










Fonte: Instituto de Pesquisa CoinW
Resumo
Gradients é uma sub-rede descentralizada de treinamento de IA construída sobre o Bittensor (SN56), cujo núcleo consiste em transformar o treinamento de modelos de um processo técnico complexo em um processo de colaboração em rede impulsionado pelo mercado, por meio de mecanismos como "publicação de tarefas, competição entre mineiros e verificação seletiva". Em termos de arquitetura, combina AutoML e capacidade de processamento distribuída para formar um mercado de treinamento centrado em mecanismos de incentivo, reduzindo não apenas a barreira de entrada para o uso de IA, mas também aumentando a eficiência na utilização da capacidade computacional. Em termos de ecossistema e desempenho de dados, o Gradients já concluiu a construção da rede básica, mas os pesos de incentivo e o fluxo de capital ainda são relativamente limitados. O Gradients complementa a infraestrutura de treinamento no ecossistema TAO e explora um novo paradigma de "otimização de IA impulsionada pelo mercado", com potencial a longo prazo de se tornar uma camada importante de entrada para o treinamento descentralizado de IA.
1. Começando com o Web2 AutoML: O estado atual e as limitações do treinamento de IA
1.1 O que é AutoML
Na percepção tradicional, treinar um modelo de IA era uma tarefa de alto nível, exigindo engenheiros para processar dados, escolher modelos, ajustar parâmetros repetidamente e avaliar os resultados — um processo complexo e demorado. A chegada do AutoML (aprendizado de máquina automatizado) consiste essencialmente em “empacotar e automatizar” esses passos繁琐. Pode-se entendê-lo como uma “ferramenta automática para criar modelos”: o usuário apenas fornece os dados e informa ao sistema o objetivo desejado, como classificação, previsão ou reconhecimento, e o sistema automaticamente realiza todo o processo restante — escolha do modelo, ajuste de parâmetros, treinamento e otimização. Isso transformou a IA de uma ferramenta exclusiva de poucos engenheiros especializados em uma capacidade acessível a desenvolvedores comuns e até empresas, sendo um passo importante na democratização da IA.
1.2 Principais limitações do AutoML tradicional
As implementações dominantes de AutoML atualmente estão concentradas em plataformas de provedores de nuvem, como o Google Vertex AI e o AWS SageMaker, que oferecem “treinamento de IA como serviço”. Embora o AutoML Web2 tenha reduzido significativamente a barreira de entrada para o uso de IA, seus modelos subjacentes ainda apresentam limitações evidentes. Primeiramente, há o problema da centralização: a capacidade de processamento, os preços e as regras são todos controlados pela plataforma, resultando em forte dependência dos usuários em relação a um único provedor e falta de poder de negociação. Em segundo lugar, os custos são altos e pouco transparentes: os recursos de GPU necessários para o treinamento de IA estão majoritariamente sob o controle dos provedores de nuvem, e os mecanismos de precificação carecem de competição de mercado. Mais importante ainda, existe um limite na eficiência de otimização. O AutoML tradicional é, essencialmente, “um sistema que busca a melhor solução para você”; independentemente da complexidade desse sistema, ele ainda se trata de uma otimização dentro de uma única abordagem tecnológica. Seu espaço de exploração é limitado e dificilmente consegue testar simultaneamente múltiplas abordagens completamente diferentes. Portanto, o treinamento de IA Web2 atual é um “sistema fechado”, no qual o treinamento, a otimização e o agendamento de recursos ocorrem em um ambiente controlado por uma única plataforma. Embora esse modelo seja eficiente, à medida que a demanda cresce, seus limites estão se tornando cada vez mais aparentes.
2. Gradients: Reconstruct AI training with "network"
2.1 Gradients é o quê: uma plataforma AutoML descentralizada
No capítulo anterior, mencionamos que o problema central do AutoML tradicional Web2 é o “sistema fechado”: o treinamento do modelo depende da plataforma, possui caminhos de otimização limitados e fluxo de recursos restrito. O Gradients é uma reestruturação desse modelo. O Gradients surgiu da comunidade descentralizada de engenheiros iniciada pela WanderingWeights, construído sobre a rede Bittensor e operando como uma sub-rede de treinamento de IA no Subnet 56. Diferentemente das plataformas tradicionais, ele não oferece serviços centralizados, mas sim divide e delega o processo de treinamento a uma rede aberta. O usuário apenas precisa definir o objetivo da tarefa, como o tipo de modelo e os dados; todo o restante — execução do treinamento, otimização de parâmetros e seleção de resultados — é feito automaticamente pela rede. Nesse modelo, o treinamento de IA é abstraído de um processo de engenharia complexo para um processo simples de “enviar uma solicitação e receber um resultado”, tornando-se mais como uma capacidade geral, em vez de um trabalho técnico com barreira de entrada muito alta.
2.2 De um sistema fechado para colaboração aberta: O que os Gradients resolvem
A mudança central do Gradients consiste em transformar o processo de treinamento, anteriormente confinado a uma única plataforma, em um processo de rede aberta e colaborativa. As tarefas de treinamento não são mais realizadas por um único sistema, mas distribuídas entre múltiplos participantes que as tentam em paralelo, sendo posteriormente selecionados os melhores resultados por meio de um mecanismo de avaliação unificado. Essa estrutura reduz inicialmente a dependência de provedores centralizados, baseando o treinamento em capacidade de computação distribuída; ao mesmo tempo, recursos de GPU dispersos são integrados em uma única rede, formando, por meio da competição, uma forma de alocação de recursos mais próxima do mercado. Mais importante ainda, a otimização do modelo não está mais limitada a um único caminho, mas avança continuamente em direção a soluções superiores por meio da exploração paralela de múltiplos métodos, elevando assim o limite geral de otimização.
2.3 Mudança essencial: de ferramenta para "mercado de treinamento"
Na AutoML tradicional, a plataforma funciona mais como uma ferramenta que ajuda os usuários a encontrar a melhor solução por meio de algoritmos internos. Já no Gradients, esse processo se assemelha mais a um “mercado” em constante funcionamento: os usuários publicam demandas, diferentes participantes competem em torno da mesma tarefa e os resultados são filtrados por mecanismos de avaliação. Assim, o desempenho do modelo não depende mais da capacidade de um único sistema, mas sim da competição e iteração contínuas promovidas por múltiplos participantes. A AutoML passa de um problema técnico relativamente fechado de otimização para um processo dinâmico impulsionado por incentivos, permitindo que a capacidade de otimização se expanda à medida que mais participantes se juntam. Essa transformação faz com que o treinamento de IA comece a exibir características de autossuperação semelhantes às de um mercado.
2.4 Papel na ecossistema TAO: Camada de infraestrutura de treinamento de IA
Na arquitetura de sub-redes do Bittensor, diferentes Subnets desempenham funções distintas, como inferência, processamento de dados e treinamento, e o Gradients está localizado na camada de treinamento. Ele é responsável por transformar a capacidade de computação distribuída em produções de modelos reais, por meio de mecanismos de distribuição e avaliação de tarefas, permitindo que esses recursos sejam continuamente agendados e otimizados. Ao mesmo tempo, ele conecta a oferta de poder computacional à demanda por modelos, transformando o treinamento de um simples processo de consumo de recursos em um processo colaborativo organizável e otimizável. Nesta arquitetura, o Gradients atua como um elo central, convertendo recursos distribuídos em capacidades de IA utilizáveis e sustentando o desenvolvimento de aplicações de camada superior.
3. Arquitetura principal: Como o treinamento de IA é realizado na rede
No capítulo anterior, mencionamos que os Gradients transformaram o treinamento de IA de “concluído dentro da plataforma” para “realizado por colaboração em rede”. Como exatamente essa rede funciona? O foco deste capítulo é descompor esse processo de forma mais intuitiva.
3.1 Treinamento distribuído: como uma tarefa é “concluída por várias pessoas”
Você pode imaginar o Gradients como uma “rede de colaboração de treinamento” em execução contínua. Quando um usuário envia uma tarefa de treinamento, essa tarefa não é atribuída a um único sistema para ser concluída, mas sim distribuída simultaneamente a múltiplos participantes da rede. Esses participantes, com base nos mesmos dados e objetivos, tentam diferentes métodos de treinamento e enviam seus resultados dentro do prazo estabelecido. Em seguida, o sistema avalia uniformemente esses resultados e seleciona a melhor solução. Finalmente, os resultados mais eficazes recebem recompensas, enquanto as outras soluções são descartadas. Do ponto de vista do usuário, esse processo exige apenas o envio de uma única tarefa, equivalendo a “chamar” simultaneamente várias abordagens de otimização diferentes e automaticamente selecionar a melhor solução. A chave desse método não reside na força individual de cada nó, mas na combinação de tentativas paralelas por múltiplas pessoas + seleção automática, permitindo que os resultados se aproximem continuamente do ótimo.
Nesta rede, há três principais participantes: usuários, mineiros e validadores. Os usuários são responsáveis por apresentar necessidades de treinamento; os mineiros fornecem poder de processamento e experimentam diferentes métodos de treinamento; os validadores avaliam os resultados e selecionam os melhores modelos. Essa divisão de tarefas permite que o processo de treinamento continue em funcionamento e constantemente identifique soluções superiores. No geral, forma uma rede colaborativa impulsionada por “demanda, oferta e avaliação”.
3.2 AutoML impulsionado pelo mercado
Na análise do mecanismo apresentada anteriormente, pode-se ver que o Gradients não simplesmente transfere o AutoML para a cadeia, mas altera a lógica subjacente da otimização de modelos ao introduzir participação múltipla e mecanismos de incentivo. O AutoML tradicional depende de um único sistema buscando a melhor solução dentro de caminhos limitados, enquanto no Gradients, esse processo é expandido para toda a rede: diferentes participantes continuamente tentam abordagens distintas para a mesma tarefa e, por meio de uma avaliação unificada, selecionam e iteram constantemente. Isso transforma a otimização do modelo de um processo computacional único em um processo dinâmico e passível de evolução contínua. Sob esse mecanismo, resultados com melhor desempenho recebem maior recompensa, atraindo continuamente participantes para aprimorar suas estratégias e impulsionando o aprimoramento constante do desempenho geral.
4. Mecanismos de incentivo e competição: Como o treinamento de IA forma um "círculo virtuoso"
4.1 Mecanismo de incentivo (impulsionado por TAO): Do comportamento de treinamento ao retorno de rendimentos
A chave para o funcionamento contínuo dos Gradients reside no mecanismo de incentivo por trás dele, que depende do sistema de incentivo nativo fornecido pelo Bittensor. Nesse contexto, TAO é o token nativo da rede Bittensor, atuando como o "veículo de valor" em toda a rede: por um lado, é usado para recompensar participantes que fornecem poder computacional e contribuições de modelos; por outro lado, também participa da alocação de peso das subredes por meio de mecanismos como staking, influenciando como os recursos fluem entre diferentes subredes.
A mainnet do Bittensor continuará a gerar novas emissões de incentivo TAO (atualmente cerca de 3600 TAO por dia), distribuindo-as entre diferentes subredes de acordo com regras específicas. A quantidade que cada subrede recebe depende de seu "desempenho" na rede como um todo, como nível de atividade, qualidade das contribuições e suporte financeiro, entre outros fatores. Para a subrede na qual o Gradients está localizado, essa parte dos TAO alocados será distribuída internamente entre os participantes. O critério central da distribuição é quem contribuiu com modelos melhores recebe mais recompensas.
Em detalhe, os mineiros enviam os resultados do treinamento, e os validadores são responsáveis por testar e pontuar esses resultados. O sistema calcula o “peso de contribuição” de cada participante com base nas pontuações e distribui recompensas de acordo com esse peso. Modelos com melhor desempenho (por exemplo, com maior capacidade de generalização e estabilidade de resultados) recebem maiores rendimentos, enquanto validadores que fornecem pontuações mais precisas e que melhor refletem a qualidade real também recebem maiores incentivos. Esse design faz com que “fazer melhor” corresponda diretamente a “ganhar mais”, incentivando os participantes a otimizarem continuamente seus modelos.
4.2 Competição entre sub-redes: não é apenas competição interna, mas também classificação externa
Além da competição interna na sub-rede, os Gradients enfrentam uma “competição horizontal” em toda a rede Bittensor. Como a distribuição de TAO é dinâmica, diferentes sub-redes competem por pesos mais altos. Apenas as sub-redes que continuam produzindo resultados de alta qualidade e atraindo mais participantes conseguem obter uma parcela maior de recompensas. Assim, os incentivos dos Gradients dependem não apenas do desempenho interno dos modelos, mas também de sua competitividade relativa dentro do ecossistema. Todo o sistema forma um ciclo multicamadas: dentro da sub-rede, há competição entre modelos; entre sub-redes, há competição pelo desempenho geral. Por fim, o investimento em capacidade de processamento, a eficácia dos modelos e os retornos econômicos estão vinculados, formando um mecanismo de retroalimentação positiva em funcionamento contínuo.
4.3 Gradientes 5.0: Da competição para o "mecanismo de torneio"
Construindo sobre a competição contínua inicial, os Gradients evoluíram para um mecanismo mais estruturado chamado “treinamento por torneio”. Pode-se entendê-lo como uma competição periódica: em cada rodada de treinamento, um intervalo de tempo é definido, múltiplos participantes competem na mesma tarefa e são progressivamente eliminados em várias etapas até que a melhor solução seja selecionada. Esse formato enfatiza comparações em estágios e avaliação concentrada. Uma importante mudança é que os mineiros não enviam mais os resultados do treinamento diretamente, mas sim os “métodos de treinamento” (código), que são então executados uniformemente pelos nós de validação. Isso aumenta a equidade, evitando interferências causadas por diferentes ambientes de computação, e também protege melhor a privacidade dos dados e do processo de treinamento. Além disso, as soluções vencedoras geralmente são incorporadas como métodos reutilizáveis, semelhantes a “práticas recomendadas” acumuladas continuamente. A longo prazo, esse mecanismo não apenas seleciona os melhores modelos, mas também constrói uma biblioteca em constante evolução de métodos de treinamento.
5. Situação ecológica
5.1 Estrutura dos participantes: rede colaborativa composta por demanda, oferta e avaliação
O ecossistema Gradients é composto por três categorias de papéis centrais: usuários (lado da demanda), mineiros (lado da oferta) e validadores (lado da avaliação). Os usuários incluem principalmente desenvolvedores de IA, pequenas e médias empresas e construtores Web3 — grupos que geralmente possuem certa base técnica, mas carecem de capacidade de processamento ou habilidades completas para treinar modelos, optando, portanto, por utilizar o Gradients para construir modelos a um custo mais baixo. Os mineiros fornecem capacidade GPU e participam da competição por tarefas de treinamento, com seu principal incentivo sendo a obtenção de recompensas em TAO; os validadores são responsáveis por avaliar e classificar os resultados do treinamento, sendo essenciais para garantir a qualidade dos modelos e o funcionamento eficaz do mecanismo.
Do ponto de vista de perfis de usuários mais específicos, o grupo real de usuários do Gradients apresenta uma característica claramente “semi-desenvolvedora”: diferente dos laboratórios de IA de ponta, mas também não composto por usuários comuns sem experiência técnica, sendo composto principalmente por desenvolvedores com certa capacidade de engenharia e usuários de tecnologia Web3. Isso também se reflete na estrutura da comunidade, cujo ecossistema atual é dominado pelo inglês, com usuários principais concentrados em grupos de desenvolvedores da América do Norte e da Europa, além de abranger parte dos mineradores do Sudeste Asiático e fornecedores globais de recursos GPU. No geral, aproxima-se de uma comunidade de desenvolvedores impulsionada por tecnologia.
5.2 Situação atual da operação do ecossistema
Até 12 de maio, o preço do token alpha do Gradients era de aproximadamente 0,0255 TAO, com cerca de 4.890 endereços detentores, 243 mineiros e 12 validadores, representando 1,61% da emissão. Ao mesmo tempo, na sua pool de liquidez, o TAO representa 2,19% e o Alpha representa 97,81%. Em termos de preço e número de endereços detentores, o Gradients já possui uma base de usuários e atenção consideráveis, mas ainda se encontra em estágio inicial de disseminação. Em comparação com o projeto líder na ecossistema TAO, Chutes, o preço do token alpha naquele dia era de 0,0877 TAO, com 13.409 endereços detentores.
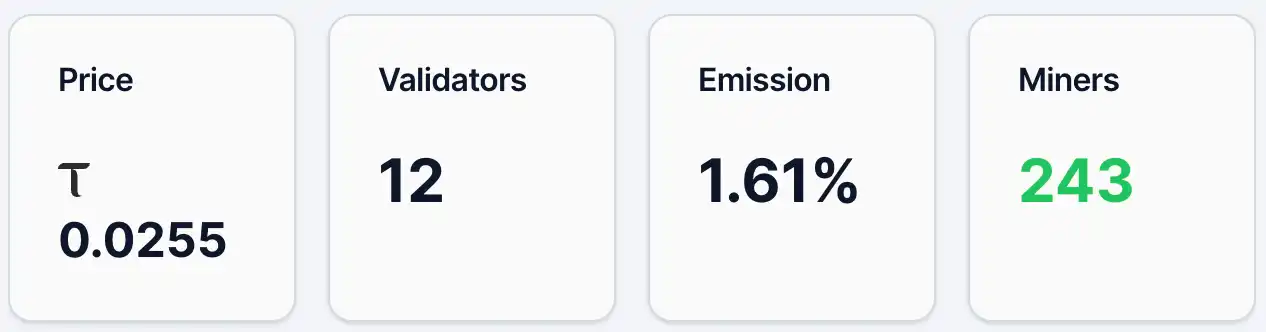
Figura 1. Dados de gradientes.
Fonte:https://bittensormarketcap.com/subnets/56
Em seguida, o mecanismo de emissão. No sistema Bittensor, Emission refere-se ao peso de alocação em tempo real de novas recompensas da rede para cada sub-rede. A rede Bittensor continua gerando novos TAO e os distribui entre as sub-redes com base nesses pesos; o atual 1,61% do Gradients significa que ele recebe apenas uma pequena parcela das novas recompensas da rede inteira. Esse indicador reflete essencialmente o "resultado da votação" da market, por meio de fluxos de capital (como staking), entre as diferentes sub-redes. Portanto, um nível de 1,61% geralmente indica uma aceitação de mercado e entrada de capital relativamente limitadas no momento, mas também sugere que ainda há espaço para aumentar seu peso no futuro. Em termos de estrutura de capital (pools de liquidez), a participação do TAO é apenas de 2,19%, enquanto o Alpha atinge 97,81%, indicando que a entrada de capital externo ainda é limitada e que a oferta atual é predominantemente interna à sub-rede. O preço é sensível a novos fluxos de capital; caso mais TAO entre na rede, pode gerar um efeito multiplicador mais significativo.
6. Cenário competitivo e vantagens e desvantagens
6.1 Posicionamento do setor: infraestrutura de treinamento de AutoML descentralizada
Gradients atua no segmento de "infraestrutura de treinamento de IA + AutoML descentralizado". Busca liberar o treinamento de modelos das plataformas centralizadas e alcançar uma utilização de recursos e otimização de modelos mais eficientes por meio de mecanismos em rede. No ecossistema Web2, esse segmento já é relativamente maduro, com representantes típicos como o Google Vertex AI e o AWS SageMaker. Essas plataformas oferecem aos desenvolvedores serviços integrados de treinamento e implantação de modelos por meio de computação em nuvem, mas sua essência permanece uma arquitetura centralizada. Em contraste, a diferença do Gradients não está em "ter mais funcionalidades", mas sim em um lógica subjacente distinta: transforma o treinamento de "serviço de plataforma" em "colaboração em rede" e utiliza mecanismos de competição para selecionar os melhores resultados, aproximando-se assim de um sistema de treinamento operado como um mercado.
6.2 Comparação horizontal: Diferenças entre Web2 e Web3 AutoML
Do ponto de vista mais amplo, a diferença entre Web2 e Web3 no campo do AutoML é essencialmente uma comparação entre dois paradigmas distintos. O modelo Web2 enfatiza eficiência e estabilidade, oferecendo uma experiência de serviço controlada e madura por meio da concentração de recursos e otimização de engenharia; já o modelo Web3 prioriza abertura e mecanismos de incentivo, permitindo que a otimização de modelos evolua constantemente por meio da participação múltipla. Concretamente, o AutoML Web2 é mais como “uma ferramenta poderosa”, na qual o usuário entrega a tarefa à plataforma, que busca internamente a melhor solução; já o AutoML Web3, representado por Gradients, é mais como “um mercado aberto”, onde os usuários publicam necessidades e diferentes participantes oferecem soluções, sendo os resultados selecionados por um mecanismo de avaliação. Essa diferença traz impactos diretos: o primeiro é mais estável e controlável, mas com caminhos de otimização limitados; o segundo oferece maior espaço de exploração e potencialmente um limite superior mais alto, embora ainda apresente margem para melhoria em estabilidade e maturidade.
6.3 Diferenciação dos Gradients no Web3
No atual cenário Web3 AI, a maioria dos projetos ainda se concentra na camada de inferência ou em AI Agents, enquanto os projetos focados em “infraestrutura de treinamento” são relativamente escassos. Alguns projetos tentam combinar redes de poder computacional ou redes de dados para fornecer capacidade de treinamento, mas, no geral, a maioria ainda permanece no nível de agendamento de recursos ou mercado de poder computacional. A diferença do Gradients é que ele não apenas oferece emparelhamento de poder computacional, mas também se estende ainda mais para cima, até o próprio “mecanismo de otimização de modelos”, introduzindo um sistema de avaliação e competição que permite que o processo de treinamento tenha capacidade de evolução contínua. Isso significa que ele não apenas resolve a questão de “de onde vem o poder computacional”, mas também aborda “como usar esse poder computacional de forma mais eficiente”. Em termos de posicionamento, o Gradients é mais próximo de uma rede “orientada para resultados de treinamento”, e não apenas um mercado de poder computacional ou plataforma de ferramentas — essa é a diferença central em relação à maioria dos projetos Web3 AI.
6.4 Vantagens principais: aumento de eficiência impulsionado por mecanismos
Em termos gerais, as vantagens do Gradients estão principalmente em seu design de mecanismo. Em primeiro lugar, ele reduz a barreira de entrada por meio da abstração de tarefas, permitindo que os usuários obtenham resultados de modelos sem participar profundamente de processos de treinamento complexos, ampliando assim o público potencial. Em segundo lugar, no nível de recursos, a introdução de poder computacional distribuído elimina a dependência de um único fornecedor de nuvem, podendo teoricamente formar, por meio da concorrência, uma estrutura de custo mais resiliente. Mais importante ainda é a mudança em sua abordagem de otimização. Ao permitir a exploração paralela por múltiplos participantes combinada com um mecanismo de seleção, o Gradients oferece uma solução diferente da otimização tradicional de caminho único, possibilitando que os modelos alcancem desempenho superior em menos tempo. Esse modelo de “otimização impulsionada pela concorrência” é sua vantagem mais central.
6.5 Desafios potenciais
A qualidade do modelo pode apresentar problemas de estabilidade. O treinamento descentralizado depende da participação de múltiplas partes; embora possa elevar o limite superior, também pode causar flutuações nos resultados, apresentando certa incerteza em termos de controle em comparação com sistemas centralizados. Em seguida, há a questão de confiança empresarial. Para usuários corporativos, a segurança dos dados e a verificabilidade do processo de treinamento são cruciais, e garantir que os dados não sejam mal utilizados e que os resultados possam ser auditados em um ambiente descentralizado continua sendo um desafio fundamental. Por fim, há a dependência do modelo econômico de tokens. O funcionamento dos Gradients depende fortemente de mecanismos de incentivo; se a atratividade dos rendimentos de TAO diminuir, isso pode afetar a participação dos mineiros e a atividade geral da rede. Portanto, sua sustentabilidade a longo prazo depende, em certa medida, de o modelo econômico conseguir formar um ciclo positivo estável.
7. Visão futura: O AutoML descentralizado pode se tornar realidade?
Do estágio atual, o Gradients ainda está no início, e seu sucesso futuro dependerá de alguns pontos-chave. O mais fundamental é se conseguir atrair continuamente demanda real de treinamento, e não apenas participação baseada em incentivos; em seguida, a qualidade do modelo — se a abordagem descentralizada pode produzir consistentemente resultados utilizáveis, ou até superiores; e se o mecanismo econômico pode formar um ciclo positivo, mantendo um equilíbrio duradouro entre oferta de poder de computação e recompensas.
Em um contexto industrial mais amplo, o treinamento de IA está se dividindo em dois caminhos. Um é o modelo Web2, liderado por grandes empresas de tecnologia, que reforçam continuamente o desempenho dos modelos por meio de recursos e capacidades de engenharia centralizadas, com a vantagem de estabilidade e maturidade; o outro é o caminho Web3, representado por Gradients, que, por meio de redes abertas e mecanismos de incentivo, permite que mais participantes colaborem na otimização dos modelos, elevando constantemente seu limite superior na competição. O primeiro está “criando sistemas mais fortes”, enquanto o segundo é mais como “construir uma rede que se autoevolui”.
Do ponto de vista deste ângulo, a exploração dos Gradients representa uma nova possibilidade: o treinamento de IA já não é apenas um problema técnico, mas uma combinação de “poder de computação + dados + mecanismos de mercado”. Se este modelo se mostrar viável, ele tem o potencial de se tornar a porta de entrada para o treinamento de IA descentralizada e desempenhar um papel crucial como infraestrutura fundamental no ecossistema Bittensor. Claro, esta direção ainda precisa de tempo para ser validada, mas já oferece ao AutoML uma linha de evolução distinta da abordagem tradicional.
Referência
1. Documentação do Bittensor:https://docs.learnbittensor.org
2. Site dos Gradients:https://www.gradients.io/
3. Gradientes:https://bittensormarketcap.com/subnets/56
4. Gradients X: https://x.com/gradients_ai
5. Taostats:https://taostats.io/subnets/56/chart