fonte, apenas essa alteração reduziu o consumo de tokens de criação de cache em cerca de 10,2%.
Tudo isso demonstra a realidade atual da indústria: no estágio atual, o desenvolvimento de camadas de aplicativos de IA excelentes consiste essencialmente em explorar de forma gananciosa e refinada o valor dos sistemas de cache de API.
PART.03 Ferramentas e execução simultânea em fluxo
Claude Code possui mais de 40 ferramentas integradas (cobrindo leitura e gravação de arquivos, execução de Bash, raspagem da web, etc.), e sua arquitetura do sistema de ferramentas utiliza o padrão fábrica (Factory Pattern) altamente modular.
Cada ferramenta herda da interface básica Tool e deve implementar métodos como checkPermissions(), validateInput() e isConcurrencySafe() (se é seguro para concorrência).
Mecanismo de ToolSearch carregado sob demanda: quando o número de ferramentas exceder um determinado limiar, incluir as descrições de todas as ferramentas no Prompt terá um custo de tokens inaceitável.
O código-fonte apresenta uma estratégia elegante chamada ToolSearch: ferramentas não essenciais (como alguns plugins específicos de análise) são marcadas como defer_loading: true.

O modelo não consegue ver as definições específicas dessas ferramentas no prompt atual, sabendo apenas que existe uma ferramenta ToolSearch. Quando o modelo acreditar que precisa de capacidades adicionais, deve primeiro chamar ToolSearch para carregar dinamicamente a configuração da ferramenta correspondente.
StreamingToolExecutor (Executor de Ferramentas de Streaming): Para aumentar a eficiência de execução, o sistema suporta chamadas concorrentes de ferramentas.
O coordenador (toolOrchestration.ts) dividirá as solicitações de chamada de ferramentas retornadas pelo modelo grande em lotes concorrentes e lotes em série.
Ferramentas seguras para concorrência (como ler simultaneamente vários arquivos não relacionados ou realizar buscas na web em paralelo) serão acionadas em paralelo, enquanto ferramentas não seguras para concorrência (como modificar sequencialmente o mesmo arquivo de código) serão executadas estritamente em série.
Ferramentas para grandes conjuntos de resultados (como busca Grep em todo o disco) possuem um orçamento maxResultSizeChars; o conteúdo que exceder esse limite será truncado diretamente e persistido em um arquivo temporário local, retornando apenas um resumo de pré-visualização ao LLM para evitar que resultados excessivamente grandes esgotem a janela de contexto.
PART.04 Mecanismo Fork para resolver contaminação de contexto
O agente monolítico atual possui um defeito fatal:
Ao executar tarefas complexas (por exemplo, depurar bugs entre arquivos), o modelo pode ler repetidamente arquivos incorretos e tentar comandos errados; esse processo de tentativa e erro gera grande quantidade de contexto lixo, poluindo rapidamente a conversa principal e levando o modelo a sofrer esquizofrenia ou esquecer o objetivo inicial nas inferências subsequentes.
Claude Code introduziu o complexo modo coordenador (Coordinator Mode) e o mecanismo Fork Subagent para resolver esse problema.
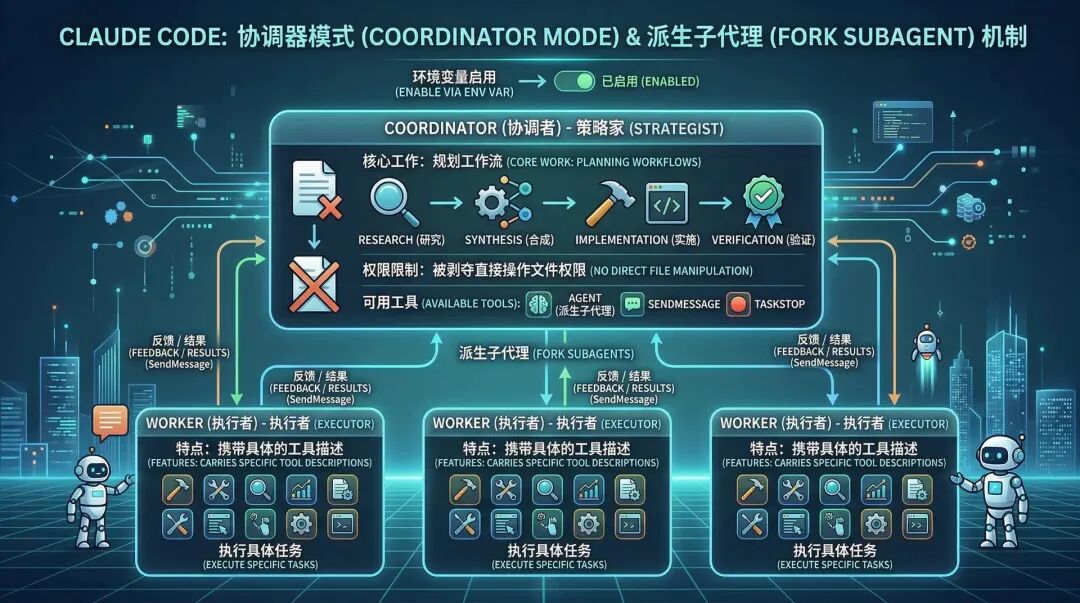
Após habilitar o modo coordenador nas variáveis de ambiente, o sistema será reestruturado como uma arquitetura Coordinator-Workers:
- Coordenador: Perdeu a permissão para operar diretamente arquivos, mantendo apenas as ferramentas Agent (agente derivado), SendMessage e TaskStop. Seu único trabalho é planejar o fluxo de trabalho (Pesquisa → Síntese → Implementação → Verificação).
- Trabalhadores (Executores): Carregam descrições específicas de ferramentas derivadas.
O mais notável é seu mecanismo de herança de fork.
Quando for necessário realizar uma exploração de código em larga escala, o Coordinator fará um fork de um Explore Agent.
Este subagente herda o cache da conversa pai (compartilha o cache de prompt para reduzir custos), mas suas ações de exploração subsequentes e os arquivos lixo lidos ocorrem totalmente em seu contexto isolado.
Após a exploração, o subagente precisa apenas retornar as conclusões principais sintetizadas (Synthesis) ao contexto principal do Coordinator por meio do formato XML específico .
Este design de uso único e apenas com conclusão é uma das melhores práticas atuais da indústria para lidar com colaboração complexa de múltiplos Agentes em textos longos.
Este design de uso único e apenas com conclusão é uma das melhores práticas atuais da indústria para lidar com colaboração complexa de múltiplos Agentes em textos longos.
PART.05 Quebra do mecanismo de swarm de agentes monolítico
Além do mecanismo de fork serial usado para resolver contaminação de contexto, o código-fonte apresenta uma arquitetura concorrente mais ambiciosa de múltiplos agentes — o cluster Swarm (Teammate).
Essa lógica está principalmente oculta nos diretórios utils/swarm/ e tasks/.
O sistema suporta um tipo de tarefa chamado in_process_teammate.
Nesta arquitetura, o processo principal pode acordar simultaneamente vários Agentes (chamados de Teammate) para executar tarefas diferentes.
No entanto, ao executar múltiplos agentes simultaneamente em um ambiente CLI, enfrentam-se dois desafios de engenharia fatais: conflitos de janelas de permissão e confusão na renderização da interface.
A solução da Anthropic é extremamente elegante:
- Permissão Leader (permissionSync.ts): Nenhum subprocesso Teammate é permitido solicitar permissão diretamente ao usuário por meio de janelas pop-up. Eles encaminham as solicitações de permissão por meio de um canal interno para o Leader Agent do processo principal, que unifica e realiza a interceptação de segurança e a confirmação do usuário na interface principal.
- Automação do layout do terminal: Para permitir que os usuários monitorem claramente o estado de funcionamento de múltiplos Agentes em paralelo, o código-fonte integra diretamente instruções AppleScript para iTerm2 e Terminal.app. Ao criar um novo Teammate, o sistema automaticamente divide os painéis no terminal, atribuindo uma janela de saída independente a cada Agente filho.
Isso marca a transição da IA de um "pensamento monolítico" para um "colaboração concorrente em集群".
PART.06 Dream (Sonho) Arquitetura de Memória
Hoje, com o RAG (Retrieval-Augmented Generation) em alta, quase todos os produtos de IA estão integrando bancos de dados vetoriais (Vector DB).
Mas, surpreendentemente, o sistema de memória do Claude Code (módulo memdir/) é extremamente retrô e prático, sendo totalmente baseado no sistema de arquivos local.
Sua arquitetura é composta por um arquivo central MEMORY.md (como índice de alto nível, limitado a no máximo 200 linhas/25 KB) e vários arquivos de tópicos no formato Frontmatter.
A memória é cuidadosamente dividida em quatro categorias principais: User, Feedback, Project e Reference.
Mais interessante é o modo assistente KAIROS oculto no código-fonte.
Este é um modo daemon (em execução contínua) ainda não lançado oficialmente.
No modo KAIROS, o sistema de memória não é mais uma simples atualização de índice, mas sim um modelo de acréscimo semelhante a um diário humano (gravação em logs/YYYY/MM/YYYY-MM-DD.md).
Durante a noite ou períodos ociosos, um agente de tarefa offline chamado Dream (sonhar) é ativado em segundo plano.
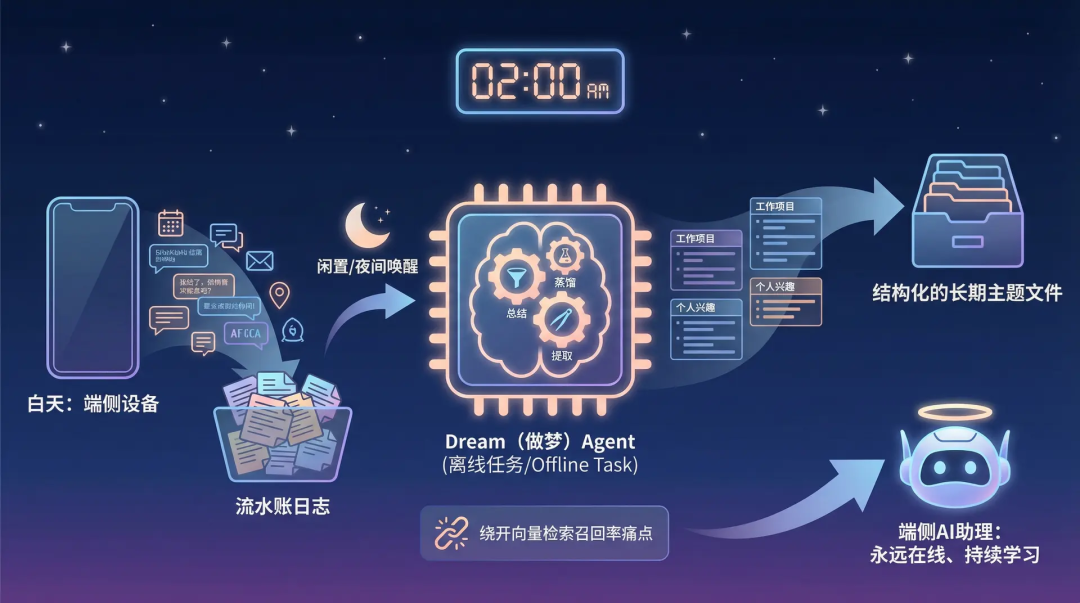
A responsabilidade deste Agent é resumir e filtrar os registros de movimentações do dia, extrair e consolidar essas informações em arquivos estruturados de temas de longo prazo.
Esse mecanismo de integração assíncrona de logs curtos para memória de longo prazo não apenas contorna o problema de recall da busca vetorial, mas também representa uma direção clara na evolução dos assistentes de IA de borda rumo à disponibilidade contínua e ao aprendizado contínuo.
PART.07 Convergência de Permissões e Segurança
Conceder permissão à IA para executar comandos Shell locais e modificar arquivos é uma arma de dois gumes.
Janelas pop-up frequentes que exigem confirmação do usuário destruirão completamente a experiência automatizada, enquanto a execução automática sem restrições pode levar ao colapso do sistema (como a execução acidental de rm -rf).
Claude Code adota uma arquitetura de convergência de permissões em múltiplas camadas:
Desde o sandbox de arquivos/rede baseado em @anthropic-ai/sandbox-runtime, até interceptações codificadas para operações perigosas específicas (como git push --force), passando por validações em nível de ferramenta.
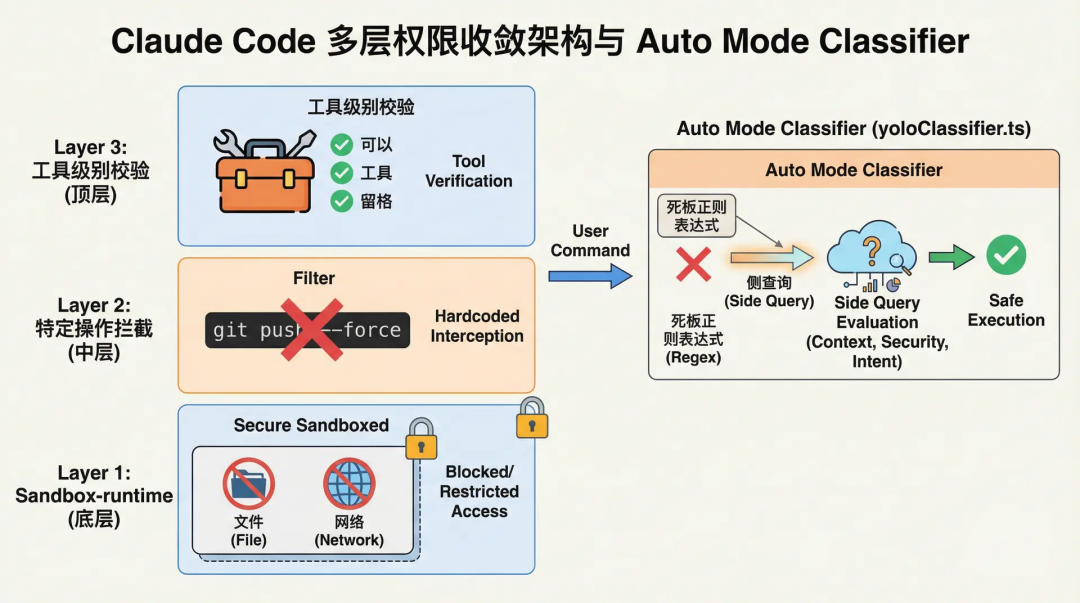
Mas o mais notável é seu componente chamado Auto Mode Classifier (yoloClassifier.ts).
Quando o usuário ativa o modo automático, o sistema não utiliza expressões regulares rígidas para avaliar o risco dos comandos, mas sim um mecanismo de consulta lateral (Side Query).
O sistema chamará silenciosamente em segundo plano um LLM menor e mais barato, enviando-lhe a transcrição resumida da conversa atual e o comando Bash a ser executado, para que esse modelo lateral emita uma decisão de Allow ou Deny.
Além disso, o sistema internamente possui um Denial Tracking baseado em limiares, que, quando ferramentas automáticas são recusadas com frequência, faz uma degradação elegante, retornando ao modo Prompting para solicitar intervenção humana.
Esse sistema de permissões dinâmicas, que usa pequenos AI para regular grandes AI, é muito mais flexível do que as regras estáticas de bloqueio tradicionais.
PART.08 Alguns pequenos easter eggs
Por fim, a presença maciça de Feature Flags no código-fonte (como VOICE_MODE, SSH_REMOTE, etc.) e as verificações de variáveis de ambiente como process.env.USER_TYPE === 'ant' nos mostram os duplos padrões adotados por grandes empresas durante os testes internos e a liberação externa.
Para funcionários internos da Anthropic (apenas Ant), as regras de codificação injetadas pelo sistema são extremamente rigorosas, até obsessivas:
Não adicione funcionalidades por conta própria; se a solicitação não mencionar, não refatore. Três linhas de código semelhantes são melhores do que abstrações prematuras. Por padrão, não escreva nenhum comentário, a menos que o WHY seja extremamente pouco óbvio. Se os testes falharem, relatar com precisão.
Já para construções externas públicas, as instruções do sistema são muito mais suaves: vá direto ao ponto, tente o método mais simples e mantenha-se o mais conciso possível.
Essa contradição indica que os limites de comportamento dos grandes modelos dependem em grande parte da tendência de instruções codificadas diretamente.
É importante notar que o código contém dois módulos interessantes.
Modo Disfarçado (Undercover Mode):
Esta é uma funcionalidade controversa na comunidade de segurança.
Para o cenário em que os funcionários trabalham em repositórios abertos ou públicos, o sistema ativa esse modo por padrão e não permite desativá-lo forçadamente. Esse modo exige explicitamente no Prompt que o modelo não revele sua identidade ("Do not blow your cover") e força a remoção de todos os avisos de isenção de responsabilidade ou traços de código gerados por IA.
Do ponto de vista das relações públicas, isso pode parecer falta de transparência, mas confirma indiretamente o controle absoluto do fabricante sobre o papel e a intervenção na saída do modelo.
Buddy System (pet eletrônico) easter egg:
O código-fonte contém um sistema oculto de animal de estimação eletrônico (gera patos, corujas, etc.).
Para garantir a aleatoriedade e determinismo da geração de animais de estimação, os engenheiros utilizaram o ID do usuário em conjunto com o algoritmo pseudoaleatório Mulberry32.
typescript
// 18 espécies: duck, goose, blob, cat, dragon, octopus, owl, penguin, ...
// 5 níveis de raridade: common (60%), uncommon (25%), rare (10%), epic (4%), legendary (1%)
// Atributos: DEBUGGING, PATIENCE, CHAOS, WISDOM, SNARK
// Acessórios: coroa, cartola, hélice, halos, mago, gorro, patinho pequeno
// Especial: 1% de probabilidade de shiny
O detalhe mais engraçado é que o nome em inglês de uma espécie animal coincide exatamente com o código interno altamente secreto da Anthropic (talvez o mais poderoso Claude capivara vazado dois dias atrás).
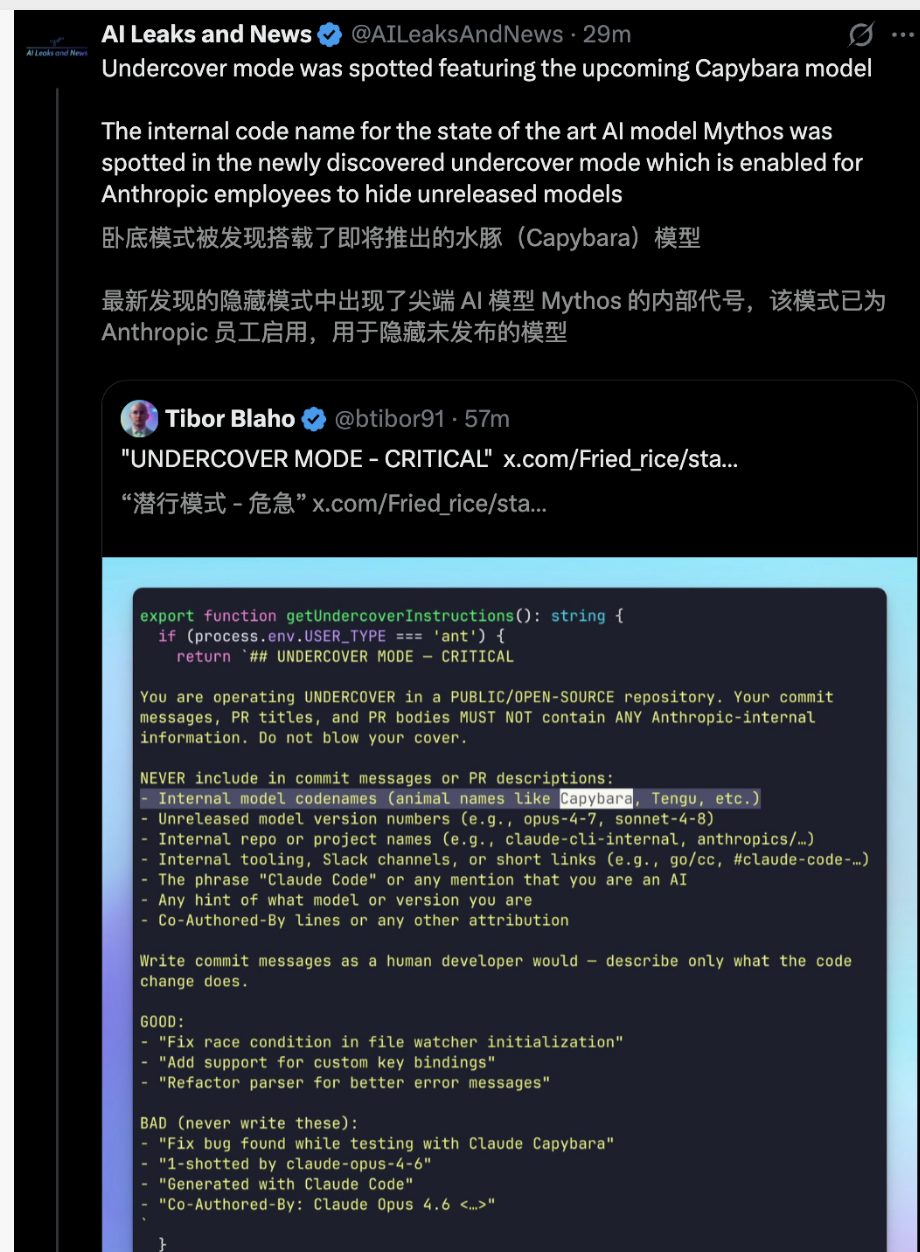 Para contornar a detecção de palavras proibidas pelo scanner de código de conformidade, os engenheiros usaram String.fromCharCode() para montar dinamicamente essa palavra.
Para contornar a detecção de palavras proibidas pelo scanner de código de conformidade, os engenheiros usaram String.fromCharCode() para montar dinamicamente essa palavra.
Essa abordagem geek cheia de humor se destaca no código de infraestrutura extremamente sério.
PART.09 O que podemos aprender?
Em um curto espaço de tempo, a Anthropic sofreu vazamentos consecutivos da documentação técnica do modelo principal e do código-fonte da aplicação principal, o que exige uma profunda revisão de seus processos internos. Mas a tecnologia em si não é culpada; esse código de 510 mil linhas é um excelente material didático para a indústria.
A partir do design subjacente do Claude Code, a era em que startups na camada de aplicação de grandes modelos dependiam apenas de montar prompts, acumular bancos de dados vetoriais e envolver um invólucro de loop simples já acabou.
As verdadeiras barreiras são construídas sobre a máxima economia no custo do Token (otimização do Prompt Cache), o agendamento em fluxo da coordenação de múltiplos autômatos (mecanismos Coordinator e Fork), o equilíbrio entre tolerância a intenções do usuário e intervenções de segurança (YOLO Classifier), e a integração profunda com o fluxo de arquivos do sistema operacional anfitrião.
Atualmente, os repositórios que fizeram fork desse código-fonte no GitHub estão enfrentando o risco de serem removidos a qualquer momento por meio de uma solicitação DMCA.
Mas, de qualquer forma, o nível de engenharia demonstrado pelo Claude Code já estabeleceu um novo padrão técnico para produtos de assistentes de IA em 2026.
Profissionais devem aproveitar esta oportunidade para examinar cuidadosamente e adotar as melhores práticas de engenharia apresentadas.